
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1B
| node_id
stringlengths 18
32
| number
int64 1
2.96k
| title
stringlengths 1
268
| user
dict | labels
sequence | state
stringclasses 2
values | locked
bool 1
class | assignee
null | assignees
sequence | milestone
null | comments
sequence | created_at
int64 1,587B
1,632B
| updated_at
int64 1,587B
1,632B
| closed_at
int64 1,587B
1,632B
⌀ | author_association
stringclasses 4
values | active_lock_reason
null | pull_request
dict | body
stringlengths 0
228k
⌀ | timeline_url
stringlengths 67
70
| performed_via_github_app
null | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2955 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2955/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2955/comments | https://api.github.com/repos/huggingface/datasets/issues/2955/events | https://github.com/huggingface/datasets/pull/2955 | 1,003,999,469 | PR_kwDODunzps4sHuRu | 2,955 | Update legacy Python image for CI tests in Linux | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,632,299,127,000 | 1,632,302,608,000 | null | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2955",
"html_url": "https://github.com/huggingface/datasets/pull/2955",
"diff_url": "https://github.com/huggingface/datasets/pull/2955.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2955.patch"
} | Instead of legacy, use next-generation convenience images, built from the ground up with CI, efficiency, and determinism in mind. Here are some of the highlights:
- Faster spin-up time - In Docker terminology, these next-gen images will generally have fewer and smaller layers. Using these new images will lead to faster image downloads when a build starts, and a higher likelihood that the image is already cached on the host.
- Improved reliability and stability - The existing legacy convenience images are rebuilt practically every day with potential changes from upstream that we cannot always test fast enough. This leads to frequent breaking changes, which is not the best environment for stable, deterministic builds. Next-gen images will only be rebuilt for security and critical-bugs, leading to more stable and deterministic images.
More info: https://circleci.com/docs/2.0/circleci-images | https://api.github.com/repos/huggingface/datasets/issues/2955/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2954/comments | https://api.github.com/repos/huggingface/datasets/issues/2954/events | https://github.com/huggingface/datasets/pull/2954 | 1,003,904,803 | PR_kwDODunzps4sHa8O | 2,954 | Run tests in parallel | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"There is a speed up in Windows machines:\r\n- From `13m 52s` to `11m 10s`\r\n\r\nIn Linux machines, some workers crash with error message:\r\n```\r\nOSError: [Errno 12] Cannot allocate memory\r\n```",
"There is also a speed up in Linux machines:\r\n- From `7m 30s` to `5m 32s`"
] | 1,632,294,044,000 | 1,632,297,373,000 | null | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2954",
"html_url": "https://github.com/huggingface/datasets/pull/2954",
"diff_url": "https://github.com/huggingface/datasets/pull/2954.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2954.patch"
} | Run CI tests in parallel to speed up the test suite. | https://api.github.com/repos/huggingface/datasets/issues/2954/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2952/comments | https://api.github.com/repos/huggingface/datasets/issues/2952/events | https://github.com/huggingface/datasets/pull/2952 | 1,002,704,096 | PR_kwDODunzps4sDU8S | 2,952 | Fix missing conda deps | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,632,237,781,000 | 1,632,285,599,000 | 1,632,238,244,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2952",
"html_url": "https://github.com/huggingface/datasets/pull/2952",
"diff_url": "https://github.com/huggingface/datasets/pull/2952.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2952.patch"
} | `aiohttp` was added as a dependency in #2662 but was missing for the conda build, which causes the 1.12.0 and 1.12.1 to fail.
Fix #2932. | https://api.github.com/repos/huggingface/datasets/issues/2952/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2951 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2951/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2951/comments | https://api.github.com/repos/huggingface/datasets/issues/2951/events | https://github.com/huggingface/datasets/pull/2951 | 1,001,267,888 | PR_kwDODunzps4r-lGs | 2,951 | Dummy labels no longer on by default in `to_tf_dataset` | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq Let me make sure we never need it, and if not then I'll remove it entirely in a follow-up PR.",
"Thanks ;) it will be less confusing and easier to maintain to not keep unused hacky features"
] | 1,632,162,419,000 | 1,632,232,857,000 | 1,632,219,272,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2951",
"html_url": "https://github.com/huggingface/datasets/pull/2951",
"diff_url": "https://github.com/huggingface/datasets/pull/2951.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2951.patch"
} | After more experimentation, I think I have a way to do things that doesn't depend on adding `dummy_labels` - they were quite a hacky solution anyway! | https://api.github.com/repos/huggingface/datasets/issues/2951/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2950 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2950/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2950/comments | https://api.github.com/repos/huggingface/datasets/issues/2950/events | https://github.com/huggingface/datasets/pull/2950 | 1,001,085,353 | PR_kwDODunzps4r-AKu | 2,950 | Fix fn kwargs in filter | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,632,150,626,000 | 1,632,154,979,000 | 1,632,151,681,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2950",
"html_url": "https://github.com/huggingface/datasets/pull/2950",
"diff_url": "https://github.com/huggingface/datasets/pull/2950.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2950.patch"
} | #2836 broke the `fn_kwargs` parameter of `filter`, as mentioned in https://github.com/huggingface/datasets/issues/2927
I fixed that and added a test to make sure it doesn't happen again (for either map or filter)
Fix #2927 | https://api.github.com/repos/huggingface/datasets/issues/2950/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2949/comments | https://api.github.com/repos/huggingface/datasets/issues/2949/events | https://github.com/huggingface/datasets/pull/2949 | 1,001,026,680 | PR_kwDODunzps4r90Pt | 2,949 | Introduce web and wiki config in triviaqa dataset | {
"login": "shirte",
"id": 1706443,
"node_id": "MDQ6VXNlcjE3MDY0NDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1706443?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shirte",
"html_url": "https://github.com/shirte",
"followers_url": "https://api.github.com/users/shirte/followers",
"following_url": "https://api.github.com/users/shirte/following{/other_user}",
"gists_url": "https://api.github.com/users/shirte/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shirte/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shirte/subscriptions",
"organizations_url": "https://api.github.com/users/shirte/orgs",
"repos_url": "https://api.github.com/users/shirte/repos",
"events_url": "https://api.github.com/users/shirte/events{/privacy}",
"received_events_url": "https://api.github.com/users/shirte/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,632,147,443,000 | 1,632,262,631,000 | null | NONE | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2949",
"html_url": "https://github.com/huggingface/datasets/pull/2949",
"diff_url": "https://github.com/huggingface/datasets/pull/2949.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2949.patch"
} | The TriviaQA paper suggests that the two subsets (Wikipedia and Web)
should be treated differently. There are also different leaderboards
for the two sets on CodaLab. For that reason, introduce additional
builder configs in the trivia_qa dataset. | https://api.github.com/repos/huggingface/datasets/issues/2949/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2948 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2948/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2948/comments | https://api.github.com/repos/huggingface/datasets/issues/2948/events | https://github.com/huggingface/datasets/pull/2948 | 1,000,844,077 | PR_kwDODunzps4r9PdV | 2,948 | Fix minor URL format in scitldr dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,632,136,292,000 | 1,632,143,908,000 | 1,632,143,908,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2948",
"html_url": "https://github.com/huggingface/datasets/pull/2948",
"diff_url": "https://github.com/huggingface/datasets/pull/2948.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2948.patch"
} | While investigating issue #2918, I found this minor format issues in the URLs (if runned in a Windows machine). | https://api.github.com/repos/huggingface/datasets/issues/2948/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2947 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2947/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2947/comments | https://api.github.com/repos/huggingface/datasets/issues/2947/events | https://github.com/huggingface/datasets/pull/2947 | 1,000,798,338 | PR_kwDODunzps4r9GIP | 2,947 | Don't use old, incompatible cache for the new `filter` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,632,133,139,000 | 1,632,155,109,000 | 1,632,145,382,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2947",
"html_url": "https://github.com/huggingface/datasets/pull/2947",
"diff_url": "https://github.com/huggingface/datasets/pull/2947.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2947.patch"
} | #2836 changed `Dataset.filter` and the resulting data that are stored in the cache are different and incompatible with the ones of the previous `filter` implementation.
However the caching mechanism wasn't able to differentiate between the old and the new implementation of filter (only the method name was taken into account).
This is an issue because anyone that update `datasets` and re-runs some code that uses `filter` would see an error, because the cache would try to load an incompatible `filter` result.
To fix this I added the notion of versioning for dataset transform in the caching mechanism, and bumped the version of the `filter` implementation to 2.0.0
This way the new `filter` outputs are now considered different from the old ones from the caching point of view.
This should fix #2943
cc @anton-l | https://api.github.com/repos/huggingface/datasets/issues/2947/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2946 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2946/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2946/comments | https://api.github.com/repos/huggingface/datasets/issues/2946/events | https://github.com/huggingface/datasets/pull/2946 | 1,000,754,824 | PR_kwDODunzps4r89f8 | 2,946 | Update meteor score from nltk update | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,632,130,126,000 | 1,632,130,559,000 | 1,632,130,559,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2946",
"html_url": "https://github.com/huggingface/datasets/pull/2946",
"diff_url": "https://github.com/huggingface/datasets/pull/2946.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2946.patch"
} | It looks like there were issues in NLTK on the way the METEOR score was computed.
A fix was added in NLTK at https://github.com/nltk/nltk/pull/2763, and therefore the scoring function no longer returns the same values.
I updated the score of the example in the docs | https://api.github.com/repos/huggingface/datasets/issues/2946/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2945/comments | https://api.github.com/repos/huggingface/datasets/issues/2945/events | https://github.com/huggingface/datasets/issues/2945 | 1,000,624,883 | I_kwDODunzps47pFLz | 2,945 | Protect master branch | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Cool, I think we can do both :)",
"@lhoestq now the 2 are implemented.\r\n\r\nPlease note that for the the second protection, finally I have chosen to protect the master branch only from **merge commits** (see update comment above), so no need to disable/re-enable the protection on each release (direct commits, different from merge commits, can be pushed to the remote master branch; and eventually reverted without messing up the repo history)."
] | 1,632,120,421,000 | 1,632,139,287,000 | 1,632,139,216,000 | MEMBER | null | null | After accidental merge commit (91c55355b634d0dc73350a7ddee1a6776dbbdd69) into `datasets` master branch, all commits present in the feature branch were permanently added to `datasets` master branch history, as e.g.:
- 00cc036fea7c7745cfe722360036ed306796a3f2
- 13ae8c98602bbad8197de3b9b425f4c78f582af1
- ...
I propose to protect our master branch, so that we avoid we can accidentally make this kind of mistakes in the future:
- [x] For Pull Requests using GitHub, allow only squash merging, so that only a single commit per Pull Request is merged into the master branch
- Currently, simple merge commits are already disabled
- I propose to disable rebase merging as well
- ~~Protect the master branch from direct pushes (to avoid accidentally pushing of merge commits)~~
- ~~This protection would reject direct pushes to master branch~~
- ~~If so, for each release (when we need to commit directly to the master branch), we should previously disable the protection and re-enable it again after the release~~
- [x] Protect the master branch only from direct pushing of **merge commits**
- GitHub offers the possibility to protect the master branch only from merge commits (which are the ones that introduce all the commits from the feature branch into the master branch).
- No need to disable/re-enable this protection on each release
This purpose of this Issue is to open a discussion about this problem and to agree in a solution. | https://api.github.com/repos/huggingface/datasets/issues/2945/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2944 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2944/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2944/comments | https://api.github.com/repos/huggingface/datasets/issues/2944/events | https://github.com/huggingface/datasets/issues/2944 | 1,000,544,370 | I_kwDODunzps47oxhy | 2,944 | Add `remove_columns` to `IterableDataset ` | {
"login": "cccntu",
"id": 31893406,
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cccntu",
"html_url": "https://github.com/cccntu",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"repos_url": "https://api.github.com/users/cccntu/repos",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,632,110,460,000 | 1,632,110,460,000 | null | CONTRIBUTOR | null | null | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is.
```python
from datasets import load_dataset
dataset = load_dataset("c4", 'realnewslike', streaming =True, split='train')
dataset = dataset.remove_columns('url')
```
```
AttributeError: 'IterableDataset' object has no attribute 'remove_columns'
```
**Describe the solution you'd like**
It would be nice to have `.remove_columns()` to match the `Datasets` api.
**Describe alternatives you've considered**
This can be done with a single call to `.map()`,
I can try to help add this. 🤗 | https://api.github.com/repos/huggingface/datasets/issues/2944/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2943 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2943/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2943/comments | https://api.github.com/repos/huggingface/datasets/issues/2943/events | https://github.com/huggingface/datasets/issues/2943 | 1,000,355,115 | I_kwDODunzps47oDUr | 2,943 | Backwards compatibility broken for cached datasets that use `.filter()` | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi ! I guess the caching mechanism should have considered the new `filter` to be different from the old one, and don't use cached results from the old `filter`.\r\nTo avoid other users from having this issue we could make the caching differentiate the two, what do you think ?",
"If it's easy enough to implement, then yes please 😄 But this issue can be low-priority, since I've only encountered it in a couple of `transformers` CI tests.",
"Well it can cause issue with anyone that updates `datasets` and re-run some code that uses filter, so I'm creating a PR",
"I just merged a fix, let me know if you're still having this kind of issues :)\r\n\r\nWe'll do a release soon to make this fix available",
"Definitely works on several manual cases with our dummy datasets, thank you @lhoestq !",
"Fixed by #2947."
] | 1,632,068,197,000 | 1,632,155,143,000 | 1,632,155,142,000 | CONTRIBUTOR | null | null | ## Describe the bug
After upgrading to datasets `1.12.0`, some cached `.filter()` steps from `1.11.0` started failing with
`ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'file': Value(dtype='string', id=None), 'text': Value(dtype='string', id=None), 'speaker_id': Value(dtype='int64', id=None), 'chapter_id': Value(dtype='int64', id=None), 'id': Value(dtype='string', id=None)}`
Related feature: https://github.com/huggingface/datasets/pull/2836
:question: This is probably a `wontfix` bug, since it can be solved by simply cleaning the related cache dirs, but the workaround could be useful for someone googling the error :)
## Workaround
Remove the cache for the given dataset, e.g. `rm -rf ~/.cache/huggingface/datasets/librispeech_asr`.
## Steps to reproduce the bug
1. Delete `~/.cache/huggingface/datasets/librispeech_asr` if it exists.
2. `pip install datasets==1.11.0` and run the following snippet:
```python
from datasets import load_dataset
ids = ["1272-141231-0000"]
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.filter(lambda x: x["id"] in ids)
```
3. `pip install datasets==1.12.1` and re-run the code again
## Expected results
Same result as with the previous `datasets` version.
## Actual results
```bash
Reusing dataset librispeech_asr (./.cache/huggingface/datasets/librispeech_asr/clean/2.1.0/468ec03677f46a8714ac6b5b64dba02d246a228d92cbbad7f3dc190fa039eab1)
Loading cached processed dataset at ./.cache/huggingface/datasets/librispeech_asr/clean/2.1.0/468ec03677f46a8714ac6b5b64dba02d246a228d92cbbad7f3dc190fa039eab1/cache-cd1c29844fdbc87a.arrow
Traceback (most recent call last):
File "./repos/transformers/src/transformers/models/wav2vec2/try_dataset.py", line 5, in <module>
ds = ds.filter(lambda x: x["id"] in ids)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/fingerprint.py", line 398, in wrapper
out = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2169, in filter
indices = self.map(
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1686, in map
return self._map_single(
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/fingerprint.py", line 398, in wrapper
out = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1896, in _map_single
return Dataset.from_file(cache_file_name, info=info, split=self.split)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 343, in from_file
return cls(
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 282, in __init__
self.info.features = self.info.features.reorder_fields_as(inferred_features)
File "./envs/transformers/lib/python3.8/site-packages/datasets/features.py", line 1151, in reorder_fields_as
return Features(recursive_reorder(self, other))
File "./envs/transformers/lib/python3.8/site-packages/datasets/features.py", line 1140, in recursive_reorder
raise ValueError(f"Keys mismatch: between {source} and {target}" + stack_position)
ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'file': Value(dtype='string', id=None), 'text': Value(dtype='string', id=None), 'speaker_id': Value(dtype='int64', id=None), 'chapter_id': Value(dtype='int64', id=None), 'id': Value(dtype='string', id=None)}
Process finished with exit code 1
```
## Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.11.0-34-generic-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 5.0.0
| https://api.github.com/repos/huggingface/datasets/issues/2943/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2942 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2942/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2942/comments | https://api.github.com/repos/huggingface/datasets/issues/2942/events | https://github.com/huggingface/datasets/pull/2942 | 1,000,309,765 | PR_kwDODunzps4r7tY6 | 2,942 | Add SEDE dataset | {
"login": "Hazoom",
"id": 13545154,
"node_id": "MDQ6VXNlcjEzNTQ1MTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/13545154?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hazoom",
"html_url": "https://github.com/Hazoom",
"followers_url": "https://api.github.com/users/Hazoom/followers",
"following_url": "https://api.github.com/users/Hazoom/following{/other_user}",
"gists_url": "https://api.github.com/users/Hazoom/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hazoom/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hazoom/subscriptions",
"organizations_url": "https://api.github.com/users/Hazoom/orgs",
"repos_url": "https://api.github.com/users/Hazoom/repos",
"events_url": "https://api.github.com/users/Hazoom/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hazoom/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Thanks @albertvillanova for your great suggestions! I just pushed a new commit with the necessary fixes. For some reason, the test `test_metric_common` failed for `meteor` metric, which doesn't have any connection to this PR, so I'm trying to rebase and see if it helps.",
"Hi @Hazoom,\r\n\r\nYou were right: the non-passing test had nothing to do with this PR.\r\n\r\nUnfortunately, you did a git rebase (instead of a git merge), which is not recommended once you have already opened a pull request because you mess up your pull request history. You can see that your pull request now contains:\r\n- your commits repeated two times\r\n- and commits which are not yours from the master branch\r\n\r\nIf you would like to clean your pull request, please make:\r\n```\r\ngit reset --hard 587b93a\r\ngit fetch upstream master\r\ngit merge upstream/master\r\ngit push --force origin sede\r\n```",
"> Hi @Hazoom,\r\n> \r\n> You were right: the non-passing test had nothing to do with this PR.\r\n> \r\n> Unfortunately, you did a git rebase (instead of a git merge), which is not recommended once you have already opened a pull request because you mess up your pull request history. You can see that your pull request now contains:\r\n> \r\n> * your commits repeated two times\r\n> * and commits which are not yours from the master branch\r\n> \r\n> If you would like to clean your pull request, please make:\r\n> \r\n> ```\r\n> git reset --hard 587b93a\r\n> git fetch upstream master\r\n> git merge upstream/master\r\n> git push --force origin sede\r\n> ```\r\n\r\nThanks @albertvillanova ",
"> Nice! Just one final request before approving your pull request:\r\n> \r\n> As you have updated the \"QuerySetId\" field data type, the size of the dataset is smaller now. You should regenerate the metadata. Please run:\r\n> \r\n> ```\r\n> rm datasets/sede/dataset_infos.json\r\n> datasets-cli test datasets/sede --save_infos --all_configs\r\n> ```\r\n\r\n@albertvillanova Good catch, just fixed it."
] | 1,632,057,084,000 | 1,632,139,643,000 | null | NONE | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2942",
"html_url": "https://github.com/huggingface/datasets/pull/2942",
"diff_url": "https://github.com/huggingface/datasets/pull/2942.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2942.patch"
} | This PR adds the SEDE dataset for the task of realistic Text-to-SQL, following the instructions of how to add a database and a dataset card.
Please see our paper for more details: https://arxiv.org/abs/2106.05006 | https://api.github.com/repos/huggingface/datasets/issues/2942/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2941/comments | https://api.github.com/repos/huggingface/datasets/issues/2941/events | https://github.com/huggingface/datasets/issues/2941 | 1,000,000,711 | I_kwDODunzps47mszH | 2,941 | OSCAR unshuffled_original_ko: NonMatchingSplitsSizesError | {
"login": "ayaka14732",
"id": 68557794,
"node_id": "MDQ6VXNlcjY4NTU3Nzk0",
"avatar_url": "https://avatars.githubusercontent.com/u/68557794?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayaka14732",
"html_url": "https://github.com/ayaka14732",
"followers_url": "https://api.github.com/users/ayaka14732/followers",
"following_url": "https://api.github.com/users/ayaka14732/following{/other_user}",
"gists_url": "https://api.github.com/users/ayaka14732/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ayaka14732/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayaka14732/subscriptions",
"organizations_url": "https://api.github.com/users/ayaka14732/orgs",
"repos_url": "https://api.github.com/users/ayaka14732/repos",
"events_url": "https://api.github.com/users/ayaka14732/events{/privacy}",
"received_events_url": "https://api.github.com/users/ayaka14732/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"I tried `unshuffled_original_da` and it is also not working"
] | 1,631,961,553,000 | 1,631,982,333,000 | null | NONE | null | null | ## Describe the bug
Cannot download OSCAR `unshuffled_original_ko` due to `NonMatchingSplitsSizesError`.
## Steps to reproduce the bug
```python
>>> dataset = datasets.load_dataset('oscar', 'unshuffled_original_ko')
NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=25292102197, num_examples=7345075, dataset_name='oscar'), 'recorded': SplitInfo(name='train', num_bytes=25284578514, num_examples=7344907, dataset_name='oscar')}]
```
## Expected results
Loading is successful.
## Actual results
Loading throws above error.
## Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.4.0-81-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 5.0.0
| https://api.github.com/repos/huggingface/datasets/issues/2941/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2940 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2940/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2940/comments | https://api.github.com/repos/huggingface/datasets/issues/2940/events | https://github.com/huggingface/datasets/pull/2940 | 999,680,796 | PR_kwDODunzps4r6EUF | 2,940 | add swedish_medical_ner dataset | {
"login": "bwang482",
"id": 6764450,
"node_id": "MDQ6VXNlcjY3NjQ0NTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6764450?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bwang482",
"html_url": "https://github.com/bwang482",
"followers_url": "https://api.github.com/users/bwang482/followers",
"following_url": "https://api.github.com/users/bwang482/following{/other_user}",
"gists_url": "https://api.github.com/users/bwang482/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bwang482/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bwang482/subscriptions",
"organizations_url": "https://api.github.com/users/bwang482/orgs",
"repos_url": "https://api.github.com/users/bwang482/repos",
"events_url": "https://api.github.com/users/bwang482/events{/privacy}",
"received_events_url": "https://api.github.com/users/bwang482/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,631,908,985,000 | 1,632,216,774,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2940",
"html_url": "https://github.com/huggingface/datasets/pull/2940",
"diff_url": "https://github.com/huggingface/datasets/pull/2940.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2940.patch"
} | Adding the Swedish Medical NER dataset, listed in "Biomedical Datasets - BigScience Workshop 2021" | https://api.github.com/repos/huggingface/datasets/issues/2940/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2939 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2939/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2939/comments | https://api.github.com/repos/huggingface/datasets/issues/2939/events | https://github.com/huggingface/datasets/pull/2939 | 999,639,630 | PR_kwDODunzps4r58Gu | 2,939 | MENYO-20k repo has moved, updating URL | {
"login": "cdleong",
"id": 4109253,
"node_id": "MDQ6VXNlcjQxMDkyNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4109253?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cdleong",
"html_url": "https://github.com/cdleong",
"followers_url": "https://api.github.com/users/cdleong/followers",
"following_url": "https://api.github.com/users/cdleong/following{/other_user}",
"gists_url": "https://api.github.com/users/cdleong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cdleong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cdleong/subscriptions",
"organizations_url": "https://api.github.com/users/cdleong/orgs",
"repos_url": "https://api.github.com/users/cdleong/repos",
"events_url": "https://api.github.com/users/cdleong/events{/privacy}",
"received_events_url": "https://api.github.com/users/cdleong/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,905,314,000 | 1,632,238,297,000 | 1,632,238,296,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2939",
"html_url": "https://github.com/huggingface/datasets/pull/2939",
"diff_url": "https://github.com/huggingface/datasets/pull/2939.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2939.patch"
} | Dataset repo moved to https://github.com/uds-lsv/menyo-20k_MT, now editing URL to match.
