
datasetId
stringlengths 5
121
| author
stringlengths 2
42
| last_modified
unknown | downloads
int64 0
2.63M
| likes
int64 0
6.49k
| tags
sequencelengths 1
7.92k
| task_categories
sequencelengths 0
47
⌀ | createdAt
unknown | card
stringlengths 15
1M
|
|---|---|---|---|---|---|---|---|---|
jiddykwon/sf_data | jiddykwon | "2024-12-06T03:58:25Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T03:49:53Z" | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
- name: input
dtype: string
splits:
- name: train
num_bytes: 500673
num_examples: 1725
download_size: 67919
dataset_size: 500673
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mlfoundations-dev/oh_v1.2_alpaca_x.5 | mlfoundations-dev | "2024-12-06T05:26:20Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T04:47:03Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: shard_id
dtype: string
splits:
- name: train
num_bytes: 1632358254
num_examples: 859777
download_size: 882984880
dataset_size: 1632358254
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
DT4LM/gp_sst2_clare_differential | DT4LM | "2024-12-09T07:41:15Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T05:04:35Z" | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int32
splits:
- name: train
num_bytes: 13475.948881789138
num_examples: 204
download_size: 15329
dataset_size: 13475.948881789138
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
DT4LM/gp_sst2_faster-alzantot_differential_original | DT4LM | "2024-12-09T08:20:16Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T05:07:56Z" | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int32
splits:
- name: train
num_bytes: 19554
num_examples: 247
download_size: 15227
dataset_size: 19554
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
kanakapriya/phi3_796_nontrunc | kanakapriya | "2024-12-06T07:15:20Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T07:15:03Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 3548659
num_examples: 636
- name: test
num_bytes: 879056
num_examples: 160
download_size: 2105327
dataset_size: 4427715
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
Quinn777/AtomMATH-SFT | Quinn777 | "2024-12-06T08:29:43Z" | 8 | 0 | [
"license:apache-2.0",
"region:us"
] | null | "2024-12-06T08:29:43Z" | ---
license: apache-2.0
---
|
kapsb2171/eng-hin-500-consistent | kapsb2171 | "2024-12-06T15:03:19Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T08:53:04Z" | ---
dataset_info:
features:
- name: translation
struct:
- name: en
dtype: string
- name: hi
dtype: string
splits:
- name: train
num_bytes: 588934
num_examples: 400
- name: validation
num_bytes: 163417
num_examples: 100
download_size: 309545
dataset_size: 752351
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
mlfoundations-dev/oh_v1.2_slim_orca_x.25 | mlfoundations-dev | "2024-12-06T08:54:12Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T08:53:19Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: shard_id
dtype: string
splits:
- name: train
num_bytes: 943141308.0
num_examples: 498381
download_size: 493821964
dataset_size: 943141308.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
kowndinya23/flan2022-zeroshot-instr-inpt-outp-25000 | kowndinya23 | "2024-12-06T09:01:40Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T09:01:37Z" | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 24667039
num_examples: 25000
- name: validation
num_bytes: 1723020
num_examples: 1806
download_size: 11471934
dataset_size: 26390059
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
modeltrainer1/finetuning_demo | modeltrainer1 | "2024-12-06T10:11:24Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T10:11:22Z" | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 14235
num_examples: 34
download_size: 5477
dataset_size: 14235
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
dreamyou/ta | dreamyou | "2024-12-06T10:58:49Z" | 8 | 0 | [
"task_categories:image-segmentation",
"region:us",
"roboflow",
"roboflow2huggingface"
] | [
"image-segmentation"
] | "2024-12-06T10:43:30Z" | ---
task_categories:
- image-segmentation
tags:
- roboflow
- roboflow2huggingface
---
<div align="center">
<img width="640" alt="dreamyou/ta" src="https://huggingface.co/datasets/dreamyou/ta/resolve/main/thumbnail.jpg">
</div>
### Dataset Labels
```
['melon']
```
### Number of Images
```json
{'valid': 100, 'test': 100, 'train': 400}
```
### How to Use
- Install [datasets](https://pypi.org/project/datasets/):
```bash
pip install datasets
```
- Load the dataset:
```python
from datasets import load_dataset
ds = load_dataset("dreamyou/ta", name="full")
example = ds['train'][0]
```
### Roboflow Dataset Page
[https://universe.roboflow.com/fifialfi/skripsi2-wb4wo/dataset/1](https://universe.roboflow.com/fifialfi/skripsi2-wb4wo/dataset/1?ref=roboflow2huggingface)
### Citation
```
@misc{
skripsi2-wb4wo_dataset,
title = { Skripsi2 Dataset },
type = { Open Source Dataset },
author = { fifialfi },
howpublished = { \\url{ https://universe.roboflow.com/fifialfi/skripsi2-wb4wo } },
url = { https://universe.roboflow.com/fifialfi/skripsi2-wb4wo },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2024 },
month = { oct },
note = { visited on 2024-12-06 },
}
```
### License
CC BY 4.0
### Dataset Summary
This dataset was exported via roboflow.com on October 17, 2024 at 9:17 AM GMT
Roboflow is an end-to-end computer vision platform that helps you
* collaborate with your team on computer vision projects
* collect & organize images
* understand and search unstructured image data
* annotate, and create datasets
* export, train, and deploy computer vision models
* use active learning to improve your dataset over time
For state of the art Computer Vision training notebooks you can use with this dataset,
visit https://github.com/roboflow/notebooks
To find over 100k other datasets and pre-trained models, visit https://universe.roboflow.com
The dataset includes 600 images.
Melon are annotated in COCO format.
The following pre-processing was applied to each image:
* Resize to 640x640 (Stretch)
No image augmentation techniques were applied.
|
vedikap11/school_projj | vedikap11 | "2024-12-06T10:58:36Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T10:58:32Z" | ---
dataset_info:
features:
- name: Context
dtype: string
- name: Response
dtype: string
splits:
- name: train
num_bytes: 1643
num_examples: 5
download_size: 4090
dataset_size: 1643
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
sumuks/fairytales_single_shot_questions | sumuks | "2024-12-06T12:18:30Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T12:18:29Z" | ---
dataset_info:
features:
- name: title
dtype: string
- name: summary
dtype: string
- name: chunk
dtype: string
- name: test_audience
dtype: string
- name: document_analysis
dtype: string
- name: question_type
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: estimated_difficulty
dtype: int64
- name: citations
dtype: string
- name: generating_model
dtype: string
splits:
- name: train
num_bytes: 13628807
num_examples: 2603
download_size: 3350848
dataset_size: 13628807
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
feedbackagent/llama3_8b_reflection1 | feedbackagent | "2024-12-06T12:43:44Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T12:43:12Z" | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: gt
dtype: string
- name: my_solu
dtype: string
- name: old_solu
dtype: string
splits:
- name: train
num_bytes: 2711102709
num_examples: 597952
download_size: 788967540
dataset_size: 2711102709
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
feedbackagent/llama3_8b_reflection2 | feedbackagent | "2024-12-06T12:46:14Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T12:45:34Z" | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: gt
dtype: string
- name: my_solu
dtype: string
- name: old_solu
dtype: string
splits:
- name: train
num_bytes: 3169596544
num_examples: 523208
download_size: 911054340
dataset_size: 3169596544
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
alleina/Real-Estate-Property-Image-Dataset-Lamudi-Facebook-Ohmyhome-PerchanceAI | alleina | "2024-12-06T15:52:31Z" | 8 | 0 | [
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"region:us",
"lamudi",
"facebook",
"ohmyhomes",
"real-estate-property",
"real-estate",
"real-estate-properties",
"AI-generated-real-estate-properties",
"watermarked-dataset",
"watermarked-real-estate-properties",
"real-estate-images"
] | null | "2024-12-06T14:30:38Z" | ---
license: apache-2.0
language:
- en
tags:
- lamudi
- facebook
- ohmyhomes
- real-estate-property
- real-estate
- real-estate-properties
- AI-generated-real-estate-properties
- watermarked-dataset
- watermarked-real-estate-properties
- real-estate-images
size_categories:
- 1K<n<10K
---
## Real Estate Property Dataset
**Overview**
This dataset is designed to train and evaluate a fraud filter system and image matching system for real estate properties. It comprises a diverse range of real estate images, including authentic images and AI-generated images.
**Dataset Composition**
1. **AI-Generated Images:**
* **Source:** Perchance AI
* **Generation Process:**
- A diverse set of properties was generated using Gemini AI, covering various property types, architectural styles, and features.
- Gemini AI generated a dataset for each property type by randomly choosing from various sets of architectural styles, property categories (interior/exterior), and feature names (e.g., bedroom, facade):
- **Property Types (11):** Condominium, House and Lot, Townhouse, Apartment, Bungalow, Villa, Office Space, Industrial Space, Commercial Lot, Land, Farm, Hotel
- **Architectural Styles (10):** Colonial, Victorian, Tudor, Ranch, Cape Cod, Mediterranean, Modern, Contemporary, Industrial, Rustic
- **Property Categories (2):** Interior, Exterior
- **Interior Features (13):** Living Room, Dining Room, Kitchen, Bedrooms, Bathrooms, Hallways, Stairs, Basement, Attic, Closet, Pantry, Laundry Room, Family Room, Office
- **Exterior Features (14):** Lot, Facade, Roof, Windows, Doors, Porch, Patio, Deck, Balcony, Garage, Driveway, Landscaping, Fence
- Image descriptions were created based on these properties.
- Perchance AI was used to generate images based on these descriptions.
* **Data Format:** CSV file containing:
- `ID`
- `Image Description`
- `Image Title`
- `Property Type`
- `Architectural Style`
- `Property Category`
- `Feature Name`
* **Total Images:** 1000 (training) + 1000 (testing)
2. **Authentic Images:**
* **Source:** Facebook Marketplace
* **Data Collection:** Scraped using Python, Beautiful Soup, and Selenium.
* **Data Format:** CSV file containing:
- `image_paths`
- `title`
- `price`
- `post_url`
- `location`
* **Total Properties:** 1000
* **Total Images:** 8158
3. **Copyrighted Images:**
* **Source:** Lamudi and Ohmyhome
* **Data Collection:** Scraped using Python and Beautiful Soup.
* **Data Types:**
- **No EXIF Data:**
- **Source:** Lamudi
- **Data Format:** CSV file containing:
- `ID`
- `Title`
- `Price`
- `Address`
- `Num_of_Bedrooms`
- `Num_of_Bathrooms`
- `Floor_Area`
- `Description`
- `List_of_Amenities`
- `Image URLs`
- `Property URL`
- **Total Properties:** 1000
- **Total Images:** 3000
- **Watermarked Images:**
- **Source:** Ohmyhome
- **Data Collection:** Python was used to generate watermarked images by adding watermarks to the original images. Watermarks were added randomly in terms of font style, size, case, and location on a contrasting background. Three types of watermarks were created: logo, transparent logo, and text.
- **Data Format:** CSV file containing:
- `Image URL`
- `Developer`
- `Logo URL`
- **Total Images:** 1500 (500 transparent logo, 500 text watermark, 500 logo watermark)
**Ethical Considerations:**
* **Data Privacy:** Sensitive information, such as personal addresses and contact details, was removed from the dataset.
* **Copyright Compliance:** Images were used in accordance with fair use principles and relevant copyright laws.
* **Data Bias:** Efforts were made to ensure a balanced and representative dataset, considering factors like property type, location, and image quality.
