|
--- |
|
library_name: transformers |
|
license: apache-2.0 |
|
language: |
|
- en |
|
pipeline_tag: object-detection |
|
tags: |
|
- object-detection |
|
- vision |
|
datasets: |
|
- coco |
|
widget: |
|
- src: >- |
|
https://huggingface.co/datasets/mishig/sample_images/resolve/main/savanna.jpg |
|
example_title: Savanna |
|
- src: >- |
|
https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg |
|
example_title: Football Match |
|
- src: >- |
|
https://huggingface.co/datasets/mishig/sample_images/resolve/main/airport.jpg |
|
example_title: Airport |
|
--- |
|
|
|
|
|
# Model Card for Model ID |
|
|
|
<!-- Provide a quick summary of what the model is/does. --> |
|
|
|
|
|
|
|
## Model Details |
|
|
|
### Model Description |
|
|
|
The YOLO series has become the most popular framework for real-time object detection due to its reasonable trade-off between speed and accuracy. |
|
However, we observe that the speed and accuracy of YOLOs are negatively affected by the NMS. |
|
Recently, end-to-end Transformer-based detectors (DETRs) have provided an alternative to eliminating NMS. |
|
Nevertheless, the high computational cost limits their practicality and hinders them from fully exploiting the advantage of excluding NMS. |
|
In this paper, we propose the Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge that addresses the above dilemma. |
|
We build RT-DETR in two steps, drawing on the advanced DETR: |
|
first we focus on maintaining accuracy while improving speed, followed by maintaining speed while improving accuracy. |
|
Specifically, we design an efficient hybrid encoder to expeditiously process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed. |
|
Then, we propose the uncertainty-minimal query selection to provide high-quality initial queries to the decoder, thereby improving accuracy. |
|
In addition, RT-DETR supports flexible speed tuning by adjusting the number of decoder layers to adapt to various scenarios without retraining. |
|
Our RT-DETR-R50 / R101 achieves 53.1% / 54.3% AP on COCO and 108 / 74 FPS on T4 GPU, outperforming previously advanced YOLOs in both speed and accuracy. |
|
We also develop scaled RT-DETRs that outperform the lighter YOLO detectors (S and M models). |
|
Furthermore, RT-DETR-R50 outperforms DINO-R50 by 2.2% AP in accuracy and about 21 times in FPS. |
|
After pre-training with Objects365, RT-DETR-R50 / R101 achieves 55.3% / 56.2% AP. The project page: this [https URL](https://zhao-yian.github.io/RTDETR/). |
|
|
|
 |
|
|
|
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated. |
|
|
|
- **Developed by:** Yian Zhao and Sangbum Choi |
|
- **Funded by [optional]:** National Key R&D Program of China (No.2022ZD0118201), Natural Science Foundation of China (No.61972217, 32071459, 62176249, 62006133, 62271465), |
|
and the Shenzhen Medical Research Funds in China (No. |
|
B2302037). |
|
- **Shared by [optional]:** Sangbum Choi |
|
- **Model type:** |
|
- **Language(s) (NLP):** |
|
- **License:** Apache-2.0 |
|
- **Finetuned from model [optional]:** |
|
|
|
### Model Sources [optional] |
|
|
|
<!-- Provide the basic links for the model. --> |
|
|
|
- **Repository:** https://github.com/lyuwenyu/RT-DETR |
|
- **Paper [optional]:** https://arxiv.org/abs/2304.08069 |
|
- **Demo [optional]:** [More Information Needed] |
|
|
|
## Uses |
|
|
|
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. --> |
|
|
|
### Direct Use |
|
|
|
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. --> |
|
|
|
You can use the raw model for object detection. See the [model hub](https://huggingface.co/models?search=rtdetr) to look for all available RTDETR models. |
|
|
|
### Downstream Use [optional] |
|
|
|
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app --> |
|
|
|
### Out-of-Scope Use |
|
|
|
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. --> |
|
|
|
## Bias, Risks, and Limitations |
|
|
|
<!-- This section is meant to convey both technical and sociotechnical limitations. --> |
|
|
|
### Recommendations |
|
|
|
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. --> |
|
|
|
