

Orion-14B
目录
1. 模型介绍
Orion-14B-Base是一个具有140亿参数的多语种大模型,该模型在一个包含2.5万亿token的多样化数据集上进行了训练,涵盖了中文、英语、日语、韩语等多种语言。在多语言环境下的一系列任务中展现出卓越的性能。在主流的公开基准评测中,Orion-14B系列模型表现优异,多项指标显著超越同等参数基本的其他模型。具体技术细节请参考技术报告。
Orion-14B系列大模型有以下几个特点:
- 基座20B参数级别大模型综合评测效果表现优异
- 多语言能力强,在日语、韩语测试集上显著领先
- 微调模型适应性强,在人类标注盲测中,表现突出
- 长上下文版本支持超长文本,在200k token长度上效果优异,最长可支持可达320k
- 量化版本模型大小缩小70%,推理速度提升30%,性能损失小于1%
|
|
- 具体而言,Orion-14B系列大语言模型包含:
- Orion-14B-Base: 基于2.5万亿tokens多样化数据集训练处的140亿参数量级的多语言基座模型。
- Orion-14B-Chat: 基于高质量语料库微调的对话类模型,旨在为大模型社区提供更好的用户交互体验。
- Orion-14B-LongChat: 在200k token长度上效果优异,最长可支持可达320k,在长文本评估集上性能比肩专有模型。
- Orion-14B-Chat-RAG: 在一个定制的检索增强生成数据集上进行微调的聊天模型,在检索增强生成任务中取得了卓越的性能。
- Orion-14B-Chat-Plugin: 专门针对插件和函数调用任务定制的聊天模型,非常适用于使用代理的相关场景,其中大语言模型充当插件和函数调用系统。
- Orion-14B-Base-Int4: 一个使用int4进行量化的基座模型。它将模型大小显著减小了70%,同时提高了推理速度30%,仅引入了1%的最小性能损失。
- Orion-14B-Chat-Int4: 一个使用int4进行量化的对话模型。
2. 下载路径
发布模型和下载链接见下表:
| 模型名称 | HuggingFace下载链接 | ModelScope下载链接 |
|---|---|---|
| ⚾ 基座模型 | Orion-14B-Base | Orion-14B-Base |
| 😛 对话模型 | Orion-14B-Chat | Orion-14B-Chat |
| 📃 长上下文模型 | Orion-14B-LongChat | Orion-14B-LongChat |
| 🔎 检索增强模型 | Orion-14B-Chat-RAG | Orion-14B-Chat-RAG |
| 🔌 插件模型 | Orion-14B-Chat-Plugin | Orion-14B-Chat-Plugin |
| 💼 基座Int4量化模型 | Orion-14B-Base-Int4 | Orion-14B-Base-Int4 |
| 📦 对话Int4量化模型 | Orion-14B-Chat-Int4 | Orion-14B-Chat-Int4 |
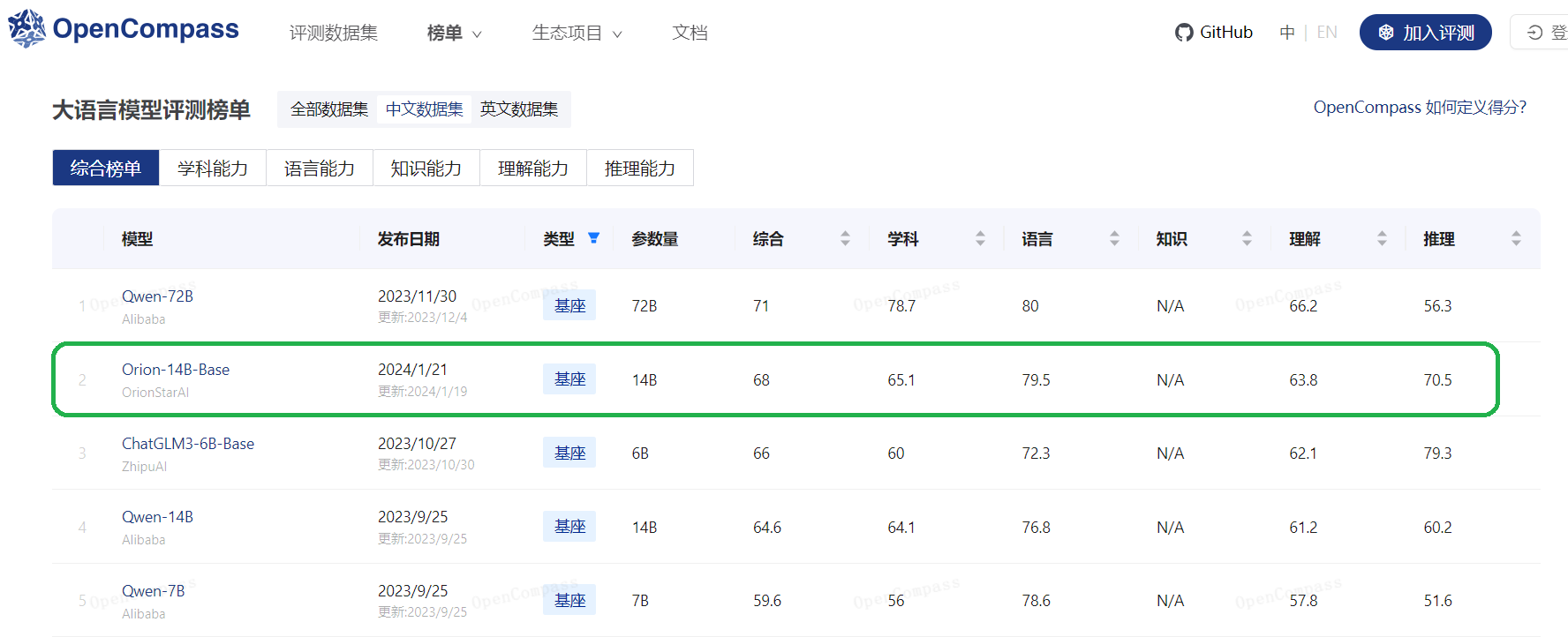
3. 评估结果
3.1. 基座模型Orion-14B-Base评估
3.1.1. 专业知识与试题评估结果
| 模型名称 | C-Eval | CMMLU | MMLU | AGIEval | Gaokao | BBH |
|---|---|---|---|---|---|---|
| LLaMA2-13B | 41.4 | 38.4 | 55.0 | 30.9 | 18.2 | 45.6 |
| Skywork-13B | 59.1 | 61.4 | 62.7 | 43.6 | 56.1 | 48.3 |
| Baichuan2-13B | 59.0 | 61.3 | 59.5 | 37.4 | 45.6 | 49.0 |
| QWEN-14B | 71.7 | 70.2 | 67.9 | 51.9 | 62.5 | 53.7 |
| InternLM-20B | 58.8 | 59.0 | 62.1 | 44.6 | 45.5 | 52.5 |
| Orion-14B-Base | 72.9 | 70.6 | 69.9 | 54.7 | 62.1 | 56.5 |
3.1.2. 理解与通识评估结果
| 模型名称 | RACE-middle | RACE-high | HellaSwag | PIQA | Lambada | WSC |
|---|---|---|---|---|---|---|
| LLaMA 2-13B | 63.0 | 58.9 | 77.5 | 79.8 | 76.5 | 66.3 |
| Skywork-13B | 87.6 | 84.1 | 73.7 | 78.3 | 71.8 | 66.3 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
| QWEN-14B | 93.0 | 90.3 | 80.2 | 79.8 | 71.4 | 66.3 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | 80.3 | 71.8 | 68.3 |
| Orion-14B-Base | 93.2 | 91.3 | 78.5 | 79.5 | 78.8 | 70.2 |
3.1.3. OpenCompass评测集评估结果
| 模型名称 | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|---|---|---|---|---|---|---|
| LLaMA 2-13B | 47.3 | 45.2 | 47.0 | 58.3 | 50.9 | 43.6 |
| Skywork-13B | 53.6 | 61.1 | 51.3 | 52.7 | 64.5 | 45.2 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | 60.1 | 67.3 | 54.9 |
| Orion-14B-Base | 64.3 | 71.4 | 55.0 | 60.0 | 71.9 | 61.6 |
3.1.4. 日语测试集评估结果
| 模型名称 | Average | JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|---|---|---|---|---|---|---|---|---|---|