This dataset provides a valuable resource for training and evaluating models for real estate image matching and fraud detection. By combining authentic and AI-generated images, the dataset enables the development of robust models that can accurately distinguish between real and fake images and identify potential copyright infringements. |
pxyyy/rlhflow_mixture_scalebio_sampled-nolisa-250k | pxyyy | "2024-12-06T20:22:42Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T15:43:13Z" | ---
dataset_info:
features:
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: conversation_id
dtype: int64
splits:
- name: train
num_bytes: 411716390.5445725
num_examples: 250000
download_size: 160285765
dataset_size: 411716390.5445725
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "rlhflow_mixture_scalebio_sampled-nolisa-600k"
```
weight = {
'SlimOrca': 0.34525978565216064,
'dart-math-uniform': 0.23386941850185394,
'GPT4-LLM-Cleaned': 0.19111572206020355,
'MathInstruct': 0.16642746329307556,
'GPTeacher-General-Instruct': 0.042891550809144974,
'ShareGPT_V3_unfiltered_cleaned_split_no_imsorry': 0.006720397621393204,
'UltraInteract_sft': 0.0042861211113631725,
'WizardLM_evol_instruct_V2_196k': 0.004021201748400927,
'Magicoder-Evol-Instruct-110K': 0.00360115640796721,
'orca-math-word-problems-200k': 0.001807231456041336,
}
```
https://wandb.ai/may_i_kiss_you/bilevel-optimization/runs/fyx1mc5z?nw=nwuserwtysalt
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
sicheng1806/New-energy-power-plant | sicheng1806 | "2024-12-07T08:10:37Z" | 8 | 0 | [
"task_categories:feature-extraction",
"license:openrail",
"size_categories:100M<n<1B",
"region:us"
] | [
"feature-extraction"
] | "2024-12-06T16:10:45Z" | ---
license: openrail
size_categories:
- 100M<n<1B
task_categories:
- feature-extraction
---
## New-energy-power-plant
这个数据集来自2024第十三届认证杯数学中国数学建模国际赛(小美赛)D题的原始数据,稍微转换为csv格式。 |
yxnd150150/uieb_llm | yxnd150150 | "2024-12-06T16:31:40Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T16:31:22Z" | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input_image
dtype: image
- name: ground_truth_image
dtype: image
splits:
- name: train
num_bytes: 107627969.0
num_examples: 700
download_size: 107338962
dataset_size: 107627969.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
AhmedBadawy11/UAE18000 | AhmedBadawy11 | "2024-12-06T18:35:48Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T17:14:24Z" | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: text
dtype: string
splits:
- name: validation
num_bytes: 54591893.0
num_examples: 874
- name: train
num_bytes: 1013988237.2
num_examples: 16320
download_size: 1070319856
dataset_size: 1068580130.2
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: train
path: data/train-*
---
|
Deepri24/Thirukural_EnglishMeaning_Updated.csv | Deepri24 | "2024-12-07T18:30:40Z" | 8 | 0 | [
"license:mit",
"size_categories:1K<n<10K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T17:51:26Z" | ---
license: mit
---
|
thexdk/wiki_ru | thexdk | "2024-12-06T19:02:29Z" | 8 | 0 | [
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T18:58:47Z" | ---
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 8196489373
num_examples: 1097341
download_size: 3983241226
dataset_size: 8196489373
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
amuvarma/audio-in-out-10k_part1 | amuvarma | "2024-12-06T19:38:13Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T19:36:12Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: audio
dtype: audio
- name: answer_audio
dtype: audio
- name: facodec_0
sequence: int64
- name: facodec_1
sequence: int64
- name: facodec_2
sequence: int64
- name: facodec_3
sequence: int64
- name: facodec_4
sequence: int64
- name: facodec_5
sequence: int64
- name: spk_embs
sequence: float64
splits:
- name: train
num_bytes: 4320277178.0
num_examples: 10000
download_size: 3857520470
dataset_size: 4320277178.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
nielsr/gemini-results-2024-11-29 | nielsr | "2024-12-08T11:49:59Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T20:07:16Z" | ---
dataset_info:
features:
- name: arxiv_id
dtype: string
- name: reached_out_link
dtype: string
- name: reached_out_success
dtype: float64
- name: reached_out_note
dtype: string
- name: num_models
dtype: float64
- name: num_datasets
dtype: float64
- name: num_spaces
dtype: float64
- name: title
dtype: string
- name: github
dtype: string
- name: github_stars
dtype: float64
- name: conference_name
dtype: string
- name: upvotes
dtype: int64
- name: num_comments
dtype: int64
- name: github_mention_hf
dtype: float64
- name: has_artifact
dtype: bool
- name: submitted_by
dtype: string
- name: date
dtype: string
- name: gemini_results
struct:
- name: github_url
dtype: string
- name: new_datasets
dtype: string
- name: new_model_checkpoints
dtype: string
- name: note
dtype: string
- name: project_page_url
dtype: string
- name: reaching_out
dtype: string
- name: reasoning
dtype: string
- name: gemini_github_url
dtype: string
- name: gemini_new_datasets
dtype: string
- name: gemini_new_model_checkpoints
dtype: string
- name: gemini_note
dtype: string
- name: gemini_project_page_url
dtype: string
- name: gemini_reaching_out
dtype: string
- name: gemini_reasoning
dtype: string
splits:
- name: train
num_bytes: 11533
num_examples: 3
download_size: 38739
dataset_size: 11533
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ivrejchik/medmcqa-instruction | ivrejchik | "2024-12-06T20:32:08Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T20:31:46Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 100074248
num_examples: 182822
- name: test
num_bytes: 417957
num_examples: 6150
- name: validation
num_bytes: 1491232
num_examples: 4183
download_size: 65245759
dataset_size: 101983437
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
---
|
SharanShivram/latestv2 | SharanShivram | "2024-12-06T22:10:12Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-06T22:01:41Z" | ---
dataset_info:
features:
- name: content
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 2099252
num_examples: 1974
download_size: 779082
dataset_size: 2099252
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
yufan/Preference_Dataset_Merged | yufan | "2024-12-08T02:35:46Z" | 8 | 0 | [
"license:unknown",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T01:40:30Z" | ---
license: unknown
dataset_info:
features:
- name: prompt
dtype: string
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 3228930805
num_examples: 597620
download_size: 1797337660
dataset_size: 3228930805
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
Collect the famous preference dataset, and convert to unified format
The dataset source are:
https://huggingface.co/datasets/lmarena-ai/arena-human-preference-55k
https://huggingface.co/datasets/trl-internal-testing/hh-rlhf-helpful-base-trl-style
https://huggingface.co/datasets/lmsys/mt_bench_human_judgments
https://huggingface.co/datasets/openbmb/UltraFeedback
https://huggingface.co/datasets/allenai/llama-3.1-tulu-3-70b-preference-mixture
|
anthracite-org/pixmo-point-explanations-images | anthracite-org | "2024-12-07T03:24:11Z" | 8 | 1 | [
"task_categories:visual-question-answering",
"language:en",
"license:odc-by",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"visual-question-answering"
] | "2024-12-07T03:06:14Z" | ---
language:
- en
license: odc-by
task_categories:
- visual-question-answering
dataset_info:
features:
- name: image
dtype: image
- name: image_url
dtype: string
- name: image_sha256
dtype: string
- name: question
dtype: string
- name: response
dtype: string
- name: matching_hash
dtype: bool
splits:
- name: train
num_bytes: 17801658654.26
num_examples: 71674
download_size: 19065050774
dataset_size: 17801658654.26
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
Big thanks to Ai2 for releasing the original [PixMo-Point-Explanations](https://huggingface.co/datasets/allenai/pixmo-point-explanations) dataset. To preserve the images and simplify usage of the dataset, we are releasing this version, which includes downloaded images. Note that while some of the images had mismatched hashes after downloading, the vast majority of those still visually match the question/answer pairs, so we decided to leave them in. If you want to, you can filter those out using the `matching_hash` column.
# PixMo-Point-Explanations
PixMo-Point-Explanations is a dataset of images, questions, and answers with explanations that can include in-line points that refer to parts of the image.
It can be used to train vison language models to respond to questions through a mixture of text and points.
PixMo-Point-Explanations is part of the [PixMo dataset collection](https://huggingface.co/collections/allenai/pixmo-674746ea613028006285687b) and was used to train the [Molmo family of models](https://huggingface.co/collections/allenai/molmo-66f379e6fe3b8ef090a8ca19)
We consider this dataset experimental, while these explanations can be very informative we have also seen
models can hallucinate more when generating outputs of this sort.
For that reason, the Molmo models are trained to only generate outputs like this when specifically requested by prefixing input questions with "point_qa:".
This mode can be used in the [Molmo demo](https://multimodal-29mpz7ym.vercel.app/share/2921825e-ef44-49fa-a6cb-1956da0be62a)
Quick links:
- 📃 [Paper](https://molmo.allenai.org/paper.pdf)
- 🎥 [Blog with Videos](https://molmo.allenai.org/blog)
## Loading
```python
data = datasets.load_dataset("anthracite-org/pixmo-point-explanations-images")
```
## Data Format
The in-line points use a format from the LLM/annotators that does not exactly match the Molmo format.
The data includes some fields derived from these responses to make them easier to parse,
these fields can be null if the original response was not parsed.
- `parsed_response` responses with the text "<|POINT|>" where the inline point annotations were
- `alt_text` the alt text for each point annotation in the response
- `inline_text` the inline text for each point annotation in the response
- `points` the list-of-list of points for each point annotation
## License
This dataset is licensed under ODC-BY-1.0. It is intended for research and educational use in accordance with Ai2's [Responsible Use Guidelines](https://allenai.org/responsible-use).
This dataset includes data generated from Claude which are subject to Anthropic [terms of service](https://www.anthropic.com/legal/commercial-terms) and [usage policy](https://www.anthropic.com/legal/aup). |
HappyAIUser/Atcgpt-Fixed2 | HappyAIUser | "2024-12-07T03:52:55Z" | 8 | 0 | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"language:en",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"conversational",
"instruction-tuning"
] | [
"text-generation",
"text2text-generation"
] | "2024-12-07T03:52:52Z" | ---
license: apache-2.0
task_categories:
- text-generation
- text2text-generation
language:
- en
size_categories:
- 1K<n<10K
tags:
- conversational
- instruction-tuning
---
# Dataset Card for Atcgpt-Fixed2
This dataset contains instruction-input-output pairs converted to ShareGPT format, designed for instruction tuning and text generation tasks.
## Dataset Description
The dataset consists of carefully curated instruction-input-output pairs, formatted for conversational AI training. Each entry contains:
- An instruction that specifies the task
- An optional input providing context
- A detailed output that addresses the instruction
## Usage
This dataset is particularly suitable for:
- Instruction tuning of language models
- Training conversational AI systems
- Fine-tuning for specific domain knowledge
|
RyanYr/reflect_mini8bSFTt2_mini8BSFTDPOt1_om2_it2 | RyanYr | "2024-12-07T13:11:32Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T06:09:48Z" | ---
dataset_info:
features:
- name: problem
dtype: string
- name: generated_solution
dtype: string
- name: answer
dtype: string
- name: problem_source
dtype: string
- name: response@0
sequence: string
- name: response@1
sequence: string
- name: response@2
sequence: string
- name: response@2_per_reflection
sequence: string
- name: response@3
sequence: string
- name: response@4_per_reflection
sequence: string
- name: response@4
sequence: string
splits:
- name: train
num_bytes: 1812369148
num_examples: 20000
download_size: 498896395
dataset_size: 1812369148
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
RyanYr/reflect_mini8bSFTt2_mini8BSFTDPOt1_om2_it3_crtc | RyanYr | "2024-12-07T16:17:11Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T06:10:20Z" | ---
dataset_info:
features:
- name: problem
dtype: string
- name: generated_solution
dtype: string
- name: answer
dtype: string
- name: problem_source
dtype: string
- name: response@0
sequence: string
- name: response@1
sequence: string
- name: response@2
sequence: string
- name: response@2_per_reflection
sequence: string
- name: response@3
sequence: string
- name: response@4_per_reflection
sequence: string
- name: response@4
sequence: string
- name: response@5
sequence: string
- name: response@6_per_reflection
sequence: string
splits:
- name: train
num_bytes: 2185466209
num_examples: 20000
download_size: 622750386
dataset_size: 2185466209
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
selfrew/filtered_data_sft | selfrew | "2024-12-07T06:27:38Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T06:23:39Z" | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: gt
dtype: string
- name: level
dtype: string
- name: type
dtype: string
- name: my_solu
dtype: string
- name: pred
sequence: string
- name: turn
dtype: int64
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 1327148858.786616
num_examples: 160313
download_size: 314166841
dataset_size: 1327148858.786616
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
artnoage/orpo2 | artnoage | "2024-12-10T18:34:34Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T08:43:42Z" | ---
dataset_info:
features:
- name: id
dtype: int64
- name: prompt
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: chosen
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected
struct:
- name: content
dtype: string
- name: role
dtype: string
- name: score_chosen
dtype: float64
- name: score_rejected
dtype: float64
- name: bifurcation_point
dtype: int64
splits:
- name: train
num_bytes: 12633074
num_examples: 7719
download_size: 3897870
dataset_size: 12633074
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
cen001/1270ganqingceshi11 | cen001 | "2024-12-07T08:50:21Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T08:49:34Z" | ---
dataset_info:
features:
- name: conversation
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 44061
num_examples: 98
