|
--- |
|
pipeline_tag: text-generation |
|
base_model: bigcode/starcoder2-15b |
|
datasets: |
|
- bigcode/self-oss-instruct-sc2-exec-filter-50k |
|
license: bigcode-openrail-m |
|
library_name: transformers |
|
tags: |
|
- code |
|
model-index: |
|
- name: starcoder2-15b-instruct-v0.1 |
|
results: |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: LiveCodeBench (code generation) |
|
type: livecodebench-codegeneration |
|
metrics: |
|
- type: pass@1 |
|
value: 20.4 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: LiveCodeBench (self repair) |
|
type: livecodebench-selfrepair |
|
metrics: |
|
- type: pass@1 |
|
value: 20.9 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: LiveCodeBench (test output prediction) |
|
type: livecodebench-testoutputprediction |
|
metrics: |
|
- type: pass@1 |
|
value: 29.8 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: LiveCodeBench (code execution) |
|
type: livecodebench-codeexecution |
|
metrics: |
|
- type: pass@1 |
|
value: 28.1 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: HumanEval |
|
type: humaneval |
|
metrics: |
|
- type: pass@1 |
|
value: 72.6 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: HumanEval+ |
|
type: humanevalplus |
|
metrics: |
|
- type: pass@1 |
|
value: 63.4 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: MBPP |
|
type: mbpp |
|
metrics: |
|
- type: pass@1 |
|
value: 75.2 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: MBPP+ |
|
type: mbppplus |
|
metrics: |
|
- type: pass@1 |
|
value: 61.2 |
|
- task: |
|
type: text-generation |
|
dataset: |
|
name: DS-1000 |
|
type: ds-1000 |
|
metrics: |
|
- type: pass@1 |
|
value: 40.6 |
|
--- |
|
|
|
# StarCoder2-Instruct: Self-Aligned, Transparent, and Fully Permissive |
|
|
|
 |
|
|
|
## Model Summary |
|
|
|
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs. |
|
|
|
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1) |
|
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align) |
|
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/) |
|
|
|
 |
|
|
|
## Use |
|
|
|
### Intended use |
|
|
|
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses. |
|
|
|
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library: |
|
|
|
```python |
|
import transformers |
|
import torch |
|
|
|
pipeline = transformers.pipeline( |
|
model="bigcode/starcoder2-15b-instruct-v0.1", |
|
task="text-generation", |
|
torch_dtype=torch.bfloat16, |
|
device_map="auto", |
|
) |
|
|
|
def respond(instruction: str, response_prefix: str) -> str: |
|
messages = [{"role": "user", "content": instruction}] |
|
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False) |
|
prompt += response_prefix |
|
|
|
teminators = [ |
|
pipeline.tokenizer.eos_token_id, |
|
pipeline.tokenizer.convert_tokens_to_ids("###"), |
|
] |
|
|
|
result = pipeline( |
|
prompt, |
|
max_length=256, |
|
num_return_sequences=1, |
|
do_sample=False, |
|
eos_token_id=teminators, |
|
pad_token_id=pipeline.tokenizer.eos_token_id, |
|
truncation=True, |
|
) |
|
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip() |
|
return response |
|
|
|
|
|
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria." |
|
response_prefix = "" |
|
|
|
print(respond(instruction, response_prefix)) |
|
``` |
|
|
|
Here is the expected output: |
|
|
|
`````` |
|
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria: |
|
|
|
```python |
|
from typing import TypeVar, Callable |
|
|
|
T = TypeVar('T') |
|
|
|
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]: |
|
if len(items) <= 1: |
|
return items |
|
|
|
pivot = items[0] |
|
less = [x for x in items[1:] if less_than(x, pivot)] |
|
greater = [x for x in items[1:] if not less_than(x, pivot)] |
|
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than) |
|
``` |
|
`````` |
|
|
|
### Bias, Risks, and Limitations |
|
|
|
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks. |
|
|
|
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b). |
|
|
|
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000 |
|
|
|
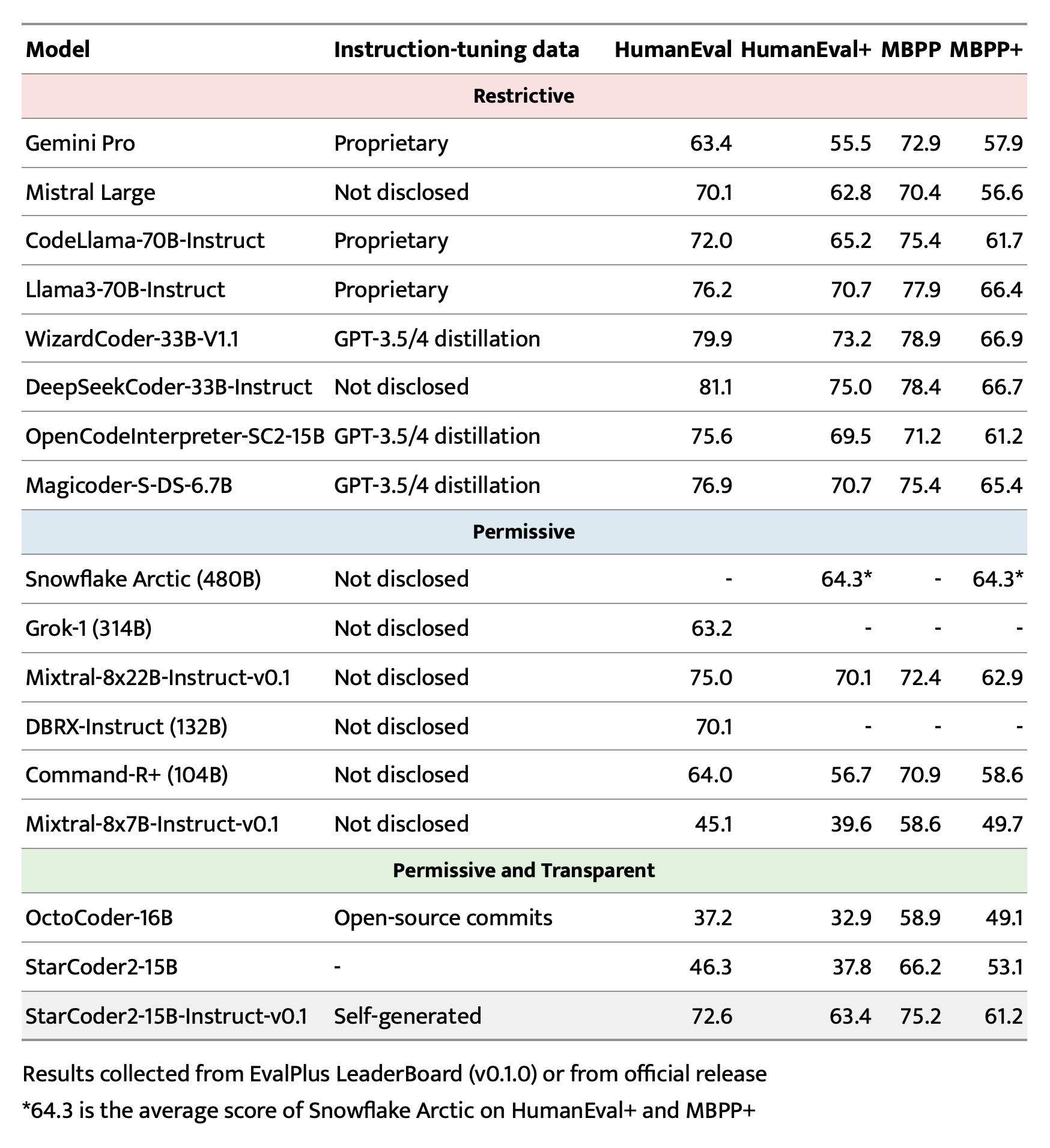 |
|
|
|
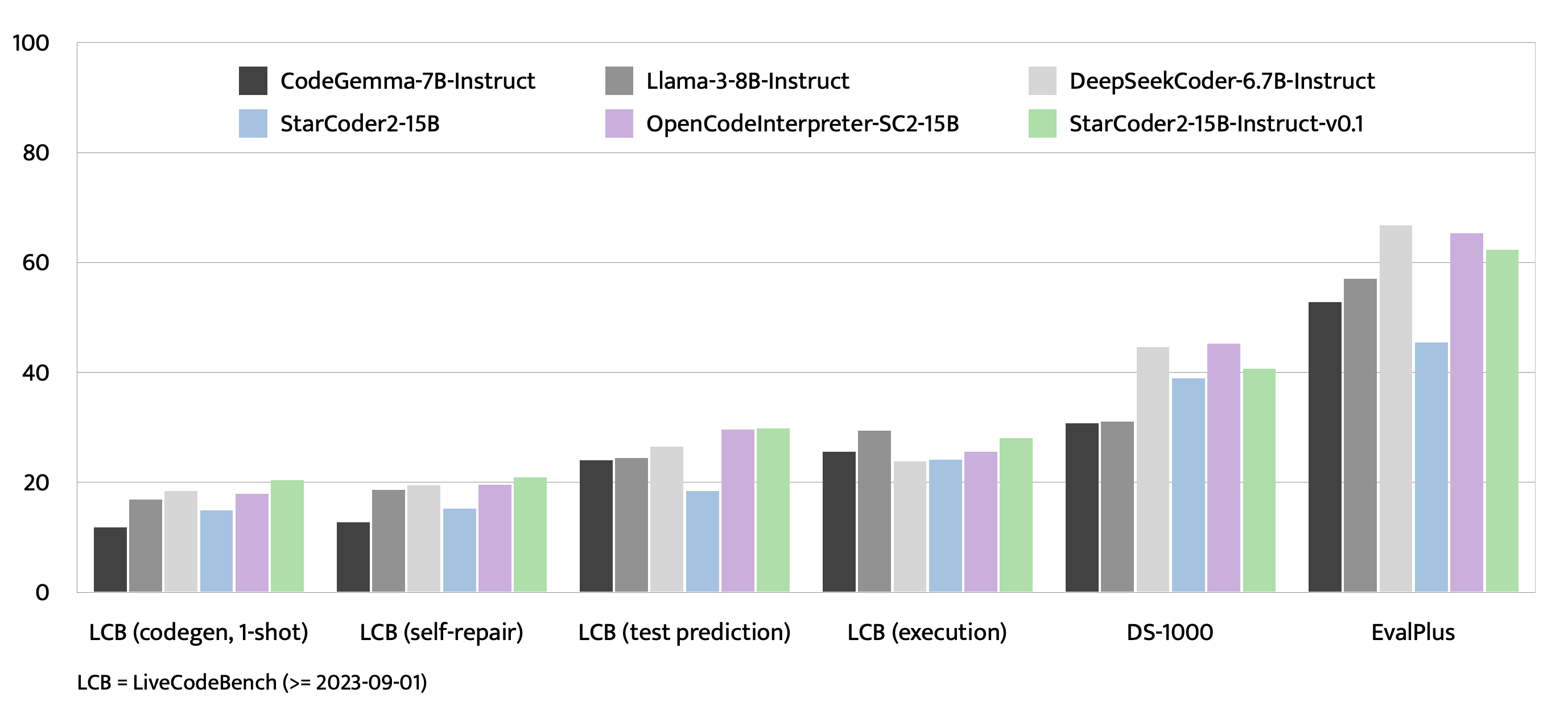 |
|
|
|
## Training Details |
|
|
|
### Hyperparameters |
|
|
|
- **Optimizer:** Adafactor |
|
- **Learning rate:** 1e-5 |
|
- **Epoch:** 4 |
|
- **Batch size:** 64 |
|
- **Warmup ratio:** 0.05 |
|
- **Scheduler:** Linear |
|
- **Sequence length:** 1280 |
|
- **Dropout**: Not applied |
|
|
|
### Hardware |
|
|
|
1 x NVIDIA A100 80GB |
|
|
|
## Resources |
|
|
|
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1) |
|
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align) |
|
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/) |
|
|