| PLaMo-13B | 52.3 | 56.7 | 42.8 | 95.8 | 70.6 | 71.0 | 8.70 | 70.5 | 2.40 |
| WebLab-10B | 50.7 | 66.6 | 53.7 | 82.1 | 62.9 | 56.2 | 10.0 | 72.0 | 2.40 |
| ELYZA-jp-7B | 48.8 | 71.7 | 25.3 | 86.6 | 70.8 | 64.1 | 2.50 | 62.1 | 7.20 |
| StableLM-jp-7B | 51.1 | 33.4 | 43.3 | 96.7 | 70.6 | 78.1 | 10.7 | 72.8 | 2.80 |
| LLaMA 2-13B | 46.3 | 75.0 | 47.6 | 38.8 | 76.1 | 67.7 | 18.1 | 63.2 | 10.4 |
| Baichuan 2-13B | 57.1 | 73.7 | 31.3 | 91.6 | 80.5 | 63.3 | 18.6 | 72.2 | 25.2 |
| QWEN-14B | 65.8 | 85.9 | 60.7 | 97.0 | 83.3 | 71.8 | 18.8 | 70.6 | 38.0 |
| Yi-34B | 67.1 | 83.8 | 61.2 | 95.2 | 86.1 | 78.5 | 27.2 | 69.2 | 35.2 |
| Orion-14B-Base | 69.1 | 88.2 | 75.8 | 94.1 | 75.7 | 85.1 | 17.3 | 78.8 | 38.0 |
3.1.5. 韩语测试集n-shot评估结果
| 模型名称 | Average n=0 n=5 |
HellaSwag n=0 n=5 |
COPA n=0 n=5 |
BooIQ n=0 n=5 |
SentiNeg n=0 n=5 |
|---|---|---|---|---|---|
| KoGPT | 53.0 70.1 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 | 37.5 89.4 |
| Polyglot-ko-13B | 69.6 73.7 | 59.5 63.1 | 79.4 81.1 | 48.2 60.4 | 91.2 90.2 |
| LLaMA 2-13B | 46.7 63.7 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 | 51.5 73.4 |
| Baichuan 2-13B | 52.1 58.7 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 | 50.3 72.9 |
| QWEN-14B | 53.8 73.7 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 | 71.5 95.7 |
| Yi-34B | 54.2 72.1 | 44.6 44.7 | 58.0 60.6 | 65.9 90.2 | 48.3 92.9 |
| Orion-14B-Base | 74.5 79.6 | 47.0 49.6 | 77.7 79.4 | 81.6 90.7 | 92.4 98.7 |
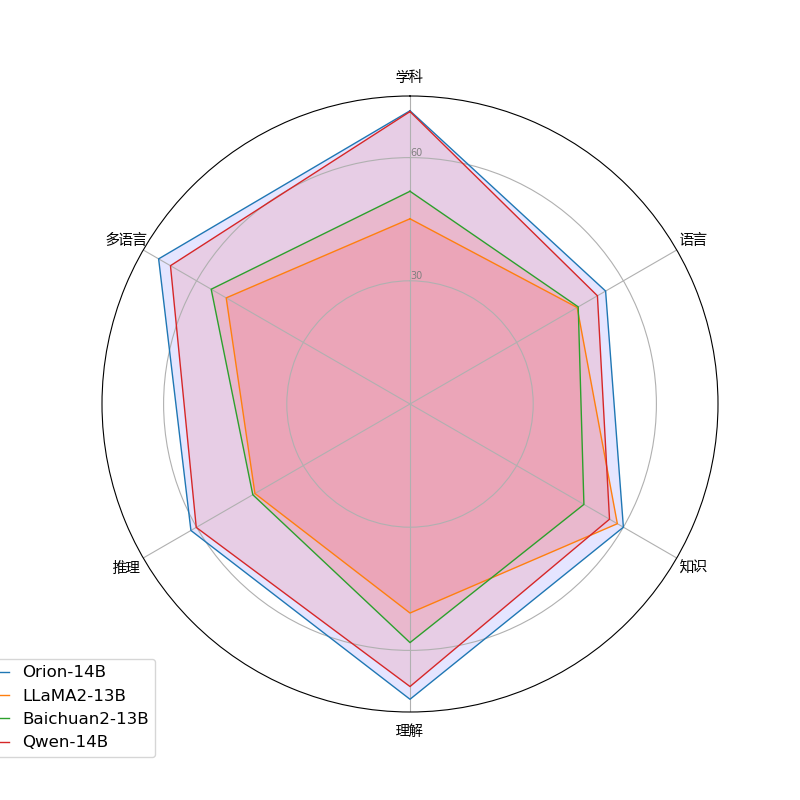
3.1.6. 多语言评估结果
| 模型名称 | Train Lang | Japanese | Korean | Chinese | English |
|---|---|---|---|---|---|
| PLaMo-13B | En,Jp | 52.3 | * | * | * |
| Weblab-10B | En,Jp | 50.7 | * | * | * |
| ELYZA-jp-7B | En,Jp | 48.8 | * | * | * |
| StableLM-jp-7B | En,Jp | 51.1 | * | * | * |
| KoGPT-6B | En,Ko | * | 70.1 | * | * |
| Polyglot-ko-13B | En,Ko | * | 70.7 | * | * |
| Baichuan2-13B | Multi | 57.1 | 58.7 | 50.8 | 57.1 |
| Qwen-14B | Multi | 65.8 | 73.7 | 64.5 | 65.4 |
| Llama2-13B | Multi | 46.3 | 63.7 | 41.4 | 55.3 |
| Yi-34B | Multi | 67.1 | 72.2 | 58.7 | 68.8 |
| Orion-14B-Base | Multi | 69.1 | 79.5 | 67.9 | 67.3 |
3.2. 对话模型Orion-14B-Chat评估
3.2.1. 对话模型MTBench主观评估
| 模型名称 | 第一轮 | 第二轮 | 平均 |
|---|---|---|---|
| Baichuan2-13B-Chat | 7.05 | 6.47 | 6.76 |
| Qwen-14B-Chat | 7.30 | 6.62 | 6.96 |
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
| Orion-14B-Chat | 7.68 | 7.07 | 7.37 |
*这里评测使用vllm进行推理
3.2.2. 对话模型AlignBench主观评估
| 模型名称 | 数学能力 | 逻辑推理 | 基本能力 | 中文理解 | 综合问答 | 写作能力 | 角色扮演 | 专业知识 | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 3.76 | 4.07 | 6.22 | 6.05 | 7.11 | 6.97 | 6.75 | 6.43 | 5.25 |
| Qwen-14B-Chat | 4.91 | 4.71 | 6.90 | 6.36 | 6.74 | 6.64 | 6.59 | 6.56 | 5.72 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | 7.18 | 6.19 | 6.49 | 6.22 | 4.96 |
| Orion-14B-Chat | 4.00 | 4.24 | 6.18 | 6.57 | 7.16 | 7.36 | 7.16 | 6.99 | 5.51 |
*这里评测使用vllm进行推理
3.3. 长上下文模型Orion-14B-LongChat评估
3.3.1. 长上下文模型LongBench评估
| 模型名称 | NarrativeQA | MultiFieldQA-en | MultiFieldQA-zh | DuReader | QMSum | VCSUM | TREC | TriviaQA | LSHT | RepoBench-P |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-16k | 23.60 | 52.30 | 61.20 | 28.70 | 23.40 | 16.00 | 68.00 | 91.40 | 29.20 | 53.60 |
| LongChat-v1.5-7B-32k | 16.90 | 41.40 | 29.10 | 19.50 | 22.70 | 9.90 | 63.50 | 82.30 | 23.20 | 55.30 |
| Vicuna-v1.5-7B-16k | 19.40 | 38.50 | 43.00 | 19.30 | 22.80 | 15.10 | 71.50 | 86.20 | 28.80 | 43.50 |
| Yi-6B-200K | 14.11 | 36.74 | 22.68 | 14.01 | 20.44 | 8.08 | 72.00 | 86.61 | 38.00 | 63.29 |
| Orion-14B-LongChat | 19.47 | 48.11 | 55.84 | 37.02 | 24.87 | 15.44 | 77.00 | 89.12 | 45.50 | 54.31 |
3.4. 检索增强模型Orion-14B-Chat-RAG评估
3.4.1. 自建检索增强测试集评估结果
| 模型名称 | 回复效果(关键字) | *回复效果(主观打分) | 引用能力 | 兜底能力 | *AutoQA | *抽取数据 |
|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 85 | 76 | 1 | 0 | 69 | 51 |
| Qwen-14B-Chat | 79 | 77 | 75 | 47 | 68 | 72 |
| Qwen-72B-Chat(Int4) | 87 | 89 | 90 | 32 | 67 | 76 |
| GPT-4 | 91 | 94 | 96 | 95 | 75 | 86 |
| Orion-14B-Chat-RAG | 86 | 87 | 91 | 97 | 73 | 71 |
| * 表示人工评判结果 |
3.5. 插件模型Orion-14B-Chat-Plugin评估
3.5.1. 自建插件测试集评估结果
| 模型名称 | 全参数意图识别 | 缺参数意图识别 | 非插件调用识别 |
|---|---|---|---|
| Baichuan2-13B-Chat | 25 | 0 | 0 |
| Qwen-14B-Chat | 55 | 0 | 50 |
| GPT-4 | 95 | 52.38 | 70 |
| Orion-14B-Chat-Plugin | 92.5 | 60.32 | 90 |
3.6. 量化模型Orion-14B-Base-Int4评估
3.6.1. 量化前后整体对比
| 模型名称 | 模型大小(GB) | 推理速度(令牌数/秒) | C-Eval | CMMLU | MMLU | RACE | HellaSwag |
|---|---|---|---|---|---|---|---|
| OrionStar-14B-Base | 28.0 | 135 | 72.8 | 70.6 | 70.0 | 93.3 | 78.5 |
| OrionStar-14B-Base-Int4 | 8.3 | 178 | 71.8 | 69.8 | 69.2 | 93.1 | 78.0 |
4. 模型推理
推理所需的模型权重、源码、配置已发布在 Hugging Face,下载链接见本文档最开始的表格。我们在此示范多种推理方式。程序会自动从 Hugging Face 下载所需资源。
4.1. Python 代码方式
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto",
torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
messages = [{"role": "user", "content": "你好! 你叫什么名字!"}]
response = model.chat(tokenizer, messages, streaming=False)
print(response)
在上述两段代码中,模型加载指定 device_map='auto'
,会使用所有可用显卡。如需指定使用的设备,可以使用类似 export CUDA_VISIBLE_DEVICES=0,1(使用了0、1号显卡)的方式控制。
4.2. 命令行工具方式
CUDA_VISIBLE_DEVICES=0 python cli_demo.py
本命令行工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
4.3. 脚本直接推理
# base model
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt 你好,你叫什么名字
# chat model
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt 你好,你叫什么名字
4.4. 使用vllm推理
4.5. 使用llama.cpp推理
如何转换GGUF格式模型
python convert-hf-to-gguf.py path/to/Orion-14B-Chat --outfile chat.gguf如何运行GGUF格式模型推理
./main --frequency-penalty 0.5 --frequency-penalty 0.5 --top-k 5 --top-p 0.9 -m chat.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
4.6. 示例输出
4.6.1. 闲聊
用户:你好,你叫什么名字
Orion-14B:你好!我是一个人工智能助手,没有固定的名字。你可以随意称呼我。有什么我可以帮助你的吗?