download_size: 27407
dataset_size: 44061
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ADHIZ/image_leelahanu1 | ADHIZ | "2024-12-07T09:41:53Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T09:41:51Z" | ---
dataset_info:
features:
- name: file_name
dtype: string
- name: text
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 1678972.0
num_examples: 2
download_size: 1680896
dataset_size: 1678972.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
rikioka/training_data_v1 | rikioka | "2024-12-07T12:00:25Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"modality:timeseries",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T12:00:20Z" | ---
dataset_info:
features:
- name: query
dtype: string
- name: pos
sequence: string
- name: neg
sequence: string
- name: category
dtype: float64
- name: type
dtype: string
- name: prompt
dtype: string
- name: pos_scores
sequence: float32
- name: neg_scores
sequence: float32
splits:
- name: train
num_bytes: 21773514
num_examples: 12862
download_size: 4560318
dataset_size: 21773514
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
1312354o/llama-ros2 | 1312354o | "2024-12-07T15:14:36Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T14:02:46Z" | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 1236245.9398194584
num_examples: 1794
- name: test
num_bytes: 137820.06018054162
num_examples: 200
download_size: 733471
dataset_size: 1374066.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
wcyat/lihkg-story-sweet-4k | wcyat | "2024-12-10T16:30:44Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T14:11:16Z" | ---
dataset_info:
features:
- name: text
dtype: string
- name: title
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 107906
num_examples: 19
- name: test
num_bytes: 11571
num_examples: 2
download_size: 103676
dataset_size: 119477
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
Fyee/yoga_kg_data | Fyee | "2024-12-10T05:34:30Z" | 8 | 0 | [
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T15:27:05Z" | ---
license: apache-2.0
---
|
amuvarma/26k-stts-duplex-convos | amuvarma | "2024-12-07T20:02:00Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T19:48:31Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: question_audio
dtype: audio
- name: answer
dtype: string
- name: answer_audio
dtype:
audio:
sampling_rate: 16000
splits:
- name: train
num_bytes: 19733823351.66848
num_examples: 26588
download_size: 25141534668
dataset_size: 19733823351.66848
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
anindaghosh/cs-gy-6613-rag-instruct-set | anindaghosh | "2024-12-08T00:03:39Z" | 8 | 0 | [
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-07T20:39:50Z" | ---
configs:
- config_name: default
data_files:
- split: train
path: "dataset.csv"
license: apache-2.0
---
|
feedbackagent/prompt_4_gen_reflection_max5 | feedbackagent | "2024-12-08T02:01:53Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T02:00:29Z" | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: gt
dtype: string
- name: problem
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 37677968
num_examples: 37389
download_size: 14112497
dataset_size: 37677968
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mlfoundations-dev/oh_v1.3_airoboros_x2 | mlfoundations-dev | "2024-12-08T04:06:40Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T04:05:34Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: shard_id
dtype: string
splits:
- name: train
num_bytes: 1481037951.0
num_examples: 893460
download_size: 817372079
dataset_size: 1481037951.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
HoangPhuc7678/OJT12 | HoangPhuc7678 | "2024-12-08T04:26:45Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T04:26:37Z" | ---
dataset_info:
features:
- name: img
dtype: image
- name: gt
dtype: image
splits:
- name: train
num_bytes: 30742007.0
num_examples: 34
download_size: 30744566
dataset_size: 30742007.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mlfoundations-dev/oh_v1.3_alpaca_x8 | mlfoundations-dev | "2024-12-08T05:15:09Z" | 8 | 0 | [
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T05:14:05Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: shard_id
dtype: string
splits:
- name: train
num_bytes: 1570543647.0
num_examples: 1132996
download_size: 866322450
dataset_size: 1570543647.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mlfoundations-dev/oh_v1.3_camel_biology_x.125 | mlfoundations-dev | "2024-12-08T05:43:26Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T05:42:25Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: shard_id
dtype: string
splits:
- name: train
num_bytes: 1349849643.0
num_examples: 845620
download_size: 745698744
dataset_size: 1349849643.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
underctrl/handcamera_double-block_2-colors_pick-up_80 | underctrl | "2024-12-09T00:38:05Z" | 8 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot"
] | [
"robotics"
] | "2024-12-08T06:44:51Z" | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "unknown",
"total_episodes": 80,
"total_frames": 40026,
"total_tasks": 1,
"total_videos": 240,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:80"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": {
"motors": [
"motor_0",
"motor_1",
"motor_2",
"motor_3",
"motor_4",
"motor_5"
]
}
},
"observation.images.android": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channel"
],
"video_info": {
"video.fps": 30.0,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.webcam": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channel"
],
"video_info": {
"video.fps": 30.0,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.handcam": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channel"
],
"video_info": {
"video.fps": 30.0,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"action": {
"dtype": "float32",
"shape": [
6
],
"names": {
"motors": [
"motor_0",
"motor_1",
"motor_2",
"motor_3",
"motor_4",
"motor_5"
]
}
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"next.done": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
feedbackagent/reflection_eval_prompt2 | feedbackagent | "2024-12-08T07:39:21Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T07:38:29Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: responses
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
splits:
- name: train
num_bytes: 9708251715
num_examples: 299072
download_size: 1050868978
dataset_size: 9708251715
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
yin30lei/wildlife_light_image_wildme | yin30lei | "2024-12-08T17:21:03Z" | 8 | 0 | [
"license:other",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T08:12:05Z" | ---
license: other
license_name: attribution-noncommercial-noderivs-license
license_link: LICENSE
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: width
dtype: int64
- name: height
dtype: int64
- name: bboxes
dtype: string
- name: areas
dtype: string
- name: normalized_bboxes
dtype: string
- name: category
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 13124983482.38
num_examples: 8188
download_size: 10426103281
dataset_size: 13124983482.38
---
|
akkikiki/global_mmlu_ja_edited | akkikiki | "2024-12-09T05:18:20Z" | 8 | 0 | [
"language:ja",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2412.03304",
"region:us"
] | null | "2024-12-08T08:34:26Z" | ---
dataset_info:
features:
- name: sample_id
dtype: string
- name: subject
dtype: string
- name: subject_category
dtype: string
- name: question
dtype: string
- name: option_a
dtype: string
- name: option_b
dtype: string
- name: option_c
dtype: string
- name: option_d
dtype: string
- name: answer
dtype: string
- name: required_knowledge
dtype: string
- name: time_sensitive
dtype: string
- name: reference
dtype: string
- name: culture
dtype: string
- name: region
dtype: string
- name: country
dtype: string
- name: cultural_sensitivity_label
dtype: string
- name: is_annotated
dtype: bool
- name: is_edited
dtype: bool
splits:
- name: train
num_bytes: 167465
num_examples: 285
download_size: 99115
dataset_size: 167465
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: apache-2.0
language:
- ja
size_categories:
- n<1K
---
Associated code for this dataset is available at https://github.com/akkikiki/global_mmlu_edit
## Loading the dataset
```
from datasets import load_dataset
# From JSON
ds = load_dataset("akkikiki/global_mmlu_ja_edited")
# If migrating with the original Global MMLU, remove additional columns
ds = ds.remove_columns("is_edited")
# load HF dataset
global_mmlu_ja = load_dataset("CohereForAI/Global-MMLU", 'ja')
global_mmlu_ja["dev"] = ds["train"]
```
## Additional Information
Authorship
* Yoshinari Fujinuma
Licensing Information
This dataset can be used for any purpose, under the terms of the Apache 2.0 License.
Citation Information
The original Global-MMLU dataset is at https://huggingface.co/datasets/CohereForAI/Global-MMLU
```
Original preprint:
@misc{singh2024globalmmluunderstandingaddressing,
title={Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation},
author={Shivalika Singh and Angelika Romanou and Clémentine Fourrier and David I. Adelani and Jian Gang Ngui and Daniel Vila-Suero and Peerat Limkonchotiwat and Kelly Marchisio and Wei Qi Leong and Yosephine Susanto and Raymond Ng and Shayne Longpre and Wei-Yin Ko and Madeline Smith and Antoine Bosselut and Alice Oh and Andre F. T. Martins and Leshem Choshen and Daphne Ippolito and Enzo Ferrante and Marzieh Fadaee and Beyza Ermis and Sara Hooker},
year={2024},
eprint={2412.03304},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.03304},
}
```
If you use this dataset, please cite the following. No preprint as of now but let me know if I should :)
```
@misc {fujinuma2024mmluv2,
author = {Fujinuma, Yoshinari},
title = {JA Revised v2 of Global-MMLU},
howpublished = {\url{https://huggingface.co/datasets/akkikiki/global_mmlu_ja_v2}},
url = {https://huggingface.co/datasets/akkikiki/global_mmlu_ja_v2},
type = {dataset},
year = {2024},
month = {Dec},
timestamp = {2024-12-07},
}
``` |
oceanpty/Skywork-pref-num-62296-config-lla31-70b-inst-n-sample-5-temp-07-top-p-1 | oceanpty | "2024-12-08T08:51:57Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T08:50:45Z" | ---
dataset_info:
features:
- name: id
dtype: int64
- name: instruction
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: source
dtype: string
- name: responses
sequence: string
- name: actions
sequence: string
- name: rewards
sequence: float64
- name: n_prompt_tokens
sequence: int64
- name: n_completion_tokens
sequence: int64
- name: total_tokens
sequence: int64
- name: best_reward
dtype: float64
- name: best_response
dtype: string
- name: best_model
dtype: string
splits:
- name: train
num_bytes: 1215259520
num_examples: 62296
download_size: 555961463
dataset_size: 1215259520
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
amyguan/newswire-20-30-labor | amyguan | "2024-12-08T09:46:26Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T09:39:18Z" | ---
dataset_info:
features:
- name: article
dtype: string
- name: byline
dtype: string
- name: dates
sequence: string
- name: newspaper_metadata
list:
- name: lccn
dtype: string
- name: newspaper_city
dtype: string
- name: newspaper_state
dtype: string
- name: newspaper_title
dtype: string
- name: antitrust
dtype: int64
- name: civil_rights
dtype: int64
- name: crime
dtype: int64
- name: govt_regulation
dtype: int64
- name: labor_movement
dtype: int64
- name: politics
dtype: int64
- name: protests
dtype: int64
- name: ca_topic
dtype: string
- name: ner_words
sequence: string
- name: ner_labels
sequence: string
- name: wire_city
dtype: string
- name: wire_state
dtype: string
- name: wire_country
dtype: string
- name: wire_coordinates
sequence: float64
- name: wire_location_notes
dtype: string
- name: people_mentioned
list:
- name: person_gender
dtype: string
- name: person_name
dtype: string
- name: person_occupation
dtype: string
- name: wikidata_id
dtype: string
- name: cluster_size
dtype: int64
- name: year
dtype: int64
splits:
- name: train
num_bytes: 93820506.88030969
num_examples: 18824
download_size: 23185111
dataset_size: 93820506.88030969
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
antphb/TD-ViOCR-CPVQA | antphb | "2024-12-11T14:40:04Z" | 8 | 0 | [
"task_categories:visual-question-answering",
"task_categories:image-to-text",
"language:vi",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2404.10652",
"arxiv:2405.11985",
"arxiv:2305.04183",
"region:us",
"vision",
"image-text-to-text"
] | [
"visual-question-answering",
"image-to-text"
] | "2024-12-08T12:39:41Z" | ---
dataset_info:
features:
- name: id
dtype: string
- name: image
dtype: image
- name: width
dtype: int64
- name: height
dtype: int64
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: TD_Vintext_CPVQA
num_bytes: 228364419.0
num_examples: 1056
- name: TD_MTCPVQA
num_bytes: 668048263.865
num_examples: 1389
- name: TD_OpenViCPVQA
num_bytes: 1403285019.368
num_examples: 7842
- name: TD_ViTextCPVQA
num_bytes: 5557837266.074
num_examples: 13286
- name: TD_VisualMediaCPVQA
num_bytes: 628929083.304
num_examples: 1416
download_size: 7189561745
dataset_size: 8486464051.611
configs:
- config_name: default
data_files:
- split: TD_Vintext_CPVQA
path: data/TD_Vintext_CPVQA-*
- split: TD_MTCPVQA
path: data/TD_MTCPVQA-*
- split: TD_OpenViCPVQA
path: data/TD_OpenViCPVQA-*
- split: TD_ViTextCPVQA
path: data/TD_ViTextCPVQA-*
- split: TD_VisualMediaCPVQA
path: data/TD_VisualMediaCPVQA-*
language:
- vi
task_categories:
- visual-question-answering
- image-to-text
tags:
- vision
- image-text-to-text
---
## Overview
Based on our research and exploration of datasets primarily related to question-answering tasks involving Vietnamese optical character recognition (OCR), we have decided to use datasets such as ViTextVQA [1], MTVQA [2], Vintext [3], OpenViVQA [4], and a custom dataset we collected related to VisualMedia.
| Dataset Name | Image | Question - Answer pairs |
|-------------------------|---------|--------------------------|
| ViTextVQA | 13,409 | 40,314 |
| Viet-Vintext-gemini-VQA | 1,056 | 5,281 |
| MTVQA | 1,389 | 4,884 |
| OpenViVQA | 10,199 | 27,275 |
| TD-VisualMedia-VQA | 1,480 | 6,337 |
## Enhanced Complexity of Dataset
Base on these dataset above, we aim to utilize Vietnamese VQA datasets and leverage AI Gemini 1.5 to create more complex datasets by combining questions into longer, more challenging ones involving multiple subjects. Additionally, answers will be refined to include clear subjects and predicates, enhancing the precision and reasoning capability of the VQA model.
The distribution of question-answer pairs has also become more diverse after being made more complex. Let’s take a look at the charts below.
