
LiT5
Collection
Linguistically-Informed T5 models from the LREC-COLING paper "Linguistic Knowledge Can Enhance Encoder-Decoder Models (If You Let It)".
•
7 items
•
Updated
•
2
This model is released as part of the paper "Linguistic Knowledge Can Enhance Encoder-Decoder Models (If You Let It)" (Miaschi et al., 2024). If you use this model in your work, we kindly ask you to cite our paper:
@inproceedings{miaschi-etal-2024-linguistic-knowledge,
title = "Linguistic Knowledge Can Enhance Encoder-Decoder Models (If You Let It)",
author = "Miaschi, Alessio and
Dell{'}Orletta, Felice and
Venturi, Giulia",
editor = "Calzolari, Nicoletta and
Kan, Min-Yen and
Hoste, Veronique and
Lenci, Alessandro and
Sakti, Sakriani and
Xue, Nianwen",
booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
month = may,
year = "2024",
address = "Torino, Italy",
publisher = "ELRA and ICCL",
url = "https://aclanthology.org/2024.lrec-main.922",
pages = "10539--10554",
abstract = "In this paper, we explore the impact of augmenting pre-trained Encoder-Decoder models, specifically T5, with linguistic knowledge for the prediction of a target task. In particular, we investigate whether fine-tuning a T5 model on an intermediate task that predicts structural linguistic properties of sentences modifies its performance in the target task of predicting sentence-level complexity. Our study encompasses diverse experiments conducted on Italian and English datasets, employing both monolingual and multilingual T5 models at various sizes. Results obtained for both languages and in cross-lingual configurations show that linguistically motivated intermediate fine-tuning has generally a positive impact on target task performance, especially when applied to smaller models and in scenarios with limited data availability.",
}
Abstract: In this paper, we explore the impact of augmenting pre-trained Encoder-Decoder models, specifically T5, with linguistic knowledge for the prediction of a target task. In particular, we investigate whether fine-tuning a T5 model on an intermediate task that predicts structural linguistic properties of sentences modifies its performance in the target task of predicting sentence-level complexity. Our study encompasses diverse experiments conducted on Italian and English datasets, employing both monolingual and multilingual T5 models at various sizes. Results obtained for both languages and in cross-lingual configurations show that linguistically motivated intermediate fine-tuning has generally a positive impact on target task performance, especially when applied to smaller models and in scenarios with limited data availability.
Other information can be found in the original GitHub repository.
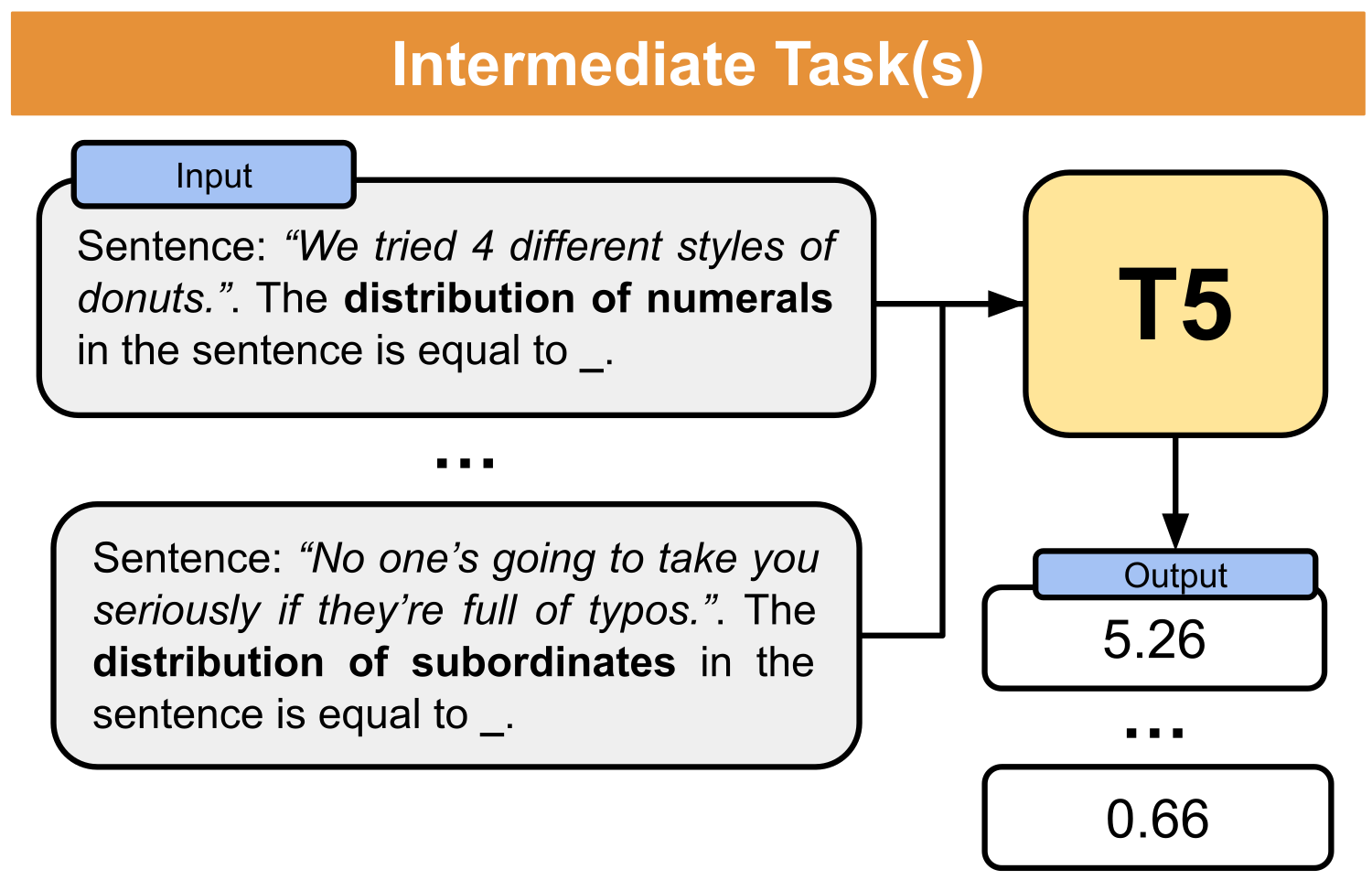
The model is based on a T5 model fine-tuned in a multitask fashion to solve a set of raw, morpho-syntactic and syntactic tasks (i.e. predictions of linguistic properties). The full list of the 10 linguistic properties used as intermediate tasks can be found in the original paper.
This model is based on the English version of t5-small, t5-small.
The other fine-tuned models presented in the original study are the following: