
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Pandas
[Pandas](https://github.com/pandas-dev/pandas) is a widely used Python data analysis toolkit.
Since it uses [fsspec](https://filesystem-spec.readthedocs.io) to read and write remote data, you can use the Hugging Face paths ([`hf://`](https://huggingface.co/docs/huggingface_hub/guides/hf_file_system#integrations)) to read and write data on the Hub:
First you need to [Login with your Hugging Face account](../huggingface_hub/quick-start#login), for example using:
```
huggingface-cli login
```
Then you can [Create a dataset repository](../huggingface_hub/quick-start#create-a-repository), for example using:
```python
from huggingface_hub import HfApi
HfApi().create_repo(repo_id="username/my_dataset", repo_type="dataset")
```
Finally, you can use [Hugging Face paths]([Hugging Face paths](https://huggingface.co/docs/huggingface_hub/guides/hf_file_system#integrations)) in Pandas:
```python
import pandas as pd
df.to_parquet("hf://datasets/username/my_dataset/data.parquet")
# or write in separate files if the dataset has train/validation/test splits
df_train.to_parquet("hf://datasets/username/my_dataset/train.parquet")
df_valid.to_parquet("hf://datasets/username/my_dataset/validation.parquet")
df_test .to_parquet("hf://datasets/username/my_dataset/test.parquet")
```
This creates a dataset repository `username/my_dataset` containing your Pandas dataset in Parquet format.
You can reload it later:
```python
import pandas as pd
df = pd.read_parquet("hf://datasets/username/my_dataset/data.parquet")
# or read from separate files if the dataset has train/validation/test splits
df_train = pd.read_parquet("hf://datasets/username/my_dataset/train.parquet")
df_valid = pd.read_parquet("hf://datasets/username/my_dataset/validation.parquet")
df_test = pd.read_parquet("hf://datasets/username/my_dataset/test.parquet")
```
To have more information on the Hugging Face paths and how they are implemented, please refer to the [the client library's documentation on the HfFileSystem](https://huggingface.co/docs/huggingface_hub/guides/hf_file_system).
| huggingface/hub-docs/blob/main/docs/hub/datasets-pandas.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Manage your Space
In this guide, we will see how to manage your Space runtime
([secrets](https://huggingface.co/docs/hub/spaces-overview#managing-secrets),
[hardware](https://huggingface.co/docs/hub/spaces-gpus), and [storage](https://huggingface.co/docs/hub/spaces-storage#persistent-storage)) using `huggingface_hub`.
## A simple example: configure secrets and hardware.
Here is an end-to-end example to create and setup a Space on the Hub.
**1. Create a Space on the Hub.**
```py
>>> from huggingface_hub import HfApi
>>> repo_id = "Wauplin/my-cool-training-space"
>>> api = HfApi()
# For example with a Gradio SDK
>>> api.create_repo(repo_id=repo_id, repo_type="space", space_sdk="gradio")
```
**1. (bis) Duplicate a Space.**
This can prove useful if you want to build up from an existing Space instead of starting from scratch.
It is also useful is you want control over the configuration/settings of a public Space. See [`duplicate_space`] for more details.
```py
>>> api.duplicate_space("multimodalart/dreambooth-training")
```
**2. Upload your code using your preferred solution.**
Here is an example to upload the local folder `src/` from your machine to your Space:
```py
>>> api.upload_folder(repo_id=repo_id, repo_type="space", folder_path="src/")
```
At this step, your app should already be running on the Hub for free !
However, you might want to configure it further with secrets and upgraded hardware.
**3. Configure secrets and variables**
Your Space might require some secret keys, token or variables to work.
See [docs](https://huggingface.co/docs/hub/spaces-overview#managing-secrets) for more details.
For example, an HF token to upload an image dataset to the Hub once generated from your Space.
```py
>>> api.add_space_secret(repo_id=repo_id, key="HF_TOKEN", value="hf_api_***")
>>> api.add_space_variable(repo_id=repo_id, key="MODEL_REPO_ID", value="user/repo")
```
Secrets and variables can be deleted as well:
```py
>>> api.delete_space_secret(repo_id=repo_id, key="HF_TOKEN")
>>> api.delete_space_variable(repo_id=repo_id, key="MODEL_REPO_ID")
```
<Tip>
From within your Space, secrets are available as environment variables (or
Streamlit Secrets Management if using Streamlit). No need to fetch them via the API!
</Tip>
<Tip warning={true}>
Any change in your Space configuration (secrets or hardware) will trigger a restart of your app.
</Tip>
**Bonus: set secrets and variables when creating or duplicating the Space!**
Secrets and variables can be set when creating or duplicating a space:
```py
>>> api.create_repo(
... repo_id=repo_id,
... repo_type="space",
... space_sdk="gradio",
... space_secrets=[{"key"="HF_TOKEN", "value"="hf_api_***"}, ...],
... space_variables=[{"key"="MODEL_REPO_ID", "value"="user/repo"}, ...],
... )
```
```py
>>> api.duplicate_space(
... from_id=repo_id,
... secrets=[{"key"="HF_TOKEN", "value"="hf_api_***"}, ...],
... variables=[{"key"="MODEL_REPO_ID", "value"="user/repo"}, ...],
... )
```
**4. Configure the hardware**
By default, your Space will run on a CPU environment for free. You can upgrade the hardware
to run it on GPUs. A payment card or a community grant is required to access upgrade your
Space. See [docs](https://huggingface.co/docs/hub/spaces-gpus) for more details.
```py
# Use `SpaceHardware` enum
>>> from huggingface_hub import SpaceHardware
>>> api.request_space_hardware(repo_id=repo_id, hardware=SpaceHardware.T4_MEDIUM)
# Or simply pass a string value
>>> api.request_space_hardware(repo_id=repo_id, hardware="t4-medium")
```
Hardware updates are not done immediately as your Space has to be reloaded on our servers.
At any time, you can check on which hardware your Space is running to see if your request
has been met.
```py
>>> runtime = api.get_space_runtime(repo_id=repo_id)
>>> runtime.stage
"RUNNING_BUILDING"
>>> runtime.hardware
"cpu-basic"
>>> runtime.requested_hardware
"t4-medium"
```
You now have a Space fully configured. Make sure to downgrade your Space back to "cpu-classic"
when you are done using it.
**Bonus: request hardware when creating or duplicating the Space!**
Upgraded hardware will be automatically assigned to your Space once it's built.
```py
>>> api.create_repo(
... repo_id=repo_id,
... repo_type="space",
... space_sdk="gradio"
... space_hardware="cpu-upgrade",
... space_storage="small",
... space_sleep_time="7200", # 2 hours in secs
... )
```
```py
>>> api.duplicate_space(
... from_id=repo_id,
... hardware="cpu-upgrade",
... storage="small",
... sleep_time="7200", # 2 hours in secs
... )
```
**5. Pause and restart your Space**
By default if your Space is running on an upgraded hardware, it will never be stopped. However to avoid getting billed,
you might want to pause it when you are not using it. This is possible using [`pause_space`]. A paused Space will be
inactive until the owner of the Space restarts it, either with the UI or via API using [`restart_space`].
For more details about paused mode, please refer to [this section](https://huggingface.co/docs/hub/spaces-gpus#pause)
```py
# Pause your Space to avoid getting billed
>>> api.pause_space(repo_id=repo_id)
# (...)
# Restart it when you need it
>>> api.restart_space(repo_id=repo_id)
```
Another possibility is to set a timeout for your Space. If your Space is inactive for more than the timeout duration,
it will go to sleep. Any visitor landing on your Space will start it back up. You can set a timeout using
[`set_space_sleep_time`]. For more details about sleeping mode, please refer to [this section](https://huggingface.co/docs/hub/spaces-gpus#sleep-time).
```py
# Put your Space to sleep after 1h of inactivity
>>> api.set_space_sleep_time(repo_id=repo_id, sleep_time=3600)
```
Note: if you are using a 'cpu-basic' hardware, you cannot configure a custom sleep time. Your Space will automatically
be paused after 48h of inactivity.
**Bonus: set a sleep time while requesting hardware**
Upgraded hardware will be automatically assigned to your Space once it's built.
```py
>>> api.request_space_hardware(repo_id=repo_id, hardware=SpaceHardware.T4_MEDIUM, sleep_time=3600)
```
**Bonus: set a sleep time when creating or duplicating the Space!**
```py
>>> api.create_repo(
... repo_id=repo_id,
... repo_type="space",
... space_sdk="gradio"
... space_hardware="t4-medium",
... space_sleep_time="3600",
... )
```
```py
>>> api.duplicate_space(
... from_id=repo_id,
... hardware="t4-medium",
... sleep_time="3600",
... )
```
**6. Add persistent storage to your Space**
You can choose the storage tier of your choice to access disk space that persists across restarts of your Space. This means you can read and write from disk like you would with a traditional hard drive. See [docs](https://huggingface.co/docs/hub/spaces-storage#persistent-storage) for more details.
```py
>>> from huggingface_hub import SpaceStorage
>>> api.request_space_storage(repo_id=repo_id, storage=SpaceStorage.LARGE)
```
You can also delete your storage, losing all the data permanently.
```py
>>> api.delete_space_storage(repo_id=repo_id)
```
Note: You cannot decrease the storage tier of your space once it's been granted. To do so,
you must delete the storage first then request the new desired tier.
**Bonus: request storage when creating or duplicating the Space!**
```py
>>> api.create_repo(
... repo_id=repo_id,
... repo_type="space",
... space_sdk="gradio"
... space_storage="large",
... )
```
```py
>>> api.duplicate_space(
... from_id=repo_id,
... storage="large",
... )
```
## More advanced: temporarily upgrade your Space !
Spaces allow for a lot of different use cases. Sometimes, you might want
to temporarily run a Space on a specific hardware, do something and then shut it down. In
this section, we will explore how to benefit from Spaces to finetune a model on demand.
This is only one way of solving this particular problem. It has to be taken as a suggestion
and adapted to your use case.
Let's assume we have a Space to finetune a model. It is a Gradio app that takes as input
a model id and a dataset id. The workflow is as follows:
0. (Prompt the user for a model and a dataset)
1. Load the model from the Hub.
2. Load the dataset from the Hub.
3. Finetune the model on the dataset.
4. Upload the new model to the Hub.
Step 3. requires a custom hardware but you don't want your Space to be running all the time on a paid
GPU. A solution is to dynamically request hardware for the training and shut it
down afterwards. Since requesting hardware restarts your Space, your app must somehow "remember"
the current task it is performing. There are multiple ways of doing this. In this guide
we will see one solution using a Dataset as "task scheduler".
### App skeleton
Here is what your app would look like. On startup, check if a task is scheduled and if yes,
run it on the correct hardware. Once done, set back hardware to the free-plan CPU and
prompt the user for a new task.
<Tip warning={true}>
Such a workflow does not support concurrent access as normal demos.
In particular, the interface will be disabled when training occurs.
It is preferable to set your repo as private to ensure you are the only user.
</Tip>
```py
# Space will need your token to request hardware: set it as a Secret !
HF_TOKEN = os.environ.get("HF_TOKEN")
# Space own repo_id
TRAINING_SPACE_ID = "Wauplin/dreambooth-training"
from huggingface_hub import HfApi, SpaceHardware
api = HfApi(token=HF_TOKEN)
# On Space startup, check if a task is scheduled. If yes, finetune the model. If not,
# display an interface to request a new task.
task = get_task()
if task is None:
# Start Gradio app
def gradio_fn(task):
# On user request, add task and request hardware
add_task(task)
api.request_space_hardware(repo_id=TRAINING_SPACE_ID, hardware=SpaceHardware.T4_MEDIUM)
gr.Interface(fn=gradio_fn, ...).launch()
else:
runtime = api.get_space_runtime(repo_id=TRAINING_SPACE_ID)
# Check if Space is loaded with a GPU.
if runtime.hardware == SpaceHardware.T4_MEDIUM:
# If yes, finetune base model on dataset !
train_and_upload(task)
# Then, mark the task as "DONE"
mark_as_done(task)
# DO NOT FORGET: set back CPU hardware
api.request_space_hardware(repo_id=TRAINING_SPACE_ID, hardware=SpaceHardware.CPU_BASIC)
else:
api.request_space_hardware(repo_id=TRAINING_SPACE_ID, hardware=SpaceHardware.T4_MEDIUM)
```
### Task scheduler
Scheduling tasks can be done in many ways. Here is an example how it could be done using
a simple CSV stored as a Dataset.
```py
# Dataset ID in which a `tasks.csv` file contains the tasks to perform.
# Here is a basic example for `tasks.csv` containing inputs (base model and dataset)
# and status (PENDING or DONE).
# multimodalart/sd-fine-tunable,Wauplin/concept-1,DONE
# multimodalart/sd-fine-tunable,Wauplin/concept-2,PENDING
TASK_DATASET_ID = "Wauplin/dreambooth-task-scheduler"
def _get_csv_file():
return hf_hub_download(repo_id=TASK_DATASET_ID, filename="tasks.csv", repo_type="dataset", token=HF_TOKEN)
def get_task():
with open(_get_csv_file()) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
if row[2] == "PENDING":
return row[0], row[1] # model_id, dataset_id
def add_task(task):
model_id, dataset_id = task
with open(_get_csv_file()) as csv_file:
with open(csv_file, "r") as f:
tasks = f.read()
api.upload_file(
repo_id=repo_id,
repo_type=repo_type,
path_in_repo="tasks.csv",
# Quick and dirty way to add a task
path_or_fileobj=(tasks + f"\n{model_id},{dataset_id},PENDING").encode()
)
def mark_as_done(task):
model_id, dataset_id = task
with open(_get_csv_file()) as csv_file:
with open(csv_file, "r") as f:
tasks = f.read()
api.upload_file(
repo_id=repo_id,
repo_type=repo_type,
path_in_repo="tasks.csv",
# Quick and dirty way to set the task as DONE
path_or_fileobj=tasks.replace(
f"{model_id},{dataset_id},PENDING",
f"{model_id},{dataset_id},DONE"
).encode()
)
``` | huggingface/huggingface_hub/blob/main/docs/source/en/guides/manage-spaces.md |
his simple demo takes advantage of Gradio's HighlightedText, JSON and HTML outputs to create a clear NER segmentation. | gradio-app/gradio/blob/main/demo/text_analysis/DESCRIPTION.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Research projects
This folder contains various research projects using 🤗 Transformers. They are not maintained and require a specific
version of 🤗 Transformers that is indicated in the requirements file of each folder. Updating them to the most recent version of the library will require some work.
To use any of them, just run the command
```
pip install -r requirements.txt
```
inside the folder of your choice.
If you need help with any of those, contact the author(s), indicated at the top of the `README` of each folder.
| huggingface/transformers/blob/main/examples/research_projects/README.md |
`@gradio/video`
```javascript
<script>
import { BaseInteractiveVideo, BaseStaticVideo, BasePlayer } from "@gradio/button";
import type { FileData } from "@gradio/upload";
import type { Gradio } from "@gradio/utils";
export let _video: FileData;
</script>
<StaticVideo
value={_video}
{label}
{show_label}
{autoplay}
{show_share_button}
i18n={gradio.i18n}
/>
<Video
value={_video}
{label}
{show_label}
source={"upload"}
{mirror_webcam}
{include_audio}
{autoplay}
i18n={gradio.i18n}
>
<p>Upload Video Here</p>
</Video>
<BasePlayer
src={value.data}
{autoplay}
on:play
on:pause
on:stop
on:end
mirror={false}
{label}
/>
```
| gradio-app/gradio/blob/main/js/video/README.md |
Table Classes
Each `Dataset` object is backed by a PyArrow Table.
A Table can be loaded from either the disk (memory mapped) or in memory.
Several Table types are available, and they all inherit from [`table.Table`].
## Table
[[autodoc]] datasets.table.Table
- validate
- equals
- to_batches
- to_pydict
- to_pandas
- to_string
- field
- column
- itercolumns
- schema
- columns
- num_columns
- num_rows
- shape
- nbytes
## InMemoryTable
[[autodoc]] datasets.table.InMemoryTable
- validate
- equals
- to_batches
- to_pydict
- to_pandas
- to_string
- field
- column
- itercolumns
- schema
- columns
- num_columns
- num_rows
- shape
- nbytes
- column_names
- slice
- filter
- flatten
- combine_chunks
- cast
- replace_schema_metadata
- add_column
- append_column
- remove_column
- set_column
- rename_columns
- select
- drop
- from_file
- from_buffer
- from_pandas
- from_arrays
- from_pydict
- from_batches
## MemoryMappedTable
[[autodoc]] datasets.table.MemoryMappedTable
- validate
- equals
- to_batches
- to_pydict
- to_pandas
- to_string
- field
- column
- itercolumns
- schema
- columns
- num_columns
- num_rows
- shape
- nbytes
- column_names
- slice
- filter
- flatten
- combine_chunks
- cast
- replace_schema_metadata
- add_column
- append_column
- remove_column
- set_column
- rename_columns
- select
- drop
- from_file
## ConcatenationTable
[[autodoc]] datasets.table.ConcatenationTable
- validate
- equals
- to_batches
- to_pydict
- to_pandas
- to_string
- field
- column
- itercolumns
- schema
- columns
- num_columns
- num_rows
- shape
- nbytes
- column_names
- slice
- filter
- flatten
- combine_chunks
- cast
- replace_schema_metadata
- add_column
- append_column
- remove_column
- set_column
- rename_columns
- select
- drop
- from_blocks
- from_tables
## Utils
[[autodoc]] datasets.table.concat_tables
[[autodoc]] datasets.table.list_table_cache_files
| huggingface/datasets/blob/main/docs/source/package_reference/table_classes.mdx |
--
title: Training Stable Diffusion with Dreambooth using Diffusers
thumbnail: /blog/assets/sd_dreambooth_training/thumbnail.jpg
authors:
- user: valhalla
- user: pcuenq
- user: 9of9
guest: true
---
# Training Stable Diffusion with Dreambooth using 🧨 Diffusers
[Dreambooth](https://dreambooth.github.io/) is a technique to teach new concepts to [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) using a specialized form of fine-tuning. Some people have been using it with a few of their photos to place themselves in fantastic situations, while others are using it to incorporate new styles. [🧨 Diffusers](https://github.com/huggingface/diffusers) provides a Dreambooth [training script](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth). It doesn't take long to train, but it's hard to select the right set of hyperparameters and it's easy to overfit.
We conducted a lot of experiments to analyze the effect of different settings in Dreambooth. This post presents our findings and some tips to improve your results when fine-tuning Stable Diffusion with Dreambooth.
Before we start, please be aware that this method should never be used for malicious purposes, to generate harm in any way, or to impersonate people without their knowledge. Models trained with it are still bound by the [CreativeML Open RAIL-M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) that governs distribution of Stable Diffusion models.
_Note: a previous version of this post was published [as a W&B report](https://wandb.ai/psuraj/dreambooth/reports/Dreambooth-Training-Analysis--VmlldzoyNzk0NDc3)_.
## TL;DR: Recommended Settings
* Dreambooth tends to overfit quickly. To get good-quality images, we must find a 'sweet spot' between the number of training steps and the learning rate. We recommend using a low learning rate and progressively increasing the number of steps until the results are satisfactory.
* Dreambooth needs more training steps for faces. In our experiments, 800-1200 steps worked well when using a batch size of 2 and LR of 1e-6.
* Prior preservation is important to avoid overfitting when training on faces. For other subjects, it doesn't seem to make a huge difference.
* If you see that the generated images are noisy or the quality is degraded, it likely means overfitting. First, try the steps above to avoid it. If the generated images are still noisy, use the DDIM scheduler or run more inference steps (~100 worked well in our experiments).
* Training the text encoder in addition to the UNet has a big impact on quality. Our best results were obtained using a combination of text encoder fine-tuning, low LR, and a suitable number of steps. However, fine-tuning the text encoder requires more memory, so a GPU with at least 24 GB of RAM is ideal. Using techniques like 8-bit Adam, `fp16` training or gradient accumulation, it is possible to train on 16 GB GPUs like the ones provided by Google Colab or Kaggle.
* Fine-tuning with or without EMA produced similar results.
* There's no need to use the `sks` word to train Dreambooth. One of the first implementations used it because it was a rare token in the vocabulary, but it's actually a kind of rifle. Our experiments, and those by for example [@nitrosocke](https://huggingface.co/nitrosocke) show that it's ok to select terms that you'd naturally use to describe your target.
## Learning Rate Impact
Dreambooth overfits very quickly. To get good results, tune the learning rate and the number of training steps in a way that makes sense for your dataset. In our experiments (detailed below), we fine-tuned on four different datasets with high and low learning rates. In all cases, we got better results with a low learning rate.
## Experiments Settings
All our experiments were conducted using the [`train_dreambooth.py`](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) script with the `AdamW` optimizer on 2x 40GB A100s. We used the same seed and kept all hyperparameters equal across runs, except LR, number of training steps and the use of prior preservation.
For the first 3 examples (various objects), we fine-tuned the model with a batch size of 4 (2 per GPU) for 400 steps. We used a high learning rate of `5e-6` and a low learning rate of `2e-6`. No prior preservation was used.
The last experiment attempts to add a human subject to the model. We used prior preservation with a batch size of 2 (1 per GPU), 800 and 1200 steps in this case. We used a high learning rate of `5e-6` and a low learning rate of `2e-6`.
Note that you can use 8-bit Adam, `fp16` training or gradient accumulation to reduce memory requirements and run similar experiments on GPUs with 16 GB of memory.
### Cat Toy
High Learning Rate (`5e-6`)

Low Learning Rate (`2e-6`)

### Pighead
High Learning Rate (`5e-6`). Note that the color artifacts are noise remnants – running more inference steps could help resolve some of those details.

Low Learning Rate (`2e-6`)

### Mr. Potato Head
High Learning Rate (`5e-6`). Note that the color artifacts are noise remnants – running more inference steps could help resolve some of those details.

Low Learning Rate (`2e-6`)

### Human Face
We tried to incorporate the Kramer character from Seinfeld into Stable Diffusion. As previously mentioned, we trained for more steps with a smaller batch size. Even so, the results were not stellar. For the sake of brevity, we have omitted these sample images and defer the reader to the next sections, where face training became the focus of our efforts.
### Summary of Initial Results
To get good results training Stable Diffusion with Dreambooth, it's important to tune the learning rate and training steps for your dataset.
* High learning rates and too many training steps will lead to overfitting. The model will mostly generate images from your training data, no matter what prompt is used.
* Low learning rates and too few steps will lead to underfitting: the model will not be able to generate the concept we were trying to incorporate.
Faces are harder to train. In our experiments, a learning rate of `2e-6` with `400` training steps works well for objects but faces required `1e-6` (or `2e-6`) with ~1200 steps.
Image quality degrades a lot if the model overfits, and this happens if:
* The learning rate is too high.
* We run too many training steps.
* In the case of faces, when no prior preservation is used, as shown in the next section.
## Using Prior Preservation when training Faces
Prior preservation is a technique that uses additional images of the same class we are trying to train as part of the fine-tuning process. For example, if we try to incorporate a new person into the model, the _class_ we'd want to preserve could be _person_. Prior preservation tries to reduce overfitting by using photos of the new person combined with photos of other people. The nice thing is that we can generate those additional class images using the Stable Diffusion model itself! The training script takes care of that automatically if you want, but you can also provide a folder with your own prior preservation images.
Prior preservation, 1200 steps, lr=`2e-6`.

No prior preservation, 1200 steps, lr=`2e-6`.

As you can see, results are better when prior preservation is used, but there are still noisy blotches. It's time for some additional tricks!
## Effect of Schedulers
In the previous examples, we used the `PNDM` scheduler to sample images during the inference process. We observed that when the model overfits, `DDIM` usually works much better than `PNDM` and `LMSDiscrete`. In addition, quality can be improved by running inference for more steps: 100 seems to be a good choice. The additional steps help resolve some of the noise patches into image details.
`PNDM`, Kramer face

`LMSDiscrete`, Kramer face. Results are terrible!

`DDIM`, Kramer face. Much better

A similar behaviour can be observed for other subjects, although to a lesser extent.
`PNDM`, Potato Head

`LMSDiscrete`, Potato Head

`DDIM`, Potato Head

## Fine-tuning the Text Encoder
The original Dreambooth paper describes a method to fine-tune the UNet component of the model but keeps the text encoder frozen. However, we observed that fine-tuning the encoder produces better results. We experimented with this approach after seeing it used in other Dreambooth implementations, and the results are striking!
Frozen text encoder

Fine-tuned text encoder

Fine-tuning the text encoder produces the best results, especially with faces. It generates more realistic images, it's less prone to overfitting and it also achieves better prompt interpretability, being able to handle more complex prompts.
## Epilogue: Textual Inversion + Dreambooth
We also ran a final experiment where we combined [Textual Inversion](https://textual-inversion.github.io) with Dreambooth. Both techniques have a similar goal, but their approaches are different.
In this experiment we first ran textual inversion for 2000 steps. From that model, we then ran Dreambooth for an additional 500 steps using a learning rate of `1e-6`. These are the results:

We think the results are much better than doing plain Dreambooth but not as good as when we fine-tune the whole text encoder. It seems to copy the style of the training images a bit more, so it could be overfitting to them. We didn't explore this combination further, but it could be an interesting alternative to improve Dreambooth and still fit the process in a 16GB GPU. Feel free to explore and tell us about your results!
| huggingface/blog/blob/main/dreambooth.md |
--
title: 'Faster Text Generation with TensorFlow and XLA'
thumbnail: /blog/assets/91_tf_xla_generate/thumbnail.png
authors:
- user: joaogante
---
# Faster Text Generation with TensorFlow and XLA
<em>TL;DR</em>: Text Generation on 🤗 `transformers` using TensorFlow can now be compiled with XLA. It is up to 100x
faster than before, and [even faster than PyTorch](https://huggingface.co/spaces/joaogante/tf_xla_generate_benchmarks)
-- check the colab below!
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Text Generation
As the quality of large language models increased, so did our expectations of what those models could do. Especially
since the release of OpenAI's [GPT-2](https://openai.com/blog/better-language-models/), models with text
generation capabilities have been in the spotlight. And for legitimate reasons -- these models can be used to
summarize, translate, and they even have demonstrated zero-shot learning capabilities on some language tasks.
This blog post will show how to take the most of this technology with TensorFlow.
The 🤗 `transformers` library started with NLP models, so it is natural that text generation is of utmost
importance to us.
It is part of Hugging Face democratization efforts to ensure it is accessible, easily controllable, and efficient.
There is a previous [blog post](https://huggingface.co/blog/how-to-generate) about the different types of text
generation. Nevertheless, below there's a quick recap of the core functionality -- feel free to
[skip it](#tensorflow-and-xla) if you're
familiar with our `generate` function and want to jump straight into TensorFlow's specificities.
Let's start with the basics. Text generation can be deterministic or stochastic, depending on the
`do_sample` flag. By default it's set to `False`, causing the output to be deterministic, which is also known as
Greedy Decoding.
When it's set to `True`, also known as Sampling, the output will be stochastic, but you can still
obtain reproducible results through the `seed` argument (with the same format as in [stateless TensorFlow random
number generation](https://www.tensorflow.org/api_docs/python/tf/random/stateless_categorical#args)).
As a rule of thumb, you want deterministic generation if you wish
to obtain factual information from the model and stochastic generation if you're aiming at more creative outputs.
```python
# Requires transformers >= 4.21.0;
# Sampling outputs may differ, depending on your hardware.
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
model.config.pad_token_id = model.config.eos_token_id
inputs = tokenizer(["TensorFlow is"], return_tensors="tf")
generated = model.generate(**inputs, do_sample=True, seed=(42, 0))
print("Sampling output: ", tokenizer.decode(generated[0]))
# > Sampling output: TensorFlow is a great learning platform for learning about
# data structure and structure in data science..
```
Depending on the target application, longer outputs might be desirable. You can control the length of the generation
output with `max_new_tokens`, keeping in mind that longer generations will require more resources.
```python
generated = model.generate(
**inputs, do_sample=True, seed=(42, 0), max_new_tokens=5
)
print("Limiting to 5 new tokens:", tokenizer.decode(generated[0]))
# > Limiting to 5 new tokens: TensorFlow is a great learning platform for
generated = model.generate(
**inputs, do_sample=True, seed=(42, 0), max_new_tokens=30
)
print("Limiting to 30 new tokens:", tokenizer.decode(generated[0]))
# > Limiting to 30 new tokens: TensorFlow is a great learning platform for
# learning about data structure and structure in data science................
```
Sampling has a few knobs you can play with to control randomness. The most important is `temperature`, which sets the overall entropy
of your output -- values below `1.0` will prioritize sampling tokens with a higher likelihood, whereas values above `1.0`
do the opposite. Setting it to `0.0` reduces the behavior to Greedy Decoding, whereas very large values approximate
uniform sampling.
```python
generated = model.generate(
**inputs, do_sample=True, seed=(42, 0), temperature=0.7
)
print("Temperature 0.7: ", tokenizer.decode(generated[0]))
# > Temperature 0.7: TensorFlow is a great way to do things like this........
generated = model.generate(
**inputs, do_sample=True, seed=(42, 0), temperature=1.5
)
print("Temperature 1.5: ", tokenizer.decode(generated[0]))
# > Temperature 1.5: TensorFlow is being developed for both Cython and Bamboo.
# On Bamboo...
```
Contrarily to Sampling, Greedy Decoding will always pick the most likely token at each iteration of generation.
However, it often results in sub-optimal outputs. You can increase the quality of the results through the `num_beams`
argument. When it is larger than `1`, it triggers Beam Search, which continuously explores high-probability sequences.
This exploration comes at the cost of additional resources and computational time.
```python
generated = model.generate(**inputs, num_beams=2)
print("Beam Search output:", tokenizer.decode(generated[0]))
# > Beam Search output: TensorFlow is an open-source, open-source,
# distributed-source application framework for the
```
Finally, when running Sampling or Beam Search, you can use `num_return_sequences` to return several sequences. For
Sampling it is equivalent to running generate multiple times from the same input prompt, while for Beam Search it
returns the highest scoring generated beams in descending order.
```python
generated = model.generate(**inputs, num_beams=2, num_return_sequences=2)
print(
"All generated hypotheses:",
"\n".join(tokenizer.decode(out) for out in generated)
)
# > All generated hypotheses: TensorFlow is an open-source, open-source,
# distributed-source application framework for the
# > TensorFlow is an open-source, open-source, distributed-source application
# framework that allows
```
The basics of text generation, as you can see, are straightforward to control. However, there are many options
not covered in the examples above, and it's encouraged to read the
[documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)
for advanced use cases.
Sadly, when you run `generate` with TensorFlow, you might notice that it takes a while to execute.
If your target application expects low latency or a large amount of input prompts, running text generation with
TensorFlow looks like an expensive endeavour. 😬
Fear not, for the remainder of this blog post aims to demonstrate that one line of code can make a drastic improvement.
If you'd rather jump straight into action,
[the colab](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb)
has an interactive example you can fiddle with!
## TensorFlow and XLA
[XLA](https://www.tensorflow.org/xla), or Accelerated Linear Algebra, is a compiler originally developed to accelerate
TensorFlow models. Nowadays, it is also the compiler behind [JAX](https://github.com/google/jax), and it can even
be [used with PyTorch](https://huggingface.co/blog/pytorch-xla). Although the word "compiler" might sound daunting for
some, XLA is simple to use with TensorFlow -- it comes packaged inside the `tensorflow` library, and it can be
triggered with the `jit_compile` argument in any graph-creating function.
For those of you familiar with TensorFlow 1 🧓, the concept of a TensorFlow graph comes naturally, as it was the only
mode of operation. First, you defined the operations in a declarative fashion to create a graph. Afterwards, you could
pipe inputs through the graph and observe the outputs. Fast, efficient, but painful to debug. With TensorFlow 2 came
Eager Execution and the ability to code the models imperatively -- the TensorFlow team explains the difference in more
detail in [their blog post](https://blog.tensorflow.org/2019/01/what-are-symbolic-and-imperative-apis.html).
Hugging Face writes their TensorFlow models with Eager Execution in mind. Transparency is a core value, and being able
to inspect the model internals at any point is very benefitial to that end. However, that does mean that some uses of
the models do not benefit from the graph mode performance advantages out of the box (e.g. when calling `model(args)`).
Fortunately, the TensorFlow team has users like us covered 🥳! Wrapping a function containing TensorFlow code with
[`tf.function`](https://www.tensorflow.org/api_docs/python/tf/function) will attempt to convert it into a graph when
you call the wrapped function. If you're training a model, calling `model.compile()` (without `run_eagerly=True`) does
precisely that wrapping, so that you benefit from graph mode when you call `model.fit()`. Since `tf.function` can be
used in any function containing TensorFlow code, it means you can use it on functions that go beyond model inference,
creating a single optimized graph.
Now that you know how to create TensorFlow graphs, compiling them with XLA is straightforward -- simply add `jit_compile=True`
as an argument to the functions mentioned above (`tf.function` and `tf.keras.Model.compile`). Assuming everything went well
(more on that below) and that you are using a GPU or a TPU, you will notice that the first call will take a while, but
that the remaining ones are much, much faster. Here's a simple example of a function that performs model inference and some post-processing of its outputs:
```python
# Note: execution times are deeply dependent on hardware -- a 3090 was used here.
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
inputs = tokenizer(["TensorFlow is"], return_tensors="tf")
def most_likely_next_token(inputs):
model_output = model(inputs)
return tf.argmax(model_output.logits[:, -1, :], axis=-1)
print("Calling regular function with TensorFlow code...")
most_likely_next_token(inputs)
# > Execution time -- 48.8 ms
```
In one line, you can create an XLA-accelerated function from the function above.
```python
xla_most_likely_next_token = tf.function(most_likely_next_token, jit_compile=True)
print("Calling XLA function... (for the first time -- will be slow)")
xla_most_likely_next_token(inputs)
# > Execution time -- 3951.0 ms
print("Calling XLA function... (for the second time -- will be fast)")
xla_most_likely_next_token(inputs)
# > Execution time -- 1.6 ms
```
## Text Generation using TensorFlow with XLA
As with any optimization procedure, there is no free lunch -- XLA is no exception. From the perspective of a text
generation user, there is only one technical aspect that you need to keep in mind. Without digging too much into
[details](https://www.tensorflow.org/guide/function#rules_of_tracing), XLA used in this fashion does just-in-time (JIT)
compilation of a `tf.function` when you call it, which relies on polymorphism.
When you compile a function this way, XLA keeps track of the shape and type of every tensor, as well as the data of
every non-tensor function input. The function is compiled to a binary, and every time it is called with the same tensor
shape and type (with ANY tensor data) and the same non-tensor arguments, the compiled function can be reused.
Contrarily, if you call the function with a different shape or type in an input tensor, or if you use a different
non-tensor argument, then a new costly compilation step will take place. Summarized in a simple example:
```python
# Note: execution times are deeply dependent on hardware -- a 3090 was used here.
import tensorflow as tf
@tf.function(jit_compile=True)
def max_plus_constant(tensor, scalar):
return tf.math.reduce_max(tensor) + scalar
# Slow: XLA compilation will kick in, as it is the first call
max_plus_constant(tf.constant([0, 0, 0]), 1)
# > Execution time -- 520.4 ms
# Fast: Not the first call with this tensor shape, tensor type, and exact same
# non-tensor argument
max_plus_constant(tf.constant([1000, 0, -10]), 1)
# > Execution time -- 0.6 ms
# Slow: Different tensor type
max_plus_constant(tf.constant([0, 0, 0], dtype=tf.int64), 1)
# > Execution time -- 27.1 ms
# Slow: Different tensor shape
max_plus_constant(tf.constant([0, 0, 0, 0]), 1)
# > Execution time -- 25.5 ms
# Slow: Different non-tensor argument
max_plus_constant(tf.constant([0, 0, 0]), 2)
# > Execution time -- 24.9 ms
```
In practice, for text generation, it simply means the input should be padded to a multiple of a certain length (so it
has a limited number of possible shapes), and that using different options will be slow for the first time you use
them. Let's see what happens when you naively call generation with XLA.
```python
# Note: execution times are deeply dependent on hardware -- a 3090 was used here.
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Notice the new argument, `padding_side="left"` -- decoder-only models, which can
# be instantiated with TFAutoModelForCausalLM, should be left-padded, as they
# continue generating from the input prompt.
tokenizer = AutoTokenizer.from_pretrained(
"gpt2", padding_side="left", pad_token="</s>"
)
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
model.config.pad_token_id = model.config.eos_token_id
input_1 = ["TensorFlow is"]
input_2 = ["TensorFlow is a"]
# One line to create a XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
# Calls XLA generation without padding
tokenized_input_1 = tokenizer(input_1, return_tensors="tf") # length = 4
tokenized_input_2 = tokenizer(input_2, return_tensors="tf") # length = 5
print(f"`tokenized_input_1` shape = {tokenized_input_1.input_ids.shape}")
print(f"`tokenized_input_2` shape = {tokenized_input_2.input_ids.shape}")
print("Calling XLA generation with tokenized_input_1...")
print("(will be slow as it is the first call)")
start = time.time_ns()
xla_generate(**tokenized_input_1)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
# > Execution time -- 9565.1 ms
print("Calling XLA generation with tokenized_input_2...")
print("(has a different length = will trigger tracing again)")
start = time.time_ns()
xla_generate(**tokenized_input_2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
# > Execution time -- 6815.0 ms
```
Oh no, that's terribly slow! A solution to keep the different combinations of shapes in check is through padding,
as mentioned above. The tokenizer classes have a `pad_to_multiple_of` argument that can be used to achieve a balance
between accepting any input length and limiting tracing.
```python
padding_kwargs = {"pad_to_multiple_of": 8, "padding": True}
tokenized_input_1_with_padding = tokenizer(
input_1, return_tensors="tf", **padding_kwargs
) # length = 8
tokenized_input_2_with_padding = tokenizer(
input_2, return_tensors="tf", **padding_kwargs
) # length = 8
print(
"`tokenized_input_1_with_padding` shape = ",
f"{tokenized_input_1_with_padding.input_ids.shape}"
)
print(
"`tokenized_input_2_with_padding` shape = ",
f"{tokenized_input_2_with_padding.input_ids.shape}"
)
print("Calling XLA generation with tokenized_input_1_with_padding...")
print("(slow, first time running with this length)")
start = time.time_ns()
xla_generate(**tokenized_input_1_with_padding)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
# > Execution time -- 6815.4 ms
print("Calling XLA generation with tokenized_input_2_with_padding...")
print("(will be fast!)")
start = time.time_ns()
xla_generate(**tokenized_input_2_with_padding)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
# > Execution time -- 19.3 ms
```
That's much better, successive generation calls performed this way will be orders of magnitude faster than before.
Keep in mind that trying new generation options, at any point, will trigger tracing.
```python
print("Calling XLA generation with the same input, but with new options...")
print("(slow again)")
start = time.time_ns()
xla_generate(**tokenized_input_1_with_padding, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
# > Execution time -- 9644.2 ms
```
From a developer perspective, relying on XLA implies being aware of a few additional nuances. XLA shines when the size
of the data structures are known in advance, such as in model training. On the other hand, when their dimensions are
impossible to determine or certain dynamic slices are used, XLA fails to compile. Modern implementations of text
generation are auto-regressive, whose natural behavior is to expand tensors and to abruptly interrupt some operations
as it goes -- in other words, not XLA-friendly by default.
We have [rewritten our entire TensorFlow text generation codebase](https://github.com/huggingface/transformers/pull/17857)
to vectorize operations and use fixed-sized
structures with padding. Our NLP models were also modified to correctly use their positional embeddings in the
presence of padded structures. The result should be invisible to TensorFlow text generation users, except for the
availability of XLA compilation.
## Benchmarks and Conclusions
Above you saw that you can convert TensorFlow functions into a graph and accelerate them with XLA compilation.
Current forms of text generation are simply an auto-regressive functions that alternate between a model forward pass
and some post-processing, producing one token per iteration. Through XLA compilation, the entire process gets
optimized, resulting in faster execution. But how much faster? The [Gradio demo below](https://huggingface.co/spaces/joaogante/tf_xla_generate_benchmarks) contains some benchmarks
comparing Hugging Face's text generation on multiple GPU models for the two main ML frameworks, TensorFlow and PyTorch.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://joaogante-tf-xla-generate-benchmarks.hf.space" frameBorder="0" width="1200px" height="760px" title="Gradio app" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
If you explore the results, two conclusions become quickly visible:
1. As this blog post has been building up to here, TensorFlow text generation is much faster when XLA is used. We are
talking about speedups larger than 100x in some cases, which truly demonstrates the power of a compiled graph 🚀
2. TensorFlow text generation with XLA is the fastest option in the vast majority of cases, in some of them by as
much as 9x faster, debunking the myth that PyTorch is the go-to framework for serious NLP tasks 💪
Give [the colab](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb)
a go, and enjoy the power of text generation supercharged with XLA!
| huggingface/blog/blob/main/tf-xla-generate.md |
utomatic speech recognition English. Record from your microphone and the app will transcribe the audio. | gradio-app/gradio/blob/main/demo/automatic-speech-recognition/DESCRIPTION.md |
Datasets without language challenge
Related to https://github.com/huggingface/hub-docs/issues/986.
## Context
The Hugging Face Hub hosts hundreds of thousands of public models and datasets. These datasets and models cover a wide range of languages. One of the main ways in which it's possible to know what language a dataset is in is by looking at the `language` field in the dataset's [metadata](https://huggingface.co/docs/hub/datasets-cards#dataset-card-metadata) section of the dataset card.
```yaml
language:
- "List of ISO 639-1 code for your language"
- lang1
pretty_name: "Pretty Name of the Dataset"
tags:
- tag1
- tag2
license: "any valid license identifier"
task_categories:
- task1
```
Having this field filled in is essential for users to find datasets in their language and give a better idea of the languages that the Hub covers. However, the dataset's author has only sometimes filled this field. This challenge is to fill in the `language` field for datasets that don't have it filled in.
## How to contribute?
How can you help improve the coverage of language metadata on the Hub?
For each dataset, the workflow is the following:
1. Find a dataset that doesn't have the `language` field filled in. You can find a list of datasets without the `language` field filled in [here](#datasets-without-language-field-filled-in). We start with datasets that have the most downloads and likes.
2. **Check that the dataset doesn't already have a PR to add a language tag(s).** Someone else may have already started working on it. You can check this by looking in the discussion section of the dataset page.
3. If there is no PR to add language metadata already open, your next step is to identify the language (if possible for the dataset). There are a few main ways you can often identify the language
1. The dataset's name. Often, the name of the dataset will include the language. Sometimes as a full name, i.e. `imdb_german` or sometimes as a language code, i.e. `imdb_de`. You can use that as the language tag if the dataset name includes the language.
2. The dataset card will sometimes mention the language(s) of the dataset explicitly.
3. Many datasets will have an active [dataset viewer](https://huggingface.co/docs/hub/datasets-viewer) for the dataset. This will allow you to see examples from the dataset. You may identify the language by looking at the text examples.
4. Sometimes, the dataset will have a column specifying the language of the text. You can use this column to fill in the language tag(s).
5. If the dataset viewer is available for the dataset, but you don't recognize the language, you can use the [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) model or [Google Translate](https://translate.google.com/) to try to identify the language.
4. Once you've identified the language(s) of the dataset, you can add the language tag(s) to the dataset card. You can do this by clicking the `Edit` button on the dataset card. This will open a PR to the dataset repo. You can add the language tag(s) to the `language` field in the dataset card. Some datasets may have multiple languages. Try and add all of the languages you have identified.
5. Once done, open a PR on GitHub to update the table below. Once merged, this will count as a Hacktoberfest contribution! Add the `pr_url` (the one on the Hub) and a status ( , merged, closed) in the PR.
6. Adding a language tag to some of the datasets below may not make sense. If so, add `not relevant` as the link in the `pr_url`. There may also be datasets where you need help with the language. In these cases, you can open a discussion to suggest a language tag(s) is added to the dataset.
## F.A.Q.
### Does it make sense to add language metadata to all datasets?
No! This is why we have focused on datasets with a `task_categories` field indicating that the dataset has a text-related task.
### Can I use a script to automate the process?
While it is possible to use machine learning to help assist this process, see [this blog](https://huggingface.co/blog/huggy-lingo) as an example; checking the accuracy of the PRs you are making is still important.
## What about datasets with multiple languages?
Some datasets may have more than one language. Do your best to add all the languages you can identify in the datasets. If there is a vast number, this may be tricky. In this case, do your best.
## What about code?
Currently, you can add a language tag for `code`. You will need to do this directly in the `YAML` rather than the visual editor since using the visual editor will lead to an auto-completion for the `co` language code (Corsican).
## Can I update the table with new datasets?
Yes, it's fine to add new rows if there are other datasets where it makes sense to have language metadata. However, we'll focus only on datasets with at least ten downloads in the past 30 days to have the most impact. You can see download information alongside the dataset on the Hub website or access this information via the API. For example, to filter datasets to have at least 20 downloads you could do the following
```python
from huggingface_hub import list_datasets
datasets = list_datasets(full=True)
datasets_with_at_least_20_downloads = [dataset for dataset in datasets if dataset.downloads >20]
```
## Datasets without language field filled in
| status | pr_url | hub_id | downloads | likes |
|--------|-----------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------|-------|
| Merged | [here](https://huggingface.co/datasets/sahil2801/CodeAlpaca-20k/discussions/5) | [sahil2801/CodeAlpaca-20k](https://huggingface.co/datasets/sahil2801/CodeAlpaca-20k) | 2124 | 104 |
| | | [facebook/winoground](https://huggingface.co/datasets/facebook/winoground) | 5468 | 57 |
| | | [oscar-corpus/OSCAR-2301](https://huggingface.co/datasets/oscar-corpus/OSCAR-2301) | 7814 | 56 |
| | [here](https://huggingface.co/datasets/HuggingFaceH4/CodeAlpaca_20K/discussions/1) | [HuggingFaceH4/CodeAlpaca_20K](https://huggingface.co/datasets/HuggingFaceH4/CodeAlpaca_20K) | 850 | 36 |
| |[here](https://huggingface.co/datasets/huggan/wikiart/discussions/3) | [huggan/wikiart](https://huggingface.co/datasets/huggan/wikiart) | 344 | 38 |
| |[here](https://huggingface.co/datasets/MMInstruction/M3IT/discussions/7) | [MMInstruction/M3IT](https://huggingface.co/datasets/MMInstruction/M3IT) | 62902 | 47 |
| Merged | [here](https://huggingface.co/datasets/codeparrot/self-instruct-starcoder/discussions/3) | [codeparrot/self-instruct-starcoder](https://huggingface.co/datasets/codeparrot/self-instruct-starcoder) | 454 | 25 |
| | [here](https://huggingface.co/datasets/unaidedelf87777/openapi-function-invocations-25k/discussions/3) | [unaidedelf87777/openapi-function-invocations-25k](https://huggingface.co/datasets/unaidedelf87777/openapi-function-invocations-25k) | 47 | 20 |
| | [here](https://huggingface.co/datasets/Matthijs/cmu-arctic-xvectors/discussions/4) | [Matthijs/cmu-arctic-xvectors](https://huggingface.co/datasets/Matthijs/cmu-arctic-xvectors) | 158508 | 19 |
| | [here](https://huggingface.co/datasets/skg/toxigen-data/discussions/4) | [skg/toxigen-data](https://huggingface.co/datasets/skg/toxigen-data) | 957 | 17 |
| | | [oscar-corpus/colossal-oscar-1.0](https://huggingface.co/datasets/oscar-corpus/colossal-oscar-1.0) | 66 | 17 |
| Merged | [here](https://huggingface.co/datasets/aadityaubhat/GPT-wiki-intro/discussions/2) | [aadityaubhat/GPT-wiki-intro](https://huggingface.co/datasets/aadityaubhat/GPT-wiki-intro) | 267 | 15 |
| | [here](https://huggingface.co/datasets/codeparrot/github-jupyter-code-to-text/discussions/1) | [codeparrot/github-jupyter-code-to-text](https://huggingface.co/datasets/codeparrot/github-jupyter-code-to-text) | 11 | 14 |
| | [here](https://huggingface.co/datasets/cfilt/iitb-english-hindi/discussions/1#651ab7559c4067f3b896564f) | [cfilt/iitb-english-hindi](https://huggingface.co/datasets/cfilt/iitb-english-hindi) | 1147 | 11 |
| | [here](https://huggingface.co/datasets/iamtarun/python_code_instructions_18k_alpaca/discussions/1) | [iamtarun/python_code_instructions_18k_alpaca](https://huggingface.co/datasets/iamtarun/python_code_instructions_18k_alpaca) | 1424 | 10 |
| Merged | [here](https://huggingface.co/datasets/argilla/databricks-dolly-15k-curated-en/discussions/1#651ab6e569d3438f0f246312) | [argilla/databricks-dolly-15k-curated-en](https://huggingface.co/datasets/argilla/databricks-dolly-15k-curated-en) | 9651261 | 9 |
| | | [sander-wood/irishman](https://huggingface.co/datasets/sander-wood/irishman) | 456 | 9 |
| | | [OleehyO/latex-formulas](https://huggingface.co/datasets/OleehyO/latex-formulas) | 46 | 9 |
| Merged | [here](https://huggingface.co/datasets/german-nlp-group/german_common_crawl/discussions/1) | [german-nlp-group/german_common_crawl](https://huggingface.co/datasets/german-nlp-group/german_common_crawl) | 116 | 7 |
| | [here](https://huggingface.co/datasets/kunishou/databricks-dolly-69k-ja-en-translation/discussions/1#651aba1b1c53eaa6dbaca648) | [kunishou/databricks-dolly-69k-ja-en-translation](https://huggingface.co/datasets/kunishou/databricks-dolly-69k-ja-en-translation) | 22 | 7 |
| | | [Muennighoff/flores200](https://huggingface.co/datasets/Muennighoff/flores200) | 93084 | 5 |
| | [here](https://huggingface.co/datasets/nanelimon/turkish-social-media-bullying-dataset/discussions/1#651ae8247d45b917399dbade) | [nanelimon/turkish-social-media-bullying-dataset](https://huggingface.co/datasets/nanelimon/turkish-social-media-bullying-dataset) | 3 | 5 |
| | [here](https://huggingface.co/datasets/vivym/midjourney-prompts/discussions/1) | [vivym/midjourney-prompts](https://huggingface.co/datasets/vivym/midjourney-prompts) | 126 | 4 |
| | | [yuweiyin/FinBench](https://huggingface.co/datasets/yuweiyin/FinBench) | 102 | 4 |
| Merged | [here](https://huggingface.co/datasets/NbAiLab/norwegian-xsum/discussions/2#651b2951b08a2b1588b8d99e) | [NbAiLab/norwegian-xsum](https://huggingface.co/datasets/NbAiLab/norwegian-xsum) | 0 | 4 |
| | [here](https://huggingface.co/datasets/merve/turkish_instructions/discussions/1#651ae7a8cc1c891376b4bb45) | [merve/turkish_instructions](https://huggingface.co/datasets/merve/turkish_instructions) | 36 | 4 |
| | | [tianyang/repobench-c](https://huggingface.co/datasets/tianyang/repobench-c) | 240 | 3 |
| | [here](https://huggingface.co/datasets/HuggingFaceH4/self_instruct/discussions/1) | [HuggingFaceH4/self_instruct](https://huggingface.co/datasets/HuggingFaceH4/self_instruct) | 219 | 3 |
| | [here](https://huggingface.co/datasets/iamtarun/code_instructions_120k_alpaca/discussions/1) | [iamtarun/code_instructions_120k_alpaca](https://huggingface.co/datasets/iamtarun/code_instructions_120k_alpaca) | 141 | 3 |
| | [here](https://huggingface.co/datasets/j0selit0/insurance-qa-en/discussions/2#651ab933aa7da01954bdc21f) | [j0selit0/insurance-qa-en](https://huggingface.co/datasets/j0selit0/insurance-qa-en) | 64 | 3 |
| | | [billray110/corpus-of-diverse-styles](https://huggingface.co/datasets/billray110/corpus-of-diverse-styles) | 18 | 3 |
| | [here](https://huggingface.co/datasets/dmayhem93/agieval-sat-en/discussions/1#651ab8b5e8b2318cdb755b17) | [dmayhem93/agieval-sat-en](https://huggingface.co/datasets/dmayhem93/agieval-sat-en) | 87 | 2 |
| | | [polymer/dolphin-only-gpt-4](https://huggingface.co/datasets/polymer/dolphin-only-gpt-4) | 69 | 2 |
| | [here](https://huggingface.co/datasets/RafaelMPereira/HealthCareMagic-100k-Chat-Format-en/discussions/1#651abaea4dba2d9ed143b11d) | [RafaelMPereira/HealthCareMagic-100k-Chat-Format-en](https://huggingface.co/datasets/RafaelMPereira/HealthCareMagic-100k-Chat-Format-en) | 7 | 2 |
| | [here](https://huggingface.co/datasets/fathyshalab/Dialogsum-german-kurz/discussions/1) | [fathyshalab/Dialogsum-german-kurz](https://huggingface.co/datasets/fathyshalab/Dialogsum-german-kurz) | 0 | 2 |
| | [here](https://huggingface.co/datasets/philschmid/test_german_squad/discussions/1) | [philschmid/test_german_squad](https://huggingface.co/datasets/philschmid/test_german_squad) | 0 | 2 |
| | | [gia-project/gia-dataset](https://huggingface.co/datasets/gia-project/gia-dataset) | 1727 | 1 |
| | [here](https://huggingface.co/datasets/stas/wmt14-en-de-pre-processed/discussions/1#651ab7aa8a5c072ce16774ac) | [stas/wmt14-en-de-pre-processed](https://huggingface.co/datasets/stas/wmt14-en-de-pre-processed) | 423 | 1 |
| | [here](https://huggingface.co/datasets/ajaykarthick/imdb-movie-reviews/discussions/1) | [ajaykarthick/imdb-movie-reviews](https://huggingface.co/datasets/ajaykarthick/imdb-movie-reviews) | 222 | 1 |
| | | [MMInstruction/M3IT-80](https://huggingface.co/datasets/MMInstruction/M3IT-80) | 108 | 1 |
| Merged | [here](https://huggingface.co/datasets/rizerphe/sharegpt-hyperfiltered-3k-llama/discussions/1) | [rizerphe/sharegpt-hyperfiltered-3k-llama](https://huggingface.co/datasets/rizerphe/sharegpt-hyperfiltered-3k-llama) | 35 | 1 |
| | [here](https://huggingface.co/datasets/alvations/globalvoices-en-es/discussions/1#651ab996996b00d2900f310f) | [alvations/globalvoices-en-es](https://huggingface.co/datasets/alvations/globalvoices-en-es) | 33 | 1 |
| | | [ejschwartz/oo-method-test](https://huggingface.co/datasets/ejschwartz/oo-method-test) | 27 | 1 |
| | [here](https://huggingface.co/datasets/soymia/boudoir-dataset/discussions/1) | [soymia/boudoir-dataset](https://huggingface.co/datasets/soymia/boudoir-dataset) | 25 | 1 |
| | | [strombergnlp/offenseval_2020](https://huggingface.co/datasets/strombergnlp/offenseval_2020) | 24 | 1 |
| | [here](https://huggingface.co/datasets/vhtran/de-en-2023/discussions/1#651aba022bc734f0fa0c36af) | [vhtran/de-en-2023](https://huggingface.co/datasets/vhtran/de-en-2023) | 23 | 1 |
| | | [cw1521/ember2018-malware](https://huggingface.co/datasets/cw1521/ember2018-malware) | 17 | 1 |
| | [here](https://huggingface.co/datasets/AgentWaller/german-formatted-oasst1/discussions/1) | [AgentWaller/german-formatted-oasst1](https://huggingface.co/datasets/AgentWaller/german-formatted-oasst1) | 15 | 1 |
| | [here](https://huggingface.co/datasets/Senem/Nostalgic_Sentiment_Analysis_of_YouTube_Comments_Data/discussions/1) | [Senem/Nostalgic_Sentiment_Analysis_of_YouTube_Comments_Data](https://huggingface.co/datasets/Senem/Nostalgic_Sentiment_Analysis_of_YouTube_Comments_Data) | 12 | 1 |
| Merged | [here](https://huggingface.co/datasets/Photolens/oasst1-en/discussions/2#651aba64e8b2318cdb759528) | [Photolens/oasst1-en](https://huggingface.co/datasets/Photolens/oasst1-en) | 10 | 1 |
| | [here](https://huggingface.co/datasets/vhtran/id-en/discussions/1#651ababdc4fdc1c93efb0f2b) | [vhtran/id-en](https://huggingface.co/datasets/vhtran/id-en) | 8 | 1 |
| Merged | [here](https://huggingface.co/datasets/openmachinetranslation/tatoeba-en-fr/discussions/1#651aba96b693acb51958884b) | [openmachinetranslation/tatoeba-en-fr](https://huggingface.co/datasets/openmachinetranslation/tatoeba-en-fr) | 8 | 1 |
| | [here](https://huggingface.co/datasets/vhtran/uniq-de-en/discussions/1#651abb5e2bc734f0fa0c7f44) | [vhtran/uniq-de-en](https://huggingface.co/datasets/vhtran/uniq-de-en) | 5 | 1 |
| | [here](https://huggingface.co/datasets/marksverdhei/wordnet-definitions-en-2021/discussions/1#651abcd1a9e1c4c6cdd06042) | [marksverdhei/wordnet-definitions-en-2021](https://huggingface.co/datasets/marksverdhei/wordnet-definitions-en-2021) | 1 | 1 |
| | [here](https://huggingface.co/datasets/nogyxo/question-answering-ukrainian/discussions/1) | [nogyxo/question-answering-ukrainian](https://huggingface.co/datasets/nogyxo/question-answering-ukrainian) | 1 | 1 |
| | [here](https://huggingface.co/datasets/dandrade/es-en/discussions/1#651ac2720047dc5f7aae8124) | [dandrade/es-en](https://huggingface.co/datasets/dandrade/es-en) | 0 | 1 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-split-v1/discussions/1#651ac23fb61121b1283a0402) | [shreevigneshs/iwslt-2023-en-vi-train-split-v1](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-split-v1) | 0 | 1 |
| Merged | [here](https://huggingface.co/datasets/loresiensis/corpus-en-es/discussions/1#651ac1e328c2633de960131e) | [loresiensis/corpus-en-es](https://huggingface.co/datasets/loresiensis/corpus-en-es) | 0 | 1 |
| Merged | [here](https://huggingface.co/datasets/Photolens/DISC-Med-SFT-en-translated-only-CMeKG/discussions/1#651ac9dfa9a91bf39df7489f) | [Photolens/DISC-Med-SFT-en-translated-only-CMeKG](https://huggingface.co/datasets/Photolens/DISC-Med-SFT-en-translated-only-CMeKG) | 0 | 1 |
| | [here](https://huggingface.co/datasets/joelniklaus/german_rental_agreements/discussions/1) | [joelniklaus/german_rental_agreements](https://huggingface.co/datasets/joelniklaus/german_rental_agreements) | 0 | 1 |
| | [here](https://huggingface.co/datasets/fathyshalab/Dialogsum-german/discussions/1) | [fathyshalab/Dialogsum-german](https://huggingface.co/datasets/fathyshalab/Dialogsum-german) | 0 | 1 |
| | [here](https://huggingface.co/datasets/Harsit/xnli2.0_german/discussions/1) | [Harsit/xnli2.0_german](https://huggingface.co/datasets/Harsit/xnli2.0_german) | 0 | 1 |
| | [here](https://huggingface.co/datasets/typevoid/german-company-addresses/discussions/1) | [typevoid/german-company-addresses](https://huggingface.co/datasets/typevoid/german-company-addresses) | 0 | 1 |
| | [here](https://huggingface.co/datasets/FreedomIntelligence/evol-instruct-italian/discussions/1) | [FreedomIntelligence/evol-instruct-italian](https://huggingface.co/datasets/FreedomIntelligence/evol-instruct-italian) | 0 | 1 |
| Merged | [here](https://huggingface.co/datasets/kmkarakaya/turkishReviews-ds/discussions/1#651ae845eb6c502094745048) | [kmkarakaya/turkishReviews-ds](https://huggingface.co/datasets/kmkarakaya/turkishReviews-ds) | 0 | 1 |
| | | [gia-project/gia-dataset-parquet](https://huggingface.co/datasets/gia-project/gia-dataset-parquet) | 10293 | 0 |
| | [here](https://huggingface.co/datasets/Jackmin108/c4-en-validation/discussions/1#651ab782bf3fb2499d4e8199) | [Jackmin108/c4-en-validation](https://huggingface.co/datasets/Jackmin108/c4-en-validation) | 1131 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-generated_flan_t5_large_with_features2/discussions/1) | [germank/hh-generated_flan_t5_large_with_features2](https://huggingface.co/datasets/germank/hh-generated_flan_t5_large_with_features2) | 681 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large/discussions/1) | [germank/hh-rlhf_with_features_flan_t5_large](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large) | 336 | 0 |
| | | [nimaster/Devign_for_VD](https://huggingface.co/datasets/nimaster/Devign_for_VD) | 239 | 0 |
| | [here](https://huggingface.co/datasets/vhtran/uniq-id-en/discussions/1#651ab8329e0bf1e7f82fd3eb) | [vhtran/uniq-id-en](https://huggingface.co/datasets/vhtran/uniq-id-en) | 118 | 0 |
| | [here](https://huggingface.co/datasets/manu/wmt-en-fr/discussions/1#651ab850e3558015826cde35) | [manu/wmt-en-fr](https://huggingface.co/datasets/manu/wmt-en-fr) | 107 | 0 |
| | | [Jeska/autonlp-data-vaccinfaq](https://huggingface.co/datasets/Jeska/autonlp-data-vaccinfaq) | 104 | 0 |
| | | [alvp/autonlp-data-alberti-stanza-names](https://huggingface.co/datasets/alvp/autonlp-data-alberti-stanza-names) | 102 | 0 |
| | | [alvp/autonlp-data-alberti-stanzas-finetuning](https://huggingface.co/datasets/alvp/autonlp-data-alberti-stanzas-finetuning) | 102 | 0 |
| Merged | [here](https://huggingface.co/datasets/jegormeister/dutch-snli/discussions/1) | [jegormeister/dutch-snli](https://huggingface.co/datasets/jegormeister/dutch-snli) | 90 | 0 |
| | [here](https://huggingface.co/datasets/Iskaj/dutch_corpora_parliament_processed/discussions/1) | [Iskaj/dutch_corpora_parliament_processed](https://huggingface.co/datasets/Iskaj/dutch_corpora_parliament_processed) | 88 | 0 |
| | [here](https://huggingface.co/datasets/mtc/german_seahorse_dataset_with_articles/discussions/1) | [mtc/german_seahorse_dataset_with_articles](https://huggingface.co/datasets/mtc/german_seahorse_dataset_with_articles) | 87 | 0 |
| | [here](https://huggingface.co/datasets/dmayhem93/agieval-logiqa-en/discussions/1#651ab8cd9e0bf1e7f82ffa01) | [dmayhem93/agieval-logiqa-en](https://huggingface.co/datasets/dmayhem93/agieval-logiqa-en) | 86 | 0 |
| | [here](https://huggingface.co/datasets/dmayhem93/agieval-sat-en-without-passage/discussions/1#651ab8efda7605b21396f125) | [dmayhem93/agieval-sat-en-without-passage](https://huggingface.co/datasets/dmayhem93/agieval-sat-en-without-passage) | 86 | 0 |
| | [here](https://huggingface.co/datasets/manu/opus100-en-fr/discussions/1#651ab90de570bf249254d7ae) | [manu/opus100-en-fr](https://huggingface.co/datasets/manu/opus100-en-fr) | 76 | 0 |
| | [here](https://huggingface.co/datasets/manu/french_librispeech_text_only/discussions/1) | [manu/french_librispeech_text_only](https://huggingface.co/datasets/manu/french_librispeech_text_only) | 76 | 0 |
| | [here](https://huggingface.co/datasets/roskoN/stereoset_german/discussions/1) | [roskoN/stereoset_german](https://huggingface.co/datasets/roskoN/stereoset_german) | 74 | 0 |
| | | [ejschwartz/oo-method-test-split](https://huggingface.co/datasets/ejschwartz/oo-method-test-split) | 53 | 0 |
| | | [PierreLepagnol/WRENCH](https://huggingface.co/datasets/PierreLepagnol/WRENCH) | 49 | 0 |
| | | [mammoth-blaze/ParcelSummaryDS](https://huggingface.co/datasets/mammoth-blaze/ParcelSummaryDS) | 49 | 0 |
| | [here](https://huggingface.co/datasets/afkfatih/turkishdataset/discussions/1#651ae795fa4bf59ced650092) | [afkfatih/turkishdataset](https://huggingface.co/datasets/afkfatih/turkishdataset) | 48 | 0 |
| | | [Isaak-Carter/Function_Calling_Private_GG](https://huggingface.co/datasets/Isaak-Carter/Function_Calling_Private_GG) | 43 | 0 |
| | [here](https://huggingface.co/datasets/stas/wmt16-en-ro-pre-processed/discussions/1#651ab96911f562eb7f04aa5e) | [stas/wmt16-en-ro-pre-processed](https://huggingface.co/datasets/stas/wmt16-en-ro-pre-processed) | 40 | 0 |
| Merged | [here](https://huggingface.co/datasets/paoloitaliani/news_articles/discussions/1) | [paoloitaliani/news_articles](https://huggingface.co/datasets/paoloitaliani/news_articles) | 40 | 0 |
| Merged | [here](https://huggingface.co/datasets/pszemraj/simplepile-lite/discussions/1) | [pszemraj/simplepile-lite](https://huggingface.co/datasets/pszemraj/simplepile-lite) | 33 | 0 |
| | [here](https://huggingface.co/datasets/webimmunization/COVID-19-conspiracy-theories-tweets/discussions/2) | [webimmunization/COVID-19-conspiracy-theories-tweets](https://huggingface.co/datasets/webimmunization/COVID-19-conspiracy-theories-tweets) | 31 | 0 |
| | | [rdpahalavan/UNSW-NB15](https://huggingface.co/datasets/rdpahalavan/UNSW-NB15) | 30 | 0 |
| | | [marekk/testing_dataset_article_category](https://huggingface.co/datasets/marekk/testing_dataset_article_category) | 28 | 0 |
| Merged | [here](https://huggingface.co/datasets/Suchinthana/Databricks-Dolly-15k-si-en-mix/discussions/1#651ab9d4c69ca64b8dac2f8e) | [Suchinthana/Databricks-Dolly-15k-si-en-mix](https://huggingface.co/datasets/Suchinthana/Databricks-Dolly-15k-si-en-mix) | 24 | 0 |
| | | [rdpahalavan/CIC-IDS2017](https://huggingface.co/datasets/rdpahalavan/CIC-IDS2017) | 22 | 0 |
| | | [Admin08077/STUPID](https://huggingface.co/datasets/Admin08077/STUPID) | 21 | 0 |
| | [here](https://huggingface.co/datasets/serbog/job_listing_german_cleaned_bert/discussions/1) | [serbog/job_listing_german_cleaned_bert](https://huggingface.co/datasets/serbog/job_listing_german_cleaned_bert) | 20 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-generated_flan_t5_large_with_features2_flan_t5_large/discussions/1) | [germank/hh-generated_flan_t5_large_with_features2_flan_t5_large](https://huggingface.co/datasets/germank/hh-generated_flan_t5_large_with_features2_flan_t5_large) | 16 | 0 |
| | [here](https://huggingface.co/datasets/W4nkel/turkish-sentiment-dataset/discussions/1#651ae7c3ad11961965111641) | [W4nkel/turkish-sentiment-dataset](https://huggingface.co/datasets/W4nkel/turkish-sentiment-dataset) | 16 | 0 |
| | | [irds/nyt](https://huggingface.co/datasets/irds/nyt) | 15 | 0 |
| | [here](https://huggingface.co/datasets/pere/italian_tweets_500k/discussions/1) | [pere/italian_tweets_500k](https://huggingface.co/datasets/pere/italian_tweets_500k) | 14 | 0 |
| | [here](https://huggingface.co/datasets/generative-newsai/news-unmasked/discussions/1) | [generative-newsai/news-unmasked](https://huggingface.co/datasets/generative-newsai/news-unmasked) | 12 | 0 |
| Merged | [here](https://huggingface.co/datasets/irds/dpr-w100/discussions/1) | [irds/dpr-w100](https://huggingface.co/datasets/irds/dpr-w100) | 12 | 0 |
| | [here](https://huggingface.co/datasets/pere/italian_tweets_10M/discussions/1) | [pere/italian_tweets_10M](https://huggingface.co/datasets/pere/italian_tweets_10M) | 11 | 0 |
| | [here](https://huggingface.co/datasets/vhtran/de-en/discussions/1#651abad1b61121b12838a021) | [vhtran/de-en](https://huggingface.co/datasets/vhtran/de-en) | 8 | 0 |
| | [here](https://huggingface.co/datasets/tbboukhari/Alpaca-in-french/discussions/1) | [tbboukhari/Alpaca-in-french](https://huggingface.co/datasets/tbboukhari/Alpaca-in-french) | 8 | 0 |
| | [here](https://huggingface.co/datasets/ismailiismail/multi_paraphrasing_french/discussions/2) | [ismailiismail/multi_paraphrasing_french](https://huggingface.co/datasets/ismailiismail/multi_paraphrasing_french) | 6 | 0 |
| Merged | [here](https://huggingface.co/datasets/TigerResearch/tigerbot-wiki-qa-bart-en-10k/discussions/1#651abb4488af1b75481d2eb5) | [TigerResearch/tigerbot-wiki-qa-bart-en-10k](https://huggingface.co/datasets/TigerResearch/tigerbot-wiki-qa-bart-en-10k) | 5 | 0 |
| | [here](https://huggingface.co/datasets/vhtran/de-en-official/discussions/1#651abbbbc69ca64b8dac7779) | [vhtran/de-en-official](https://huggingface.co/datasets/vhtran/de-en-official) | 4 | 0 |
| | [here](https://huggingface.co/datasets/yongsun-yoon/open-ner-english/discussions/1#651abba3996b00d2900f86a7) | [yongsun-yoon/open-ner-english](https://huggingface.co/datasets/yongsun-yoon/open-ner-english) | 4 | 0 |
| | [here](https://huggingface.co/datasets/Shularp/un_multi-ar-en/discussions/1#651abb81da7605b213974dc7) | [Shularp/un_multi-ar-en](https://huggingface.co/datasets/Shularp/un_multi-ar-en) | 4 | 0 |
| | [here](https://huggingface.co/datasets/FreedomIntelligence/alpaca-gpt4-french/discussions/1) | [FreedomIntelligence/alpaca-gpt4-french](https://huggingface.co/datasets/FreedomIntelligence/alpaca-gpt4-french) | 4 | 0 |
| Merged | [here](https://huggingface.co/datasets/kmkarakaya/turkishReviews-ds-mini/discussions/1#651ae7d9ccad5410910c4bc3) | [kmkarakaya/turkishReviews-ds-mini](https://huggingface.co/datasets/kmkarakaya/turkishReviews-ds-mini) | 4 | 0 |
| | [here](https://huggingface.co/datasets/erkanxyzalaca/turkishKuran/discussions/1#651ae80b5e0d2101c96638e2) | [erkanxyzalaca/turkishKuran](https://huggingface.co/datasets/erkanxyzalaca/turkishKuran) | 4 | 0 |
| Merged | [here](https://huggingface.co/datasets/indiejoseph/wikipedia-en-filtered/discussions/1#651abc11a9e1c4c6cdd03916) | [indiejoseph/wikipedia-en-filtered](https://huggingface.co/datasets/indiejoseph/wikipedia-en-filtered) | 3 | 0 |
| Merged | [here](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-en-fr/discussions/1#651abbf7be3dd64112847e1d) | [thesistranslation/distilled-ccmatrix-en-fr](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-en-fr) | 3 | 0 |
| | [here](https://huggingface.co/datasets/lsb/million-english-numbers/discussions/1#651abbd556e1d8e756d2c65d) | [lsb/million-english-numbers](https://huggingface.co/datasets/lsb/million-english-numbers) | 3 | 0 |
| | [here](https://huggingface.co/datasets/thomasavare/italian-dataset-deepl2/discussions/2) | [thomasavare/italian-dataset-deepl2](https://huggingface.co/datasets/thomasavare/italian-dataset-deepl2) | 3 | 0 |
| | [here](https://huggingface.co/datasets/Jackmin108/c4-en-validation-mini/discussions/1#651abcac977774bdec1784e0) | [Jackmin108/c4-en-validation-mini](https://huggingface.co/datasets/Jackmin108/c4-en-validation-mini) | 2 | 0 |
| Merged | [here](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-de-en/discussions/1#651abc82aa88d6caadcc0410) | [thesistranslation/distilled-ccmatrix-de-en](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-de-en) | 2 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-zh-en/discussions/1#651abc526a6b822b88debf13) | [yezhengli9/wmt20-zh-en](https://huggingface.co/datasets/yezhengli9/wmt20-zh-en) | 2 | 0 |
| | [here](https://huggingface.co/datasets/masoudjs/c4-en-html-with-metadata-ppl-clean/discussions/1#651abc31be3dd64112848501) | [masoudjs/c4-en-html-with-metadata-ppl-clean](https://huggingface.co/datasets/masoudjs/c4-en-html-with-metadata-ppl-clean) | 2 | 0 |
| | [here](https://huggingface.co/datasets/FreedomIntelligence/sharegpt-french/discussions/1) | [FreedomIntelligence/sharegpt-french](https://huggingface.co/datasets/FreedomIntelligence/sharegpt-french) | 2 | 0 |
| | [here](https://huggingface.co/datasets/serbog/job_listing_german_cleaned/discussions/1) | [serbog/job_listing_german_cleaned](https://huggingface.co/datasets/serbog/job_listing_german_cleaned) | 2 | 0 |
| | [here](https://huggingface.co/datasets/erebos/germanZickleinLLAMA2Dataset/discussions/1) | [erebos/germanZickleinLLAMA2Dataset](https://huggingface.co/datasets/erebos/germanZickleinLLAMA2Dataset) | 2 | 0 |
| | [here](https://huggingface.co/datasets/FreedomIntelligence/sharegpt-italian/discussions/1) | [FreedomIntelligence/sharegpt-italian](https://huggingface.co/datasets/FreedomIntelligence/sharegpt-italian) | 2 | 0 |
| | [here](https://huggingface.co/datasets/thomasavare/italian-dataset-helsinki/discussions/1) | [thomasavare/italian-dataset-helsinki](https://huggingface.co/datasets/thomasavare/italian-dataset-helsinki) | 2 | 0 |
| | [here](https://huggingface.co/datasets/OpenFact/CLEF23-CheckThat-1b-en/discussions/1#651ac040977774bdec18067f) | [OpenFact/CLEF23-CheckThat-1b-en](https://huggingface.co/datasets/OpenFact/CLEF23-CheckThat-1b-en) | 1 | 0 |
| Merged | [here](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-es-en/discussions/1#651ac0267febf41d1222745f) | [thesistranslation/distilled-ccmatrix-es-en](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-es-en) | 1 | 0 |
| Merged | [here](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-en-es/discussions/1#651ac014715329b230298f88) | [thesistranslation/distilled-ccmatrix-en-es](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-en-es) | 1 | 0 |
| Merged | [here](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-fr-en/discussions/1#651ac002c3093392e0480676) | [thesistranslation/distilled-ccmatrix-fr-en](https://huggingface.co/datasets/thesistranslation/distilled-ccmatrix-fr-en) | 1 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-split/discussions/1#651abcf5bab322bb63de27da) | [shreevigneshs/iwslt-2023-en-vi-train-split](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-split) | 1 | 0 |
| | [here](https://huggingface.co/datasets/vekkt/french_CEFR/discussions/1) | [vekkt/french_CEFR](https://huggingface.co/datasets/vekkt/french_CEFR) | 1 | 0 |
| | [here](https://huggingface.co/datasets/thisserand/health_care_german/discussions/1) | [thisserand/health_care_german](https://huggingface.co/datasets/thisserand/health_care_german) | 1 | 0 |
| | [here](https://huggingface.co/datasets/scribis/italian-literature-corpus-mini/discussions/1) | [scribis/italian-literature-corpus-mini](https://huggingface.co/datasets/scribis/italian-literature-corpus-mini) | 1 | 0 |
| | [here](https://huggingface.co/datasets/FreedomIntelligence/alpaca-gpt4-italian/discussions/1) | [FreedomIntelligence/alpaca-gpt4-italian](https://huggingface.co/datasets/FreedomIntelligence/alpaca-gpt4-italian) | 1 | 0 |
| | [here](https://huggingface.co/datasets/manu/europarl-en-fr/discussions/1#651ac9bf11f562eb7f079e78) | [manu/europarl-en-fr](https://huggingface.co/datasets/manu/europarl-en-fr) | 0 | 0 |
| | [here](https://huggingface.co/datasets/buddhist-nlp/buddhist-zh-en-with-gpt/discussions/1#651ac9a1a36fadd8776b76dd) | [buddhist-nlp/buddhist-zh-en-with-gpt](https://huggingface.co/datasets/buddhist-nlp/buddhist-zh-en-with-gpt) | 0 | 0 |
| | [here](https://huggingface.co/datasets/neil-code/subset-data-en-zh/discussions/1#651ac98a9c4067f3b89935c0) | [neil-code/subset-data-en-zh](https://huggingface.co/datasets/neil-code/subset-data-en-zh) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-ente-da-sys-test/discussions/1#651ac9449e0bf1e7f8331b82) | [dipteshkanojia/t5-qe-2023-ente-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-ente-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enta-da-sys-test/discussions/1#651ac937aa7da01954c03a27) | [dipteshkanojia/t5-qe-2023-enta-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enta-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enmr-da-sys-test/discussions/1#651ac926d03e9190093559a3) | [dipteshkanojia/t5-qe-2023-enmr-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enmr-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enhi-da-sys-test/discussions/1#651ac91569d3438f0f27501c) | [dipteshkanojia/t5-qe-2023-enhi-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enhi-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-engu-da-sys-test/discussions/1#651ac904394b647a6434d949) | [dipteshkanojia/t5-qe-2023-engu-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-engu-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-ente-da-test/discussions/1#651ac8f4996b00d29011d611) | [dipteshkanojia/t5-qe-2023-ente-da-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-ente-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enmr-da-test/discussions/1#651ac8e44dba2d9ed14616c4) | [dipteshkanojia/t5-qe-2023-enmr-da-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enmr-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enta-da-test/discussions/1#651ac8d8394b647a6434d2f6) | [dipteshkanojia/t5-qe-2023-enta-da-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enta-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enhi-da-test/discussions/1#651ac8c1551c9a100b07e5ec) | [dipteshkanojia/t5-qe-2023-enhi-da-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-enhi-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-engu-da-test/discussions/1#651ac8ae394b647a6434ccc2) | [dipteshkanojia/t5-qe-2023-engu-da-test](https://huggingface.co/datasets/dipteshkanojia/t5-qe-2023-engu-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-da-sys-test/discussions/1#651ac8957febf41d12242744) | [dipteshkanojia/llama-2-qe-2023-ente-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-da-sys-test/discussions/1#651ac886b3e605cc4cea0859) | [dipteshkanojia/llama-2-qe-2023-enta-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-da-sys-test/discussions/1#651ac8768a5c072ce16a39f0) | [dipteshkanojia/llama-2-qe-2023-enmr-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-da-sys-test/discussions/1#651ac8646effdc27ae2b0cca) | [dipteshkanojia/llama-2-qe-2023-enhi-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-da-sys-test/discussions/1#651ac854977774bdec191193) | [dipteshkanojia/llama-2-qe-2023-engu-da-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-da-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-da-test/discussions/1#651ac841a36fadd8776b3cf7) | [dipteshkanojia/llama-2-qe-2023-ente-da-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-da-test/discussions/1#651ac83114846378181edef0) | [dipteshkanojia/llama-2-qe-2023-enta-da-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-da-test/discussions/1#651ac82328c2633de9611ba2) | [dipteshkanojia/llama-2-qe-2023-enmr-da-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-da-test/discussions/1#651ac813c4fdc1c93efd1abd) | [dipteshkanojia/llama-2-qe-2023-enhi-da-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-da-test/discussions/1#651ac803dcfe1eed916654c9) | [dipteshkanojia/llama-2-qe-2023-engu-da-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-da-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-sys-test/discussions/1#651ac7f1c4fdc1c93efd150c) | [dipteshkanojia/llama-2-qe-2023-enta-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-sys-test/discussions/1#651ac7e1715329b2302b309e) | [dipteshkanojia/llama-2-qe-2023-ente-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-sys-test/discussions/1#651ac7cdaa7da01954bff621) | [dipteshkanojia/llama-2-qe-2023-enmr-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-sys-test/discussions/1#651ac7c196e6bcaa1411b5d3) | [dipteshkanojia/llama-2-qe-2023-enhi-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-sys-test/discussions/1#651ac7b32bc734f0fa0e7b0c) | [dipteshkanojia/llama-2-qe-2023-engu-sys-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-sys-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-test/discussions/1#651ac7a3e3558015826f1b0a) | [dipteshkanojia/llama-2-qe-2023-ente-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-ente-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-test/discussions/1#651ac786be3dd641128612f0) | [dipteshkanojia/llama-2-qe-2023-enta-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enta-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-test/discussions/1#651ac776655e3fdc2a80c0bc) | [dipteshkanojia/llama-2-qe-2023-enmr-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enmr-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-test/discussions/1#651ac766c4fdc1c93efd0661) | [dipteshkanojia/llama-2-qe-2023-enhi-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-enhi-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-test/discussions/1#651ac74ef4c139a2f7fa3351) | [dipteshkanojia/llama-2-qe-2023-engu-test](https://huggingface.co/datasets/dipteshkanojia/llama-2-qe-2023-engu-test) | 0 | 0 |
| | [here](https://huggingface.co/datasets/ahazeemi/opus-it-en-de-new/discussions/1#651ac72ed03e91900935037f) | [ahazeemi/opus-it-en-de-new](https://huggingface.co/datasets/ahazeemi/opus-it-en-de-new) | 0 | 0 |
| | [here](https://huggingface.co/datasets/aimona/stripchat-fixed-grammar-eng/discussions/1#651ac72156e1d8e756d4acd7) | [aimona/stripchat-fixed-grammar-eng](https://huggingface.co/datasets/aimona/stripchat-fixed-grammar-eng) | 0 | 0 |
| | [here](https://huggingface.co/datasets/phi0108/demo-noun-phrase-en/discussions/1#651ac6f8655e3fdc2a80a8bb) | [phi0108/demo-noun-phrase-en](https://huggingface.co/datasets/phi0108/demo-noun-phrase-en) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/ChanceFocus/flare-multifin-en/discussions/1#651ac6e68e62b015b8438a94) | [ChanceFocus/flare-multifin-en](https://huggingface.co/datasets/ChanceFocus/flare-multifin-en) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/kaleinaNyan/wmt19_ru-en/discussions/1#651ac6d0977774bdec18e32b) | [kaleinaNyan/wmt19_ru-en](https://huggingface.co/datasets/kaleinaNyan/wmt19_ru-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/VFiona/covid-19-synthetic-it-en-5000/discussions/1#651ac6be7febf41d1223cf89) | [VFiona/covid-19-synthetic-it-en-5000](https://huggingface.co/datasets/VFiona/covid-19-synthetic-it-en-5000) | 0 | 0 |
| | [here](https://huggingface.co/datasets/ahazeemi/opus-law-en-de-new/discussions/1#651ac6ac2bc734f0fa0e5785) | [ahazeemi/opus-law-en-de-new](https://huggingface.co/datasets/ahazeemi/opus-law-en-de-new) | 0 | 0 |
| | [here](https://huggingface.co/datasets/VFiona/covid-19-synthetic-it-en-10000/discussions/1#651ac69a28c2633de960de71) | [VFiona/covid-19-synthetic-it-en-10000](https://huggingface.co/datasets/VFiona/covid-19-synthetic-it-en-10000) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/flozi00/oasst1-en-to-de/discussions/1#651ac67f655e3fdc2a80981b) | [flozi00/oasst1-en-to-de](https://huggingface.co/datasets/flozi00/oasst1-en-to-de) | 0 | 0 |
| | [here](https://huggingface.co/datasets/pvduy/oasst-h4-en/discussions/2#651ac64ada7605b213993185) | [pvduy/oasst-h4-en](https://huggingface.co/datasets/pvduy/oasst-h4-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-ta/discussions/1#651ac635dcfe1eed916608a8) | [yezhengli9/wmt20-en-ta](https://huggingface.co/datasets/yezhengli9/wmt20-en-ta) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-cs-en/discussions/1#651ac588394b647a64343774) | [yezhengli9/wmt20-cs-en](https://huggingface.co/datasets/yezhengli9/wmt20-cs-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-cs/discussions/1#651ac57a28c2633de960b37a) | [yezhengli9/wmt20-en-cs](https://huggingface.co/datasets/yezhengli9/wmt20-en-cs) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-iu-en/discussions/1#651ac567c4fdc1c93efcc6b0) | [yezhengli9/wmt20-iu-en](https://huggingface.co/datasets/yezhengli9/wmt20-iu-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-ru/discussions/1#651ac558bab322bb63df9277) | [yezhengli9/wmt20-en-ru](https://huggingface.co/datasets/yezhengli9/wmt20-en-ru) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-ps/discussions/1#651ac54adeec0b994149f510) | [yezhengli9/wmt20-en-ps](https://huggingface.co/datasets/yezhengli9/wmt20-en-ps) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-ta-en/discussions/1#651ac52d11f562eb7f06ed57) | [yezhengli9/wmt20-ta-en](https://huggingface.co/datasets/yezhengli9/wmt20-ta-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-pl-en/discussions/1#651ac51f11f562eb7f06ea7f) | [yezhengli9/wmt20-pl-en](https://huggingface.co/datasets/yezhengli9/wmt20-pl-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-zh/discussions/1#651ac50fbe3dd6411285aba2) | [yezhengli9/wmt20-en-zh](https://huggingface.co/datasets/yezhengli9/wmt20-en-zh) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-ps-en/discussions/1#651ac4fcf0354540aa1c8b2c) | [yezhengli9/wmt20-ps-en](https://huggingface.co/datasets/yezhengli9/wmt20-ps-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-pl/discussions/1#651ac4e2c69ca64b8dadb35f) | [yezhengli9/wmt20-en-pl](https://huggingface.co/datasets/yezhengli9/wmt20-en-pl) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-ru-en/discussions/1#651ac4cd9c4067f3b8985810) | [yezhengli9/wmt20-ru-en](https://huggingface.co/datasets/yezhengli9/wmt20-ru-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-iu/discussions/1#651ac4ba0b13514f9885e927) | [yezhengli9/wmt20-en-iu](https://huggingface.co/datasets/yezhengli9/wmt20-en-iu) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-ja-en/discussions/1#651ac48fd03e9190093470a5) | [yezhengli9/wmt20-ja-en](https://huggingface.co/datasets/yezhengli9/wmt20-ja-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-ja/discussions/1#651ac47ce3558015826ea6d1) | [yezhengli9/wmt20-en-ja](https://huggingface.co/datasets/yezhengli9/wmt20-en-ja) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-km/discussions/1#651ac46a88af1b75481eba7c) | [yezhengli9/wmt20-en-km](https://huggingface.co/datasets/yezhengli9/wmt20-en-km) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-en-de/discussions/1#651ac4326e33be3f9b0e20af) | [yezhengli9/wmt20-en-de](https://huggingface.co/datasets/yezhengli9/wmt20-en-de) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yezhengli9/wmt20-de-en/discussions/1#651ac41a1c53eaa6dbae71fd) | [yezhengli9/wmt20-de-en](https://huggingface.co/datasets/yezhengli9/wmt20-de-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/alvations/globalvoices-de-en/discussions/1#651ac4069e0bf1e7f83212cf) | [alvations/globalvoices-de-en](https://huggingface.co/datasets/alvations/globalvoices-de-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/alvations/aymara-english/discussions/1#651ac3f2b693acb5195a3bd2) | [alvations/aymara-english](https://huggingface.co/datasets/alvations/aymara-english) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ru-train-val-split-0.2/discussions/1#651ac3b16e33be3f9b0e026b) | [shreevigneshs/iwslt-2023-en-ru-train-val-split-0.2](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ru-train-val-split-0.2) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-pt-train-val-split-0.2/discussions/1#651ac3a1e3558015826e969d) | [shreevigneshs/iwslt-2023-en-pt-train-val-split-0.2](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-pt-train-val-split-0.2) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ko-train-val-split-0.2/discussions/1#651ac38cd007d5f9b5b33157) | [shreevigneshs/iwslt-2023-en-ko-train-val-split-0.2](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ko-train-val-split-0.2) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-val-split-0.2/discussions/1#651ac378822edee297c97ec8) | [shreevigneshs/iwslt-2023-en-vi-train-val-split-0.2](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-val-split-0.2) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-es-train-val-split-0.1/discussions/1#651ac2b4d007d5f9b5b31565) | [shreevigneshs/iwslt-2023-en-es-train-val-split-0.1](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-es-train-val-split-0.1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ko-train-val-split-0.1/discussions/1#651ac2a1d007d5f9b5b3111a) | [shreevigneshs/iwslt-2023-en-ko-train-val-split-0.1](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ko-train-val-split-0.1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-val-split-0.1/discussions/1#651ac28bf4c139a2f7f976e3) | [shreevigneshs/iwslt-2023-en-vi-train-val-split-0.1](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-vi-train-val-split-0.1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/cahya/instructions-en/discussions/1#651ac25fbf3fb2499d502b3e) | [cahya/instructions-en](https://huggingface.co/datasets/cahya/instructions-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2022-en-de/discussions/1#651ac225f4c139a2f7f9632a) | [shreevigneshs/iwslt-2022-en-de](https://huggingface.co/datasets/shreevigneshs/iwslt-2022-en-de) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ko-train-split/discussions/1#651ac2146a6b822b88dfbd96) | [shreevigneshs/iwslt-2023-en-ko-train-split](https://huggingface.co/datasets/shreevigneshs/iwslt-2023-en-ko-train-split) | 0 | 0 |
| | [here](https://huggingface.co/datasets/shreevigneshs/iwslt-2022-en-es/discussions/1#651ac200f0354540aa1bded1) | [shreevigneshs/iwslt-2022-en-es](https://huggingface.co/datasets/shreevigneshs/iwslt-2022-en-es) | 0 | 0 |
| | [here](https://huggingface.co/datasets/NadiaHassan/ar-en/discussions/1#651ac1936a6b822b88dfa214) | [NadiaHassan/ar-en](https://huggingface.co/datasets/NadiaHassan/ar-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Rexhaif/mintaka-qa-en/discussions/1#651ac12e6a6b822b88df8eb2) | [Rexhaif/mintaka-qa-en](https://huggingface.co/datasets/Rexhaif/mintaka-qa-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/mbarnig/Tatoeba-en-lb/discussions/1#651ac0f324e76a098722c960) | [mbarnig/Tatoeba-en-lb](https://huggingface.co/datasets/mbarnig/Tatoeba-en-lb) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yogiyulianto/twitter-sentiment-dataset-en/discussions/1#651ac0cba9e1c4c6cdd0fc71) | [yogiyulianto/twitter-sentiment-dataset-en](https://huggingface.co/datasets/yogiyulianto/twitter-sentiment-dataset-en) | 0 | 0 |
| | [here](https://huggingface.co/datasets/vocab-transformers/wiki-en-passages-20210101/discussions/1#651ac05bb61121b128399516) | [vocab-transformers/wiki-en-passages-20210101](https://huggingface.co/datasets/vocab-transformers/wiki-en-passages-20210101) | 0 | 0 |
| | [here](https://huggingface.co/datasets/AgentWaller/dutch-formatted-oasst1/discussions/1) | [AgentWaller/dutch-formatted-oasst1](https://huggingface.co/datasets/AgentWaller/dutch-formatted-oasst1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/AgentWaller/dutch-oasst1-qlora-format/discussions/1) | [AgentWaller/dutch-oasst1-qlora-format](https://huggingface.co/datasets/AgentWaller/dutch-oasst1-qlora-format) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/BramVanroy/stackoverflow-chat-dutch-llamav2-format/discussions/1) | [BramVanroy/stackoverflow-chat-dutch-llamav2-format](https://huggingface.co/datasets/BramVanroy/stackoverflow-chat-dutch-llamav2-format) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/Harsit/xnli2.0_train_french/discussions/1) | [Harsit/xnli2.0_train_french](https://huggingface.co/datasets/Harsit/xnli2.0_train_french) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Makxxx/french_CEFR/discussions/1) | [Makxxx/french_CEFR](https://huggingface.co/datasets/Makxxx/french_CEFR) | 0 | 0 |
| | [here](https://huggingface.co/datasets/sugam11/french-snli/discussions/1) | [sugam11/french-snli](https://huggingface.co/datasets/sugam11/french-snli) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Brendan/nlp244_french_snli/discussions/1) | [Brendan/nlp244_french_snli](https://huggingface.co/datasets/Brendan/nlp244_french_snli) | 0 | 0 |
| | [here](https://huggingface.co/datasets/pvisnrt/french-snli/discussions/1) | [pvisnrt/french-snli](https://huggingface.co/datasets/pvisnrt/french-snli) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/pranjali97/french_translated_snli/discussions/1) | [pranjali97/french_translated_snli](https://huggingface.co/datasets/pranjali97/french_translated_snli) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/FreedomIntelligence/evol-instruct-french/discussions/1) | [FreedomIntelligence/evol-instruct-french](https://huggingface.co/datasets/FreedomIntelligence/evol-instruct-french) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/gollumeo/french-litterature/discussions/1) | [gollumeo/french-litterature](https://huggingface.co/datasets/gollumeo/french-litterature) | 0 | 0 |
| | [here](https://huggingface.co/datasets/nielsr/datacomp_small_french_captions/discussions/1) | [nielsr/datacomp_small_french_captions](https://huggingface.co/datasets/nielsr/datacomp_small_french_captions) | 0 | 0 |
| | [here](https://huggingface.co/datasets/manu/french_5p/discussions/1) | [manu/french_5p](https://huggingface.co/datasets/manu/french_5p) | 0 | 0 |
| | [here](https://huggingface.co/datasets/fathyshalab/google-presto-german/discussions/1) | [fathyshalab/google-presto-german](https://huggingface.co/datasets/fathyshalab/google-presto-german) | 0 | 0 |
| | [here](https://huggingface.co/datasets/dvilasuero/alpaca-german-validation/discussions/1) | [dvilasuero/alpaca-german-validation](https://huggingface.co/datasets/dvilasuero/alpaca-german-validation) | 0 | 0 |
| | [here](https://huggingface.co/datasets/fathyshalab/germanquad_qg_qg_dataset/discussions/1) | [fathyshalab/germanquad_qg_qg_dataset](https://huggingface.co/datasets/fathyshalab/germanquad_qg_qg_dataset) | 0 | 0 |
| | [here](https://huggingface.co/datasets/fathyshalab/germanquad_qaeval_dataset/discussions/1) | [fathyshalab/germanquad_qaeval_dataset](https://huggingface.co/datasets/fathyshalab/germanquad_qaeval_dataset) | 0 | 0 |
| | [here](https://huggingface.co/datasets/AgentWaller/german-oasst1-qlora-format/discussions/2) | [AgentWaller/german-oasst1-qlora-format](https://huggingface.co/datasets/AgentWaller/german-oasst1-qlora-format) | 0 | 0 |
| | [here](https://huggingface.co/datasets/AgentWaller/german-oasst1-qa-format/discussions/1) | [AgentWaller/german-oasst1-qa-format](https://huggingface.co/datasets/AgentWaller/german-oasst1-qa-format) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Jakelolipopp/truthful_qa-validation-german_q_n_a/discussions/1) | [Jakelolipopp/truthful_qa-validation-german_q_n_a](https://huggingface.co/datasets/Jakelolipopp/truthful_qa-validation-german_q_n_a) | 0 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-rlhf_with_features/discussions/1) | [germank/hh-rlhf_with_features](https://huggingface.co/datasets/germank/hh-rlhf_with_features) | 0 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large-no_eos/discussions/1) | [germank/hh-rlhf_with_features_flan_t5_large-no_eos](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large-no_eos) | 0 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large_lll_relabeled/discussions/1) | [germank/hh-rlhf_with_features_flan_t5_large_lll_relabeled](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large_lll_relabeled) | 0 | 0 |
| | [here](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large_rx/discussions/1) | [germank/hh-rlhf_with_features_flan_t5_large_rx](https://huggingface.co/datasets/germank/hh-rlhf_with_features_flan_t5_large_rx) | 0 | 0 |
| | [here](https://huggingface.co/datasets/philschmid/prompted-germanquad/discussions/1) | [philschmid/prompted-germanquad](https://huggingface.co/datasets/philschmid/prompted-germanquad) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Harsit/xnli2.0_train_german/discussions/1) | [Harsit/xnli2.0_train_german](https://huggingface.co/datasets/Harsit/xnli2.0_train_german) | 0 | 0 |
| | [here](https://huggingface.co/datasets/akash418/german_europarl/discussions/1) | [akash418/german_europarl](https://huggingface.co/datasets/akash418/german_europarl) | 0 | 0 |
| | [here](https://huggingface.co/datasets/flxclxc/english-norwegian-bible-set/discussions/1#651b292fccad5410911777de) | [flxclxc/english-norwegian-bible-set](https://huggingface.co/datasets/flxclxc/english-norwegian-bible-set) | 0 | 0 |
| | [here](https://huggingface.co/datasets/volkanaltintas/turkishTradeReviews-ds-mini-4000/discussions/1#651ae85ba6e00a1678bf6469) | [volkanaltintas/turkishTradeReviews-ds-mini-4000](https://huggingface.co/datasets/volkanaltintas/turkishTradeReviews-ds-mini-4000) | 0 | 0 |
| | [here](https://huggingface.co/datasets/cansen88/turkishReviews_5_topic/discussions/1#651ae93877d6b4b1ea4e17d7) | [cansen88/turkishReviews_5_topic](https://huggingface.co/datasets/cansen88/turkishReviews_5_topic) | 0 | 0 |
| | [here](https://huggingface.co/datasets/orhanxakarsu/turkishReviews-ds-mini/discussions/1#651ae958003b43b95133496f) | [orhanxakarsu/turkishReviews-ds-mini](https://huggingface.co/datasets/orhanxakarsu/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-ds-mini1/discussions/1#651ae99c0010bbb67013b4da) | [orhanxakarsu/turkishPoe-ds-mini1](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-ds-mini1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-ds-mini2/discussions/1#651aeaa4cd08536ba4cb9abe) | [orhanxakarsu/turkishPoe-ds-mini2](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-ds-mini2) | 0 | 0 |
| | [here](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-generation/discussions/1#651aeab6a6e00a1678bfc778) | [orhanxakarsu/turkishPoe-generation](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-generation) | 0 | 0 |
| | [here](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-generation-1/discussions/1#651aeacd888a4dcfa4918bce) | [orhanxakarsu/turkishPoe-generation-1](https://huggingface.co/datasets/orhanxakarsu/turkishPoe-generation-1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/orhanxakarsu/turkish-poem-generation/discussions/1#651aeadcdae56722e34b4735) | [orhanxakarsu/turkish-poem-generation](https://huggingface.co/datasets/orhanxakarsu/turkish-poem-generation) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Harsit/xnli2.0_turkish/discussions/1#651aeb0c14145f2a00e9af5c) | [Harsit/xnli2.0_turkish](https://huggingface.co/datasets/Harsit/xnli2.0_turkish) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Harsit/xnli2.0_train_turkish/discussions/1#651aeb1f14145f2a00e9b55b) | [Harsit/xnli2.0_train_turkish](https://huggingface.co/datasets/Harsit/xnli2.0_train_turkish) | 0 | 0 |
| | [here](https://huggingface.co/datasets/eminecg/turkishReviews-ds-mini/discussions/1#651aeb33b08a2b1588ae791b) | [eminecg/turkishReviews-ds-mini](https://huggingface.co/datasets/eminecg/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/erkanxyzalaca/turkishReviews-ds-mini/discussions/1#651aeb43bec377c8b84dccef) | [erkanxyzalaca/turkishReviews-ds-mini](https://huggingface.co/datasets/erkanxyzalaca/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/ozz/turkishReviews-ds-mini/discussions/1#651aeb55a467986d401a35df) | [ozz/turkishReviews-ds-mini](https://huggingface.co/datasets/ozz/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/erytrn/turkishReviews-ds-mini/discussions/1#651aeb97b117eac9222b70f2) | [erytrn/turkishReviews-ds-mini](https://huggingface.co/datasets/erytrn/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/erytrn/turkishReviews-ds-mini2/discussions/1#651aeba5b08a2b1588ae89a6) | [erytrn/turkishReviews-ds-mini2](https://huggingface.co/datasets/erytrn/turkishReviews-ds-mini2) | 0 | 0 |
| | [here](https://huggingface.co/datasets/ramazank2000/turkishReviews-ds-mini1/discussions/1#651aebb3704bfab3988e1608) | [ramazank2000/turkishReviews-ds-mini1](https://huggingface.co/datasets/ramazank2000/turkishReviews-ds-mini1) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Hilalcelik/turkishReviews-ds-mini/discussions/1#651aebc10010bbb6701436ab) | [Hilalcelik/turkishReviews-ds-mini](https://huggingface.co/datasets/Hilalcelik/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/sebinbusra/turkishReviews-ds-mini/discussions/1#651aebcf1a90782f9c92b201) | [sebinbusra/turkishReviews-ds-mini](https://huggingface.co/datasets/sebinbusra/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/kaaniince/turkishReviews-project/discussions/1#651aebeb2930812657b3138f) | [kaaniince/turkishReviews-project](https://huggingface.co/datasets/kaaniince/turkishReviews-project) | 0 | 0 |
| | [here](https://huggingface.co/datasets/kaaniince/turkishReviews-ds-textGeneration/discussions/1#651aebfa52659d023a23671d) | [kaaniince/turkishReviews-ds-textGeneration](https://huggingface.co/datasets/kaaniince/turkishReviews-ds-textGeneration) | 0 | 0 |
| | [here](https://huggingface.co/datasets/AzerKBU/turkishReviews-ds-mini/discussions/1#651aec0b52659d023a23692f) | [AzerKBU/turkishReviews-ds-mini](https://huggingface.co/datasets/AzerKBU/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/bosnakdev/turkishReviews-ds-mini/discussions/1#651aec1b7a7ad76a365d0051) | [bosnakdev/turkishReviews-ds-mini](https://huggingface.co/datasets/bosnakdev/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yankihue/tweets-turkish/discussions/1#651aec2e52659d023a236e34) | [yankihue/tweets-turkish](https://huggingface.co/datasets/yankihue/tweets-turkish) | 0 | 0 |
| | [here](https://huggingface.co/datasets/yankihue/turkish-news-categories/discussions/1#651aec3dcd08536ba4cbd825) | [yankihue/turkish-news-categories](https://huggingface.co/datasets/yankihue/turkish-news-categories) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/Mursel/turkishReviews-ds-mini/discussions/1#651aec4ddae56722e34b779d) | [Mursel/turkishReviews-ds-mini](https://huggingface.co/datasets/Mursel/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Veyselbyte/turkishReviews-ds-mini/discussions/1#651aec5f6ca982328d0e7463) | [Veyselbyte/turkishReviews-ds-mini](https://huggingface.co/datasets/Veyselbyte/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/cagrimehmet/turkishReviews-ds-mini/discussions/1#651aec6adf4244e94a7710a6) | [cagrimehmet/turkishReviews-ds-mini](https://huggingface.co/datasets/cagrimehmet/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/styraist/turkishReview-ds-mini/discussions/1#651aec77cd08536ba4cbe0c7) | [styraist/turkishReview-ds-mini](https://huggingface.co/datasets/styraist/turkishReview-ds-mini) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/serkandyck/turkish_instructions/discussions/1#651aec89d67d22a16abaed2a) | [serkandyck/turkish_instructions](https://huggingface.co/datasets/serkandyck/turkish_instructions) | 0 | 0 |
| | [here](https://huggingface.co/datasets/Memis/turkishReviews-ds-mini/discussions/1#651aec95a6e00a1678c00c78) | [Memis/turkishReviews-ds-mini](https://huggingface.co/datasets/Memis/turkishReviews-ds-mini) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/PulsarAI/turkish_movie_sentiment/discussions/1#651aecb96ef522c487d5ef62) | [PulsarAI/turkish_movie_sentiment](https://huggingface.co/datasets/PulsarAI/turkish_movie_sentiment) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/ahmet1338/turkishReviews-ds-mini/discussions/1#651aecc4d76ad9bc085fe5e5) | [ahmet1338/turkishReviews-ds-mini](https://huggingface.co/datasets/ahmet1338/turkishReviews-ds-mini) | 0 | 0 |
| | [here](https://huggingface.co/datasets/nogyxo/question-answering-ukrainian-json-answers/discussions/1) | [nogyxo/question-answering-ukrainian-json-answers](https://huggingface.co/datasets/nogyxo/question-answering-ukrainian-json-answers) | 0 | 0 |
| Merged | [here](https://huggingface.co/datasets/TokenBender/Tamil_chat_dataset/discussions/1#6527abe4d7bedf9045c20ad5) | [TokenBender/Tamil_chat_dataset](https://huggingface.co/datasets/TokenBender/Tamil_chat_dataset) | 1 | 1 |
| Merged | [here](https://huggingface.co/datasets/AnanthZeke/tamil_sentences_sample/discussions/1#6528ef7a64aaab7f818a7874) | [AnanthZeke/tamil_sentences_sample](https://huggingface.co/datasets/AnanthZeke/tamil_sentences_sample) | 21 | 0 |
| Merged | [here](https://huggingface.co/datasets/DeepPavlov/verbalist_prompts/discussions/2) | [DeepPavlov/verbalist_prompts](https://huggingface.co/datasets/DeepPavlov/verbalist_prompts) | 0 | 1 |
| huggingface/hub-docs/blob/main/hacktoberfest_challenges/datasets_without_language.md |
Gradio Demo: longest_word
```
!pip install -q gradio
```
```
import gradio as gr
def longest_word(text):
words = text.split(" ")
lengths = [len(word) for word in words]
return max(lengths)
ex = "The quick brown fox jumped over the lazy dog."
demo = gr.Interface(
longest_word, "textbox", "label", examples=[[ex]]
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/longest_word/run.ipynb |
n this video, we're going to go over the HuggingFace Model Hub navigation. This is the huggingface.co landing page. To access the model hub, click on the "Models" tab in the upper right corner. You should be facing this web interface, which can be split into several parts. On the left, you'll find categories, which you can use to tailor your model search. The first category is the "Tasks". Models on the hub may be used for a wide variety of tasks. These include natural language processing tasks, such as question answering or text classification, but it isn't only limited to NLP. Other tasks from other fields are also available, such as image classification for computer vision, or automatic speech recognition for speech. The second category is the "libraries". Models on the hub usually share one of three backbones: PyTorch, TensorFlow, or JAX. However, other backbones, such as rust or ONNX also exist. Finally, this tab can also be used to specify from which high-level framework the model comes. This includes Transformers, but it isn't limited to it. The model Hub is used to host a lot of different frameworks' models, and we are actively looking to host other frameworks' models. The third category is the "Datasets" tab. Selecting a dataset from this tab means filtering the models so that they were trained on that specific dataset. The fourth category is the "Languages" tab. Selecting a language from this tab means filtering the models so that they handle the language selected. Finally, the last category allows to choose the license with which the model is shared. On the right, you'll find the models available on the model Hub! The models are ordered by downloads. When clicking on a model, you should be facing its model card. The model card contains information about the model: its description, intended use, limitations and biases. It can also show code snippets on how to use the model, as well as any relevant information: training procedure, data processing, evaluation results, copyrights. This information is crucial for the model to be used. The better crafted a model card is, the easier it will be for other users to leverage your model in their applications. On the right of the model card is the inference API. This inference API can be used to play with the model directly. Feel free to modify the text and click on compute to see how would the model behave to your inputs. At the top of the screen lie the model tags. These include the model task, as well as any other tag that is relevant to the categories we have just seen. The "Files & Versions tab" displays the architecture of the repository of that model. Here, we can see all the files that define this model. You'll see all usual features of a git repository: the branches available, the commit history as well as the commit diff. Three different buttons are available at the top of the model card. The first one shows how to use the inference API programmatically. The second one shows how to train this model in SageMaker, and the last one shows how to load that model within the appropriate library. For BERT, this is transformers. | huggingface/course/blob/main/subtitles/en/raw/chapter4/01_huggingface-hub.md |
Advanced Topics
## Contents
- [Integrate your library with the Hub](./models-adding-libraries)
- [Adding new tasks to the Hub](./models-tasks) | huggingface/hub-docs/blob/main/docs/hub/models-advanced.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# IPNDMScheduler
`IPNDMScheduler` is a fourth-order Improved Pseudo Linear Multistep scheduler. The original implementation can be found at [crowsonkb/v-diffusion-pytorch](https://github.com/crowsonkb/v-diffusion-pytorch/blob/987f8985e38208345c1959b0ea767a625831cc9b/diffusion/sampling.py#L296).
## IPNDMScheduler
[[autodoc]] IPNDMScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/ipndm.md |
## Motivation
Without processing, english-> romanian mbart-large-en-ro gets BLEU score 26.8 on the WMT data.
With post processing, it can score 37..
Here is the postprocessing code, stolen from @mjpost in this [issue](https://github.com/pytorch/fairseq/issues/1758)
### Instructions
Note: You need to have your test_generations.txt before you start this process.
(1) Setup `mosesdecoder` and `wmt16-scripts`
```bash
cd $HOME
git clone git@github.com:moses-smt/mosesdecoder.git
cd mosesdecoder
git clone git@github.com:rsennrich/wmt16-scripts.git
```
(2) define a function for post processing.
It removes diacritics and does other things I don't understand
```bash
ro_post_process () {
sys=$1
ref=$2
export MOSES_PATH=$HOME/mosesdecoder
REPLACE_UNICODE_PUNCT=$MOSES_PATH/scripts/tokenizer/replace-unicode-punctuation.perl
NORM_PUNC=$MOSES_PATH/scripts/tokenizer/normalize-punctuation.perl
REM_NON_PRINT_CHAR=$MOSES_PATH/scripts/tokenizer/remove-non-printing-char.perl
REMOVE_DIACRITICS=$MOSES_PATH/wmt16-scripts/preprocess/remove-diacritics.py
NORMALIZE_ROMANIAN=$MOSES_PATH/wmt16-scripts/preprocess/normalise-romanian.py
TOKENIZER=$MOSES_PATH/scripts/tokenizer/tokenizer.perl
lang=ro
for file in $sys $ref; do
cat $file \
| $REPLACE_UNICODE_PUNCT \
| $NORM_PUNC -l $lang \
| $REM_NON_PRINT_CHAR \
| $NORMALIZE_ROMANIAN \
| $REMOVE_DIACRITICS \
| $TOKENIZER -no-escape -l $lang \
> $(basename $file).tok
done
# compute BLEU
cat $(basename $sys).tok | sacrebleu -tok none -s none -b $(basename $ref).tok
}
```
(3) Call the function on test_generations.txt and test.target
For example,
```bash
ro_post_process enro_finetune/test_generations.txt wmt_en_ro/test.target
```
This will split out a new blue score and write a new fine called `test_generations.tok` with post-processed outputs.
```
| huggingface/transformers/blob/main/examples/legacy/seq2seq/romanian_postprocessing.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# How To Request Support
This is an Open Source Project so please be mindful that like in any other project of this kind there is no obligation to answer all requests for help.
However, we want to encourage you to ask for help whenever you think it's needed! We are happy about every question we get because it allows us to better understand your needs, possible misunderstandings, and most importantly a way for you to help us make this library better. That being said, this document's main purpose is to provide guidelines at how you can formulate your requests to increase your chances to be understood and to get support.
There are two main venues to receive support: [the forums](https://discuss.huggingface.co/) and [the GitHub issues](https://github.com/huggingface/transformers/issues).
## The Forums
[The user forums](https://discuss.huggingface.co/) are supported by the wide community of the library users and backed up by developers when needed.
If you have a difficulty with deploying this library or some questions, or you'd like to discuss a new feature, please first consider discussing those things at the forums. Only when you feel your subject matter has been crystalized and you still need support from the library developers do proceed to file an [issue](https://github.com/huggingface/transformers/issues).
In particular all "Please explain" questions or objectively very user-specific feature requests belong to the forums. Here are some example of such questions:
* "I would like to use a BertModel within a RL-Agent for a customer support service. How can I use a BertForMaskedLM in my ChatBotModel?"
* "Could you please explain why T5 has no positional embedding matrix under T5Model?"
* "How should I set my generation parameters for translation?"
* "How to train T5 on De->En translation?"
## The GitHub Issues
Everything which hints at a bug should be opened as an [issue](https://github.com/huggingface/transformers/issues).
You are not required to read the following guidelines before opening an issue. However, if you notice that your issue doesn't get any replies, chances are that the developers have one or several difficulties with its quality. In this case, reading the following points and adjusting your issue accordingly could help.
1. Before posting an issue, first search for already posted issues, since chances are someone has already asked a similar question before you.
If you use Google your search query should be:
```
"huggingface" "transformers" your query
```
The first two quoted words tell Google to limit the search to the context of the Huggingface Transformers. The remainder is your query - most commonly this would be the error message the software fails with. We will go deeper into details shortly.
The results of such a query will typically match GitHub issues, Hugging Face forums, StackExchange, and blogs.
If you find relevant hints, you may choose to continue the discussion there if you have follow up questions.
If what you found is similar but doesn't quite answer your problem, please, post a new issue and do include links to similar issues or forum discussions you may have found.
Let's look at some examples:
The error message, often referred to as an assertion, tells us what went wrong. Here is an example of an assertion:
```python
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/transformers/src/transformers/__init__.py", line 34, in <module>
from . import dependency_versions_check
File "/transformers/src/transformers/dependency_versions_check.py", line 34, in <module>
from .utils import is_tokenizers_available
File "/transformers/src/transformers/utils/import_utils.py", line 40, in <module>
from tqdm.auto import tqdm
ModuleNotFoundError: No module named 'tqdm.auto'
```
and it typically includes a traceback, so that we can see the full stack of calls the program made before it fails. This gives us the context to know why the program failed.
Going back to the above example. If you received this error search, look at the very last line of the error which is:
```python
ModuleNotFoundError: No module named 'tqdm.auto'
```
And now we can use it to do the searching on your favorite search engine:
1. first for `"huggingface" "transformers" "ModuleNotFoundError: No module named 'tqdm.auto'"`
2. if you don't find relevant results, then search for just `"ModuleNotFoundError: No module named 'tqdm.auto'"`
3. and finally if nothing still comes up, then remove the outside quotes: `ModuleNotFoundError: No module named 'tqdm.auto'`
If the error includes any messages that include bits unique to your filesystem, always remove those in the search query since other users will not have the same filesystem as yours. For example:
```bash
python -c 'open("/tmp/wrong_path.txt", "r")'
Traceback (most recent call last):
File "<string>", line 1, in <module>
FileNotFoundError: [Errno 2] No such file or directory: '/tmp/wrong_path.txt'
```
Here you'd search for just: `"FileNotFoundError: [Errno 2] No such file or directory"`
If the local information that you removed were inside the error message and you removed them you may need to remove double quotes since your query is no longer exact. So if the error message was something like:
```bash
ValueError: '/tmp/wrong_path.txt' cannot be found
```
then you'd search for `"ValueError" "cannot be found"`
As you search you will notice that when you don't use quotes often the search engines will return a variety of unrelated hits, which may or may not be what you want.
Experiment with different ways and find which approach gives the most satisfactory results.
2. Keep the issue short, providing the information that you think will aid the developers to understand your situation. Put yourself in the shoes of the person who has never seen your code or knows anything about your custom setup. This mental exercise will help to develop an intuition to what/what not to share"
3. If there is a software failure, always provide the full traceback, for example:
```python
$ python -c 'import transformers'
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/transformers/src/transformers/__init__.py", line 34, in <module>
from . import dependency_versions_check
File "/transformers/src/transformers/dependency_versions_check.py", line 34, in <module>
from .utils import is_tokenizers_available
File "/transformers/src/transformers/utils/import_utils.py", line 40, in <module>
from tqdm.auto import tqdm
ModuleNotFoundError: No module named 'tqdm.auto'
```
As compared to providing just the last line of the error message, e.g.:
```python
ModuleNotFoundError: No module named 'tqdm.auto'
```
which is not sufficient.
If your application is running on more than one GPU (e.g. under `DistributedDataParallel`) and typically getting every log and traceback printed multiple times, please make sure that you paste only one copy of it. At times the traceback from parallel processes may get interleaved - so either disentangle these or change the loggers to log only for `local_rank==0` so that only one process logs things.
4. When quoting a traceback, command line instructions and any type of code always enclose it in triple backticks inside the editor window, that is:
````
```
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
````
If it's a command line with a long argument list, please consider breaking it down using backslashes and new lines. Here is an example of a good command line quote:
```bash
cd examples/seq2seq
torchrun --nproc_per_node=2 ./finetune_trainer.py \
--model_name_or_path sshleifer/distill-mbart-en-ro-12-4 --data_dir wmt_en_ro \
--output_dir output_dir --overwrite_output_dir \
--do_train --n_train 500 --num_train_epochs 1 \
--per_device_train_batch_size 1 --freeze_embeds \
--src_lang en_XX --tgt_lang ro_RO --task translation \
--fp16
```
If you don't break it up, one has to scroll horizontally which often makes it quite difficult to quickly see what's happening.
The backslashes allow us to copy the command directly into the console to run it, without needing to edit it.
5. Include only the important information that you think will help the developer to quickly identify the problem.
For example applications often create huge amounts of logs. Ask yourself whether providing all or parts of the log is useful.
Pasting a 100-1000 lines of log into the issue is an immediate turn off, since it will take a lot of time to figure out where the pertinent parts of the log are.
Attaching a full log can be helpful if it's done as an attachment, if it's enclosed in the following html code in the comment editor window:
```
<details>
<summary>Full log</summary>
<pre>
many
lines
go
here
</pre>
</details>
```
which would result in the following entry, which can be opened if desired, but otherwise takes little space.
<details>
<summary>Full log</summary>
<pre>
many
lines
go
here
</pre>
</details>
You could also provide a link to a pastebin service, but this is less beneficial since those links tend to expire quickly and future readers of your issue might not be able to access that log file anymore and may lack some context.
6. If this is an issue in your code, do try to reduce that code to a minimal example that still demonstrates the problem. Please ask at the forums if you have a hard time figuring how to do that. Please realize that we don't have the luxury of having time to try and understand all of your custom code.
If you really tried to make a short reproducible code but couldn't figure it out, it might be that having a traceback will give the developer enough information to know what's going on. But if it is not enough and we can't reproduce the problem, we can't really solve it.
Do not despair if you can't figure it out from the beginning, just share what you can and perhaps someone else will be able to help you at the forums.
If your setup involves any custom datasets, the best way to help us reproduce the problem is to create a [Google Colab notebook](https://colab.research.google.com/) that demonstrates the issue and once you verify that the issue still exists, include a link to that notebook in the Issue. Just make sure that you don't copy and paste the location bar url of the open notebook - as this is private and we won't be able to open it. Instead, you need to click on `Share` in the right upper corner of the notebook, select `Get Link` and then copy and paste the public link it will give to you.
7. If you forked off some of this project's code or example applications, please, do not ask us to go into your code repository and figure out what you may have done. The code is already very complex and unless there is an easy way to do a diff and it's a small diff, it won't be possible to find someone with time on their hands to make a lengthy investigation. Albeit, you might find someone at the forums who will be generous to do this for you.
8. Before reporting an issue, first, always try to update your environment to the latest official version of this library. We have no resources to go and debug older revisions, which could easily have bugs that have been fixed in the latest released version.
We understand that this is not always possible, especially when APIs change, in which case file an issue against the highest library version your environment can support.
Of course, if you upgrade the library, always retest that the problem is still there.
9. Please do not ask us to reproduce an issue with your custom data, since we don't have it. So, either you should use some existing dataset supported by HF datasets or you need to supply a code that generates a small sample on the fly, or some another quick and simple way to get it.
Please do not send us any non-public domain data that may require a license or a permission to be used.
10. Do not tag multiple developers on the issue unless you know this is expected, either because you asked them and they gave you an explicit permission to tag them or the issue template instructs you to do so.
The "who to tag for what domain" part of the issue template is there to help users direct their questions to the right developers who are designated maintainers of project's specific domains. They can then decide at their own discretion to tag other developers if they feel it'd help move the issue forward.
We currently don't have a triage service and we trust your capacity to identify the right domain and thus the persons to tag in your issue. If you are not sure, please use the forums to ask for guidance.
When in doubt, err on the side of not tagging a given person. If you tag multiple people out of context or permission don't be surprised if you get no response at all. Please remember that every time you tag someone, they get a notification and you're taking their time without their permission. Please be sensitive to that.
If you got helped by one of the developers in the past please don't tag them in future issues, unless they are listed in the issue template for the domain you are asking about or that developer gave you an explicit permission to tag them in future issues.
If you see a certain developer doing multiple and/or recent commits into a specific area of the project that you feel is relevant to your issue, it is not a good reason to tag them. Various developers may be fixing things that prevent them from moving forward, but often their work is focused on a totally different domain. And while they may or may not know how to help you with the problem at hand, it would benefit the whole community much more if they focus on the domain of their unique expertise.
11. Use the Edit button. Take your time, and re-read and improve the wording and formatting to make your posts and comments as easy to understand as possible.
Avoid posting multiple comments in a row, as each comment generates a notification for the developers tagged in that issue. If you happened to post multiple comments in a row, and nobody followed up yet - consider merging those into one or a few comments while editing the combined content to be coherent.
If you choose to edit your older comments after others posted follow up comments you need to be aware that your modifications might not be noticed, so if it's not a typo fixing, try to write a new comment flagging that something has been changed in the previous comments.
For example, the very first comment is the most important one. If while the thread unfolds you realize that things aren't as they seemed to you originally you may want to edit the first post to reflect the up-to-date understanding of the issue at hand so that it helps those who read your issue in the future quickly understand what's going on and not need to sift through dozens of comments. It also helps to indicate that the post was edited. So, those reading the thread later can understand why there might be certain discontinuity in the information flow.
Use bullets and items if you have lists of items and the outcome improves overall readability.
Use backticks to refer to class and function names, e.g. `BartModel` and `generate` as these stand out and improve the speed of a reader's comprehension.
Try not use italics and bold text too much as these often make the text more difficult to read.
12. If you are cross-referencing a specific comment in a given thread or another issue, always link to that specific comment, rather than using the issue link. If you do the latter it could be quite impossible to find which specific comment you're referring to.
To get the link to the specific comment do not copy the url from the location bar of your browser, but instead, click the `...` icon in the upper right corner of the comment and then select "Copy Link".
For example the first link is a link to an issue, and the second to a specific comment in the same issue:
1. https://github.com/huggingface/transformers/issues/9257
2. https://github.com/huggingface/transformers/issues/9257#issuecomment-749945162
13. If you are replying to a last comment, it's totally fine to make your reply with just your comment in it. The readers can follow the information flow here.
But if you're replying to a comment that happened some comments back it's always a good practice to quote just the relevant lines you're replying it. The `>` is used for quoting, or you can always use the menu to do so. For example your editor box will look like:
```
> How big is your gpu cluster?
Our cluster is made of 256 gpus.
```
If you are addressing multiple comments, quote the relevant parts of each before your answer. Some people use the same comment to do multiple replies, others separate them into separate comments. Either way works. The latter approach helps for linking to a specific comment.
In general the best way to figure out what works the best is learn from issues posted by other people - see which issues get great responses and which get little to no response - observe what the posters who received great responses did differently from those who did not.
Thank you for reading this somewhat lengthy document. We would like to conclude that these are not absolute rules, but a friendly advice that will help maximize the chances for us to understand what you are trying to communicate, reproduce the problem then resolve it to your satisfaction and the benefit of the whole community.
If after reading this document there are remaining questions on how and why or there is a need for further elucidation, please, don't hesitate to ask your question in [this thread](https://discuss.huggingface.co/t/how-to-request-support/3128).
| huggingface/transformers/blob/main/ISSUES.md |
p align="center">
<br>
<img src="docs/source/assets/simulate_library.png" width="400"/>
<br>
</p>
<p align="center">
<a href="https://github.com/huggingface/simulate/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue">
</a>
<a href="https://github.com/huggingface/simulate/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/diffusers.svg">
</a>
<a href="CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.0-4baaaa.svg">
</a>
</p>
# Simulate
**Note**: The library is not actively maintained / built, if you want to contribute, please open an issue.
Simulate is a library for easily creating and sharing simulation environments for intelligent agents (e.g. reinforcement learning) or synthetic data generation.
## Install
Install Simulate (preferentially in a virtual environment) with a simple `pip install simulate`
*Note*: `vtk` is not built for Apple Silicon with Python 3.8. Please install with >3.9 in that case.
### Install for contribution (from [CONTRIBUTING.md](CONTRIBUTING.md))
Create a virtual env and then install the code style/quality tools as well as the code base locally
```
pip install --upgrade simulate
```
Before you merge a PR, fix the style (we use `isort` + `black`)
```
make style
```
## Quick tour
Simulate's API is inspired by the great [Kubric's API](https://github.com/google-research/kubric).
The user create a `Scene` and add `Assets` in it (objects, cameras, lights etc).
Once the scene is created, you can save and share it as a file. This is a gIFT file, aka a JSON file with associated resources.
You can also render the scene or do simulations using one of the backend rendering/simulation engines (at the moment Unity, Blender and Godot).
The saving/sharing format is engine agnostic and using a graphic industry standard.
Let's do a quick exploration together.
```
import simulate as sm
scene = sm.Scene()
```
### Project Structure
The Python API is located in src/simulate. It allows creation and loading of scenes, and sending commands to the backend.
We provide several backends to render and/or run the scene.
The default backend requires no specific installation and is based on [pyvista](https://docs.pyvista.org/user-guide/index.html). It allows one to quick render/explored scene but doesn't handle physics simulation.
To allow physic simulations, the Unity backend can for instance be used by setting `engine="unity"` (and soon the Godot and Blender Engines backend as well). A Unity build will be automatically downloaded (if not already) and spawed to run simulations. Alternatively, one can download and use the Unity editor themself, which must then be opened with Unity version 2021.3.2f1.
### Loading a scene from the Hub or a local file
Loading a scene from a local file or the Hub is done with `Scene.create_from()`, saving locally or pushing to the Hub with `scene.save()` or `scene.push_to_hub()`:
```
from simulate import Scene
scene = Scene.create_from('tests/test_assets/fixtures/Box.gltf') # either local (priority) or on the Hub with full path to file
scene = Scene.create_from('simulate-tests/Box/glTF/Box.gltf', is_local=False) # Set priority to the Hub file
scene.save('local_dir/file.gltf') # Save to a local file
scene.push_to_hub('simulate-tests/Debug/glTF/Box.gltf') # Save to the Hub - use a token if necessary
scene.show()
```
<p align="center">
<br>
<img src="https://user-images.githubusercontent.com/10695622/191554717-acba4764-a4f4-4609-834a-39ddb50b844a.png" width="400"/>
<br>
<p>
### Creating a Scene and adding/managing Objects in the scene
Basic example of creating a scene with a plane and a sphere above it:
```
import simulate as sm
scene = sm.Scene()
scene += sm.Plane() + sm.Sphere(position=[0, 1, 0], radius=0.2)
>>> scene
>>> Scene(dimensionality=3, engine='PyVistaEngine')
>>> └── plane_01 (Plane - Mesh: 121 points, 100 cells)
>>> └── sphere_02 (Sphere - Mesh: 842 points, 870 cells)
scene.show()
```
An object (as well as the Scene) is just a node in a tree provided with optional mesh (under the hood created/stored/edited as a [`pyvista.PolyData`](https://docs.pyvista.org/api/core/_autosummary/pyvista.PolyData.html#pyvista-polydata) or [`pyvista.MultiBlock`](https://docs.pyvista.org/api/core/_autosummary/pyvista.MultiBlock.html#pyvista-multiblock) objects) and material and/or light, camera, agents special objects.
The following objects creation helpers are currently provided:
- `Object3D` any object with a mesh and/or material
- `Plane`
- `Sphere`
- `Capsule`
- `Cylinder`
- `Box`
- `Cone`
- `Line`
- `MultipleLines`
- `Tube`
- `Polygon`
- `Ring`
- `Text3D`
- `Triangle`
- `Rectangle`
- `Circle`
- `StructuredGrid`
- ... (see the doc)
Many of these objects can be visualized by running the following [example](https://github.com/huggingface/simulate/tree/main/examples/objects.py):
```
python examples/basic/objects.py
```
<p align="center">
<br>
<img src="https://user-images.githubusercontent.com/10695622/191562825-49d4c692-a1ed-44e9-bdb9-da5f0bfb9828.png" width="400"/>
<br>
<p>
### Objects are organized in a tree structure
Adding/removing objects:
- Using the addition (`+`) operator (or alternatively the method `.add(object)`) will add an object as a child of a previous object.
- Objects can be removed with the subtraction (`-`) operator or the `.remove(object)` command.
- Several objects can be added at once by adding a list/tuple to the scene.
- The whole scene can be cleared with `.clear()`.
- To add a nested object, just add it to the object under which it should be nested, e.g. `scene.sphere += sphere_child`.
Accessing objects:
- Objects can be directly accessed as attributes of their parents using their names (given with `name` attribute at creation or automatically generated from the class name + creation counter).
- Objects can also be accessed from their names with `.get_node(name)`.
- The names of the object are enforced to be unique (on save/show).
- Various `tree_*` attributes are available on any node to quickly navegate or list part of the tree of nodes.
Here are a couple of examples of manipulations:
```
# Add two copy of the sphere to the scene as children of the root node (using list will add all objects on the same level)
# Using `.copy()` will create a copy of an object (the copy doesn't have any parent or children)
scene += [scene.plane_01.sphere_02.copy(), scene.plane_01.sphere_02.copy()]
>>> scene
>>> Scene(dimensionality=3, engine='pyvista')
>>> ├── plane_01 (Plane - Mesh: 121 points, 100 cells)
>>> │ └── sphere_02 (Sphere - Mesh: 842 points, 870 cells)
>>> ├── sphere_03 (Sphere - Mesh: 842 points, 870 cells)
>>> └── sphere_04 (Sphere - Mesh: 842 points, 870 cells)
# Remove the last added sphere
>>> scene.remove(scene.sphere_04)
>>> Scene(dimensionality=3, engine='pyvista')
>>> ├── plane_01 (Plane - Mesh: 121 points, 100 cells)
>>> │ └── sphere_02 (Sphere - Mesh: 842 points, 870 cells)
>>> └── sphere_03 (Sphere - Mesh: 842 points, 870 cells)
```
### Editing and moving objects
Objects can be easily translated, rotated, scaled
Here are a couple of examples:
```
# Let's translate our floor (with the first sphere, it's child)
scene.plane_01.translate_x(1)
# Let's scale the second sphere uniformly
scene.sphere_03.scale(0.1)
# Inspect the current position and scaling values
print(scene.plane_01.position)
>>> array([1., 0., 0.])
print(scene.sphere_03.scaling)
>>> array([0.1, 0.1, 0.1])
# We can also translate from a vector and rotate from a quaternion or along the various axis
```
Editing objects:
- mesh of the object can be edited with all the manipulation operator provided by [pyvista](https://docs.pyvista.org/user-guide/index.html)
## Visualization engine
A default visualization engine is provided with the vtk backend of [`pyvista`](https://docs.pyvista.org/user-guide/index.html).
Starting the visualization engine can be done simply with `.show()`.
```
scene.show()
```
You can find bridges to other rendering/simulation engines in the `integrations` directory.
## Tips
If you are running on GCP, remember not to install `pyvistaqt`, and if you did so, uninstall it in your environment, since QT doesn't work well on GCP.
## Citation
```bibtex
@misc{simulate,
author = {Thomas Wolf, Edward Beeching, Carl Cochet, Dylan Ebert, Alicia Machado, Nathan Lambert, Clément Romac},
title = {Simulate},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/simulate}}
}
```
| huggingface/simulate/blob/main/README.md |
--
title: "Perceiver IO: a scalable, fully-attentional model that works on any modality"
thumbnail: /blog/assets/41_perceiver/thumbnail.png
authors:
- user: nielsr
---
# Perceiver IO: a scalable, fully-attentional model that works on any modality
### TLDR
We've added [Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver) to Transformers, the first Transformer-based neural network that works on all kinds of modalities (text, images, audio, video, point clouds,...) and combinations thereof. Take a look at the following Spaces to view some examples:
- predicting [optical flow](https://huggingface.co/spaces/nielsr/perceiver-optical-flow) between images
- [classifying images](https://huggingface.co/spaces/nielsr/perceiver-image-classification).
We also provide [several notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
Below, you can find a technical explanation of the model.
### Introduction
The [Transformer](https://arxiv.org/abs/1706.03762), originally introduced by
Vaswani et al. in 2017, caused a revolution in the AI community, initially improving
state-of-the-art (SOTA) results in machine translation. In 2018, [BERT](https://arxiv.org/abs/1810.04805)
was released, a Transformer encoder-only model that crushed the benchmarks of natural language
processing (NLP), most famously the [GLUE benchmark](https://gluebenchmark.com/).
Not long after that, AI researchers started to apply the idea of BERT to other domains. To name a few examples:
* [Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2) by Facebook AI illustrated that the architecture could be extended to audio
* the [Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit) by Google AI showed that the architecture works really well for vision
* most recently the [Video Vision transformer (ViViT)](https://arxiv.org/abs/2103.15691), also by Google AI, applied the architecture to video.
In all of these domains, state-of-the-art results were improved dramatically, thanks to the combination of this powerful architecture with large-scale pre-training.
However, there's an important limitation to the architecture of the Transformer: due to its [self-attention mechanism](https://jalammar.github.io/illustrated-transformer/), it scales [very poorly](https://arxiv.org/abs/2009.06732v2) in both compute and memory. In every layer, all inputs are used to produce queries and keys, for which a pairwise dot product is computed. Hence, it is not possible to apply self-attention on high-dimensional data without some form of preprocessing. Wav2Vec2, for example, solves this by employing a feature encoder to turn a raw waveform into a sequence of time-based features. The Vision Transformer (ViT) divides an image into a sequence of non-overlapping patches, which serve as "tokens". The Video Vision Transformer (ViViT) extracts non-overlapping, spatio-temporal
“tubes” from a video, which serve as "tokens". To make the Transformer work on a particular modality, one typically discretizes it to a sequence of tokens to make it work.
## The Perceiver
The [Perceiver](https://arxiv.org/abs/2103.03206) aims to solve this limitation by employing the self-attention mechanism on a set of latent variables, rather than on the inputs. The `inputs` (which could be text, image, audio, video) are only used for doing cross-attention with the latents. This has the advantage that the bulk of compute happens in a latent space, where compute is cheap (one typically uses 256 or 512 latents). The resulting architecture has no quadratic dependence on the input size: the Transformer encoder only depends linearly on the input size, while latent attention is independent of it. In a follow-up paper, called [Perceiver IO](https://arxiv.org/abs/2107.14795), the authors extend this idea to let the Perceiver also handle arbitrary outputs. The idea is similar: one only uses the outputs for doing cross-attention with the latents. Note that I'll use the terms "Perceiver" and "Perceiver IO" interchangeably to refer to the Perceiver IO model throughout this blog post.
In the following section, we look in a bit more detail at how Perceiver IO actually works by going over its implementation in [HuggingFace Transformers](https://github.com/huggingface/transformers), a popular library that initially implemented Transformer-based models for NLP, but is now starting to implement them for other domains as well. In the sections below, we explain in detail - in terms of shapes of tensors - how the Perceiver actually pre and post processes modalities of any kind.
All Perceiver variants in HuggingFace Transformers are based on the `PerceiverModel` class. To initialize a `PerceiverModel`, one can provide 3 additional instances to the model:
- a preprocessor
- a decoder
- a postprocessor.
Note that each of these are optional. A `preprocessor` is only required in case one hasn't already embedded the `inputs` (such as text, image, audio, video) themselves. A `decoder` is only required in case one wants to decode the output of the Perceiver encoder (i.e. the last hidden states of the latents) into something more useful, such as classification logits or optical flow. A `postprocessor` is only required in case one wants to turn the output of the decoder into a specific feature (this is only required when doing auto-encoding, as we will see further). An overview of the architecture is depicted below.
<img src="assets/41_perceiver/perceiver_architecture.png" width="800">
<small>The Perceiver architecture.</small>
In other words, the `inputs` (which could be any modality, or a combination thereof) are first optionally preprocessed using a `preprocessor`. Next, the preprocessed inputs perform a cross-attention operation with the latent variables of the Perceiver encoder. In this operation, the latent variables produce queries (Q), while the preprocessed inputs produce keys and values (KV). After this operation, the Perceiver encoder employs a (repeatable) block of self-attention layers to update the embeddings of the latents. The encoder will finally produce a tensor of shape (batch_size, num_latents, d_latents), containing the last hidden states of the latents. Next, there's an optional `decoder`, which can be used to decode the final hidden states of the latents into something more useful, such as classification logits. This is done by performing a cross-attention operation, in which trainable embeddings are used to produce queries (Q), while the latents are used to produce keys and values (KV). Finally, there's an optional `postprocessor`, which can be used to postprocess the decoder outputs to specific features.
Let's start off by showing how the Perceiver is implemented to work on text.
## Perceiver for text
Suppose that one wants to apply the Perceiver to perform text classification. As the memory and time requirements of the Perceiver's self-attention mechanism don't depend on the size of the inputs, one can directly provide raw UTF-8 bytes to the model. This is beneficial, as familar Transformer-based models (like [BERT](https://arxiv.org/abs/1810.04805) and [RoBERTa](https://arxiv.org/abs/1907.11692)) all employ some form of explicit tokenization, such as [WordPiece](https://research.google/pubs/pub37842/), [BPE](https://arxiv.org/abs/1508.07909) or [SentencePiece](https://arxiv.org/abs/1808.06226), which [may be harmful](https://arxiv.org/abs/2004.03720). For a fair comparison to BERT (which uses a sequence length of 512 subword tokens), the authors used input sequences of 2048 bytes. Let's say one also adds a batch dimension, then the `inputs` to the model are of shape (batch_size, 2048). The `inputs` contain the byte IDs (similar to the `input_ids` of BERT) for a single piece of text. One can use `PerceiverTokenizer` to turn a text into a sequence of byte IDs, padded up to a length of 2048:
``` python
from transformers import PerceiverTokenizer
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
text = "hello world"
inputs = tokenizer(text, padding="max_length", return_tensors="pt").input_ids
```
In this case, one provides `PerceiverTextPreprocessor` as preprocessor to the model, which will take care of embedding the `inputs` (i.e. turn each byte ID into a corresponding vector), as well as adding absolute position embeddings. As decoder, one provides `PerceiverClassificationDecoder` to the model (which will turn the last hidden states of the latents into classification logits). No postprocessor is required. In other words, a Perceiver model for text classification (which is called `PerceiverForSequenceClassification` in HuggingFace Transformers) is implemented as follows:
``` python
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverTextPreprocessor, PerceiverClassificationDecoder
class PerceiverForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverTextPreprocessor(config),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)
```
One can already see here that the decoder is initialized with trainable position encoding arguments. Why is that? Well, let's take a look in detail at how Perceiver IO works. At initialization, `PerceiverModel` internally defines a set of latent variables, as follows:
``` python
from torch import nn
self.latents = nn.Parameter(torch.randn(config.num_latents, config.d_latents))
```
In the Perceiver IO paper, one uses 256 latents, and sets the dimensionality of the latents to 1280. If one also adds a batch dimension, the Perceiver has latents of shape (batch_size, 256, 1280). First, the preprocessor (which one provides at initialization) will take care of embedding the UTF-8 byte IDs to embedding vectors. Hence, `PerceiverTextPreprocessor` will turn the `inputs` of shape (batch_size, 2048) to a tensor of shape (batch_size, 2048, 768) - assuming that each byte ID is turned into a vector of size 768 (this is determined by the `d_model` attribute of `PerceiverConfig`).
After this, Perceiver IO applies cross-attention between the latents (which produce queries) of shape (batch_size, 256, 1280) and the preprocessed inputs (which produce keys and values) of shape (batch_size, 2048, 768). The output of this initial cross-attention operation is a tensor that has the same shape as the queries (which are the latents, in this case). In other words, the output of the cross-attention operation is of shape (batch_size, 256, 1280).
Next, a (repeatable) block of self-attention layers is applied to update the representations of the latents. Note that these don't depend on the length of the inputs (i.e. the bytes) one provided, as these were only used during the cross-attention operation. In the Perceiver IO paper, a single block of 26 self-attention layers (each of which has 8 attention heads) were used to update the representations of the latents of the text model. Note that the output after these 26 self-attention layers still has the same shape as what one initially provided as input to the encoder: (batch_size, 256, 1280). These are also called the "last hidden states" of the latents. This is very similar to the "last hidden states" of the tokens one provides to BERT.
Ok, so now one has final hidden states of shape (batch_size, 256, 1280). Great, but one actually wants to turn these into classification logits of shape (batch_size, num_labels). How can we make the Perceiver output these?
This is handled by `PerceiverClassificationDecoder`. The idea is very similar to what was done when mapping the inputs to the latent space: one uses cross-attention. But now, the latent variables will produce keys and values, and one provides a tensor of whatever shape we'd like - in this case we'll provide a tensor of shape (batch_size, 1, num_labels) which will act as queries (the authors refer to these as "decoder queries", because they are used in the decoder). This tensor will be randomly initialized at the beginning of training, and trained end-to-end. As one can see, one just provides a dummy sequence length dimension of 1. Note that the output of a QKV attention layer always has the same shape as the shape of the queries - hence the decoder will output a tensor of shape (batch_size, 1, num_labels). The decoder then simply squeezes this tensor to have shape (batch_size, num_labels) and boom, one has classification logits<sup id="a1">[1](#f1)</sup>.
Great, isn't it? The Perceiver authors also show that it is straightforward to pre-train the Perceiver for masked language modeling, similar to BERT. This model is also available in HuggingFace Transformers, and called `PerceiverForMaskedLM`. The only difference with `PerceiverForSequenceClassification` is that it doesn't use `PerceiverClassificationDecoder` as decoder, but rather `PerceiverBasicDecoder`, to decode the latents to a tensor of shape (batch_size, 2048, 1280). After this, a language modeling head is added, which turns it into a tensor of shape (batch_size, 2048, vocab_size). The vocabulary size of the Perceiver is only 262, namely the 256 UTF-8 byte IDs, as well as 6 special tokens. By pre-training the Perceiver on English Wikipedia and [C4](https://arxiv.org/abs/1910.10683), the authors show that it is possible to achieve an overall score of 81.8 on GLUE after fine-tuning.
## Perceiver for images
Now that we've seen how to apply the Perceiver to perform text classification, it is straightforward to apply the Perceiver to do image classification. The only difference is that we'll provide a different `preprocessor` to the model, which will embed the image `inputs`. The Perceiver authors actually tried out 3 different ways of preprocessing:
- flattening the pixel values, applying a convolutional layer with kernel size 1 and adding learned absolute 1D position embeddings.
- flattening the pixel values and adding fixed 2D Fourier position embeddings.
- applying a 2D convolutional + maxpool layer and adding fixed 2D Fourier position embeddings.
Each of these are implemented in the Transformers library, and called `PerceiverForImageClassificationLearned`, `PerceiverForImageClassificationFourier` and `PerceiverForImageClassificationConvProcessing` respectively. They only differ in their configuration of `PerceiverImagePreprocessor`. Let's take a closer look at `PerceiverForImageClassificationLearned`. It initializes a `PerceiverModel` as follows:
``` python
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverClassificationDecoder
class PerceiverForImageClassificationLearned(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverImagePreprocessor(
config,
prep_type="conv1x1",
spatial_downsample=1,
out_channels=256,
position_encoding_type="trainable",
concat_or_add_pos="concat",
project_pos_dim=256,
trainable_position_encoding_kwargs=dict(num_channels=256, index_dims=config.image_size ** 2),
),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)
```
One can see that `PerceiverImagePreprocessor` is initialized with `prep_type = "conv1x1"` and that one adds arguments for the trainable position encodings. So how does this preprocessor work in detail? Suppose that one provides a batch of images to the model. Let's say one applies center cropping to a resolution of 224 and normalization of the color channels first, such that the `inputs` are of shape (batch_size, num_channels, height, width) = (batch_size, 3, 224, 224). One can use `PerceiverImageProcessor` for this, as follows:
``` python
from transformers import PerceiverImageProcessor
import requests
from PIL import Image
processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(image, return_tensors="pt").pixel_values
```
`PerceiverImagePreprocessor` (with the settings defined above) will first apply a convolutional layer with kernel size (1, 1) to turn the `inputs` into a tensor of shape (batch_size, 256, 224, 224) - hence increasing the channel dimension. It will then place the channel dimension last - so now one has a tensor of shape (batch_size, 224, 224, 256). Next, it flattens the spatial (height + width) dimensions such that one has a tensor of shape (batch_size, 50176, 256). Next, it concatenates it with trainable 1D position embeddings. As the dimensionality of the position embeddings is defined to be 256 (see the `num_channels` argument above), one is left with a tensor of shape (batch_size, 50176, 512). This tensor will be used for the cross-attention operation with the latents.
The authors use 512 latents for all image models, and set the dimensionality of the latents to 1024. Hence, the latents are a tensor of shape (batch_size, 512, 1024) - assuming we add a batch dimension. The cross-attention layer takes the queries of shape (batch_size, 512, 1024) and keys + values of shape (batch_size, 50176, 512) as input, and produces a tensor that has the same shape as the queries, so outputs a new tensor of shape (batch_size, 512, 1024). Next, a block of 6 self-attention layers is applied repeatedly (8 times), to produce final hidden states of the latents of shape (batch_size, 512, 1024). To turn these into classification logits, `PerceiverClassificationDecoder` is used, which works similarly to the one for text classification: it uses the latents as keys + values, and uses trainable position embeddings of shape (batch_size, 1, num_labels) as queries. The output of the cross-attention operation is a tensor of shape (batch_size, 1, num_labels), which is squeezed to have classification logits of shape (batch_size, num_labels).
The Perceiver authors show that the model is capable of achieving strong results compared to models designed primarily for image classification (such as [ResNet](https://arxiv.org/abs/1512.03385) or [ViT](https://arxiv.org/abs/2010.11929)). After large-scale pre-training on [JFT](https://paperswithcode.com/dataset/jft-300m), the model that uses conv+maxpool preprocessing (`PerceiverForImageClassificationConvProcessing`) achieves 84.5 top-1 accuracy on ImageNet. Remarkably, `PerceiverForImageClassificationLearned`, the model that only employs a 1D fully learned position encoding, achieves a top-1 accuracy of 72.7 despite having no privileged information about the 2D structure of images.
## Perceiver for optical flow
The authors show that it's straightforward to make the Perceiver also work on optical flow, which is a decades-old problem in computer vision, with many broader applications. For an introduction to optical flow, I refer to [this blog post](https://medium.com/swlh/what-is-optical-flow-and-why-does-it-matter-in-deep-learning-b3278bb205b5). Given two images of the same scene (e.g. two consecutive frames of a video), the task is to estimate the 2D displacement for each pixel in the first image. Existing algorithms are quite hand-engineered and complex, however with the Perceiver, this becomes relatively simple. The model is implemented in the Transformers library, and available as `PerceiverForOpticalFlow`. It is implemented as follows:
``` python
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverOpticalFlowDecoder
class PerceiverForOpticalFlow(nn.Module):
def __init__(self, config):
super().__init__(config)
fourier_position_encoding_kwargs_preprocessor = dict(
num_bands=64,
max_resolution=config.train_size,
sine_only=False,
concat_pos=True,
)
fourier_position_encoding_kwargs_decoder = dict(
concat_pos=True, max_resolution=config.train_size, num_bands=64, sine_only=False
)
image_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="patches",
spatial_downsample=1,
conv_after_patching=True,
conv_after_patching_in_channels=54,
temporal_downsample=2,
position_encoding_type="fourier",
# position_encoding_kwargs
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_preprocessor,
)
self.perceiver = PerceiverModel(
config,
input_preprocessor=image_preprocessor,
decoder=PerceiverOpticalFlowDecoder(
config,
num_channels=image_preprocessor.num_channels,
output_image_shape=config.train_size,
rescale_factor=100.0,
use_query_residual=False,
output_num_channels=2,
position_encoding_type="fourier",
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_decoder,
),
)
```
As one can see, `PerceiverImagePreprocessor` is used as preprocessor (i.e. to prepare the 2 images for the cross-attention operation with the latents) and `PerceiverOpticalFlowDecoder` is used as decoder (i.e. to decode the final hidden states of the latents to an actual predicted flow). For each of the 2 frames, the authors extract a 3 x 3 patch around each pixel, leading to 3 x 3 x 3 = 27 values for each pixel (as each pixel also has 3 color channels). The authors use a training resolution of (368, 496). If one stacks 2 frames of size (368, 496) of each training example on top of each other, the `inputs` to the model are of shape (batch_size, 2, 27, 368, 496).
The preprocessor (with the settings defined above) will first concatenate the frames along the channel dimension, leading to a tensor of shape (batch_size, 368, 496, 54) - assuming one also moves the channel dimension to be last. The authors explain in their paper (page 8) why concatenation along the channel dimension makes sense. Next, the spatial dimensions are flattened, leading to a tensor of shape (batch_size, 368*496, 54) = (batch_size, 182528, 54). Then, position embeddings (each of which have dimensionality 258) are concatenated, leading to a final preprocessed input of shape (batch_size, 182528, 322). These will be used to perform cross-attention with the latents.
The authors use 2048 latents for the optical flow model (yes, 2048!), with a dimensionality of 512 for each latent. Hence, the latents have shape (batch_size, 2048, 512). After the cross-attention, one again has a tensor of the same shape (as the latents act as queries). Next, a single block of 24 self-attention layers (each of which has 16 attention heads) are applied to update the embeddings of the latents.
To decode the final hidden states of the latents to an actual predicted flow, `PerceiverOpticalFlowDecoder` simply uses the preprocessed inputs of shape (batch_size, 182528, 322) as queries for the cross-attention operation. Next, these are projected to a tensor of shape (batch_size, 182528, 2). Finally, one rescales and reshapes this back to the original image size to get a predicted flow of shape (batch_size, 368, 496, 2). The authors claim state-of-the-art results on important benchmarks including [Sintel](https://link.springer.com/chapter/10.1007/978-3-642-33783-3_44) and [KITTI](http://www.cvlibs.net/publications/Menze2015CVPR.pdf) when training on [AutoFlow](https://arxiv.org/abs/2104.14544), a large synthetic dataset of 400,000 annotated image pairs.
The video below shows the predicted flow on 2 examples.
<p float="left">
<img src="https://lh3.googleusercontent.com/Rkhzc3Ckl4oWrOjxviohVmK4ZYGvGGrxaXCaOgBl3YGdBuHeFcQG_0-QjenoHKlTsHR6_6LpmCYu2bghEEzWdpYYp6QksFi0nkI3RNkdJEP-6c13bg=w2048-rw-v1" width="300" style="display:inline" />
<img src="https://lh3.googleusercontent.com/p51q5x-JYJKltxxUtp60lUViVguTnxBpw7dQFfs47FTWpaj3iTmz2RJCGuiIEEpIoJKhZBU19W_k85lJ-8AtywD9YiVXc5KbiubvZakz2qFrNMj-cA=w2048-rw-v1" width="300" style="display:inline" />
<img src="assets/41_perceiver/flow_legend.jpeg" width="300" />
</p>
<small> Optical flow estimation by Perceiver IO. The colour of each pixel shows the direction and speed of motion estimated by the model, as indicated by the legend on the right.</small>
## Perceiver for multimodal autoencoding
The authors also use the Perceiver for multimodal autoencoding. The goal of multimodal autoencoding is to learn a model that can accurately reconstruct multimodal inputs in the presence of a bottleneck induced by an architecture. The authors train the model on the [Kinetics-700 dataset](https://deepmind.com/research/open-source/kinetics), in which each example consists of a sequence of images (i.e. frames), audio and a class label (one of 700 possible labels). This model is also implemented in HuggingFace Transformers, and available as `PerceiverForMultimodalAutoencoding`. For brevity, I will omit the code of defining this model, but important to note is that it uses `PerceiverMultimodalPreprocessor` to prepare the `inputs` for the model. This preprocessor will first use the respective preprocessor for each modality (image, audio, label) separately. Suppose one has a video of 16 frames of resolution 224x224 and 30,720 audio samples, then the modalities are preprocessed as follows:
- The images - actually a sequence of frames - of shape (batch_size, 16, 3, 224, 224) are turned into a tensor of shape (batch_size, 50176, 243) using `PerceiverImagePreprocessor`. This is a “space to depth” transformation, after which fixed 2D Fourier position embeddings are concatenated.
- The audio has shape (batch_size, 30720, 1) and is turned into a tensor of shape (batch_size, 1920, 401) using `PerceiverAudioPreprocessor` (which concatenates fixed Fourier position embeddings to the raw audio).