用户:讲个故事
Orion-14B:从前有一个小男孩叫杰克,他住在一个小村庄里。杰克非常喜欢冒险和探索,总是梦想着能够发现一些神奇的事情。
有一天,杰克听说在附近的森林深处有一座传说中的魔法城堡,里面住着一个邪恶的巨人。这个巨人的名字叫格里姆,他被困在城堡中,无法离开。
杰克决定要去解救这个巨人,因为他相信格里姆一定有自己的原因被困在那里。于是,他带着勇气和决心,踏上了前往魔法城堡的旅程。
经过长时间的跋涉,杰克终于来到了城堡的大门前。他小心翼翼地推开大门,进入了一个充满神秘气息的房间。
房间里弥漫着黑暗的气息,但杰克并没有被吓倒。他勇敢地向城堡深处走去,最终找到了格里姆。
格里姆告诉杰克,他是被一个邪恶的女巫诅咒的,只有通过解开咒语才能获得自由。杰克决定要帮助格里姆,他开始寻找线索和解开咒语的方法。
经过一番努力,杰克终于找到了一条通往女巫的秘密实验室的道路。他在那里发现了女巫留下的魔法书,书中记载了解开咒语的方法。
杰克按照书上所写的步骤进行操作,成功地解开了格里姆身上的诅咒。巨人感激不已,他答应帮助杰克实现他的愿望。
从此以后,杰克和格里姆成为了好朋友,他们一起经历了许多惊险刺激的冒险,并用他们的勇气和智慧战胜了各种困难。
这个故事告诉我们,只要有勇气和决心,我们就能克服一切困难,实现自己的梦想。
4.6.2. 日韩
用户:自己を紹介してください
Orion-14B:こんにちは、私の名前はChatMaxで、OrionStarによって開発されたAIアシスタントです。私はユーザーに正確で、客観的で、有用な回答を提供し、彼らが問題を解決し、情報を取得するのを助けることができます。
用户:자기소개를 해주세요.
Orion-14B:안녕하세요, 제 이름은 ChatMax입니다. OrionStar에서 개발한 AI 어시스턴트입니다. 저는 사용자들에게 정확하고 객관적이며 유용한 답변을 제공하여 문제를 해결하고 정보를 얻는 데 도움을 줄 수 있습니다.
5. 声明、协议
5.1. 声明
我们强烈呼吁所有使用者,不要利用 Orion-14B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Orion-14B 模型用于未经适当安全审查和备案的互联网服务。
我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。 我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Orion-14B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
5.2. 协议
社区使用Orion-14B系列模型
- 代码请遵循 Apache License Version 2.0
- 模型请遵循 Orion-14B系列模型社区许可协议
6. 企业介绍
猎户星空(OrionStar)是一家全球领先的服务机器人解决方案公司,成立于2016年9月。猎户星空致力于基于人工智能技术打造下一代革命性机器人,使人们能够摆脱重复的体力劳动,使人类的工作和生活更加智能和有趣,通过技术使社会和世界变得更加美好。
猎户星空拥有完全自主开发的全链条人工智能技术,如语音交互和视觉导航。它整合了产品开发能力和技术应用能力。基于Orion机械臂平台,它推出了ORION STAR AI Robot Greeting、AI Robot Greeting Mini、Lucki、Coffee Master等产品,并建立了Orion机器人的开放平台OrionOS。通过为 真正有用的机器人而生 的理念实践,它通过AI技术为更多人赋能。
凭借7年AI经验积累,猎户星空已推出的大模型深度应用“聚言”,并陆续面向行业客户提供定制化AI大模型咨询与服务解决方案,真正帮助客户实现企业经营效率领先同行目标。
猎户星空具备全链条大模型应用能力的核心优势,包括拥有从海量数据处理、大模型预训练、二次预训练、微调(Fine-tune)、Prompt Engineering 、Agent开发的全链条能力和经验积累;拥有完整的端到端模型训练能力,包括系统化的数据处理流程和数百张GPU的并行模型训练能力,现已在大政务、云服务、出海电商、快消等多个行业场景落地。
欢迎有大模型应用落地需求的企业联系我们进行商务合作
咨询电话: 400-898-7779
电子邮箱: ai@orionstar.com
Discord社区链接: https://discord.gg/zumjDWgdAs

Table of Contents
- 📖 Model Introduction
- 🔗 Model Download
- 🔖 Model Benchmark
- 📊 Model Inference
- 📜 Declarations & License
- 🥇 Company Introduction
1. Model Introduction
Orion-14B series models are open-source multilingual large language models trained from scratch by OrionStarAI. The base model is trained on 2.5T multilingual corpus, including Chinese, English, Japanese, Korean, etc, and it exhibits superior performance in these languages. For details, please refer to tech report.