| Dataset Name | Task | Image | Complex Question - Answer pairs |
|--------------------------|---------|---------|----------------------------------|
| TD-Vintext-CPVQA | OCR QA | 1,056 | 4,312 |
| TD-MTCPVQA | OCR QA | 1,389 | 5,503 |
| TD-ViTextCPVQA | OCR QA | 13,409 | 34,253 |
| TD-OpenViCPVQA | OCR QA | 7,859 | 27,980 |
| TD-VisualMedia-CPVQA | OCR QA | 1,480 | 4,725 |
| **Total** | | **25,193** | **76,773** |
----
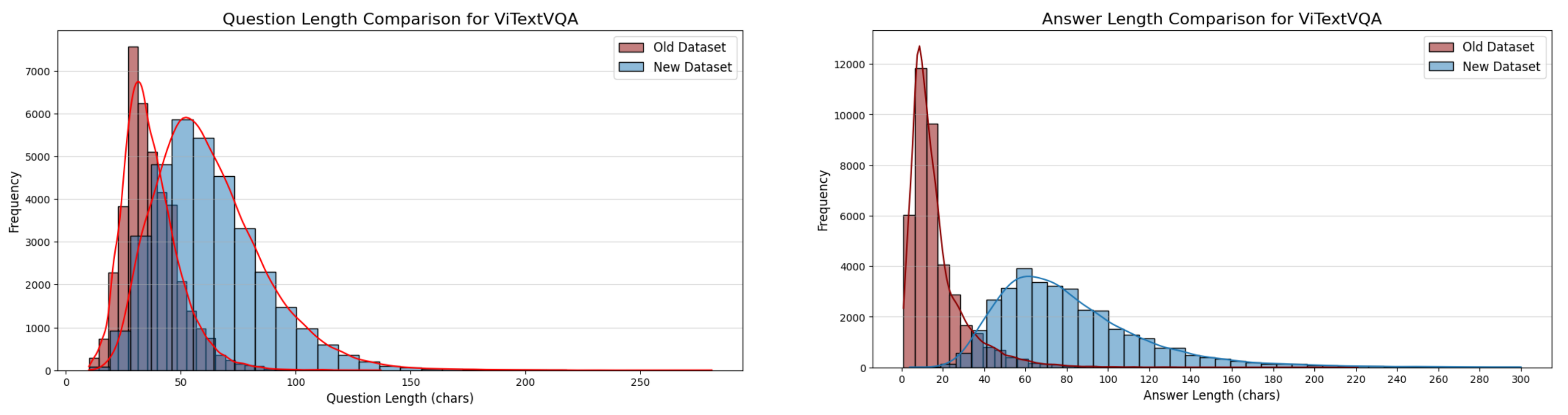
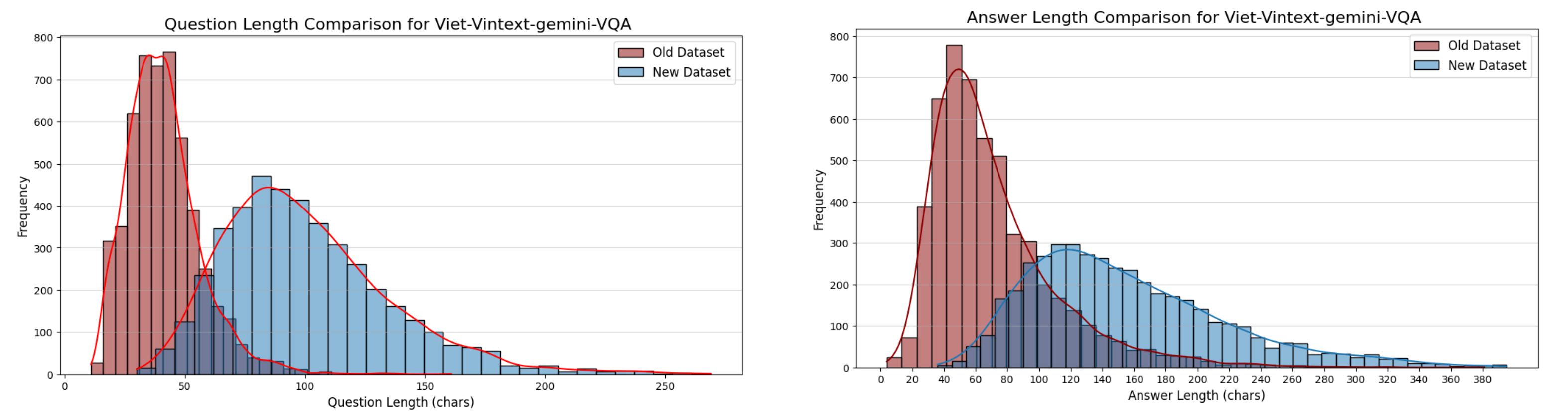
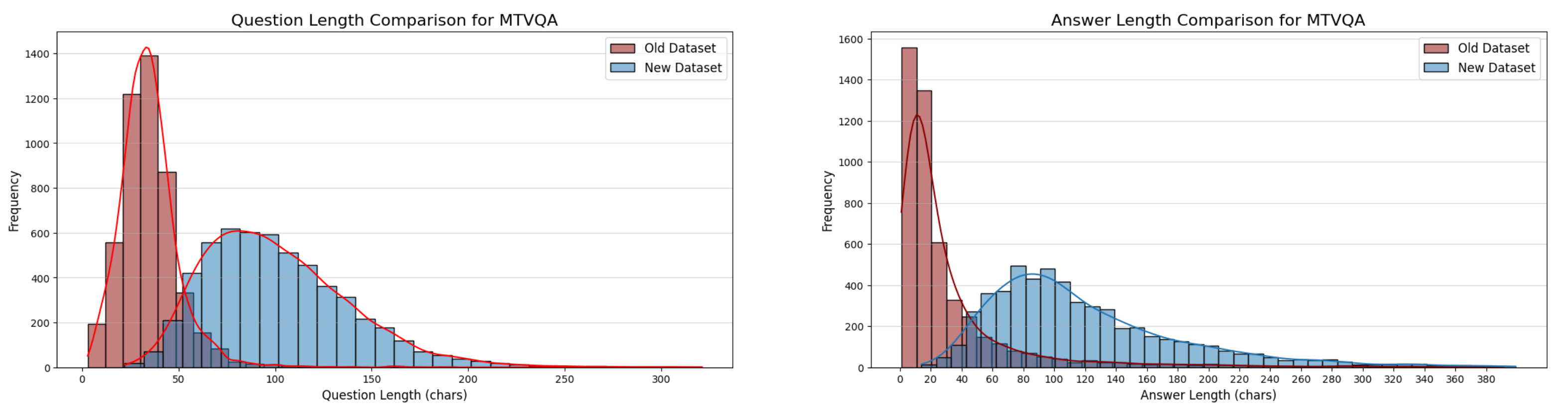
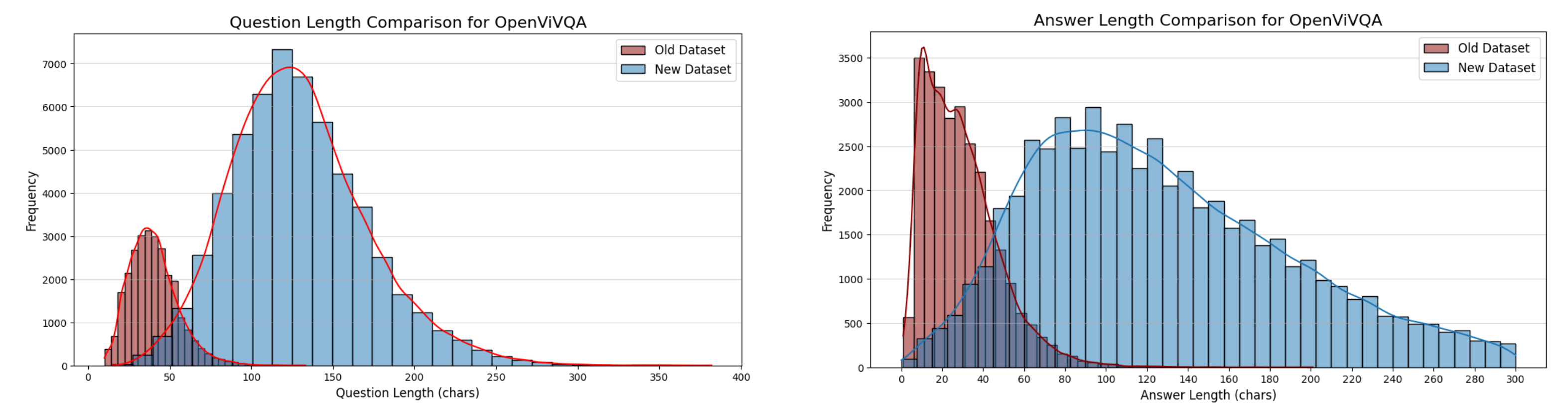
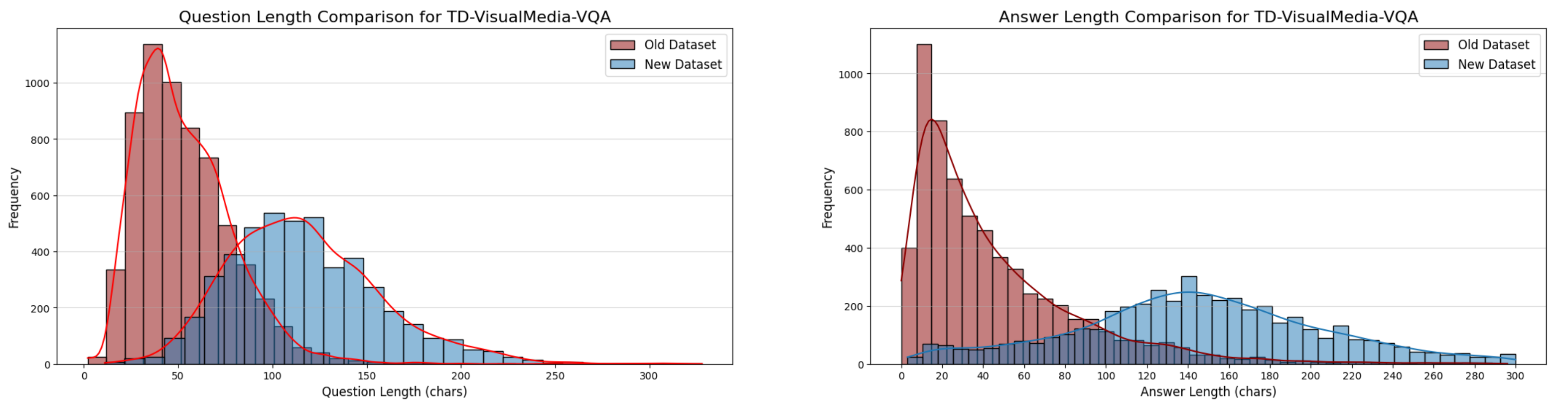
As you can see, the data distribution has changed, with questions tending to be longer and involving more subjects, while answers are more detailed and meaningful. This is a crucial factor in helping the model understand complex contexts.
## Example
<div align="center">
<img width = 400 alt="image" src="https://res.cloudinary.com/dk2cnqatr/image/upload/v1733903889/dataset1_vc9hkx.jpg">
</div>
**Original**
```
Q: khách hàng sống ở đâu sẽ được giảm 2.5% tại fpt shop?
A: thành phố hồ chí minh , đồng nai và bình dương.
Q: fpt shop ưu đãi giảm giá lên đến bao nhiêu phần trăm?
A: fpt shop ưu đãi giảm giá lên đến 50%.
```
**Complex Enhanced**
```
Q: FPT Shop cam kết giao hàng tận nhà trong thời gian bao lâu và có tính phí không?
A: Theo quảng cáo, FPT Shop cam kết giao hàng tận nhà trong vòng một giờ và miễn phí giao hàng.
Q: Ngoài laptop, quảng cáo của FPT Shop còn hiển thị những loại sản phẩm điện tử nào khác?
A: Bên cạnh laptop, quảng cáo của FPT Shop cũng trưng bày hình ảnh của điện thoại thông minh và đồng hồ thông minh.
```
<div align="center">
<img width = 400 alt="image" src="https://res.cloudinary.com/dk2cnqatr/image/upload/v1733903889/dataset2_er9o4r.jpg">
</div>
**Original**
```
Q: Tên của công ty này là gì?
A: Lộc nam việt
Q: Địa chỉ của công ty này ở đâu?
A: 1695 bùi ăn hòa ( quốc lộ 15 cũ ) , p . phước tân , tp . biên hòa , đồng nai
```
**Complex Enhanced**
```
Q: Công ty TNHH Lộc Nam Việt kinh doanh lĩnh vực gì, và địa chỉ trụ sở chính của công ty ở đâu?
A: Công ty TNHH Lộc Nam Việt là công ty chuyên kinh doanh sơn, trụ sở chính của công ty ở 1695 Bùi Văn Hòa (Quốc lộ 15 cũ), P. Phước Tân, TP. Biên Hòa, Đồng Nai.
Q: Ngoài website, khách hàng có thể liên lạc với Công ty TNHH Lộc Nam Việt bằng cách nào?
A: Khách hàng có thể liên lạc với Công ty TNHH Lộc Nam Việt qua số điện thoại (061) 3939 451, 0979 938 545, 098 556 4245 hoặc email loc@locnamviet.com.
```
<div align="center">
<img width = 400 alt="image" src="https://res.cloudinary.com/dk2cnqatr/image/upload/v1733903888/dataset3_vrygux.jpg">
</div>
**Original**
```
Q: Tên công ty là gì?
A: Tên công ty là Công ty TNHH Dịch Vụ Giáo Dục EB Đà Nẵng.
Q: Công ty hoạt động trong lĩnh vực gì?
A: Công ty hoạt động trong lĩnh vực giáo dục.
```
**Complex Enhanced**
```
Q: Công ty tên gì, hoạt động trong lĩnh vực nào và địa chỉ ở đâu?
A: Tên công ty là Công ty TNHH Dịch Vụ Giáo Dục EB Đà Nẵng, hoạt động trong lĩnh vực giáo dục và địa chỉ tại 113 Xuân Diệu, P.Thuận Phước, Q.Hải Châu, TP.Đà Nẵng.
Q: Thông tin liên hệ của công ty bao gồm email, website và số fax là gì?
A: Email của công ty là info@ebstem.edu.vn, website là http://ebstem.edu.vn và số Fax là 0511.31234567.
```
## References
1. ViTextVQA: A Large-Scale Visual Question Answering Dataset for Evaluating Vietnamese Text Comprehension in Images. [Link](https://arxiv.org/abs/2404.10652)
2. MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
[Link](https://arxiv.org/abs/2405.11985)
3. 5CD-AI/Viet-Vintext-gemini-VQA [Link](https://huggingface.co/datasets/5CD-AI/Viet-Vintext-gemini-VQA?)
4. OpenViVQA: Task, Dataset, and Multimodal Fusion Models for Visual Question Answering in Vietnamese [Link](https://arxiv.org/abs/2305.04183)
## Authors
- Thanh Nguyen - thannd2462245@gmail.com
- Du Nguyen - julowin2002@gmail.com |
RichMiguel/Continuation | RichMiguel | "2024-12-08T14:50:37Z" | 8 | 0 | [
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T14:25:21Z" | ---
license: mit
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: Bills
dtype: image
- name: Values
dtype: string
splits:
- name: train
num_bytes: 1767216.0
num_examples: 150
download_size: 1752148
dataset_size: 1767216.0
---
|
lucaelin/generic_situational_action_dialogs_v1 | lucaelin | "2024-12-11T11:13:17Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T16:19:01Z" | ---
dataset_info:
features:
- name: profession
dtype: string
- name: process
dtype: string
- name: situation_json
dtype: string
- name: action
dtype: string
- name: request
dtype: string
- name: requests
dtype: string
- name: function
dtype: string
- name: arguments
dtype: string
- name: result
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 7869729.0
num_examples: 3383
download_size: 2334868
dataset_size: 7869729.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
lucaelin/generic_covas_commentary_v2 | lucaelin | "2024-12-11T11:36:20Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T17:52:04Z" | ---
dataset_info:
features:
- name: profession
dtype: string
- name: process
dtype: string
- name: tools
dtype: string
- name: messages
dtype: string
splits:
- name: train
num_bytes: 6875073
num_examples: 708
download_size: 2268451
dataset_size: 6875073
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
pnsahoo/30-40-macro-embedding | pnsahoo | "2024-12-08T20:21:23Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T18:08:05Z" | ---
dataset_info:
features:
- name: article
dtype: string
- name: byline
dtype: string
- name: dates
sequence: string
- name: newspaper_metadata
list:
- name: lccn
dtype: string
- name: newspaper_city
dtype: string
- name: newspaper_state
dtype: string
- name: newspaper_title
dtype: string
- name: antitrust
dtype: int64
- name: civil_rights
dtype: int64
- name: crime
dtype: int64
- name: govt_regulation
dtype: int64
- name: labor_movement
dtype: int64
- name: politics
dtype: int64
- name: protests
dtype: int64
- name: ca_topic
dtype: string
- name: ner_words
sequence: string
- name: ner_labels
sequence: string
- name: wire_city
dtype: string
- name: wire_state
dtype: string
- name: wire_country
dtype: string
- name: wire_coordinates
sequence: float64
- name: wire_location_notes
dtype: string
- name: people_mentioned
list:
- name: person_gender
dtype: string
- name: person_name
dtype: string
- name: person_occupation
dtype: string
- name: wikidata_id
dtype: string
- name: cluster_size
dtype: int64
- name: year
dtype: int64
- name: embedding
sequence: float64
splits:
- name: train
num_bytes: 173155054
num_examples: 14524
download_size: 94896485
dataset_size: 173155054
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
pnsahoo/30-40-civil-rights-embedding | pnsahoo | "2024-12-08T20:23:33Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T18:10:24Z" | ---
dataset_info:
features:
- name: article
dtype: string
- name: byline
dtype: string
- name: dates
sequence: string
- name: newspaper_metadata
list:
- name: lccn
dtype: string
- name: newspaper_city
dtype: string
- name: newspaper_state
dtype: string
- name: newspaper_title
dtype: string
- name: antitrust
dtype: int64
- name: civil_rights
dtype: int64
- name: crime
dtype: int64
- name: govt_regulation
dtype: int64
- name: labor_movement
dtype: int64
- name: politics
dtype: int64
- name: protests
dtype: int64
- name: ca_topic
dtype: string
- name: ner_words
sequence: string
- name: ner_labels
sequence: string
- name: wire_city
dtype: string
- name: wire_state
dtype: string
- name: wire_country
dtype: string
- name: wire_coordinates
sequence: float64
- name: wire_location_notes
dtype: string
- name: people_mentioned
list:
- name: person_gender
dtype: string
- name: person_name
dtype: string
- name: person_occupation
dtype: string
- name: wikidata_id
dtype: string
- name: cluster_size
dtype: int64
- name: year
dtype: int64
- name: embedding
sequence: float64
splits:
- name: train
num_bytes: 72415700
num_examples: 6991
download_size: 43265124
dataset_size: 72415700
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
pnsahoo/40-50-macro-embedding | pnsahoo | "2024-12-08T20:36:16Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T18:23:21Z" | ---
dataset_info:
features:
- name: article
dtype: string
- name: byline
dtype: string
- name: dates
sequence: string
- name: newspaper_metadata
list:
- name: lccn
dtype: string
- name: newspaper_city
dtype: string
- name: newspaper_state
dtype: string
- name: newspaper_title
dtype: string
- name: antitrust
dtype: int64
- name: civil_rights
dtype: int64
- name: crime
dtype: int64
- name: govt_regulation
dtype: int64
- name: labor_movement
dtype: int64
- name: politics
dtype: int64
- name: protests
dtype: int64
- name: ca_topic
dtype: string
- name: ner_words
sequence: string
- name: ner_labels
sequence: string
- name: wire_city
dtype: string
- name: wire_state
dtype: string
- name: wire_country
dtype: string
- name: wire_coordinates
sequence: float64
- name: wire_location_notes
dtype: string
- name: people_mentioned
list:
- name: person_gender
dtype: string
- name: person_name
dtype: string
- name: person_occupation
dtype: string
- name: wikidata_id
dtype: string
- name: cluster_size
dtype: int64
- name: year
dtype: int64
- name: embedding
sequence: float64
splits:
- name: train
num_bytes: 118959700
num_examples: 9763
download_size: 63558500
dataset_size: 118959700
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
pnsahoo/40-50-civil-rights-embedding | pnsahoo | "2024-12-08T20:37:59Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T18:25:11Z" | ---
dataset_info:
features:
- name: article
dtype: string
- name: byline
dtype: string
- name: dates
sequence: string
- name: newspaper_metadata
list:
- name: lccn
dtype: string
- name: newspaper_city
dtype: string
- name: newspaper_state
dtype: string
- name: newspaper_title
dtype: string
- name: antitrust
dtype: int64
- name: civil_rights
dtype: int64
- name: crime
dtype: int64
- name: govt_regulation
dtype: int64
- name: labor_movement
dtype: int64
- name: politics
dtype: int64
- name: protests
dtype: int64
- name: ca_topic
dtype: string
- name: ner_words
sequence: string
- name: ner_labels
sequence: string
- name: wire_city
dtype: string
- name: wire_state
dtype: string
- name: wire_country
dtype: string
- name: wire_coordinates
sequence: float64
- name: wire_location_notes
dtype: string
- name: people_mentioned
list:
- name: person_gender
dtype: string
- name: person_name
dtype: string
- name: person_occupation
dtype: string
- name: wikidata_id
dtype: string
- name: cluster_size
dtype: int64
- name: year
dtype: int64
- name: embedding
sequence: float64
splits:
- name: train
num_bytes: 57689765
num_examples: 5471
download_size: 34287928
dataset_size: 57689765
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
NAMAA-Space/mteb-eval-mrtydi | NAMAA-Space | "2024-12-11T11:42:29Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T19:04:57Z" | ---
dataset_info:
features:
- name: query
dtype: string
- name: positive
sequence: string
- name: negative
sequence: string
splits:
- name: test
num_bytes: 2362241
num_examples: 918
download_size: 1162857
dataset_size: 2362241
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
selfrew/no_fitered_3epoch_2e6_bz128_tmp10_scaling_time | selfrew | "2024-12-09T18:05:20Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T22:41:40Z" | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: gt
dtype: string
- name: prompt
dtype: string
- name: level
dtype: string
- name: type
dtype: string
- name: solution
dtype: string
- name: rewards
sequence: bool
- name: my_solu
sequence: string
splits:
- name: train
num_bytes: 1444504458
num_examples: 355000
download_size: 452313835
dataset_size: 1444504458
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ashwin-4000/ros_instruct_dataset | ashwin-4000 | "2024-12-08T23:53:36Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-08T23:47:26Z" | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: metadata_total_chunks_retrieved
dtype: int64
- name: metadata_total_batches_processed
dtype: int64
- name: metadata_batch_size
dtype: int64
- name: metadata_total_pairs
dtype: int64
- name: metadata_total_tokens
dtype: int64
- name: metadata_max_workers
dtype: int64
- name: uploaded_at
dtype: string
splits:
- name: train
num_bytes: 1078713
num_examples: 1792
download_size: 502330
dataset_size: 1078713
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ZCM5115/so100_test | ZCM5115 | "2024-12-10T02:18:47Z" | 8 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"tutorial"
] | [
"robotics"
] | "2024-12-09T02:15:08Z" | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "so100",
"total_episodes": 5,
"total_frames": 4042,
"total_tasks": 1,
"total_videos": 10,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:5"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.laptop": {
"dtype": "video",
"shape": [
360,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 360,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.hikvision": {
"dtype": "video",
"shape": [
360,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 360,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
KMH158/Dataset_150x10_t1ce | KMH158 | "2024-12-09T05:20:09Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T05:20:01Z" | ---
dataset_info:
features:
- name: messages
struct:
- name: text
dtype: string
- name: images
dtype: image
splits:
- name: train
num_bytes: 4444644.4
num_examples: 1200
- name: eval
num_bytes: 1066728.0
num_examples: 290
download_size: 3662529
dataset_size: 5511372.4
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: eval
path: data/eval-*
---
|
feedbackagent/subset | feedbackagent | "2024-12-09T06:32:51Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T06:32:28Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: completions
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
splits:
- name: train
num_bytes: 1902121542
num_examples: 74768
download_size: 620758742
dataset_size: 1902121542
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
disl/musinsa-snap-final | disl | "2024-12-09T06:46:44Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T06:46:28Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 190190600.625
num_examples: 9667
download_size: 171116866
dataset_size: 190190600.625
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
prezent-ml/lilly-augmented-clean | prezent-ml | "2024-12-09T08:43:04Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T08:43:03Z" | ---
dataset_info:
features:
- name: problem
dtype: string
- name: solution
dtype: string
splits:
- name: train
num_bytes: 3339203
num_examples: 2323
download_size: 1224498
dataset_size: 3339203
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Deepnoid/phrases_2 | Deepnoid | "2024-12-09T10:04:41Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T10:04:37Z" | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 15961690
num_examples: 288199
download_size: 4779478
dataset_size: 15961690
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
vasu718/traders_questions | vasu718 | "2024-12-09T12:36:09Z" | 8 | 0 | [
"license:mit",
"size_categories:n<1K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T12:34:37Z" | ---
license: mit
---
|
feecha/chatbot_zh_dataset | feecha | "2024-12-09T12:47:07Z" | 8 | 0 | [
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T12:38:32Z" | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 6660730789
num_examples: 6750047
download_size: 3996954739
dataset_size: 6660730789
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
oceanpty/Self-J-score-w-ref-skywork-pref-ref-lla31-70b-inst-model-lla-31-70b-inst-thre-1 | oceanpty | "2024-12-09T12:54:20Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T12:54:06Z" | ---
dataset_info:
features:
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: chosen_score
dtype: float64
- name: rejected_score
dtype: float64
splits:
- name: train
num_bytes: 217352360
num_examples: 44669
download_size: 110082438
dataset_size: 217352360
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Negev900/control_test_1 | Negev900 | "2024-12-09T13:11:28Z" | 8 | 0 | [
"language:en",
"license:mit",
"size_categories:n<1K",
"format:arrow",
"modality:image",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us",
"controlnet",
"image-to-image"
] | [
"controlled-image-generation"
] | "2024-12-09T13:09:27Z" | ---
license: mit
task_categories:
- controlled-image-generation
language:
- en
tags:
- controlnet
- image-to-image
---
# Negev900/control_test_1
ControlNet dataset with conditioning images.
## Dataset Description
A dataset for training ControlNet models, containing original images paired with their conditioning images.
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("Negev900/control_test_1")
```
## Dataset Structure
Each example contains:
- `text`: The caption/text description
- `image`: The original image
- `conditioning_image`: The conditioning image for ControlNet
|
juliadollis/dataset_nlp_test | juliadollis | "2024-12-09T13:59:01Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T13:58:58Z" | ---
dataset_info:
features:
- name: pergunta
dtype: string
- name: resposta
dtype: string
splits:
- name: train
num_bytes: 167150.29881293493
num_examples: 100
download_size: 101853
dataset_size: 167150.29881293493
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
gdurkin/s1_nlcd_sfbay_plus | gdurkin | "2024-12-09T14:00:31Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"modality:image",
"region:us"
] | null | "2024-12-09T13:59:58Z" | ---
dataset_info:
features:
- name: pixel_values
dtype: image
- name: labels
dtype: image
splits:
- name: group_40_46
num_bytes: 145273040.072
num_examples: 1738
- name: group_30_39
num_bytes: 225842135.0
num_examples: 2500
- name: group_0_9
num_bytes: 212875058.256
num_examples: 2499
- name: group_10_19
num_bytes: 204868215.0
num_examples: 2500
- name: group_20_29
num_bytes: 226897607.0
num_examples: 2500
download_size: 1015859359
dataset_size: 1015756055.3280001
configs:
- config_name: default
data_files:
- split: group_40_46
path: data/group_40_46-*
- split: group_30_39
path: data/group_30_39-*
- split: group_0_9
path: data/group_0_9-*
- split: group_10_19
path: data/group_10_19-*
- split: group_20_29
path: data/group_20_29-*
---
|
ferrazzipietro/IK_llama3.1-8b_e3c_16_16_0.05 | ferrazzipietro | "2024-12-10T13:30:06Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T14:46:38Z" | ---
dataset_info:
features:
- name: inference_prompt
dtype: string
- name: sentence
dtype: string
- name: model_responses
dtype: string
- name: ground_truth
dtype: string
splits:
- name: validation
num_bytes: 88345
num_examples: 106
- name: test
num_bytes: 712632
num_examples: 666
download_size: 271519
dataset_size: 800977
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
ferrazzipietro/IK_llama3.1-8b_e3c_16_32_0.01 | ferrazzipietro | "2024-12-10T13:30:26Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T14:49:33Z" | ---
dataset_info:
features:
- name: inference_prompt
dtype: string
- name: sentence
dtype: string
- name: model_responses
dtype: string
- name: ground_truth
dtype: string
splits:
- name: validation
num_bytes: 88529
num_examples: 106
- name: test
num_bytes: 713174
num_examples: 666
download_size: 271274
dataset_size: 801703
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
grahamakercustom/pbllm | grahamakercustom | "2024-12-10T05:12:38Z" | 8 | 0 | [
"license:apache-2.0",
"size_categories:1K<n<10K",
"region:us",
"not-for-all-audiences"
] | null | "2024-12-09T15:30:14Z" | ---
license: apache-2.0
tags:
- not-for-all-audiences
size_categories:
- 1K<n<10K
--- |
ahmedsamirtarjama/misconception_multiple_choice_quiz | ahmedsamirtarjama | "2024-12-09T17:37:06Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T15:49:06Z" | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 1430747
num_examples: 1619
download_size: 631801
dataset_size: 1430747
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
code-planning/deepseek-family | code-planning | "2024-12-11T14:56:08Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T15:56:32Z" | ---
dataset_info:
features:
- name: model_name
dtype: string
- name: benchmark_name
dtype: string
- name: benchmark_q_id
dtype: string
- name: input
dtype: string
- name: code_output
dtype: string
- name: is_correct_base
dtype: string
- name: is_correct_plus
dtype: string
- name: variant
dtype: string
- name: is_correct
dtype: string
splits:
- name: train
num_bytes: 19198447
num_examples: 7938
download_size: 7608631
dataset_size: 19198447
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
albinandersson/Nordisk-Familjebok-Headword-Extraction-Dataset | albinandersson | "2024-12-10T22:53:18Z" | 8 | 0 | [
"task_categories:text-classification",
"language:sv",
"license:cc-by-nc-sa-4.0",
"size_categories:100K<n<1M",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-classification"
] | "2024-12-09T16:00:56Z" | ---
license: cc-by-nc-sa-4.0
language:
- sv
train_size: 300075
test_size: 5000
content_types:
- biographical
- geographical
- scientific
- historical
- cultural
- technical
pretty_name: "Nordisk Familjebok Headword Extraction Dataset"
task_categories:
- text-classification
size_categories:
- 100K<n<1M
libraries:
- datasets
- pandas
- polars
- croissant
modalities:
- text
formats:
- jsonl
date_published: "2024-12-09"
version: "1.0.0"
cite_as: "@dataset{albinandersson2024,
title = {Nordisk Familjebok Headword Extraction Dataset},
author = {Albin Andersson and Salam Jonasson and Fredrik Wastring},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/datasets/albinandersson/Nordisk-Familjebok-Headword-Extraction-Dataset}
}"
croissant:
"@context":
"@vocab": "http://mlcommons.org/croissant/"
schema: "https://schema.org/"
citeAs: "http://mlcommons.org/croissant/citeAs"
"@type": "Dataset"
name: "Nordisk Familjebok Headword Extraction Dataset"
description: "A dataset extracted from Nordisk Familjebok used for training a headword extraction model."