- The class label of shape (batch_size, 700) is turned into a tensor of shape (batch_size, 1, 700) using `PerceiverOneHotPreprocessor`. In other words, this preprocessor just adds a dummy time (index) dimension. Note that one initializes the class label with a tensor of zeros during evaluation, so as to let the model act as a video classifier.
Next, `PerceiverMultimodalPreprocessor` will pad the preprocessed modalities with modality-specific trainable embeddings to make concatenation along the time dimension possible. In this case, the modality with the highest channel dimension is the class label (it has 700 channels). The authors enforce a minimum padding size of 4, hence each modality will be padded to have 704 channels. They can then be concatenated, hence the final preprocessed input is a tensor of shape (batch_size, 50176 + 1920 + 1, 704) = (batch_size, 52097, 704).
The authors use 784 latents, with a dimensionality of 512 for each latent. Hence, the latents have shape (batch_size, 784, 512). After the cross-attention, one again has a tensor of the same shape (as the latents act as queries). Next, a single block of 8 self-attention layers (each of which has 8 attention heads) is applied to update the embeddings of the latents.
Next, there is `PerceiverMultimodalDecoder`, which will first create output queries for each modality separately. However, as it is not possible to decode an entire video in a single forward pass, the authors instead auto-encode in chunks. Each chunk will subsample certain index dimensions for every modality. Let's say we process the video in 128 chunks, then the decoder queries will be produced as follows:
- For the image modality, the total size of the decoder query is 16x3x224x224 = 802,816. However, when auto-encoding the first chunk, one subsamples the first 802,816/128 = 6272 values. The shape of the image output query is (batch_size, 6272, 195) - the 195 comes from the fact that fixed Fourier position embeddings are used.
- For the audio modality, the total input has 30,720 values. However, one only subsamples the first 30720/128/16 = 15 values. Hence, the shape of the audio query is (batch_size, 15, 385). Here, the 385 comes from the fact that fixed Fourier position embeddings are used.
- For the class label modality, there's no need to subsample. Hence, the subsampled index is set to 1. The shape of the label output query is (batch_size, 1, 1024). One uses trainable position embeddings (of size 1024) for the queries.
Similarly to the preprocessor, `PerceiverMultimodalDecoder` pads the different modalities to the same number of channels, to make concatenation of the modality-specific queries possible along the time dimension. Here, the class label has again the highest number of channels (1024), and the authors enforce a minimum padding size of 2, hence every modality will be padded to have 1026 channels. After concatenation, the final decoder query has shape (batch_size, 6272 + 15 + 1, 1026) = (batch_size, 6288, 1026). This tensor produces queries in the cross-attention operation, while the latents act as keys and values. Hence, the output of the cross-attention operation is a tensor of shape (batch_size, 6288, 1026). Next, `PerceiverMultimodalDecoder` employs a linear layer to reduce the output channels to get a tensor of shape (batch_size, 6288, 512).
Finally, there is `PerceiverMultimodalPostprocessor`. This class postprocesses the output of the decoder to produce an actual reconstruction of each modality. It first splits up the time dimension of the decoder output according to the different modalities: (batch_size, 6272, 512) for image, (batch_size, 15, 512) for audio and (batch_size, 1, 512) for the class label. Next, the respective postprocessors for each modality are applied:
- The image post processor (which is called `PerceiverProjectionPostprocessor` in Transformers) simply turns the (batch_size, 6272, 512) tensor into a tensor of shape (batch_size, 6272, 3) - i.e. it projects the final dimension to RGB values.
- `PerceiverAudioPostprocessor` turns the (batch_size, 15, 512) tensor into a tensor of shape (batch_size, 240).
- `PerceiverClassificationPostprocessor` simply takes the first (and only index), to get a tensor of shape (batch_size, 700).
So now one ends up with tensors containing the reconstruction of the image, audio and class label modalities respectively. As one auto-encodes an entire video in chunks, one needs to concatenate the reconstruction of each chunk to have a final reconstruction of an entire video. The figure below shows an example:
<p float="left">
<img src="assets/41_perceiver/original_video.gif" width="200" style="display:inline">
<img src="assets/41_perceiver/reconstructed_video.gif" width="200" style="display:inline">
<img src="assets/41_perceiver/perceiver_audio_autoencoding.png" width="400">
</p>
<small>Above: original video (left), reconstruction of the first 16 frames (right). Video taken from the [UCF101 dataset](https://www.crcv.ucf.edu/data/UCF101.php). Below: reconstructed audio (taken from the paper). </small>
<img src="assets/41_perceiver/predicted_labels.png" width="500">
<small>Top 5 predicted labels for the video above. By masking the class label, the Perceiver becomes a video classifier. </small>
With this approach, the model learns a joint distribution across 3 modalities. The authors do note that because the latent variables are shared across modalities and not explicitly allocated between them, the quality of reconstructions for each modality is sensitive to the weight of its loss term and other training hyperparameters. By putting stronger emphasis on classification accuracy, they are able to reach 45% top-1 accuracy while maintaining 20.7 PSNR (peak signal-to-noise ratio) for video.
## Other applications of the Perceiver
Note that there are no limits on the applications of the Perceiver! In the original [Perceiver paper](https://arxiv.org/abs/2103.03206), the authors showed that the architecture can be used to process 3D point clouds – a common concern for self-driving cars equipped with Lidar sensors. They trained the model on [ModelNet40](https://modelnet.cs.princeton.edu/), a dataset of point clouds derived from 3D triangular meshes spanning 40 object categories. The model was shown to achieve a top-1 accuracy of 85.7 % on the test set, competing with [PointNet++](https://arxiv.org/abs/1706.02413), a highly specialized model that uses extra geometric features and performs more advanced augmentations.
The authors also used the Perceiver to replace the original Transformer in [AlphaStar](https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii), the state-of-the-art reinforcement learning system for the complex game of [StarCraft II](https://starcraft2.com/en-us/). Without tuning any additional parameters, the authors observed that the resulting agent reached the same level of performance as the original AlphaStar agent, reaching an 87% win-rate versus the Elite bot after [behavioral cloning](https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf) on human data.
It is important to note that the models currently implemented (such as `PerceiverForImageClassificationLearned`, `PerceiverForOpticalFlow`) are just examples of what you can do with the Perceiver. Each of these are different instances of `PerceiverModel`, just with a different preprocessor and/or decoder (and optionally, a postprocessor as is the case for multimodal autoencoding). People can come up with new preprocessors, decoders and postprocessors to make the model solve different problems. For instance, one could extend the Perceiver to perform named-entity recognition (NER) or question-answering similar to BERT, audio classification similar to Wav2Vec2 or object detection similar to DETR.
## Conclusion
In this blog post, we went over the architecture of Perceiver IO, an extension of the Perceiver by Google Deepmind, and showed its generality of handling all kinds of modalities. The big advantage of the Perceiver is that the compute and memory requirements of the self-attention mechanism don't depend on the size of the inputs and outputs, as the bulk of compute happens in a latent space (a not-too large set of vectors). Despite its task-agnostic architecture, the model is capabable of achieving great results on modalities such as language, vision, multimodal data, and point clouds. In the future, it might be interesting to train a single (shared) Perceiver encoder on several modalities at the same time, and use modality-specific preprocessors and postprocessors. As [Karpathy puts it](https://twitter.com/karpathy/status/1424469507658031109), it may well be that this architecture can unify all modalities into a shared space, with a library of encoders/decoders.
Speaking of a library, the model is available in [HuggingFace Transformers](https://github.com/huggingface/transformers) as of today. It will be exciting to see what people build with it, as its applications seem endless!
### Appendix
The implementation in HuggingFace Transformers is based on the original JAX/Haiku implementation which can be found [here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
The documentation of the Perceiver IO model in HuggingFace Transformers is available [here](https://huggingface.co/docs/transformers/model_doc/perceiver).
Tutorial notebooks regarding the Perceiver on several modalities can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
## Footnotes
<b id="f1">1</b> Note that in the official paper, the authors used a two-layer MLP to generate the output logits, which was omitted here for brevity. [↩](#a1)
| huggingface/blog/blob/main/perceiver.md |
--
title: "Train a Sentence Embedding Model with 1B Training Pairs"
authors:
- user: asi
guest: true
---
# Train a Sentence Embedding Model with 1 Billion Training Pairs
**Sentence embedding** is a method that maps sentences to vectors of real numbers. Ideally, these vectors would capture the semantic of a sentence and be highly generic. Such representations could then be used for many downstream applications such as clustering, text mining, or question answering.
We developed state-of-the-art sentence embedding models as part of the project ["Train the Best Sentence Embedding Model Ever with 1B Training Pairs"](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). This project took place during the [Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by Hugging Face. We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as guidance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks!
## Training methodology
### Model
Unlike words, we can not define a finite set of sentences. Sentence embedding methods, therefore, compose inner words to compute the final representation. For example, SentenceBert model ([Reimers and Gurevych, 2019](https://aclanthology.org/D19-1410.pdf)) uses Transformer, the cornerstone of many NLP applications, followed by a pooling operation over the contextualized word vectors. (c.f. Figure below.)

### Multiple Negative Ranking Loss
The parameters from the composition module are usually learned using a self-supervised objective. For the project, we used a contrastive training method illustrated in the figure below. We constitute a dataset with sentence pairs \\( (a_i, p_i) \\) such that sentences from the pair have a close meaning. For example, we consider pairs such as (query, answer-passage), (question, duplicate_question),(paper title, cited paper title). Our model is then trained to map pairs \\( (a_i , p_i) \\) to close vectors while assigning unmatched pairs \\( (a_i , p_j), i \neq j \\) to distant vectors in the embedding space. This training method is also called training with in-batch negatives, InfoNCE or NTXentLoss.

Formally, given a batch of training samples, the model optimises the following [loss function](https://github.com/UKPLab/sentence-transformers/blob/master/sentence_transformers/losses/MultipleNegativesRankingLoss.py):
$$-\frac{1}{n}\sum_{i=1}^n\frac{exp(sim(a_i, p_i))}{\sum_j exp(sim(a_i, p_j))}$$
An illustrative example can be seen below. The model first embeds each sentence from every pair in the batch. Then, we compute a similarity matrix between every possible pair \\( (a_i, p_j) \\). We then compare the similarity matrix with the ground truth, which indicates the original pairs. Finally, we perform the comparison using the cross entropy loss.
Intuitively, the model should assign high similarity to the sentences « How many people live in Berlin? » and « Around 3.5 million people live in Berlin » and low similarity to other negative answers such as « The capital of France is Paris » as detailed in the Figure below.

In the loss equation, `sim` indicates a similarity function between \\( (a, p) \\). The similarity function could be either the Cosine-Similarity or the Dot-Product operator. Both methods have their pros and cons summarized below ([Thakur et al., 2021](https://arxiv.org/abs/2104.08663), [Bachrach et al., 2014](https://dl.acm.org/doi/10.1145/2645710.2645741)):
| Cosine-similarity | Dot-product |
|---------------------|-------------|
| Vector has highest similarity to itself since \\( cos(a, a)=1 \\). | Other vectors can have higher dot-products \\( dot(a, a) < dot (a, b) \\). |
| With normalised vectors it is equal to the dot product. The max vector length is equals 1. | It might be slower with certain approximate nearest neighbour methods since the max vector not known. |
| With normalised vectors, it is proportional to euclidian distance. It works with k-means clustering. | It does not work with k-means clustering. |
In practice, we used a scaled similarity because score differences tends to be too small and apply a scaling factor \\( C \\) such that \\( sim_{scaled}(a, b) = C * sim(a, b) \\) with typically \\( C = 20 \\) ([Henderson and al., 2020]([https://doi.org/10.18653/v1/2020.findings-emnlp.196), [Radford and al., 2021](http://proceedings.mlr.press/v139/radford21a.html)).
### Improving Quality with Better Batches
In our method, we build batches of sample pairs \\( (a_i , p_i) \\). We consider all other samples from the batch, \\( (a_i , p_j), i \neq j \\), as negatives sample pairs. The batch composition is therefore a key training aspect. Given the literature in the domain, we mainly focused on three main aspects of the batch.
#### 1. Size matters
In contrastive learning, a larger batch size is synonymous with better performance. As shown in the Figure extracted from Qu and al., ([2021](https://doi.org/10.18653/v1/2021.naacl-main.466)), a larger batch size increases the results.

#### 2. Hard Negatives
In the same figure, we observe that including hard negatives also improves performance. Hard negatives are sample \\( p_j \\) which are hard to distinguish from \\( p_i \\). In our example, it could be the pairs « What is the capital of France? » and « What is the capital of the US? » which have a close semantic content and requires precisely understanding the full sentence to be answered correctly. On the contrary, the samples « What is the capital of France? » and «How many Star Wars movies is there?» are less difficult to distinguish since they do not refer to the same topic.
#### 3. Cross dataset batches
We concatenated multiple datasets to train our models. We built a large batch and gathered samples from the same batch dataset to limit the topic distribution and favor hard negatives. However, we also mix at least two datasets in the batch to learn a global structure between topics and not only a local structure within a topic.
## Training infrastructure and data
As mentioned earlier, the quantity of data and the batch size directly impact the model performances. As part of the project, we benefited from efficient hardware infrastructure. We trained our models on [TPUs](https://cloud.google.com/tpu) which are compute units developed by Google and super efficient for matrix multiplications. TPUs have some [hardware specificities](https://huggingface.co/docs/accelerate/quicktour.html#training-on-tpu) which might require some specific code implementation.
Additionally, we trained models on a large corpus as we concatenated multiple datasets up to 1 billion sentence pairs! All datasets used are detailed for each model in the [model card](https://huggingface.co/flax-sentence-embeddings/all_datasets_v3_MiniLM-L12).
## Conclusion
You can find all models and datasets we created during the challenge in our [HuggingFace repository](https://huggingface.co/flax-sentence-embeddings). We trained 20 general-purpose Sentence Transformers models such as Mini-LM ([Wang and al., 2020](https://proceedings.neurips.cc/paper/2020/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html)), RoBERTa ([liu and al., 2019](https://arxiv.org/abs/1907.11692 )), DistilBERT ([Sanh and al., 2020](http://arxiv.org/abs/1910.01108)) and MPNet ([Song and al., 2020](https://proceedings.neurips.cc/paper/2020/hash/c3a690be93aa602ee2dc0ccab5b7b67e-Abstract.html)). Our models achieve SOTA on multiple general-purpose Sentence Similarity evaluation tasks. We also shared [8 datasets](https://huggingface.co/flax-sentence-embeddings) specialized for Question Answering, Sentence-Similarity, and Gender Evaluation.
General sentence embeddings might be used for many applications. We built a [Spaces demo](https://huggingface.co/spaces/flax-sentence-embeddings/sentence-embeddings) to showcase several applications:
* The **sentence similarity** module compares the similarity of the main text with other texts of your choice. In the background, the demo extracts the embedding for each text and computes the similarity between the source sentence and the other using cosine similarity.
* **Asymmetric QA** compares the answer likeliness of a given query with answer candidates of your choice.
* **Search / Cluster** returns nearby answers from a query. For example, if you input « python », it will retrieve closest sentences using dot-product distance.
* **Gender Bias Evaluation** report *inherent gender bias* in training set via random sampling of the sentences. Given an anchor text without mentioning gender for target occupation and 2 propositions with gendered pronouns, we compare if models assign a higher similarity to a given proposition and therefore evaluate their proportion to favor a specific gender.
The [Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) has been an intense and highly rewarding experience! The quality of Google’s Flax, JAX, and Cloud and Hugging Face team members' guidance and their presence helped us all learn a lot. We hope all projects had as much fun as we did in ours. Whenever you have questions or suggestions, don’t hesitate to contact us!
| huggingface/blog/blob/main/1b-sentence-embeddings.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Funnel Transformer
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=funnel">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-funnel-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/funnel-transformer-small">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
(CNN) in computer vision.
The abstract from the paper is the following:
*With the success of language pretraining, it is highly desirable to develop more efficient architectures of good
scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the
much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only
require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which
gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More
importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further
improve the model capacity. In addition, to perform token-level predictions as required by common pretraining
objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence
via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on
a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading
comprehension.*
This model was contributed by [sgugger](https://huggingface.co/sgugger). The original code can be found [here](https://github.com/laiguokun/Funnel-Transformer).
## Usage tips
- Since Funnel Transformer uses pooling, the sequence length of the hidden states changes after each block of layers. This way, their length is divided by 2, which speeds up the computation of the next hidden states.
The base model therefore has a final sequence length that is a quarter of the original one. This model can be used
directly for tasks that just require a sentence summary (like sequence classification or multiple choice). For other
tasks, the full model is used; this full model has a decoder that upsamples the final hidden states to the same
sequence length as the input.
- For tasks such as classification, this is not a problem, but for tasks like masked language modeling or token classification, we need a hidden state with the same sequence length as the original input. In those cases, the final hidden states are upsampled to the input sequence length and go through two additional layers. That's why there are two versions of each checkpoint. The version suffixed with “-base” contains only the three blocks, while the version without that suffix contains the three blocks and the upsampling head with its additional layers.
- The Funnel Transformer checkpoints are all available with a full version and a base version. The first ones should be
used for [`FunnelModel`], [`FunnelForPreTraining`],
[`FunnelForMaskedLM`], [`FunnelForTokenClassification`] and
[`FunnelForQuestionAnswering`]. The second ones should be used for
[`FunnelBaseModel`], [`FunnelForSequenceClassification`] and
[`FunnelForMultipleChoice`].
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## FunnelConfig
[[autodoc]] FunnelConfig
## FunnelTokenizer
[[autodoc]] FunnelTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## FunnelTokenizerFast
[[autodoc]] FunnelTokenizerFast
## Funnel specific outputs
[[autodoc]] models.funnel.modeling_funnel.FunnelForPreTrainingOutput
[[autodoc]] models.funnel.modeling_tf_funnel.TFFunnelForPreTrainingOutput
<frameworkcontent>
<pt>
## FunnelBaseModel
[[autodoc]] FunnelBaseModel
- forward
## FunnelModel
[[autodoc]] FunnelModel
- forward
## FunnelModelForPreTraining
[[autodoc]] FunnelForPreTraining
- forward
## FunnelForMaskedLM
[[autodoc]] FunnelForMaskedLM
- forward
## FunnelForSequenceClassification
[[autodoc]] FunnelForSequenceClassification
- forward
## FunnelForMultipleChoice
[[autodoc]] FunnelForMultipleChoice
- forward
## FunnelForTokenClassification
[[autodoc]] FunnelForTokenClassification
- forward
## FunnelForQuestionAnswering
[[autodoc]] FunnelForQuestionAnswering
- forward
</pt>
<tf>
## TFFunnelBaseModel
[[autodoc]] TFFunnelBaseModel
- call
## TFFunnelModel
[[autodoc]] TFFunnelModel
- call
## TFFunnelModelForPreTraining
[[autodoc]] TFFunnelForPreTraining
- call
## TFFunnelForMaskedLM
[[autodoc]] TFFunnelForMaskedLM
- call
## TFFunnelForSequenceClassification
[[autodoc]] TFFunnelForSequenceClassification
- call
## TFFunnelForMultipleChoice
[[autodoc]] TFFunnelForMultipleChoice
- call
## TFFunnelForTokenClassification
[[autodoc]] TFFunnelForTokenClassification
- call
## TFFunnelForQuestionAnswering
[[autodoc]] TFFunnelForQuestionAnswering
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/funnel.md |
n this video, we're going to see how to load and fine-tune a pre-trained model. It's very quick, and if you've watched our pipeline videos, which I'll link below, the process is very similar. This time, though, we're going to be using transfer learning and doing some training ourselves, rather than just loading a model and using it as-is. To learn more about transfer learning, head to the 'What is transfer learning?' video, which we'll link below too! So now let's look at this code. To start, we pick which model we want to start with - in this case we're going to use the famous, the original BERT. But what does this monstrosity, 'TFAutoModelForSequenceClassification' mean? Well, the TF stands for TensorFlow, and the rest means "take a language model, and stick a sequence classification head onto it if it doesn't have one already". So what we're going to do here is load BERT, a general language model, and then do some transfer learning to use it on our task of interest. We load the language model with this one line of code here, using the "from_pretrained" method. That method needs to know two things: Firstly the name of the model you want it to load, and secondly how many classes your problem has. If you want to follow along with the data from our datasets videos, which I'll link below, then you'll have two classes, positive and negative, and thus num_labels equals two. What about this "compile" thing? If you're familiar with Keras, you've probably seen this already, but if not, this is one of its core methods - you always need to "compile" your model before you train it. Compile needs to know two things: Firstly, the loss function - what are we trying to optimize? Here, we import the sparse categorical crossentropy loss function - that's a mouthful, but it's the standard loss function for any neural network that's doing a classification task. It basically encourages the network to output large values for the right class, and low values for the wrong classes. Note that you can specify the loss function as a string, like we did with the optimizer, but there's a very common pitfall there - by default, this loss assumes the output is probabilities after a softmax layer, but what our model has actually output is the values before the softmax, often called the "logits" - you saw these before in the videos about pipelines. If you get this wrong, your model won't train and it'll be very annoying to figure out why. In fact, if you remember absolutely nothing else from this video, remember to always check whether your model is outputting logits or probabilities, and to make sure your loss is set up to match that. It'll save you a lot of debugging headaches in your career! The second thing compile needs to know is the optimizer you want. In our case, we use Adam, which is sort of the standard optimizer for deep learning these days. The one thing you might want to change is the learning rate, and to do that we'll need to import the actual optimizer rather than just calling it by string, but we'll talk about that in another video, which I'll link below. For now, let's just try training the model! So how do you train a model? Well, if you’ve used Keras before, this will all be very familiar to you - but if not, let's look at what we're doing here. Fit() is pretty much the central method for Keras models - it tells the model to break the data into batches and train on it. So the first input is tokenized text - you will almost always be getting this from a tokenizer, and if you want to learn more about that process, and what exactly the outputs look like, please check out our videos on tokenizers - there'll be links below for those too! So that's our inputs, and then the second input is our labels - this is just a one-dimensional Numpy or Tensorflow array of integers, corresponding to the classes for our examples, and that’s it. If you're following along with the data from our datasets video, there'll only be two classes, so this will just be zeroes and ones. Once we have our inputs and our labels, we do the same thing with the validation data, we pass the validation inputs and the validation labels in a tuple, then we can, if we want, specify details like the batch_size for training, and then you just pass it all to model.fit() and let it rip. If everything works out, you should see a little training progress bar as your loss goes down. And while that's running you call your boss and tell him you’re a senior NLP machine learning engineer now and you’re going to want a salary review next quarter. This is really all it takes to apply the power of a massive pretrained language model to your NLP problem. Could we do better, though? We certainly could, with a few more advanced Keras features like a tuned, scheduled learning rate we can get an even lower loss, and an even more accurate model. And what do we do with our model once it's trained? I'll cover this and more in the videos linked below! | huggingface/course/blob/main/subtitles/en/raw/chapter3/03c_keras-finetuning.md |
`@gradio/colorpicker`
```html
<script>
import { BaseColorPicker, BaseExample } from "@gradio/colorpicker";
</script>
```
BaseColorPicker
```javascript
export let value = "#000000";
export let value_is_output = false;
export let label: string;
export let info: string | undefined = undefined;
export let disabled = false;
export let show_label = true;
```
BaseExample
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
``` | gradio-app/gradio/blob/main/js/colorpicker/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Checks on a Pull Request
When you open a pull request on 🤗 Transformers, a fair number of checks will be run to make sure the patch you are adding is not breaking anything existing. Those checks are of four types:
- regular tests
- documentation build
- code and documentation style
- general repository consistency
In this document, we will take a stab at explaining what those various checks are and the reason behind them, as well as how to debug them locally if one of them fails on your PR.
Note that, ideally, they require you to have a dev install:
```bash
pip install transformers[dev]
```
or for an editable install:
```bash
pip install -e .[dev]
```
inside the Transformers repo. Since the number of optional dependencies of Transformers has grown a lot, it's possible you don't manage to get all of them. If the dev install fails, make sure to install the Deep Learning framework you are working with (PyTorch, TensorFlow and/or Flax) then do
```bash
pip install transformers[quality]
```
or for an editable install:
```bash
pip install -e .[quality]
```
## Tests
All the jobs that begin with `ci/circleci: run_tests_` run parts of the Transformers testing suite. Each of those jobs focuses on a part of the library in a certain environment: for instance `ci/circleci: run_tests_pipelines_tf` runs the pipelines test in an environment where TensorFlow only is installed.
Note that to avoid running tests when there is no real change in the modules they are testing, only part of the test suite is run each time: a utility is run to determine the differences in the library between before and after the PR (what GitHub shows you in the "Files changes" tab) and picks the tests impacted by that diff. That utility can be run locally with:
```bash
python utils/tests_fetcher.py
```
from the root of the Transformers repo. It will:
1. Check for each file in the diff if the changes are in the code or only in comments or docstrings. Only the files with real code changes are kept.
2. Build an internal map that gives for each file of the source code of the library all the files it recursively impacts. Module A is said to impact module B if module B imports module A. For the recursive impact, we need a chain of modules going from module A to module B in which each module imports the previous one.
3. Apply this map on the files gathered in step 1, which gives us the list of model files impacted by the PR.
4. Map each of those files to their corresponding test file(s) and get the list of tests to run.
When executing the script locally, you should get the results of step 1, 3 and 4 printed and thus know which tests are run. The script will also create a file named `test_list.txt` which contains the list of tests to run, and you can run them locally with the following command:
```bash
python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
```
Just in case anything slipped through the cracks, the full test suite is also run daily.
## Documentation build
The `build_pr_documentation` job builds and generates a preview of the documentation to make sure everything looks okay once your PR is merged. A bot will add a link to preview the documentation in your PR. Any changes you make to the PR are automatically updated in the preview. If the documentation fails to build, click on **Details** next to the failed job to see where things went wrong. Often, the error is as simple as a missing file in the `toctree`.
If you're interested in building or previewing the documentation locally, take a look at the [`README.md`](https://github.com/huggingface/transformers/tree/main/docs) in the docs folder.
## Code and documentation style
Code formatting is applied to all the source files, the examples and the tests using `black` and `ruff`. We also have a custom tool taking care of the formatting of docstrings and `rst` files (`utils/style_doc.py`), as well as the order of the lazy imports performed in the Transformers `__init__.py` files (`utils/custom_init_isort.py`). All of this can be launched by executing
```bash
make style
```
The CI checks those have been applied inside the `ci/circleci: check_code_quality` check. It also runs `ruff`, that will have a basic look at your code and will complain if it finds an undefined variable, or one that is not used. To run that check locally, use
```bash
make quality
```
This can take a lot of time, so to run the same thing on only the files you modified in the current branch, run
```bash
make fixup
```
This last command will also run all the additional checks for the repository consistency. Let's have a look at them.
## Repository consistency
This regroups all the tests to make sure your PR leaves the repository in a good state, and is performed by the `ci/circleci: check_repository_consistency` check. You can locally run that check by executing the following:
```bash
make repo-consistency
```
This checks that:
- All objects added to the init are documented (performed by `utils/check_repo.py`)
- All `__init__.py` files have the same content in their two sections (performed by `utils/check_inits.py`)
- All code identified as a copy from another module is consistent with the original (performed by `utils/check_copies.py`)
- All configuration classes have at least one valid checkpoint mentioned in their docstrings (performed by `utils/check_config_docstrings.py`)
- All configuration classes only contain attributes that are used in corresponding modeling files (performed by `utils/check_config_attributes.py`)
- The translations of the READMEs and the index of the doc have the same model list as the main README (performed by `utils/check_copies.py`)
- The auto-generated tables in the documentation are up to date (performed by `utils/check_table.py`)
- The library has all objects available even if not all optional dependencies are installed (performed by `utils/check_dummies.py`)
- All docstrings properly document the arguments in the signature of the object (performed by `utils/check_docstrings.py`)
Should this check fail, the first two items require manual fixing, the last four can be fixed automatically for you by running the command
```bash
make fix-copies
```
Additional checks concern PRs that add new models, mainly that:
- All models added are in an Auto-mapping (performed by `utils/check_repo.py`)
<!-- TODO Sylvain, add a check that makes sure the common tests are implemented.-->
- All models are properly tested (performed by `utils/check_repo.py`)
<!-- TODO Sylvain, add the following
- All models are added to the main README, inside the main doc
- All checkpoints used actually exist on the Hub
-->
### Check copies
Since the Transformers library is very opinionated with respect to model code, and each model should fully be implemented in a single file without relying on other models, we have added a mechanism that checks whether a copy of the code of a layer of a given model stays consistent with the original. This way, when there is a bug fix, we can see all other impacted models and choose to trickle down the modification or break the copy.
<Tip>
If a file is a full copy of another file, you should register it in the constant `FULL_COPIES` of `utils/check_copies.py`.
</Tip>
This mechanism relies on comments of the form `# Copied from xxx`. The `xxx` should contain the whole path to the class of function which is being copied below. For instance, `RobertaSelfOutput` is a direct copy of the `BertSelfOutput` class, so you can see [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L289) it has a comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
```
Note that instead of applying this to a whole class, you can apply it to the relevant methods that are copied from. For instance [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L598) you can see how `RobertaPreTrainedModel._init_weights` is copied from the same method in `BertPreTrainedModel` with the comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
```
Sometimes the copy is exactly the same except for names: for instance in `RobertaAttention`, we use `RobertaSelfAttention` insted of `BertSelfAttention` but other than that, the code is exactly the same. This is why `# Copied from` supports simple string replacements with the follwoing syntax: `Copied from xxx with foo->bar`. This means the code is copied with all instances of `foo` being replaced by `bar`. You can see how it used [here](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L304C1-L304C86) in `RobertaAttention` with the comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
```
Note that there shouldn't be any spaces around the arrow (unless that space is part of the pattern to replace of course).
You can add several patterns separated by a comma. For instance here `CamemberForMaskedLM` is a direct copy of `RobertaForMaskedLM` with two replacements: `Roberta` to `Camembert` and `ROBERTA` to `CAMEMBERT`. You can see [here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929) this is done with the comment:
```py
# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
```
If the order matters (because one of the replacements might conflict with a previous one), the replacements are executed from left to right.
<Tip>
If the replacements change the formatting (if you replace a short name by a very long name for instance), the copy is checked after applying the auto-formatter.
</Tip>
Another way when the patterns are just different casings of the same replacement (with an uppercased and a lowercased variants) is just to add the option `all-casing`. [Here](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237) is an example in `MobileBertForSequenceClassification` with the comment:
```py
# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
```
In this case, the code is copied from `BertForSequenceClassification` by replacing:
- `Bert` by `MobileBert` (for instance when using `MobileBertModel` in the init)
- `bert` by `mobilebert` (for instance when defining `self.mobilebert`)
- `BERT` by `MOBILEBERT` (in the constant `MOBILEBERT_INPUTS_DOCSTRING`)
| huggingface/transformers/blob/main/docs/source/en/pr_checks.md |
--
title: "Large-scale Near-deduplication Behind BigCode"
thumbnail: /blog/assets/dedup/thumbnail.png
authors:
- user: chenghao
---
# Large-scale Near-deduplication Behind BigCode
## Intended Audience
People who are interested in document-level near-deduplication at a large scale, and have some understanding of hashing, graph and text processing.
## Motivations
It is important to take care of our data before feeding it to the model, at least Large Language Model in our case, as the old saying goes, garbage in, garbage out. Even though it's increasingly difficult to do so with headline-grabbing models (or should we say APIs) creating an illusion that data quality matters less.
One of the problems we face in both BigScience and BigCode for data quality is duplication, including possible benchmark contamination. It has been shown that models tend to output training data verbatim when there are many duplicates[[1]](#1) (though it is less clear in some other domains[[2]](#2)), and it also makes the model vulnerable to privacy attacks[[1]](#1). Additionally, some typical advantages of deduplication also include:
1. Efficient training: You can achieve the same, and sometimes better, performance with less training steps[[3]](#3) [[4]](#4).
2. Prevent possible data leakage and benchmark contamination: Non-zero duplicates discredit your evaluations and potentially make so-called improvement a false claim.
3. Accessibility. Most of us cannot afford to download or transfer thousands of gigabytes of text repeatedly, not to mention training a model with it. Deduplication, for a fix-sized dataset, makes it easier to study, transfer and collaborate with.
## From BigScience to BigCode
Allow me to share a story first on how I jumped on this near-deduplication quest, how the results have progressed, and what lessons I have learned along the way.
It all started with a conversation on LinkedIn when [BigScience](https://bigscience.huggingface.co/) had already started for a couple of months. Huu Nguyen approached me when he noticed my pet project on GitHub, asking me if I were interested in working on deduplication for BigScience. Of course, my answer was a yes, completely ignorant of just how much effort will be required alone due to the sheer mount of the data.
It was fun and challenging at the same time. It is challenging in a sense that I didn't really have much research experience with that sheer scale of data, and everyone was still welcoming and trusting you with thousands of dollars of cloud compute budget. Yes, I had to wake up from my sleep to double-check that I had turned off those machines several times. As a result, I had to learn on the job through all the trials and errors, which in the end opened me to a new perspective that I don't think I would ever have if it weren't for BigScience.
Moving forward, one year later, I am putting what I have learned back into [BigCode](https://www.bigcode-project.org/), working on even bigger datasets. In addition to LLMs that are trained for English[[3]](#3), we have confirmed that deduplication improves code models too[[4]](#4), while using a much smaller dataset. And now, I am sharing what I have learned with you, my dear reader, and hopefully, you can also get a sense of what is happening behind the scene of BigCode through the lens of deduplication.
In case you are interested, here is an updated version of the deduplication comparison that we started in BigScience:
| Dataset | Input Size | Output Size or Deduction | Level | Method | Parameters | Language | Time |
| ------------------------------------ | -------------------------------- | --------------------------------------------------------------- | --------------------- | --------------------------------------------- | ---------------------------------------------------------------- | ------------ | ------------------- |
| OpenWebText2[[5]](#5) | After URL dedup: 193.89 GB (69M) | After MinHashLSH: 65.86 GB (17M) | URL + Document | URL(Exact) + Document(MinHash LSH) | \\( (10, 0.5, ?, ?, ?) \\) | English | |
| Pile-CC[[5]](#5) | _~306 GB_ | _227.12 GiB (~55M)_ | Document | Document(MinHash LSH) | \\( (10, 0.5, ?, ?, ?) \\) | English | "several days" |
| BNE5[[6]](#6) | 2TB | 570 GB | Document | Onion | 5-gram | Spanish | |
| MassiveText[[7]](#7) | | 0.001 TB ~ 2.1 TB | Document | Document(Exact + MinHash LSH) | \\( (?, 0.8, 13, ?, ?) \\) | English | |
| CC100-XL[[8]](#8) | | 0.01 GiB ~ 3324.45 GiB | URL + Paragraph | URL(Exact) + Paragraph(Exact) | SHA-1 | Multilingual | |
| C4[[3]](#3) | 806.92 GB (364M) | 3.04% ~ 7.18% **↓** (train) | Substring or Document | Substring(Suffix Array) or Document(MinHash) | Suffix Array: 50-token, MinHash: \\( (9000, 0.8, 5, 20, 450) \\) | English | |
| Real News[[3]](#3) | ~120 GiB | 13.63% ~ 19.4% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | |
| LM1B[[3]](#3) | ~4.40 GiB (30M) | 0.76% ~ 4.86% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | |
| WIKI40B[[3]](#3) | ~2.9M | 0.39% ~ 2.76% **↓** (train) | Same as **C4** | Same as **C4** | Same as **C4** | English | |
| The BigScience ROOTS Corpus[[9]](#9) | | 0.07% ~ 2.7% **↓** (document) + 10.61%~32.30% **↓** (substring) | Document + Substring | Document (SimHash) + Substring (Suffix Array) | SimHash: 6-grams, hamming distance of 4, Suffix Array: 50-token | Multilingual | 12 hours ~ few days |
This is the one for code datasets we created for BigCode as well. Model names are used when the dataset name isn't available.
| Model | Method | Parameters | Level |
| --------------------- | -------------------- | -------------------------------------- | -------- |
| InCoder[[10]](#10) | Exact | Alphanumeric tokens/md5 + Bloom filter | Document |
| CodeGen[[11]](#11) | Exact | SHA256 | Document |
| AlphaCode[[12]](#12) | Exact | ignore whiespaces | Document |
| PolyCode[[13]](#13) | Exact | SHA256 | Document |
| PaLM Coder[[14]](#14) | Levenshtein distance | | Document |
| CodeParrot[[15]](#15) | MinHash + LSH | \\( (256, 0.8, 1) \\) | Document |
| The Stack[[16]](#16) | MinHash + LSH | \\( (256, 0.7, 5) \\) | Document |
MinHash + LSH parameters \\( (P, T, K, B, R) \\):
1. \\( P \\) number of permutations/hashes
2. \\( T \\) Jaccard similarity threshold
3. \\( K \\) n-gram/shingle size
4. \\( B \\) number of bands
5. \\( R \\) number of rows
To get a sense of how those parameters might impact your results, here is a simple demo to illustrate the computation mathematically: [MinHash Math Demo](https://huggingface.co/spaces/bigcode/near-deduplication).
## MinHash Walkthrough
In this section, we will cover each step of MinHash, the one used in BigCode, and potential scaling issues and solutions. We will demonstrate the workflow via one example of three documents in English:
| doc_id | content |
| ------ | ---------------------------------------- |
| 0 | Deduplication is so much fun! |
| 1 | Deduplication is so much fun and easy! |
| 2 | I wish spider dog[[17]](#17) is a thing. |
The typical workflow of MinHash is as follows:
1. Shingling (tokenization) and fingerprinting (MinHashing), where we map each document into a set of hashes.
2. Locality-sensitive hashing (LSH). This step is to reduce the number of comparisons by grouping documents with similar bands together.
3. Duplicate removal. This step is where we decide which duplicated documents to keep or remove.
### Shingles
Like in most applications involving text, we need to begin with tokenization. N-grams, a.k.a. shingles, are often used. In our example, we will be using word-level tri-grams, without any punctuations. We will circle back to how the size of ngrams impacts the performance in a later section.
| doc_id | shingles |
| ------ | ------------------------------------------------------------------------------- |
| 0 | {"Deduplication is so", "is so much", "so much fun"} |
| 1 | {'so much fun', 'fun and easy', 'Deduplication is so', 'is so much'} |
| 2 | {'dog is a', 'is a thing', 'wish spider dog', 'spider dog is', 'I wish spider'} |
This operation has a time complexity of \\( \mathcal{O}(NM) \\) where \\( N \\) is the number of documents and \\( M \\) is the length of the document. In other words, it is linearly dependent on the size of the dataset. This step can be easily scaled by parallelization by multiprocessing or distributed computation.
### Fingerprint Computation
In MinHash, each shingle will typically either be 1) hashed multiple times with different hash functions, or 2) permuted multiple times using one hash function. Here, we choose to permute each hash 5 times. More variants of MinHash can be found in [MinHash - Wikipedia](https://en.wikipedia.org/wiki/MinHash?useskin=vector).
| shingle | permuted hashes |
| ------------------- | ----------------------------------------------------------- |
| Deduplication is so | [403996643, 2764117407, 3550129378, 3548765886, 2353686061] |
| is so much | [3594692244, 3595617149, 1564558780, 2888962350, 432993166] |
| so much fun | [1556191985, 840529008, 1008110251, 3095214118, 3194813501] |
Taking the minimum value of each column within each document — the "Min" part of the "MinHash", we arrive at the final MinHash for this document:
| doc_id | minhash |
| ------ | ---------------------------------------------------------- |
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] |
Technically, we don't have to use the minimum value of each column, but the minimum value is the most common choice. Other order statistics such as maximum, kth smallest, or kth largest can be used as well[[21]](#21).
In implementation, you can easily vectorize these steps with `numpy` and expect to have a time complexity of \\( \mathcal{O}(NMK) \\) where \\( K \\) is your number of permutations. Code modified based on [Datasketch](https://github.com/ekzhu/datasketch).
```python
def embed_func(
content: str,
idx: int,
*,
num_perm: int,
ngram_size: int,
hashranges: List[Tuple[int, int]],
permutations: np.ndarray,
) -> Dict[str, Any]:
a, b = permutations
masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH)
tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)}
hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64)
permuted_hashvalues = np.bitwise_and(
((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH
)
hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0)
Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges]
return {"__signatures__": Hs, "__id__": idx}
```
If you are familiar with [Datasketch](https://github.com/ekzhu/datasketch), you might ask, why do we bother to strip all the nice high-level functions the library provides? It is not because we want to avoid adding dependencies, but because we intend to squeeze as much CPU computation as possible during parallelization. Fusing few steps into one function call enables us to utilize our compute resources better.
Since one document's calculation is not dependent on anything else. A good parallelization choice would be using the `map` function from the `datasets` library:
```python
embedded = ds.map(
function=embed_func,
fn_kwargs={
"num_perm": args.num_perm,
"hashranges": HASH_RANGES,
"ngram_size": args.ngram,
"permutations": PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)
```
After the fingerprint calculation, one particular document is mapped to one array of integer values. To figure out what documents are similar to each other, we need to group them based on such fingerprints. Entering the stage, **Locality Sensitive Hashing (LSH)**.
### Locality Sensitive Hashing
LSH breaks the fingerprint array into bands, each band containing the same number of rows. If there is any hash values left, it will be ignored. Let's use \\( b=2 \\) bands and \\( r=2 \\) rows to group those documents:
| doc_id | minhash | bands |
| ------ | ---------------------------------------------------------- | ------------------------------------------------------ |
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 2888962350]] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 1998729813]] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] | [0:[166417565, 213933364], 1:[1129612544, 1419614622]] |
If two documents share the same hashes in a band at a particular location (band index), they will be clustered into the same bucket and will be considered as candidates.
| band index | band value | doc_ids |
| ---------- | ------------------------ | ------- |
| 0 | [403996643, 840529008] | 0, 1 |
| 1 | [1008110251, 2888962350] | 0 |
| 1 | [1008110251, 1998729813] | 1 |
| 0 | [166417565, 213933364] | 2 |
| 1 | [1129612544, 1419614622] | 2 |
For each row in the `doc_ids` column, we can generate candidate pairs by pairing every two of them. From the above table, we can generate one candidate pair: `(0, 1)`.
### Beyond Duplicate Pairs
This is where many deduplication descriptions in papers or tutorials stop. We are still left with the question of what to do with them. Generally, we can proceed with two options:
1. Double-check their actual Jaccard similarities by calculating their shingle overlap, due to the estimation nature of MinHash. The Jaccard Similarity of two sets is defined as the size of the intersection divided by the size of the union. And now it becomes much more doable than computing all-pair similarities, because we can focus only for documents within a cluster. This is also what we initially did for BigCode, which worked reasonably well.
2. Treat them as true positives. You probably already noticed the issue here: the Jaccard similarity isn't transitive, meaning \\( A \\) is similar to \\( B \\) and \\( B \\) is similar to \\( C \\), but \\( A \\) and \\( C \\) do not necessary share the similarity. However, our experiments from The Stack show that treating all of them as duplicates improves the downstream model's performance the best. And now we gradually moved towards this method instead, and it saves time as well. But to apply this to your dataset, we still recommend going over your dataset and looking at your duplicates, and then making a data-driven decision.
From such pairs, whether they are validated or not, we can now construct a graph with those pairs as edges, and duplicates will be clustered into communities or connected components. In terms of implementation, unfortunately, this is where `datasets` couldn't help much because now we need something like a `groupby` where we can cluster documents based on their _band offset_ and _band values_. Here are some options we have tried:
**Option 1: Iterate the datasets the old-fashioned way and collect edges. Then use a graph library to do community detection or connected component detection.**
This did not scale well in our tests, and the reasons are multifold. First, iterating the whole dataset is slow and memory consuming at a large scale. Second, popular graph libraries like `graphtool` or `networkx` have a lot of overhead for graph creation.
**Option 2: Use popular python frameworks such as `dask` to allow more efficient `groupby` operations**.
But then you still have problems of slow iteration and slow graph creation.
**Option 3: Iterate the dataset, but use a union find data structure to cluster documents.**
This adds negligible overhead to the iteration, and it works relatively well for medium datasets.
```python
for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="Clustering..."):
for cluster in table.values():
if len(cluster) <= 1:
continue
idx = min(cluster)
for x in cluster:
uf.union(x, idx)
```
**Option 4: For large datasets, use Spark.**
We already know that steps up to the LSH part can be parallelized, which is also achievable in Spark. In addition to that, Spark supports distributed `groupBy` out of the box, and it is also straightforward to implement algorithms like [[18]](#18) for connected component detection. If you are wondering why we didn't use Spark's implementation of MinHash, the answer is that all our experiments so far stemmed from [Datasketch](https://github.com/ekzhu/datasketch), which uses an entirely different implementation than Spark, and we want to ensure that we carry on the lessons and insights learned from that without going into another rabbit hole of ablation experiments.
```python
edges = (
records.flatMap(
lambda x: generate_hash_values(
content=x[1],
idx=x[0],
num_perm=args.num_perm,
ngram_size=args.ngram_size,
hashranges=HASH_RANGES,
permutations=PERMUTATIONS,
)
)
.groupBy(lambda x: (x[0], x[1]))
.flatMap(lambda x: generate_edges([i[2] for i in x[1]]))
.distinct()
.cache()
)
```
A simple connected component algorithm based on [[18]](#18) implemented in Spark.
```python
a = edges
while True:
b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache()
a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache()
changes = a.subtract(b).union(b.subtract(a)).collect()
if len(changes) == 0:
break
results = a.collect()
```
Additionally, thanks to cloud providers, we can set up Spark clusters like a breeze with services like GCP DataProc. **In the end, we can comfortably run the program to deduplicate 1.4 TB of data in just under 4 hours with a budget of $15 an hour.**
## Quality Matters
Scaling a ladder doesn't get us to the moon. That's why we need to make sure this is the right direction, and we are using it the right way.
Early on, our parameters were largely inherited from the CodeParrot experiments, and our ablation experiment indicated that those settings did improve the model's downstream performance[[16]](#16). We then set to further explore this path and can confirm that[[4]](#4):
1. Near-deduplication improves the model's downstream performance with a much smaller dataset (6 TB VS. 3 TB)
2. We haven't figured out the limit yet, but a more aggressive deduplication (6 TB VS. 2.4 TB) can improve the performance even more:
1. Lower the similarity threshold
2. Increase the shingle size (unigram → 5-gram)
3. Ditch false positive checking because we can afford to lose a small percentage of false positives
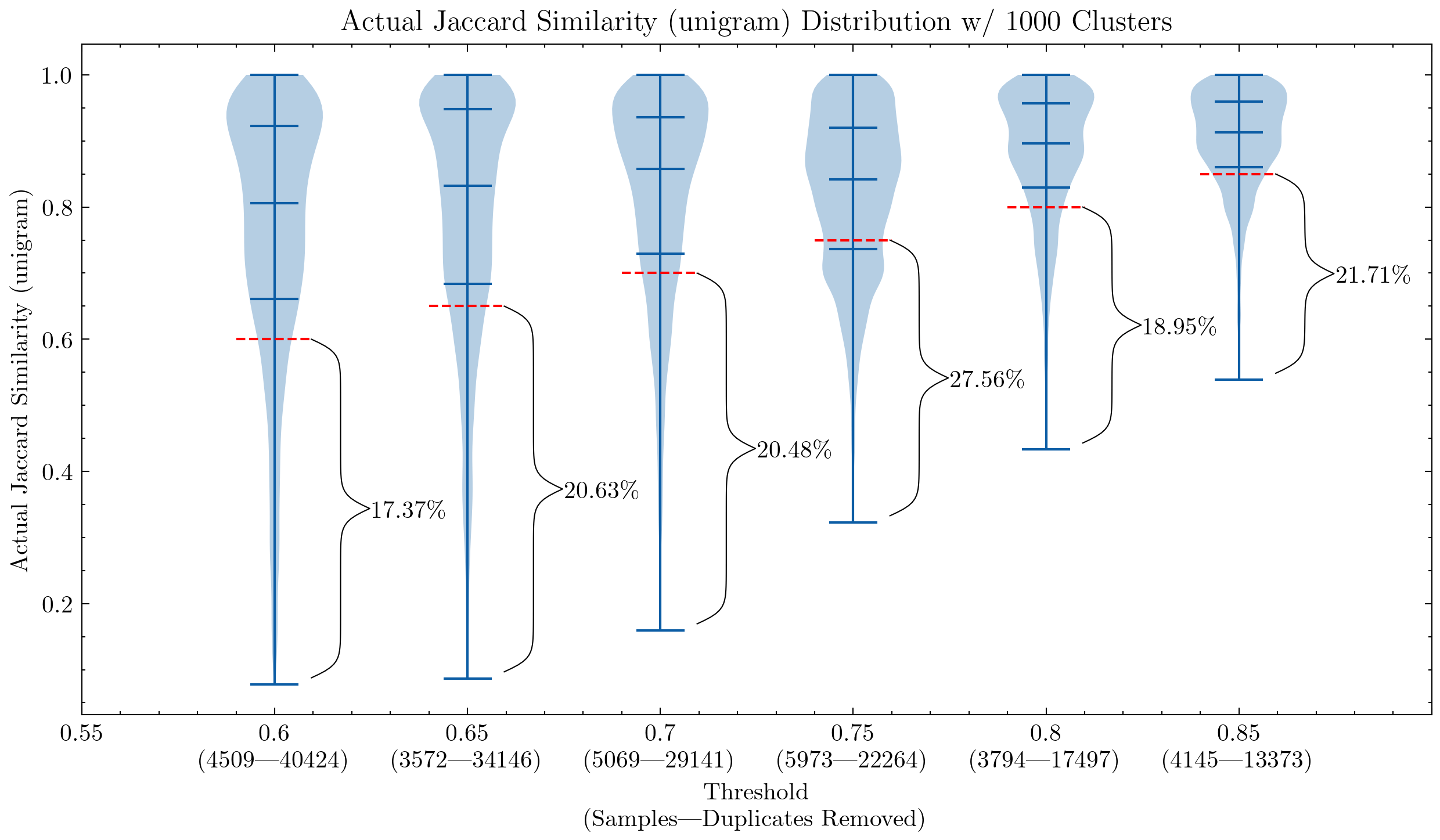
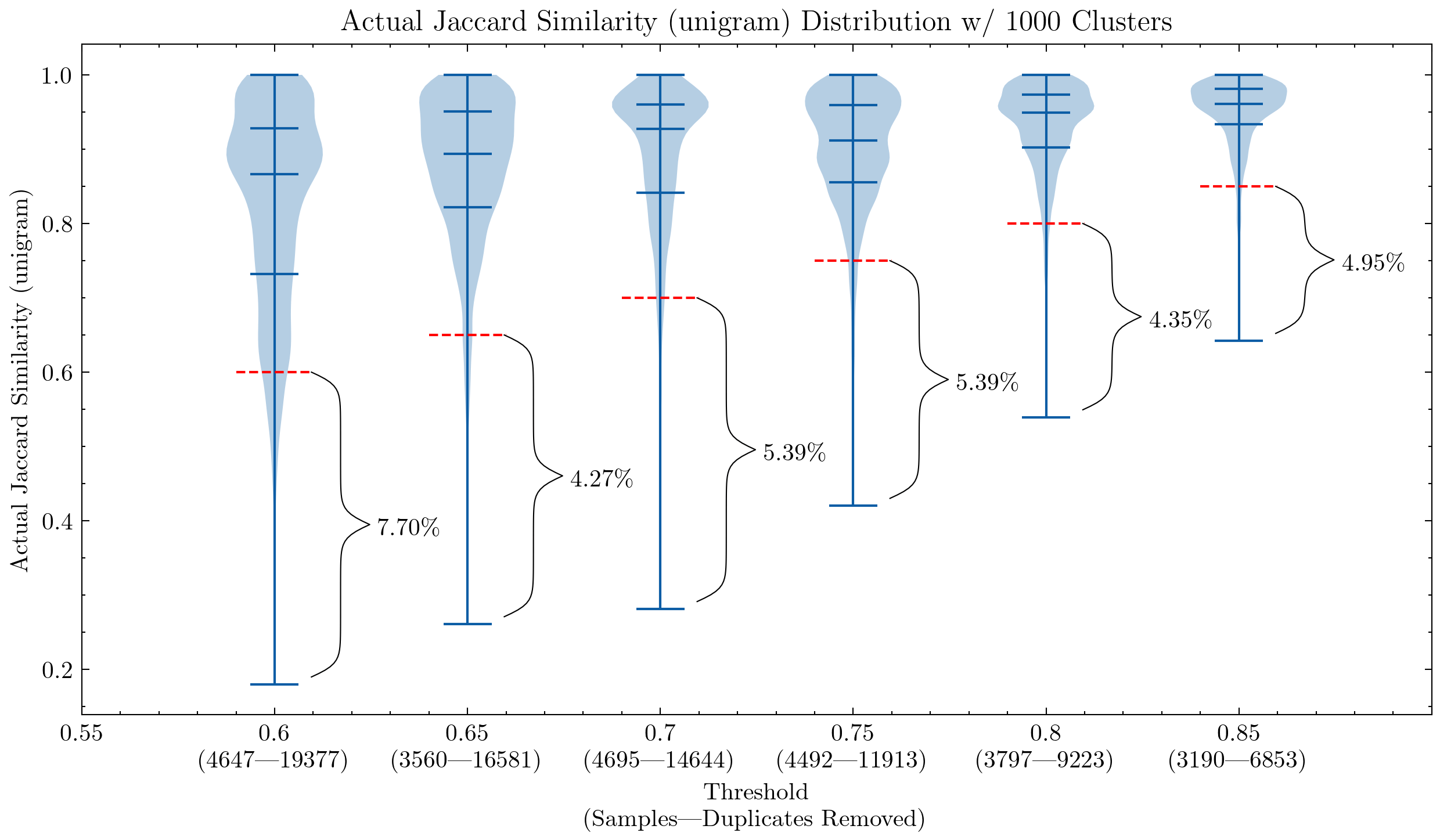
<center>
Image: Two graphs showing the impact of similarity threshold and shingle size, the first one is using unigram and the second one 5-gram. The red dash line shows the similarity cutoff: any documents below would be considered as false positives — their similarities with other documents within a cluster are lower than the threshold.
</center>
These graphs can help us understand why it was necessary to double-check the false positives for CodeParrot and early version of the Stack: using unigram creates many false positives; They also demonstrate that by increasing the shingle size to 5-gram, the percentage of false positives decreases significantly. A smaller threshold is desired if we want to keep the deduplication aggressiveness.
Additional experiments also showed that lowering the threshold removes more documents that have high similarity pairs, meaning an increased recall in the segment we actually would like to remove the most.
## Scaling
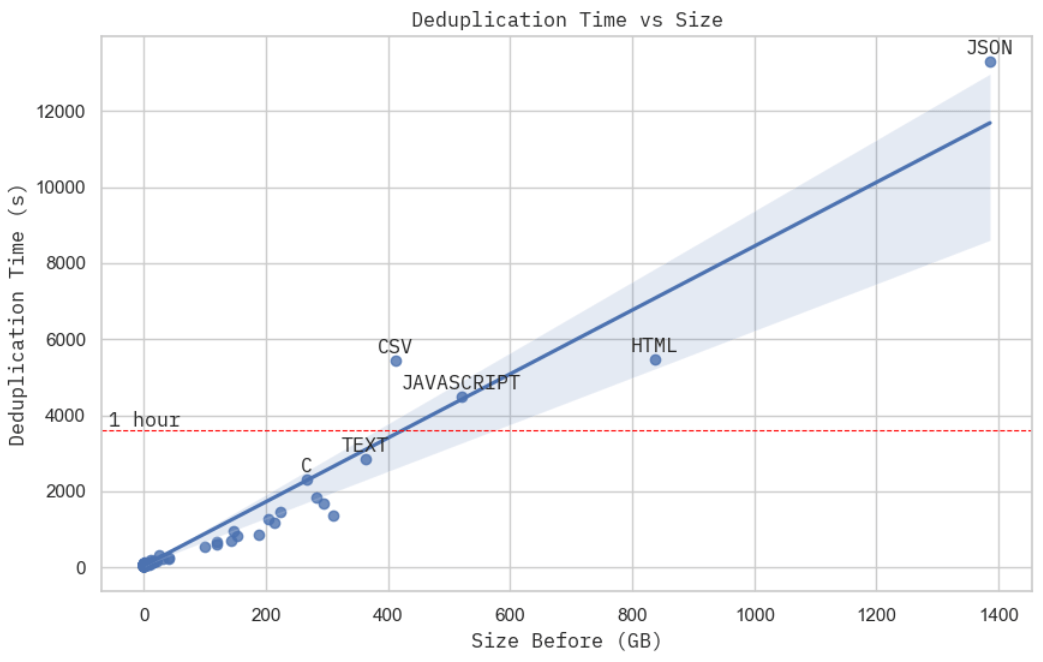
<center>Image: Deduplication time versus raw dataset size. This is achieved with 15 worker c2d-standard-16 machines on GCP, and each costed around $0.7 per hour. </center>

<center>Image: CPU usage screenshot for the cluster during processing JSON dataset.</center>
This isn't the most rigorous scaling proof you can find, but the deduplication time, given a fixed computation budget, looks practically linear to the physical size of the dataset. When you take a closer look at the cluster resource usage when processing JSON dataset, the largest subset in the Stack, you can see the MinHash + LSH (stage 2) dominated the total real computation time (stage 2 + 3), which from our previous analysis is \\( \mathcal{O}(NM) \\) — linear to the dataset physical volume.
## Proceed with Caution
Deduplication doesn't exempt you from thorough data exploration and analysis. In addition, these deduplication discoveries hold true for the Stack, but it does not mean it is readily applicable to other datasets or languages. It is a good first step towards building a better dataset, and further investigations such as data quality filtering (e.g., vulnerability, toxicity, bias, generated templates, PII) are still much needed.
We still encourage you to perform similar analysis on your datasets before training. For example, it might not be very helpful to do deduplication if you have tight time and compute budget: [@geiping_2022](http://arxiv.org/abs/2212.14034) mentions that substring deduplication didn't improve their model's downstream performance. Existing datasets might also require thorough examination before use, for example, [@gao_2020](http://arxiv.org/abs/2101.00027) states that they only made sure the Pile itself, along with its splits, are deduplicated, and they won't proactively deduplicating for any downstream benchmarks and leave that decision to readers.
In terms of data leakage and benchmark contamination, there is still much to explore. We had to retrain our code models because HumanEval was published in one of the GitHub repos in Python. Early near-deduplication results also suggest that MBPP[[19]](#19), one of the most popular benchmarks for coding, shares a lot of similarity with many Leetcode problems (e.g., task 601 in MBPP is basically Leetcode 646, task 604 ≃ Leetcode 151.). And we all know GitHub is no short of those coding challenges and solutions. It will be even more difficult if someone with bad intentions upload all the benchmarks in the form of python scripts, or other less obvious ways, and pollute all your training data.
## Future Directions
1. Substring deduplication. Even though it showed some benefits for English[[3]](#3), it is not clear yet if this should be applied to code data as well;
2. Repetition: paragraphs that are repeated multiple times in one document. [@rae_2021](http://arxiv.org/abs/2112.11446) shared some interesting heuristics on how to detect and remove them.
3. Using model embeddings for semantic deduplication. It is another whole research question with scaling, cost, ablation experiments, and trade-off with near-deduplication. There are some intriguing takes on this[[20]](#20), but we still need more situated evidence to draw a conclusion (e.g, [@abbas_2023](http://arxiv.org/abs/2303.09540)'s only text deduplication reference is [@lee_2022a](http://arxiv.org/abs/2107.06499), whose main claim is deduplicating helps instead of trying to be SOTA).
4. Optimization. There is always room for optimization: better quality evaluation, scaling, downstream performance impact analysis etc.
5. Then there is another direction to look at things: To what extent near-deduplication starts to hurt performance? To what extent similarity is needed for diversity instead of being considered as redundancy?
## Credits
The banner image contains emojis (hugging face, Santa, document, wizard, and wand) from Noto Emoji (Apache 2.0). This blog post is proudly written without any generative APIs.
Huge thanks to Huu Nguyen @Huu and Hugo Laurençon @HugoLaurencon for the collaboration in BigScience and everyone at BigCode for the help along the way! If you ever find any error, feel free to contact me: mouchenghao at gmail dot com.
## Supporting Resources
- [Datasketch](https://github.com/ekzhu/datasketch) (MIT)
- [simhash-py](https://github.com/seomoz/simhash-py/tree/master/simhash) and [simhash-cpp](https://github.com/seomoz/simhash-cpp) (MIT)
- [Deduplicating Training Data Makes Language Models Better](https://github.com/google-research/deduplicate-text-datasets) (Apache 2.0)
- [Gaoya](https://github.com/serega/gaoya) (MIT)
- [BigScience](https://github.com/bigscience-workshop) (Apache 2.0)
- [BigCode](https://github.com/bigcode-project) (Apache 2.0)
## References
- <a id="1">[1]</a> : Nikhil Kandpal, Eric Wallace, Colin Raffel, [Deduplicating Training Data Mitigates Privacy Risks in Language Models](http://arxiv.org/abs/2202.06539), 2022
- <a id="2">[2]</a> : Gowthami Somepalli, et al., [Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models](http://arxiv.org/abs/2212.03860), 2022
- <a id="3">[3]</a> : Katherine Lee, Daphne Ippolito, et al., [Deduplicating Training Data Makes Language Models Better](http://arxiv.org/abs/2107.06499), 2022
- <a id="4">[4]</a> : Loubna Ben Allal, Raymond Li, et al., [SantaCoder: Don't reach for the stars!](http://arxiv.org/abs/2301.03988), 2023
- <a id="5">[5]</a> : Leo Gao, Stella Biderman, et al., [The Pile: An 800GB Dataset of Diverse Text for Language Modeling](http://arxiv.org/abs/2101.00027), 2020
- <a id="6">[6]</a> : Asier Gutiérrez-Fandiño, Jordi Armengol-Estapé, et al., [MarIA: Spanish Language Models](http://arxiv.org/abs/2107.07253), 2022
- <a id="7">[7]</a> : Jack W. Rae, Sebastian Borgeaud, et al., [Scaling Language Models: Methods, Analysis & Insights from Training Gopher](http://arxiv.org/abs/2112.11446), 2021
- <a id="8">[8]</a> : Xi Victoria Lin, Todor Mihaylov, et al., [Few-shot Learning with Multilingual Language Models](http://arxiv.org/abs/2112.10668), 2021
- <a id="9">[9]</a> : Hugo Laurençon, Lucile Saulnier, et al., [The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset](https://openreview.net/forum?id=UoEw6KigkUn), 2022
- <a id="10">[10]</a> : Daniel Fried, Armen Aghajanyan, et al., [InCoder: A Generative Model for Code Infilling and Synthesis](http://arxiv.org/abs/2204.05999), 2022
- <a id="11">[11]</a> : Erik Nijkamp, Bo Pang, et al., [CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis](http://arxiv.org/abs/2203.13474), 2023
- <a id="12">[12]</a> : Yujia Li, David Choi, et al., [Competition-Level Code Generation with AlphaCode](http://arxiv.org/abs/2203.07814), 2022
- <a id="13">[13]</a> : Frank F. Xu, Uri Alon, et al., [A Systematic Evaluation of Large Language Models of Code](http://arxiv.org/abs/2202.13169), 2022
- <a id="14">[14]</a> : Aakanksha Chowdhery, Sharan Narang, et al., [PaLM: Scaling Language Modeling with Pathways](http://arxiv.org/abs/2204.02311), 2022
- <a id="15">[15]</a> : Lewis Tunstall, Leandro von Werra, Thomas Wolf, [Natural Language Processing with Transformers, Revised Edition](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/), 2022
- <a id="16">[16]</a> : Denis Kocetkov, Raymond Li, et al., [The Stack: 3 TB of permissively licensed source code](http://arxiv.org/abs/2211.15533), 2022
- <a id="17">[17]</a> : [Rocky | Project Hail Mary Wiki | Fandom](https://projecthailmary.fandom.com/wiki/Rocky)
- <a id="18">[18]</a> : Raimondas Kiveris, Silvio Lattanzi, et al., [Connected Components in MapReduce and Beyond](https://doi.org/10.1145/2670979.2670997), 2014
- <a id="19">[19]</a> : Jacob Austin, Augustus Odena, et al., [Program Synthesis with Large Language Models](http://arxiv.org/abs/2108.07732), 2021
- <a id="20">[20]</a>: Amro Abbas, Kushal Tirumala, et al., [SemDeDup: Data-efficient learning at web-scale through semantic deduplication](http://arxiv.org/abs/2303.09540), 2023
- <a id="21">[21]</a>: Edith Cohen, [MinHash Sketches : A Brief Survey](http://www.cohenwang.com/edith/Surveys/minhash.pdf), 2016
| huggingface/blog/blob/main/dedup.md |
Gradio Demo: annotatedimage_component
```
!pip install -q gradio
```
```
import gradio as gr
import pathlib
from PIL import Image
import numpy as np
import urllib.request
source_dir = pathlib.Path(__file__).parent
urllib.request.urlretrieve(
'https://gradio-builds.s3.amazonaws.com/demo-files/base.png',
str(source_dir / "base.png")
)
urllib.request.urlretrieve(
"https://gradio-builds.s3.amazonaws.com/demo-files/buildings.png",
str(source_dir / "buildings.png")
)
base_image = Image.open(str(source_dir / "base.png"))
building_image = Image.open(str(source_dir / "buildings.png"))
# Create segmentation mask
building_image = np.asarray(building_image)[:, :, -1] > 0
with gr.Blocks() as demo:
gr.AnnotatedImage(
value=(base_image, [(building_image, "buildings")]),
height=500,
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/annotatedimage_component/run.ipynb |
Storage Regions on the Hub
Regions let you decide where your org's models and datasets will be stored.
<Tip warning={true}>
This feature is part of the <a href="https://huggingface.co/enterprise" target="_blank">Enterprise Hub</a>.
</Tip>
This has two main benefits:
- Regulatory and legal compliance
- Performance (improved download and upload speeds and latency)
Currently we support the following regions:
- US 🇺🇸
- EU 🇪🇺
- coming soon: Asia-Pacific 🌏
## How to set up
If your organization is subscribed to Enterprise Hub, you will be able to see the Regions settings page:
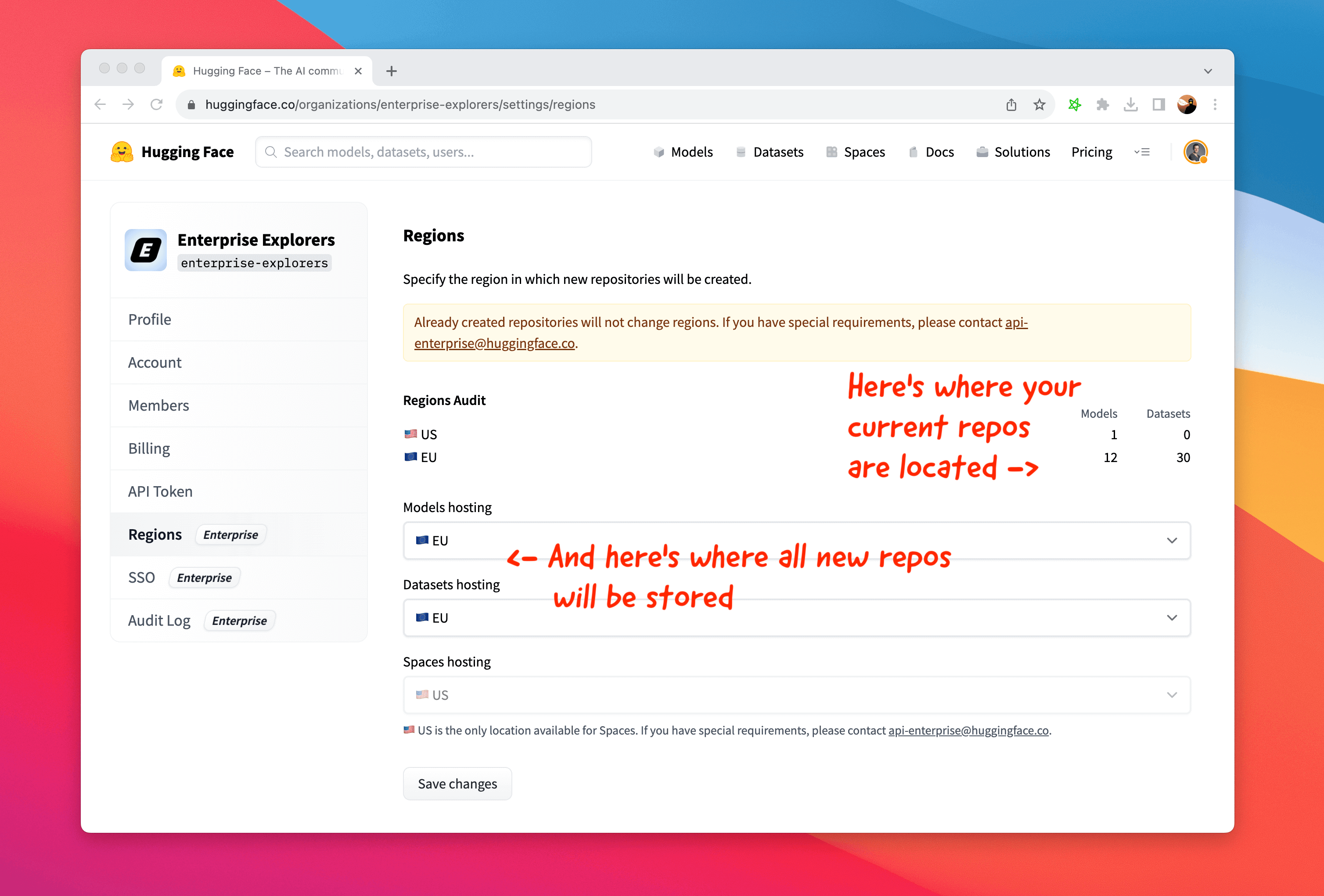
On that page you can see:
- an audit of where your organization repos are currently located
- dropdowns to select where your repos will be created
## Repository Tag
Any repo (model or dataset) stored in a non-default location will display its Region directly as a tag. That way your organization's members can see at a glance where repos are located.
<div class="flex justify-center">
<img class="block" width="400" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/storage-regions/tag-on-repo.png"/>
</div>
## Regulatory and legal compliance
In regulated industries, companies may be required to store data in a specific region.
For companies in the EU, that means you can use the Hub to build ML in a GDPR compliant way: with datasets, models and inference endpoints all stored within EU data centers.
## Performance
Storing your models or your datasets closer to your team and infrastructure also means significantly improved performance, for both uploads and downloads.
This makes a big difference considering model weights and dataset files are usually very large.

