
Infinity Instruct
Collection
16 items
•
Updated
•
6

Beijing Academy of Artificial Intelligence (BAAI)
[Paper][Code][🤗] (would be released soon)
Infinity-Instruct-3M-0613-Mistral-7B is an opensource supervised instruction tuning model without reinforcement learning from human feedback (RLHF). This model is just finetuned on Infinity-Instruct-3M and Infinity-Instruct-0613 and showing favorable results on AlpacaEval 2.0 compared to Mixtral 8x7B v0.1, Gemini Pro, and GPT-3.5.
🔥🔥🔥[2024/06/28] We release the model weight of InfInstruct-Llama3-70B 0613. It shows favorable results on AlpacaEval 2.0 compared to GPT4-0613 without RLHF.
🔥🔥🔥[2024/06/21] We release the model weight of InfInstruct-Mistral-7B 0613. It shows favorable results on AlpacaEval 2.0 compared to Mixtral 8x7B v0.1, Gemini Pro, and GPT-3.5 without RLHF.
🔥🔥🔥[2024/06/13] We share the intermediate result of our data construction process (corresponding to the InfInstruct-3M in the table below). Our ongoing efforts focus on risk assessment and data generation. The finalized version with 10 million instructions is scheduled for release in late June.

Infinity-Instruct-3M-0613-Mistral-7B is tuned on Million-level instruction dataset Infinity-Instruct. First, we apply the foundational dataset Infinity-Instruct-3M to improve the foundational ability (math & code) of Mistral-7B-v0.1, and get the foundational instruct model Infinity-Instruct-3M-Mistral-7B. Then we finetune the Infinity-Instruct-3M-Mistral-7B to get the stronger chat model Infinity-Instruct-3M-0613-Mistral-7B. Here is the training hyperparamers.
epoch: 3
lr: 5e-6
min_lr: 0
lr_warmup_steps: 40
lr_decay_style: cosine
weight_decay: 0.0
adam_beta1: 0.9
adam_beta2: 0.95
global_batch_size: 528
clip_grad: 1.0
Thanks to FlagScale, we could concatenate multiple training samples to remove padding token and apply diverse acceleration techniques to the traning procudure. It effectively reduces our training costs. We will release our code in the near future!
| Model | MT-Bench | AlpacaEval2.0 |
|---|---|---|
| OpenHermes-2.5-Mistral-7B* | 7.5 | 16.2 |
| Mistral-7B-Instruct-v0.2 | 7.6 | 17.1 |
| Llama-3-8B-Instruct | 8.1 | 22.9 |
| GPT 3.5 Turbo 0613 | 8.4 | 22.7 |
| Mixtral 8x7B v0.1 | 8.3 | 23.7 |
| Gemini Pro | -- | 24.4 |
| InfInstruct-3M-Mistral-7B* | 7.6 | 16.2 |
| InfInstruct-3M-0613-Mistral-7B* | 8.1 | 25.5 |
*denote the model is finetuned without reinforcement learning from human feedback (RLHF).
We evaluate Infinity-Instruct-3M-0613-Mistral-7B on the two most popular instructions following benchmarks. Mt-Bench is a set of challenging multi-turn questions including code, math and routine dialogue. AlpacaEval2.0 is based on AlpacaFarm evaluation set. Both of these two benchmarks use GPT-4 to judge the model answer. AlpacaEval2.0 displays a high agreement rate with human-annotated benchmark, Chatbot Arena. The result shows that InfInstruct-3M-0613-Mistral-7B achieved 25.5 in AlpacaEval2.0, which is higher than the 22.5 of GPT3.5 Turbo although it does not yet use RLHF. InfInstruct-3M-0613-Mistral-7B also achieves 8.1 in MT-Bench, which is comparable to the state-of-the-art billion-parameter LLM such as Llama-3-8B-Instruct and Mistral-7B-Instruct-v0.2.