url: "https://huggingface.co/datasets/albinandersson/Nordisk-Familjebok-Headword-Extraction-Dataset"
version: "1.0.0"
datePublished: "2024-12-09"
citeAs: "@dataset{albinandersson2024,
title = {Nordisk Familjebok Headword Extraction Dataset},
author = {Albin Andersson and Salam Jonasson and Fredrik Wastring},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/datasets/albinandersson/Nordisk-Familjebok-Headword-Extraction-Dataset}
}"
license: "https://creativecommons.org/licenses/by-nc-sa/4.0/"
creator:
"@type": "Organization"
name: "Albin Andersson, Salam Jonasson, Fredrik Wastring"
---
# Dataset Name: Nordisk Familjebok Headword Extraction Dataset
## Description
This dataset contains pairs of extracted text and their corresponding headwords from all editions of Nordisk Familjebok. Each entry includes a `text` and a `headword` field. If a text has a corresponding headword, the `headword` field is populated; otherwise, it contains an empty string. This dataset is designed for training and evaluating headword extraction models.
## Files
- **train_set.jsonl**: Contains text-headword pairs from the scraped version of Nordisk Familjebok. Entries are not manually verified.
- **test_set.jsonl**: Contains manually verified entries ensuring higher accuracy and quality for evaluation purposes.
## Data Fields
- **text**: A string representing an extraction of text (max 500 characters) from the scraped digitalized version of Nordisk Familjebok with all HTML tags removed.
- **headword**: A string representing the corresponding headword. If no headword is present, this field is an empty string.
## Licensing
This dataset is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0). Users can use, modify, and share this dataset for non-commercial purposes with appropriate credit and under the same license.
## Citation
If you use this dataset, please cite it as follows:
```bibtex
@misc{albinandersson2024,
title = {Nordisk Familjebok Headword Extraction Dataset},
author = {Albin Andersson and Salam Jonasson and Fredrik Wastring},
year = {2024},
publisher = {Hugging Face},
url = {https://huggingface.co/datasets/albinandersson/Nordisk-Familjebok-Headword-Extraction-Dataset}
} |
seanwhen/dasso100_test | seanwhen | "2024-12-09T17:27:39Z" | 8 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so100",
"tutorial"
] | [
"robotics"
] | "2024-12-09T17:26:54Z" | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so100
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "so100",
"total_episodes": 2,
"total_frames": 479,
"total_tasks": 1,
"total_videos": 4,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:2"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.laptop": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.phone": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
amuvarma/eliasfiz-audio_pretrain_10m-facodec-1dups | amuvarma | "2024-12-09T21:59:35Z" | 8 | 0 | [
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T21:35:00Z" | ---
dataset_info:
features:
- name: transcript
dtype: string
- name: facodec_0
sequence: int64
- name: facodec_1
sequence: int64
- name: facodec_2
sequence: int64
- name: facodec_3
sequence: int64
- name: facodec_4
sequence: int64
- name: facodec_5
sequence: int64
- name: spk_embs
sequence: float64
splits:
- name: train
num_bytes: 147579503014
num_examples: 3243931
download_size: 28596207138
dataset_size: 147579503014
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
amuvarma/CanopyLabs-audio_pretrain_10m-facodec-1dups | amuvarma | "2024-12-09T23:28:17Z" | 8 | 0 | [
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-09T22:57:39Z" | ---
dataset_info:
features:
- name: transcript
dtype: string
- name: facodec_0
sequence: int64
- name: facodec_1
sequence: int64
- name: facodec_2
sequence: int64
- name: facodec_3
sequence: int64
- name: facodec_4
sequence: int64
- name: facodec_5
sequence: int64
- name: spk_embs
sequence: float64
splits:
- name: train
num_bytes: 179995591117
num_examples: 3953797
download_size: 34870388777
dataset_size: 179995591117
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
davidr99/blackjack-more-questions | davidr99 | "2024-12-10T01:47:59Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T01:32:26Z" | ---
dataset_info:
features:
- name: image
dtype: image
- name: question
dtype: string
- name: multiple_choice_answer
dtype: string
splits:
- name: train
num_bytes: 452861865.261
num_examples: 1177
download_size: 71099230
dataset_size: 452861865.261
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
seongil-dn/korean_retrieval_451949 | seongil-dn | "2024-12-10T13:45:27Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T02:39:39Z" | ---
dataset_info:
features:
- name: anchor
dtype: string
- name: positive
dtype: string
- name: negative
dtype: string
- name: subset
dtype: string
splits:
- name: train
num_bytes: 1546738570
num_examples: 451949
download_size: 857531101
dataset_size: 1546738570
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
yin30lei/wildlife_very_dark | yin30lei | "2024-12-10T03:03:56Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T03:03:38Z" | ---
dataset_info:
features:
- name: file_name
dtype: string
- name: image_id
dtype: int64
- name: width
dtype: int64
- name: height
dtype: int64
- name: image
dtype: image
- name: labels
dtype: string
splits:
- name: train
num_bytes: 40595743.742
num_examples: 1638
- name: test
num_bytes: 17273301.0
num_examples: 702
download_size: 36387229
dataset_size: 57869044.742
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
feedbackagent/train_reflection_eval1_with_rewards | feedbackagent | "2024-12-10T03:17:38Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T03:17:19Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: completions
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
- name: rewards
sequence: bool
- name: preds
sequence: string
splits:
- name: train
num_bytes: 1069622536
num_examples: 49998
download_size: 344998480
dataset_size: 1069622536
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
feedbackagent/train_reflection_eval2_with_rewards2 | feedbackagent | "2024-12-10T03:49:54Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T03:48:58Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: completions
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
- name: rewards
sequence: bool
- name: preds
sequence: string
splits:
- name: train
num_bytes: 3819118429
num_examples: 149071
download_size: 1242757096
dataset_size: 3819118429
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
feedbackagent/train_reflection_eval3_with_rewards | feedbackagent | "2024-12-10T04:05:56Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T04:05:33Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: completions
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
- name: rewards
sequence: bool
- name: preds
sequence: string
splits:
- name: train
num_bytes: 1438976901
num_examples: 50000
download_size: 462282281
dataset_size: 1438976901
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
feedbackagent/subset_with_rewards | feedbackagent | "2024-12-10T04:50:39Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T04:50:15Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: completions
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
- name: rewards
sequence: bool
- name: preds
sequence: string
splits:
- name: train
num_bytes: 1917204623
num_examples: 74768
download_size: 624059932
dataset_size: 1917204623
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
feedbackagent/train_reflection_eval4_with_rewards | feedbackagent | "2024-12-10T05:50:05Z" | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T05:49:14Z" | ---
dataset_info:
features:
- name: gt
dtype: string
- name: idx
dtype: int64
- name: prompt
dtype: string
- name: completions
sequence: string
- name: problem
dtype: string
- name: response
dtype: string
- name: reflection
dtype: string
- name: rewards
sequence: bool
- name: preds
sequence: string
splits:
- name: train
num_bytes: 3281174028
num_examples: 124304
download_size: 1065772357
dataset_size: 3281174028
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
mostafaashahin/common_voice_Arabic_12.0_Augmented_SWS_catt_new_split | mostafaashahin | "2024-12-10T08:01:20Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T07:50:25Z" | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: sentence
dtype: string
- name: score
dtype: int64
- name: q_indx
dtype: int64
- name: start_word_indx
dtype: int64
- name: end_word_indx
dtype: int64
- name: tashkeel_sentence
dtype: string
- name: ID
dtype: string
splits:
- name: train
num_bytes: 13955666205.535368
num_examples: 71391
- name: dev
num_bytes: 75785042.00785968
num_examples: 2588
download_size: 12169157511
dataset_size: 14031451247.543228
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: dev
path: data/dev-*
---
|
junsashihara/response-dataset-qwen-instruct | junsashihara | "2024-12-10T09:35:28Z" | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T08:35:07Z" | ---
dataset_info:
features:
- name: conversation
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 116929626
num_examples: 50782
download_size: 53160260
dataset_size: 116929626
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
seand0101/manggarai-watergate-binary | seand0101 | "2024-12-10T10:22:22Z" | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2024-12-10T09:59:43Z" | ---
dataset_info:
features:
- name: pixel_values
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 6016508709.488
num_examples: 8752
download_size: 6065824739
dataset_size: 6016508709.488
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
gabrielmbmb/logprobs | gabrielmbmb | "2024-12-10T13:49:51Z" | 8 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"library:distilabel",
"region:us",
"synthetic",
"distilabel",
"rlaif"
] | null | "2024-12-10T13:49:46Z" | ---
size_categories: n<1K
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: source
dtype: string
- name: score
dtype: float64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: generation
dtype: string
- name: distilabel_metadata
struct:
- name: raw_input_text_generation_vllm
list:
- name: content
dtype: string
- name: role
dtype: string
- name: raw_output_text_generation_vllm
dtype: string
- name: statistics_text_generation_vllm
struct:
- name: input_tokens
dtype: int64
- name: output_tokens
dtype: int64
- name: llm_text_generation_vllm_logprobs
list:
list:
- name: logprob
dtype: float64
- name: token
dtype: string
- name: model_name
dtype: string
splits:
- name: train
num_bytes: 3158554
num_examples: 20
download_size: 1507282
dataset_size: 3158554
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- synthetic
- distilabel
- rlaif
---
<p align="left">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
# Dataset Card for logprobs
This dataset has been created with [distilabel](https://distilabel.argilla.io/).
## Dataset Summary
This dataset contains a `pipeline.yaml` which can be used to reproduce the pipeline that generated it in distilabel using the `distilabel` CLI:
```console
distilabel pipeline run --config "https://huggingface.co/datasets/gabrielmbmb/logprobs/raw/main/pipeline.yaml"
```
or explore the configuration:
```console
distilabel pipeline info --config "https://huggingface.co/datasets/gabrielmbmb/logprobs/raw/main/pipeline.yaml"
```
## Dataset structure
The examples have the following structure per configuration:
<details><summary> Configuration: default </summary><hr>
```json
{
"conversations": [
{
"from": "human",
"value": "Explain what boolean operators are, what they do, and provide examples of how they can be used in programming. Additionally, describe the concept of operator precedence and provide examples of how it affects the evaluation of boolean expressions. Discuss the difference between short-circuit evaluation and normal evaluation in boolean expressions and demonstrate their usage in code. \n\nFurthermore, add the requirement that the code must be written in a language that does not support short-circuit evaluation natively, forcing the test taker to implement their own logic for short-circuit evaluation.\n\nFinally, delve into the concept of truthiness and falsiness in programming languages, explaining how it affects the evaluation of boolean expressions. Add the constraint that the test taker must write code that handles cases where truthiness and falsiness are implemented differently across different programming languages."