https://github.com/uds-lsv/menyo-20k_MT/blob/master/data/train.tsv is the file we're looking for | https://api.github.com/repos/huggingface/datasets/issues/2939/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2938 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2938/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2938/comments | https://api.github.com/repos/huggingface/datasets/issues/2938/events | https://github.com/huggingface/datasets/pull/2938 | 999,552,263 | PR_kwDODunzps4r5qwa | 2,938 | Take namespace into account in caching | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"We might have collisions if a username and a dataset_name are the same. Maybe instead serialize the dataset name by replacing `/` with some string, eg `__SLASH__`, that will hopefully never appear in a dataset or user name (it's what I did in https://github.com/huggingface/datasets-preview-backend/blob/master/benchmark/scripts/serialize.py. That way, all the datasets are one-level deep directories",
"IIRC we enforce that no repo id or username can contain `___` (exactly 3 underscores) specifically for this reason, so you can use that string (that we use in other projects)\r\n\r\ncc @Pierrci ",
"> IIRC we enforce that no repo id or username can contain ___ (exactly 3 underscores) specifically for this reason, so you can use that string (that we use in other projects)\r\n\r\nout of curiosity: where is it enforced?",
"> where is it enforced?\r\n\r\nNowhere yet but we should :) feel free to track in internal tracker and/or implement, as this will be useful in the future",
"Thanks for the trick, I'm doing the change :)\r\nWe can use\r\n`~/.cache/huggingface/datasets/username___dataset_name` for the data\r\n`~/.cache/huggingface/modules/datasets_modules/datasets/username___dataset_name` for the python files"
] | 1,631,897,853,000 | 1,632,242,634,000 | null | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2938",
"html_url": "https://github.com/huggingface/datasets/pull/2938",
"diff_url": "https://github.com/huggingface/datasets/pull/2938.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2938.patch"
} | Loading a dataset "username/dataset_name" hosted by a user on the hub used to cache the dataset only taking into account the dataset name, and ignorign the username. Because of this, if a user later loads "dataset_name" without specifying the username, it would reload the dataset from the cache instead of failing.
I changed the dataset cache and module cache mechanism to include the username in the name of the cache directory that is used:
<s>
`~/.cache/huggingface/datasets/username/dataset_name` for the data
`~/.cache/huggingface/modules/datasets_modules/datasets/username/dataset_name` for the python files
</s>
EDIT: actually using three underscores:
`~/.cache/huggingface/datasets/username___dataset_name` for the data
`~/.cache/huggingface/modules/datasets_modules/datasets/username___dataset_name` for the python files
This PR should fix the issue https://github.com/huggingface/datasets/issues/2842
cc @stas00 | https://api.github.com/repos/huggingface/datasets/issues/2938/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2937 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2937/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2937/comments | https://api.github.com/repos/huggingface/datasets/issues/2937/events | https://github.com/huggingface/datasets/issues/2937 | 999,548,277 | I_kwDODunzps47k-V1 | 2,937 | load_dataset using default cache on Windows causes PermissionError: [WinError 5] Access is denied | {
"login": "daqieq",
"id": 40532020,
"node_id": "MDQ6VXNlcjQwNTMyMDIw",
"avatar_url": "https://avatars.githubusercontent.com/u/40532020?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daqieq",
"html_url": "https://github.com/daqieq",
"followers_url": "https://api.github.com/users/daqieq/followers",
"following_url": "https://api.github.com/users/daqieq/following{/other_user}",
"gists_url": "https://api.github.com/users/daqieq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/daqieq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daqieq/subscriptions",
"organizations_url": "https://api.github.com/users/daqieq/orgs",
"repos_url": "https://api.github.com/users/daqieq/repos",
"events_url": "https://api.github.com/users/daqieq/events{/privacy}",
"received_events_url": "https://api.github.com/users/daqieq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi @daqieq, thanks for reporting.\r\n\r\nUnfortunately, I was not able to reproduce this bug:\r\n```ipython\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset('wiki_bio')\r\nDownloading: 7.58kB [00:00, 26.3kB/s]\r\nDownloading: 2.71kB [00:00, ?B/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to C:\\Users\\username\\.cache\\huggingface\\datasets\\wiki_bio\\default\\\r\n1.1.0\\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...\r\nDownloading: 334MB [01:17, 4.32MB/s]\r\nDataset wiki_bio downloaded and prepared to C:\\Users\\username\\.cache\\huggingface\\datasets\\wiki_bio\\default\\1.1.0\\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9. Subsequent calls will reuse thi\r\ns data.\r\n```\r\n\r\nThis kind of error messages usually happen because:\r\n- Your running Python script hasn't write access to that directory\r\n- You have another program (the File Explorer?) already browsing inside that directory",
"Thanks @albertvillanova for looking at it! I tried on my personal Windows machine and it downloaded just fine.\r\n\r\nRunning on my work machine and on a colleague's machine it is consistently hitting this error. It's not a write access issue because the `.incomplete` directory is written just fine. It just won't rename and then it deletes the directory in the `finally` step. Also the zip file is written and extracted fine in the downloads directory.\r\n\r\nThat leaves another program that might be interfering, and there are plenty of those in my work machine ... (full antivirus, data loss prevention, etc.). So the question remains, why not extend the `try` block to allow catching the error and circle back to the rename after the unknown program is finished doing its 'stuff'. This is the approach that I read about in the linked repo (see my comments above).\r\n\r\nIf it's not high priority, that's fine. However, if someone were to write an PR that solved this issue in our environment in an `except` clause, would it be reviewed for inclusion in a future release? Just wondering whether I should spend any more time on this issue."
] | 1,631,897,530,000 | 1,632,189,875,000 | null | NONE | null | null | ## Describe the bug
Standard process to download and load the wiki_bio dataset causes PermissionError in Windows 10 and 11.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset('wiki_bio')
```
## Expected results
It is expected that the dataset downloads without any errors.
## Actual results
PermissionError see trace below:
```
Using custom data configuration default
Downloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to C:\Users\username\.cache\huggingface\datasets\wiki_bio\default\1.1.0\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\username\.conda\envs\hf\lib\site-packages\datasets\load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "C:\Users\username\.conda\envs\hf\lib\site-packages\datasets\builder.py", line 644, in download_and_prepare
self._save_info()
File "C:\Users\username\.conda\envs\hf\lib\contextlib.py", line 120, in __exit__
next(self.gen)
File "C:\Users\username\.conda\envs\hf\lib\site-packages\datasets\builder.py", line 598, in incomplete_dir
os.rename(tmp_dir, dirname)
PermissionError: [WinError 5] Access is denied: 'C:\\Users\\username\\.cache\\huggingface\\datasets\\wiki_bio\\default\\1.1.0\\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9.incomplete' -> 'C:\\Users\\username\\.cache\\huggingface\\datasets\\wiki_bio\\default\\1.1.0\\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9'
```
By commenting out the os.rename() [L604](https://github.com/huggingface/datasets/blob/master/src/datasets/builder.py#L604) and the shutil.rmtree() [L607](https://github.com/huggingface/datasets/blob/master/src/datasets/builder.py#L607) lines, in my virtual environment, I was able to get the load process to complete, rename the directory manually and then rerun the `load_dataset('wiki_bio')` to get what I needed.
It seems that os.rename() in the `incomplete_dir` content manager is the culprit. Here's another project [Conan](https://github.com/conan-io/conan/issues/6560) with similar issue with os.rename() if it helps debug this issue.
## Environment info
- `datasets` version: 1.12.1
- Platform: Windows-10-10.0.22449-SP0
- Python version: 3.8.12
- PyArrow version: 5.0.0
| https://api.github.com/repos/huggingface/datasets/issues/2937/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2936 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2936/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2936/comments | https://api.github.com/repos/huggingface/datasets/issues/2936/events | https://github.com/huggingface/datasets/pull/2936 | 999,521,647 | PR_kwDODunzps4r5knb | 2,936 | Check that array is not Float as nan != nan | {
"login": "Iwontbecreative",
"id": 494951,
"node_id": "MDQ6VXNlcjQ5NDk1MQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/494951?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Iwontbecreative",
"html_url": "https://github.com/Iwontbecreative",
"followers_url": "https://api.github.com/users/Iwontbecreative/followers",
"following_url": "https://api.github.com/users/Iwontbecreative/following{/other_user}",
"gists_url": "https://api.github.com/users/Iwontbecreative/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Iwontbecreative/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Iwontbecreative/subscriptions",
"organizations_url": "https://api.github.com/users/Iwontbecreative/orgs",
"repos_url": "https://api.github.com/users/Iwontbecreative/repos",
"events_url": "https://api.github.com/users/Iwontbecreative/events{/privacy}",
"received_events_url": "https://api.github.com/users/Iwontbecreative/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,895,401,000 | 1,632,217,145,000 | 1,632,217,144,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2936",
"html_url": "https://github.com/huggingface/datasets/pull/2936",
"diff_url": "https://github.com/huggingface/datasets/pull/2936.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2936.patch"
} | The Exception wants to check for issues with StructArrays/ListArrays but catches FloatArrays with value nan as nan != nan.
Pass on FloatArrays as we should not raise an Exception for them. | https://api.github.com/repos/huggingface/datasets/issues/2936/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2935/comments | https://api.github.com/repos/huggingface/datasets/issues/2935/events | https://github.com/huggingface/datasets/pull/2935 | 999,518,469 | PR_kwDODunzps4r5j8B | 2,935 | Add Jigsaw unintended Bias | {
"login": "Iwontbecreative",
"id": 494951,
"node_id": "MDQ6VXNlcjQ5NDk1MQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/494951?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Iwontbecreative",
"html_url": "https://github.com/Iwontbecreative",
"followers_url": "https://api.github.com/users/Iwontbecreative/followers",
"following_url": "https://api.github.com/users/Iwontbecreative/following{/other_user}",
"gists_url": "https://api.github.com/users/Iwontbecreative/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Iwontbecreative/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Iwontbecreative/subscriptions",
"organizations_url": "https://api.github.com/users/Iwontbecreative/orgs",
"repos_url": "https://api.github.com/users/Iwontbecreative/repos",
"events_url": "https://api.github.com/users/Iwontbecreative/events{/privacy}",
"received_events_url": "https://api.github.com/users/Iwontbecreative/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Note that the tests seem to fail because of a bug in an Exception at the moment, see: https://github.com/huggingface/datasets/pull/2936 for the fix",
"@lhoestq implemented your changes, I think this might be ready for another look."
] | 1,631,895,151,000 | 1,632,269,548,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2935",
"html_url": "https://github.com/huggingface/datasets/pull/2935",
"diff_url": "https://github.com/huggingface/datasets/pull/2935.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2935.patch"
} | Hi,
Here's a first attempt at this dataset. Would be great if it could be merged relatively quickly as it is needed for Bigscience-related stuff.
This requires manual download, and I had some trouble generating dummy_data in this setting, so welcoming feedback there. | https://api.github.com/repos/huggingface/datasets/issues/2935/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2934 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2934/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2934/comments | https://api.github.com/repos/huggingface/datasets/issues/2934/events | https://github.com/huggingface/datasets/issues/2934 | 999,477,413 | I_kwDODunzps47ktCl | 2,934 | to_tf_dataset keeps a reference to the open data somewhere, causing issues on windows | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"I did some investigation and, as it seems, the bug stems from [this line](https://github.com/huggingface/datasets/blob/8004d7c3e1d74b29c3e5b0d1660331cd26758363/src/datasets/arrow_dataset.py#L325). The lifecycle of the dataset from the linked line is bound to one of the returned `tf.data.Dataset`. So my (hacky) solution involves wrapping the linked dataset with `weakref.proxy` and adding a custom `__del__` to `tf.python.data.ops.dataset_ops.TensorSliceDataset` (this is the type of a dataset that is returned by `tf.data.Dataset.from_tensor_slices`; this works for TF 2.x, but I'm not sure `tf.python.data.ops.dataset_ops` is a valid path for TF 1.x) that deletes the linked dataset, which is assigned to the dataset object as a property. Will open a draft PR soon!",
"Thanks a lot for investigating !"
] | 1,631,892,413,000 | 1,632,155,004,000 | null | MEMBER | null | null | To reproduce:
```python
import datasets as ds
import weakref
import gc
d = ds.load_dataset("mnist", split="train")
ref = weakref.ref(d._data.table)
tfd = d.to_tf_dataset("image", batch_size=1, shuffle=False, label_cols="label")
del tfd, d
gc.collect()
assert ref() is None, "Error: there is at least one reference left"
```
This causes issues because the table holds a reference to an open arrow file that should be closed. So on windows it's not possible to delete or move the arrow file afterwards.