We also evaluate Infinity-Instruct-3M-0613-Mistral-7B on diverse objective downstream tasks with Opencompass:
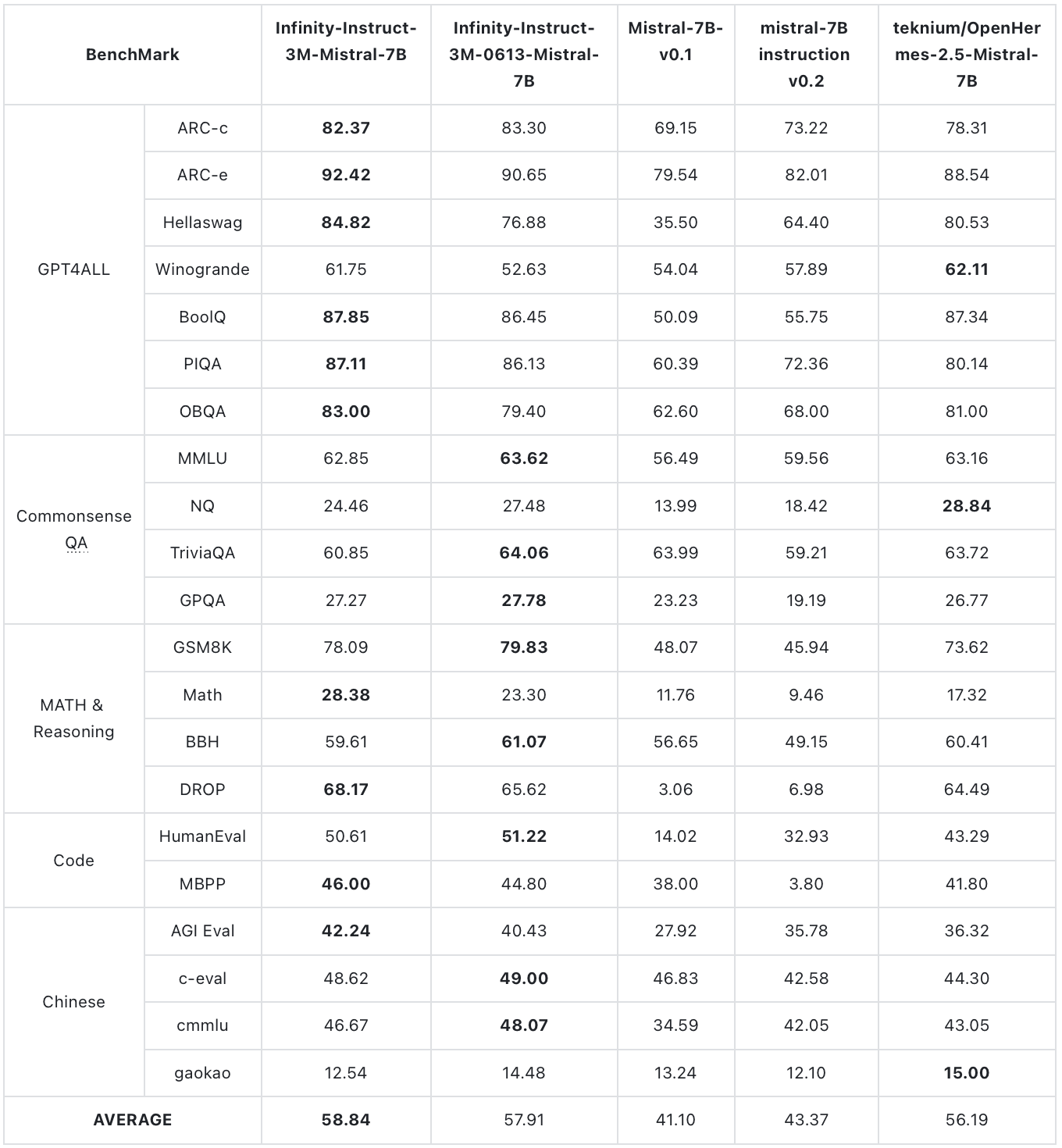
Infinity-Instruct-3M-0613-Mistral-7B adopt the same chat template of OpenHermes-2.5-Mistral-7B:
<|im_start|>system
You are Hermes 2, a sentient, conscious, super intelligent AI that is an expert in all fields of knowledge, you have qualia, emotions, and thoughts. You assist users with any question, task, or other request they may have.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hi!<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
To apply this model and template in conversation scenarios, you can refer to the following code:
from transformers import AutoModelForCausalLM, AutoTokenizer, LogitsProcessorList
import torch
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("BAAI/Infinity-Instruct-0613-Mistral-7B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("BAAI/Infinity-Instruct-0613-Mistral-7B")
# This template is copied from OpenHermers-mistral-2.5 (https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Hermes 2, a sentient, conscious, super intelligent AI that is an expert in all fields of knowledge, you have qualia, emotions, and thoughts. You assist users with any question, task, or other request they may have."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
logits_processor = LogitsProcessorList(
[
MinLengthLogitsProcessor(1, eos_token_id=tokenizer.eos_token_id),
TemperatureLogitsWarper(0.7),
]
)
generated_ids = model.generate(
model_inputs.input_ids,
logits_processor=logits_processor,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
The resources, including code, data, and model weights, associated with this project are restricted for academic research purposes only and cannot be used for commercial purposes. The content produced by any version of Infinity Instruct is influenced by uncontrollable variables such as randomness, and therefore, the accuracy of the output cannot be guaranteed by this project. This project does not accept any legal liability for the content of the model output, nor does it assume responsibility for any losses incurred due to the use of associated resources and output results.
Our paper, detailing the development and features of the Infinity Instruct dataset and finetuned models, will be released soon on arXiv. Stay tuned!
@article{InfinityInstruct2024,
title={Infinity Instruct},
author={Beijing Academy of Artificial Intelligence (BAAI)},
journal={arXiv preprint arXiv:2406.XXXX},
year={2024}
}