},
{
"from": "gpt",
"value": "Boolean operators are logical operators used in programming to manipulate boolean values. They operate on one or more boolean operands and return a boolean result. The three main boolean operators are \"AND\" (\u0026\u0026), \"OR\" (||), and \"NOT\" (!).\n\nThe \"AND\" operator returns true if both of its operands are true, and false otherwise. For example:\n\n```python\nx = 5\ny = 10\nresult = (x \u003e 0) and (y \u003c 20) # This expression evaluates to True\n```\n\nThe \"OR\" operator returns true if at least one of its operands is true, and false otherwise. For example:\n\n```python\nx = 5\ny = 10\nresult = (x \u003e 0) or (y \u003c 20) # This expression evaluates to True\n```\n\nThe \"NOT\" operator negates the boolean value of its operand. It returns true if the operand is false, and false if the operand is true. For example:\n\n```python\nx = 5\nresult = not (x \u003e 10) # This expression evaluates to True\n```\n\nOperator precedence refers to the order in which operators are evaluated in an expression. It ensures that expressions are evaluated correctly. In most programming languages, logical AND has higher precedence than logical OR. For example:\n\n```python\nresult = True or False and False # This expression is evaluated as (True or (False and False)), which is True\n```\n\nShort-circuit evaluation is a behavior where the second operand of a logical operator is not evaluated if the result can be determined based on the value of the first operand. In short-circuit evaluation, if the first operand of an \"AND\" operator is false, the second operand is not evaluated because the result will always be false. Similarly, if the first operand of an \"OR\" operator is true, the second operand is not evaluated because the result will always be true.\n\nIn programming languages that support short-circuit evaluation natively, you can use it to improve performance or avoid errors. For example:\n\n```python\nif x != 0 and (y / x) \u003e 10:\n # Perform some operation\n```\n\nIn languages without native short-circuit evaluation, you can implement your own logic to achieve the same behavior. Here\u0027s an example in pseudocode:\n\n```\nif x != 0 {\n if (y / x) \u003e 10 {\n // Perform some operation\n }\n}\n```\n\nTruthiness and falsiness refer to how non-boolean values are evaluated in boolean contexts. In many programming languages, non-zero numbers and non-empty strings are considered truthy, while zero, empty strings, and null/None values are considered falsy.\n\nWhen evaluating boolean expressions, truthiness and falsiness come into play. For example:\n\n```python\nx = 5\nresult = x # The value of x is truthy, so result is also truthy\n```\n\nTo handle cases where truthiness and falsiness are implemented differently across programming languages, you can explicitly check the desired condition. For example:\n\n```python\nx = 5\nresult = bool(x) # Explicitly converting x to a boolean value\n```\n\nThis ensures that the result is always a boolean value, regardless of the language\u0027s truthiness and falsiness rules."
}
],
"distilabel_metadata": {
"raw_input_text_generation_vllm": [
{
"content": "Explain what boolean operators are, what they do, and provide examples of how they can be used in programming. Additionally, describe the concept of operator precedence and provide examples of how it affects the evaluation of boolean expressions. Discuss the difference between short-circuit evaluation and normal evaluation in boolean expressions and demonstrate their usage in code. \n\nFurthermore, add the requirement that the code must be written in a language that does not support short-circuit evaluation natively, forcing the test taker to implement their own logic for short-circuit evaluation.\n\nFinally, delve into the concept of truthiness and falsiness in programming languages, explaining how it affects the evaluation of boolean expressions. Add the constraint that the test taker must write code that handles cases where truthiness and falsiness are implemented differently across different programming languages.",
"role": "user"
}
],
"raw_output_text_generation_vllm": "Boolean operators are operators used to combine conditions in programming, returning a boolean value (true or false) based on the evaluation of those conditions. There are six primary boolean operators:\n\n1. `AND` (\u0026\u0026): Returns true if both conditions are true.\n2. `OR` (||): Returns true if either condition is true.\n3. `NOT` (!): Returns the opposite of the condition, i.e., true if the condition is false, and false if the condition is true.\n\nHere are some examples of how boolean operators work in programming:\n\n1. `(x == 5) \u0026\u0026 (y \u003e= 10)` returns true only if both `x` is 5 and `y` is greater than or equal to 10.\n2. `(x \u003e 10) || (y \u003c 0)` returns true if either `x` is greater than 10 or `y` is less than 0.\n3. `!(x == y)` returns true if `x` is not equal to `y`.\n\nOperator precedence in boolean expressions determines the order in which the conditions are evaluated. It is similar to operator precedence in arithmetic expressions. Here is the order of precedence:\n\n1. `NOT` (!)\n2. `||` (OR)\n3. `\u0026\u0026` (AND)\n\nFor example, `(x \u003e 10) || (y \u003c 0)` has higher precedence than `!(x == y)`, so the expression `(x \u003e 10) || (y \u003c 0)` is evaluated before `!(x == y)`.\n\nShort-circuit evaluation is a feature of some programming languages that allows the evaluation of a boolean expression to stop as soon as the truth value has been determined. This means that if the first condition in the boolean expression is false, the second condition will not be evaluated.\n\nFor example, in C#, the expression `(x \u003e 10) || (y \u003c 0)` is short-circuit evaluated, so `y` is not evaluated if `x` is greater than 10.\n\nNormal evaluation, on the other hand, evaluates both conditions even if one of them is false.\n\nTo implement short-circuit evaluation in a language that does not support it natively, you can use a technique called \"parenthesizing\" the boolean expression, which forces the language to evaluate the expression in a way that mimics short-circuit evaluation. This can be done by using parentheses to group the conditions in a way that causes the language to evaluate the expression in a short-circuit manner.\n\nHere is an example of how to implement short-circuit evaluation in Python:\n\n```python\ndef short_circuit(x, y):\n return (x \u003e 0) or (y \u003c 10)\n```\n\nIn this example, the function `short_circuit` takes two arguments `x` and `y`. The expression `(x \u003e 0) or (y \u003c 10)` is short-circuit evaluated, so `y` is not evaluated if `x` is greater than 0.\n\nTruthiness and falsiness in programming languages are concepts that determine whether a value is considered \"true\" or \"false\" in a boolean context. The truthiness of a value depends on its type and the language\u0027s boolean implementation.\n\nFor example, in Python, the following values are considered falsy:\n\n- Empty strings (`\"\"`),\n- Empty lists (`[]`),\n- Empty dictionaries (`{}`),\n- Empty sets (`set()`),\n- None,\n- Zero (integers, floats, etc.),\n- False.\n\nOn the other hand, the following values are considered truthy:\n\n- Non-empty strings (`\"hello\"`),\n- Non-empty lists (`[1, 2, 3]`),\n- Non-empty dictionaries (`{\"a\": 1, \"b\": 2}`),\n- Non-empty sets (`{1, 2, 3}`),\n- True,\n- All non-empty values.\n\nTo handle cases where truthiness and falsiness are implemented differently across different programming languages, you can write code that checks the type of the value and handles it accordingly. For example, in Python:\n\n```python\ndef handle_truthiness(value):\n if not isinstance(value, (str, list, dict, set)):\n return False\n if value:\n return True\n return False\n```\n\nThis function checks the type of the value and returns `True` if the value is a string, list, dictionary, or set, and `False` otherwise. It then checks the value for truthyness by returning `True` if the value is not empty",
"statistics_text_generation_vllm": {
"input_tokens": 193,
"output_tokens": 1024
}
},
"generation": "Boolean operators are operators used to combine conditions in programming, returning a boolean value (true or false) based on the evaluation of those conditions. There are six primary boolean operators:\n\n1. `AND` (\u0026\u0026): Returns true if both conditions are true.\n2. `OR` (||): Returns true if either condition is true.\n3. `NOT` (!): Returns the opposite of the condition, i.e., true if the condition is false, and false if the condition is true.\n\nHere are some examples of how boolean operators work in programming:\n\n1. `(x == 5) \u0026\u0026 (y \u003e= 10)` returns true only if both `x` is 5 and `y` is greater than or equal to 10.\n2. `(x \u003e 10) || (y \u003c 0)` returns true if either `x` is greater than 10 or `y` is less than 0.\n3. `!(x == y)` returns true if `x` is not equal to `y`.\n\nOperator precedence in boolean expressions determines the order in which the conditions are evaluated. It is similar to operator precedence in arithmetic expressions. Here is the order of precedence:\n\n1. `NOT` (!)\n2. `||` (OR)\n3. `\u0026\u0026` (AND)\n\nFor example, `(x \u003e 10) || (y \u003c 0)` has higher precedence than `!(x == y)`, so the expression `(x \u003e 10) || (y \u003c 0)` is evaluated before `!(x == y)`.\n\nShort-circuit evaluation is a feature of some programming languages that allows the evaluation of a boolean expression to stop as soon as the truth value has been determined. This means that if the first condition in the boolean expression is false, the second condition will not be evaluated.\n\nFor example, in C#, the expression `(x \u003e 10) || (y \u003c 0)` is short-circuit evaluated, so `y` is not evaluated if `x` is greater than 10.\n\nNormal evaluation, on the other hand, evaluates both conditions even if one of them is false.\n\nTo implement short-circuit evaluation in a language that does not support it natively, you can use a technique called \"parenthesizing\" the boolean expression, which forces the language to evaluate the expression in a way that mimics short-circuit evaluation. This can be done by using parentheses to group the conditions in a way that causes the language to evaluate the expression in a short-circuit manner.\n\nHere is an example of how to implement short-circuit evaluation in Python:\n\n```python\ndef short_circuit(x, y):\n return (x \u003e 0) or (y \u003c 10)\n```\n\nIn this example, the function `short_circuit` takes two arguments `x` and `y`. The expression `(x \u003e 0) or (y \u003c 10)` is short-circuit evaluated, so `y` is not evaluated if `x` is greater than 0.\n\nTruthiness and falsiness in programming languages are concepts that determine whether a value is considered \"true\" or \"false\" in a boolean context. The truthiness of a value depends on its type and the language\u0027s boolean implementation.\n\nFor example, in Python, the following values are considered falsy:\n\n- Empty strings (`\"\"`),\n- Empty lists (`[]`),\n- Empty dictionaries (`{}`),\n- Empty sets (`set()`),\n- None,\n- Zero (integers, floats, etc.),\n- False.\n\nOn the other hand, the following values are considered truthy:\n\n- Non-empty strings (`\"hello\"`),\n- Non-empty lists (`[1, 2, 3]`),\n- Non-empty dictionaries (`{\"a\": 1, \"b\": 2}`),\n- Non-empty sets (`{1, 2, 3}`),\n- True,\n- All non-empty values.\n\nTo handle cases where truthiness and falsiness are implemented differently across different programming languages, you can write code that checks the type of the value and handles it accordingly. For example, in Python:\n\n```python\ndef handle_truthiness(value):\n if not isinstance(value, (str, list, dict, set)):\n return False\n if value:\n return True\n return False\n```\n\nThis function checks the type of the value and returns `True` if the value is a string, list, dictionary, or set, and `False` otherwise. It then checks the value for truthyness by returning `True` if the value is not empty",
"llm_text_generation_vllm_logprobs": [
[
{
"logprob": -0.06034397706389427,
"token": "Boolean"
},
{
"logprob": -4.082690238952637,
"token": "Sure"
},
{
"logprob": -4.082690238952637,
"token": "I"
},
{
"logprob": -4.887158393859863,
"token": "B"
},
{
"logprob": -5.5128583908081055,
"token": "Hello"
},
{
"logprob": -5.87039852142334,
"token": "In"
},
{
"logprob": -6.317326545715332,
"token": "A"
},
{
"logprob": -6.764254570007324,
"token": "boolean"
},
{
"logprob": -6.764254570007324,
"token": "1"
},
{
"logprob": -6.943024635314941,
"token": "As"
},
{
"logprob": -7.121796607971191,
"token": "**"
},
{
"logprob": -7.568722724914551,
"token": "What"
},
{
"logprob": -7.568722724914551,
"token": "Here"
},
{
"logprob": -7.747494697570801,
"token": "Certainly"
},
{
"logprob": -7.926264762878418,
"token": "Let"
},
{
"logprob": -7.926264762878418,
"token": "#"
},
{
"logprob": -8.820120811462402,
"token": "Absol"
},
{
"logprob": -8.909504890441895,
"token": "Welcome"
},
{
"logprob": -9.088276863098145,
"token": " Boolean"
},
{
"logprob": -9.17766284942627,
"token": "\u003c"
}
],
[
{
"logprob": -0.1830323338508606,
"token": " operators"
},
{
"logprob": -1.7919704914093018,
"token": " Oper"
},
{
"logprob": -8.406495094299316,
"token": " expressions"
},
{
"logprob": -8.585265159606934,
"token": " operations"
},
{
"logprob": -9.479121208190918,
"token": " values"
},
{
"logprob": -10.283589363098145,
"token": " logic"
},
{
"logprob": -10.641131401062012,
"token": " Operations"
},
{
"logprob": -10.819903373718262,
"token": " operator"
},
{
"logprob": -11.445601463317871,
"token": " Logic"
},
{
"logprob": -11.713757514953613,
"token": " algebra"
},
{
"logprob": -11.803143501281738,
"token": " oper"
},
{
"logprob": -11.89252758026123,
"token": "Oper"
},
{
"logprob": -11.981913566589355,
"token": " Algebra"
},
{
"logprob": -12.07129955291748,
"token": " O"
},
{
"logprob": -12.339455604553223,
"token": " variables"
},
{
"logprob": -12.87576961517334,
"token": "oper"
},
{
"logprob": -13.50146770477295,
"token": " Values"
},
{
"logprob": -13.769623756408691,
"token": " Expressions"
},
{
"logprob": -13.859009742736816,
"token": " and"
},
{
"logprob": -13.948393821716309,
"token": " Variables"
}
],
[
{
"logprob": -0.05496400222182274,
"token": " are"
},
{
"logprob": -3.2728404998779297,
"token": ","
},
{
"logprob": -4.881780624389648,
"token": ":"
},
{
"logprob": -5.596864700317383,
"token": " in"
},
{
"logprob": -5.95440673828125,
"token": "\n"
},
{
"logprob": -6.848260879516602,
"token": " and"
},
{
"logprob": -8.814741134643555,
"token": " allow"
},
{
"logprob": -9.172283172607422,
"token": " perform"
},
{
"logprob": -9.172283172607422,
"token": " ("
},
{
"logprob": -10.066137313842773,
"token": "!"