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations. |
|
|
|
## How to Get Started with the Model |
|
|
|
Use the code below to get started with the model. |
|
|
|
``` |
|
import torch |
|
import requests |
|
|
|
from PIL import Image |
|
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor |
|
|
|
url = 'http://images.cocodataset.org/val2017/000000039769.jpg' |
|
image = Image.open(requests.get(url, stream=True).raw) |
|
|
|
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r18vd_coco_o365") |
|
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r18vd_coco_o365") |
|
|
|
inputs = image_processor(images=image, return_tensors="pt") |
|
|
|
with torch.no_grad(): |
|
outputs = model(**inputs) |
|
|
|
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3) |
|
|
|
for result in results: |
|
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]): |
|
score, label = score.item(), label_id.item() |
|
box = [round(i, 2) for i in box.tolist()] |
|
print(f"{model.config.id2label[label]}: {score:.2f} {box}") |
|
``` |
|
|
|
## Training Details |
|
|
|
### Training Data |
|
|
|
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. --> |
|
|
|
The RTDETR model was trained on [COCO 2017 object detection](https://cocodataset.org/#download), a dataset consisting of 118k/5k annotated images for training/validation respectively. |
|
|
|
### Training Procedure |
|
|
|
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. --> |
|
|
|
We conduct experiments on |
|
COCO [20] and Objects365 [35], where RT-DETR is trained |
|
on COCO train2017 and validated on COCO val2017 |
|
dataset. We report the standard COCO metrics, including |
|
AP (averaged over uniformly sampled IoU thresholds ranging from 0.50-0.95 with a step size of 0.05), AP50, AP75, as |
|
well as AP at different scales: APS, APM, APL. |
|
|
|
#### Preprocessing [optional] |
|
|
|
Images are resized/rescaled such that the shortest side is at 640 pixels. |
|
|
|
#### Training Hyperparameters |
|
|
|
- **Training regime:** <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision --> |
|
|
|
 |
|
|
|
#### Speeds, Sizes, Times [optional] |
|
|
|
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. --> |
|
|
|
## Evaluation |
|
|
|
<!-- This section describes the evaluation protocols and provides the results. --> |
|
|
|
This model achieves an AP (average precision) of 53.1 on COCO 2017 validation. For more details regarding evaluation results, we refer to table 2 of the original paper. |
|
|
|
### Testing Data, Factors & Metrics |
|
|
|
#### Testing Data |
|
|
|
<!-- This should link to a Dataset Card if possible. --> |
|
|
|
#### Factors |
|
|
|
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. --> |
|
|
|
#### Metrics |
|
|
|
<!-- These are the evaluation metrics being used, ideally with a description of why. --> |
|
|
|
### Results |
|
|
|
#### Summary |
|
|
|
|
|
|
|
## Model Examination [optional] |
|
|
|
<!-- Relevant interpretability work for the model goes here --> |
|
|
|
## Environmental Impact |
|
|
|
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly --> |
|
|
|
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). |
|
|
|
|
|
## Technical Specifications [optional] |
|
|
|
### Model Architecture and Objective |
|
|
|
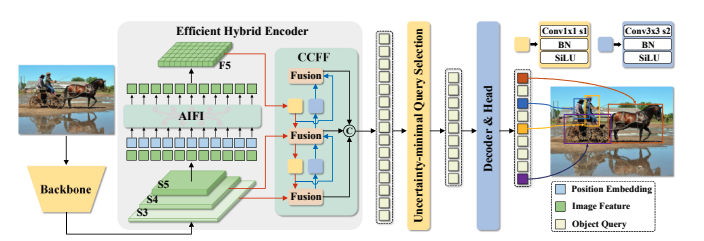 |
|
|
|
### Compute Infrastructure |
|
|
|
#### Hardware |
|
|
|
#### Software |
|
|
|
## Citation [optional] |
|
|
|
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. --> |
|
|
|
**BibTeX:** |
|
|
|
```bibtex |
|
@misc{lv2023detrs, |
|
title={DETRs Beat YOLOs on Real-time Object Detection}, |
|
author={Yian Zhao and Wenyu Lv and Shangliang Xu and Jinman Wei and Guanzhong Wang and Qingqing Dang and Yi Liu and Jie Chen}, |
|
year={2023}, |
|
eprint={2304.08069}, |
|
archivePrefix={arXiv}, |
|
primaryClass={cs.CV} |
|
} |
|
``` |
|
|
|
**APA:** |
|
|
|
## Glossary [optional] |
|
|
|
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. --> |
|
|
|
## More Information [optional] |
|
|
|
## Model Card Authors [optional] |
|
|
|
[Sangbum Choi](https://huggingface.co/danelcsb) |
|
|
|
## Model Card Contact |