The Orion-14B series models exhibit the following features:
- Among models with 20B-parameter scale level, Orion-14B-Base model shows outstanding performance in comprehensive evaluations.
- Strong multilingual capabilities, significantly outperforming in Japanese and Korean testsets.
- The fine-tuned models demonstrate strong adaptability, excelling in human-annotated blind tests.
- The long-chat version supports extremely long texts, performing exceptionally well at a token length of 200k and can support up to a maximum of 320k.
- The quantized versions reduce model size by 70%, improve inference speed by 30%, with performance loss less than 1%.
Orion-14B series models including:
- Orion-14B-Base: A multilingual large language foundational model with 14 billion parameters, pretrained on a diverse dataset of 2.5 trillion tokens.
- Orion-14B-Chat: A chat-model fine-tuned on a high-quality corpus aims to provide an excellence interactive experience for users in the large model community.
- Orion-14B-LongChat: The long-context version excels at handling extremely lengthy texts, performing exceptionally well at a token length of 200k and can support up to a maximum of 320k.
- Orion-14B-Chat-RAG: A chat-model fine-tuned on a custom retrieval augmented generation dataset, achieving superior performance in retrieval augmented generation tasks.
- Orion-14B-Chat-Plugin: A chat-model specifically tailored for plugin and function calling tasks, ideal for agent-related scenarios where the LLM acts as a plugin and function call system.
- Orion-14B-Base-Int4: A quantized base model utilizing 4-bit integer weights. It significantly reduces the model size by 70% and increases the inference speed by 30% while incurring a minimal performance loss of only 1%.
- Orion-14B-Chat-Int4: A quantized chat model utilizing 4-bit integer weights.
2. Model Download
Model release and download links are provided in the table below:
| Model Name | HuggingFace Download Links | ModelScope Download Links |
|---|---|---|
| ⚾Orion-14B-Base | Orion-14B-Base | Orion-14B-Base |
| 😛Orion-14B-Chat | Orion-14B-Chat | Orion-14B-Chat |
| 📃Orion-14B-LongChat | Orion-14B-LongChat | Orion-14B-LongChat |
| 🔎Orion-14B-Chat-RAG | Orion-14B-Chat-RAG | Orion-14B-Chat-RAG |
| 🔌Orion-14B-Chat-Plugin | Orion-14B-Chat-Plugin | Orion-14B-Chat-Plugin |
| 💼Orion-14B-Base-Int4 | Orion-14B-Base-Int4 | Orion-14B-Base-Int4 |
| 📦Orion-14B-Chat-Int4 | Orion-14B-Chat-Int4 | Orion-14B-Chat-Int4 |
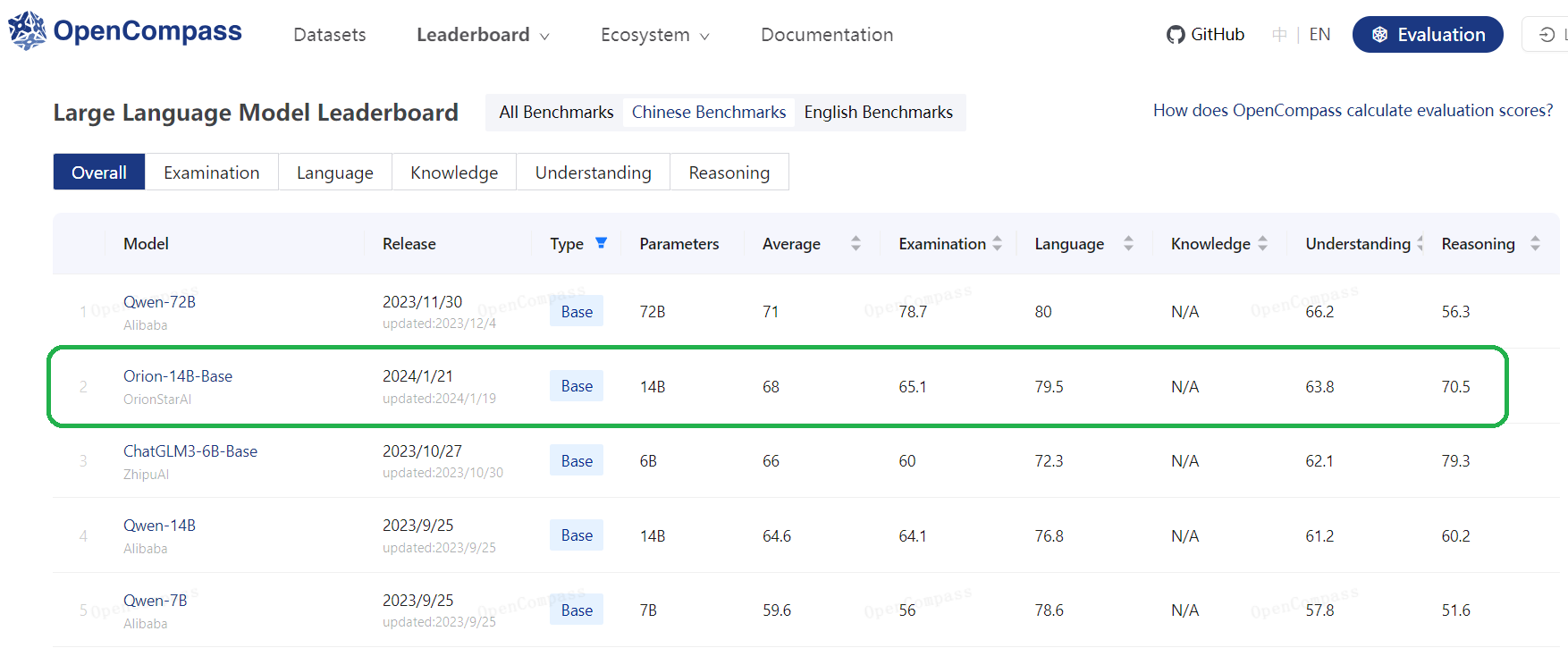
3. Model Benchmarks
3.1. Base Model Orion-14B-Base Benchmarks
3.1.1. LLM evaluation results on examination and professional knowledge
| Model | C-Eval | CMMLU | MMLU | AGIEval | Gaokao | BBH |
|---|---|---|---|---|---|---|
| LLaMA2-13B | 41.4 | 38.4 | 55.0 | 30.9 | 18.2 | 45.6 |
| Skywork-13B | 59.1 | 61.4 | 62.7 | 43.6 | 56.1 | 48.3 |
| Baichuan2-13B | 59.0 | 61.3 | 59.5 | 37.4 | 45.6 | 49.0 |
| QWEN-14B | 71.7 | 70.2 | 67.9 | 51.9 | 62.5 | 53.7 |
| InternLM-20B | 58.8 | 59.0 | 62.1 | 44.6 | 45.5 | 52.5 |
| Orion-14B-Base | 72.9 | 70.6 | 69.9 | 54.7 | 62.1 | 56.5 |
3.1.2. LLM evaluation results on language understanding and common knowledge
| Model | RACE-middle | RACE-high | HellaSwag | PIQA | Lambada | WSC |