},
{
"logprob": -10.244909286499023,
"token": " can"
},
{
"logprob": -10.60245132446289,
"token": " play"
},
{
"logprob": -10.60245132446289,
"token": " -"
},
{
"logprob": -11.138763427734375,
"token": " or"
},
{
"logprob": -11.138763427734375,
"token": " refer"
},
{
"logprob": -11.138763427734375,
"token": " form"
},
{
"logprob": -11.317535400390625,
"token": "\n\n"
},
{
"logprob": -11.496305465698242,
"token": " act"
},
{
"logprob": -11.496305465698242,
"token": " take"
},
{
"logprob": -11.67507553100586,
"token": " have"
}
],
[
{
"logprob": -1.8189913034439087,
"token": " operators"
},
{
"logprob": -1.1039072275161743,
"token": " a"
},
{
"logprob": -1.1039072275161743,
"token": " logical"
},
{
"logprob": -3.070387363433838,
"token": " special"
},
{
"logprob": -3.070387363433838,
"token": " used"
},
{
"logprob": -3.249159336090088,
"token": " symbols"
},
{
"logprob": -4.3217854499816895,
"token": " fundamental"
},
{
"logprob": -5.394411563873291,
"token": " logic"
},
{
"logprob": -5.573181629180908,
"token": " simple"
},
{
"logprob": -5.751951694488525,
"token": " operations"
},
{
"logprob": -5.751951694488525,
"token": " the"
},
{
"logprob": -5.930723667144775,
"token": " binary"
},
{
"logprob": -6.109493732452393,
"token": " expressions"
},
{
"logprob": -6.46703577041626,
"token": " programming"
},
{
"logprob": -6.64580774307251,
"token": " functions"
},
{
"logprob": -7.003349781036377,
"token": " basic"
},
{
"logprob": -7.182119846343994,
"token": " shorthand"
},
{
"logprob": -7.360891819000244,
"token": " an"
},
{
"logprob": -7.539661884307861,
"token": " mathematical"
},
{
"logprob": -8.075974464416504,
"token": " control"
}
],
[
{
"logprob": -1.5109121799468994,
"token": " used"
},
{
"logprob": -0.25951603055000305,
"token": " that"
},
{
"logprob": -4.9075608253479,
"token": " in"
},
{
"logprob": -8.125436782836914,
"token": " which"
},
{
"logprob": -9.376832962036133,
"token": " designed"
},
{
"logprob": -10.628231048583984,
"token": " specifically"
},
{
"logprob": -11.164543151855469,
"token": " or"
},
{
"logprob": -11.343315124511719,
"token": " for"
},
{
"logprob": -11.522085189819336,
"token": ","
},
{
"logprob": -12.05839729309082,
"token": " whose"
},
{
"logprob": -12.23716926574707,
"token": " commonly"
},
{
"logprob": -12.23716926574707,
"token": " utilized"
},
{
"logprob": -12.23716926574707,
"token": " with"
},
{
"logprob": -12.952253341674805,
"token": " within"
},
{
"logprob": -13.309795379638672,
"token": " such"
},
{
"logprob": -13.488565444946289,
"token": " like"
},
{
"logprob": -13.846107482910156,
"token": " applied"
},
{
"logprob": -13.846107482910156,
"token": " ("
},
{
"logprob": -14.024879455566406,
"token": " to"
},
{
"logprob": -14.024879455566406,
"token": " of"
}
],
[
{
"logprob": -0.1652197688817978,
"token": " to"
},
{
"logprob": -1.952928066253662,
"token": " in"
},
{
"logprob": -4.63449239730835,
"token": " for"
},
{
"logprob": -7.6735968589782715,
"token": " with"
},
{
"logprob": -8.388680458068848,
"token": " within"
},
{
"logprob": -11.78532886505127,
"token": " on"
},
{
"logprob": -11.96410083770752,
"token": " primarily"
},
{
"logprob": -12.142870903015137,
"token": " by"
},
{
"logprob": -12.500412940979004,
"token": " as"
},
{
"logprob": -13.394267082214355,
"token": " extensively"
},
{
"logprob": -13.394267082214355,
"token": " when"
},
{
"logprob": -13.394267082214355,
"token": " specifically"
},
{
"logprob": -13.930581092834473,
"token": " together"
},
{
"logprob": -13.930581092834473,
"token": " exclusively"
},
{
"logprob": -15.003207206726074,
"token": " inside"
},
{
"logprob": -15.181977272033691,
"token": " solely"
},
{
"logprob": -15.181977272033691,
"token": " along"
},
{
"logprob": -15.360749244689941,
"token": " mainly"
},
{
"logprob": -15.539519309997559,
"token": " during"
},
{
"logprob": -16.612146377563477,
"token": " commonly"
}
],
[
{
"logprob": -2.2875277996063232,
"token": " combine"
},
{
"logprob": -1.0361316204071045,
"token": " manipulate"
},
{
"logprob": -1.0361316204071045,
"token": " perform"
},
{
"logprob": -2.4662997722625732,
"token": " evaluate"
},
{
"logprob": -3.717695951461792,
"token": " compare"
},
{
"logprob": -3.717695951461792,
"token": " form"
},
{
"logprob": -4.611550331115723,
"token": " test"
},
{
"logprob": -4.611550331115723,
"token": " create"
},
{
"logprob": -4.96909236907959,
"token": " control"
},
{
"logprob": -5.14786434173584,
"token": " make"
},
{
"logprob": -5.684176445007324,
"token": " produce"
},
{
"logprob": -5.862946510314941,
"token": " determine"
},
{
"logprob": -6.041718482971191,
"token": " work"
},
{
"logprob": -6.220488548278809,
"token": " connect"
},
{
"logprob": -6.220488548278809,
"token": " execute"
},
{
"logprob": -6.578030586242676,
"token": " return"
},
{
"logprob": -6.935572624206543,
"token": " construct"
},
{
"logprob": -7.114344596862793,
"token": " check"
},
{
"logprob": -7.114344596862793,
"token": " operate"
},
{
"logprob": -7.47188663482666,
"token": " express"
}
],
[
{
"logprob": -0.7143782377243042,
"token": " conditions"
},
{
"logprob": -1.965774416923523,
"token": " values"
},
{
"logprob": -2.1445465087890625,
"token": " boolean"
},
{
"logprob": -2.5020885467529297,
"token": " or"
},
{
"logprob": -3.038400650024414,
"token": " one"
},
{
"logprob": -3.3959426879882812,
"token": " two"
},
{
"logprob": -3.9322547912597656,
"token": " conditional"
},
{
"logprob": -3.9322547912597656,
"token": " and"
},
{
"logprob": -3.9322547912597656,
"token": " expressions"
},
{
"logprob": -4.82611083984375,
"token": " multiple"
},
{
"logprob": -5.004880905151367,
"token": " statements"
},
{
"logprob": -5.541194915771484,
"token": " Boolean"
},
{
"logprob": -5.541194915771484,
"token": " simple"
},
{
"logprob": -5.719964981079102,
"token": " logical"
},
{
"logprob": -7.3289031982421875,
"token": " relational"
},
{
"logprob": -7.3289031982421875,
"token": " true"
},
{
"logprob": -7.686445236206055,
"token": " logic"
},
{
"logprob": -7.686445236206055,
"token": " condition"
},
{
"logprob": -7.686445236206055,
"token": " the"
},
{
"logprob": -7.865217208862305,
"token": " truth"
}
],
[
{
"logprob": -0.11622606217861176,
"token": " in"
},
{
"logprob": -2.619018316268921,
"token": " or"
},
{
"logprob": -4.406726837158203,
"token": " and"
},
{
"logprob": -4.585498809814453,
"token": " to"
},
{
"logprob": -5.6581268310546875,
"token": "."
},
{
"logprob": -5.836894989013672,
"token": " using"
},
{
"logprob": -5.836894989013672,
"token": ","
},
{
"logprob": -6.730751037597656,
"token": " into"
},
{
"logprob": -6.909521102905273,
"token": " within"
},
{
"logprob": -7.267063140869141,
"token": " with"
},
{
"logprob": -7.267063140869141,
"token": " that"
},
{
"logprob": -7.445835113525391,
"token": " based"
},
{
"logprob": -7.803377151489258,
"token": " for"
},
{
"logprob": -8.51845932006836,
"token": " of"
},
{
"logprob": -9.591085433959961,
"token": " from"
},
{
"logprob": -9.591085433959961,
"token": " together"
},
{
"logprob": -9.769857406616211,
"token": " ("
},
{
"logprob": -11.200023651123047,
"token": " when"
},
{
"logprob": -11.200023651123047,
"token": " inside"
},
{
"logprob": -11.378795623779297,
"token": " by"
}
],
[
{
"logprob": -0.46720749139785767,
"token": " programming"
},
{
"logprob": -1.1822915077209473,
"token": " a"
},
{
"logprob": -3.1487717628479004,
"token": " conditional"
},
{
"logprob": -4.221397876739502,
"token": " an"
},
{
"logprob": -6.545420169830322,
"token": " programs"
},
{
"logprob": -6.7241902351379395,
"token": " logic"
},
{
"logprob": -6.7241902351379395,
"token": " order"
},
{
"logprob": -6.9029622077941895,
"token": " logical"
},
{
"logprob": -7.081732273101807,
"token": " code"
},
{
"logprob": -7.081732273101807,
"token": " boolean"
},
{
"logprob": -7.796816349029541,
"token": " if"
},
{
"logprob": -7.975588321685791,
"token": " expressions"
},
{
"logprob": -8.154358863830566,
"token": " the"
},
{
"logprob": -8.511900901794434,
"token": " program"
},
{
"logprob": -8.511900901794434,
"token": " Boolean"
},
{
"logprob": -8.69067096710205,
"token": " computer"
},
{
"logprob": -8.8694429397583,
"token": " your"
},
{
"logprob": -9.048213005065918,
"token": " control"
},
{
"logprob": -9.048213005065918,
"token": " Python"
},
{
"logprob": -9.226984977722168,
"token": " conditions"
}
],
"... (truncated - showing 10 of 1024 elements)"
],
"messages": [
{
"content": "Explain what boolean operators are, what they do, and provide examples of how they can be used in programming. Additionally, describe the concept of operator precedence and provide examples of how it affects the evaluation of boolean expressions. Discuss the difference between short-circuit evaluation and normal evaluation in boolean expressions and demonstrate their usage in code. \n\nFurthermore, add the requirement that the code must be written in a language that does not support short-circuit evaluation natively, forcing the test taker to implement their own logic for short-circuit evaluation.\n\nFinally, delve into the concept of truthiness and falsiness in programming languages, explaining how it affects the evaluation of boolean expressions. Add the constraint that the test taker must write code that handles cases where truthiness and falsiness are implemented differently across different programming languages.",
"role": "user"
}
],
"model_name": "HuggingFaceTB/SmolLM2-1.7B-Instruct",
"score": 5.212620735168457,
"source": "infini-instruct-top-500k"
}
```
This subset can be loaded as:
```python
from datasets import load_dataset
ds = load_dataset("gabrielmbmb/logprobs", "default")
```
Or simply as it follows, since there's only one configuration and is named `default`:
```python
from datasets import load_dataset
ds = load_dataset("gabrielmbmb/logprobs")
```
</details>
|
maniro-ai/20241210_validation_cover-workspace_rotmat | maniro-ai | "2024-12-10T15:49:16Z" | 8 | 0 | [
"task_categories:robotics",
"region:us",
"LeRobot"
] | [
"robotics"
] | "2024-12-10T15:49:11Z" | ---
task_categories:
- robotics
tags:
- LeRobot
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
|
haydn-jones/PubChem | haydn-jones | "2024-12-11T03:47:13Z" | 8 | 0 | [
"size_categories:100M<n<1B",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"chemistry",
"biology",
"medical"
] | null | "2024-12-10T21:32:34Z" | ---
dataset_info:
features:
- name: CID
dtype: int64
- name: SMILES
dtype: large_string
- name: SELFIES
dtype: string
splits:
- name: train
num_bytes: 36600584436.0
num_examples: 119009905
download_size: 9179713025
dataset_size: 36600584436.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- chemistry
- biology
- medical
size_categories:
- 100M<n<1B
---
|
ziyou-li/cantonese_processed_daily | ziyou-li | "2022-12-08T22:41:45Z" | 7 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2022-12-08T22:40:55Z" | ---
dataset_info:
features:
- name: input_features
sequence:
sequence: float32
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 3899650216
num_examples: 4060
download_size: 623179139
dataset_size: 3899650216
---
# Dataset Card for "cantonese_processed_daily"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
athugodage/legal_simplification_corpus | athugodage | "2023-03-16T20:18:43Z" | 7 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | null | "2023-03-11T08:03:06Z" | ---
dataset_info:
features:
- name: Текст
dtype: string
- name: Комментарий РГ
dtype: string
splits:
- name: train
num_bytes: 118357564.79574679
num_examples: 1819
- name: test
num_bytes: 13208678.204253215
num_examples: 203
download_size: 42722724
dataset_size: 131566243.0
---
# Dataset Card for "legal_simplification_corpus"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |