
Aquila
Collection
22 items
•
Updated
•
4
The Aquila-135M model is a small bilingual(Chinese and English) language model, which is trained using a two-phrase paradigm: pre-training and annealing. This model used 1.66TB bilingual tokens in Chinese and English during pre-training phrase and 100B tokens during annealing training phrase. In annealing stage, we selected 100B tokens of high-quality bilingual data and finally got our model.
The Aquila-135M-Instuct model is finetuned using Infinity Instruct.
The entire training process was conducted using FlagGems based on Triton and parallel training framework named FlagScale.
Also, we have open-sourced all intermediate checkpoints.
2024/12/24: We have released Aquila-135M and Aquila-135M-Instruct.2024/12/24: We have released all datasets and intermediate checkpoints during training. Please feel free to use these models for analysis and experimentation.We have open-sourced all bilingual datasets during both pre-training and annealing phrases.
Datasets composition and mix proportions are shown in the figure below.
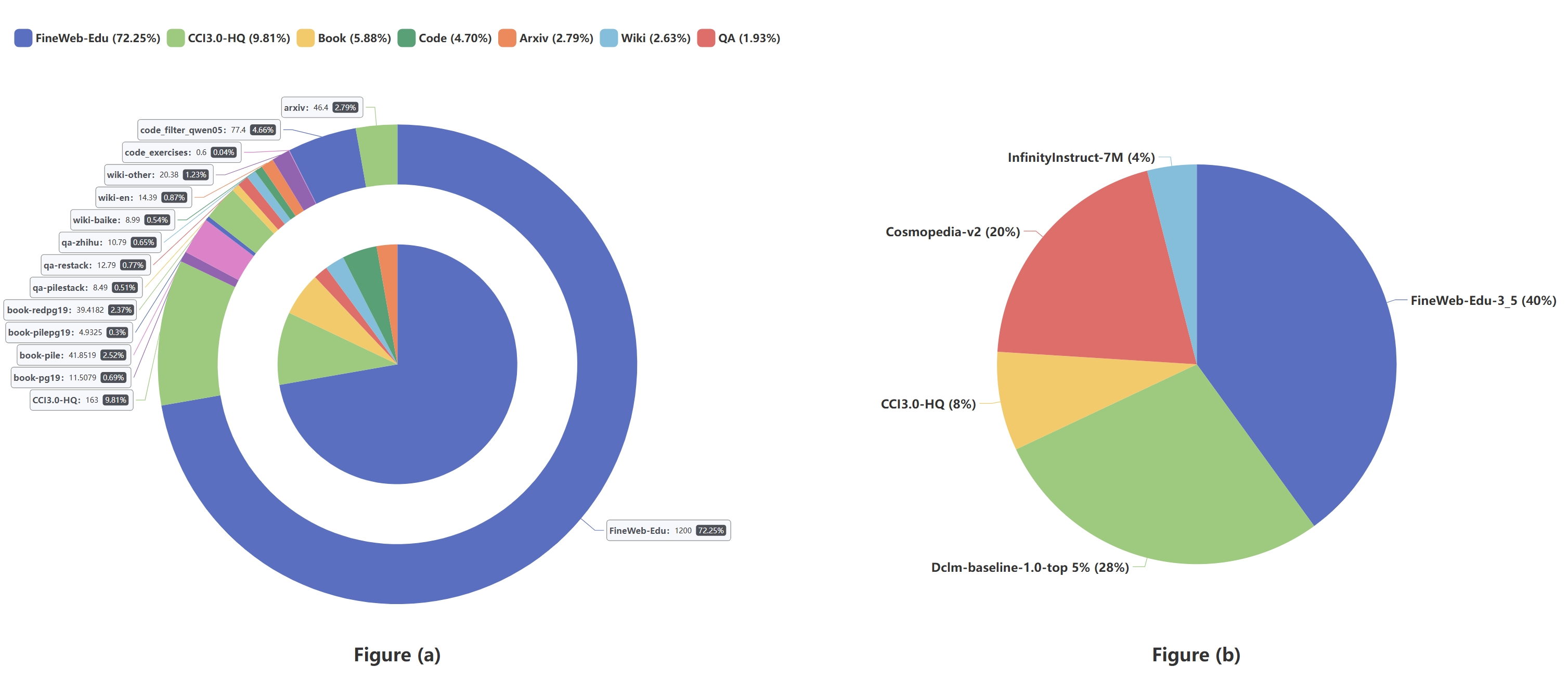
We followed the same evaluation setting of SmolLM models and evaluated models using the lighteval tool.
The parameter count excludes the embedding part and Aquila-135M and SmolLM2-135M share an identical model structure. Aquila-135M achieves comparable performance on English benchmarks, while Aquila-135M demonstrates significantly better results on Chinese benchmarks.
Among small models with a total parameter count below and around 400M, Aquila-135M maintains a leading position in processing capabilities while significantly enhancing Chinese language proficiency.
| Metrics (0-shot) | Aquila-135M (Trition) | Aquila-135M (CUDA) | SmolLM-135M | SmolLM2-135M | gpt2-medium-360M | TinyMistral-248M | TinyMistral-248M-2.5 | OpenELM-270M | Wide-Sheared-LLaMA-290M | opt-350m | MobileLLM-350M | pythia-410m | SmolLM-360M | SmolLM2-360M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HellaSwag | 41.19 | 41.12 | 41.15 | 42.10 | 37.08 | 27.06 | 26.80 | 45.74 | 24.94 | 36.08 | 26.28 | 39.22 | 51.73 | 54.66 |
| ARC (Average) | 44.76 | 44.15 | 42.34 | 43.93 | 34.34 | 29.71 | 27.63 | 35.74 | 26.20 | 31.91 | 27.72 | 35.14 | 49.95 | 53.24 |
| PIQA | 66.38 | 67.52 | 68.28 | 68.44 | 66.38 | 57.40 | 53.92 | 69.75 | 50.60 | 64.36 | 50.27 | 67.19 | 71.55 | 71.98 |
| MMLU (cloze) | 31.07 | 30.67 | 30.26 | 31.58 | 27.75 | 25.82 | 25.59 | 27.89 | 24.75 | 26.58 | 24.86 | 28.88 | 34.32 | 36.09 |
| CommonsenseQA | 32.10 | 31.70 | 32.02 | 32.92 | 31.70 | 24.57 | 21.46 | 35.71 | 16.54 | 32.10 | 17.53 | 31.45 | 36.61 | 38.74 |
| TriviaQA | 6.65 | 7.02 | 4.24 | 4.03 | 2.36 | 0.50 | 0.08 | 1.34 | 0.00 | 1.38 | 0.00 | 2.06 | 9.19 | 16.92 |
| Winograde | 51.07 | 51.70 | 51.22 | 50.99 | 49.49 | 49.25 | 49.01 | 52.41 | 49.72 | 51.54 | 49.41 | 49.96 | 53.12 | 52.49 |
| OpenBookQA | 34.40 | 34.40 | 33.80 | 34.60 | 31.40 | 29.40 | 27.40 | 30.60 | 26.00 | 27.80 | 24.80 | 28.40 | 37.20 | 37.00 |
| GSM8K (5-shot) | 2.12 | 2.12 | 1.00 | 1.52 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.81 |
| SIQA | 41.81 | 42.32 | 41.15 | 41.45 | 41.30 | 41.86 | 39.71 | 42.73 | 39.76 | 42.37 | 37.10 | 42.02 | 43.45 | 41.61 |
| CEval | 29.22 | 29.82 | 28.28 | 26.41 | 25.40 | 25.38 | 26.89 | 26.69 | 26.37 | 26.67 | 25.68 | 27.97 | 27.66 | 28.51 |
| CMMLU | 29.48 | 29.63 | 26.01 | 26.66 | 27.20 | 26.67 | 25.57 | 26.25 | 26.33 | 26.93 | 25.61 | 26.91 | 27.06 | 27.39 |
| Average-English | 35.16 | 35.27 | 34.55 | 35.16 | 32.18 | 28.56 | 27.16 | 34.19 | 25.85 | 31.41 | 25.80 | 32.43 | 38.71 | 40.55 |
| Average-Chinese | 29.35 | 29.73 | 27.15 | 26.54 | 26.30 | 26.03 | 26.23 | 26.47 | 26.35 | 26.80 | 25.65 | 27.44 | 27.36 | 27.95 |
| Average | 32.25 | 32.50 | 30.85 | 30.85 | 29.24 | 27.29 | 26.70 | 30.33 | 26.10 | 29.11 | 25.72 | 29.94 | 33.04 | 34.25 |
For comparison models, evaluations were conducted in a local environment, so the scores may differ slightly from those reported in papers.
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "BAAI/Aquila-135M-Instruct"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
# for multiple GPUs install accelerate and do `model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")`
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
messages = [{"role": "user", "content": "什么是引力?"}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_new_tokens=500)
print(tokenizer.decode(outputs[0]))
## 引力是宇宙中的一个基本力,由多个物体相互作用而产生的。它由能量和质量组成,与引力定律密切相关。
messages = [{"role": "user", "content": "What is gravity?"}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_new_tokens=500)
print(tokenizer.decode(outputs[0]))
## Gravity is the force that keeps us on Earth as we orbit it. It pulls objects towards each other with a strength that depends on how far apart they are from each other, and how strong the gravitational pull is. The stronger the object's mass, the greater its gravitational pull.
If you find this useful, please cite the following work
@misc{aquila-135m,
title={Aquila-135M: A Bilingual Small Language Model in Chinese and English},
author={BAAI},
year={},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={},
}