|---|---|---|---|---|---|---|
| LLaMA 2-13B | 63.0 | 58.9 | 77.5 | 79.8 | 76.5 | 66.3 |
| Skywork-13B | 87.6 | 84.1 | 73.7 | 78.3 | 71.8 | 66.3 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
| QWEN-14B | 93.0 | 90.3 | 80.2 | 79.8 | 71.4 | 66.3 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | 80.3 | 71.8 | 68.3 |
| Orion-14B-Base | 93.2 | 91.3 | 78.5 | 79.5 | 78.8 | 70.2 |
3.1.3. LLM evaluation results of OpenCompass testsets
| Model | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|---|---|---|---|---|---|---|
| LLaMA 2-13B | 47.3 | 45.2 | 47.0 | 58.3 | 50.9 | 43.6 |
| Skywork-13B | 53.6 | 61.1 | 51.3 | 52.7 | 64.5 | 45.2 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | 60.1 | 67.3 | 54.9 |
| Orion-14B-Base | 64.3 | 71.4 | 55.0 | 60.0 | 71.9 | 61.6 |
3.1.4. Comparison of LLM performances on Japanese testsets
| Model | Average | JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|---|---|---|---|---|---|---|---|---|---|
| PLaMo-13B | 52.3 | 56.7 | 42.8 | 95.8 | 70.6 | 71.0 | 8.70 | 70.5 | 2.40 |
| WebLab-10B | 50.7 | 66.6 | 53.7 | 82.1 | 62.9 | 56.2 | 10.0 | 72.0 | 2.40 |
| ELYZA-jp-7B | 48.8 | 71.7 | 25.3 | 86.6 | 70.8 | 64.1 | 2.50 | 62.1 | 7.20 |
| StableLM-jp-7B | 51.1 | 33.4 | 43.3 | 96.7 | 70.6 | 78.1 | 10.7 | 72.8 | 2.80 |
| LLaMA 2-13B | 46.3 | 75.0 | 47.6 | 38.8 | 76.1 | 67.7 | 18.1 | 63.2 | 10.4 |
| Baichuan 2-13B | 57.1 | 73.7 | 31.3 | 91.6 | 80.5 | 63.3 | 18.6 | 72.2 | 25.2 |
| QWEN-14B | 65.8 | 85.9 | 60.7 | 97.0 | 83.3 | 71.8 | 18.8 | 70.6 | 38.0 |
| Yi-34B | 67.1 | 83.8 | 61.2 | 95.2 | 86.1 | 78.5 | 27.2 | 69.2 | 35.2 |
| Orion-14B-Base | 69.1 | 88.2 | 75.8 | 94.1 | 75.7 | 85.1 | 17.3 | 78.8 | 38.0 |
3.1.5. Comparison of LLM performances on Korean testsets. n = 0 and n = 5 stand for n-shot prompts used in the evaluation
| Model | Average n=0 n=5 |
HellaSwag n=0 n=5 |
COPA n=0 n=5 |
BooIQ n=0 n=5 |
SentiNeg n=0 n=5 |
|---|---|---|---|---|---|
| KoGPT | 53.0 70.1 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 | 37.5 89.4 |
| Polyglot-ko-13B | 69.6 73.7 | 59.5 63.1 | 79.4 81.1 | 48.2 60.4 | 91.2 90.2 |
| LLaMA 2-13B | 46.7 63.7 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 | 51.5 73.4 |
| Baichuan 2-13B | 52.1 58.7 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 | 50.3 72.9 |
| QWEN-14B | 53.8 73.7 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 | 71.5 95.7 |
| Yi-34B | 54.2 72.1 | 44.6 44.7 | 58.0 60.6 | 65.9 90.2 | 48.3 92.9 |
| Orion-14B-Chat | 74.5 79.6 | 47.0 49.6 | 77.7 79.4 | 81.6 90.7 | 92.4 98.7 |
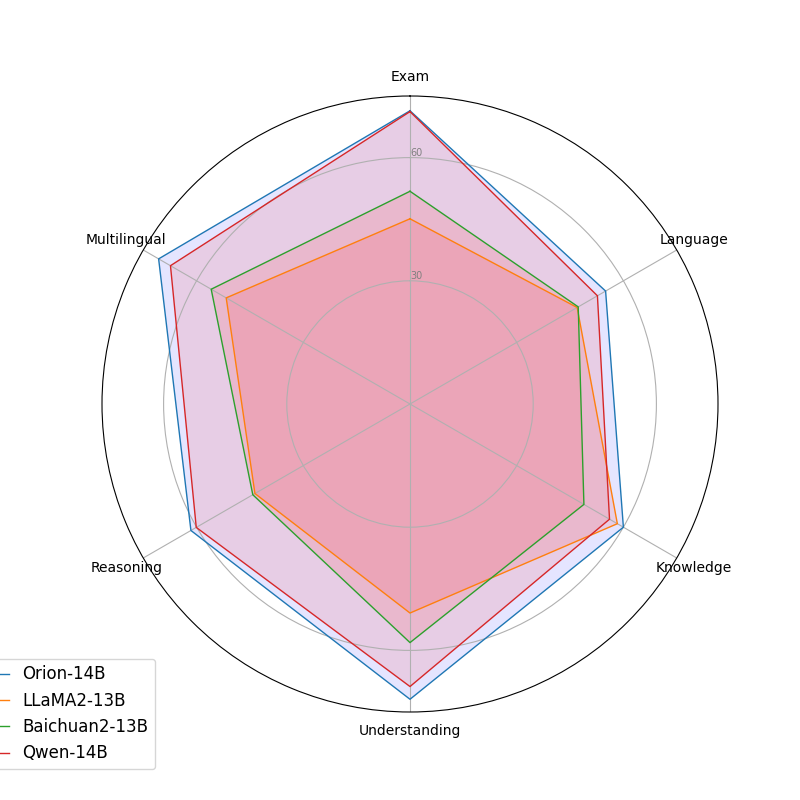
3.1.6. Multilingual evaluation
| Model | Train Lang | Japanese | Korean | Chinese | English |
|---|---|---|---|---|---|
| PLaMo-13B | En,Jp | 52.3 | * | * | * |
| Weblab-10B | En,Jp | 50.7 | * | * | * |
| ELYZA-jp-7B | En,Jp | 48.8 | * | * | * |
| StableLM-jp-7B | En,Jp | 51.1 | * | * | * |
| KoGPT-6B | En,Ko | * | 70.1 | * | * |
| Polyglot-ko-13B | En,Ko | * | 70.7 | * | * |
| Baichuan2-13B | Multi | 57.1 | 58.7 | 50.8 | 57.1 |
| Qwen-14B | Multi | 65.8 | 73.7 | 64.5 | 65.4 |
| Llama2-13B | Multi | 46.3 | 63.7 | 41.4 | 55.3 |
| Yi-34B | Multi | 67.1 | 72.2 | 58.7 | 68.8 |
| Orion-14B-Chat | Multi | 69.1 | 79.5 | 67.9 | 67.3 |
3.2. Chat Model Orion-14B-Chat Benchmarks
3.2.1. Chat model subjective evaluation of MTBench