Moreover the CI test of the `to_tf_dataset` method isn't able to clean up the temporary arrow files because of this.
cc @Rocketknight1 | https://api.github.com/repos/huggingface/datasets/issues/2934/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2933 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2933/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2933/comments | https://api.github.com/repos/huggingface/datasets/issues/2933/events | https://github.com/huggingface/datasets/pull/2933 | 999,392,566 | PR_kwDODunzps4r5MHs | 2,933 | Replace script_version with revision | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm also fine with the removal in 1.15"
] | 1,631,887,479,000 | 1,632,131,530,000 | 1,632,131,530,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2933",
"html_url": "https://github.com/huggingface/datasets/pull/2933",
"diff_url": "https://github.com/huggingface/datasets/pull/2933.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2933.patch"
} | As discussed in https://github.com/huggingface/datasets/pull/2718#discussion_r707013278, the parameter name `script_version` is no longer applicable to datasets without loading script (i.e., datasets only with raw data files).
This PR replaces the parameter name `script_version` with `revision`.
This way, we are also aligned with:
- Transformers: `AutoTokenizer.from_pretrained(..., revision=...)`
- Hub: `HfApi.dataset_info(..., revision=...)`, `HfApi.upload_file(..., revision=...)` | https://api.github.com/repos/huggingface/datasets/issues/2933/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2932 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2932/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2932/comments | https://api.github.com/repos/huggingface/datasets/issues/2932/events | https://github.com/huggingface/datasets/issues/2932 | 999,317,750 | I_kwDODunzps47kGD2 | 2,932 | Conda build fails | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Why 1.9 ?\r\n\r\nhttps://anaconda.org/HuggingFace/datasets currently says 1.11",
"Alright I added 1.12.0 and 1.12.1 and fixed the conda build #2952 "
] | 1,631,882,962,000 | 1,632,238,270,000 | 1,632,238,270,000 | MEMBER | null | null | ## Describe the bug
Current `datasets` version in conda is 1.9 instead of 1.12.
The build of the conda package fails.
| https://api.github.com/repos/huggingface/datasets/issues/2932/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2931 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2931/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2931/comments | https://api.github.com/repos/huggingface/datasets/issues/2931/events | https://github.com/huggingface/datasets/pull/2931 | 998,326,359 | PR_kwDODunzps4r1-JH | 2,931 | Fix bug in to_tf_dataset | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm going to merge it, but yeah - hopefully the CI runner just cleans that up automatically and few other people run the tests on Windows anyway!"
] | 1,631,804,883,000 | 1,631,811,698,000 | 1,631,811,697,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2931",
"html_url": "https://github.com/huggingface/datasets/pull/2931",
"diff_url": "https://github.com/huggingface/datasets/pull/2931.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2931.patch"
} | Replace `set_format()` to `with_format()` so that we don't alter the original dataset in `to_tf_dataset()` | https://api.github.com/repos/huggingface/datasets/issues/2931/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2930/comments | https://api.github.com/repos/huggingface/datasets/issues/2930/events | https://github.com/huggingface/datasets/issues/2930 | 998,154,311 | I_kwDODunzps47fqBH | 2,930 | Mutable columns argument breaks set_format | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
},
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Pushed a fix to my branch #2731 "
] | 1,631,795,242,000 | 1,631,800,253,000 | 1,631,800,253,000 | CONTRIBUTOR | null | null | ## Describe the bug
If you pass a mutable list to the `columns` argument of `set_format` and then change the list afterwards, the returned columns also change.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
column_list = ["idx", "label"]
dataset.set_format("python", columns=column_list)
column_list[1] = "foo" # Change the list after we call `set_format`
dataset['train'][:4].keys()
```
## Expected results
```python
dict_keys(['idx', 'label'])
```
## Actual results
```python
dict_keys(['idx'])
``` | https://api.github.com/repos/huggingface/datasets/issues/2930/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2929 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2929/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2929/comments | https://api.github.com/repos/huggingface/datasets/issues/2929/events | https://github.com/huggingface/datasets/pull/2929 | 997,960,024 | PR_kwDODunzps4r015C | 2,929 | Add regression test for null Sequence | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,782,713,000 | 1,631,867,039,000 | 1,631,867,039,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2929",
"html_url": "https://github.com/huggingface/datasets/pull/2929",
"diff_url": "https://github.com/huggingface/datasets/pull/2929.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2929.patch"
} | Relates to #2892 and #2900. | https://api.github.com/repos/huggingface/datasets/issues/2929/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2928/comments | https://api.github.com/repos/huggingface/datasets/issues/2928/events | https://github.com/huggingface/datasets/pull/2928 | 997,941,506 | PR_kwDODunzps4r0yUb | 2,928 | Update BibTeX entry | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,781,560,000 | 1,631,795,734,000 | 1,631,795,734,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2928",
"html_url": "https://github.com/huggingface/datasets/pull/2928",
"diff_url": "https://github.com/huggingface/datasets/pull/2928.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2928.patch"
} | Update BibTeX entry. | https://api.github.com/repos/huggingface/datasets/issues/2928/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2927/comments | https://api.github.com/repos/huggingface/datasets/issues/2927/events | https://github.com/huggingface/datasets/issues/2927 | 997,654,680 | I_kwDODunzps47dwCY | 2,927 | Datasets 1.12 dataset.filter TypeError: get_indices_from_mask_function() got an unexpected keyword argument | {
"login": "timothyjlaurent",
"id": 2000204,
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/timothyjlaurent",
"html_url": "https://github.com/timothyjlaurent",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting, I'm looking into it :)",
"Fixed by #2950."
] | 1,631,754,842,000 | 1,632,155,002,000 | 1,632,155,001,000 | NONE | null | null | ## Describe the bug
Upgrading to 1.12 caused `dataset.filter` call to fail with
> get_indices_from_mask_function() got an unexpected keyword argument valid_rel_labels
## Steps to reproduce the bug
```pythondef
filter_good_rows(
ex: Dict,
valid_rel_labels: Set[str],
valid_ner_labels: Set[str],
tokenizer: PreTrainedTokenizerFast,
) -> bool:
"""Get the good rows"""
encoding = get_encoding_for_text(text=ex["text"], tokenizer=tokenizer)
ex["encoding"] = encoding
for relation in ex["relations"]:
if not is_valid_relation(relation, valid_rel_labels):
return False
for span in ex["spans"]:
if not is_valid_span(span, valid_ner_labels, encoding):
return False
return True
def get_dataset():
loader_path = str(Path(__file__).parent / "prodigy_dataset_builder.py")
ds = load_dataset(
loader_path,
name="prodigy-dataset",
data_files=sorted(file_paths),
cache_dir=cache_dir,
)["train"]
valid_ner_labels = set(vocab.ner_category)
valid_relations = set(vocab.relation_types.keys())
ds = ds.filter(
filter_good_rows,
fn_kwargs=dict(
valid_rel_labels=valid_relations,
valid_ner_labels=valid_ner_labels,
tokenizer=vocab.tokenizer,
),
keep_in_memory=True,
num_proc=num_proc,
)
```
`ds` is a `DatasetDict` produced by a jsonl dataset.
This runs fine on 1.11 but fails on 1.12
**Stack Trace**
## Expected results
I expect 1.12 datasets filter to filter the dataset without raising as it does on 1.11
## Actual results
```
tf_ner_rel_lib/dataset.py:695: in load_prodigy_arrow_datasets_from_jsonl
ds = ds.filter(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:185: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/fingerprint.py:398: in wrapper
out = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:2169: in filter
indices = self.map(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:1686: in map
return self._map_single(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:185: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/fingerprint.py:398: in wrapper
out = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:2048: in _map_single
batch = apply_function_on_filtered_inputs(
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
inputs = {'_input_hash': [2108817714, 1477695082, -1021597032, 2130671338, -1260483858, -1203431639, ...], '_task_hash': [18070...ons', 'relations', 'relations', ...], 'answer': ['accept', 'accept', 'accept', 'accept', 'accept', 'accept', ...], ...}
indices = [0, 1, 2, 3, 4, 5, ...], check_same_num_examples = False, offset = 0
def apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples=False, offset=0):
"""Utility to apply the function on a selection of columns."""
nonlocal update_data
fn_args = [inputs] if input_columns is None else [inputs[col] for col in input_columns]
if offset == 0:
effective_indices = indices
else:
effective_indices = [i + offset for i in indices] if isinstance(indices, list) else indices + offset
processed_inputs = (
> function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
)
E TypeError: get_indices_from_mask_function() got an unexpected keyword argument 'valid_rel_labels'
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:1939: TypeError
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: Mac
- Python version: 3.8.9
- PyArrow version: pyarrow==5.0.0
| https://api.github.com/repos/huggingface/datasets/issues/2927/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2926 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2926/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2926/comments | https://api.github.com/repos/huggingface/datasets/issues/2926/events | https://github.com/huggingface/datasets/issues/2926 | 997,463,277 | I_kwDODunzps47dBTt | 2,926 | Error when downloading datasets to non-traditional cache directories | {
"login": "dar-tau",
"id": 45885627,
"node_id": "MDQ6VXNlcjQ1ODg1NjI3",
"avatar_url": "https://avatars.githubusercontent.com/u/45885627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dar-tau",
"html_url": "https://github.com/dar-tau",
"followers_url": "https://api.github.com/users/dar-tau/followers",
"following_url": "https://api.github.com/users/dar-tau/following{/other_user}",
"gists_url": "https://api.github.com/users/dar-tau/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dar-tau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dar-tau/subscriptions",
"organizations_url": "https://api.github.com/users/dar-tau/orgs",
"repos_url": "https://api.github.com/users/dar-tau/repos",
"events_url": "https://api.github.com/users/dar-tau/events{/privacy}",
"received_events_url": "https://api.github.com/users/dar-tau/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,631,735,986,000 | 1,631,736,135,000 | null | NONE | null | null | ## Describe the bug
When the cache directory is linked (soft link) to a directory on a NetApp device, the download fails.
## Steps to reproduce the bug
```bash
ln -s /path/to/netapp/.cache ~/.cache
```
```python
load_dataset("imdb")
```
## Expected results
Successfully loading IMDB dataset
## Actual results
```
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=33432835,
num_examples=25000, dataset_name='imdb'), 'recorded': SplitInfo(name='train', num_bytes=0, num_examples=0,
dataset_name='imdb')}, {'expected': SplitInfo(name='test', num_bytes=32650697, num_examples=25000, dataset_name='imdb'),
'recorded': SplitInfo(name='test', num_bytes=659932, num_examples=503, dataset_name='imdb')}, {'expected':
SplitInfo(name='unsupervised', num_bytes=67106814, num_examples=50000, dataset_name='imdb'), 'recorded':
SplitInfo(name='unsupervised', num_bytes=0, num_examples=0, dataset_name='imdb')}]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.1.2
- Platform: Ubuntu
- Python version: 3.8
## Extra notes
Stranger yet, trying to debug the phenomenon, I found the range of results to vary a lot without clear direction:
- With `cache_dir="/path/to/netapp/.cache"` the same thing happens.
- However, when linking `~/netapp/` to `/path/to/netapp` *and* setting `cache_dir="~/netapp/.cache/huggingface/datasets"` - it does work
- On the other hand, when linking `~/.cache` to `~/netapp/.cache` without using `cache_dir`, it does work anymore.
While I could test it only for a NetApp device, it might have to do with any other mounted FS.
Thanks :)
| https://api.github.com/repos/huggingface/datasets/issues/2926/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2925 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2925/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2925/comments | https://api.github.com/repos/huggingface/datasets/issues/2925/events | https://github.com/huggingface/datasets/pull/2925 | 997,407,034 | PR_kwDODunzps4rzJ9s | 2,925 | Add tutorial for no-code dataset upload | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Cool, love it ! :)\r\n\r\nFeel free to add a paragraph saying how to load the dataset:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"stevhliu/demo\")\r\n\r\n# or to separate each csv file into several splits\r\ndata_files = {\"train\": \"train.csv\", \"test\": \"test.csv\"}\r\ndataset = load_dataset(\"stevhliu/demo\", data_files=data_files)\r\nprint(dataset[\"train\"][0])\r\n```",
"Perfect, feel free to mark this PR ready for review :)\r\n\r\ncc @albertvillanova do you have any comment ? You can check the tutorial here:\r\nhttps://47389-250213286-gh.circle-artifacts.com/0/docs/_build/html/no_code_upload.html\r\n\r\nMaybe we can just add a list of supported file types:\r\n- csv\r\n- json\r\n- json lines\r\n- text\r\n- parquet"
] | 1,631,732,082,000 | 1,632,248,034,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2925",
"html_url": "https://github.com/huggingface/datasets/pull/2925",
"diff_url": "https://github.com/huggingface/datasets/pull/2925.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2925.patch"
} | This PR is for a tutorial for uploading a dataset to the Hub. It relies on the Hub UI elements to upload a dataset, introduces the online tagging tool for creating tags, and the Dataset card template to get a head start on filling it out. The addition of this tutorial should make it easier for beginners to upload a dataset without accessing the terminal or knowing Git. | https://api.github.com/repos/huggingface/datasets/issues/2925/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2924 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2924/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2924/comments | https://api.github.com/repos/huggingface/datasets/issues/2924/events | https://github.com/huggingface/datasets/issues/2924 | 997,378,113 | I_kwDODunzps47cshB | 2,924 | "File name too long" error for file locks | {
"login": "gar1t",
"id": 184949,
"node_id": "MDQ6VXNlcjE4NDk0OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/184949?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gar1t",
"html_url": "https://github.com/gar1t",
"followers_url": "https://api.github.com/users/gar1t/followers",
"following_url": "https://api.github.com/users/gar1t/following{/other_user}",
"gists_url": "https://api.github.com/users/gar1t/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gar1t/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gar1t/subscriptions",
"organizations_url": "https://api.github.com/users/gar1t/orgs",
"repos_url": "https://api.github.com/users/gar1t/repos",
"events_url": "https://api.github.com/users/gar1t/events{/privacy}",
"received_events_url": "https://api.github.com/users/gar1t/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi, the filename here is less than 255\r\n```python\r\n>>> len(\"_home_garrett_.cache_huggingface_datasets_csv_test-7c856aea083a7043_0.0.0_9144e0a4e8435090117cea53e6c7537173ef2304525df4a077c435d8ee7828ff.incomplete.lock\")\r\n154\r\n```\r\nso not sure why it's considered too long for your filesystem.\r\n(also note that the lock files we use always have smaller filenames than 255)\r\n\r\nhttps://github.com/huggingface/datasets/blob/5d1a9f1e3c6c495dc0610b459e39d2eb8893f152/src/datasets/utils/filelock.py#L135-L135",
"Yes, you're right! I need to get you more info here. Either there's something going with the name itself that the file system doesn't like (an encoding that blows up the name length??) or perhaps there's something with the path that's causing the entire string to be used as a name. I haven't seen this on any system before and the Internet's not forthcoming with any info."
] | 1,631,729,810,000 | 1,632,232,993,000 | null | NONE | null | null | ## Describe the bug
Getting the following error when calling `load_dataset("gar1t/test")`:
```
OSError: [Errno 36] File name too long: '<user>/.cache/huggingface/datasets/_home_garrett_.cache_huggingface_datasets_csv_test-7c856aea083a7043_0.0.0_9144e0a4e8435090117cea53e6c7537173ef2304525df4a077c435d8ee7828ff.incomplete.lock'
```
## Steps to reproduce the bug
Where the user cache dir (e.g. `~/.cache`) is on a file system that limits filenames to 255 chars (e.g. ext4):
```python
from datasets import load_dataset
load_dataset("gar1t/test")
```
## Expected results
Expect the function to return without an error.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<python_venv>/lib/python3.9/site-packages/datasets/load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "<python_venv>/lib/python3.9/site-packages/datasets/builder.py", line 644, in download_and_prepare
self._save_info()
File "<python_venv>/lib/python3.9/site-packages/datasets/builder.py", line 765, in _save_info
with FileLock(lock_path):
File "<python_venv>/lib/python3.9/site-packages/datasets/utils/filelock.py", line 323, in __enter__
self.acquire()
File "<python_venv>/lib/python3.9/site-packages/datasets/utils/filelock.py", line 272, in acquire
self._acquire()
File "<python_venv>/lib/python3.9/site-packages/datasets/utils/filelock.py", line 403, in _acquire
fd = os.open(self._lock_file, open_mode)
OSError: [Errno 36] File name too long: '<user>/.cache/huggingface/datasets/_home_garrett_.cache_huggingface_datasets_csv_test-7c856aea083a7043_0.0.0_9144e0a4e8435090117cea53e6c7537173ef2304525df4a077c435d8ee7828ff.incomplete.lock'
```
## Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.11.0-27-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyArrow version: 5.0.0
| https://api.github.com/repos/huggingface/datasets/issues/2924/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2923/comments | https://api.github.com/repos/huggingface/datasets/issues/2923/events | https://github.com/huggingface/datasets/issues/2923 | 997,351,590 | I_kwDODunzps47cmCm | 2,923 | Loading an autonlp dataset raises in normal mode but not in streaming mode | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,631,727,878,000 | 1,631,727,878,000 | null | CONTRIBUTOR | null | null | ## Describe the bug
The same dataset (from autonlp) raises an error in normal mode, but does not raise in streaming mode
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("severo/autonlp-data-sentiment_detection-3c8bcd36", split="train", streaming=False)
## raises an error
load_dataset("severo/autonlp-data-sentiment_detection-3c8bcd36", split="train", streaming=True)
## does not raise an error
```
## Expected results
Both calls should raise the same error
## Actual results
Call with streaming=False:
```
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 5825.42it/s]
Using custom data configuration autonlp-data-sentiment_detection-3c8bcd36-fe30267462d1d42b
Downloading and preparing dataset json/autonlp-data-sentiment_detection-3c8bcd36 to /home/slesage/.cache/huggingface/datasets/json/autonlp-data-sentiment_detection-3c8bcd36-fe30267462d1d42b/0.0.0/d75ead8d5cfcbe67495df0f89bd262f0023257fbbbd94a730313295f3d756d50...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 15923.71it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 3346.88it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 636, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 726, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 1187, in _prepare_split
writer.write_table(table)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/arrow_writer.py", line 418, in write_table
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/arrow_writer.py", line 418, in <listcomp>
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "pyarrow/table.pxi", line 1249, in pyarrow.lib.Table.__getitem__
File "pyarrow/table.pxi", line 1825, in pyarrow.lib.Table.column
File "pyarrow/table.pxi", line 1800, in pyarrow.lib.Table._ensure_integer_index
KeyError: 'Field "splits" does not exist in table schema'
```
Call with `streaming=False`:
```
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 6000.43it/s]
Using custom data configuration autonlp-data-sentiment_detection-3c8bcd36-fe30267462d1d42b
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 46916.15it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 148734.18it/s]
```
## Environment info
- `datasets` version: 1.12.1.dev0
- Platform: Linux-5.11.0-1017-aws-x86_64-with-glibc2.29
- Python version: 3.8.11
- PyArrow version: 4.0.1
| https://api.github.com/repos/huggingface/datasets/issues/2923/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2922 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2922/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2922/comments | https://api.github.com/repos/huggingface/datasets/issues/2922/events | https://github.com/huggingface/datasets/pull/2922 | 997,332,662 | PR_kwDODunzps4ry6-s | 2,922 | Fix conversion of multidim arrays in list to arrow | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,726,496,000 | 1,631,726,572,000 | 1,631,726,505,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2922",
"html_url": "https://github.com/huggingface/datasets/pull/2922",
"diff_url": "https://github.com/huggingface/datasets/pull/2922.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2922.patch"
} | Arrow only supports 1-dim arrays. Previously we were converting all the numpy arrays to python list before instantiating arrow arrays to workaround this limitation.
However in #2361 we started to keep numpy arrays in order to keep their dtypes.
It works when we pass any multi-dim numpy array (the conversion to arrow has been added on our side), but not for lists of multi-dim numpy arrays.
In this PR I added two strategies:
- one that takes a list of multi-dim numpy arrays on returns an arrow array in an optimized way (more common case)
- one that takes a list of possibly very nested data (lists, dicts, tuples) containing multi-dim arrays. This one is less optimized since it converts all the multi-dim numpy arrays into lists of 1-d arrays for compatibility with arrow. This strategy is simpler that just trying to create the arrow array from a possibly very nested data structure, but in the future we can improve it if needed.
Fix https://github.com/huggingface/datasets/issues/2921 | https://api.github.com/repos/huggingface/datasets/issues/2922/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2921 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2921/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2921/comments | https://api.github.com/repos/huggingface/datasets/issues/2921/events | https://github.com/huggingface/datasets/issues/2921 | 997,325,424 | I_kwDODunzps47cfpw | 2,921 | Using a list of multi-dim numpy arrays raises an error "can only convert 1-dimensional array values" | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,725,931,000 | 1,631,726,505,000 | 1,631,726,505,000 | MEMBER | null | null | This error has been introduced in https://github.com/huggingface/datasets/pull/2361
To reproduce:
```python
import numpy as np
from datasets import Dataset
d = Dataset.from_dict({"a": [np.zeros((2, 2))]})
```
raises
```python
Traceback (most recent call last):
File "playground/ttest.py", line 5, in <module>
d = Dataset.from_dict({"a": [np.zeros((2, 2))]}).with_format("torch")
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_dataset.py", line 458, in from_dict
pa_table = InMemoryTable.from_pydict(mapping=mapping)
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 365, in from_pydict
return cls(pa.Table.from_pydict(*args, **kwargs))
File "pyarrow/table.pxi", line 1639, in pyarrow.lib.Table.from_pydict
File "pyarrow/array.pxi", line 332, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 223, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_writer.py", line 107, in __arrow_array__
out = pa.array(self.data, type=type)
File "pyarrow/array.pxi", line 306, in pyarrow.lib.array
File "pyarrow/array.pxi", line 39, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 143, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 99, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Can only convert 1-dimensional array values | https://api.github.com/repos/huggingface/datasets/issues/2921/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2920 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2920/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2920/comments | https://api.github.com/repos/huggingface/datasets/issues/2920/events | https://github.com/huggingface/datasets/pull/2920 | 997,323,014 | PR_kwDODunzps4ry4_u | 2,920 | Fix unwanted tqdm bar when accessing examples | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,725,751,000 | 1,631,726,304,000 | 1,631,726,304,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2920",
"html_url": "https://github.com/huggingface/datasets/pull/2920",
"diff_url": "https://github.com/huggingface/datasets/pull/2920.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2920.patch"
} | A change in #2814 added bad progress bars in `map_nested`. Now they're disabled by default
Fix #2919 | https://api.github.com/repos/huggingface/datasets/issues/2920/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2919 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2919/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2919/comments | https://api.github.com/repos/huggingface/datasets/issues/2919/events | https://github.com/huggingface/datasets/issues/2919 | 997,127,487 | I_kwDODunzps47bvU_ | 2,919 | Unwanted progress bars when accessing examples | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"doing a patch release now :)"
] | 1,631,714,710,000 | 1,631,726,509,000 | 1,631,726,303,000 | MEMBER | null | null | When accessing examples from a dataset formatted for pytorch, some progress bars appear when accessing examples:
```python
In [1]: import datasets as ds
In [2]: d = ds.Dataset.from_dict({"a": [0, 1, 2]}).with_format("torch")
In [3]: d[0]
100%|████████████████████████████████| 1/1 [00:00<00:00, 3172.70it/s]
Out[3]: {'a': tensor(0)}
```
This is because the pytorch formatter calls `map_nested` that uses progress bars
cc @sgugger | https://api.github.com/repos/huggingface/datasets/issues/2919/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2918/comments | https://api.github.com/repos/huggingface/datasets/issues/2918/events | https://github.com/huggingface/datasets/issues/2918 | 997,063,347 | I_kwDODunzps47bfqz | 2,918 | `Can not decode content-encoding: gzip` when loading `scitldr` dataset with streaming | {
"login": "SBrandeis",
"id": 33657802,
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SBrandeis",
"html_url": "https://github.com/SBrandeis",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3287858981,
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming",
"name": "streaming",
"color": "fef2c0",
"default": false,
"description": ""
}
] | open | false | null | [] | null | [
"Hi @SBrandeis, thanks for reporting! ^^\r\n\r\nI think this is an issue with `fsspec`: https://github.com/intake/filesystem_spec/issues/389\r\n\r\nI will ask them if they are planning to fix it...",
"Code to reproduce the bug: `ClientPayloadError: 400, message='Can not decode content-encoding: gzip'`\r\n```python\r\nIn [1]: import fsspec\r\n\r\nIn [2]: import json\r\n\r\nIn [3]: with fsspec.open('https://raw.githubusercontent.com/allenai/scitldr/master/SciTLDR-Data/SciTLDR-FullText/test.jsonl', encoding=\"utf-8\") as f:\r\n ...: for row in f:\r\n ...: data = json.loads(row)\r\n ...:\r\n---------------------------------------------------------------------------\r\nClientPayloadError Traceback (most recent call last)\r\n```",
"Thanks for investigating @albertvillanova ! 🤗 "
] | 1,631,711,167,000 | 1,632,127,898,000 | null | CONTRIBUTOR | null | null | ## Describe the bug
Trying to load the `"FullText"` config of the `"scitldr"` dataset with `streaming=True` raises an error from `aiohttp`:
```python
ClientPayloadError: 400, message='Can not decode content-encoding: gzip'
```
cc @lhoestq
## Steps to reproduce the bug
```python
from datasets import load_dataset
iter_dset = iter(
load_dataset("scitldr", name="FullText", split="test", streaming=True)
)
next(iter_dset)
```
## Expected results
Returns the first sample of the dataset
## Actual results
Calling `__next__` crashes with the following Traceback:
```python
----> 1 next(dset_iter)
~\miniconda3\envs\datasets\lib\site-packages\datasets\iterable_dataset.py in __iter__(self)
339
340 def __iter__(self):
--> 341 for key, example in self._iter():
342 if self.features:
343 # we encode the example for ClassLabel feature types for example
~\miniconda3\envs\datasets\lib\site-packages\datasets\iterable_dataset.py in _iter(self)
336 else:
337 ex_iterable = self._ex_iterable
--> 338 yield from ex_iterable
339
340 def __iter__(self):
~\miniconda3\envs\datasets\lib\site-packages\datasets\iterable_dataset.py in __iter__(self)
76
77 def __iter__(self):
---> 78 for key, example in self.generate_examples_fn(**self.kwargs):
79 yield key, example
80
~\.cache\huggingface\modules\datasets_modules\datasets\scitldr\72d6e2195786c57e1d343066fb2cc4f93ea39c5e381e53e6ae7c44bbfd1f05ef\scitldr.py in _generate_examples(self, filepath, split)
162
163 with open(filepath, encoding="utf-8") as f:
--> 164 for id_, row in enumerate(f):
165 data = json.loads(row)
166 if self.config.name == "AIC":
~\miniconda3\envs\datasets\lib\site-packages\fsspec\implementations\http.py in read(self, length)
496 else:
497 length = min(self.size - self.loc, length)
--> 498 return super().read(length)
499
500 async def async_fetch_all(self):
~\miniconda3\envs\datasets\lib\site-packages\fsspec\spec.py in read(self, length)
1481 # don't even bother calling fetch
1482 return b""
-> 1483 out = self.cache._fetch(self.loc, self.loc + length)
1484 self.loc += len(out)
1485 return out
~\miniconda3\envs\datasets\lib\site-packages\fsspec\caching.py in _fetch(self, start, end)
378 elif start < self.start:
379 if self.end - end > self.blocksize:
--> 380 self.cache = self.fetcher(start, bend)
381 self.start = start
382 else:
~\miniconda3\envs\datasets\lib\site-packages\fsspec\asyn.py in wrapper(*args, **kwargs)
86 def wrapper(*args, **kwargs):
87 self = obj or args[0]
---> 88 return sync(self.loop, func, *args, **kwargs)
89
90 return wrapper
~\miniconda3\envs\datasets\lib\site-packages\fsspec\asyn.py in sync(loop, func, timeout, *args, **kwargs)
67 raise FSTimeoutError
68 if isinstance(result[0], BaseException):
---> 69 raise result[0]
70 return result[0]
71
~\miniconda3\envs\datasets\lib\site-packages\fsspec\asyn.py in _runner(event, coro, result, timeout)
23 coro = asyncio.wait_for(coro, timeout=timeout)
24 try:
---> 25 result[0] = await coro
26 except Exception as ex:
27 result[0] = ex
~\miniconda3\envs\datasets\lib\site-packages\fsspec\implementations\http.py in async_fetch_range(self, start, end)
538 if r.status == 206:
539 # partial content, as expected
--> 540 out = await r.read()
541 elif "Content-Length" in r.headers:
542 cl = int(r.headers["Content-Length"])
~\miniconda3\envs\datasets\lib\site-packages\aiohttp\client_reqrep.py in read(self)
1030 if self._body is None:
1031 try:
-> 1032 self._body = await self.content.read()
1033 for trace in self._traces:
1034 await trace.send_response_chunk_received(
~\miniconda3\envs\datasets\lib\site-packages\aiohttp\streams.py in read(self, n)
342 async def read(self, n: int = -1) -> bytes:
343 if self._exception is not None:
--> 344 raise self._exception
345
346 # migration problem; with DataQueue you have to catch
ClientPayloadError: 400, message='Can not decode content-encoding: gzip'
```
## Environment info
- `datasets` version: 1.12.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.5
- PyArrow version: 2.0.0
- aiohttp version: 3.7.4.post0
| https://api.github.com/repos/huggingface/datasets/issues/2918/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2917/comments | https://api.github.com/repos/huggingface/datasets/issues/2917/events | https://github.com/huggingface/datasets/issues/2917 | 997,041,658 | I_kwDODunzps47baX6 | 2,917 | windows download abnormal | {
"login": "wei1826676931",
"id": 52347799,
"node_id": "MDQ6VXNlcjUyMzQ3Nzk5",
"avatar_url": "https://avatars.githubusercontent.com/u/52347799?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wei1826676931",
"html_url": "https://github.com/wei1826676931",
"followers_url": "https://api.github.com/users/wei1826676931/followers",
"following_url": "https://api.github.com/users/wei1826676931/following{/other_user}",
"gists_url": "https://api.github.com/users/wei1826676931/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wei1826676931/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wei1826676931/subscriptions",
"organizations_url": "https://api.github.com/users/wei1826676931/orgs",
"repos_url": "https://api.github.com/users/wei1826676931/repos",
"events_url": "https://api.github.com/users/wei1826676931/events{/privacy}",
"received_events_url": "https://api.github.com/users/wei1826676931/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! Is there some kind of proxy that is configured in your browser that gives you access to internet ? If it's the case it could explain why it doesn't work in the code, since the proxy wouldn't be used",
"It is indeed an agency problem, thank you very, very much",
"Let me know if you have other questions :)\r\n\r\nClosing this issue now"
] | 1,631,709,935,000 | 1,631,812,668,000 | 1,631,812,668,000 | NONE | null | null | ## Describe the bug
The script clearly exists (accessible from the browser), but the script download fails on windows. Then I tried it again and it can be downloaded normally on linux. why??
## Steps to reproduce the bug
```python3.7 + windows
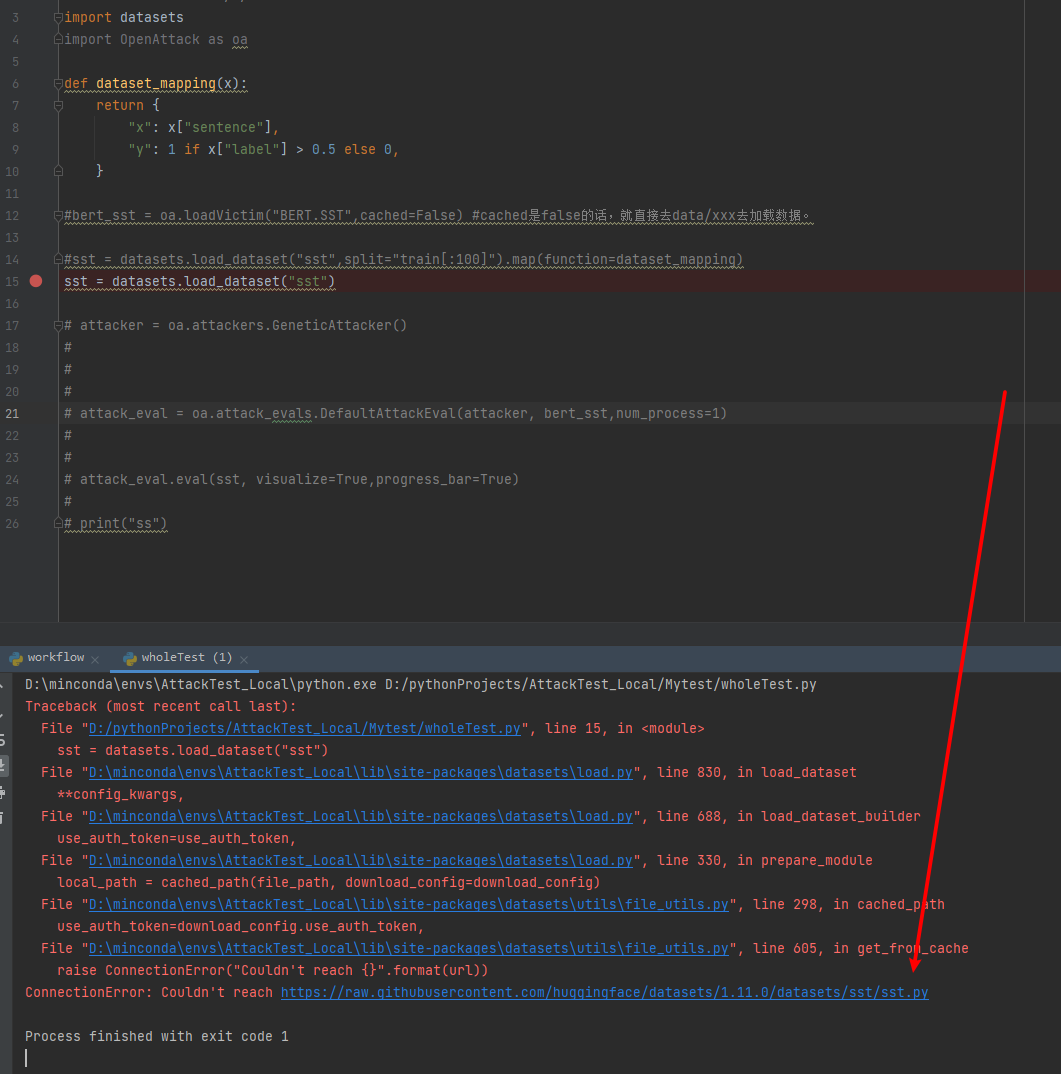
# Sample code to reproduce the bug
```
## Expected results
It can be downloaded normally.
## Actual results
it cann't
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.11.0
- Platform:windows
- Python version:3.7
- PyArrow version:
| https://api.github.com/repos/huggingface/datasets/issues/2917/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2916/comments | https://api.github.com/repos/huggingface/datasets/issues/2916/events | https://github.com/huggingface/datasets/pull/2916 | 997,003,661 | PR_kwDODunzps4rx5ua | 2,916 | Add OpenAI's pass@k code evaluation metric | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"> The implementation makes heavy use of multiprocessing which this PR does not touch. Is this conflicting with multiprocessing natively integrated in datasets?\r\n\r\nIt should work normally, but feel free to test it.\r\nThere is some documentation about using metrics in a distributed setup that uses multiprocessing [here](https://huggingface.co/docs/datasets/loading.html?highlight=rank#distributed-setup)\r\nYou can test to spawn several processes where each process would load the metric. Then in each process you add some references/predictions to the metric. Finally you call compute() in each process and on process 0 it should return the result on all the references/predictions\r\n\r\nLet me know if you have questions or if I can help",
"Is there a good way to debug the Windows tests? I suspect it is an issue with `multiprocessing`, but I can't see the error messages."
] | 1,631,707,543,000 | 1,631,951,964,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2916",
"html_url": "https://github.com/huggingface/datasets/pull/2916",
"diff_url": "https://github.com/huggingface/datasets/pull/2916.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2916.patch"
} | This PR introduces the `code_eval` metric which implements [OpenAI's code evaluation harness](https://github.com/openai/human-eval) introduced in the [Codex paper](https://arxiv.org/abs/2107.03374). It is heavily based on the original implementation and just adapts the interface to follow the `predictions`/`references` convention.
The addition of this metric should enable the evaluation against the code evaluation datasets added in #2897 and #2893.
A few open questions:
- The implementation makes heavy use of multiprocessing which this PR does not touch. Is this conflicting with multiprocessing natively integrated in `datasets`?
- This metric executes generated Python code and as such it poses dangers of executing malicious code. OpenAI addresses this issue by 1) commenting the `exec` call in the code so the user has to actively uncomment it and read the warning and 2) suggests using a sandbox environment (gVisor container). Should we add a similar safeguard? E.g. a prompt that needs to be answered when initialising the metric? Or at least a warning message?
- Naming: the implementation sticks to the `predictions`/`references` naming, however, the references are not reference solutions but unittest to test the solution. While reference solutions are also available they are not used. Should the naming be adapted? | https://api.github.com/repos/huggingface/datasets/issues/2916/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2915 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2915/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2915/comments | https://api.github.com/repos/huggingface/datasets/issues/2915/events | https://github.com/huggingface/datasets/pull/2915 | 996,870,071 | PR_kwDODunzps4rxfWb | 2,915 | Fix fsspec AbstractFileSystem access | {
"login": "pierre-godard",
"id": 3969168,
"node_id": "MDQ6VXNlcjM5NjkxNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3969168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pierre-godard",
"html_url": "https://github.com/pierre-godard",
"followers_url": "https://api.github.com/users/pierre-godard/followers",
"following_url": "https://api.github.com/users/pierre-godard/following{/other_user}",
"gists_url": "https://api.github.com/users/pierre-godard/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pierre-godard/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pierre-godard/subscriptions",
"organizations_url": "https://api.github.com/users/pierre-godard/orgs",
"repos_url": "https://api.github.com/users/pierre-godard/repos",
"events_url": "https://api.github.com/users/pierre-godard/events{/privacy}",
"received_events_url": "https://api.github.com/users/pierre-godard/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,698,760,000 | 1,631,705,724,000 | 1,631,705,724,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2915",
"html_url": "https://github.com/huggingface/datasets/pull/2915",
"diff_url": "https://github.com/huggingface/datasets/pull/2915.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2915.patch"
} | This addresses the issue from #2914 by changing the way fsspec's AbstractFileSystem is accessed. | https://api.github.com/repos/huggingface/datasets/issues/2915/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2914 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2914/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2914/comments | https://api.github.com/repos/huggingface/datasets/issues/2914/events | https://github.com/huggingface/datasets/issues/2914 | 996,770,168 | I_kwDODunzps47aYF4 | 2,914 | Having a dependency defining fsspec entrypoint raises an AttributeError when importing datasets | {
"login": "pierre-godard",
"id": 3969168,
"node_id": "MDQ6VXNlcjM5NjkxNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3969168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pierre-godard",
"html_url": "https://github.com/pierre-godard",
"followers_url": "https://api.github.com/users/pierre-godard/followers",
"following_url": "https://api.github.com/users/pierre-godard/following{/other_user}",
"gists_url": "https://api.github.com/users/pierre-godard/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pierre-godard/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pierre-godard/subscriptions",
"organizations_url": "https://api.github.com/users/pierre-godard/orgs",
"repos_url": "https://api.github.com/users/pierre-godard/repos",
"events_url": "https://api.github.com/users/pierre-godard/events{/privacy}",
"received_events_url": "https://api.github.com/users/pierre-godard/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Closed by #2915."
] | 1,631,692,446,000 | 1,631,724,557,000 | 1,631,724,556,000 | CONTRIBUTOR | null | null | ## Describe the bug
In one of my project, I defined a custom fsspec filesystem with an entrypoint.
My guess is that by doing so, a variable named `spec` is created in the module `fsspec` (created by entering a for loop as there are entrypoints defined, see the loop in question [here](https://github.com/intake/filesystem_spec/blob/0589358d8a029ed6b60d031018f52be2eb721291/fsspec/__init__.py#L55)).
So that `fsspec.spec`, that was previously referring to the `spec` submodule, is now referring to that `spec` variable.
This make the import of datasets failing as it is using that `fsspec.spec`.
## Steps to reproduce the bug
I could reproduce the bug with a dummy poetry project.
Here is the pyproject.toml:
```toml
[tool.poetry]
name = "debug-datasets"
version = "0.1.0"
description = ""
authors = ["Pierre Godard"]
[tool.poetry.dependencies]
python = "^3.8"
datasets = "^1.11.0"
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
[tool.poetry.plugins."fsspec.specs"]
"file2" = "fsspec.implementations.local.LocalFileSystem"
```
The only other file being a `debug_datasets/__init__.py` empty file.
The overall structure of the project is as follows:
```
.
├── pyproject.toml
└── debug_datasets
└── __init__.py
```
Then, within the project folder run:
```
poetry install
poetry run python
```
And in the python interpreter, try to import `datasets`:
```
import datasets
```
## Expected results
The import should run successfully.
## Actual results
Here is the trace of the error I get:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/godarpi/.cache/pypoetry/virtualenvs/debug-datasets-JuFzTKL--py3.8/lib/python3.8/site-packages/datasets/__init__.py", line 33, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/godarpi/.cache/pypoetry/virtualenvs/debug-datasets-JuFzTKL--py3.8/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 48, in <module>
from .filesystems import extract_path_from_uri, is_remote_filesystem
File "/home/godarpi/.cache/pypoetry/virtualenvs/debug-datasets-JuFzTKL--py3.8/lib/python3.8/site-packages/datasets/filesystems/__init__.py", line 30, in <module>
def is_remote_filesystem(fs: fsspec.spec.AbstractFileSystem) -> bool:
AttributeError: 'EntryPoint' object has no attribute 'AbstractFileSystem'
```
## Suggested fix
`datasets/filesystems/__init__.py`, line 30, replace:
```
def is_remote_filesystem(fs: fsspec.spec.AbstractFileSystem) -> bool:
```
by:
```
def is_remote_filesystem(fs: fsspec.AbstractFileSystem) -> bool:
```
I will come up with a PR soon if this effectively solves the issue.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: WSL2 (Ubuntu 20.04.1 LTS)
- Python version: 3.8.5
- PyArrow version: 5.0.0
- `fsspec` version: 2021.8.1
| https://api.github.com/repos/huggingface/datasets/issues/2914/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2913 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2913/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2913/comments | https://api.github.com/repos/huggingface/datasets/issues/2913/events | https://github.com/huggingface/datasets/issues/2913 | 996,436,368 | I_kwDODunzps47ZGmQ | 2,913 | timit_asr dataset only includes one text phrase | {
"login": "margotwagner",
"id": 39107794,
"node_id": "MDQ6VXNlcjM5MTA3Nzk0",
"avatar_url": "https://avatars.githubusercontent.com/u/39107794?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/margotwagner",
"html_url": "https://github.com/margotwagner",
"followers_url": "https://api.github.com/users/margotwagner/followers",
"following_url": "https://api.github.com/users/margotwagner/following{/other_user}",
"gists_url": "https://api.github.com/users/margotwagner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/margotwagner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/margotwagner/subscriptions",
"organizations_url": "https://api.github.com/users/margotwagner/orgs",
"repos_url": "https://api.github.com/users/margotwagner/repos",
"events_url": "https://api.github.com/users/margotwagner/events{/privacy}",
"received_events_url": "https://api.github.com/users/margotwagner/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @margotwagner, \r\nThis bug was fixed in #1995. Upgrading the datasets should work (min v1.8.0 ideally)",
"Hi @margotwagner,\r\n\r\nYes, as @bhavitvyamalik has commented, this bug was fixed in `datasets` version 1.5.0. You need to update it, as your current version is 1.4.1:\r\n> Environment info\r\n> - `datasets` version: 1.4.1"
] | 1,631,653,567,000 | 1,631,693,119,000 | 1,631,693,118,000 | NONE | null | null | ## Describe the bug
The dataset 'timit_asr' only includes one text phrase. It only includes the transcription "Would such an act of refusal be useful?" multiple times rather than different phrases.
## Steps to reproduce the bug
Note: I am following the tutorial https://huggingface.co/blog/fine-tune-wav2vec2-english
1. Install the dataset and other packages
```python
!pip install datasets>=1.5.0
!pip install transformers==4.4.0
!pip install soundfile
!pip install jiwer
```
2. Load the dataset
```python
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
```
3. Remove columns that we don't want
```python
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
```
4. Write a short function to display some random samples of the dataset.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file"]))
```
## Expected results
10 random different transcription phrases.
## Actual results
10 of the same transcription phrase "Would such an act of refusal be useful?"
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.4.1
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: not listed
| https://api.github.com/repos/huggingface/datasets/issues/2913/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2912 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2912/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2912/comments | https://api.github.com/repos/huggingface/datasets/issues/2912/events | https://github.com/huggingface/datasets/pull/2912 | 996,256,005 | PR_kwDODunzps4rvhgp | 2,912 | Update link to Blog in docs footer | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,640,194,000 | 1,631,692,763,000 | 1,631,692,763,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2912",
"html_url": "https://github.com/huggingface/datasets/pull/2912",
"diff_url": "https://github.com/huggingface/datasets/pull/2912.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2912.patch"
} | Update link. | https://api.github.com/repos/huggingface/datasets/issues/2912/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2911 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2911/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2911/comments | https://api.github.com/repos/huggingface/datasets/issues/2911/events | https://github.com/huggingface/datasets/pull/2911 | 996,202,598 | PR_kwDODunzps4rvW7Y | 2,911 | Fix exception chaining | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,636,369,000 | 1,631,804,684,000 | 1,631,804,684,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2911",
"html_url": "https://github.com/huggingface/datasets/pull/2911",
"diff_url": "https://github.com/huggingface/datasets/pull/2911.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2911.patch"
} | Fix exception chaining to avoid tracebacks with message: `During handling of the above exception, another exception occurred:` | https://api.github.com/repos/huggingface/datasets/issues/2911/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2910 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2910/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2910/comments | https://api.github.com/repos/huggingface/datasets/issues/2910/events | https://github.com/huggingface/datasets/pull/2910 | 996,149,632 | PR_kwDODunzps4rvL9N | 2,910 | feat: 🎸 pass additional arguments to get private configs + info | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Included in https://github.com/huggingface/datasets/pull/2906"
] | 1,631,633,059,000 | 1,631,722,749,000 | 1,631,722,746,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2910",
"html_url": "https://github.com/huggingface/datasets/pull/2910",
"diff_url": "https://github.com/huggingface/datasets/pull/2910.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2910.patch"
} | `use_auth_token` can now be passed to the functions to get the configs
or infos of private datasets on the hub | https://api.github.com/repos/huggingface/datasets/issues/2910/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2909 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2909/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2909/comments | https://api.github.com/repos/huggingface/datasets/issues/2909/events | https://github.com/huggingface/datasets/pull/2909 | 996,002,180 | PR_kwDODunzps4rutdo | 2,909 | fix anli splits | {
"login": "zaidalyafeai",
"id": 15667714,
"node_id": "MDQ6VXNlcjE1NjY3NzE0",
"avatar_url": "https://avatars.githubusercontent.com/u/15667714?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zaidalyafeai",
"html_url": "https://github.com/zaidalyafeai",
"followers_url": "https://api.github.com/users/zaidalyafeai/followers",
"following_url": "https://api.github.com/users/zaidalyafeai/following{/other_user}",
"gists_url": "https://api.github.com/users/zaidalyafeai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zaidalyafeai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zaidalyafeai/subscriptions",
"organizations_url": "https://api.github.com/users/zaidalyafeai/orgs",
"repos_url": "https://api.github.com/users/zaidalyafeai/repos",
"events_url": "https://api.github.com/users/zaidalyafeai/events{/privacy}",
"received_events_url": "https://api.github.com/users/zaidalyafeai/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,631,625,035,000 | 1,631,625,035,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2909",
"html_url": "https://github.com/huggingface/datasets/pull/2909",
"diff_url": "https://github.com/huggingface/datasets/pull/2909.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2909.patch"
} | I can't run the tests for dummy data, facing this error
`ImportError while loading conftest '/home/zaid/tmp/fix_anli_splits/datasets/tests/conftest.py'.
tests/conftest.py:10: in <module>
from datasets import config
E ImportError: cannot import name 'config' from 'datasets' (unknown location)` | https://api.github.com/repos/huggingface/datasets/issues/2909/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2908 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2908/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2908/comments | https://api.github.com/repos/huggingface/datasets/issues/2908/events | https://github.com/huggingface/datasets/pull/2908 | 995,970,612 | PR_kwDODunzps4rumwW | 2,908 | Update Zenodo metadata with creator names and affiliation | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,623,177,000 | 1,631,629,765,000 | 1,631,629,765,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2908",
"html_url": "https://github.com/huggingface/datasets/pull/2908",
"diff_url": "https://github.com/huggingface/datasets/pull/2908.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2908.patch"
} | This PR helps in prefilling author data when automatically generating the DOI after each release. | https://api.github.com/repos/huggingface/datasets/issues/2908/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2907 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2907/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2907/comments | https://api.github.com/repos/huggingface/datasets/issues/2907/events | https://github.com/huggingface/datasets/pull/2907 | 995,968,152 | PR_kwDODunzps4rumOy | 2,907 | add story_cloze dataset | {
"login": "zaidalyafeai",
"id": 15667714,
"node_id": "MDQ6VXNlcjE1NjY3NzE0",
"avatar_url": "https://avatars.githubusercontent.com/u/15667714?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zaidalyafeai",
"html_url": "https://github.com/zaidalyafeai",
"followers_url": "https://api.github.com/users/zaidalyafeai/followers",
"following_url": "https://api.github.com/users/zaidalyafeai/following{/other_user}",
"gists_url": "https://api.github.com/users/zaidalyafeai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zaidalyafeai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zaidalyafeai/subscriptions",
"organizations_url": "https://api.github.com/users/zaidalyafeai/orgs",
"repos_url": "https://api.github.com/users/zaidalyafeai/repos",
"events_url": "https://api.github.com/users/zaidalyafeai/events{/privacy}",
"received_events_url": "https://api.github.com/users/zaidalyafeai/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,631,623,013,000 | 1,631,623,013,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2907",
"html_url": "https://github.com/huggingface/datasets/pull/2907",
"diff_url": "https://github.com/huggingface/datasets/pull/2907.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2907.patch"
} | @lhoestq I have spent some time but I still I can't succeed in correctly testing the dummy_data. | https://api.github.com/repos/huggingface/datasets/issues/2907/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2906 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2906/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2906/comments | https://api.github.com/repos/huggingface/datasets/issues/2906/events | https://github.com/huggingface/datasets/pull/2906 | 995,962,905 | PR_kwDODunzps4rulH- | 2,906 | feat: 🎸 add a function to get a dataset config's split names | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"> Should I add a section in https://github.com/huggingface/datasets/blob/master/docs/source/load_hub.rst? (there is no section for get_dataset_infos)\r\n\r\nYes totally :) This tutorial should indeed mention this, given how fundamental it is"
] | 1,631,622,682,000 | 1,632,155,739,000 | null | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2906",
"html_url": "https://github.com/huggingface/datasets/pull/2906",
"diff_url": "https://github.com/huggingface/datasets/pull/2906.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2906.patch"
} | Also: pass additional arguments (use_auth_token) to get private configs + info of private datasets on the hub
Questions:
- <strike>I'm not sure how the versions work: I changed 1.12.1.dev0 to 1.12.1.dev1, was it correct?</strike> no -> reverted
- Should I add a section in https://github.com/huggingface/datasets/blob/master/docs/source/load_hub.rst? (there is no section for get_dataset_infos) | https://api.github.com/repos/huggingface/datasets/issues/2906/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2905 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2905/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2905/comments | https://api.github.com/repos/huggingface/datasets/issues/2905/events | https://github.com/huggingface/datasets/pull/2905 | 995,843,964 | PR_kwDODunzps4ruL5X | 2,905 | Update BibTeX entry | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,631,614,577,000 | 1,631,622,337,000 | 1,631,622,337,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2905",
"html_url": "https://github.com/huggingface/datasets/pull/2905",
"diff_url": "https://github.com/huggingface/datasets/pull/2905.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2905.patch"
} | Update BibTeX entry. | https://api.github.com/repos/huggingface/datasets/issues/2905/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2904 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2904/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2904/comments | https://api.github.com/repos/huggingface/datasets/issues/2904/events | https://github.com/huggingface/datasets/issues/2904 | 995,814,222 | I_kwDODunzps47WutO | 2,904 | FORCE_REDOWNLOAD does not work | {
"login": "anoopkatti",
"id": 5278299,
"node_id": "MDQ6VXNlcjUyNzgyOTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/5278299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anoopkatti",
"html_url": "https://github.com/anoopkatti",
"followers_url": "https://api.github.com/users/anoopkatti/followers",
"following_url": "https://api.github.com/users/anoopkatti/following{/other_user}",
"gists_url": "https://api.github.com/users/anoopkatti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anoopkatti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anoopkatti/subscriptions",
"organizations_url": "https://api.github.com/users/anoopkatti/orgs",
"repos_url": "https://api.github.com/users/anoopkatti/repos",
"events_url": "https://api.github.com/users/anoopkatti/events{/privacy}",
"received_events_url": "https://api.github.com/users/anoopkatti/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! Thanks for reporting. The error seems to happen only if you use compressed files.\r\n\r\nThe second dataset is prepared in another dataset cache directory than the first - which is normal, since the source file is different. However, it doesn't uncompress the new data file because it finds the old uncompressed data in the extraction cache directory.\r\n\r\nIf we fix the extraction cache mechanism to uncompress a local file if it changed then it should fix the issue.\r\nCurrently the extraction cache mechanism only takes into account the path of the compressed file, which is an issue."
] | 1,631,612,726,000 | 1,632,129,275,000 | null | NONE | null | null | ## Describe the bug
With GenerateMode.FORCE_REDOWNLOAD, the documentation says
+------------------------------------+-----------+---------+
| | Downloads | Dataset |
+====================================+===========+=========+
| `REUSE_DATASET_IF_EXISTS` (default)| Reuse | Reuse |
+------------------------------------+-----------+---------+
| `REUSE_CACHE_IF_EXISTS` | Reuse | Fresh |
+------------------------------------+-----------+---------+
| `FORCE_REDOWNLOAD` | Fresh | Fresh |
+------------------------------------+-----------+---------+
However, the old dataset is loaded even when FORCE_REDOWNLOAD is chosen.
## Steps to reproduce the bug
```python
import pandas as pd
from datasets import load_dataset, GenerateMode
pd.DataFrame(range(5), columns=['numbers']).to_csv('/tmp/test.tsv.gz', index=False)
ee = load_dataset('csv', data_files=['/tmp/test.tsv.gz'], delimiter='\t', split='train', download_mode=GenerateMode.FORCE_REDOWNLOAD)
print(ee)
pd.DataFrame(range(10), columns=['numerals']).to_csv('/tmp/test.tsv.gz', index=False)
ee = load_dataset('csv', data_files=['/tmp/test.tsv.gz'], delimiter='\t', split='train', download_mode=GenerateMode.FORCE_REDOWNLOAD)
print(ee)
```
## Expected results
Dataset({
features: ['numbers'],
num_rows: 5
})
Dataset({
features: ['numerals'],
num_rows: 10
})
## Actual results
Dataset({
features: ['numbers'],
num_rows: 5
})
Dataset({
features: ['numbers'],
num_rows: 5
})
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: Linux-4.14.181-108.257.amzn1.x86_64-x86_64-with-glibc2.10
- Python version: 3.7.10
- PyArrow version: 3.0.0
| https://api.github.com/repos/huggingface/datasets/issues/2904/timeline | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2903 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2903/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2903/comments | https://api.github.com/repos/huggingface/datasets/issues/2903/events | https://github.com/huggingface/datasets/pull/2903 | 995,715,191 | PR_kwDODunzps4rtxxV | 2,903 | Fix xpathopen to accept positional arguments | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"thanks!"
] | 1,631,606,570,000 | 1,631,609,481,000 | 1,631,608,847,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2903",
"html_url": "https://github.com/huggingface/datasets/pull/2903",
"diff_url": "https://github.com/huggingface/datasets/pull/2903.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/2903.patch"
} | Fix `xpathopen()` so that it also accepts positional arguments.
Fix #2901. | https://api.github.com/repos/huggingface/datasets/issues/2903/timeline | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2902 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2902/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2902/comments | https://api.github.com/repos/huggingface/datasets/issues/2902/events | https://github.com/huggingface/datasets/issues/2902 | 995,254,216 | MDU6SXNzdWU5OTUyNTQyMTY= | 2,902 | Add WIT Dataset | {
"login": "nateraw",
"id": 32437151,
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nateraw",
"html_url": "https://github.com/nateraw",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"repos_url": "https://api.github.com/users/nateraw/repos",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"@hassiahk is working on it #2810 ",
"WikiMedia is now hosting the pixel values directly which should make it a lot easier!\r\nThe files can be found here:\r\nhttps://techblog.wikimedia.org/2021/09/09/the-wikipedia-image-caption-matching-challenge-and-a-huge-release-of-image-data-for-research/\r\nhttps://analytics.wikimedia.org/published/datasets/one-off/caption_competition/training/image_pixels/",
"> @hassiahk is working on it #2810\r\n\r\nThank you @bhavitvyamalik! Added this issue so we could track progress 😄 . Just linked the PR as well for visibility. "
] | 1,631,561,929,000 | 1,631,567,400,000 | null | CONTRIBUTOR | null | null | ## Adding a Dataset
- **Name:** *WIT*
- **Description:** *Wikipedia-based Image Text Dataset*
- **Paper:** *[WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
](https://arxiv.org/abs/2103.01913)*
- **Data:** *https://github.com/google-research-datasets/wit*
- **Motivation:** (excerpt from their Github README.md)
> - The largest multimodal dataset (publicly available at the time of this writing) by the number of image-text examples.
> - A massively multilingual dataset (first of its kind) with coverage for over 100+ languages.
> - A collection of diverse set of concepts and real world entities.
> - Brings forth challenging real-world test sets.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| https://api.github.com/repos/huggingface/datasets/issues/2902/timeline | null | false |
Dataset Card for GitHub Issues
Dataset Summary
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.
Supported Tasks and Leaderboards
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the task-category-tag with an appropriate other:other-task-name).
task-category-tag: The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a high/low metric name. The (model name or model class) model currently achieves the following score. [IF A LEADERBOARD IS AVAILABLE]: This task has an active leaderboard which can be found at leaderboard url and ranks models based on metric name while also reporting other metric name.
Languages
Provide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...
When relevant, please provide BCP-47 codes, which consist of a primary language subtag, with a script subtag and/or region subtag if available.
Dataset Structure
Data Instances
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
{
'example_field': ...,
...
}
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
Data Fields
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
example_field: description ofexample_field
Note that the descriptions can be initialized with the Show Markdown Data Fields output of the tagging app, you will then only need to refine the generated descriptions.
Data Splits
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
| Tain | Valid | Test | |
|---|---|---|---|
| Input Sentences | |||
| Average Sentence Length |
Dataset Creation
Curation Rationale
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
Source Data
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
Initial Data Collection and Normalization
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their Hugging Face version.
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
Who are the source language producers?
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
Annotations
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
Annotation process
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
Who are the annotators?
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Personal and Sensitive Information
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See Larson 2017 for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
Considerations for Using the Data
Social Impact of Dataset
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
Discussion of Biases
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example Dinan et al 2020 on biases in Wikipedia (esp. Table 1), or Blodgett et al 2020 for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
Other Known Limitations
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
Additional Information
Dataset Curators
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
Licensing Information
Provide the license and link to the license webpage if available.
Citation Information
Provide the BibTex-formatted reference for the dataset. For example:
@article{article_id,
author = {Author List},
title = {Dataset Paper Title},
journal = {Publication Venue},
year = {2525}
}
If the dataset has a DOI, please provide it here.
Contributions
Thanks to @lewtun for adding this dataset.
- Downloads last month
- 322