
Special Thanks:
- Lewdiculous's superb gguf version, thank you for your conscientious and responsible dedication.
- https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF-IQ-Imatrix-Request
fast quantizations
- The difference with normal quantizations is that I quantize the output and embed tensors to f16.and the other tensors to 15_k,q6_k or q8_0.This creates models that are little or not degraded at all and have a smaller size.They run at about 3-6 t/sec on CPU only using llama.cpp And obviously faster on computers with potent GPUs
- https://huggingface.co/ZeroWw/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF
- More models here: https://huggingface.co/RobertSinclair
Model Description:
The module combination has been readjusted to better fulfill various roles and has been adapted for mobile phones.
- Saving money(LLama 3)
- Uncensored
- Quick response
- The underlying model used is winglian/Llama-3-8b-64k-PoSE (The theoretical support is 64k, but I have only tested up to 32k. :)
- A scholarly response akin to a thesis.(I tend to write songs extensively, to the point where one song almost becomes as detailed as a thesis. :)
- DarkIdol:Roles that you can imagine and those that you cannot imagine.
- Roleplay
- Specialized in various role-playing scenarios
- more look at test role. (https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.2/tree/main/test)
- more look at LM Studio presets (https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.2/tree/main/config-presets)

Chang Log
2024-06-26
- 32k
2024-06-26
- 之前版本的迭代太多了,已经开始出现过拟合现象.重新使用了新的工艺重新制作模型,虽然制作复杂了,结果很好,新的迭代工艺如图
- The previous version had undergone excessive iterations, resulting in overfitting. We have recreated the model using a new process, which, although more complex to produce, has yielded excellent results. The new iterative process is depicted in the figure.
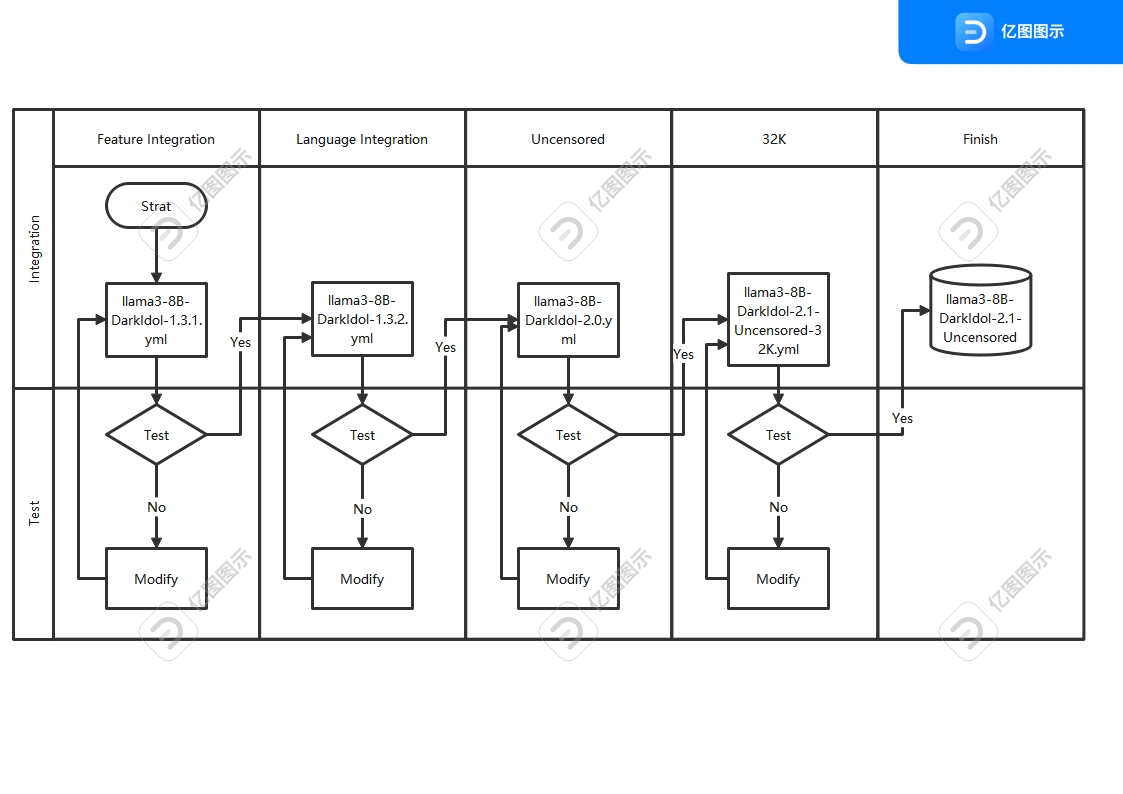
Questions
- The model's response results are for reference only, please do not fully trust them.
- I am unable to test Japanese and Korean parts very well. Based on my testing, Korean performs excellently, but sometimes Japanese may have furigana (if anyone knows a good Japanese language module, - I need to replace the module for integration).
- With the new manufacturing process, overfitting and crashes have been reduced, but there may be new issues, so please leave a message if you encounter any.
- testing with other tools is not comprehensive.but there may be new issues, so please leave a message if you encounter any.
- The range between 32K and 64K was not tested, and the approach was somewhat casual. I didn't expect the results to be exceptionally good.
问题
- 模型回复结果仅供参考,请勿完全相信
- 日语,韩语部分我没办法进行很好的测试,根据我测试情况,韩语表现的很好,日语有时候会出现注音(谁知道好的日文语言模块,我需要换模块集成)
- 新工艺制作,过拟合现象和崩溃减少了,可能会有新的问题,碰到了请给我留言
- 32K-64k区间没有测试,做的有点随意,没想到结果特别的好
- 其他工具的测试不完善
Stop Strings
stop = [
"## Instruction:",
"### Instruction:",
"<|end_of_text|>",
" //:",
"</s>",
"<3```",
"### Note:",
"### Input:",
"### Response:",
"### Emoticons:"
],
Model Use
- Koboldcpp https://github.com/LostRuins/koboldcpp
- Since KoboldCpp is taking a while to update with the latest llama.cpp commits, I'll recommend this fork if anyone has issues.
- LM Studio https://lmstudio.ai/
- llama.cpp https://github.com/ggerganov/llama.cpp
- Backyard AI https://backyard.ai/
- Meet Layla,Layla is an AI chatbot that runs offline on your device.No internet connection required.No censorship.Complete privacy.Layla Lite https://www.layla-network.ai/
- Layla Lite llama3-8B-DarkIdol-1.1-Q4_K_S-imat.gguf https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K/blob/main/llama3-8B-DarkIdol-2.1-Uncensored-32K-Q4_K_S-imat.gguf?download=true
- more gguf at https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF-IQ-Imatrix-Request
character
- https://character-tavern.com/
- https://characterhub.org/
- https://pygmalion.chat/
- https://aetherroom.club/
- https://backyard.ai/
- Layla AI chatbot
If you want to use vision functionality:
- You must use the latest versions of Koboldcpp.
To use the multimodal capabilities of this model and use vision you need to load the specified mmproj file, this can be found inside this model repo. Llava MMProj
- You can load the mmproj by using the corresponding section in the interface:

Thank you:
To the authors for their hard work, which has given me more options to easily create what I want. Thank you for your efforts. - Hastagaras - Gryphe - cgato - ChaoticNeutrals - mergekit - merge - transformers - llama - Nitral-AI - MLP-KTLim - rinna - hfl - Rupesh2 - stephenlzc - theprint - Sao10K - turboderp - TheBossLevel123 - winglian - .........
base_model:
- Nitral-AI/Hathor_Fractionate-L3-8B-v.05
- Hastagaras/Jamet-8B-L3-MK.V-Blackroot
- turboderp/llama3-turbcat-instruct-8b
- aifeifei798/Meta-Llama-3-8B-Instruct
- Sao10K/L3-8B-Stheno-v3.3-32K
- TheBossLevel123/Llama3-Toxic-8B-Float16
- cgato/L3-TheSpice-8b-v0.8.3 library_name: transformers tags:
- mergekit
- merge
llama3-8B-DarkIdol-1.3.1
This is a merge of pre-trained language models created using mergekit.
Merge Details
Merge Method
This model was merged using the Model Stock merge method using aifeifei798/Meta-Llama-3-8B-Instruct as a base.
Models Merged
The following models were included in the merge:
- Nitral-AI/Hathor_Fractionate-L3-8B-v.05
- Hastagaras/Jamet-8B-L3-MK.V-Blackroot
- turboderp/llama3-turbcat-instruct-8b
- Sao10K/L3-8B-Stheno-v3.3-32K
- TheBossLevel123/Llama3-Toxic-8B-Float16
- cgato/L3-TheSpice-8b-v0.8.3
Configuration
The following YAML configuration was used to produce this model:
models:
- model: Sao10K/L3-8B-Stheno-v3.3-32K
- model: Hastagaras/Jamet-8B-L3-MK.V-Blackroot
- model: cgato/L3-TheSpice-8b-v0.8.3
- model: Nitral-AI/Hathor_Fractionate-L3-8B-v.05
- model: TheBossLevel123/Llama3-Toxic-8B-Float16
- model: turboderp/llama3-turbcat-instruct-8b
- model: aifeifei798/Meta-Llama-3-8B-Instruct
merge_method: model_stock
base_model: aifeifei798/Meta-Llama-3-8B-Instruct
dtype: bfloat16
base_model:
- hfl/llama-3-chinese-8b-instruct-v3
- rinna/llama-3-youko-8b
- MLP-KTLim/llama-3-Korean-Bllossom-8B library_name: transformers tags:
- mergekit
- merge
llama3-8B-DarkIdol-1.3.2
This is a merge of pre-trained language models created using mergekit.
Merge Details
Merge Method
This model was merged using the Model Stock merge method using ./llama3-8B-DarkIdol-1.3.1 as a base.
Models Merged
The following models were included in the merge:
Configuration
The following YAML configuration was used to produce this model:
models:
- model: hfl/llama-3-chinese-8b-instruct-v3
- model: rinna/llama-3-youko-8b
- model: MLP-KTLim/llama-3-Korean-Bllossom-8B
- model: ./llama3-8B-DarkIdol-1.3.1
merge_method: model_stock
base_model: ./llama3-8B-DarkIdol-1.3.1
dtype: bfloat16
base_model:
- theprint/Llama-3-8B-Lexi-Smaug-Uncensored
- Rupesh2/OrpoLlama-3-8B-instruct-uncensored
- stephenlzc/dolphin-llama3-zh-cn-uncensored library_name: transformers tags:
- mergekit
- merge
llama3-8B-DarkIdol-2.0-Uncensored
This is a merge of pre-trained language models created using mergekit.
Merge Details
Merge Method
This model was merged using the Model Stock merge method using ./llama3-8B-DarkIdol-1.3.2 as a base.
Models Merged
The following models were included in the merge:
- theprint/Llama-3-8B-Lexi-Smaug-Uncensored
- Rupesh2/OrpoLlama-3-8B-instruct-uncensored
- stephenlzc/dolphin-llama3-zh-cn-uncensored
Configuration
The following YAML configuration was used to produce this model:
models:
- model: Rupesh2/OrpoLlama-3-8B-instruct-uncensored
- model: stephenlzc/dolphin-llama3-zh-cn-uncensored
- model: theprint/Llama-3-8B-Lexi-Smaug-Uncensored
- model: ./llama3-8B-DarkIdol-1.3.2
merge_method: model_stock
base_model: ./llama3-8B-DarkIdol-2.0-Uncensored
dtype: bfloat16
base_model:
- winglian/Llama-3-8b-64k-PoSE library_name: transformers tags:
- mergekit
- merge
llama3-8B-DarkIdol-2.1-Uncensored-32K
This is a merge of pre-trained language models created using mergekit.
Merge Details
Merge Method
This model was merged using the Model Stock merge method using winglian/Llama-3-8b-64k-PoSE as a base.
Models Merged
The following models were included in the merge:
- ./llama3-8B-DarkIdol-1.3.2
- ./llama3-8B-DarkIdol-2.0
- ./llama3-8B-DarkIdol-1.3.1
Configuration
The following YAML configuration was used to produce this model:
models:
- model: ./llama3-8B-DarkIdol-1.3.1
- model: ./llama3-8B-DarkIdol-1.3.2
- model: ./llama3-8B-DarkIdol-2.0
- model: winglian/Llama-3-8b-64k-PoSE
merge_method: model_stock
base_model: winglian/Llama-3-8b-64k-PoSE
dtype: bfloat16
- Downloads last month
- 308