| Model | First-Turn | Second-Turn | Average |
|---|---|---|---|
| Baichuan2-13B-Chat | 7.05 | 6.47 | 6.76 |
| Qwen-14B-Chat | 7.30 | 6.62 | 6.96 |
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
| Orion-14B-Chat | 7.68 | 7.07 | 7.37 |
| * use vllm for inference |
3.2.2. Chat model subjective evaluation of AlignBench
| Model | Math. | Logi. | Basic. | Chi. | Comp. | Writ. | Role. | Prof. | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 3.76 | 4.07 | 6.22 | 6.05 | 7.11 | 6.97 | 6.75 | 6.43 | 5.25 |
| Qwen-14B-Chat | 4.91 | 4.71 | 6.90 | 6.36 | 6.74 | 6.64 | 6.59 | 6.56 | 5.72 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | 7.18 | 6.19 | 6.49 | 6.22 | 4.96 |
| Orion-14B-Chat | 4.00 | 4.24 | 6.18 | 6.57 | 7.16 | 7.36 | 7.16 | 6.99 | 5.51 |
| * use vllm for inference |
3.3. LongChat Model Orion-14B-LongChat Benchmarks
3.3.1. LongChat evaluation of LongBench
| Model | NarrativeQA | MultiFieldQA-en | MultiFieldQA-zh | DuReader | QMSum | VCSUM | TREC | TriviaQA | LSHT | RepoBench-P |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-16k | 23.60 | 52.30 | 61.20 | 28.70 | 23.40 | 16.00 | 68.00 | 91.40 | 29.20 | 53.60 |
| LongChat-v1.5-7B-32k | 16.90 | 41.40 | 29.10 | 19.50 | 22.70 | 9.90 | 63.50 | 82.30 | 23.20 | 55.30 |
| Vicuna-v1.5-7B-16k | 19.40 | 38.50 | 43.00 | 19.30 | 22.80 | 15.10 | 71.50 | 86.20 | 28.80 | 43.50 |
| Yi-6B-200K | 14.11 | 36.74 | 22.68 | 14.01 | 20.44 | 8.08 | 72.00 | 86.61 | 38.00 | 63.29 |
| Orion-14B-LongChat | 19.47 | 48.11 | 55.84 | 37.02 | 24.87 | 15.44 | 77.00 | 89.12 | 45.50 | 54.31 |
3.4. Chat RAG Model Benchmarks
3.4.1. LLM evaluation results of self-built RAG testsets
| Model | Effectiveness of Response(Keyword) | *Effectiveness of Response(subjective evaluation) | Quoting Ability | Fallback Ability | *AutoQA | *Data Extraction |
|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 85 | 76 | 1 | 0 | 69 | 51 |
| Qwen-14B-Chat | 79 | 77 | 75 | 47 | 68 | 72 |
| Qwen-72B-Chat(Int4) | 87 | 89 | 90 | 32 | 67 | 76 |
| GPT-4 | 91 | 94 | 96 | 95 | 75 | 86 |
| Orion-14B-Chat-RAG | 86 | 87 | 91 | 97 | 73 | 71 |
| * means manual assessment |
3.5. Chat Plugin Model Orion-14B-Chat-Plugin Benchmarks
3.5.1. LLM evaluation results of self-built plugin testsets
| Model | Intent Recognition with Full Params | Intent Recognition with Missing Params | Non-Plugin Invocation Recognition |
|---|---|---|---|
| Baichuan2-13B-Chat | 25 | 0 | 0 |
| Qwen-14B-Chat | 55 | 0 | 50 |
| GPT-4 | 95 | 52.38 | 70 |
| Orion-14B-Chat-Plugin | 92.5 | 60.32 | 90 |
3.6. Quantized Model Orion-14B-Base-Int4 Benchmarks
3.6.1. Comparison of before and after quantization
| Model | Size(GB) | Inference Speed(tokens/s) | C-Eval | CMMLU | MMLU | RACE | HellaSwag |
|---|---|---|---|---|---|---|---|
| OrionStar-14B-Base | 28.0 | 135 | 72.8 | 70.6 | 70.0 | 93.3 | 78.5 |
| OrionStar-14B-Base-Int4 | 8.3 | 178 | 71.8 | 69.8 | 69.2 | 93.1 | 78.0 |
4. Model Inference
Model weights, source code, and configuration needed for inference are published on Hugging Face, and the download link is available in the table at the beginning of this document. We demonstrate various inference methods here, and the program will automatically download the necessary resources from Hugging Face.
