

metadata
license: apache-2.0
library_name: transformers
basemodel: google/gemma-7b
model-index:
- name: firefly-gemma-7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 62.12
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=YeungNLP/firefly-gemma-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 79.77
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=YeungNLP/firefly-gemma-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 61.57
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=YeungNLP/firefly-gemma-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 49.41
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=YeungNLP/firefly-gemma-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 75.45
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=YeungNLP/firefly-gemma-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 49.28
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=YeungNLP/firefly-gemma-7b
name: Open LLM Leaderboard
Model Card for Firefly-Gemma
firefly-gemma-7b is trained based on gemma-7b to act as a helpful and harmless AI assistant. We use Firefly to train the model on a single V100 GPU with QLoRA.
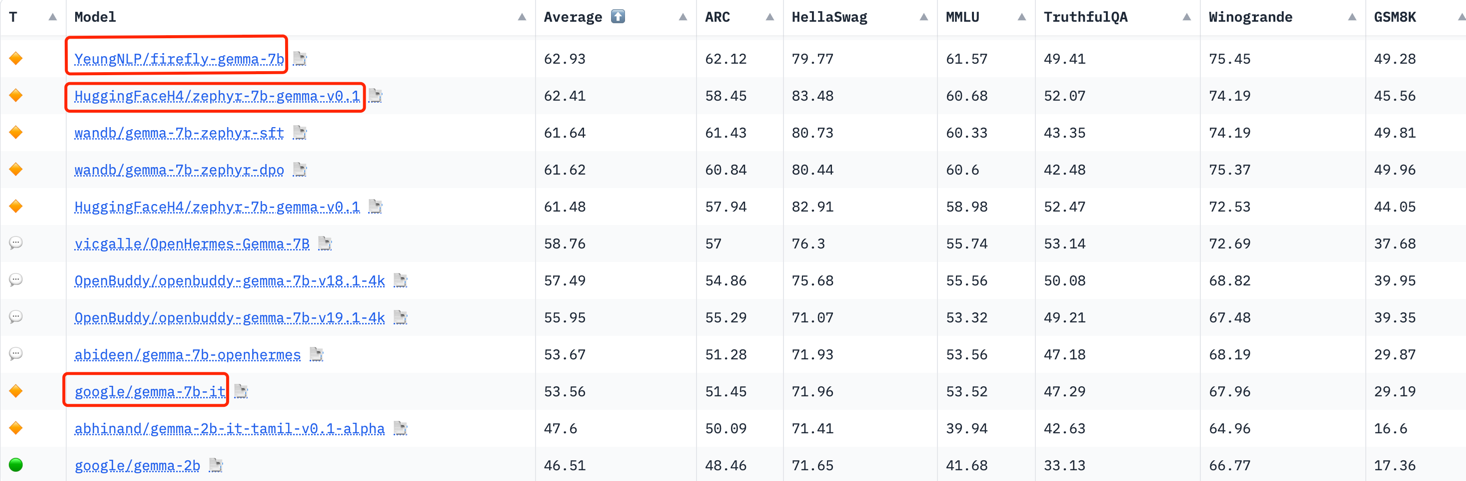
Our model outperforms the official gemma-7b-it, zephyr-7b-gemma-v0.1, Qwen1.5-7B-Chat and Zephyr-7B-Beta on Open LLM Leaderboard.
We advise you to install transformers>=4.38.1.
Performance
We evaluate our models on Open LLM Leaderboard, they achieve good performance.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|
| firefly-gemma-7b | 62.93 | 62.12 | 79.77 | 61.57 | 49.41 | 75.45 | 49.28 |
| zephyr-7b-gemma-v0.1 | 62.41 | 58.45 | 83.48 | 60.68 | 52.07 | 74.19 | 45.56 |
| firefly-qwen1.5-en-7b-dpo-v0.1 | 62.36 | 54.35 | 76.04 | 61.21 | 56.4 | 72.06 | 54.13 |
| zephyr-7b-beta | 61.95 | 62.03 | 84.36 | 61.07 | 57.45 | 77.74 | 29.04 |
| firefly-qwen1.5-en-7b | 61.44 | 53.41 | 75.51 | 61.67 | 51.96 | 70.72 | 55.34 |
| vicuna-13b-v1.5 | 55.41 | 57.08 | 81.24 | 56.67 | 51.51 | 74.66 | 11.3 |
| Xwin-LM-13B-V0.1 | 55.29 | 62.54 | 82.8 | 56.53 | 45.96 | 74.27 | 9.63 |
| Qwen1.5-7B-Chat | 55.15 | 55.89 | 78.56 | 61.65 | 53.54 | 67.72 | 13.57 |
| gemma-7b-it | 53.56 | 51.45 | 71.96 | 53.52 | 47.29 | 67.96 | 29.19 |
Usage
The chat template of our chat models is similar as Official gemma-7b-it:
<bos><start_of_turn>user
hello, who are you?<end_of_turn>
<start_of_turn>model
I am a AI program developed by Firefly<eos>
You can use script to inference in Firefly.
You can also use the following code:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name_or_path = "YeungNLP/firefly-gemma-7b"
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
prompt = "Compose an engaging travel blog post about a recent trip to Hawaii, highlighting cultural experiences and must-see attractions. "
text = f"""
<bos><start_of_turn>user
{prompt}<end_of_turn>
<start_of_turn>model
""".strip()
model_inputs = tokenizer([text], return_tensors="pt").to('cuda')
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1500,
top_p = 0.9,
temperature = 0.35,
repetition_penalty = 1.0,
eos_token_id=tokenizer.encode('<eos>', add_special_tokens=False)
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 62.93 |
| AI2 Reasoning Challenge (25-Shot) | 62.12 |
| HellaSwag (10-Shot) | 79.77 |
| MMLU (5-Shot) | 61.57 |
| TruthfulQA (0-shot) | 49.41 |
| Winogrande (5-shot) | 75.45 |
| GSM8k (5-shot) | 49.28 |