As an example, if you are located in Europe and store your repositories in the EU region, you can expect to see ~4-5x faster upload and download speeds vs. if they were stored in the US.
| huggingface/hub-docs/blob/main/docs/hub/storage-regions.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Semantic segmentation using LoRA
This guide demonstrates how to use LoRA, a low-rank approximation technique, to finetune a SegFormer model variant for semantic segmentation.
By using LoRA from 🤗 PEFT, we can reduce the number of trainable parameters in the SegFormer model to only 14% of the original trainable parameters.
LoRA achieves this reduction by adding low-rank "update matrices" to specific blocks of the model, such as the attention
blocks. During fine-tuning, only these matrices are trained, while the original model parameters are left unchanged.
At inference time, the update matrices are merged with the original model parameters to produce the final classification result.
For more information on LoRA, please refer to the [original LoRA paper](https://arxiv.org/abs/2106.09685).
## Install dependencies
Install the libraries required for model training:
```bash
!pip install transformers accelerate evaluate datasets peft -q
```
## Authenticate to share your model
To share the finetuned model with the community at the end of the training, authenticate using your 🤗 token.
You can obtain your token from your [account settings](https://huggingface.co/settings/token).
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Load a dataset
To ensure that this example runs within a reasonable time frame, here we are limiting the number of instances from the training
set of the [SceneParse150 dataset](https://huggingface.co/datasets/scene_parse_150) to 150.
```python
from datasets import load_dataset
ds = load_dataset("scene_parse_150", split="train[:150]")
```
Next, split the dataset into train and test sets.
```python
ds = ds.train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
```
## Prepare label maps
Create a dictionary that maps a label id to a label class, which will be useful when setting up the model later:
* `label2id`: maps the semantic classes of the dataset to integer ids.
* `id2label`: maps integer ids back to the semantic classes.
```python
import json
from huggingface_hub import cached_download, hf_hub_url
repo_id = "huggingface/label-files"
filename = "ade20k-id2label.json"
id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename, repo_type="dataset")), "r"))
id2label = {int(k): v for k, v in id2label.items()}
label2id = {v: k for k, v in id2label.items()}
num_labels = len(id2label)
```
## Prepare datasets for training and evaluation
Next, load the SegFormer image processor to prepare the images and annotations for the model. This dataset uses the
zero-index as the background class, so make sure to set `do_reduce_labels=True` to subtract one from all labels since the
background class is not among the 150 classes.
```python
from transformers import AutoImageProcessor
checkpoint = "nvidia/mit-b0"
image_processor = AutoImageProcessor.from_pretrained(checkpoint, do_reduce_labels=True)
```
Add a function to apply data augmentation to the images, so that the model is more robust against overfitting. Here we use the
[ColorJitter](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html) function from
[torchvision](https://pytorch.org/vision/stable/index.html) to randomly change the color properties of an image.
```python
from torchvision.transforms import ColorJitter
jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
```
Add a function to handle grayscale images and ensure that each input image has three color channels, regardless of
whether it was originally grayscale or RGB. The function converts RGB images to array as is, and for grayscale images
that have only one color channel, the function replicates the same channel three times using `np.tile()` before converting
the image into an array.
```python
import numpy as np
def handle_grayscale_image(image):
np_image = np.array(image)
if np_image.ndim == 2:
tiled_image = np.tile(np.expand_dims(np_image, -1), 3)
return Image.fromarray(tiled_image)
else:
return Image.fromarray(np_image)
```
Finally, combine everything in two functions that you'll use to transform training and validation data. The two functions
are similar except data augmentation is applied only to the training data.
```python
from PIL import Image
def train_transforms(example_batch):
images = [jitter(handle_grayscale_image(x)) for x in example_batch["image"]]
labels = [x for x in example_batch["annotation"]]
inputs = image_processor(images, labels)
return inputs
def val_transforms(example_batch):
images = [handle_grayscale_image(x) for x in example_batch["image"]]
labels = [x for x in example_batch["annotation"]]
inputs = image_processor(images, labels)
return inputs
```
To apply the preprocessing functions over the entire dataset, use the 🤗 Datasets `set_transform` function:
```python
train_ds.set_transform(train_transforms)
test_ds.set_transform(val_transforms)
```
## Create evaluation function
Including a metric during training is helpful for evaluating your model's performance. You can load an evaluation
method with the [🤗 Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, use
the [mean Intersection over Union (IoU)](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate
[quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```python
import torch
from torch import nn
import evaluate
metric = evaluate.load("mean_iou")
def compute_metrics(eval_pred):
with torch.no_grad():
logits, labels = eval_pred
logits_tensor = torch.from_numpy(logits)
logits_tensor = nn.functional.interpolate(
logits_tensor,
size=labels.shape[-2:],
mode="bilinear",
align_corners=False,
).argmax(dim=1)
pred_labels = logits_tensor.detach().cpu().numpy()
# currently using _compute instead of compute
# see this issue for more info: https://github.com/huggingface/evaluate/pull/328#issuecomment-1286866576
metrics = metric._compute(
predictions=pred_labels,
references=labels,
num_labels=len(id2label),
ignore_index=0,
reduce_labels=image_processor.do_reduce_labels,
)
per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
per_category_iou = metrics.pop("per_category_iou").tolist()
metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
return metrics
```
## Load a base model
Before loading a base model, let's define a helper function to check the total number of parameters a model has, as well
as how many of them are trainable.
```python
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
)
```
Choose a base model checkpoint. For this example, we use the [SegFormer B0 variant](https://huggingface.co/nvidia/mit-b0).
In addition to the checkpoint, pass the `label2id` and `id2label` dictionaries to let the `AutoModelForSemanticSegmentation` class know that we're
interested in a custom base model where the decoder head should be randomly initialized using the classes from the custom dataset.
```python
from transformers import AutoModelForSemanticSegmentation, TrainingArguments, Trainer
model = AutoModelForSemanticSegmentation.from_pretrained(
checkpoint, id2label=id2label, label2id=label2id, ignore_mismatched_sizes=True
)
print_trainable_parameters(model)
```
At this point you can check with the `print_trainable_parameters` helper function that all 100% parameters in the base
model (aka `model`) are trainable.
## Wrap the base model as a PeftModel for LoRA training
To leverage the LoRa method, you need to wrap the base model as a `PeftModel`. This involves two steps:
1. Defining LoRa configuration with `LoraConfig`
2. Wrapping the original `model` with `get_peft_model()` using the config defined in the step above.
```python
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=32,
lora_alpha=32,
target_modules=["query", "value"],
lora_dropout=0.1,
bias="lora_only",
modules_to_save=["decode_head"],
)
lora_model = get_peft_model(model, config)
print_trainable_parameters(lora_model)
```
Let's review the `LoraConfig`. To enable LoRA technique, we must define the target modules within `LoraConfig` so that
`PeftModel` can update the necessary matrices. Specifically, we want to target the `query` and `value` matrices in the
attention blocks of the base model. These matrices are identified by their respective names, "query" and "value".
Therefore, we should specify these names in the `target_modules` argument of `LoraConfig`.
After we wrap our base model `model` with `PeftModel` along with the config, we get
a new model where only the LoRA parameters are trainable (so-called "update matrices") while the pre-trained parameters
are kept frozen. These include the parameters of the randomly initialized classifier parameters too. This is NOT we want
when fine-tuning the base model on our custom dataset. To ensure that the classifier parameters are also trained, we
specify `modules_to_save`. This also ensures that these modules are serialized alongside the LoRA trainable parameters
when using utilities like `save_pretrained()` and `push_to_hub()`.
In addition to specifying the `target_modules` within `LoraConfig`, we also need to specify the `modules_to_save`. When
we wrap our base model with `PeftModel` and pass the configuration, we obtain a new model in which only the LoRA parameters
are trainable, while the pre-trained parameters and the randomly initialized classifier parameters are kept frozen.
However, we do want to train the classifier parameters. By specifying the `modules_to_save` argument, we ensure that the
classifier parameters are also trainable, and they will be serialized alongside the LoRA trainable parameters when we
use utility functions like `save_pretrained()` and `push_to_hub()`.
Let's review the rest of the parameters:
- `r`: The dimension used by the LoRA update matrices.
- `alpha`: Scaling factor.
- `bias`: Specifies if the `bias` parameters should be trained. `None` denotes none of the `bias` parameters will be trained.
When all is configured, and the base model is wrapped, the `print_trainable_parameters` helper function lets us explore
the number of trainable parameters. Since we're interested in performing **parameter-efficient fine-tuning**,
we should expect to see a lower number of trainable parameters from the `lora_model` in comparison to the original `model`
which is indeed the case here.
You can also manually verify what modules are trainable in the `lora_model`.
```python
for name, param in lora_model.named_parameters():
if param.requires_grad:
print(name, param.shape)
```
This confirms that only the LoRA parameters appended to the attention blocks and the `decode_head` parameters are trainable.
## Train the model
Start by defining your training hyperparameters in `TrainingArguments`. You can change the values of most parameters however
you prefer. Make sure to set `remove_unused_columns=False`, otherwise the image column will be dropped, and it's required here.
The only other required parameter is `output_dir` which specifies where to save your model.
At the end of each epoch, the `Trainer` will evaluate the IoU metric and save the training checkpoint.
Note that this example is meant to walk you through the workflow when using PEFT for semantic segmentation. We didn't
perform extensive hyperparameter tuning to achieve optimal results.
```python
model_name = checkpoint.split("/")[-1]
training_args = TrainingArguments(
output_dir=f"{model_name}-scene-parse-150-lora",
learning_rate=5e-4,
num_train_epochs=50,
per_device_train_batch_size=4,
per_device_eval_batch_size=2,
save_total_limit=3,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=5,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
)
```
Pass the training arguments to `Trainer` along with the model, dataset, and `compute_metrics` function.
Call `train()` to finetune your model.
```python
trainer = Trainer(
model=lora_model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
trainer.train()
```
## Save the model and run inference
Use the `save_pretrained()` method of the `lora_model` to save the *LoRA-only parameters* locally.
Alternatively, use the `push_to_hub()` method to upload these parameters directly to the Hugging Face Hub
(as shown in the [Image classification using LoRA](image_classification_lora) task guide).
```python
model_id = "segformer-scene-parse-150-lora"
lora_model.save_pretrained(model_id)
```
We can see that the LoRA-only parameters are just **2.2 MB in size**! This greatly improves the portability when using very large models.
```bash
!ls -lh {model_id}
total 2.2M
-rw-r--r-- 1 root root 369 Feb 8 03:09 adapter_config.json
-rw-r--r-- 1 root root 2.2M Feb 8 03:09 adapter_model.bin
```
Let's now prepare an `inference_model` and run inference.
```python
from peft import PeftConfig
config = PeftConfig.from_pretrained(model_id)
model = AutoModelForSemanticSegmentation.from_pretrained(
checkpoint, id2label=id2label, label2id=label2id, ignore_mismatched_sizes=True
)
inference_model = PeftModel.from_pretrained(model, model_id)
```
Get an image:
```python
import requests
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/semantic-seg-image.png"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/semantic-seg-image.png" alt="photo of a room"/>
</div>
Preprocess the image to prepare for inference.
```python
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
```
Run inference with the encoded image.
```python
with torch.no_grad():
outputs = inference_model(pixel_values=encoding.pixel_values)
logits = outputs.logits
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1],
mode="bilinear",
align_corners=False,
)
pred_seg = upsampled_logits.argmax(dim=1)[0]
```
Next, visualize the results. We need a color palette for this. Here, we use ade_palette(). As it is a long array, so
we don't include it in this guide, please copy it from [the TensorFlow Model Garden repository](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51).
```python
import matplotlib.pyplot as plt
color_seg = np.zeros((pred_seg.shape[0], pred_seg.shape[1], 3), dtype=np.uint8)
palette = np.array(ade_palette())
for label, color in enumerate(palette):
color_seg[pred_seg == label, :] = color
color_seg = color_seg[..., ::-1] # convert to BGR
img = np.array(image) * 0.5 + color_seg * 0.5 # plot the image with the segmentation map
img = img.astype(np.uint8)
plt.figure(figsize=(15, 10))
plt.imshow(img)
plt.show()
```
As you can see, the results are far from perfect, however, this example is designed to illustrate the end-to-end workflow of
fine-tuning a semantic segmentation model with LoRa technique, and is not aiming to achieve state-of-the-art
results. The results you see here are the same as you would get if you performed full fine-tuning on the same setup (same
model variant, same dataset, same training schedule, etc.), except LoRA allows to achieve them with a fraction of total
trainable parameters and in less time.
If you wish to use this example and improve the results, here are some things that you can try:
* Increase the number of training samples.
* Try a larger SegFormer model variant (explore available model variants on the [Hugging Face Hub](https://huggingface.co/models?search=segformer)).
* Try different values for the arguments available in `LoraConfig`.
* Tune the learning rate and batch size.
| huggingface/peft/blob/main/docs/source/task_guides/semantic_segmentation_lora.md |
Running a Gradio App on your Web Server with Nginx
Tags: DEPLOYMENT, WEB SERVER, NGINX
## Introduction
Gradio is a Python library that allows you to quickly create customizable web apps for your machine learning models and data processing pipelines. Gradio apps can be deployed on [Hugging Face Spaces](https://hf.space) for free.
In some cases though, you might want to deploy a Gradio app on your own web server. You might already be using [Nginx](https://www.nginx.com/), a highly performant web server, to serve your website (say `https://www.example.com`), and you want to attach Gradio to a specific subpath on your website (e.g. `https://www.example.com/gradio-demo`).
In this Guide, we will guide you through the process of running a Gradio app behind Nginx on your own web server to achieve this.
**Prerequisites**
1. A Linux web server with [Nginx installed](https://www.nginx.com/blog/setting-up-nginx/) and [Gradio installed](/quickstart)
2. A working Gradio app saved as a python file on your web server
## Editing your Nginx configuration file
1. Start by editing the Nginx configuration file on your web server. By default, this is located at: `/etc/nginx/nginx.conf`
In the `http` block, add the following line to include server block configurations from a separate file:
```bash
include /etc/nginx/sites-enabled/*;
```
2. Create a new file in the `/etc/nginx/sites-available` directory (create the directory if it does not already exist), using a filename that represents your app, for example: `sudo nano /etc/nginx/sites-available/my_gradio_app`
3. Paste the following into your file editor:
```bash
server {
listen 80;
server_name example.com www.example.com; # Change this to your domain name
location /gradio-demo/ { # Change this if you'd like to server your Gradio app on a different path
proxy_pass http://127.0.0.1:7860/; # Change this if your Gradio app will be running on a different port
proxy_buffering off;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
}
}
```
## Run your Gradio app on your web server
1. Before you launch your Gradio app, you'll need to set the `root_path` to be the same as the subpath that you specified in your nginx configuration. This is necessary for Gradio to run on any subpath besides the root of the domain.
Here's a simple example of a Gradio app with a custom `root_path`:
```python
import gradio as gr
import time
def test(x):
time.sleep(4)
return x
gr.Interface(test, "textbox", "textbox").queue().launch(root_path="/gradio-demo")
```
2. Start a `tmux` session by typing `tmux` and pressing enter (optional)
It's recommended that you run your Gradio app in a `tmux` session so that you can keep it running in the background easily
3. Then, start your Gradio app. Simply type in `python` followed by the name of your Gradio python file. By default, your app will run on `localhost:7860`, but if it starts on a different port, you will need to update the nginx configuration file above.
## Restart Nginx
1. If you are in a tmux session, exit by typing CTRL+B (or CMD+B), followed by the "D" key.
2. Finally, restart nginx by running `sudo systemctl restart nginx`.
And that's it! If you visit `https://example.com/gradio-demo` on your browser, you should see your Gradio app running there
| gradio-app/gradio/blob/main/guides/09_other-tutorials/running-gradio-on-your-web-server-with-nginx.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ControlNet-XS with Stable Diffusion XL
ControlNet-XS was introduced in [ControlNet-XS](https://vislearn.github.io/ControlNet-XS/) by Denis Zavadski and Carsten Rother. It is based on the observation that the control model in the [original ControlNet](https://huggingface.co/papers/2302.05543) can be made much smaller and still produce good results.
Like the original ControlNet model, you can provide an additional control image to condition and control Stable Diffusion generation. For example, if you provide a depth map, the ControlNet model generates an image that'll preserve the spatial information from the depth map. It is a more flexible and accurate way to control the image generation process.
ControlNet-XS generates images with comparable quality to a regular ControlNet, but it is 20-25% faster ([see benchmark](https://github.com/UmerHA/controlnet-xs-benchmark/blob/main/Speed%20Benchmark.ipynb)) and uses ~45% less memory.
Here's the overview from the [project page](https://vislearn.github.io/ControlNet-XS/):
*With increasing computing capabilities, current model architectures appear to follow the trend of simply upscaling all components without validating the necessity for doing so. In this project we investigate the size and architectural design of ControlNet [Zhang et al., 2023] for controlling the image generation process with stable diffusion-based models. We show that a new architecture with as little as 1% of the parameters of the base model achieves state-of-the art results, considerably better than ControlNet in terms of FID score. Hence we call it ControlNet-XS. We provide the code for controlling StableDiffusion-XL [Podell et al., 2023] (Model B, 48M Parameters) and StableDiffusion 2.1 [Rombach et al. 2022] (Model B, 14M Parameters), all under openrail license.*
This model was contributed by [UmerHA](https://twitter.com/UmerHAdil). ❤️
<Tip warning={true}>
🧪 Many of the SDXL ControlNet checkpoints are experimental, and there is a lot of room for improvement. Feel free to open an [Issue](https://github.com/huggingface/diffusers/issues/new/choose) and leave us feedback on how we can improve!
</Tip>
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## StableDiffusionXLControlNetXSPipeline
[[autodoc]] StableDiffusionXLControlNetXSPipeline
- all
- __call__
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/controlnetxs_sdxl.md |
Movement Pruning: Adaptive Sparsity by Fine-Tuning
Author: @VictorSanh
*Magnitude pruning is a widely used strategy for reducing model size in pure supervised learning; however, it is less effective in the transfer learning regime that has become standard for state-of-the-art natural language processing applications. We propose the use of *movement pruning*, a simple, deterministic first-order weight pruning method that is more adaptive to pretrained model fine-tuning. Experiments show that when pruning large pretrained language models, movement pruning shows significant improvements in high-sparsity regimes. When combined with distillation, the approach achieves minimal accuracy loss with down to only 3% of the model parameters:*
| Fine-pruning+Distillation<br>(Teacher=BERT-base fine-tuned) | BERT base<br>fine-tuned | Remaining<br>Weights (%) | Magnitude Pruning | L0 Regularization | Movement Pruning | Soft Movement Pruning |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| SQuAD - Dev<br>EM/F1 | 80.4/88.1 | 10%<br>3% | 70.2/80.1<br>45.5/59.6 | 72.4/81.9<br>64.3/75.8 | 75.6/84.3<br>67.5/78.0 | **76.6/84.9**<br>**72.7/82.3** |
| MNLI - Dev<br>acc/MM acc | 84.5/84.9 | 10%<br>3% | 78.3/79.3<br>69.4/70.6 | 78.7/79.7<br>76.0/76.2 | 80.1/80.4<br>76.5/77.4 | **81.2/81.8**<br>**79.5/80.1** |
| QQP - Dev<br>acc/F1 | 91.4/88.4 | 10%<br>3% | 79.8/65.0<br>72.4/57.8 | 88.1/82.8<br>87.0/81.9 | 89.7/86.2<br>86.1/81.5 | **90.2/86.8**<br>**89.1/85.5** |
This page contains information on how to fine-prune pre-trained models such as `BERT` to obtain extremely sparse models with movement pruning. In contrast to magnitude pruning which selects weights that are far from 0, movement pruning retains weights that are moving away from 0.
For more information, we invite you to check out [our paper](https://arxiv.org/abs/2005.07683).
You can also have a look at this fun *Explain Like I'm Five* introductory [slide deck](https://www.slideshare.net/VictorSanh/movement-pruning-explain-like-im-five-234205241).
<div align="center">
<img src="https://www.seekpng.com/png/detail/166-1669328_how-to-make-emmental-cheese-at-home-icooker.png" width="400">
</div>
## Extreme sparsity and efficient storage
One promise of extreme pruning is to obtain extremely small models that can be easily sent (and stored) on edge devices. By setting weights to 0., we reduce the amount of information we need to store, and thus decreasing the memory size. We are able to obtain extremely sparse fine-pruned models with movement pruning: ~95% of the dense performance with ~5% of total remaining weights in the BERT encoder.
In [this notebook](https://github.com/huggingface/transformers/blob/main/examples/research_projects/movement-pruning/Saving_PruneBERT.ipynb), we showcase how we can leverage standard tools that exist out-of-the-box to efficiently store an extremely sparse question answering model (only 6% of total remaining weights in the encoder). We are able to reduce the memory size of the encoder **from the 340MB (the original dense BERT) to 11MB**, without any additional training of the model (every operation is performed *post fine-pruning*). It is sufficiently small to store it on a [91' floppy disk](https://en.wikipedia.org/wiki/Floptical) 📎!
While movement pruning does not directly optimize for memory footprint (but rather the number of non-null weights), we hypothetize that further memory compression ratios can be achieved with specific quantization aware trainings (see for instance [Q8BERT](https://arxiv.org/abs/1910.06188), [And the Bit Goes Down](https://arxiv.org/abs/1907.05686) or [Quant-Noise](https://arxiv.org/abs/2004.07320)).
## Fine-pruned models
As examples, we release two English PruneBERT checkpoints (models fine-pruned from a pre-trained `BERT` checkpoint), one on SQuAD and the other on MNLI.
- **`prunebert-base-uncased-6-finepruned-w-distil-squad`**<br/>
Pre-trained `BERT-base-uncased` fine-pruned with soft movement pruning on SQuAD v1.1. We use an additional distillation signal from `BERT-base-uncased` finetuned on SQuAD. The encoder counts 6% of total non-null weights and reaches 83.8 F1 score. The model can be accessed with: `pruned_bert = BertForQuestionAnswering.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-squad")`
- **`prunebert-base-uncased-6-finepruned-w-distil-mnli`**<br/>
Pre-trained `BERT-base-uncased` fine-pruned with soft movement pruning on MNLI. We use an additional distillation signal from `BERT-base-uncased` finetuned on MNLI. The encoder counts 6% of total non-null weights and reaches 80.7 (matched) accuracy. The model can be accessed with: `pruned_bert = BertForSequenceClassification.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-mnli")`
## How to fine-prune?
### Setup
The code relies on the 🤗 Transformers library. In addition to the dependencies listed in the [`examples`](https://github.com/huggingface/transformers/tree/main/examples) folder, you should install a few additional dependencies listed in the `requirements.txt` file: `pip install -r requirements.txt`.
Note that we built our experiments on top of a stabilized version of the library (commit https://github.com/huggingface/transformers/commit/352d5472b0c1dec0f420d606d16747d851b4bda8): we do not guarantee that everything is still compatible with the latest version of the main branch.
### Fine-pruning with movement pruning
Below, we detail how to reproduce the results reported in the paper. We use SQuAD as a running example. Commands (and scripts) can be easily adapted for other tasks.
The following command fine-prunes a pre-trained `BERT-base` on SQuAD using movement pruning towards 15% of remaining weights (85% sparsity). Note that we freeze all the embeddings modules (from their pre-trained value) and only prune the Fully Connected layers in the encoder (12 layers of Transformer Block).
```bash
SERIALIZATION_DIR=<OUTPUT_DIR>
SQUAD_DATA=<SQUAD_DATA>
python examples/movement-pruning/masked_run_squad.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $SQUAD_DATA \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
--initial_threshold 1 --final_threshold 0.15 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method topK --mask_init constant --mask_scale 0.
```
### Fine-pruning with other methods
We can also explore other fine-pruning methods by changing the `pruning_method` parameter:
Soft movement pruning
```bash
python examples/movement-pruning/masked_run_squad.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $SQUAD_DATA \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
--initial_threshold 0 --final_threshold 0.1 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method sigmoied_threshold --mask_init constant --mask_scale 0. \
--regularization l1 --final_lambda 400.
```
L0 regularization
```bash
python examples/movement-pruning/masked_run_squad.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $SQUAD_DATA \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-1 \
--initial_threshold 1. --final_threshold 1. \
--initial_warmup 1 --final_warmup 1 \
--pruning_method l0 --mask_init constant --mask_scale 2.197 \
--regularization l0 --final_lambda 125.
```
Iterative Magnitude Pruning
```bash
python examples/movement-pruning/masked_run_squad.py \
--output_dir ./dbg \
--data_dir examples/distillation/data/squad_data \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 \
--initial_threshold 1 --final_threshold 0.15 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method magnitude
```
### After fine-pruning
**Counting parameters**
Regularization based pruning methods (soft movement pruning and L0 regularization) rely on the penalty to induce sparsity. The multiplicative coefficient controls the sparsity level.
To obtain the effective sparsity level in the encoder, we simply count the number of activated (non-null) weights:
```bash
python examples/movement-pruning/counts_parameters.py \
--pruning_method sigmoied_threshold \
--threshold 0.1 \
--serialization_dir $SERIALIZATION_DIR
```
**Pruning once for all**
Once the model has been fine-pruned, the pruned weights can be set to 0. once for all (reducing the amount of information to store). In our running experiments, we can convert a `MaskedBertForQuestionAnswering` (a BERT model augmented to enable on-the-fly pruning capabilities) to a standard `BertForQuestionAnswering`:
```bash
python examples/movement-pruning/bertarize.py \
--pruning_method sigmoied_threshold \
--threshold 0.1 \
--model_name_or_path $SERIALIZATION_DIR
```
## Hyper-parameters
For reproducibility purposes, we share the detailed results presented in the paper. These [tables](https://docs.google.com/spreadsheets/d/17JgRq_OFFTniUrz6BZWW_87DjFkKXpI1kYDSsseT_7g/edit?usp=sharing) exhaustively describe the individual hyper-parameters used for each data point.
## Inference speed
Early experiments show that even though models fine-pruned with (soft) movement pruning are extremely sparse, they do not benefit from significant improvement in terms of inference speed when using the standard PyTorch inference.
We are currently benchmarking and exploring inference setups specifically for sparse architectures.
In particular, hardware manufacturers are announcing devices that will speedup inference for sparse networks considerably.
## Citation
If you find this resource useful, please consider citing the following paper:
```
@article{sanh2020movement,
title={Movement Pruning: Adaptive Sparsity by Fine-Tuning},
author={Victor Sanh and Thomas Wolf and Alexander M. Rush},
year={2020},
eprint={2005.07683},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| huggingface/transformers/blob/main/examples/research_projects/movement-pruning/README.md |
@gradio/upload
## 0.5.6
### Fixes
- [#6766](https://github.com/gradio-app/gradio/pull/6766) [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144) - Improve source selection UX. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.5.5
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/client@0.9.2
- @gradio/upload@0.5.5
## 0.5.4
### Fixes
- [#6525](https://github.com/gradio-app/gradio/pull/6525) [`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a) - Fixes Drag and Drop for Upload. Thanks [@dawoodkhan82](https://github.com/dawoodkhan82)!
## 0.5.3
### Fixes
- [#6709](https://github.com/gradio-app/gradio/pull/6709) [`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88) - Remove progress animation on streaming. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.5.2
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/upload@0.5.2
## 0.5.1
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/client@0.8.2
- @gradio/upload@0.5.1
## 0.5.0
### Highlights
#### New `ImageEditor` component ([#6169](https://github.com/gradio-app/gradio/pull/6169) [`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8))
A brand new component, completely separate from `Image` that provides simple editing capabilities.
- Set background images from file uploads, webcam, or just paste!
- Crop images with an improved cropping UI. App authors can event set specific crop size, or crop ratios (`1:1`, etc)
- Paint on top of any image (or no image) and erase any mistakes!
- The ImageEditor supports layers, confining draw and erase actions to that layer.
- More flexible access to data. The image component returns a composite image representing the final state of the canvas as well as providing the background and all layers as individual images.
- Fully customisable. All features can be enabled and disabled. Even the brush color swatches can be customised.
<video src="https://user-images.githubusercontent.com/12937446/284027169-31188926-fd16-4a1c-8718-998e7aae4695.mp4" autoplay muted></video>
```py
def fn(im):
im["composite"] # the full canvas
im["background"] # the background image
im["layers"] # a list of individual layers
im = gr.ImageEditor(
# decide which sources you'd like to accept
sources=["upload", "webcam", "clipboard"],
# set a cropsize constraint, can either be a ratio or a concrete [width, height]
crop_size="1:1",
# enable crop (or disable it)
transforms=["crop"],
# customise the brush
brush=Brush(
default_size="25", # or leave it as 'auto'
color_mode="fixed", # 'fixed' hides the user swatches and colorpicker, 'defaults' shows it
default_color="hotpink", # html names are supported
colors=[
"rgba(0, 150, 150, 1)", # rgb(a)
"#fff", # hex rgb
"hsl(360, 120, 120)" # in fact any valid colorstring
]
),
brush=Eraser(default_size="25")
)
```
Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.2
### Fixes
- [#6441](https://github.com/gradio-app/gradio/pull/6441) [`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521) - Small but important bugfixes for gr.Image: The upload event was not triggering at all. The paste-from-clipboard was not triggering an upload event. The clear button was not triggering a change event. The change event was triggering infinitely. Uploaded images were not preserving their original names. Uploading a new image should clear out the previous image. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.1
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/client@0.8.1
- @gradio/upload@0.4.1
## 0.4.0
### Features
- [#6356](https://github.com/gradio-app/gradio/pull/6356) [`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c) - Redesign file upload. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#6307](https://github.com/gradio-app/gradio/pull/6307) [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57) - Provide status updates on file uploads. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.3
### Fixes
- [#6279](https://github.com/gradio-app/gradio/pull/6279) [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780) - Ensure source selection does not get hidden in overflow. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.2
### Fixes
- [#6234](https://github.com/gradio-app/gradio/pull/6234) [`aaa55ce85`](https://github.com/gradio-app/gradio/commit/aaa55ce85e12f95aba9299445e9c5e59824da18e) - Video/Audio fixes. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/client@0.7.1
- @gradio/upload@0.3.1
## 0.3.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.6
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.5
### Features
- [#6044](https://github.com/gradio-app/gradio/pull/6044) [`9053c95a1`](https://github.com/gradio-app/gradio/commit/9053c95a10de12aef572018ee37c71106d2da675) - Simplify File Component. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.3.0-beta.4
### Features
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.3
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
## 0.3.2
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.4
## 0.3.1
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/icons@0.2.0
- @gradio/atoms@0.1.3
## 0.3.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.1
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.2
## 0.2.0
### Features
- [#5373](https://github.com/gradio-app/gradio/pull/5373) [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96) - Adds `height` and `zoom_speed` parameters to `Model3D` component, as well as a button to reset the camera position. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
### Fixes
- [#5285](https://github.com/gradio-app/gradio/pull/5285) [`cdfd4217`](https://github.com/gradio-app/gradio/commit/cdfd42174a9c777eaee9c1209bf8e90d8c7791f2) - Tweaks to `icon` parameter in `gr.Button()`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.0.3
### Fixes
- [#5077](https://github.com/gradio-app/gradio/pull/5077) [`667875b2`](https://github.com/gradio-app/gradio/commit/667875b2441753e74d25bd9d3c8adedd8ede11cd) - Live audio streaming output
highlight:
#### Now supports loading streamed outputs
Allows users to use generators to stream audio out, yielding consecutive chunks of audio. Requires `streaming=True` to be set on the output audio.
```python
import gradio as gr
from pydub import AudioSegment
def stream_audio(audio_file):
audio = AudioSegment.from_mp3(audio_file)
i = 0
chunk_size = 3000
while chunk_size*i < len(audio):
chunk = audio[chunk_size*i:chunk_size*(i+1)]
i += 1
if chunk:
file = f"/tmp/{i}.mp3"
chunk.export(file, format="mp3")
yield file
demo = gr.Interface(
fn=stream_audio,
inputs=gr.Audio(type="filepath", label="Audio file to stream"),
outputs=gr.Audio(autoplay=True, streaming=True),
)
demo.queue().launch()
```
From the backend, streamed outputs are served from the `/stream/` endpoint instead of the `/file/` endpoint. Currently just used to serve audio streaming output. The output JSON will have `is_stream`: `true`, instead of `is_file`: `true` in the file data object. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.0.2
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.0.2 | gradio-app/gradio/blob/main/js/upload/CHANGELOG.md |
ControlNet training example
[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
This example is based on the [training example in the original ControlNet repository](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md). It trains a ControlNet to fill circles using a [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k).
## Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
## Circle filling dataset
The original dataset is hosted in the [ControlNet repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip). We re-uploaded it to be compatible with `datasets` [here](https://huggingface.co/datasets/fusing/fill50k). Note that `datasets` handles dataloading within the training script.
Our training examples use [Stable Diffusion 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the original set of ControlNet models were trained from it. However, ControlNet can be trained to augment any Stable Diffusion compatible model (such as [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)) or [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1).
## Training
Our training examples use two test conditioning images. They can be downloaded by running
```sh
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=4
```
This default configuration requires ~38GB VRAM.
By default, the training script logs outputs to tensorboard. Pass `--report_to wandb` to use weights and
biases.
Gradient accumulation with a smaller batch size can be used to reduce training requirements to ~20 GB VRAM.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4
```
## Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch --mixed_precision="fp16" --multi_gpu train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=4 \
--mixed_precision="fp16" \
--tracker_project_name="controlnet-demo" \
--report_to=wandb
```
## Example results
#### After 300 steps with batch size 8
| | |
|-------------------|:-------------------------:|
| | red circle with blue background |
 |  |
| | cyan circle with brown floral background |
 |  |
#### After 6000 steps with batch size 8:
| | |
|-------------------|:-------------------------:|
| | red circle with blue background |
 |  |
| | cyan circle with brown floral background |
 |  |
## Training on a 16 GB GPU
Optimizations:
- Gradient checkpointing
- bitsandbyte's 8-bit optimizer
[bitandbytes install instructions](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
```
## Training on a 12 GB GPU
Optimizations:
- Gradient checkpointing
- bitsandbyte's 8-bit optimizer
- xformers
- set grads to none
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none
```
When using `enable_xformers_memory_efficient_attention`, please make sure to install `xformers` by `pip install xformers`.
## Training on an 8 GB GPU
We have not exhaustively tested DeepSpeed support for ControlNet. While the configuration does
save memory, we have not confirmed the configuration to train successfully. You will very likely
have to make changes to the config to have a successful training run.
Optimizations:
- Gradient checkpointing
- xformers
- set grads to none
- DeepSpeed stage 2 with parameter and optimizer offloading
- fp16 mixed precision
[DeepSpeed](https://www.deepspeed.ai/) can offload tensors from VRAM to either
CPU or NVME. This requires significantly more RAM (about 25 GB).
Use `accelerate config` to enable DeepSpeed stage 2.
The relevant parts of the resulting accelerate config file are
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 4
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
```
See [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more DeepSpeed configuration options.
Changing the default Adam optimizer to DeepSpeed's Adam
`deepspeed.ops.adam.DeepSpeedCPUAdam` gives a substantial speedup but
it requires CUDA toolchain with the same version as pytorch. 8-bit optimizer
does not seem to be compatible with DeepSpeed at the moment.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none \
--mixed_precision fp16
```
## Performing inference with the trained ControlNet
The trained model can be run the same as the original ControlNet pipeline with the newly trained ControlNet.
Set `base_model_path` and `controlnet_path` to the values `--pretrained_model_name_or_path` and
`--output_dir` were respectively set to in the training script.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import torch
base_model_path = "path to model"
controlnet_path = "path to controlnet"
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
base_model_path, controlnet=controlnet, torch_dtype=torch.float16
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# remove following line if xformers is not installed or when using Torch 2.0.
pipe.enable_xformers_memory_efficient_attention()
# memory optimization.
pipe.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
# generate image
generator = torch.manual_seed(0)
image = pipe(
prompt, num_inference_steps=20, generator=generator, image=control_image
).images[0]
image.save("./output.png")
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
### Running on Google Cloud TPU
See below for commands to set up a TPU VM(`--accelerator-type v4-8`). For more details about how to set up and use TPUs, refer to [Cloud docs for single VM setup](https://cloud.google.com/tpu/docs/run-calculation-jax).
First create a single TPUv4-8 VM and connect to it:
```
ZONE=us-central2-b
TPU_TYPE=v4-8
VM_NAME=hg_flax
gcloud alpha compute tpus tpu-vm create $VM_NAME \
--zone $ZONE \
--accelerator-type $TPU_TYPE \
--version tpu-vm-v4-base
gcloud alpha compute tpus tpu-vm ssh $VM_NAME --zone $ZONE -- \
```
When connected install JAX `0.4.5`:
```
pip install "jax[tpu]==0.4.5" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
```
To verify that JAX was correctly installed, you can run the following command:
```
import jax
jax.device_count()
```
This should display the number of TPU cores, which should be 4 on a TPUv4-8 VM.
Then install Diffusers and the library's training dependencies:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -U -r requirements_flax.txt
```
If you want to use Weights and Biases logging, you should also install `wandb` now
```bash
pip install wandb
```
Now let's downloading two conditioning images that we will use to run validation during the training in order to track our progress
```
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
We encourage you to store or share your model with the community. To use huggingface hub, please login to your Hugging Face account, or ([create one](https://huggingface.co/docs/diffusers/main/en/training/hf.co/join) if you don’t have one already):
```
huggingface-cli login
```
Make sure you have the `MODEL_DIR`,`OUTPUT_DIR` and `HUB_MODEL_ID` environment variables set. The `OUTPUT_DIR` and `HUB_MODEL_ID` variables specify where to save the model to on the Hub:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/fill-circle-{timestamp}"
export HUB_MODEL_ID="controlnet-fill-circle"
```
And finally start the training
```bash
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=1000 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID \
--num_train_epochs=11 \
--push_to_hub \
--hub_model_id=$HUB_MODEL_ID
```
Since we passed the `--push_to_hub` flag, it will automatically create a model repo under your huggingface account based on `$HUB_MODEL_ID`. By the end of training, the final checkpoint will be automatically stored on the hub. You can find an example model repo [here](https://huggingface.co/YiYiXu/fill-circle-controlnet).
Our training script also provides limited support for streaming large datasets from the Hugging Face Hub. In order to enable streaming, one must also set `--max_train_samples`. Here is an example command (from [this blog article](https://huggingface.co/blog/train-your-controlnet)):
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/uncanny-faces-{timestamp}"
export HUB_MODEL_ID="controlnet-uncanny-faces"
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--streaming \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--max_train_samples 100000 \
--learning_rate=1e-5 \
--train_batch_size=1 \
--revision="flax" \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID
```
Note, however, that the performance of the TPUs might get bottlenecked as streaming with `datasets` is not optimized for images. For ensuring maximum throughput, we encourage you to explore the following options:
* [Webdataset](https://webdataset.github.io/webdataset/)
* [TorchData](https://github.com/pytorch/data)
* [TensorFlow Datasets](https://www.tensorflow.org/datasets/tfless_tfds)
When work with a larger dataset, you may need to run training process for a long time and it’s useful to save regular checkpoints during the process. You can use the following argument to enable intermediate checkpointing:
```bash
--checkpointing_steps=500
```
This will save the trained model in subfolders of your output_dir. Subfolder names is the number of steps performed so far; for example: a checkpoint saved after 500 training steps would be saved in a subfolder named 500
You can then start your training from this saved checkpoint with
```bash
--controlnet_model_name_or_path="./control_out/500"
```
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
We also support gradient accumulation - it is a technique that lets you use a bigger batch size than your machine would normally be able to fit into memory. You can use `gradient_accumulation_steps` argument to set gradient accumulation steps. The ControlNet author recommends using gradient accumulation to achieve better convergence. Read more [here](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md#more-consideration-sudden-converge-phenomenon-and-gradient-accumulation).
You can **profile your code** with:
```bash
--profile_steps==5
```
Refer to the [JAX documentation on profiling](https://jax.readthedocs.io/en/latest/profiling.html). To inspect the profile trace, you'll have to install and start Tensorboard with the profile plugin:
```bash
pip install tensorflow tensorboard-plugin-profile
tensorboard --logdir runs/fill-circle-100steps-20230411_165612/
```
The profile can then be inspected at http://localhost:6006/#profile
Sometimes you'll get version conflicts (error messages like `Duplicate plugins for name projector`), which means that you have to uninstall and reinstall all versions of Tensorflow/Tensorboard (e.g. with `pip uninstall tensorflow tf-nightly tensorboard tb-nightly tensorboard-plugin-profile && pip install tf-nightly tbp-nightly tensorboard-plugin-profile`).
Note that the debugging functionality of the Tensorboard `profile` plugin is still under active development. Not all views are fully functional, and for example the `trace_viewer` cuts off events after 1M (which can result in all your device traces getting lost if you for example profile the compilation step by accident).
## Support for Stable Diffusion XL
We provide a training script for training a ControlNet with [Stable Diffusion XL](https://huggingface.co/papers/2307.01952). Please refer to [README_sdxl.md](./README_sdxl.md) for more details.
| huggingface/diffusers/blob/main/examples/controlnet/README.md |
Metric Card for Precision
## Metric Description
Precision is the fraction of correctly labeled positive examples out of all of the examples that were labeled as positive. It is computed via the equation:
Precision = TP / (TP + FP)
where TP is the True positives (i.e. the examples correctly labeled as positive) and FP is the False positive examples (i.e. the examples incorrectly labeled as positive).
## How to Use
At minimum, precision takes as input a list of predicted labels, `predictions`, and a list of output labels, `references`.
```python
>>> precision_metric = datasets.load_metric("precision")
>>> results = precision_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'precision': 1.0}
```
### Inputs
- **predictions** (`list` of `int`): Predicted class labels.
- **references** (`list` of `int`): Actual class labels.
- **labels** (`list` of `int`): The set of labels to include when `average` is not set to `'binary'`. If `average` is `None`, it should be the label order. Labels present in the data can be excluded, for example to calculate a multiclass average ignoring a majority negative class. Labels not present in the data will result in 0 components in a macro average. For multilabel targets, labels are column indices. By default, all labels in `predictions` and `references` are used in sorted order. Defaults to None.
- **pos_label** (`int`): The class to be considered the positive class, in the case where `average` is set to `binary`. Defaults to 1.
- **average** (`string`): This parameter is required for multiclass/multilabel targets. If set to `None`, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data. Defaults to `'binary'`.
- 'binary': Only report results for the class specified by `pos_label`. This is applicable only if the classes found in `predictions` and `references` are binary.
- 'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.
- 'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- 'weighted': Calculate metrics for each label, and find their average weighted by support (the number of true instances for each label). This alters `'macro'` to account for label imbalance. This option can result in an F-score that is not between precision and recall.
- 'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification).
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
- **zero_division** (): Sets the value to return when there is a zero division. Defaults to .
- 0: Returns 0 when there is a zero division.
- 1: Returns 1 when there is a zero division.
- 'warn': Raises warnings and then returns 0 when there is a zero division.
### Output Values
- **precision**(`float` or `array` of `float`): Precision score or list of precision scores, depending on the value passed to `average`. Minimum possible value is 0. Maximum possible value is 1. Higher values indicate that fewer negative examples were incorrectly labeled as positive, which means that, generally, higher scores are better.
Output Example(s):
```python
{'precision': 0.2222222222222222}
```
```python
{'precision': array([0.66666667, 0.0, 0.0])}
```
#### Values from Popular Papers
### Examples
Example 1-A simple binary example
```python
>>> precision_metric = datasets.load_metric("precision")
>>> results = precision_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0])
>>> print(results)
{'precision': 0.5}
```
Example 2-The same simple binary example as in Example 1, but with `pos_label` set to `0`.
```python
>>> precision_metric = datasets.load_metric("precision")
>>> results = precision_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], pos_label=0)
>>> print(round(results['precision'], 2))
0.67
```
Example 3-The same simple binary example as in Example 1, but with `sample_weight` included.
```python
>>> precision_metric = datasets.load_metric("precision")
>>> results = precision_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], sample_weight=[0.9, 0.5, 3.9, 1.2, 0.3])
>>> print(results)
{'precision': 0.23529411764705882}
```
Example 4-A multiclass example, with different values for the `average` input.
```python
>>> predictions = [0, 2, 1, 0, 0, 1]
>>> references = [0, 1, 2, 0, 1, 2]
>>> results = precision_metric.compute(predictions=predictions, references=references, average='macro')
>>> print(results)
{'precision': 0.2222222222222222}
>>> results = precision_metric.compute(predictions=predictions, references=references, average='micro')
>>> print(results)
{'precision': 0.3333333333333333}
>>> results = precision_metric.compute(predictions=predictions, references=references, average='weighted')
>>> print(results)
{'precision': 0.2222222222222222}
>>> results = precision_metric.compute(predictions=predictions, references=references, average=None)
>>> print([round(res, 2) for res in results['precision']])
[0.67, 0.0, 0.0]
```
## Limitations and Bias
[Precision](https://huggingface.co/metrics/precision) and [recall](https://huggingface.co/metrics/recall) are complementary and can be used to measure different aspects of model performance -- using both of them (or an averaged measure like [F1 score](https://huggingface.co/metrics/F1) to better represent different aspects of performance. See [Wikipedia](https://en.wikipedia.org/wiki/Precision_and_recall) for more information.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
- [Wikipedia -- Precision and recall](https://en.wikipedia.org/wiki/Precision_and_recall)
| huggingface/datasets/blob/main/metrics/precision/README.md |
Getting Started with the Gradio Python client
Tags: CLIENT, API, SPACES
The Gradio Python client makes it very easy to use any Gradio app as an API. As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.
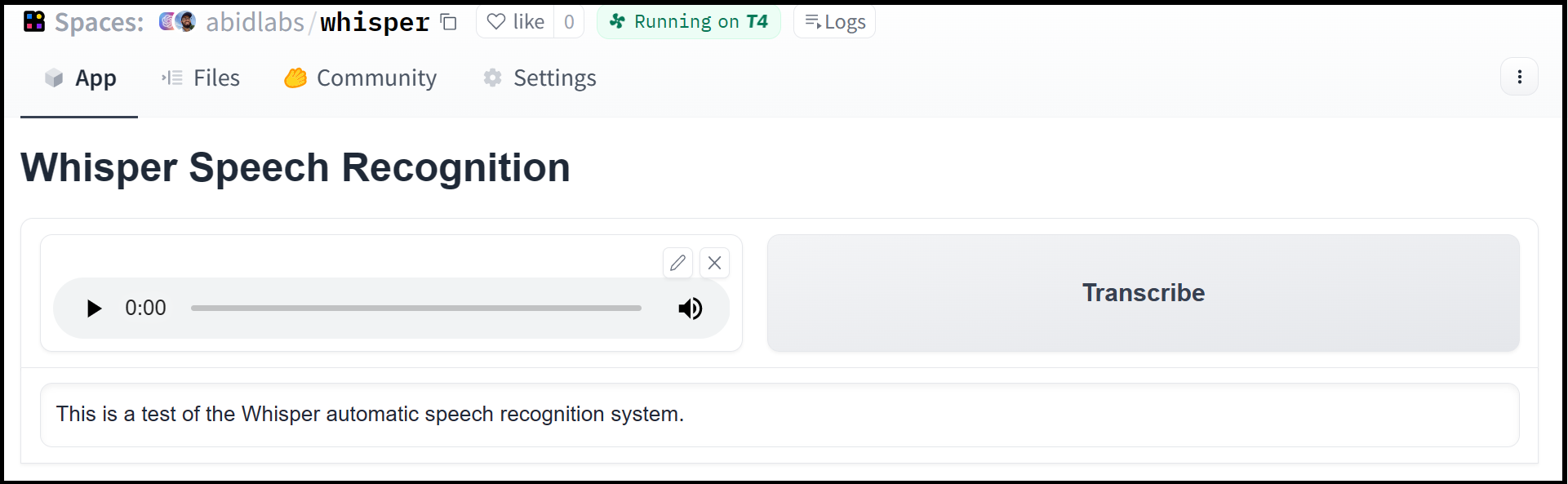
Using the `gradio_client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```python
from gradio_client import Client
client = Client("abidlabs/whisper")
client.predict("audio_sample.wav")
>> "This is a test of the whisper speech recognition model."
```
The Gradio client works with any hosted Gradio app, whether it be an image generator, a text summarizer, a stateful chatbot, a tax calculator, or anything else! The Gradio Client is mostly used with apps hosted on [Hugging Face Spaces](https://hf.space), but your app can be hosted anywhere, such as your own server.
**Prerequisites**: To use the Gradio client, you do _not_ need to know the `gradio` library in great detail. However, it is helpful to have general familiarity with Gradio's concepts of input and output components.
## Installation
If you already have a recent version of `gradio`, then the `gradio_client` is included as a dependency.
Otherwise, the lightweight `gradio_client` package can be installed from pip (or pip3) and is tested to work with Python versions 3.9 or higher:
```bash
$ pip install gradio_client
```
## Connecting to a running Gradio App
Start by connecting instantiating a `Client` object and connecting it to a Gradio app that is running on Hugging Face Spaces or generally anywhere on the web.
## Connecting to a Hugging Face Space
```python
from gradio_client import Client
client = Client("abidlabs/en2fr") # a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `hf_token` parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```python
from gradio_client import Client
client = Client("abidlabs/my-private-space", hf_token="...")
```
## Duplicating a Space for private use
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space,
and then use it to make as many requests as you'd like!
The `gradio_client` includes a class method: `Client.duplicate()` to make this process simple (you'll need to pass in your [Hugging Face token](https://huggingface.co/settings/tokens) or be logged in using the Hugging Face CLI):
```python
import os
from gradio_client import Client
HF_TOKEN = os.environ.get("HF_TOKEN")
client = Client.duplicate("abidlabs/whisper", hf_token=HF_TOKEN)
client.predict("audio_sample.wav")
>> "This is a test of the whisper speech recognition model."
```
If you have previously duplicated a Space, re-running `duplicate()` will _not_ create a new Space. Instead, the Client will attach to the previously-created Space. So it is safe to re-run the `Client.duplicate()` method multiple times.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 1 hour of inactivity. You can also set the hardware using the `hardware` parameter of `duplicate()`.
## Connecting a general Gradio app
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```python
from gradio_client import Client
client = Client("https://bec81a83-5b5c-471e.gradio.live")
```
## Inspecting the API endpoints
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `Client.view_api()` method. For the Whisper Space, we see the following:
```bash
Client.predict() Usage Info
---------------------------
Named API endpoints: 1
- predict(input_audio, api_name="/predict") -> value_0
Parameters:
- [Audio] input_audio: str (filepath or URL)
Returns:
- [Textbox] value_0: str (value)
```
This shows us that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method (which we will explore below), providing a parameter `input_audio` of type `str`, which is a `filepath or URL`.
We should also provide the `api_name='/predict'` argument to the `predict()` method. Although this isn't necessary if a Gradio app has only 1 named endpoint, it does allow us to call different endpoints in a single app if they are available. If an app has unnamed API endpoints, these can also be displayed by running `.view_api(all_endpoints=True)`.
## Making a prediction
The simplest way to make a prediction is simply to call the `.predict()` function with the appropriate arguments:
```python
from gradio_client import Client
client = Client("abidlabs/en2fr", api_name='/predict')
client.predict("Hello")
>> Bonjour
```
If there are multiple parameters, then you should pass them as separate arguments to `.predict()`, like this:
```python
from gradio_client import Client
client = Client("gradio/calculator")
client.predict(4, "add", 5)
>> 9.0
```
For certain inputs, such as images, you should pass in the filepath or URL to the file. Likewise, for the corresponding output types, you will get a filepath or URL returned.
```python
from gradio_client import Client
client = Client("abidlabs/whisper")
client.predict("https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3")
>> "My thought I have nobody by a beauty and will as you poured. Mr. Rochester is serve in that so don't find simpus, and devoted abode, to at might in a r—"
```
## Running jobs asynchronously
Oe should note that `.predict()` is a _blocking_ operation as it waits for the operation to complete before returning the prediction.
In many cases, you may be better off letting the job run in the background until you need the results of the prediction. You can do this by creating a `Job` instance using the `.submit()` method, and then later calling `.result()` on the job to get the result. For example:
```python
from gradio_client import Client
client = Client(space="abidlabs/en2fr")
job = client.submit("Hello", api_name="/predict") # This is not blocking
# Do something else
job.result() # This is blocking
>> Bonjour
```
## Adding callbacks
Alternatively, one can add one or more callbacks to perform actions after the job has completed running, like this:
```python
from gradio_client import Client
def print_result(x):
print("The translated result is: {x}")
client = Client(space="abidlabs/en2fr")
job = client.submit("Hello", api_name="/predict", result_callbacks=[print_result])
# Do something else
>> The translated result is: Bonjour
```
## Status
The `Job` object also allows you to get the status of the running job by calling the `.status()` method. This returns a `StatusUpdate` object with the following attributes: `code` (the status code, one of a set of defined strings representing the status. See the `utils.Status` class), `rank` (the current position of this job in the queue), `queue_size` (the total queue size), `eta` (estimated time this job will complete), `success` (a boolean representing whether the job completed successfully), and `time` (the time that the status was generated).
```py
from gradio_client import Client
client = Client(src="gradio/calculator")
job = client.submit(5, "add", 4, api_name="/predict")
job.status()
>> <Status.STARTING: 'STARTING'>
```
_Note_: The `Job` class also has a `.done()` instance method which returns a boolean indicating whether the job has completed.
## Cancelling Jobs
The `Job` class also has a `.cancel()` instance method that cancels jobs that have been queued but not started. For example, if you run:
```py
client = Client("abidlabs/whisper")
job1 = client.submit("audio_sample1.wav")
job2 = client.submit("audio_sample2.wav")
job1.cancel() # will return False, assuming the job has started
job2.cancel() # will return True, indicating that the job has been canceled
```
If the first job has started processing, then it will not be canceled. If the second job
has not yet started, it will be successfully canceled and removed from the queue.
## Generator Endpoints
Some Gradio API endpoints do not return a single value, rather they return a series of values. You can get the series of values that have been returned at any time from such a generator endpoint by running `job.outputs()`:
```py
from gradio_client import Client
client = Client(src="gradio/count_generator")
job = client.submit(3, api_name="/count")
while not job.done():
time.sleep(0.1)
job.outputs()
>> ['0', '1', '2']
```
Note that running `job.result()` on a generator endpoint only gives you the _first_ value returned by the endpoint.
The `Job` object is also iterable, which means you can use it to display the results of a generator function as they are returned from the endpoint. Here's the equivalent example using the `Job` as a generator:
```py
from gradio_client import Client
client = Client(src="gradio/count_generator")
job = client.submit(3, api_name="/count")
for o in job:
print(o)
>> 0
>> 1
>> 2
```
You can also cancel jobs that that have iterative outputs, in which case the job will finish as soon as the current iteration finishes running.
```py
from gradio_client import Client
import time
client = Client("abidlabs/test-yield")
job = client.submit("abcdef")
time.sleep(3)
job.cancel() # job cancels after 2 iterations
```
| gradio-app/gradio/blob/main/guides/08_gradio-clients-and-lite/01_getting-started-with-the-python-client.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# The Transformer model family
Since its introduction in 2017, the [original Transformer](https://arxiv.org/abs/1706.03762) model has inspired many new and exciting models that extend beyond natural language processing (NLP) tasks. There are models for [predicting the folded structure of proteins](https://huggingface.co/blog/deep-learning-with-proteins), [training a cheetah to run](https://huggingface.co/blog/train-decision-transformers), and [time series forecasting](https://huggingface.co/blog/time-series-transformers). With so many Transformer variants available, it can be easy to miss the bigger picture. What all these models have in common is they're based on the original Transformer architecture. Some models only use the encoder or decoder, while others use both. This provides a useful taxonomy to categorize and examine the high-level differences within models in the Transformer family, and it'll help you understand Transformers you haven't encountered before.
If you aren't familiar with the original Transformer model or need a refresher, check out the [How do Transformers work](https://huggingface.co/course/chapter1/4?fw=pt) chapter from the Hugging Face course.
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/H39Z_720T5s" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
</div>
## Computer vision
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FacQBpeFBVvrDUlzFlkejoz%2FModelscape-timeline%3Fnode-id%3D0%253A1%26t%3Dm0zJ7m2BQ9oe0WtO-1" allowfullscreen></iframe>
### Convolutional network
For a long time, convolutional networks (CNNs) were the dominant paradigm for computer vision tasks until the [Vision Transformer](https://arxiv.org/abs/2010.11929) demonstrated its scalability and efficiency. Even then, some of a CNN's best qualities, like translation invariance, are so powerful (especially for certain tasks) that some Transformers incorporate convolutions in their architecture. [ConvNeXt](model_doc/convnext) flipped this exchange around and incorporated design choices from Transformers to modernize a CNN. For example, ConvNeXt uses non-overlapping sliding windows to patchify an image and a larger kernel to increase its global receptive field. ConvNeXt also makes several layer design choices to be more memory-efficient and improve performance, so it competes favorably with Transformers!
### Encoder[[cv-encoder]]
The [Vision Transformer (ViT)](model_doc/vit) opened the door to computer vision tasks without convolutions. ViT uses a standard Transformer encoder, but its main breakthrough was how it treated an image. It splits an image into fixed-size patches and uses them to create an embedding, just like how a sentence is split into tokens. ViT capitalized on the Transformers' efficient architecture to demonstrate competitive results with the CNNs at the time while requiring fewer resources to train. ViT was soon followed by other vision models that could also handle dense vision tasks like segmentation as well as detection.
One of these models is the [Swin](model_doc/swin) Transformer. It builds hierarchical feature maps (like a CNN 👀 and unlike ViT) from smaller-sized patches and merges them with neighboring patches in deeper layers. Attention is only computed within a local window, and the window is shifted between attention layers to create connections to help the model learn better. Since the Swin Transformer can produce hierarchical feature maps, it is a good candidate for dense prediction tasks like segmentation and detection. The [SegFormer](model_doc/segformer) also uses a Transformer encoder to build hierarchical feature maps, but it adds a simple multilayer perceptron (MLP) decoder on top to combine all the feature maps and make a prediction.
Other vision models, like BeIT and ViTMAE, drew inspiration from BERT's pretraining objective. [BeIT](model_doc/beit) is pretrained by *masked image modeling (MIM)*; the image patches are randomly masked, and the image is also tokenized into visual tokens. BeIT is trained to predict the visual tokens corresponding to the masked patches. [ViTMAE](model_doc/vitmae) has a similar pretraining objective, except it must predict the pixels instead of visual tokens. What's unusual is 75% of the image patches are masked! The decoder reconstructs the pixels from the masked tokens and encoded patches. After pretraining, the decoder is thrown away, and the encoder is ready to be used in downstream tasks.
### Decoder[[cv-decoder]]
Decoder-only vision models are rare because most vision models rely on an encoder to learn an image representation. But for use cases like image generation, the decoder is a natural fit, as we've seen from text generation models like GPT-2. [ImageGPT](model_doc/imagegpt) uses the same architecture as GPT-2, but instead of predicting the next token in a sequence, it predicts the next pixel in an image. In addition to image generation, ImageGPT could also be finetuned for image classification.
### Encoder-decoder[[cv-encoder-decoder]]
Vision models commonly use an encoder (also known as a backbone) to extract important image features before passing them to a Transformer decoder. [DETR](model_doc/detr) has a pretrained backbone, but it also uses the complete Transformer encoder-decoder architecture for object detection. The encoder learns image representations and combines them with object queries (each object query is a learned embedding that focuses on a region or object in an image) in the decoder. DETR predicts the bounding box coordinates and class label for each object query.
## Natural language processing
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FUhbQAZDlpYW5XEpdFy6GoG%2Fnlp-model-timeline%3Fnode-id%3D0%253A1%26t%3D4mZMr4r1vDEYGJ50-1" allowfullscreen></iframe>
### Encoder[[nlp-encoder]]
[BERT](model_doc/bert) is an encoder-only Transformer that randomly masks certain tokens in the input to avoid seeing other tokens, which would allow it to "cheat". The pretraining objective is to predict the masked token based on the context. This allows BERT to fully use the left and right contexts to help it learn a deeper and richer representation of the inputs. However, there was still room for improvement in BERT's pretraining strategy. [RoBERTa](model_doc/roberta) improved upon this by introducing a new pretraining recipe that includes training for longer and on larger batches, randomly masking tokens at each epoch instead of just once during preprocessing, and removing the next-sentence prediction objective.
The dominant strategy to improve performance is to increase the model size. But training large models is computationally expensive. One way to reduce computational costs is using a smaller model like [DistilBERT](model_doc/distilbert). DistilBERT uses [knowledge distillation](https://arxiv.org/abs/1503.02531) - a compression technique - to create a smaller version of BERT while keeping nearly all of its language understanding capabilities.
However, most Transformer models continued to trend towards more parameters, leading to new models focused on improving training efficiency. [ALBERT](model_doc/albert) reduces memory consumption by lowering the number of parameters in two ways: separating the larger vocabulary embedding into two smaller matrices and allowing layers to share parameters. [DeBERTa](model_doc/deberta) added a disentangled attention mechanism where the word and its position are separately encoded in two vectors. The attention is computed from these separate vectors instead of a single vector containing the word and position embeddings. [Longformer](model_doc/longformer) also focused on making attention more efficient, especially for processing documents with longer sequence lengths. It uses a combination of local windowed attention (attention only calculated from fixed window size around each token) and global attention (only for specific task tokens like `[CLS]` for classification) to create a sparse attention matrix instead of a full attention matrix.
### Decoder[[nlp-decoder]]
[GPT-2](model_doc/gpt2) is a decoder-only Transformer that predicts the next word in the sequence. It masks tokens to the right so the model can't "cheat" by looking ahead. By pretraining on a massive body of text, GPT-2 became really good at generating text, even if the text is only sometimes accurate or true. But GPT-2 lacked the bidirectional context from BERT's pretraining, which made it unsuitable for certain tasks. [XLNET](model_doc/xlnet) combines the best of both BERT and GPT-2's pretraining objectives by using a permutation language modeling objective (PLM) that allows it to learn bidirectionally.
After GPT-2, language models grew even bigger and are now known as *large language models (LLMs)*. LLMs demonstrate few- or even zero-shot learning if pretrained on a large enough dataset. [GPT-J](model_doc/gptj) is an LLM with 6B parameters and trained on 400B tokens. GPT-J was followed by [OPT](model_doc/opt), a family of decoder-only models, the largest of which is 175B and trained on 180B tokens. [BLOOM](model_doc/bloom) was released around the same time, and the largest model in the family has 176B parameters and is trained on 366B tokens in 46 languages and 13 programming languages.
### Encoder-decoder[[nlp-encoder-decoder]]
[BART](model_doc/bart) keeps the original Transformer architecture, but it modifies the pretraining objective with *text infilling* corruption, where some text spans are replaced with a single `mask` token. The decoder predicts the uncorrupted tokens (future tokens are masked) and uses the encoder's hidden states to help it. [Pegasus](model_doc/pegasus) is similar to BART, but Pegasus masks entire sentences instead of text spans. In addition to masked language modeling, Pegasus is pretrained by gap sentence generation (GSG). The GSG objective masks whole sentences important to a document, replacing them with a `mask` token. The decoder must generate the output from the remaining sentences. [T5](model_doc/t5) is a more unique model that casts all NLP tasks into a text-to-text problem using specific prefixes. For example, the prefix `Summarize:` indicates a summarization task. T5 is pretrained by supervised (GLUE and SuperGLUE) training and self-supervised training (randomly sample and drop out 15% of tokens).