4.1. Python Code
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto",
torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
messages = [{"role": "user", "content": "Hello, what is your name? "}]
response = model.chat(tokenizer, messages, streaming=False)
print(response)
In the above Python code, the model is loaded with device_map='auto' to utilize all available GPUs. To specify the
device, you can use something like export CUDA_VISIBLE_DEVICES=0,1 (using GPUs 0 and 1).
4.2. Command Line Tool
CUDA_VISIBLE_DEVICES=0 python cli_demo.py
This command-line tool is designed for chat scenarios, and thus, it does not support calling the base model.
4.3. Direct Script Inference
# base model
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt hello
# chat model
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt hi
4.4. 使用vllm推理
4.5. 使用llama.cpp推理
如何转换GGUF格式模型
python convert-hf-to-gguf.py path/to/Orion-14B-Chat --outfile chat.gguf如何运行GGUF格式模型推理
./main --frequency-penalty 0.5 --frequency-penalty 0.5 --top-k 5 --top-p 0.9 -m chat.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
4.6 Example Output
4.6.1. Casual Chat
User: Hello
Orion-14B: Hello! How can I help you today? If you have any questions or need assistance, feel free to ask.
User: What functions do you have?
Orion-14B: As an AI language model, I have a wide range of functions and capabilities, including but not limited to:
Answering general knowledge questions: I can provide information on various topics such as history, science, geography, and more.
Providing definitions and explanations: I can explain complex concepts and provide definitions for words and phrases.
Assisting with tasks: I can help with simple tasks like setting reminders, converting units of measurement, and even ordering food from restaurants.
Generating text: I can write short stories, essays, articles, and other types of content based on prompts given to me.
Translating languages: I can translate text from one language to another.
Chatting: I can engage in conversation with users and respond to their queries in a conversational manner.
Summarizing long texts: I can summarize longer texts like articles, books, and research papers.
Generating random numbers and names: I can generate random numbers within a specified range and also suggest names based on certain criteria.
Playing games: I can play simple games like Hangman, Trivia, and more.
Providing recommendations: I can recommend movies, music, books, and other forms of entertainment based on user preferences.
These are just some of the many functions that I am capable of performing. If you have a specific task in mind, feel free to ask me about it.
User: Tell me a joke.
Orion-14B: Sure, here's a classic one-liner: Why don't scientists trust atoms? Because they make up everything.
4.6.2. Japanese & Korean Chat
User:自己を紹介してください
Orion-14B:こんにちは、私の名前はChatMaxで、OrionStarによって開発されたAIアシスタントです。私はユーザーに正確で、客観的で、有用な回答を提供し、彼らが問題を解決し、情報を取得するのを助けることができます。
User:자기소개를 해주세요.
Orion-14B:안녕하세요, 제 이름은 ChatMax입니다. OrionStar에서 개발한 AI 어시스턴트입니다. 저는 사용자들에게 정확하고 객관적이며 유용한 답변을 제공하여 문제를 해결하고 정보를 얻는 데 도움을 줄 수 있습니다.
5. Declarations, License
5.1. Declarations
We strongly urge all users not to use the Orion-14B model for any activities that may harm national or social security or violate the law. Additionally, we request users not to use the Orion-14B model for internet services without proper security review and filing. We hope all users abide by this principle to ensure that technological development takes place in a regulated and legal environment. We have done our best to ensure the compliance of the data used in the model training process. However, despite our significant efforts, unforeseen issues may still arise due to the complexity of the model and data. Therefore, if any problems arise due to the use of the Orion-14B open-source model, including but not limited to data security issues, public opinion risks, or any risks and issues arising from the model being misled, abused, disseminated, or improperly utilized, we will not assume any responsibility.
5.2. License
Community use of the Orion-14B series models
- For code, please comply with Apache License Version 2.0
- For model, please comply with 【Orion-14B Series】 Models Community License Agreement
6. Company Introduction
OrionStar is a leading global service robot solutions company, founded in September 2016. OrionStar is dedicated to using artificial intelligence technology to create the next generation of revolutionary robots, allowing people to break free from repetitive physical labor and making human work and life more intelligent and enjoyable. Through technology, OrionStar aims to make society and the world a better place.
OrionStar possesses fully self-developed end-to-end artificial intelligence technologies, such as voice interaction and visual navigation. It integrates product development capabilities and technological application capabilities. Based on the Orion robotic arm platform, it has launched products such as OrionStar AI Robot Greeting, AI Robot Greeting Mini, Lucki, Coffee Master, and established the open platform OrionOS for Orion robots. Following the philosophy of "Born for Truly Useful Robots", OrionStar empowers more people through AI technology.
The core strengths of OrionStar lies in possessing end-to-end AI application capabilities, including big data preprocessing, large model pretraining, fine-tuning, prompt engineering, agent, etc. With comprehensive end-to-end model training capabilities, including systematic data processing workflows and the parallel model training capability of hundreds of GPUs, it has been successfully applied in various industry scenarios such as government affairs, cloud services, international e-commerce, and fast-moving consumer goods.
Companies with demands for deploying large-scale model applications are welcome to contact us.
Enquiry Hotline: 400-898-7779
E-mail: ai@orionstar.com
Discord Link: https://discord.gg/zumjDWgdAs
- Downloads last month
- 23