Datasets:

File size: 7,019 Bytes
025dc57 009aeca 025dc57 07d8f68 68127a3 3088e7f f91d3f7 3088e7f b67b929 f2f55c2 0ebe088 b415248 38a9684 b415248 0ebe088 c77a172 0ebe088 1446a95 0ebe088 f75b822 0ebe088 f75b822 bb637f8 97366a4 f75b822 bb637f8 97366a4 bb637f8 97366a4 f75b822 0ebe088 93115a5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
---
license: openrail
task_categories:
- conversational
language:
- aa
tags:
- music
size_categories:
- n<1K
pretty_name: genshin_voice_sovits
---
# 效果预览
本仓库用于预览训练出的各种语音模型的效果,点击角色名自动跳转对应训练参数。</br>
推荐用谷歌浏览器,其他浏览器可能无法正确加载预览的音频。</br>
正常说话的音色转换较为准确,歌曲包含较广的音域且bgm和声等难以去除干净,效果有所折扣。</br>
有推荐的歌想要转换听听效果,或者其他内容建议,[点我](https://huggingface.co/datasets/jiaheillu/audio_preview/discussions/new)发起讨论</br>
下面是预览音频,左右滑动可以看到全部
<style>
.scrolling-container {
width: 100%;
max-width: 800px;
height: 300px;
overflow: auto;
margin: 0;
}
@media screen and (max-width: 768px) {
.scrolling-container {
width: 100%;
height: auto;
overflow: auto;
}
}
</style>
<div class="scrolling-container">
<table border="1" style="white-space: nowrap; text-align: center;">
<thead>
<tr>
<th>角色名</th>
<th>角色原声A</th>
<th>被转换人声B</th>
<th>A音色替换B</th>
<th>A音色翻唱(点击直接下载)</th>
</tr>
</thead>
<tbody>
<tr>
<td><a href="https://huggingface.co/datasets/jiaheillu/audio_preview/blob/main/散兵效果预览/训练参数速览.md">散兵</a></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/散兵效果预览/部分训练集/真遗憾,小吉祥草王让他消除了那么多的切片,剥夺了我将他一片一片千刀万剐的快乐%E3%80%82.mp3" controls="controls"></audio></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/散兵效果预览/原声/shenli3.wav" controls="controls"></audio></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/散兵效果预览/转换结果/shenli3mp3_auto_liulangzhe.wav" controls="controls"></audio></td>
<td><a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/散兵效果预览/转换结果/夢で逢えたら2liulangzhe_f.wav">夢で会えたら</a></td>
</tr>
<tr>
<td><a href="https://huggingface.co/datasets/jiaheillu/audio_preview/blob/main/胡桃_preview/README.md">胡桃</a></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/%E8%83%A1%E6%A1%83_preview/hutao.wav" controls="controls"></audio></td>
<td>.........</td>
<td>.........</td>
<td>
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/胡桃_preview/moonlight_shadow2胡桃.WAV">moonlight shadow</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/胡桃_preview/云烟成雨2胡桃.WAV">云烟成雨</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/胡桃_preview/原点2胡桃.WAV">原点</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/胡桃_preview/夢だ会えたら2胡桃.WAV">夢で逢えたら</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/胡桃_preview/贝加尔湖畔2胡桃.WAV">贝加尔湖畔</a>
</td>
</tr>
<tr>
<td><a href="https://huggingface.co/datasets/jiaheillu/audio_preview/blob/main/绫华_preview/README.md">神里绫华</a></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/绫华_preview/linghua428.wav" controls="controls"></audio></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/绫华_preview/yelan.wav" controls="controls"></audio></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/绫华_preview/yelan.wav_auto_linghua_0.5.flac" controls="controls"></audio></td>
<td>
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/绫华_preview/アムリタ2绫华.WAV">アムリタ</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/绫华_preview/大鱼2绫华.WAV">大鱼</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/绫华_preview/遊園施設2绫华.WAV">遊園施設</a>,
<a href="https://huggingface.co/datasets/jiaheillu/audio_preview/resolve/main/绫华_preview/the_day_you_want_away2绫华.WAV">the day you want away</a>
</td>
</tr>
<tr>
<td><a href="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/blob/main/宵宫_preview/README.md">宵宫</a></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/宵宫_preview/xiaogong.wav" controls="controls"></audio></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/宵宫_preview/hutao2.wav" controls="controls"></audio></td>
<td><audio src="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/宵宫_preview/hutao2wav_0key_xiaogong_0.5-2.flac" controls="controls"></audio></td>
<td>
<a href="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/宵宫_preview/昨夜书2宵宫.WAV">昨夜书</a>,
<a href="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/宵宫_preview/lemon2宵宫.WAV">lemon</a>,
<a href="https://huggingface.co/datasets/jiaheillu/sovits_audio_preview/resolve/main/宵宫_preview/my_heart_will_go_no2宵宫.WAV">my heart will go on</a>,
</td>
</tr>
</tbody>
</table>
</div>
关键参数:
audio duration:训练集总时长
epoch: 轮数
其余:
batch_size = 一个step训练的片段数<br>
segments = 音频被切分的片段<br>
step=segments*epoch/batch_size,即模型文件后面数字由来<br>
以散兵为例:
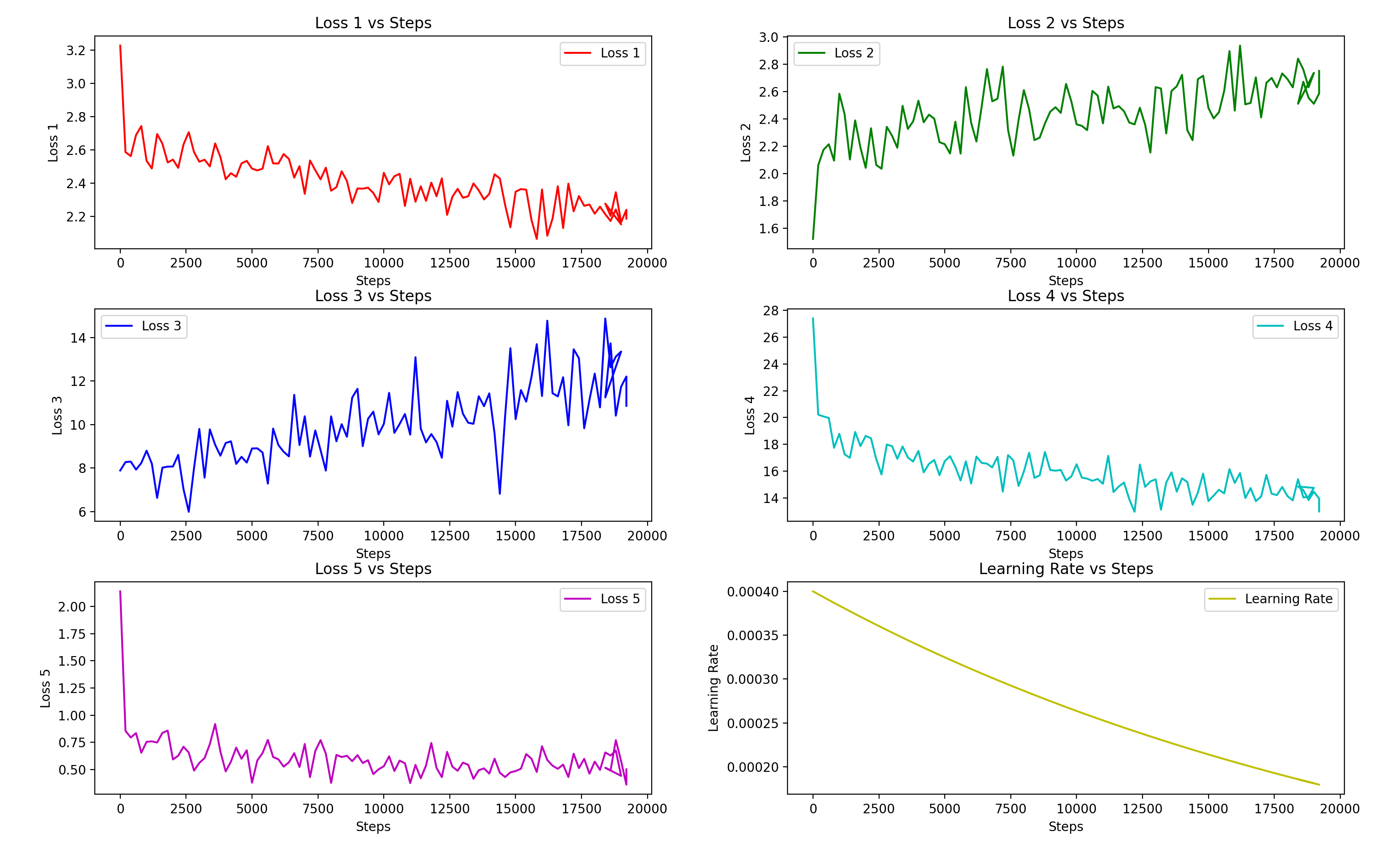
损失函数图像:主要看step 与 loss5,比如:<br>
给一个大致的参考,待转换音频都为高音女生,这是较为刁钻的测试:如图,10min纯净人声,<br>
差不多2800epoch(10000step)就已经出结果了,实际使用的是5571epoch(19500step)的文件,被训练音色和原音色相差几<br>
何,差不多有个概念。当然即使loss也不足以参考,唯一的衡量标准就是当事人的耳朵。当然,正常训练,10min还是有些少的。<br>
[点我查看相关文件](https://huggingface.co/datasets/jiaheillu/audio_preview/tree/main)<br>
 |