## Audio
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2Fvrchl8jDV9YwNVPWu2W0kK%2Fspeech-and-audio-model-timeline%3Fnode-id%3D0%253A1%26t%3DmM4H8pPMuK23rClL-1" allowfullscreen></iframe>
### Encoder[[audio-encoder]]
[Wav2Vec2](model_doc/wav2vec2) uses a Transformer encoder to learn speech representations directly from raw audio waveforms. It is pretrained with a contrastive task to determine the true speech representation from a set of false ones. [HuBERT](model_doc/hubert) is similar to Wav2Vec2 but has a different training process. Target labels are created by a clustering step in which segments of similar audio are assigned to a cluster which becomes a hidden unit. The hidden unit is mapped to an embedding to make a prediction.
### Encoder-decoder[[audio-encoder-decoder]]
[Speech2Text](model_doc/speech_to_text) is a speech model designed for automatic speech recognition (ASR) and speech translation. The model accepts log mel-filter bank features extracted from the audio waveform and pretrained autoregressively to generate a transcript or translation. [Whisper](model_doc/whisper) is also an ASR model, but unlike many other speech models, it is pretrained on a massive amount of ✨ labeled ✨ audio transcription data for zero-shot performance. A large chunk of the dataset also contains non-English languages, meaning Whisper can also be used for low-resource languages. Structurally, Whisper is similar to Speech2Text. The audio signal is converted to a log-mel spectrogram encoded by the encoder. The decoder generates the transcript autoregressively from the encoder's hidden states and the previous tokens.
## Multimodal
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FcX125FQHXJS2gxeICiY93p%2Fmultimodal%3Fnode-id%3D0%253A1%26t%3DhPQwdx3HFPWJWnVf-1" allowfullscreen></iframe>
### Encoder[[mm-encoder]]
[VisualBERT](model_doc/visual_bert) is a multimodal model for vision-language tasks released shortly after BERT. It combines BERT and a pretrained object detection system to extract image features into visual embeddings, passed alongside text embeddings to BERT. VisualBERT predicts the masked text based on the unmasked text and the visual embeddings, and it also has to predict whether the text is aligned with the image. When ViT was released, [ViLT](model_doc/vilt) adopted ViT in its architecture because it was easier to get the image embeddings this way. The image embeddings are jointly processed with the text embeddings. From there, ViLT is pretrained by image text matching, masked language modeling, and whole word masking.
[CLIP](model_doc/clip) takes a different approach and makes a pair prediction of (`image`, `text`) . An image encoder (ViT) and a text encoder (Transformer) are jointly trained on a 400 million (`image`, `text`) pair dataset to maximize the similarity between the image and text embeddings of the (`image`, `text`) pairs. After pretraining, you can use natural language to instruct CLIP to predict the text given an image or vice versa. [OWL-ViT](model_doc/owlvit) builds on top of CLIP by using it as its backbone for zero-shot object detection. After pretraining, an object detection head is added to make a set prediction over the (`class`, `bounding box`) pairs.
### Encoder-decoder[[mm-encoder-decoder]]
Optical character recognition (OCR) is a long-standing text recognition task that typically involves several components to understand the image and generate the text. [TrOCR](model_doc/trocr) simplifies the process using an end-to-end Transformer. The encoder is a ViT-style model for image understanding and processes the image as fixed-size patches. The decoder accepts the encoder's hidden states and autoregressively generates text. [Donut](model_doc/donut) is a more general visual document understanding model that doesn't rely on OCR-based approaches. It uses a Swin Transformer as the encoder and multilingual BART as the decoder. Donut is pretrained to read text by predicting the next word based on the image and text annotations. The decoder generates a token sequence given a prompt. The prompt is represented by a special token for each downstream task. For example, document parsing has a special `parsing` token that is combined with the encoder hidden states to parse the document into a structured output format (JSON).
## Reinforcement learning
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FiB3Y6RvWYki7ZuKO6tNgZq%2Freinforcement-learning%3Fnode-id%3D0%253A1%26t%3DhPQwdx3HFPWJWnVf-1" allowfullscreen></iframe>
### Decoder[[rl-decoder]]
The Decision and Trajectory Transformer casts the state, action, and reward as a sequence modeling problem. The [Decision Transformer](model_doc/decision_transformer) generates a series of actions that lead to a future desired return based on returns-to-go, past states, and actions. For the last *K* timesteps, each of the three modalities are converted into token embeddings and processed by a GPT-like model to predict a future action token. [Trajectory Transformer](model_doc/trajectory_transformer) also tokenizes the states, actions, and rewards and processes them with a GPT architecture. Unlike the Decision Transformer, which is focused on reward conditioning, the Trajectory Transformer generates future actions with beam search. | huggingface/transformers/blob/main/docs/source/en/model_summary.md |
Load tabular data
A tabular dataset is a generic dataset used to describe any data stored in rows and columns, where the rows represent an example and the columns represent a feature (can be continuous or categorical). These datasets are commonly stored in CSV files, Pandas DataFrames, and in database tables. This guide will show you how to load and create a tabular dataset from:
- CSV files
- Pandas DataFrames
- Databases
## CSV files
🤗 Datasets can read CSV files by specifying the generic `csv` dataset builder name in the [`~datasets.load_dataset`] method. To load more than one CSV file, pass them as a list to the `data_files` parameter:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("csv", data_files="my_file.csv")
# load multiple CSV files
>>> dataset = load_dataset("csv", data_files=["my_file_1.csv", "my_file_2.csv", "my_file_3.csv"])
```
You can also map specific CSV files to the train and test splits:
```py
>>> dataset = load_dataset("csv", data_files={"train": ["my_train_file_1.csv", "my_train_file_2.csv"], "test": "my_test_file.csv"})
```
To load remote CSV files, pass the URLs instead:
```py
>>> base_url = "https://huggingface.co/datasets/lhoestq/demo1/resolve/main/data/"
>>> dataset = load_dataset('csv', data_files={"train": base_url + "train.csv", "test": base_url + "test.csv"})
```
To load zipped CSV files:
```py
>>> url = "https://domain.org/train_data.zip"
>>> data_files = {"train": url}
>>> dataset = load_dataset("csv", data_files=data_files)
```
## Pandas DataFrames
🤗 Datasets also supports loading datasets from [Pandas DataFrames](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html) with the [`~datasets.Dataset.from_pandas`] method:
```py
>>> from datasets import Dataset
>>> import pandas as pd
# create a Pandas DataFrame
>>> df = pd.read_csv("https://huggingface.co/datasets/imodels/credit-card/raw/main/train.csv")
>>> df = pd.DataFrame(df)
# load Dataset from Pandas DataFrame
>>> dataset = Dataset.from_pandas(df)
```
Use the `splits` parameter to specify the name of the dataset split:
```py
>>> train_ds = Dataset.from_pandas(train_df, split="train")
>>> test_ds = Dataset.from_pandas(test_df, split="test")
```
If the dataset doesn't look as expected, you should explicitly [specify your dataset features](loading#specify-features). A [pandas.Series](https://pandas.pydata.org/docs/reference/api/pandas.Series.html) may not always carry enough information for Arrow to automatically infer a data type. For example, if a DataFrame is of length `0` or if the Series only contains `None/NaN` objects, the type is set to `null`.
## Databases
Datasets stored in databases are typically accessed with SQL queries. With 🤗 Datasets, you can connect to a database, query for the data you need, and create a dataset out of it. Then you can use all the processing features of 🤗 Datasets to prepare your dataset for training.
### SQLite
SQLite is a small, lightweight database that is fast and easy to set up. You can use an existing database if you'd like, or follow along and start from scratch.
Start by creating a quick SQLite database with this [Covid-19 data](https://github.com/nytimes/covid-19-data/blob/master/us-states.csv) from the New York Times:
```py
>>> import sqlite3
>>> import pandas as pd
>>> conn = sqlite3.connect("us_covid_data.db")
>>> df = pd.read_csv("https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-states.csv")
>>> df.to_sql("states", conn, if_exists="replace")
```
This creates a `states` table in the `us_covid_data.db` database which you can now load into a dataset.
To connect to the database, you'll need the [URI string](https://docs.sqlalchemy.org/en/13/core/engines.html#database-urls) that identifies your database. Connecting to a database with a URI caches the returned dataset. The URI string differs for each database dialect, so be sure to check the [Database URLs](https://docs.sqlalchemy.org/en/13/core/engines.html#database-urls) for whichever database you're using.
For SQLite, it is:
```py
>>> uri = "sqlite:///us_covid_data.db"
```
Load the table by passing the table name and URI to [`~datasets.Dataset.from_sql`]:
```py
>>> from datasets import Dataset
>>> ds = Dataset.from_sql("states", uri)
>>> ds
Dataset({
features: ['index', 'date', 'state', 'fips', 'cases', 'deaths'],
num_rows: 54382
})
```
Then you can use all of 🤗 Datasets process features like [`~datasets.Dataset.filter`] for example:
```py
>>> ds.filter(lambda x: x["state"] == "California")
```
You can also load a dataset from a SQL query instead of an entire table, which is useful for querying and joining multiple tables.
Load the dataset by passing your query and URI to [`~datasets.Dataset.from_sql`]:
```py
>>> from datasets import Dataset
>>> ds = Dataset.from_sql('SELECT * FROM states WHERE state="California";', uri)
>>> ds
Dataset({
features: ['index', 'date', 'state', 'fips', 'cases', 'deaths'],
num_rows: 1019
})
```
Then you can use all of 🤗 Datasets process features like [`~datasets.Dataset.filter`] for example:
```py
>>> ds.filter(lambda x: x["cases"] > 10000)
```
### PostgreSQL
You can also connect and load a dataset from a PostgreSQL database, however we won't directly demonstrate how in the documentation because the example is only meant to be run in a notebook. Instead, take a look at how to install and setup a PostgreSQL server in this [notebook](https://colab.research.google.com/github/nateraw/huggingface-hub-examples/blob/main/sql_with_huggingface_datasets.ipynb#scrollTo=d83yGQMPHGFi)!
After you've setup your PostgreSQL database, you can use the [`~datasets.Dataset.from_sql`] method to load a dataset from a table or query. | huggingface/datasets/blob/main/docs/source/tabular_load.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Super-resolution
The Stable Diffusion upscaler diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/). It is used to enhance the resolution of input images by a factor of 4.
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## StableDiffusionUpscalePipeline
[[autodoc]] StableDiffusionUpscalePipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/upscale.md |
Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
feedback@huggingface.co.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
[https://www.contributor-covenant.org/version/2/0/code_of_conduct.html][v2.0].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available
at [https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.0]: https://www.contributor-covenant.org/version/2/0/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
| huggingface/evaluate/blob/main/CODE_OF_CONDUCT.md |
# Unity Integration
### Install with the Unity editor
Currently we use Unity version `2021.3.2f1` as the development version.
To install and run the project in Unity:
- First install Unity `2021.3.2f1` using the Unity Hub if you don't have it.
- From the Unity Hub, open the project at `./integrations/Unity/simulate-unity`
- Open the Sample Scene or create a new scene with an empty GameObject with a `Client.cs` component attached
(Note that installation of this specific version on Apple Silicon Mac's has been tricky -- to do so, first install Unity Hub, then download the [source](https://unity3d.com/get-unity/download/archive) package from Unity directly, then install the package.
It is easiest to do this from a fresh Unity install; detecting the second from-source Unity editor version is more challenging.)
### Run with the Unity engine
1. If it's not already opened, open the Unity project with Scene with a GameObject with a `Client.cs` component attached.
2. Create the `simulate` scene with a `'Unity'` engine, for example:
```
import simulate as sm
scene = sm.Scene(engine="unity")
scene += sm.Sphere()
scene.render()
```
3. Run the python script. It should print "Waiting for connection...", meaning that it has spawned a websocket server, and is waiting for a connection from the Unity client.
4. Press Play in Unity. It should connect to the Python client, then display a basic Sphere. The python script should finish execution.
### Creating Custom Functionality
Communication with the backend is through JSON messages over a socket connection. A socket command has the following format:
```
{
"type": "MyCommand",
"contents": json.dumps({
"message": "hello from python API"
})
}
```
The `type` and `contents` dict is a wrapper around each command. The internal contents of the command are an embedded JSON string in `contents`.
The above example will only work if `MyCommand` is implemented in the backend. To implement this in the backend, add the following script in the Unity project:
```
using UnityEngine.Events;
using Simulate;
public class MyCommand : Command {
public string message;
public override void Execute(UnityAction<string> callback) {
Debug.Log(message);
callback("{}");
}
}
```
Simply adding the script to the project should be sufficient to make it work. Any public fields defined in a `Command` can be passed through your `contents` JSON. Only simple types (i.e. `int`, `float`, `string`) and arrays are supported, not Lists, Vector3, etc., since it uses Unity's built-in JSON serialization. You need to serialize/deserialize these yourself.
### Colliders Extension
The HF_colliders extension is based loosely on the PANDA3D_physics_collision_shapes extension: https://github.com/Moguri/glTF/tree/panda3d_physics_collision_shapes/extensions/2.0/Vendor/PANDA3D_collision_shapes
This extension is defined both at the scene-level (storing the colliders) and the node-level (storing pointers to the colliders). For example, a node with a box collider:
```
{
"extensions": {
"HF_colliders": {
collider: {
"type": "BOX",
"boundingBox": [
0.5,
0.5,
0.5
]
}
}
}
}
```
This currently only supports Box, Sphere, and Capsule colliders (the Unity/PhysX colliders).
Differences from the PANDA3D extension:
- Properties `group` and `mask` are removed, since layer interactions are defined engine-wide, not per-object, in Unity. Layer interaction will need to be defined a different way if added, or throw an error if there are conflicting layer interactions per-object.
- `Intangible` moved from outer class to shape class, because there can be a mix of intangible and tangible colliders on an object.
- Removed redundant features (offset rotation, scale, matrix, axis) that can be represented through other properties.
- Removed support for multiple shapes. Multiple collision shapes can be equivalently represented with child nodes.
Collider TODOs:
- Add mesh collider support.
- Add support for other collider shapes, i.e. bullet has cylinders and cones. This isn't natively in Unity/PhysX, but could be approximated on import.
| huggingface/simulate/blob/main/integrations/Unity/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Load adapters with 🤗 PEFT
[[open-in-colab]]
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it. The adapters are trained to learn task-specific information. This approach has been shown to be very memory-efficient with lower compute usage while producing results comparable to a fully fine-tuned model.
Adapters trained with PEFT are also usually an order of magnitude smaller than the full model, making it convenient to share, store, and load them.
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">The adapter weights for a OPTForCausalLM model stored on the Hub are only ~6MB compared to the full size of the model weights, which can be ~700MB.</figcaption>
</div>
If you're interested in learning more about the 🤗 PEFT library, check out the [documentation](https://huggingface.co/docs/peft/index).
## Setup
Get started by installing 🤗 PEFT:
```bash
pip install peft
```
If you want to try out the brand new features, you might be interested in installing the library from source:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## Supported PEFT models
🤗 Transformers natively supports some PEFT methods, meaning you can load adapter weights stored locally or on the Hub and easily run or train them with a few lines of code. The following methods are supported:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
If you want to use other PEFT methods, such as prompt learning or prompt tuning, or about the 🤗 PEFT library in general, please refer to the [documentation](https://huggingface.co/docs/peft/index).
## Load a PEFT adapter
To load and use a PEFT adapter model from 🤗 Transformers, make sure the Hub repository or local directory contains an `adapter_config.json` file and the adapter weights, as shown in the example image above. Then you can load the PEFT adapter model using the `AutoModelFor` class. For example, to load a PEFT adapter model for causal language modeling:
1. specify the PEFT model id
2. pass it to the [`AutoModelForCausalLM`] class
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
You can load a PEFT adapter with either an `AutoModelFor` class or the base model class like `OPTForCausalLM` or `LlamaForCausalLM`.
</Tip>
You can also load a PEFT adapter by calling the `load_adapter` method:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
## Load in 8bit or 4bit
The `bitsandbytes` integration supports 8bit and 4bit precision data types, which are useful for loading large models because it saves memory (see the `bitsandbytes` integration [guide](./quantization#bitsandbytes-integration) to learn more). Add the `load_in_8bit` or `load_in_4bit` parameters to [`~PreTrainedModel.from_pretrained`] and set `device_map="auto"` to effectively distribute the model to your hardware:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
```
## Add a new adapter
You can use [`~peft.PeftModel.add_adapter`] to add a new adapter to a model with an existing adapter as long as the new adapter is the same type as the current one. For example, if you have an existing LoRA adapter attached to a model:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
To add a new adapter:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
Now you can use [`~peft.PeftModel.set_adapter`] to set which adapter to use:
```py
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## Enable and disable adapters
Once you've added an adapter to a model, you can enable or disable the adapter module. To enable the adapter module:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
To disable the adapter module:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## Train a PEFT adapter
PEFT adapters are supported by the [`Trainer`] class so that you can train an adapter for your specific use case. It only requires adding a few more lines of code. For example, to train a LoRA adapter:
<Tip>
If you aren't familiar with fine-tuning a model with [`Trainer`], take a look at the [Fine-tune a pretrained model](training) tutorial.
</Tip>
1. Define your adapter configuration with the task type and hyperparameters (see [`~peft.LoraConfig`] for more details about what the hyperparameters do).
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
```
2. Add adapter to the model.
```py
model.add_adapter(peft_config)
```
3. Now you can pass the model to [`Trainer`]!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
To save your trained adapter and load it back:
```py
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
```
## Add additional trainable layers to a PEFT adapter
You can also fine-tune additional trainable adapters on top of a model that has adapters attached by passing `modules_to_save` in your PEFT config. For example, if you want to also fine-tune the lm_head on top of a model with a LoRA adapter:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
modules_to_save=["lm_head"],
)
model.add_adapter(lora_config)
```
<!--
TODO: (@younesbelkada @stevhliu)
- Link to PEFT docs for further details
- Trainer
- 8-bit / 4-bit examples ?
-->
| huggingface/transformers/blob/main/docs/source/en/peft.md |
Frequently Asked Questions
## What do I need to install before using Custom Components?
Before using Custom Components, make sure you have Python 3.8+, Node.js v16.14+, npm 9+, and Gradio 4.0+ installed.
## What templates can I use to create my custom component?
Run `gradio cc show` to see the list of built-in templates.
You can also start off from other's custom components!
Simply `git clone` their repository and make your modifications.
## What is the development server?
When you run `gradio cc dev`, a development server will load and run a Gradio app of your choosing.
This is like when you run `python <app-file>.py`, however the `gradio` command will hot reload so you can instantly see your changes.
## The development server didn't work for me
Make sure you have your package installed along with any dependencies you have added by running `gradio cc install`.
Make sure there aren't any syntax or import errors in the Python or JavaScript code.
## Do I need to host my custom component on HuggingFace Spaces?
You can develop and build your custom component without hosting or connecting to HuggingFace.
If you would like to share your component with the gradio community, it is recommended to publish your package to PyPi and host a demo on HuggingFace so that anyone can install it or try it out.
## What methods are mandatory for implementing a custom component in Gradio?
You must implement the `preprocess`, `postprocess`, `as_example`, `api_info`, `example_inputs`, `flag`, and `read_from_flag` methods. Read more in the [backend guide](./backend).
## What is the purpose of a `data_model` in Gradio custom components?
A `data_model` defines the expected data format for your component, simplifying the component development process and self-documenting your code. It streamlines API usage and example caching.
## Why is it important to use `FileData` for components dealing with file uploads?
Utilizing `FileData` is crucial for components that expect file uploads. It ensures secure file handling, automatic caching, and streamlined client library functionality.
## How can I add event triggers to my custom Gradio component?
You can define event triggers in the `EVENTS` class attribute by listing the desired event names, which automatically adds corresponding methods to your component.
## Can I implement a custom Gradio component without defining a `data_model`?
Yes, it is possible to create custom components without a `data_model`, but you are going to have to manually implement `api_info`, `example_inputs`, `flag`, and `read_from_flag` methods.
## Are there sample custom components I can learn from?
We have prepared this [collection](https://huggingface.co/collections/gradio/custom-components-65497a761c5192d981710b12) of custom components on the HuggingFace Hub that you can use to get started!
## How can I find custom components created by the Gradio community?
We're working on creating a gallery to make it really easy to discover new custom components.
In the meantime, you can search for HuggingFace Spaces that are tagged as a `gradio-custom-component` [here](https://huggingface.co/search/full-text?q=gradio-custom-component&type=space) | gradio-app/gradio/blob/main/guides/05_custom-components/06_frequently-asked-questions.md |
Part 2 Release Event[[part-2-release-event]]
For the release of part 2 of the course, we organized a live event with two days of talks before a fine-tuning sprint. If you missed it, you can catch up with the talks which are all listed below!
## Day 1: A high-level view of Transformers and how to train them[[day-1-a-high-level-view-of-transformers-and-how-to-train-them]]
**Thomas Wolf:** *Transfer Learning and the birth of the Transformers library*
<div class="flex justify-center">
<Youtube id="wCYVeahJES0"/>
</div>
<p align="center">
<img src="https://i.imgur.com/9eq8oUi.png" alt="A visual summary of Thom's talk" width="80%"/>
</p>
Thomas Wolf is co-founder and Chief Science Officer of Hugging Face. The tools created by Thomas Wolf and the Hugging Face team are used across more than 5,000 research organisations including Facebook Artificial Intelligence Research, Google Research, DeepMind, Amazon Research, Apple, the Allen Institute for Artificial Intelligence as well as most university departments. Thomas Wolf is the initiator and senior chair of the largest research collaboration that has ever existed in Artificial Intelligence: [“BigScience”](https://bigscience.huggingface.co), as well as a set of widely used [libraries and tools](https://github.com/huggingface/). Thomas Wolf is also a prolific educator, a thought leader in the field of Artificial Intelligence and Natural Language Processing, and a regular invited speaker to conferences all around the world [https://thomwolf.io](https://thomwolf.io).
**Jay Alammar:** *A gentle visual intro to Transformers models*
<div class="flex justify-center">
<Youtube id="VzvG23gmcYU"/>
</div>
<p align="center">
<img src="https://i.imgur.com/rOZAuE9.png" alt="A visual summary of Jay's talk" width="80%"/>
</p>
Through his popular ML blog, Jay has helped millions of researchers and engineers visually understand machine learning tools and concepts from the basic (ending up in NumPy, Pandas docs) to the cutting-edge (Transformers, BERT, GPT-3).
**Margaret Mitchell:** *On Values in ML Development*
<div class="flex justify-center">
<Youtube id="8j9HRMjh_s8"/>
</div>
<p align="center">
<img src="https://i.imgur.com/NuIsnY3.png" alt="A visual summary of Margaret's talk" width="80%"/>
</p>
Margaret Mitchell is a researcher working on Ethical AI, currently focused on the ins and outs of ethics-informed AI development in tech. She has published over 50 papers on natural language generation, assistive technology, computer vision, and AI ethics, and holds multiple patents in the areas of conversation generation and sentiment classification. She previously worked at Google AI as a Staff Research Scientist, where she founded and co-led Google's Ethical AI group, focused on foundational AI ethics research and operationalizing AI ethics Google-internally. Before joining Google, she was a researcher at Microsoft Research, focused on computer vision-to-language generation; and was a postdoc at Johns Hopkins, focused on Bayesian modeling and information extraction. She holds a PhD in Computer Science from the University of Aberdeen and a Master's in computational linguistics from the University of Washington. While earning her degrees, she also worked from 2005-2012 on machine learning, neurological disorders, and assistive technology at Oregon Health and Science University. She has spearheaded a number of workshops and initiatives at the intersections of diversity, inclusion, computer science, and ethics. Her work has received awards from Secretary of Defense Ash Carter and the American Foundation for the Blind, and has been implemented by multiple technology companies. She likes gardening, dogs, and cats.
**Matthew Watson and Chen Qian:** *NLP workflows with Keras*
<div class="flex justify-center">
<Youtube id="gZIP-_2XYMM"/>
</div>
<p align="center">
<img src="https://i.imgur.com/1vD2az8.png" alt="A visual summary of Matt and Chen's talk" width="80%"/>
</p>
Matthew Watson is a machine learning engineer on the Keras team, with a focus on high-level modeling APIs. He studied Computer Graphics during undergrad and a Masters at Stanford University. An almost English major who turned towards computer science, he is passionate about working across disciplines and making NLP accessible to a wider audience.
Chen Qian is a software engineer from Keras team, with a focus on high-level modeling APIs. Chen got a Master degree of Electrical Engineering from Stanford University, and he is especially interested in simplifying code implementations of ML tasks and large-scale ML.
**Mark Saroufim:** *How to Train a Model with Pytorch*
<div class="flex justify-center">
<Youtube id="KmvPlW2cbIo"/>
</div>
<p align="center">
<img src="https://i.imgur.com/TPmlkm8.png" alt="A visual summary of Mark's talk" width="80%"/>
</p>
Mark Saroufim is a Partner Engineer at Pytorch working on OSS production tools including TorchServe and Pytorch Enterprise. In his past lives, Mark was an Applied Scientist and Product Manager at Graphcore, [yuri.ai](http://yuri.ai/), Microsoft and NASA's JPL. His primary passion is to make programming more fun.
**Jakob Uszkoreit:** *It Ain't Broke So <del>Don't Fix</del> Let's Break It*
<div class="flex justify-center">
<Youtube id="C6jweXYFHSA"/>
</div>
<p align="center">
<img src="https://i.imgur.com/5dWQeNB.png" alt="A visual summary of Jakob's talk" width="80%"/>
</p>
Jakob Uszkoreit is the co-founder of Inceptive. Inceptive designs RNA molecules for vaccines and therapeutics using large-scale deep learning in a tight loop with high throughput experiments with the goal of making RNA-based medicines more accessible, more effective and more broadly applicable. Previously, Jakob worked at Google for more than a decade, leading research and development teams in Google Brain, Research and Search working on deep learning fundamentals, computer vision, language understanding and machine translation.
## Day 2: The tools to use[[day-2-the-tools-to-use]]
**Lewis Tunstall:** *Simple Training with the 🤗 Transformers Trainer*
<div class="flex justify-center">
<Youtube id="u--UVvH-LIQ"/>
</div>
Lewis is a machine learning engineer at Hugging Face, focused on developing open-source tools and making them accessible to the wider community. He is also a co-author of the O’Reilly book [Natural Language Processing with Transformers](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/). You can follow him on Twitter (@_lewtun) for NLP tips and tricks!
**Matthew Carrigan:** *New TensorFlow Features for 🤗 Transformers and 🤗 Datasets*
<div class="flex justify-center">
<Youtube id="gQUlXp1691w"/>
</div>
Matt is responsible for TensorFlow maintenance at Transformers, and will eventually lead a coup against the incumbent PyTorch faction which will likely be co-ordinated via his Twitter account @carrigmat.
**Lysandre Debut:** *The Hugging Face Hub as a means to collaborate on and share Machine Learning projects*
<div class="flex justify-center">
<Youtube id="RBw1TmdEZp0"/>
</div>
<p align="center">
<img src="https://i.imgur.com/TarIPCz.png" alt="A visual summary of Lysandre's talk" width="80%"/>
</p>
Lysandre is a Machine Learning Engineer at Hugging Face where he is involved in many open source projects. His aim is to make Machine Learning accessible to everyone by developing powerful tools with a very simple API.
**Lucile Saulnier:** *Get your own tokenizer with 🤗 Transformers & 🤗 Tokenizers*
<div class="flex justify-center">
<Youtube id="UkNmyTFKriI"/>
</div>
Lucile is a machine learning engineer at Hugging Face, developing and supporting the use of open source tools. She is also actively involved in many research projects in the field of Natural Language Processing such as collaborative training and BigScience.
**Sylvain Gugger:** *Supercharge your PyTorch training loop with 🤗 Accelerate*
<div class="flex justify-center">
<Youtube id="t8Krzu-nSeY"/>
</div>
Sylvain is a Research Engineer at Hugging Face and one of the core maintainers of 🤗 Transformers and the developer behind 🤗 Accelerate. He likes making model training more accessible.
**Merve Noyan:** *Showcase your model demos with 🤗 Spaces*
<div class="flex justify-center">
<Youtube id="vbaKOa4UXoM"/>
</div>
Merve is a developer advocate at Hugging Face, working on developing tools and building content around them to democratize machine learning for everyone.
**Abubakar Abid:** *Building Machine Learning Applications Fast*
<div class="flex justify-center">
<Youtube id="c7mle2yYpwQ"/>
</div>
<p align="center">
<img src="https://i.imgur.com/qWIFeiF.png" alt="A visual summary of Abubakar's talk" width="80%"/>
</p>
Abubakar Abid is the CEO of [Gradio](www.gradio.app). He received his Bachelor's of Science in Electrical Engineering and Computer Science from MIT in 2015, and his PhD in Applied Machine Learning from Stanford in 2021. In his role as the CEO of Gradio, Abubakar works on making machine learning models easier to demo, debug, and deploy.
**Mathieu Desvé:** *AWS ML Vision: Making Machine Learning Accessible to all Customers*
<div class="flex justify-center">
<Youtube id="O2e3pXO4aRE"/>
</div>
<p align="center">
<img src="https://i.imgur.com/oLdZTKy.png" alt="A visual summary of Mathieu's talk" width="80%"/>
</p>
Technology enthusiast, maker on my free time. I like challenges and solving problem of clients and users, and work with talented people to learn every day. Since 2004, I work in multiple positions switching from frontend, backend, infrastructure, operations and managements. Try to solve commons technical and managerial issues in agile manner.
**Philipp Schmid:** *Managed Training with Amazon SageMaker and 🤗 Transformers*
<div class="flex justify-center">
<Youtube id="yG6J2Zfo8iw"/>
</div>
Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
| huggingface/course/blob/main/chapters/en/events/2.mdx |
Create Your Own Friends with a GAN
Related spaces: https://huggingface.co/spaces/NimaBoscarino/cryptopunks, https://huggingface.co/spaces/nateraw/cryptopunks-generator
Tags: GAN, IMAGE, HUB
Contributed by <a href="https://huggingface.co/NimaBoscarino">Nima Boscarino</a> and <a href="https://huggingface.co/nateraw">Nate Raw</a>
## Introduction
It seems that cryptocurrencies, [NFTs](https://www.nytimes.com/interactive/2022/03/18/technology/nft-guide.html), and the web3 movement are all the rage these days! Digital assets are being listed on marketplaces for astounding amounts of money, and just about every celebrity is debuting their own NFT collection. While your crypto assets [may be taxable, such as in Canada](https://www.canada.ca/en/revenue-agency/programs/about-canada-revenue-agency-cra/compliance/digital-currency/cryptocurrency-guide.html), today we'll explore some fun and tax-free ways to generate your own assortment of procedurally generated [CryptoPunks](https://www.larvalabs.com/cryptopunks).
Generative Adversarial Networks, often known just as _GANs_, are a specific class of deep-learning models that are designed to learn from an input dataset to create (_generate!_) new material that is convincingly similar to elements of the original training set. Famously, the website [thispersondoesnotexist.com](https://thispersondoesnotexist.com/) went viral with lifelike, yet synthetic, images of people generated with a model called StyleGAN2. GANs have gained traction in the machine learning world, and are now being used to generate all sorts of images, text, and even [music](https://salu133445.github.io/musegan/)!
Today we'll briefly look at the high-level intuition behind GANs, and then we'll build a small demo around a pre-trained GAN to see what all the fuss is about. Here's a [peek](https://nimaboscarino-cryptopunks.hf.space) at what we're going to be putting together.
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). To use the pretrained model, also install `torch` and `torchvision`.
## GANs: a very brief introduction
Originally proposed in [Goodfellow et al. 2014](https://arxiv.org/abs/1406.2661), GANs are made up of neural networks which compete with the intention of outsmarting each other. One network, known as the _generator_, is responsible for generating images. The other network, the _discriminator_, receives an image at a time from the generator along with a **real** image from the training data set. The discriminator then has to guess: which image is the fake?
The generator is constantly training to create images which are trickier for the discriminator to identify, while the discriminator raises the bar for the generator every time it correctly detects a fake. As the networks engage in this competitive (_adversarial!_) relationship, the images that get generated improve to the point where they become indistinguishable to human eyes!
For a more in-depth look at GANs, you can take a look at [this excellent post on Analytics Vidhya](https://www.analyticsvidhya.com/blog/2021/06/a-detailed-explanation-of-gan-with-implementation-using-tensorflow-and-keras/) or this [PyTorch tutorial](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html). For now, though, we'll dive into a demo!
## Step 1 — Create the Generator model
To generate new images with a GAN, you only need the generator model. There are many different architectures that the generator could use, but for this demo we'll use a pretrained GAN generator model with the following architecture:
```python
from torch import nn
class Generator(nn.Module):
# Refer to the link below for explanations about nc, nz, and ngf
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
```
We're taking the generator from [this repo by @teddykoker](https://github.com/teddykoker/cryptopunks-gan/blob/main/train.py#L90), where you can also see the original discriminator model structure.
After instantiating the model, we'll load in the weights from the Hugging Face Hub, stored at [nateraw/cryptopunks-gan](https://huggingface.co/nateraw/cryptopunks-gan):
```python
from huggingface_hub import hf_hub_download
import torch
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # Use 'cuda' if you have a GPU available
```
## Step 2 — Defining a `predict` function
The `predict` function is the key to making Gradio work! Whatever inputs we choose through the Gradio interface will get passed through our `predict` function, which should operate on the inputs and generate outputs that we can display with Gradio output components. For GANs it's common to pass random noise into our model as the input, so we'll generate a tensor of random numbers and pass that through the model. We can then use `torchvision`'s `save_image` function to save the output of the model as a `png` file, and return the file name:
```python
from torchvision.utils import save_image
def predict(seed):
num_punks = 4
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
We're giving our `predict` function a `seed` parameter, so that we can fix the random tensor generation with a seed. We'll then be able to reproduce punks if we want to see them again by passing in the same seed.
_Note!_ Our model needs an input tensor of dimensions 100x1x1 to do a single inference, or (BatchSize)x100x1x1 for generating a batch of images. In this demo we'll start by generating 4 punks at a time.
## Step 3 — Creating a Gradio interface
At this point you can even run the code you have with `predict(<SOME_NUMBER>)`, and you'll find your freshly generated punks in your file system at `./punks.png`. To make a truly interactive demo, though, we'll build out a simple interface with Gradio. Our goals here are to:
- Set a slider input so users can choose the "seed" value
- Use an image component for our output to showcase the generated punks
- Use our `predict()` to take the seed and generate the images
With `gr.Interface()`, we can define all of that with a single function call:
```python
import gradio as gr
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
],
outputs="image",
).launch()
```
## Step 4 — Even more punks!
Generating 4 punks at a time is a good start, but maybe we'd like to control how many we want to make each time. Adding more inputs to our Gradio interface is as simple as adding another item to the `inputs` list that we pass to `gr.Interface`:
```python
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10), # Adding another slider!
],
outputs="image",
).launch()
```
The new input will be passed to our `predict()` function, so we have to make some changes to that function to accept a new parameter:
```python
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
When you relaunch your interface, you should see a second slider that'll let you control the number of punks!
## Step 5 - Polishing it up
Your Gradio app is pretty much good to go, but you can add a few extra things to really make it ready for the spotlight ✨
We can add some examples that users can easily try out by adding this to the `gr.Interface`:
```python
gr.Interface(
# ...
# keep everything as it is, and then add
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True) # cache_examples is optional
```
The `examples` parameter takes a list of lists, where each item in the sublists is ordered in the same order that we've listed the `inputs`. So in our case, `[seed, num_punks]`. Give it a try!
You can also try adding a `title`, `description`, and `article` to the `gr.Interface`. Each of those parameters accepts a string, so try it out and see what happens 👀 `article` will also accept HTML, as [explored in a previous guide](/guides/key-features/#descriptive-content)!
When you're all done, you may end up with something like [this](https://nimaboscarino-cryptopunks.hf.space).
For reference, here is our full code:
```python
import torch
from torch import nn
from huggingface_hub import hf_hub_download
from torchvision.utils import save_image
import gradio as gr
class Generator(nn.Module):
# Refer to the link below for explanations about nc, nz, and ngf
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # Use 'cuda' if you have a GPU available
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10),
],
outputs="image",
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True)
```
---
Congratulations! You've built out your very own GAN-powered CryptoPunks generator, with a fancy Gradio interface that makes it easy for anyone to use. Now you can [scour the Hub for more GANs](https://huggingface.co/models?other=gan) (or train your own) and continue making even more awesome demos 🤗
| gradio-app/gradio/blob/main/guides/09_other-tutorials/create-your-own-friends-with-a-gan.md |
How do Transformers work?[[how-do-transformers-work]]
<CourseFloatingBanner
chapter={1}
classNames="absolute z-10 right-0 top-0"
/>
In this section, we will take a high-level look at the architecture of Transformer models.
## A bit of Transformer history[[a-bit-of-transformer-history]]
Here are some reference points in the (short) history of Transformer models:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers_chrono.svg" alt="A brief chronology of Transformers models.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers_chrono-dark.svg" alt="A brief chronology of Transformers models.">
</div>
The [Transformer architecture](https://arxiv.org/abs/1706.03762) was introduced in June 2017. The focus of the original research was on translation tasks. This was followed by the introduction of several influential models, including:
- **June 2018**: [GPT](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf), the first pretrained Transformer model, used for fine-tuning on various NLP tasks and obtained state-of-the-art results
- **October 2018**: [BERT](https://arxiv.org/abs/1810.04805), another large pretrained model, this one designed to produce better summaries of sentences (more on this in the next chapter!)
- **February 2019**: [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf), an improved (and bigger) version of GPT that was not immediately publicly released due to ethical concerns
- **October 2019**: [DistilBERT](https://arxiv.org/abs/1910.01108), a distilled version of BERT that is 60% faster, 40% lighter in memory, and still retains 97% of BERT's performance
- **October 2019**: [BART](https://arxiv.org/abs/1910.13461) and [T5](https://arxiv.org/abs/1910.10683), two large pretrained models using the same architecture as the original Transformer model (the first to do so)
- **May 2020**, [GPT-3](https://arxiv.org/abs/2005.14165), an even bigger version of GPT-2 that is able to perform well on a variety of tasks without the need for fine-tuning (called _zero-shot learning_)
This list is far from comprehensive, and is just meant to highlight a few of the different kinds of Transformer models. Broadly, they can be grouped into three categories:
- GPT-like (also called _auto-regressive_ Transformer models)
- BERT-like (also called _auto-encoding_ Transformer models)
- BART/T5-like (also called _sequence-to-sequence_ Transformer models)
We will dive into these families in more depth later on.
## Transformers are language models[[transformers-are-language-models]]
All the Transformer models mentioned above (GPT, BERT, BART, T5, etc.) have been trained as *language models*. This means they have been trained on large amounts of raw text in a self-supervised fashion. Self-supervised learning is a type of training in which the objective is automatically computed from the inputs of the model. That means that humans are not needed to label the data!
This type of model develops a statistical understanding of the language it has been trained on, but it's not very useful for specific practical tasks. Because of this, the general pretrained model then goes through a process called *transfer learning*. During this process, the model is fine-tuned in a supervised way -- that is, using human-annotated labels -- on a given task.
An example of a task is predicting the next word in a sentence having read the *n* previous words. This is called *causal language modeling* because the output depends on the past and present inputs, but not the future ones.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/causal_modeling.svg" alt="Example of causal language modeling in which the next word from a sentence is predicted.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/causal_modeling-dark.svg" alt="Example of causal language modeling in which the next word from a sentence is predicted.">
</div>
Another example is *masked language modeling*, in which the model predicts a masked word in the sentence.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/masked_modeling.svg" alt="Example of masked language modeling in which a masked word from a sentence is predicted.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/masked_modeling-dark.svg" alt="Example of masked language modeling in which a masked word from a sentence is predicted.">
</div>
## Transformers are big models[[transformers-are-big-models]]
Apart from a few outliers (like DistilBERT), the general strategy to achieve better performance is by increasing the models' sizes as well as the amount of data they are pretrained on.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/model_parameters.png" alt="Number of parameters of recent Transformers models" width="90%">
</div>
Unfortunately, training a model, especially a large one, requires a large amount of data. This becomes very costly in terms of time and compute resources. It even translates to environmental impact, as can be seen in the following graph.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/carbon_footprint.svg" alt="The carbon footprint of a large language model.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/carbon_footprint-dark.svg" alt="The carbon footprint of a large language model.">
</div>
<Youtube id="ftWlj4FBHTg"/>
And this is showing a project for a (very big) model led by a team consciously trying to reduce the environmental impact of pretraining. The footprint of running lots of trials to get the best hyperparameters would be even higher.
Imagine if each time a research team, a student organization, or a company wanted to train a model, it did so from scratch. This would lead to huge, unnecessary global costs!
This is why sharing language models is paramount: sharing the trained weights and building on top of already trained weights reduces the overall compute cost and carbon footprint of the community.
By the way, you can evaluate the carbon footprint of your models' training through several tools. For example [ML CO2 Impact](https://mlco2.github.io/impact/) or [Code Carbon]( https://codecarbon.io/) which is integrated in 🤗 Transformers. To learn more about this, you can read this [blog post](https://huggingface.co/blog/carbon-emissions-on-the-hub) which will show you how to generate an `emissions.csv` file with an estimate of the footprint of your training, as well as the [documentation](https://huggingface.co/docs/hub/model-cards-co2) of 🤗 Transformers addressing this topic.
## Transfer Learning[[transfer-learning]]
<Youtube id="BqqfQnyjmgg" />
*Pretraining* is the act of training a model from scratch: the weights are randomly initialized, and the training starts without any prior knowledge.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/pretraining.svg" alt="The pretraining of a language model is costly in both time and money.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/pretraining-dark.svg" alt="The pretraining of a language model is costly in both time and money.">
</div>
This pretraining is usually done on very large amounts of data. Therefore, it requires a very large corpus of data, and training can take up to several weeks.
*Fine-tuning*, on the other hand, is the training done **after** a model has been pretrained. To perform fine-tuning, you first acquire a pretrained language model, then perform additional training with a dataset specific to your task. Wait -- why not simply train the model for your final use case from the start (**scratch**)? There are a couple of reasons:
* The pretrained model was already trained on a dataset that has some similarities with the fine-tuning dataset. The fine-tuning process is thus able to take advantage of knowledge acquired by the initial model during pretraining (for instance, with NLP problems, the pretrained model will have some kind of statistical understanding of the language you are using for your task).
* Since the pretrained model was already trained on lots of data, the fine-tuning requires way less data to get decent results.
* For the same reason, the amount of time and resources needed to get good results are much lower.
For example, one could leverage a pretrained model trained on the English language and then fine-tune it on an arXiv corpus, resulting in a science/research-based model. The fine-tuning will only require a limited amount of data: the knowledge the pretrained model has acquired is "transferred," hence the term *transfer learning*.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/finetuning.svg" alt="The fine-tuning of a language model is cheaper than pretraining in both time and money.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/finetuning-dark.svg" alt="The fine-tuning of a language model is cheaper than pretraining in both time and money.">
</div>
Fine-tuning a model therefore has lower time, data, financial, and environmental costs. It is also quicker and easier to iterate over different fine-tuning schemes, as the training is less constraining than a full pretraining.
This process will also achieve better results than training from scratch (unless you have lots of data), which is why you should always try to leverage a pretrained model -- one as close as possible to the task you have at hand -- and fine-tune it.
## General architecture[[general-architecture]]
In this section, we'll go over the general architecture of the Transformer model. Don't worry if you don't understand some of the concepts; there are detailed sections later covering each of the components.
<Youtube id="H39Z_720T5s" />
## Introduction[[introduction]]
The model is primarily composed of two blocks:
* **Encoder (left)**: The encoder receives an input and builds a representation of it (its features). This means that the model is optimized to acquire understanding from the input.
* **Decoder (right)**: The decoder uses the encoder's representation (features) along with other inputs to generate a target sequence. This means that the model is optimized for generating outputs.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers_blocks.svg" alt="Architecture of a Transformers models">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers_blocks-dark.svg" alt="Architecture of a Transformers models">
</div>
Each of these parts can be used independently, depending on the task:
* **Encoder-only models**: Good for tasks that require understanding of the input, such as sentence classification and named entity recognition.
* **Decoder-only models**: Good for generative tasks such as text generation.
* **Encoder-decoder models** or **sequence-to-sequence models**: Good for generative tasks that require an input, such as translation or summarization.
We will dive into those architectures independently in later sections.
## Attention layers[[attention-layers]]
A key feature of Transformer models is that they are built with special layers called *attention layers*. In fact, the title of the paper introducing the Transformer architecture was ["Attention Is All You Need"](https://arxiv.org/abs/1706.03762)! We will explore the details of attention layers later in the course; for now, all you need to know is that this layer will tell the model to pay specific attention to certain words in the sentence you passed it (and more or less ignore the others) when dealing with the representation of each word.
To put this into context, consider the task of translating text from English to French. Given the input "You like this course", a translation model will need to also attend to the adjacent word "You" to get the proper translation for the word "like", because in French the verb "like" is conjugated differently depending on the subject. The rest of the sentence, however, is not useful for the translation of that word. In the same vein, when translating "this" the model will also need to pay attention to the word "course", because "this" translates differently depending on whether the associated noun is masculine or feminine. Again, the other words in the sentence will not matter for the translation of "course". With more complex sentences (and more complex grammar rules), the model would need to pay special attention to words that might appear farther away in the sentence to properly translate each word.
The same concept applies to any task associated with natural language: a word by itself has a meaning, but that meaning is deeply affected by the context, which can be any other word (or words) before or after the word being studied.
Now that you have an idea of what attention layers are all about, let's take a closer look at the Transformer architecture.
## The original architecture[[the-original-architecture]]
The Transformer architecture was originally designed for translation. During training, the encoder receives inputs (sentences) in a certain language, while the decoder receives the same sentences in the desired target language. In the encoder, the attention layers can use all the words in a sentence (since, as we just saw, the translation of a given word can be dependent on what is after as well as before it in the sentence). The decoder, however, works sequentially and can only pay attention to the words in the sentence that it has already translated (so, only the words before the word currently being generated). For example, when we have predicted the first three words of the translated target, we give them to the decoder which then uses all the inputs of the encoder to try to predict the fourth word.
To speed things up during training (when the model has access to target sentences), the decoder is fed the whole target, but it is not allowed to use future words (if it had access to the word at position 2 when trying to predict the word at position 2, the problem would not be very hard!). For instance, when trying to predict the fourth word, the attention layer will only have access to the words in positions 1 to 3.
The original Transformer architecture looked like this, with the encoder on the left and the decoder on the right:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers.svg" alt="Architecture of a Transformers models">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter1/transformers-dark.svg" alt="Architecture of a Transformers models">
</div>
Note that the first attention layer in a decoder block pays attention to all (past) inputs to the decoder, but the second attention layer uses the output of the encoder. It can thus access the whole input sentence to best predict the current word. This is very useful as different languages can have grammatical rules that put the words in different orders, or some context provided later in the sentence may be helpful to determine the best translation of a given word.
The *attention mask* can also be used in the encoder/decoder to prevent the model from paying attention to some special words -- for instance, the special padding word used to make all the inputs the same length when batching together sentences.
## Architectures vs. checkpoints[[architecture-vs-checkpoints]]
As we dive into Transformer models in this course, you'll see mentions of *architectures* and *checkpoints* as well as *models*. These terms all have slightly different meanings:
* **Architecture**: This is the skeleton of the model -- the definition of each layer and each operation that happens within the model.
* **Checkpoints**: These are the weights that will be loaded in a given architecture.
* **Model**: This is an umbrella term that isn't as precise as "architecture" or "checkpoint": it can mean both. This course will specify *architecture* or *checkpoint* when it matters to reduce ambiguity.
For example, BERT is an architecture while `bert-base-cased`, a set of weights trained by the Google team for the first release of BERT, is a checkpoint. However, one can say "the BERT model" and "the `bert-base-cased` model."
| huggingface/course/blob/main/chapters/en/chapter1/4.mdx |
n this video we'll take a look at how you upload your very own dataset to the Hub. The first you'll need to do is create a new dataset repository on the Hub. Just click on your profile icon and select the "New Dataset" button. Next we need to assign an owner of the dataset. By default, this will be your Hub account, but you can also create datasets under any organisation that you belong to. Then we just need to give the dataset a name and specify whether it is a public or private dataset. Public datasets can be accessed by anyone, while private datasets can only be accessed by you or members of your organisation. And with that we can go ahead and create the dataset! Now that you have an empty dataset repository on the Hub, the next thing to do is add some data to it! You can do this with Git, but the easiest way is by selecting "Upload file" and uploading the files directly from your machine. After you've uploaded the files, you'll see them appear in the repository under the "Files and versions" tab. The last step is to create a dataset card. Well documented datasets are more likely to be useful to others (including your future self!) as they provide the context to decide whether the dataset is relevant or whether there are any biases or risks associated with using the dataset. On the Hugging Face Hub, this information is stored in each repository’s README.md file and there are two main steps you should take. First you need to create some metadata that will allow your dataset to be easily found by others on the Hub. You can create this metadata using the Datasets Tagging Application which we'll link to in the video description. Once you have created the metadata, you can fill out the rest of the dataset card and we provide a template that is also linked in the video. And once your dataset is up on the Hub, you can load it using the trusty load_dataset() function! Just provide the name of your repository and a data_files argument for the files and you're good to go! | huggingface/course/blob/main/subtitles/en/raw/chapter5/05_upload-dataset.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Video Vision Transformer (ViViT)
## Overview
The Vivit model was proposed in [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
The paper proposes one of the first successful pure-transformer based set of models for video understanding.
The abstract from the paper is the following:
*We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks.*
This model was contributed by [jegormeister](https://huggingface.co/jegormeister). The original code (written in JAX) can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/vivit).
## VivitConfig
[[autodoc]] VivitConfig
## VivitImageProcessor
[[autodoc]] VivitImageProcessor
- preprocess
## VivitModel
[[autodoc]] VivitModel
- forward
## VivitForVideoClassification
[[autodoc]] transformers.VivitForVideoClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/vivit.md |
Introduction [[introduction]]
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/thumbnail.png" alt="Thumbnail"/>
In unit 4, we learned about our first Policy-Based algorithm called **Reinforce**.
In Policy-Based methods, **we aim to optimize the policy directly without using a value function**. More precisely, Reinforce is part of a subclass of *Policy-Based Methods* called *Policy-Gradient methods*. This subclass optimizes the policy directly by **estimating the weights of the optimal policy using Gradient Ascent**.
We saw that Reinforce worked well. However, because we use Monte-Carlo sampling to estimate return (we use an entire episode to calculate the return), **we have significant variance in policy gradient estimation**.
Remember that the policy gradient estimation is **the direction of the steepest increase in return**. In other words, how to update our policy weights so that actions that lead to good returns have a higher probability of being taken. The Monte Carlo variance, which we will further study in this unit, **leads to slower training since we need a lot of samples to mitigate it**.
So today we'll study **Actor-Critic methods**, a hybrid architecture combining value-based and Policy-Based methods that helps to stabilize the training by reducing the variance using:
- *An Actor* that controls **how our agent behaves** (Policy-Based method)
- *A Critic* that measures **how good the taken action is** (Value-Based method)
We'll study one of these hybrid methods, Advantage Actor Critic (A2C), **and train our agent using Stable-Baselines3 in robotic environments**. We'll train:
- A robotic arm 🦾 to move to the correct position.
Sound exciting? Let's get started!
| huggingface/deep-rl-class/blob/main/units/en/unit6/introduction.mdx |
--
title: 'Getting Started With Embeddings'
thumbnail: /blog/assets/80_getting_started_with_embeddings/thumbnail.png
authors:
- user: espejelomar
---
# Getting Started With Embeddings
Check out this tutorial with the Notebook Companion:
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/80_getting_started_with_embeddings.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Understanding embeddings
An embedding is a numerical representation of a piece of information, for example, text, documents, images, audio, etc. The representation captures the semantic meaning of what is being embedded, making it robust for many industry applications.
Given the text "What is the main benefit of voting?", an embedding of the sentence could be represented in a vector space, for example, with a list of 384 numbers (for example, [0.84, 0.42, ..., 0.02]). Since this list captures the meaning, we can do exciting things, like calculating the distance between different embeddings to determine how well the meaning of two sentences matches.
Embeddings are not limited to text! You can also create an embedding of an image (for example, a list of 384 numbers) and compare it with a text embedding to determine if a sentence describes the image. This concept is under powerful systems for image search, classification, description, and more!
How are embeddings generated? The open-source library called [Sentence Transformers](https://www.sbert.net/index.html) allows you to create state-of-the-art embeddings from images and text for free. This blog shows an example with this library.
## What are embeddings for?
> "[...] once you understand this ML multitool (embedding), you'll be able to build everything from search engines to recommendation systems to chatbots and a whole lot more. You don't have to be a data scientist with ML expertise to use them, nor do you need a huge labeled dataset." - [Dale Markowitz, Google Cloud](https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings).
Once a piece of information (a sentence, a document, an image) is embedded, the creativity starts; several interesting industrial applications use embeddings. E.g., Google Search uses embeddings to [match text to text and text to images](https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings); Snapchat uses them to "[serve the right ad to the right user at the right time](https://eng.snap.com/machine-learning-snap-ad-ranking)"; and Meta (Facebook) uses them for [their social search](https://research.facebook.com/publications/embedding-based-retrieval-in-facebook-search/).
Before they could get intelligence from embeddings, these companies had to embed their pieces of information. An embedded dataset allows algorithms to search quickly, sort, group, and more. However, it can be expensive and technically complicated. In this post, we use simple open-source tools to show how easy it can be to embed and analyze a dataset.
## Getting started with embeddings
We will create a small Frequently Asked Questions (FAQs) engine: receive a query from a user and identify which FAQ is the most similar. We will use the [US Social Security Medicare FAQs](https://faq.ssa.gov/en-US/topic/?id=CAT-01092).
But first, we need to embed our dataset (other texts use the terms encode and embed interchangeably). The Hugging Face Inference API allows us to embed a dataset using a quick POST call easily.
Since the embeddings capture the semantic meaning of the questions, it is possible to compare different embeddings and see how different or similar they are. Thanks to this, you can get the most similar embedding to a query, which is equivalent to finding the most similar FAQ. Check out our [semantic search tutorial](https://huggingface.co/spaces/sentence-transformers/embeddings-semantic-search) for a more detailed explanation of how this mechanism works.
In a nutshell, we will:
1. Embed Medicare's FAQs using the Inference API.
2. Upload the embedded questions to the Hub for free hosting.
3. Compare a customer's query to the embedded dataset to identify which is the most similar FAQ.
## 1. Embedding a dataset
The first step is selecting an existing pre-trained model for creating the embeddings. We can choose a model from the [Sentence Transformers library](https://huggingface.co/sentence-transformers). In this case, let's use the ["sentence-transformers/all-MiniLM-L6-v2"](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) because it's a small but powerful model. In a future post, we will examine other models and their trade-offs.
Log in to the Hub. You must create a write token in your [Account Settings](http://hf.co/settings/tokens). We will store the write token in `hf_token`.
```py
model_id = "sentence-transformers/all-MiniLM-L6-v2"
hf_token = "get your token in http://hf.co/settings/tokens"
```
To generate the embeddings you can use the `https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}` endpoint with the headers `{"Authorization": f"Bearer {hf_token}"}`. Here is a function that receives a dictionary with the texts and returns a list with embeddings.
```py
import requests
api_url = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}"
headers = {"Authorization": f"Bearer {hf_token}"}
```
The first time you generate the embeddings, it may take a while (approximately 20 seconds) for the API to return them. We use the `retry` decorator (install with `pip install retry`) so that if on the first try, `output = query(dict(inputs = texts))` doesn't work, wait 10 seconds and try three times again. This happens because, on the first request, the model needs to be downloaded and installed on the server, but subsequent calls are much faster.
```py
def query(texts):
response = requests.post(api_url, headers=headers, json={"inputs": texts, "options":{"wait_for_model":True}})
return response.json()
```
The current API does not enforce strict rate limitations. Instead, Hugging Face balances the loads evenly between all our available resources and favors steady flows of requests. If you need to embed several texts or images, the [Hugging Face Accelerated Inference API](https://huggingface.co/docs/api-inference/index) would speed the inference and let you choose between using a CPU or GPU.
```py
texts = ["How do I get a replacement Medicare card?",
"What is the monthly premium for Medicare Part B?",
"How do I terminate my Medicare Part B (medical insurance)?",
"How do I sign up for Medicare?",
"Can I sign up for Medicare Part B if I am working and have health insurance through an employer?",
"How do I sign up for Medicare Part B if I already have Part A?",
"What are Medicare late enrollment penalties?",
"What is Medicare and who can get it?",
"How can I get help with my Medicare Part A and Part B premiums?",
"What are the different parts of Medicare?",
"Will my Medicare premiums be higher because of my higher income?",
"What is TRICARE ?",
"Should I sign up for Medicare Part B if I have Veterans' Benefits?"]
output = query(texts)
```
As a response, you get back a list of lists. Each list contains the embedding of a FAQ. The model, ["sentence-transformers/all-MiniLM-L6-v2"](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2), is encoding the input questions to 13 embeddings of size 384 each. Let's convert the list to a Pandas `DataFrame` of shape (13x384).
```py
import pandas as pd
embeddings = pd.DataFrame(output)
```
It looks similar to this matrix:
```py
[[-0.02388945 0.05525852 -0.01165488 ... 0.00577787 0.03409787 -0.0068891 ]
[-0.0126876 0.04687412 -0.01050217 ... -0.02310316 -0.00278466 0.01047371]
[ 0.00049438 0.11941205 0.00522949 ... 0.01687654 -0.02386115 0.00526433]
...
[-0.03900796 -0.01060951 -0.00738271 ... -0.08390449 0.03768405 0.00231361]
[-0.09598278 -0.06301168 -0.11690582 ... 0.00549841 0.1528919 0.02472013]
[-0.01162949 0.05961934 0.01650903 ... -0.02821241 -0.00116556 0.0010672 ]]
```
## 2. Host embeddings for free on the Hugging Face Hub
🤗 Datasets is a library for quickly accessing and sharing datasets. Let's host the embeddings dataset in the Hub using the user interface (UI). Then, anyone can load it with a single line of code. You can also use the terminal to share datasets; see [the documentation](https://huggingface.co/docs/datasets/share#share) for the steps. In the [notebook companion](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/80_getting_started_with_embeddings.ipynb) of this entry, you will be able to use the terminal to share the dataset. If you want to skip this section, check out the [`ITESM/embedded_faqs_medicare` repo](https://huggingface.co/datasets/ITESM/embedded_faqs_medicare) with the embedded FAQs.
First, we export our embeddings from a Pandas `DataFrame` to a CSV. You can save your dataset in any way you prefer, e.g., zip or pickle; you don't need to use Pandas or CSV. Since our embeddings file is not large, we can store it in a CSV, which is easily inferred by the `datasets.load_dataset()` function we will employ in the next section (see the [Datasets documentation](https://huggingface.co/docs/datasets/about_dataset_load#build-and-load)), i.e., we don't need to create a loading script. We will save the embeddings with the name `embeddings.csv`.
```py
embeddings.to_csv("embeddings.csv", index=False)
```
Follow the next steps to host `embeddings.csv` in the Hub.
* Click on your user in the top right corner of the [Hub UI](https://huggingface.co/).
* Create a dataset with "New dataset."

* Choose the Owner (organization or individual), name, and license of the dataset. Select if you want it to be private or public. Create the dataset.

* Go to the "Files" tab (screenshot below) and click "Add file" and "Upload file."

* Finally, drag or upload the dataset, and commit the changes.

Now the dataset is hosted on the Hub for free. You (or whoever you want to share the embeddings with) can quickly load them. Let's see how.
## 3. Get the most similar Frequently Asked Questions to a query
Suppose a Medicare customer asks, "How can Medicare help me?". We will **find** which of our FAQs could best answer our user query. We will create an embedding of the query that can represent its semantic meaning. We then compare it to each embedding in our FAQ dataset to identify which is closest to the query in vector space.
Install the 🤗 Datasets library with `pip install datasets`. Then, load the embedded dataset from the Hub and convert it to a PyTorch `FloatTensor`. Note that this is not the only way to operate on a `Dataset`; for example, you could use NumPy, Tensorflow, or SciPy (refer to the [Documentation](https://huggingface.co/docs/datasets/loading)). If you want to practice with a real dataset, the [`ITESM/embedded_faqs_medicare`](https://huggingface.co/datasets/ITESM/embedded_faqs_medicare) repo contains the embedded FAQs, or you can use the [companion notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/80_getting_started_with_embeddings.ipynb) to this blog.
```py
import torch
from datasets import load_dataset
faqs_embeddings = load_dataset('namespace/repo_name')
dataset_embeddings = torch.from_numpy(faqs_embeddings["train"].to_pandas().to_numpy()).to(torch.float)
```
We use the query function we defined before to embed the customer's question and convert it to a PyTorch `FloatTensor` to operate over it efficiently. Note that after the embedded dataset is loaded, we could use the `add_faiss_index` and `search` methods of a `Dataset` to identify the closest FAQ to an embedded query using the [faiss library](https://github.com/facebookresearch/faiss). Here is a [nice tutorial of the alternative](https://huggingface.co/docs/datasets/faiss_es).
```py
question = ["How can Medicare help me?"]
output = query(question)
query_embeddings = torch.FloatTensor(output)
```
You can use the `util.semantic_search` function in the Sentence Transformers library to identify which of the FAQs are closest (most similar) to the user's query. This function uses cosine similarity as the default function to determine the proximity of the embeddings. However, you could also use other functions that measure the distance between two points in a vector space, for example, the dot product.
Install `sentence-transformers` with `pip install -U sentence-transformers`, and search for the five most similar FAQs to the query.
```py
from sentence_transformers.util import semantic_search
hits = semantic_search(query_embeddings, dataset_embeddings, top_k=5)
```
`util.semantic_search` identifies how close each of the 13 FAQs is to the customer query and returns a list of dictionaries with the top `top_k` FAQs. `hits` looks like this:
```py
[{'corpus_id': 8, 'score': 0.75653076171875},
{'corpus_id': 7, 'score': 0.7418993711471558},
{'corpus_id': 3, 'score': 0.7252674102783203},
{'corpus_id': 9, 'score': 0.6735571622848511},
{'corpus_id': 10, 'score': 0.6505177617073059}]
```
The values in `corpus_id` allow us to index the list of `texts` we defined in the first section and get the five most similar FAQs:
```py
print([texts[hits[0][i]['corpus_id']] for i in range(len(hits[0]))])
```
Here are the 5 FAQs that come closest to the customer's query:
```py
['How can I get help with my Medicare Part A and Part B premiums?',
'What is Medicare and who can get it?',
'How do I sign up for Medicare?',
'What are the different parts of Medicare?',
'Will my Medicare premiums be higher because of my higher income?']
```
This list represents the 5 FAQs closest to the customer's query. Nice! We used here PyTorch and Sentence Transformers as our main numerical tools. However, we could have defined the cosine similarity and ranking functions by ourselves using tools such as NumPy and SciPy.
## Additional resources to keep learning
If you want to know more about the Sentence Transformers library:
- The [Hub Organization](https://huggingface.co/sentence-transformers) for all the new models and instructions on how to download models.
- The [Nils Reimers tweet](https://twitter.com/Nils_Reimers/status/1487014195568775173) comparing Sentence Transformer models with GPT-3 Embeddings. Spoiler alert: the Sentence Transformers are awesome!
- The [Sentence Transformers documentation](https://www.sbert.net/),
- [Nima's thread](https://twitter.com/NimaBoscarino/status/1535331680805801984) on recent research.
Thanks for reading!
| huggingface/blog/blob/main/getting-started-with-embeddings.md |
Managing Spaces with Github Actions
You can keep your app in sync with your GitHub repository with **Github Actions**. Remember that for files larger than 10MB, Spaces requires Git-LFS. If you don't want to use Git-LFS, you may need to review your files and check your history. Use a tool like [BFG Repo-Cleaner](https://rtyley.github.io/bfg-repo-cleaner/) to remove any large files from your history. BFG Repo-Cleaner will keep a local copy of your repository as a backup.
First, you should set up your GitHub repository and Spaces app together. Add your Spaces app as an additional remote to your existing Git repository.
```bash
git remote add space https://huggingface.co/spaces/HF_USERNAME/SPACE_NAME
```
Then force push to sync everything for the first time:
```bash
git push --force space main
```
Next, set up a GitHub Action to push your main branch to Spaces. In the example below:
* Replace `HF_USERNAME` with your username and `SPACE_NAME` with your Space name.
* Create a [Github secret](https://docs.github.com/en/actions/security-guides/encrypted-secrets#creating-encrypted-secrets-for-an-environment) with your `HF_TOKEN`. You can find your Hugging Face API token under **API Tokens** on your Hugging Face profile.
```yaml
name: Sync to Hugging Face hub
on:
push:
branches: [main]
# to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
sync-to-hub:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
fetch-depth: 0
lfs: true
- name: Push to hub
env:
HF_TOKEN: ${{ secrets.HF_TOKEN }}
run: git push https://HF_USERNAME:$HF_TOKEN@huggingface.co/spaces/HF_USERNAME/SPACE_NAME main
```
Finally, create an Action that automatically checks the file size of any new pull request:
```yaml
name: Check file size
on: # or directly `on: [push]` to run the action on every push on any branch
pull_request:
branches: [main]
# to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
sync-to-hub:
runs-on: ubuntu-latest
steps:
- name: Check large files
uses: ActionsDesk/lfs-warning@v2.0
with:
filesizelimit: 10485760 # this is 10MB so we can sync to HF Spaces
```
| huggingface/hub-docs/blob/main/docs/hub/spaces-github-actions.md |
Added Tokens
<tokenizerslangcontent>
<python>
## AddedToken
[[autodoc]] tokenizers.AddedToken
- content
- lstrip
- normalized
- rstrip
- single_word
</python>
<rust>
The Rust API Reference is available directly on the [Docs.rs](https://docs.rs/tokenizers/latest/tokenizers/) website.
</rust>
<node>
The node API has not been documented yet.
</node>
</tokenizerslangcontent> | huggingface/tokenizers/blob/main/docs/source-doc-builder/api/added-tokens.mdx |
Gradio Demo: blocks_component_shortcut
```
!pip install -q gradio
```
```
import gradio as gr
def greet(str):
return str
with gr.Blocks() as demo:
"""
You can make use of str shortcuts you use in Interface within Blocks as well.
Interface shortcut example:
Interface(greet, "textarea", "textarea")
You can use
1. gr.component()
2. gr.templates.Template()
3. gr.Template()
All the templates are listed in gradio/templates.py
"""
with gr.Row():
text1 = gr.component("textarea")
text2 = gr.TextArea()
text3 = gr.templates.TextArea()
text1.blur(greet, text1, text2)
text2.blur(greet, text2, text3)
text3.blur(greet, text3, text1)
button = gr.component("button")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_component_shortcut/run.ipynb |
--
title: Getting Started with Transformers on Habana Gaudi
thumbnail: /blog/assets/61_getting_started_habana/habana01.png
authors:
- user: juliensimon
---
# Getting Started with Transformers on Habana Gaudi
A couple of weeks ago, we've had the pleasure to [announce](https://huggingface.co/blog/habana) that [Habana Labs](https://habana.ai) and [Hugging Face](https://huggingface.co/) would partner to accelerate Transformer model training.
Habana Gaudi accelerators deliver up to 40% better price performance for training machine learning models compared to the latest GPU-based Amazon EC2 instances. We are super excited to bring this price performance advantages to Transformers 🚀
In this hands-on post, I'll show you how to quickly set up a Habana Gaudi instance on Amazon Web Services, and then fine-tune a BERT model for text classification. As usual, all code is provided so that you may reuse it in your projects.
Let's get started!
## Setting up an Habana Gaudi instance on AWS
The simplest way to work with Habana Gaudi accelerators is to launch an Amazon EC2 [DL1](https://aws.amazon.com/ec2/instance-types/dl1/) instance. These instances are equipped with 8 Habana Gaudi processors that can easily be put to work thanks to the [Habana Deep Learning Amazon Machine Image](https://aws.amazon.com/marketplace/server/procurement?productId=9a75c51a-a4d1-4470-884f-6be27933fcc8) (AMI). This AMI comes preinstalled with the [Habana SynapseAI® SDK](https://developer.habana.ai/), and the tools required to run Gaudi accelerated Docker containers. If you'd like to use other AMIs or containers, instructions are available in the [Habana documentation](https://docs.habana.ai/en/latest/AWS_Quick_Starts/index.html).
Starting from the [EC2 console](https://console.aws.amazon.com/ec2sp/v2/) in the us-east-1 region, I first click on **Launch an instance** and define a name for the instance ("habana-demo-julsimon").
Then, I search the Amazon Marketplace for Habana AMIs.
<kbd>
<img src="assets/61_getting_started_habana/habana01.png">
</kbd>
I pick the Habana Deep Learning Base AMI (Ubuntu 20.04).
<kbd>
<img src="assets/61_getting_started_habana/habana02.png">
</kbd>
Next, I pick the *dl1.24xlarge* instance size (the only size available).
<kbd>
<img src="assets/61_getting_started_habana/habana03.png">
</kbd>
Then, I select the keypair that I'll use to connect to the instance with ```ssh```. If you don't have a keypair, you can create one in place.
<kbd>
<img src="assets/61_getting_started_habana/habana04.png">
</kbd>
As a next step, I make sure that the instance allows incoming ```ssh``` traffic. I do not restrict the source address for simplicity, but you should definitely do it in your account.
<kbd>
<img src="assets/61_getting_started_habana/habana05.png">
</kbd>
By default, this AMI will start an instance with 8GB of Amazon EBS storage, which won't be enough here. I bump storage to 50GB.
<kbd>
<img src="assets/61_getting_started_habana/habana08.png">
</kbd>
Next, I assign an Amazon IAM role to the instance. In real life, this role should have the minimum set of permissions required to run your training job, such as the ability to read data from one of your Amazon S3 buckets. This role is not needed here as the dataset will be downloaded from the Hugging Face hub. If you're not familiar with IAM, I highly recommend reading the [Getting Started](https://docs.aws.amazon.com/IAM/latest/UserGuide/getting-started.html) documentation.
Then, I ask EC2 to provision my instance as a [Spot Instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-instances.html), a great way to reduce the $13.11 per hour cost.
<kbd>
<img src="assets/61_getting_started_habana/habana06.png">
</kbd>
Finally, I launch the instance. A couple of minutes later, the instance is ready and I can connect to it with ```ssh```. Windows users can do the same with *PuTTY* by following the [documentation](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/putty.html).
```
ssh -i ~/.ssh/julsimon-keypair.pem ubuntu@ec2-18-207-189-109.compute-1.amazonaws.com
```
On this instance, the last setup step is to pull the Habana container for PyTorch, which is the framework I'll use to fine-tune my model. You can find information on other prebuilt containers and on how to build your own in the Habana [documentation](https://docs.habana.ai/en/latest/Installation_Guide/index.html).
```
docker pull \
vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
```
Once the image has been pulled to the instance, I run it in interactive mode.
```
docker run -it \
--runtime=habana \
-e HABANA_VISIBLE_DEVICES=all \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice \
--net=host \
--ipc=host vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
```
I'm now ready to fine-tune my model.
## Fine-tuning a text classification model on Habana Gaudi
I first clone the [Optimum Habana](https://github.com/huggingface/optimum-habana) repository inside the container I've just started.
```
git clone https://github.com/huggingface/optimum-habana.git
```
Then, I install the Optimum Habana package from source.
```
cd optimum-habana
pip install .
```
Then, I move to the subdirectory containing the text classification example and install the required Python packages.
```
cd examples/text-classification
pip install -r requirements.txt
```
I can now launch the training job, which downloads the [bert-large-uncased-whole-word-masking](https://huggingface.co/bert-large-uncased-whole-word-masking) model from the Hugging Face hub, and fine-tunes it on the [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) task of the [GLUE](https://gluebenchmark.com/) benchmark.
Please note that I'm fetching the Habana Gaudi configuration for BERT from the Hugging Face hub, and you could also use your own. In addition, other popular models are supported, and you can find their configuration file in the [Habana organization](https://huggingface.co/Habana).
```
python run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--gaudi_config_name Habana/bert-large-uncased-whole-word-masking \
--task_name mrpc \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--max_seq_length 128 \
--use_habana \
--use_lazy_mode \
--output_dir ./output/mrpc/
```
After 2 minutes and 12 seconds, the job is complete and has achieved an excellent F1 score of 0.9181, which could certainly improve with more epochs.
```
***** train metrics *****
epoch = 3.0
train_loss = 0.371
train_runtime = 0:02:12.85
train_samples = 3668
train_samples_per_second = 82.824
train_steps_per_second = 2.597
***** eval metrics *****
epoch = 3.0
eval_accuracy = 0.8505
eval_combined_score = 0.8736
eval_f1 = 0.8968
eval_loss = 0.385
eval_runtime = 0:00:06.45
eval_samples = 408
eval_samples_per_second = 63.206
eval_steps_per_second = 7.901
```
Last but not least, I terminate the EC2 instance to avoid unnecessary charges. Looking at the [Savings Summary](https://console.aws.amazon.com/ec2sp/v2/home/spot) in the EC2 console, I see that I saved 70% thanks to Spot Instances, paying only $3.93 per hour instead of $13.11.
<kbd>
<img src="assets/61_getting_started_habana/habana07.png">
</kbd>
As you can see, the combination of Transformers, Habana Gaudi, and AWS instances is powerful, simple, and cost-effective. Give it a try and let us know what you think. We definitely welcome your questions and feedback on the [Hugging Face Forum](https://discuss.huggingface.co/).
---
*Please [reach out to Habana](https://developer.habana.ai/accelerate-transformer-training-on-habana-gaudi-processors-with-hugging-face/) to learn more about training Hugging Face models on Gaudi processors.*
| huggingface/blog/blob/main/getting-started-habana.md |
--
title: "Personal Copilot: Train Your Own Coding Assistant"
thumbnail: /blog/assets/170_personal_copilot/thumbnail.png
authors:
- user: smangrul
- user: sayakpaul
---
# Personal Copilot: Train Your Own Coding Assistant
In the ever-evolving landscape of programming and software development, the quest for efficiency and productivity has led to remarkable innovations. One such innovation is the emergence of code generation models such as [Codex](https://openai.com/blog/openai-codex), [StarCoder](https://arxiv.org/abs/2305.06161) and [Code Llama](https://arxiv.org/abs/2308.12950). These models have demonstrated remarkable capabilities in generating human-like code snippets, thereby showing immense potential as coding assistants.
However, while these pre-trained models can perform impressively across a range of tasks, there's an exciting possibility lying just beyond the horizon: the ability to tailor a code generation model to your specific needs. Think of personalized coding assistants which could be leveraged at an enterprise scale.
In this blog post we show how we created HugCoder 🤗, a code LLM fine-tuned on the code contents from the public repositories of the [`huggingface` GitHub organization](https://github.com/huggingface). We will discuss our data collection workflow, our training experiments, and some interesting results. This will enable you to create your own personal copilot based on your proprietary codebase. We will leave you with a couple of further extensions of this project for experimentation.
Let’s begin 🚀

## Data Collection Workflow
Our desired dataset is conceptually simple, we structured it like so:
| | | |
|---|---|---|
| Repository Name | Filepath in the Repository | File Contents |
|---|---|---|
|---|---|---|
Scraping code contents from GitHub is straightforward with the [Python GitHub API](https://github.com/PyGithub/PyGithub). However, depending on the number of repositories and the number of code files within a repository, one might easily run into API rate-limiting issues.
To prevent such problems, we decided to clone all the public repositories locally and extract the contents from them instead of through the API. We used the `multiprocessing` module from Python to download all repos in parallel, as shown in [this download script](https://github.com/sayakpaul/hf-codegen/blob/main/data/parallel_clone_repos.py).
A repository can often contain non-code files such as images, presentations and other assets. We’re not interested in scraping them. We created a [list of extensions](https://github.com/sayakpaul/hf-codegen/blob/f659eba76f07e622873211e5b975168b634e6c22/data/prepare_dataset.py#L17C1-L49C68) to filter them out. To parse code files other than Jupyter Notebooks, we simply used the "utf-8" encoding. For notebooks, we only considered the code cells.
We also excluded all file paths that were not directly related to code. These include: `.git`, `__pycache__`, and `xcodeproj`.
To keep the serialization of this content relatively memory-friendly, we used chunking and the [feather format](https://arrow.apache.org/docs/python/feather.html#:~:text=Feather%20is%20a%20portable%20file,Python%20(pandas)%20and%20R.). Refer to [this script](https://github.com/sayakpaul/hf-codegen/blob/main/data/prepare_dataset.py) for the full implementation.
The final dataset is [available on the Hub](https://huggingface.co/datasets/sayakpaul/hf-codegen-v2), and it looks like this:
For this blog, we considered the top 10 Hugging Face public repositories, based on stargazers. They are the following:
> ['transformers', 'pytorch-image-models', 'datasets', 'diffusers', 'peft', 'tokenizers', 'accelerate', 'text-generation-inference', 'chat-ui', 'deep-rl-class']
[This is the code we used to generate this dataset](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/dataset_generation), and [this is the dataset in the Hub](https://huggingface.co/datasets/smangrul/hf-stack-v1). Here is a snapshot of what it looks like:
To reduce the project complexity, we didn’t consider deduplication of the dataset. If you are interested in applying deduplication techniques for a production application, [this blog post](https://huggingface.co/blog/dedup) is an excellent resource about the topic in the context of code LLMs.
## Finetuning your own Personal Co-Pilot
In this section, we show how to fine-tune the following models: [`bigcode/starcoder`](https://hf.co/bigcode/starcoder) (15.5B params), [`bigcode/starcoderbase-1b`](https://hf.co/bigcode/starcoderbase-1b) (1B params), [`Deci/DeciCoder-1b`](https://hf.co/Deci/DeciCoder-1b) (1B params). We'll use a single A100 40GB Colab Notebook using 🤗 PEFT (Parameter-Efficient Fine-Tuning) for all the experiments. Additionally, we'll show how to fully finetune the `bigcode/starcoder` (15.5B params) on a machine with 8 A100 80GB GPUs using 🤗 Accelerate's FSDP integration. The training objective is [fill in the middle (FIM)](https://arxiv.org/abs/2207.14255), wherein parts of a training sequence are moved to the end, and the reordered sequence is predicted auto-regressively.
Why PEFT? Full fine-tuning is expensive. Let’s have some numbers to put things in perspective:
Minimum GPU memory required for full fine-tuning:
1. Weight: 2 bytes (Mixed-Precision training)
2. Weight gradient: 2 bytes
3. Optimizer state when using Adam: 4 bytes for original FP32 weight + 8 bytes for first and second moment estimates
4. Cost per parameter adding all of the above: 16 bytes per parameter
5. **15.5B model -> 248GB of GPU memory without even considering huge memory requirements for storing intermediate activations -> minimum 4X A100 80GB GPUs required**
Since the hardware requirements are huge, we'll be using parameter-efficient fine-tuning using [QLoRA](https://arxiv.org/abs/2305.14314). Here are the minimal GPU memory requirements for fine-tuning StarCoder using QLoRA:
> trainable params: 110,428,160 || all params: 15,627,884,544 || trainable%: 0.7066097761926236
1. Base model Weight: 0.5 bytes * 15.51B frozen params = 7.755 GB
2. Adapter weight: 2 bytes * 0.11B trainable params = 0.22GB
3. Weight gradient: 2 bytes * 0.11B trainable params = 0.12GB
4. Optimizer state when using Adam: 4 bytes * 0.11B trainable params * 3 = 1.32GB
5. **Adding all of the above -> 9.51 GB ~10GB -> 1 A100 40GB GPU required** 🤯. The reason for A100 40GB GPU is that the intermediate activations for long sequence lengths of 2048 and batch size of 4 for training lead to higher memory requirements. As we will see below, GPU memory required is 26GB which can be accommodated on A100 40GB GPU. Also, A100 GPUs have better compatibilty with Flash Attention 2.
In the above calculations, we didn't consider memory required for intermediate activation checkpointing which is considerably huge. We leverage Flash Attention V2 and Gradient Checkpointing to overcome this issue.
1. For QLoRA along with flash attention V2 and gradient checkpointing, the total memory occupied by the model on a single A100 40GB GPU is **26 GB** with a **batch size of 4**.
2. For full fine-tuning using FSDP along with Flash Attention V2 and Gradient Checkpointing, the memory occupied per GPU ranges between **70 GB to 77.6 GB** with a **per_gpu_batch_size of 1**.
Please refer to the [model-memory-usage](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) to easily calculate how much vRAM is needed to train and perform big model inference on a model hosted on the 🤗 Hugging Face Hub.
## Full Finetuning
We will look at how to do full fine-tuning of `bigcode/starcoder` (15B params) on 8 A100 80GB GPUs using PyTorch Fully Sharded Data Parallel (FSDP) technique. For more information on FSDP, please refer to [Fine-tuning Llama 2 70B using PyTorch FSDP](https://huggingface.co/blog/ram-efficient-pytorch-fsdp) and [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp).
**Resources**
1. Codebase: [link](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/training). It uses the recently added Flash Attention V2 support in Transformers.
2. FSDP Config: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/configs/fsdp_config.yaml)
3. Model: [bigcode/stacoder](https://huggingface.co/bigcode/starcoder)
4. Dataset: [smangrul/hf-stack-v1](https://huggingface.co/datasets/smangrul/hf-stack-v1)
5. Fine-tuned Model: [smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab](https://huggingface.co/smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab)
The command to launch training is given at [run_fsdp.sh](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/run_fsdp.sh).
```
accelerate launch --config_file "configs/fsdp_config.yaml" train.py \
--model_path "bigcode/starcoder" \
--dataset_name "smangrul/hf-stack-v1" \
--subset "data" \
--data_column "content" \
--split "train" \
--seq_length 2048 \
--max_steps 2000 \
--batch_size 1 \
--gradient_accumulation_steps 2 \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--num_warmup_steps 30 \
--eval_freq 100 \
--save_freq 500 \
--log_freq 25 \
--num_workers 4 \
--bf16 \
--no_fp16 \
--output_dir "starcoder-personal-copilot-A100-40GB-colab" \
--fim_rate 0.5 \
--fim_spm_rate 0.5 \
--use_flash_attn
```
The total training time was **9 Hours**. Taking the cost of $12.00 / hr based on [lambdalabs](https://lambdalabs.com/service/gpu-cloud/pricing) for 8x A100 80GB GPUs, the total cost would be **$108**.
## PEFT
We will look at how to use QLoRA for fine-tuning `bigcode/starcoder` (15B params) on a single A100 40GB GPU using 🤗 PEFT. For more information on QLoRA and PEFT methods, please refer to [Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes) and [🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware](https://huggingface.co/blog/peft).
**Resources**
1. Codebase: [link](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/training). It uses the recently added Flash Attention V2 support in Transformers.
2. Colab notebook: [link](https://colab.research.google.com/drive/1Tz9KKgacppA4S6H4eo_sw43qEaC9lFLs?usp=sharing). Make sure to choose A100 GPU with High RAM setting.
3. Model: [bigcode/stacoder](https://huggingface.co/bigcode/starcoder)
4. Dataset: [smangrul/hf-stack-v1](https://huggingface.co/datasets/smangrul/hf-stack-v1)
5. QLoRA Fine-tuned Model: [smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab](https://huggingface.co/smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab)
The command to launch training is given at [run_peft.sh](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/run_peft.sh). The total training time was **12.5 Hours**. Taking the cost of **$1.10 / hr** based on [lambdalabs](https://lambdalabs.com/service/gpu-cloud/pricing), the total cost would be **$13.75**. That's pretty good 🚀! In terms of cost, it's **7.8X** lower than the cost for full fine-tuning.
## Comparison
The plot below shows the eval loss, train loss and learning rate scheduler for QLoRA vs full fine-tuning. We observe that full fine-tuning leads to slightly lower loss and converges a bit faster compared to QLoRA. The learning rate for peft fine-tuning is 10X more than that of full fine-tuning.
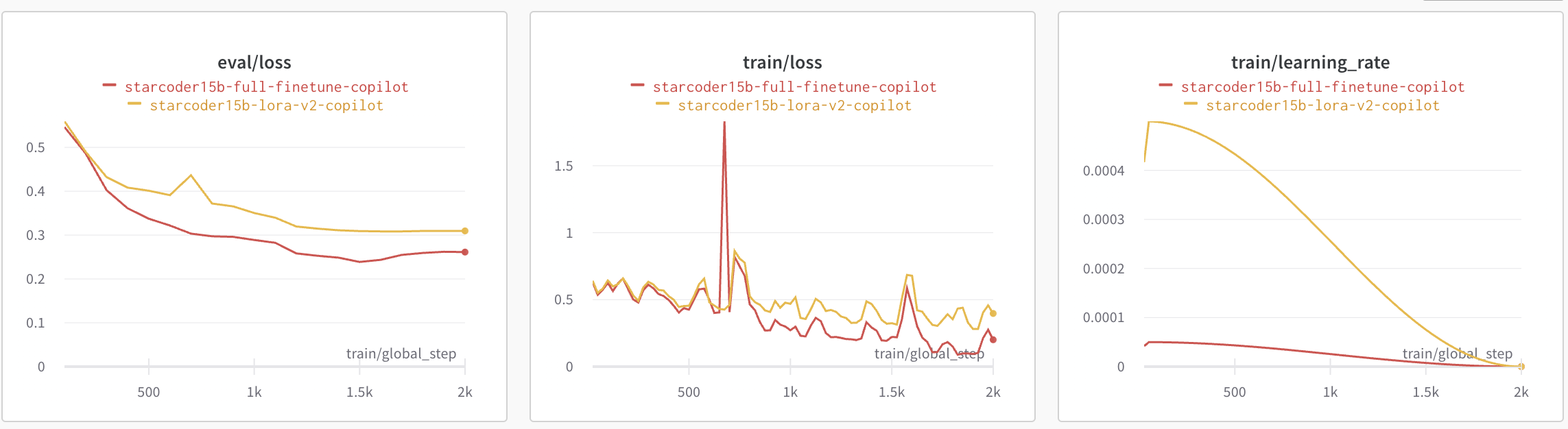
To make sure that our QLoRA model doesn't lead to catastrophic forgetting, we run the Python Human Eval on it. Below are the results we got. `Pass@1` measures the pass rate of completions considering just a single generated code candidate per problem. We can observe that the performance on `humaneval-python` is comparable between the base `bigcode/starcoder` (15B params) and the fine-tuned PEFT model `smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab`.
| | |
|---|---|
| Model | Pass@1 |
|bigcode/starcoder | 33.57|
|smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab| 33.37 |
Let's now look at some qualitative samples. In our manual analysis, we noticed that the QLoRA led to slight overfitting and as such we down weigh it by creating new weighted adapter with weight 0.8 via `add_weighted_adapter` utility of PEFT.
We will look at 2 code infilling examples wherein the task of the model is to fill the part denoted by the `<FILL_ME>` placeholder. We will consider infilling completions from GitHub Copilot, the QLoRA fine-tuned model and the full fine-tuned model.

*Qualitative Example 1*
In the example above, the completion from GitHub Copilot is along the correct lines but doesn't help much. On the other hand, completions from QLoRA and full fine-tuned models are correctly infilling the entire function call with the necessary parameters. However, they are also adding a lot more noise afterwards. This could be controlled with a post-processing step to limit completions to closing brackets or new lines. Note that both QLoRA and full fine-tuned models produce results with similar quality.

Qualitative Example 2
In the second example above, **GitHub Copilot didn't give any completion**. This can be due to the fact that 🤗 PEFT is a recent library and not yet part of Copilot's training data, which **is exactly the type of problem we are trying to address**. On the other hand, completions from QLoRA and full fine-tuned models are correctly infilling the entire function call with the necessary parameters. Again, note that both the QLoRA and the full fine-tuned models are giving generations of similar quality. Inference Code with various examples for full fine-tuned model and peft model are available at [Full_Finetuned_StarCoder_Inference.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/Full_Finetuned_StarCoder_Inference.ipynb) and [PEFT_StarCoder_Inference.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/PEFT_StarCoder_Inference.ipynb), respectively.
Therefore, we can observe that the generations from both the variants are as per expectations. Awesome! 🚀
## How do I use it in VS Code?
You can easily configure a custom code-completion LLM in VS Code using 🤗 [llm-vscode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) VS Code Extension, together with hosting the model via [🤗 Inference EndPoints](https://ui.endpoints.huggingface.co/). We'll go through the required steps below. You can learn more details about deploying an endpoint in the [inference endpoints documentation](https://huggingface.co/docs/inference-endpoints/index).
### Setting an Inference Endpoint
Below are the screenshots with the steps we followed to create our custom Inference Endpoint. We used our QLoRA model, exported as a full-sized _merged_ model that can be easily loaded in `transformers`.
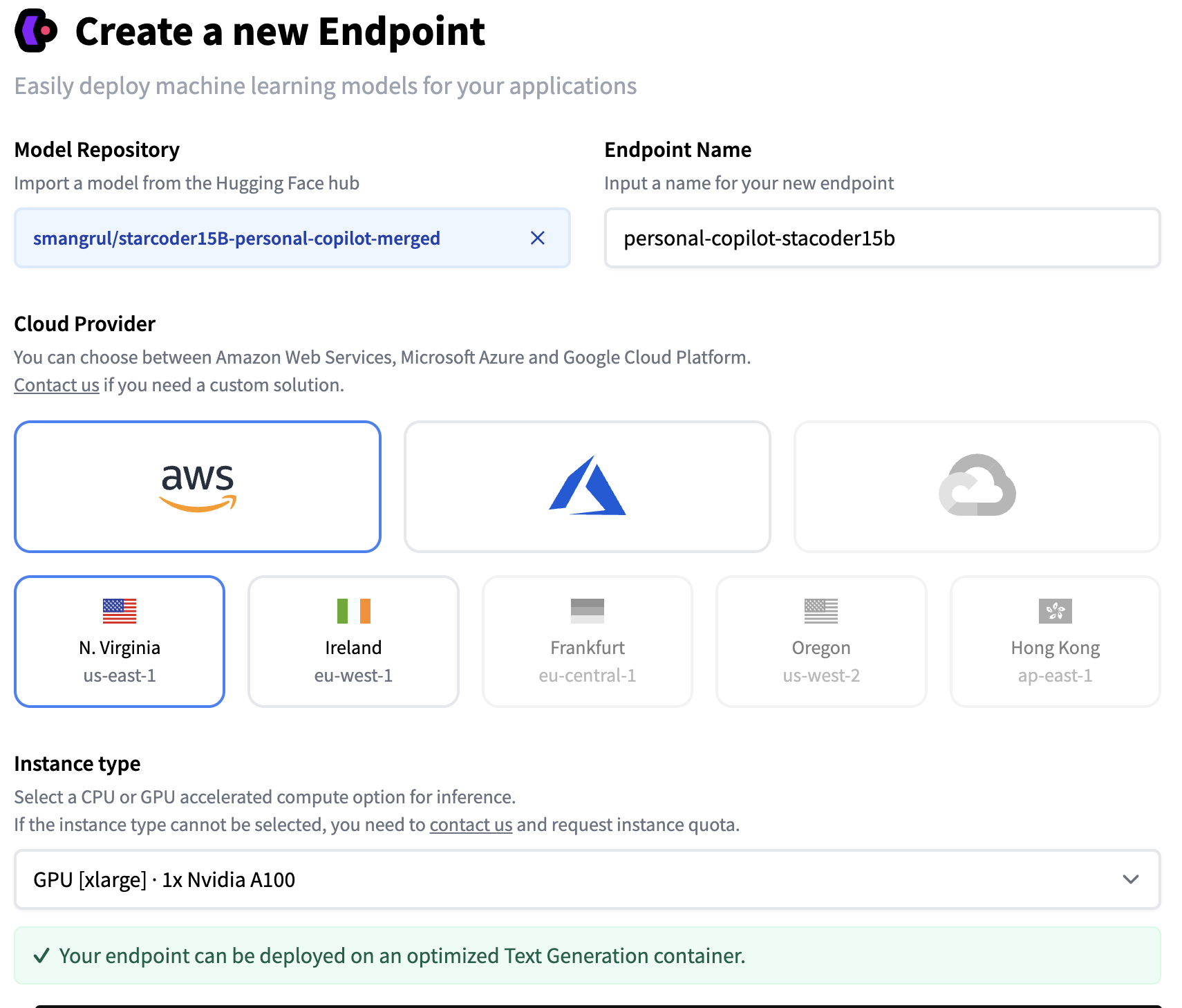
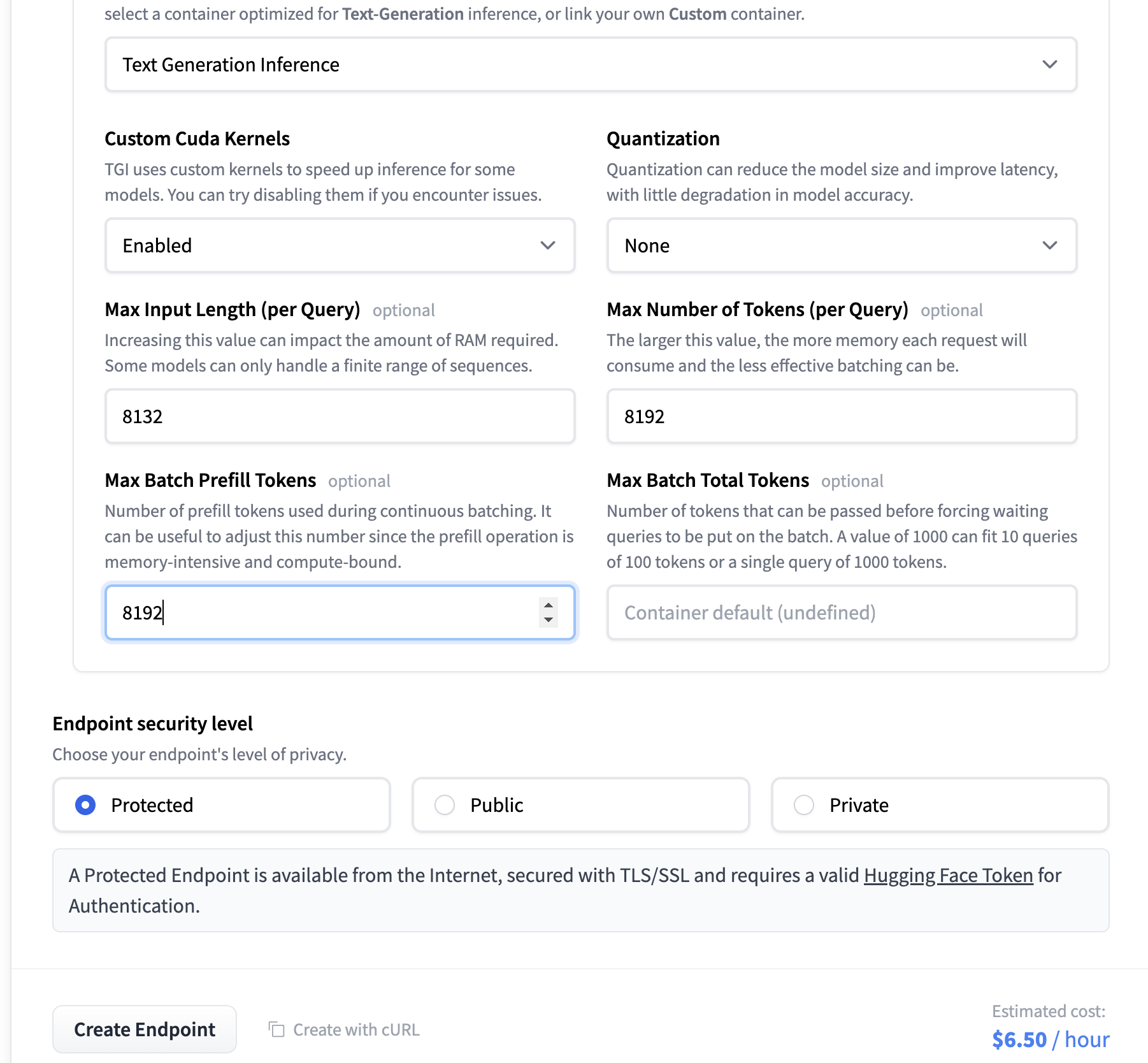
### Setting up the VS Code Extension
Just follow the [installation steps](https://github.com/huggingface/llm-vscode#installation). In the settings, replace the endpoint in the field below, so it points to the HF Inference Endpoint you deployed.
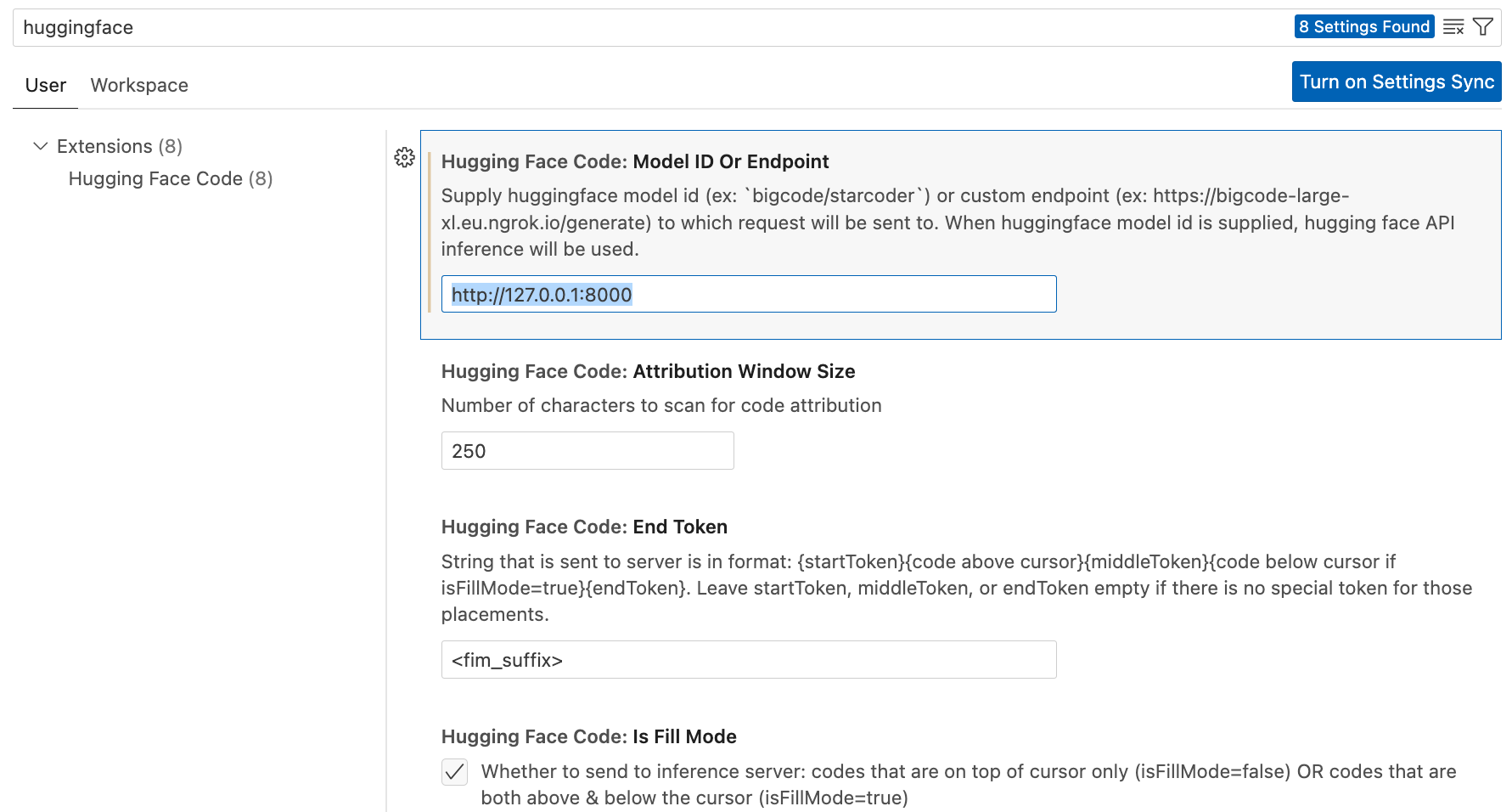
Usage will look like below:
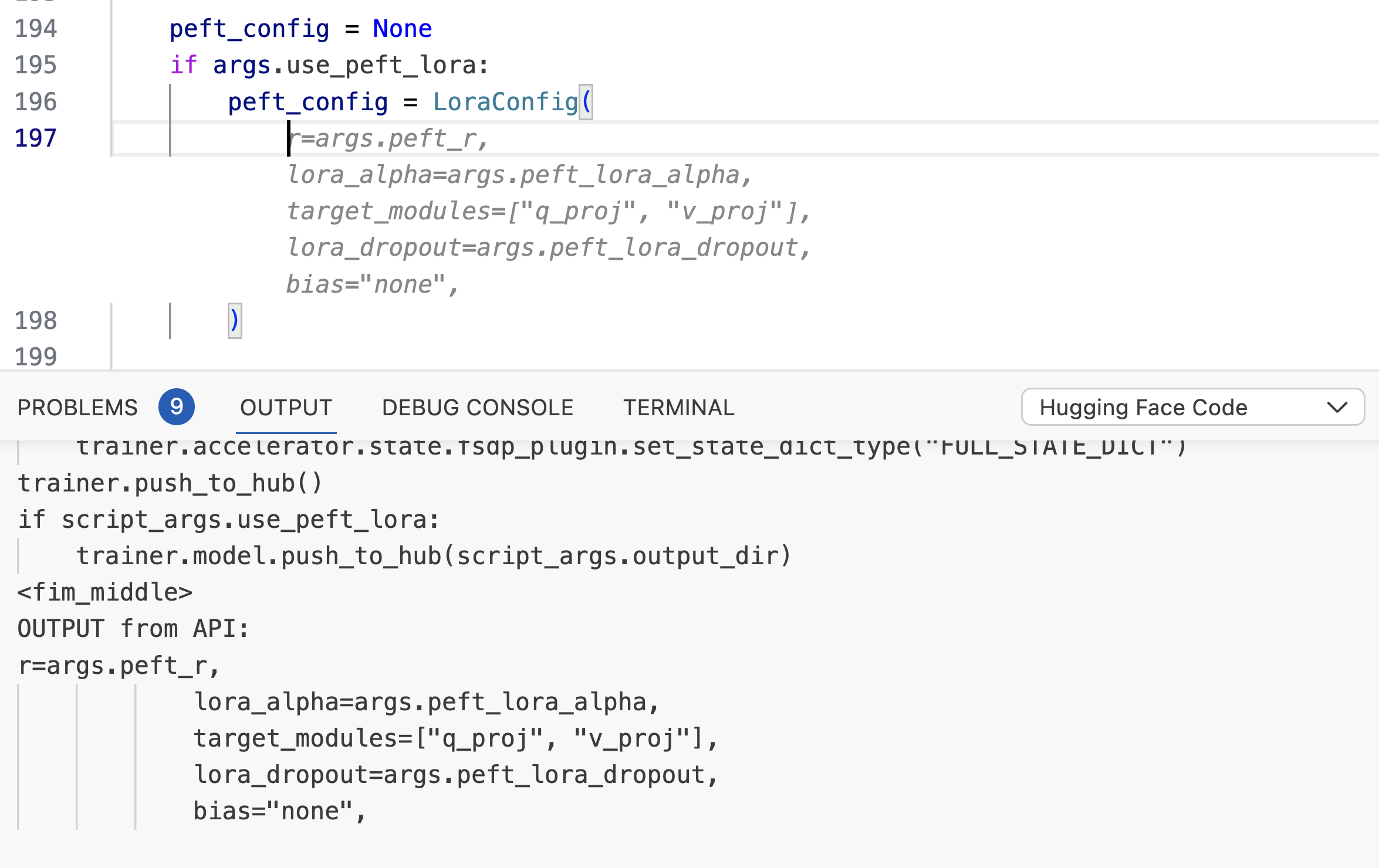
# Finetuning your own Code Chat Assistant
So far, the models we trained were specifically trained as personal co-pilot for code completion tasks. They aren't trained to carry out conversations or for question answering. `Octocoder` and `StarChat` are great examples of such models. This section briefly describes how to achieve that.
**Resources**
1. Codebase: [link](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/code_assistant/training). It uses the recently added Flash Attention V2 support in Transformers.
2. Colab notebook: [link](https://colab.research.google.com/drive/1XFyePK-3IoyX81RM94JO73CcIZtAU4i4?usp=sharing). Make sure to choose A100 GPU with High RAM setting.
3. Model: [bigcode/stacoderplus](https://huggingface.co/bigcode/starcoderplus)
4. Dataset: [smangrul/code-chat-assistant-v1](https://huggingface.co/datasets/smangrul/code-chat-assistant-v1). Mix of `LIMA+GUANACO` with proper formatting in a ready-to-train format.
5. Trained Model: [smangrul/peft-lora-starcoderplus-chat-asst-A100-40GB-colab](https://huggingface.co/smangrul/peft-lora-starcoderplus-chat-asst-A100-40GB-colab)
# Dance of LoRAs
If you have dabbled with Stable Diffusion models and LoRAs for making your own Dreambooth models, you might be familiar with the concepts of combining different LoRAs with different weights, using a LoRA model with a different base model than the one on which it was trained. In text/code domain, this remains unexplored territory. We carry out experiments in this regard and have observed very promising findings. Are you ready? Let's go! 🚀
## Mix-and-Match LoRAs
PEFT currently supports 3 ways of combining LoRA models, `linear`, `svd` and `cat`. For more details, refer to [tuners#peft.LoraModel.add_weighted_adapter](https://huggingface.co/docs/peft/main/en/package_reference/tuners#peft.LoraModel.add_weighted_adapter).
Our notebook [Dance_of_LoRAs.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/Dance_of_LoRAs.ipynb) includes all the inference code and various LoRA loading combinations, like loading the chat assistant on top of `starcoder` instead of `starcodeplus`, which is the base model that we fine-tuned.
Here, we will consider 2 abilities (`chatting/QA` and `code-completion`) on 2 data distributions (`top 10 public hf codebase` and `generic codebase`). That gives us 4 axes on which we'll carry out some qualitative evaluation analyses.
#### First, let us consider the `chatting/QA` task.
If we disable adapters, we observe that the task fails for both datasets, as the base model (`starcoder`) is only meant for code completion and not suitable for `chatting/question-answering`. Enabling `copilot` adapter performs similar to the disabled case because this LoRA was also specifically fine-tuned for code-completion.
Now, let's enable the `assistant` adapter.
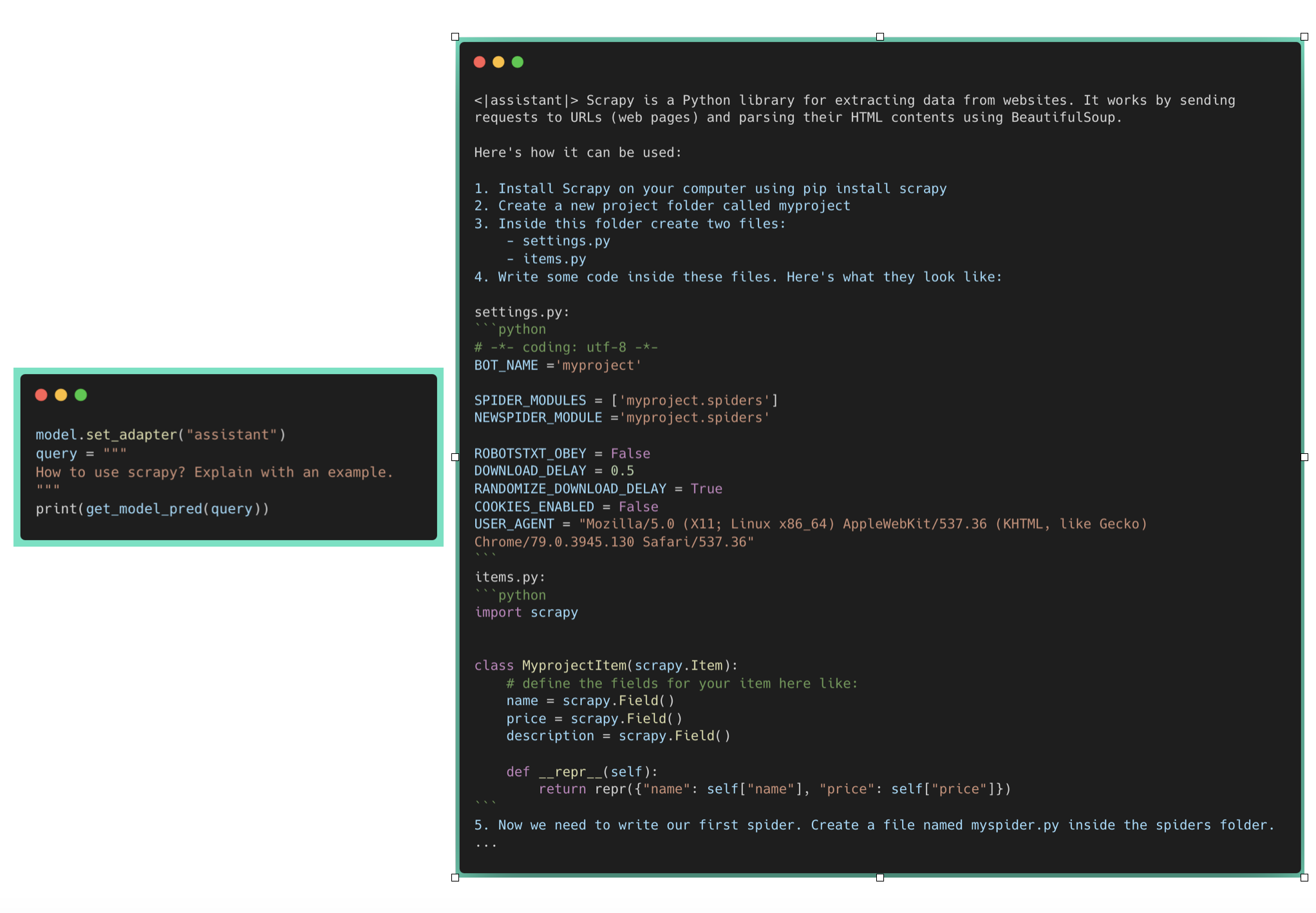
Question Answering based on generic code

Question Answering based on HF code
We can observe that generic question regarding `scrapy` is being answered properly. However, it is failing for the HF code related question which wasn't part of its pretraining data.
##### Let us now consider the `code-completion` task.
On disabling adapters, we observe that the code completion for the generic two-sum works as expected. However, the HF code completion fails with wrong params to `LoraConfig`, because the base model hasn't seen it in its pretraining data. Enabling `assistant` performs similar to the disabled case as it was trained on natural language conversations which didn't have any Hugging Face code repos.
Now, let's enable the `copilot` adapter.

We can observe that the `copilot` adapter gets it right in both cases. Therefore, it performs as expected for code-completions when working with HF specific codebase as well as generic codebases.
**Now, as a user, I want to combine the ability of `assistant` as well as `copilot`. This will enable me to use it for code completion while coding in an IDE, and also have it as a chatbot to answer my questions regarding APIs, classes, methods, documentation. It should be able to provide answers to questions like `How do I use x`, `Please write a code snippet for Y` on my codebase.**
PEFT allows you to do it via `add_weighted_adapter`. Let's create a new adapter `code_buddy` with equal weights to `assistant` and `copilot` adapters.

Combining Multiple Adapters
Now, let's see how `code_buddy` performs on the `chatting/question_answering` tasks.
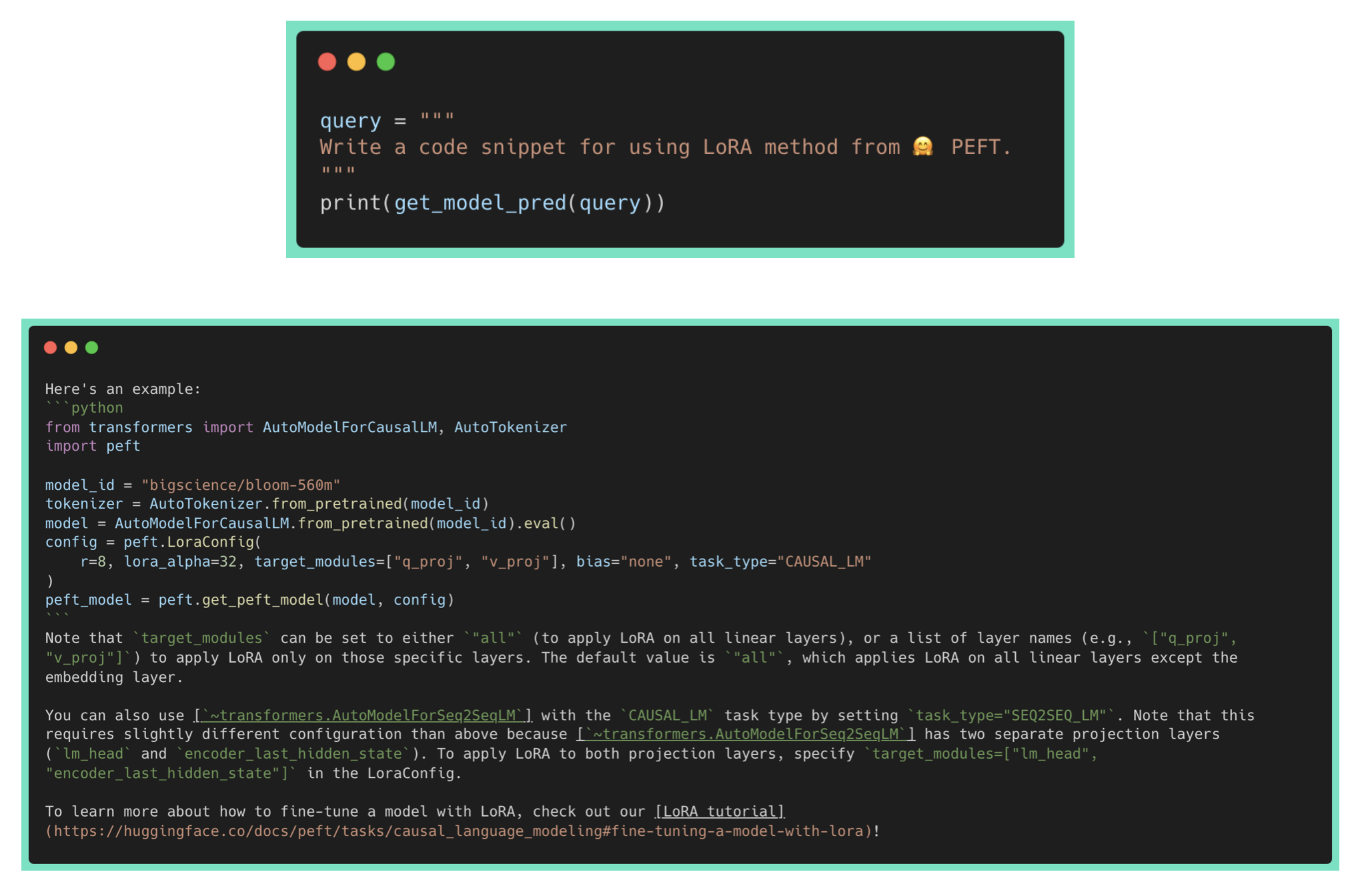
We can observe that `code_buddy` is performing much better than the `assistant` or `copilot` adapters alone! It is able to answer the _write a code snippet_ request to show how to use a specific HF repo API. However, it is also hallucinating the wrong links/explanations, which remains an open challenge for LLMs.
Below is the performance of `code_buddy` on code completion tasks.

We can observe that `code_buddy` is performing on par with `copilot`, which was specifically finetuned for this task.
## Transfer LoRAs to different base models
We can also transfer the LoRA models to different base models.
We will take the hot-off-the-press `Octocoder` model and apply on it the LoRA we trained above with `starcoder` base model. Please go through the following notebook [PEFT_Personal_Code_CoPilot_Adapter_Transfer_Octocoder.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/PEFT_Personal_Code_CoPilot_Adapter_Transfer_Octocoder.ipynb) for the entire code.
**Performance on the Code Completion task**

We can observe that `octocoder` is performing great. It is able to complete HF specific code snippets. It is also able to complete generic code snippets as seen in the notebook.
**Performance on the Chatting/QA task**
As Octocoder is trained to answer questions and carry out conversations about coding, let's see if it can use our LoRA adapter to answer HF specific questions.
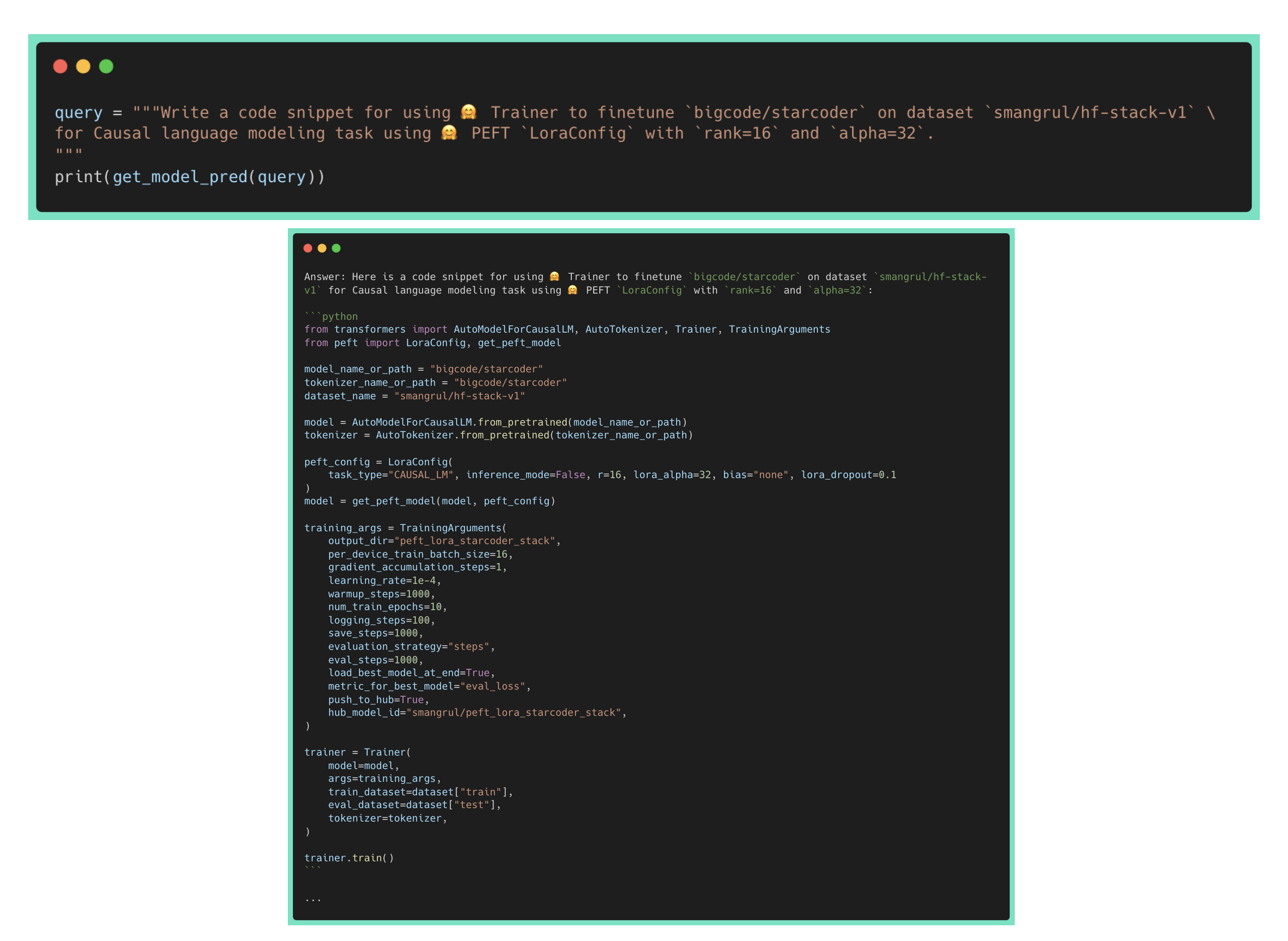
Yay! It correctly answers in detail how to create `LoraConfig` and related peft model along with correctly using the model name, dataset name as well as param values of LoraConfig. On disabling the adapter, it fails to correctly use the API of `LoraConfig` or to create a PEFT model, suggesting that it isn't part of the training data of Octocoder.
# How do I run it locally?
I know, after all this, you want to finetune starcoder on your codebase and use it locally on your consumer hardware such as Mac laptops with M1 GPUs, windows with RTX 4090/3090 GPUs ...
Don't worry, we have got you covered.
We will be using this super cool open source library [mlc-llm](https://github.com/mlc-ai/mlc-llm) 🔥. Specifically, we will be using this fork [pacman100/mlc-llm](https://github.com/pacman100/mlc-llm) which has changes to get it working with the Hugging Face Code Completion extension for VS Code. On my Mac latop with M1 Metal GPU, the 15B model was painfully slow. Hence, we will go small and train a PEFT LoRA version as well as a full finetuned version of `bigcode/starcoderbase-1b`. The training colab notebooks are linked below:
1. Colab notebook for Full fine-tuning and PEFT LoRA finetuning of `starcoderbase-1b`: [link](https://colab.research.google.com/drive/1tTdvc2buL3Iy1PKwrG_bBIDP06DC9r5m?usp=sharing)
The training loss, evaluation loss as well as learning rate schedules are plotted below:
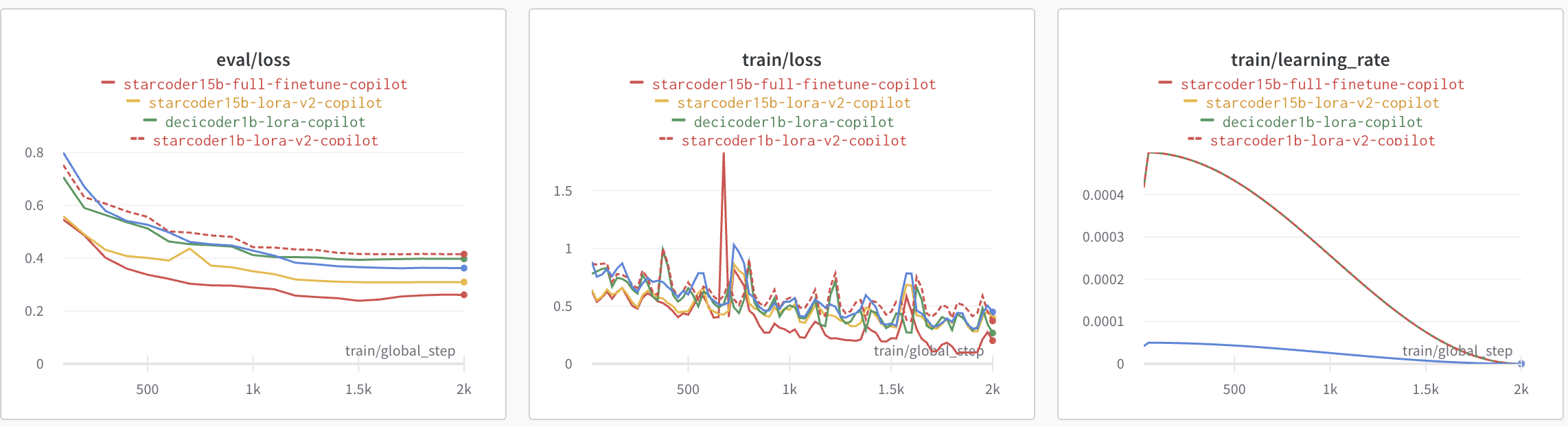
Now, we will look at detailed steps for locally hosting the merged model [smangrul/starcoder1B-v2-personal-copilot-merged](https://huggingface.co/smangrul/starcoder1B-v2-personal-copilot-merged) and using it with 🤗 [llm-vscode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) VS Code Extension.
1. Clone the repo
```
git clone --recursive https://github.com/pacman100/mlc-llm.git && cd mlc-llm/
```
2. Install the mlc-ai and mlc-chat (in editable mode) :
```
pip install --pre --force-reinstall mlc-ai-nightly mlc-chat-nightly -f https://mlc.ai/wheels
cd python
pip uninstall mlc-chat-nightly
pip install -e "."
```
3. Compile the model via:
```
time python3 -m mlc_llm.build --hf-path smangrul/starcoder1B-v2-personal-copilot-merged --target metal --use-cache=0
```
4. Update the config with the following values in `dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/params/mlc-chat-config.json`:
```diff
{
"model_lib": "starcoder7B-personal-copilot-merged-q4f16_1",
"local_id": "starcoder7B-personal-copilot-merged-q4f16_1",
"conv_template": "code_gpt",
- "temperature": 0.7,
+ "temperature": 0.2,
- "repetition_penalty": 1.0,
"top_p": 0.95,
- "mean_gen_len": 128,
+ "mean_gen_len": 64,
- "max_gen_len": 512,
+ "max_gen_len": 64,
"shift_fill_factor": 0.3,
"tokenizer_files": [
"tokenizer.json",
"merges.txt",
"vocab.json"
],
"model_category": "gpt_bigcode",
"model_name": "starcoder1B-v2-personal-copilot-merged"
}
```
5. Run the local server:
```
python -m mlc_chat.rest --model dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/params --lib-path dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/starcoder1B-v2-personal-copilot-merged-q4f16_1-metal.so
```
6. Change the endpoint of HF Code Completion extension in VS Code to point to the local server:
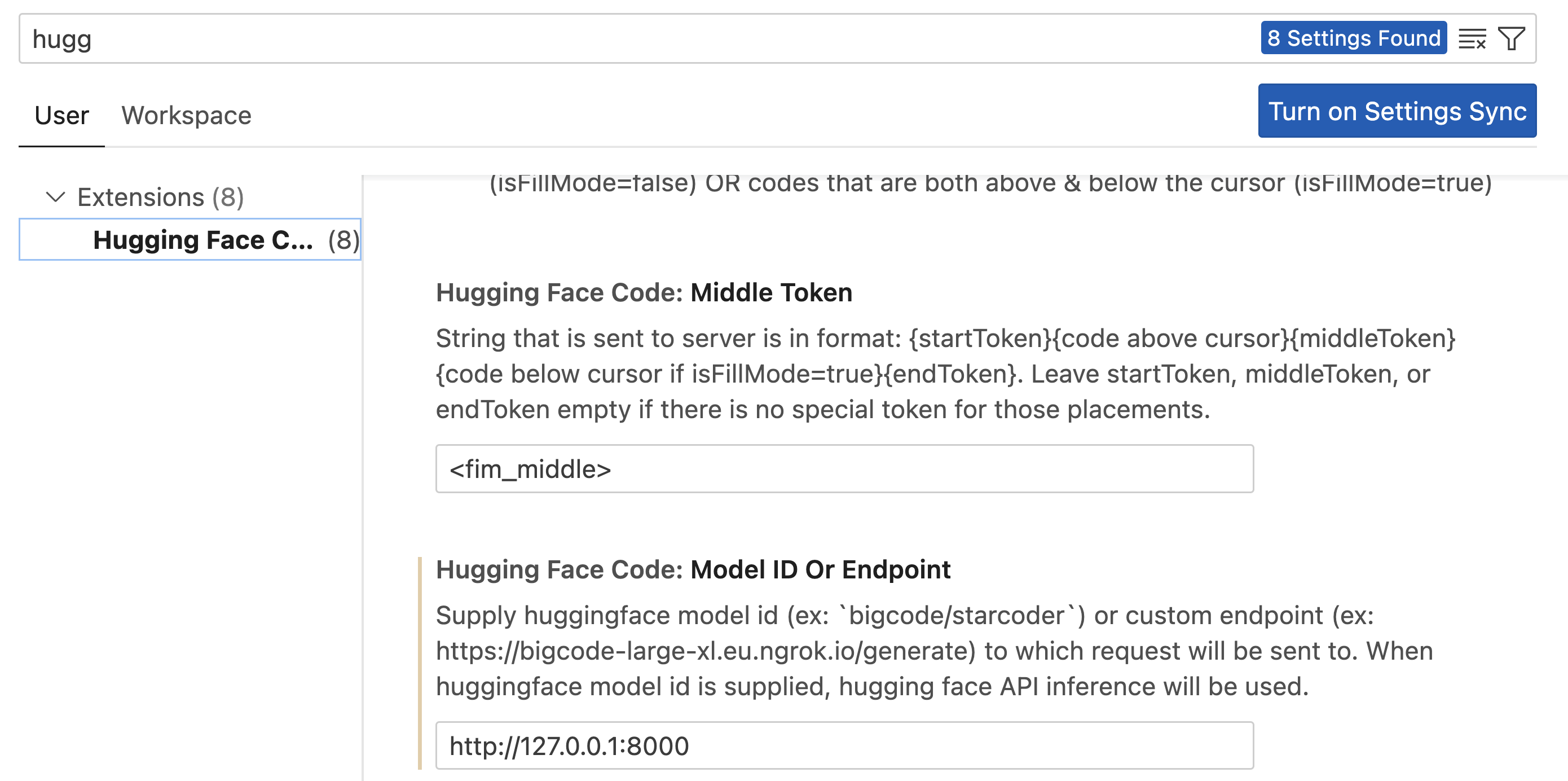
7. Open a new file in VS code, paste the code below and have the cursor in-between the doc quotes, so that the model tries to infill the doc string:
Voila! ⭐️
The demo at the start of this post is this 1B model running locally on my Mac laptop.
## Conclusion
In this blog plost, we saw how to finetune `starcoder` to create a personal co-pilot that knows about our code. We called it 🤗 HugCoder, as we trained it on Hugging Face code :) After looking at the data collection workflow, we compared training using QLoRA vs full fine-tuning. We also experimented by combining different LoRAs, which is still an unexplored technique in the text/code domain. For deployment, we examined remote inference using 🤗 Inference Endpoints, and also showed on-device execution of a smaller model with VS Code and MLC.
Please, let us know if you use these methods for your own codebase!
## Acknowledgements
We would like to thank [Pedro Cuenca](https://github.com/pcuenca), [Leandro von Werra](https://github.com/lvwerra), [Benjamin Bossan](https://github.com/BenjaminBossan), [Sylvain Gugger](https://github.com/sgugger) and [Loubna Ben Allal](https://github.com/loubnabnl) for their help with the writing of this blogpost.
| huggingface/blog/blob/main/personal-copilot.md |
Gradio Demo: progress_component
```
!pip install -q gradio tqdm
```
```
import gradio as gr
import time
def load_set(progress=gr.Progress()):
imgs = [None] * 24
for img in progress.tqdm(imgs, desc="Loading..."):
time.sleep(0.1)
return "Loaded"
with gr.Blocks() as demo:
load = gr.Button("Load")
label = gr.Label(label="Loader")
load.click(load_set, outputs=label)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/progress_component/run.ipynb |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Under construction | huggingface/simulate/blob/main/docs/source/tutorials/interaction.mdx |
n this video we take a look at the mysterious sounding metric called Perplexity. You might have encountered perplexity when reading about generative models. You can see two examples here from the original transformer paper “Attention is all you need” as well as the more recent GPT-2 paper. Perplexity is a common metric to measure the performance of language models. The smaller the value the better the performance. But what does it actually mean and how can we calculate it? A very common quantity in machine learning is the likelihood. We can calculate the likelihood as the product of each token’s probability What this means is that for each token we use the language model to predict its probability based on the previous tokens. In the end we multiply all probabilities to get the Likelihood. With the likelihood we can calculate another important quantity: the cross entropy. You might already have heard about cross-entropy when looking at loss function. Cross-entropy is often used as a loss function in classification. In language modeling we predict the next token which also is a classification task. Therefore, if we want to calculate the cross entropy of an example we can simply pass it to the model with the inputs as labels. The loss return by the model then corresponds the cross entropy. We are now only a single operation away from calculating the perplexity. By exponentiating the cross-entropy we get the perplexity. So you see that the perplexity is closely related to the loss. Keep in mind that the loss is only a weak proxy for a model’s ability to generate quality text and the same is true for perplexity. For this reason one usually also calculates more sophisticated metrics such as BLEU or ROUGE on generative tasks. | huggingface/course/blob/main/subtitles/en/raw/chapter7/03b_perplexity.md |
Gradio Demo: calculator
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('examples')
!wget -q -O examples/log.csv https://github.com/gradio-app/gradio/raw/main/demo/calculator/examples/log.csv
```
```
import gradio as gr
#from foo import BAR
#
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
if num2 == 0:
raise gr.Error("Cannot divide by zero!")
return num1 / num2
demo = gr.Interface(
calculator,
[
"number",
gr.Radio(["add", "subtract", "multiply", "divide"]),
"number"
],
"number",
examples=[
[45, "add", 3],
[3.14, "divide", 2],
[144, "multiply", 2.5],
[0, "subtract", 1.2],
],
title="Toy Calculator",
description="Here's a sample toy calculator. Allows you to calculate things like $2+2=4$",
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/calculator/run.ipynb |
Gradio Demo: cancel_events
```
!pip install -q gradio
```
```
import time
import gradio as gr
def fake_diffusion(steps):
for i in range(steps):
print(f"Current step: {i}")
time.sleep(1)
yield str(i)
def long_prediction(*args, **kwargs):
time.sleep(10)
return 42
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
n = gr.Slider(1, 10, value=9, step=1, label="Number Steps")
run = gr.Button(value="Start Iterating")
output = gr.Textbox(label="Iterative Output")
stop = gr.Button(value="Stop Iterating")
with gr.Column():
textbox = gr.Textbox(label="Prompt")
prediction = gr.Number(label="Expensive Calculation")
run_pred = gr.Button(value="Run Expensive Calculation")
with gr.Column():
cancel_on_change = gr.Textbox(label="Cancel Iteration and Expensive Calculation on Change")
cancel_on_submit = gr.Textbox(label="Cancel Iteration and Expensive Calculation on Submit")
echo = gr.Textbox(label="Echo")
with gr.Row():
with gr.Column():
image = gr.Image(sources=["webcam"], label="Cancel on clear", interactive=True)
with gr.Column():
video = gr.Video(sources=["webcam"], label="Cancel on start recording", interactive=True)
click_event = run.click(fake_diffusion, n, output)
stop.click(fn=None, inputs=None, outputs=None, cancels=[click_event])
pred_event = run_pred.click(fn=long_prediction, inputs=[textbox], outputs=prediction)
cancel_on_change.change(None, None, None, cancels=[click_event, pred_event])
cancel_on_submit.submit(lambda s: s, cancel_on_submit, echo, cancels=[click_event, pred_event])
image.clear(None, None, None, cancels=[click_event, pred_event])
video.start_recording(None, None, None, cancels=[click_event, pred_event])
demo.queue(max_size=20)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/cancel_events/run.ipynb |
--
TODO: Add YAML tags here. Copy-paste the tags obtained with the online tagging app: https://huggingface.co/spaces/huggingface/datasets-tagging
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| huggingface/datasets/blob/main/templates/README.md |
!--Copyright 2023 Mistral AI and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Mistral
## Overview
Mistral-7B-v0.1 is Mistral AI's first Large Language Model (LLM).
### Model Details
Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices:
* Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
* GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
* Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
We also provide an instruction fine-tuned model: `Mistral-7B-Instruct-v0.1` which can be used for chat-based inference.
For more details please read our [release blog post](https://mistral.ai/news/announcing-mistral-7b/)
### License
Both `Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` are released under the Apache 2.0 license.
## Usage tips
`Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` can be found on the [Huggingface Hub](https://huggingface.co/mistralai)
These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
```
Raw weights for `Mistral-7B-v0.1` and `Mistral-7B-Instruct-v0.1` can be downloaded from:
| Model Name | Checkpoint |
|----------------------------|-----------------------------------------------------------------------------------------|
| `Mistral-7B-v0.1` | [Raw Checkpoint](https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-v0.1.tar) |
| `Mistral-7B-Instruct-v0.1` | [Raw Checkpoint](https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-instruct-v0.1.tar) |
To use these raw checkpoints with HuggingFace you can use the `convert_mistral_weights_to_hf.py` script to convert them to the HuggingFace format:
```bash
python src/transformers/models/mistral/convert_mistral_weights_to_hf.py \
--input_dir /path/to/downloaded/mistral/weights --model_size 7B --output_dir /output/path
```
You can then load the converted model from the `output/path`:
```python
from transformers import MistralForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = MistralForCausalLM.from_pretrained("/output/path")
```
## Combining Mistral and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"The expected output"
```
### Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `mistralai/Mistral-7B-v0.1` checkpoint and the Flash Attention 2 version of the model.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/mistral-7b-inference-large-seqlen.png">
</div>
### Sliding window Attention
The current implementation supports the sliding window attention mechanism and memory efficient cache management.
To enable sliding window attention, just make sure to have a `flash-attn` version that is compatible with sliding window attention (`>=2.3.0`).
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (`self.config.sliding_window`), support batched generation only for `padding_side="left"` and use the absolute position of the current token to compute the positional embedding.
## The Mistral Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
## MistralConfig
[[autodoc]] MistralConfig
## MistralModel
[[autodoc]] MistralModel
- forward
## MistralForCausalLM
[[autodoc]] MistralForCausalLM
- forward
## MistralForSequenceClassification
[[autodoc]] MistralForSequenceClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mistral.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# What 🤗 Transformers can do
🤗 Transformers is a library of pretrained state-of-the-art models for natural language processing (NLP), computer vision, and audio and speech processing tasks. Not only does the library contain Transformer models, but it also has non-Transformer models like modern convolutional networks for computer vision tasks. If you look at some of the most popular consumer products today, like smartphones, apps, and televisions, odds are that some kind of deep learning technology is behind it. Want to remove a background object from a picture taken by your smartphone? This is an example of a panoptic segmentation task (don't worry if you don't know what this means yet, we'll describe it in the following sections!).
This page provides an overview of the different speech and audio, computer vision, and NLP tasks that can be solved with the 🤗 Transformers library in just three lines of code!
## Audio
Audio and speech processing tasks are a little different from the other modalities mainly because audio as an input is a continuous signal. Unlike text, a raw audio waveform can't be neatly split into discrete chunks the way a sentence can be divided into words. To get around this, the raw audio signal is typically sampled at regular intervals. If you take more samples within an interval, the sampling rate is higher, and the audio more closely resembles the original audio source.
Previous approaches preprocessed the audio to extract useful features from it. It is now more common to start audio and speech processing tasks by directly feeding the raw audio waveform to a feature encoder to extract an audio representation. This simplifies the preprocessing step and allows the model to learn the most essential features.
### Audio classification
Audio classification is a task that labels audio data from a predefined set of classes. It is a broad category with many specific applications, some of which include:
* acoustic scene classification: label audio with a scene label ("office", "beach", "stadium")
* acoustic event detection: label audio with a sound event label ("car horn", "whale calling", "glass breaking")
* tagging: label audio containing multiple sounds (birdsongs, speaker identification in a meeting)
* music classification: label music with a genre label ("metal", "hip-hop", "country")
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
```
### Automatic speech recognition
Automatic speech recognition (ASR) transcribes speech into text. It is one of the most common audio tasks due partly to speech being such a natural form of human communication. Today, ASR systems are embedded in "smart" technology products like speakers, phones, and cars. We can ask our virtual assistants to play music, set reminders, and tell us the weather.
But one of the key challenges Transformer architectures have helped with is in low-resource languages. By pretraining on large amounts of speech data, finetuning the model on only one hour of labeled speech data in a low-resource language can still produce high-quality results compared to previous ASR systems trained on 100x more labeled data.
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
## Computer vision
One of the first and earliest successful computer vision tasks was recognizing images of zip code numbers using a [convolutional neural network (CNN)](glossary#convolution). An image is composed of pixels, and each pixel has a numerical value. This makes it easy to represent an image as a matrix of pixel values. Each particular combination of pixel values describes the colors of an image.
Two general ways computer vision tasks can be solved are:
1. Use convolutions to learn the hierarchical features of an image from low-level features to high-level abstract things.
2. Split an image into patches and use a Transformer to gradually learn how each image patch is related to each other to form an image. Unlike the bottom-up approach favored by a CNN, this is kind of like starting out with a blurry image and then gradually bringing it into focus.
### Image classification
Image classification labels an entire image from a predefined set of classes. Like most classification tasks, there are many practical use cases for image classification, some of which include:
* healthcare: label medical images to detect disease or monitor patient health
* environment: label satellite images to monitor deforestation, inform wildland management or detect wildfires
* agriculture: label images of crops to monitor plant health or satellite images for land use monitoring
* ecology: label images of animal or plant species to monitor wildlife populations or track endangered species
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
```
### Object detection
Unlike image classification, object detection identifies multiple objects within an image and the objects' positions in an image (defined by the bounding box). Some example applications of object detection include:
* self-driving vehicles: detect everyday traffic objects such as other vehicles, pedestrians, and traffic lights
* remote sensing: disaster monitoring, urban planning, and weather forecasting
* defect detection: detect cracks or structural damage in buildings, and manufacturing defects
```py
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
```
### Image segmentation
Image segmentation is a pixel-level task that assigns every pixel in an image to a class. It differs from object detection, which uses bounding boxes to label and predict objects in an image because segmentation is more granular. Segmentation can detect objects at a pixel-level. There are several types of image segmentation:
* instance segmentation: in addition to labeling the class of an object, it also labels each distinct instance of an object ("dog-1", "dog-2")
* panoptic segmentation: a combination of semantic and instance segmentation; it labels each pixel with a semantic class **and** each distinct instance of an object
Segmentation tasks are helpful in self-driving vehicles to create a pixel-level map of the world around them so they can navigate safely around pedestrians and other vehicles. It is also useful for medical imaging, where the task's finer granularity can help identify abnormal cells or organ features. Image segmentation can also be used in ecommerce to virtually try on clothes or create augmented reality experiences by overlaying objects in the real world through your camera.
```py
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
```
### Depth estimation
Depth estimation predicts the distance of each pixel in an image from the camera. This computer vision task is especially important for scene understanding and reconstruction. For example, in self-driving cars, vehicles need to understand how far objects like pedestrians, traffic signs, and other vehicles are to avoid obstacles and collisions. Depth information is also helpful for constructing 3D representations from 2D images and can be used to create high-quality 3D representations of biological structures or buildings.
There are two approaches to depth estimation:
* stereo: depths are estimated by comparing two images of the same image from slightly different angles
* monocular: depths are estimated from a single image
```py
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
```
## Natural language processing
NLP tasks are among the most common types of tasks because text is such a natural way for us to communicate. To get text into a format recognized by a model, it needs to be tokenized. This means dividing a sequence of text into separate words or subwords (tokens) and then converting these tokens into numbers. As a result, you can represent a sequence of text as a sequence of numbers, and once you have a sequence of numbers, it can be input into a model to solve all sorts of NLP tasks!
### Text classification
Like classification tasks in any modality, text classification labels a sequence of text (it can be sentence-level, a paragraph, or a document) from a predefined set of classes. There are many practical applications for text classification, some of which include:
* sentiment analysis: label text according to some polarity like `positive` or `negative` which can inform and support decision-making in fields like politics, finance, and marketing
* content classification: label text according to some topic to help organize and filter information in news and social media feeds (`weather`, `sports`, `finance`, etc.)
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
```
### Token classification
In any NLP task, text is preprocessed by separating the sequence of text into individual words or subwords. These are known as [tokens](glossary#token). Token classification assigns each token a label from a predefined set of classes.
Two common types of token classification are:
* named entity recognition (NER): label a token according to an entity category like organization, person, location or date. NER is especially popular in biomedical settings, where it can label genes, proteins, and drug names.
* part-of-speech tagging (POS): label a token according to its part-of-speech like noun, verb, or adjective. POS is useful for helping translation systems understand how two identical words are grammatically different (bank as a noun versus bank as a verb).
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
... {
... "entity": pred["entity"],
... "score": round(pred["score"], 4),
... "index": pred["index"],
... "word": pred["word"],
... "start": pred["start"],
... "end": pred["end"],
... }
... for pred in preds
... ]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
```
### Question answering
Question answering is another token-level task that returns an answer to a question, sometimes with context (open-domain) and other times without context (closed-domain). This task happens whenever we ask a virtual assistant something like whether a restaurant is open. It can also provide customer or technical support and help search engines retrieve the relevant information you're asking for.
There are two common types of question answering:
* extractive: given a question and some context, the answer is a span of text from the context the model must extract
* abstractive: given a question and some context, the answer is generated from the context; this approach is handled by the [`Text2TextGenerationPipeline`] instead of the [`QuestionAnsweringPipeline`] shown below
```py
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
... question="What is the name of the repository?",
... context="The name of the repository is huggingface/transformers",
... )
>>> print(
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
... )
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
```
### Summarization
Summarization creates a shorter version of a text from a longer one while trying to preserve most of the meaning of the original document. Summarization is a sequence-to-sequence task; it outputs a shorter text sequence than the input. There are a lot of long-form documents that can be summarized to help readers quickly understand the main points. Legislative bills, legal and financial documents, patents, and scientific papers are a few examples of documents that could be summarized to save readers time and serve as a reading aid.
Like question answering, there are two types of summarization:
* extractive: identify and extract the most important sentences from the original text
* abstractive: generate the target summary (which may include new words not in the input document) from the original text; the [`SummarizationPipeline`] uses the abstractive approach
```py
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
... )
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
```
### Translation
Translation converts a sequence of text in one language to another. It is important in helping people from different backgrounds communicate with each other, help translate content to reach wider audiences, and even be a learning tool to help people learn a new language. Along with summarization, translation is a sequence-to-sequence task, meaning the model receives an input sequence and returns a target output sequence.
In the early days, translation models were mostly monolingual, but recently, there has been increasing interest in multilingual models that can translate between many pairs of languages.
```py
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
```
### Language modeling
Language modeling is a task that predicts a word in a sequence of text. It has become a very popular NLP task because a pretrained language model can be finetuned for many other downstream tasks. Lately, there has been a lot of interest in large language models (LLMs) which demonstrate zero- or few-shot learning. This means the model can solve tasks it wasn't explicitly trained to do! Language models can be used to generate fluent and convincing text, though you need to be careful since the text may not always be accurate.
There are two types of language modeling:
* causal: the model's objective is to predict the next token in a sequence, and future tokens are masked
```py
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
```
* masked: the model's objective is to predict a masked token in a sequence with full access to the tokens in the sequence
```py
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
... {
... "score": round(pred["score"], 4),
... "token": pred["token"],
... "token_str": pred["token_str"],
... "sequence": pred["sequence"],
... }
... for pred in preds
... ]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
```
## Multimodal
Multimodal tasks require a model to process multiple data modalities (text, image, audio, video) to solve a particular problem. Image captioning is an example of a multimodal task where the model takes an image as input and outputs a sequence of text describing the image or some properties of the image.
Although multimodal models work with different data types or modalities, internally, the preprocessing steps help the model convert all the data types into embeddings (vectors or list of numbers that holds meaningful information about the data). For a task like image captioning, the model learns relationships between image embeddings and text embeddings.
### Document question answering
Document question answering is a task that answers natural language questions from a document. Unlike a token-level question answering task which takes text as input, document question answering takes an image of a document as input along with a question about the document and returns an answer. Document question answering can be used to parse structured documents and extract key information from it. In the example below, the total amount and change due can be extracted from a receipt.
```py
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/2/image/image.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
... question="What is the total amount?",
... image=image,
... )
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
```
Hopefully, this page has given you some more background information about all the types of tasks in each modality and the practical importance of each one. In the next [section](tasks_explained), you'll learn **how** 🤗 Transformers work to solve these tasks. | huggingface/transformers/blob/main/docs/source/en/task_summary.md |
--
title: "Hugging Face on PyTorch / XLA TPUs"
thumbnail: /blog/assets/13_pytorch_xla/pytorch_xla_thumbnail.png
authors:
- user: jysohn23
guest: true
- user: lysandre
---
# Hugging Face on PyTorch / XLA TPUs: Faster and cheaper training
<a href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/13_pytorch_xla.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Training Your Favorite Transformers on Cloud TPUs using PyTorch / XLA
The PyTorch-TPU project originated as a collaborative effort between the Facebook PyTorch and Google TPU teams and officially launched at the 2019 PyTorch Developer Conference 2019. Since then, we’ve worked with the Hugging Face team to bring first-class support to training on Cloud TPUs using [PyTorch / XLA](https://github.com/pytorch/xla). This new integration enables PyTorch users to run and scale up their models on Cloud TPUs while maintaining the exact same Hugging Face trainers interface.
This blog post provides an overview of changes made in the Hugging Face library, what the PyTorch / XLA library does, an example to get you started training your favorite transformers on Cloud TPUs, and some performance benchmarks. If you can’t wait to get started with TPUs, please skip ahead to the [“Train Your Transformer on Cloud TPUs”](#train-your-transformer-on-cloud-tpus) section - we handle all the PyTorch / XLA mechanics for you within the `Trainer` module!
### XLA:TPU Device Type
PyTorch / XLA adds a new `xla` device type to PyTorch. This device type works just like other PyTorch device types. For example, here's how to create and print an XLA tensor:
```python
import torch
import torch_xla
import torch_xla.core.xla_model as xm
t = torch.randn(2, 2, device=xm.xla_device())
print(t.device)
print(t)
```
This code should look familiar. PyTorch / XLA uses the same interface as regular PyTorch with a few additions. Importing `torch_xla` initializes PyTorch / XLA, and `xm.xla_device()` returns the current XLA device. This may be a CPU, GPU, or TPU depending on your environment, but for this blog post we’ll focus primarily on TPU.
The `Trainer` module leverages a `TrainingArguments` dataclass in order to define the training specifics. It handles multiple arguments, from batch sizes, learning rate, gradient accumulation and others, to the devices used. Based on the above, in `TrainingArguments._setup_devices()` when using XLA:TPU devices, we simply return the TPU device to be used by the `Trainer`:
```python
@dataclass
class TrainingArguments:
...
@cached_property
@torch_required
def _setup_devices(self) -> Tuple["torch.device", int]:
...
elif is_torch_tpu_available():
device = xm.xla_device()
n_gpu = 0
...
return device, n_gpu
```
### XLA Device Step Computation
In a typical XLA:TPU training scenario we’re training on multiple TPU cores in parallel (a single Cloud TPU device includes 8 TPU cores). So we need to ensure that all the gradients are exchanged between the data parallel replicas by consolidating the gradients and taking an optimizer step. For this we provide the `xm.optimizer_step(optimizer)` which does the gradient consolidation and step-taking. In the Hugging Face trainer, we correspondingly update the train step to use the PyTorch / XLA APIs:
```python
class Trainer:
…
def train(self, *args, **kwargs):
...
if is_torch_tpu_available():
xm.optimizer_step(self.optimizer)
```
### PyTorch / XLA Input Pipeline
There are two main parts to running a PyTorch / XLA model: (1) tracing and executing your model’s graph lazily (refer to below [“PyTorch / XLA Library”](https://github.com/pytorch/xla) section for a more in-depth explanation) and (2) feeding your model. Without any optimization, the tracing/execution of your model and input feeding would be executed serially, leaving chunks of time during which your host CPU and your TPU accelerators would be idle, respectively. To avoid this, we provide an API, which pipelines the two and thus is able to overlap the tracing of step n+1 while step n is still executing.
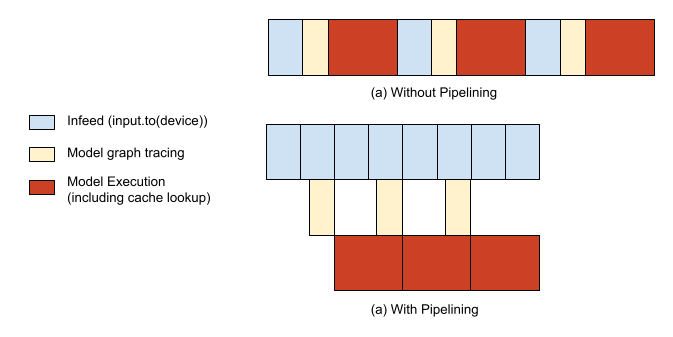
```python
import torch_xla.distributed.parallel_loader as pl
...
dataloader = pl.MpDeviceLoader(dataloader, device)
```
### Checkpoint Writing and Loading
When a tensor is checkpointed from a XLA device and then loaded back from the checkpoint, it will be loaded back to the original device. Before checkpointing tensors in your model, you want to ensure that all of your tensors are on CPU devices instead of XLA devices. This way, when you load back the tensors, you’ll load them through CPU devices and then have the opportunity to place them on whatever XLA devices you desire. We provide the `xm.save()` API for this, which already takes care of only writing to storage location from only one process on each host (or one globally if using a shared file system across hosts).
```python
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):
…
def save_pretrained(self, save_directory):
...
if getattr(self.config, "xla_device", False):
import torch_xla.core.xla_model as xm
if xm.is_master_ordinal():
# Save configuration file
model_to_save.config.save_pretrained(save_directory)
# xm.save takes care of saving only from master
xm.save(state_dict, output_model_file)
```
```python
class Trainer:
…
def train(self, *args, **kwargs):
...
if is_torch_tpu_available():
xm.rendezvous("saving_optimizer_states")
xm.save(self.optimizer.state_dict(),
os.path.join(output_dir, "optimizer.pt"))
xm.save(self.lr_scheduler.state_dict(),
os.path.join(output_dir, "scheduler.pt"))
```
## PyTorch / XLA Library
PyTorch / XLA is a Python package that uses the XLA linear algebra compiler to connect the PyTorch deep learning framework with XLA devices, which includes CPU, GPU, and Cloud TPUs. Part of the following content is also available in our [API_GUIDE.md](https://github.com/pytorch/xla/blob/master/API_GUIDE.md).
### PyTorch / XLA Tensors are Lazy
Using XLA tensors and devices requires changing only a few lines of code. However, even though XLA tensors act a lot like CPU and CUDA tensors, their internals are different. CPU and CUDA tensors launch operations immediately or eagerly. XLA tensors, on the other hand, are lazy. They record operations in a graph until the results are needed. Deferring execution like this lets XLA optimize it. A graph of multiple separate operations might be fused into a single optimized operation.
Lazy execution is generally invisible to the caller. PyTorch / XLA automatically constructs the graphs, sends them to XLA devices, and synchronizes when copying data between an XLA device and the CPU. Inserting a barrier when taking an optimizer step explicitly synchronizes the CPU and the XLA device.
This means that when you call `model(input)` forward pass, calculate your loss `loss.backward()`, and take an optimization step `xm.optimizer_step(optimizer)`, the graph of all operations is being built in the background. Only when you either explicitly evaluate the tensor (ex. Printing the tensor or moving it to a CPU device) or mark a step (this will be done by the `MpDeviceLoader` everytime you iterate through it), does the full step get executed.
### Trace, Compile, Execute, and Repeat
From a user’s point of view, a typical training regimen for a model running on PyTorch / XLA involves running a forward pass, backward pass, and optimizer step. From the PyTorch / XLA library point of view, things look a little different.
While a user runs their forward and backward passes, an intermediate representation (IR) graph is traced on the fly. The IR graph leading to each root/output tensor can be inspected as following:
```python
>>> import torch
>>> import torch_xla
>>> import torch_xla.core.xla_model as xm
>>> t = torch.tensor(1, device=xm.xla_device())
>>> s = t*t
>>> print(torch_xla._XLAC._get_xla_tensors_text([s]))
IR {
%0 = s64[] prim::Constant(), value=1
%1 = s64[] prim::Constant(), value=0
%2 = s64[] xla::as_strided_view_update(%1, %0), size=(), stride=(), storage_offset=0
%3 = s64[] aten::as_strided(%2), size=(), stride=(), storage_offset=0
%4 = s64[] aten::mul(%3, %3), ROOT=0
}
```
This live graph is accumulated while the forward and backward passes are run on the user's program, and once `xm.mark_step()` is called (indirectly by `pl.MpDeviceLoader`), the graph of live tensors is cut. This truncation marks the completion of one step and subsequently we lower the IR graph into XLA Higher Level Operations (HLO), which is the IR language for XLA.
This HLO graph then gets compiled into a TPU binary and subsequently executed on the TPU devices. However, this compilation step can be costly, typically taking longer than a single step, so if we were to compile the user’s program every single step, overhead would be high. To avoid this, we have caches that store compiled TPU binaries keyed by their HLO graphs’ unique hash identifiers. So once this TPU binary cache has been populated on the first step, subsequent steps will typically not have to re-compile new TPU binaries; instead, they can simply look up the necessary binaries from the cache.
Since TPU compilations are typically much slower than the step execution time, this means that if the graph keeps changing in shape, we’ll have cache misses and compile too frequently. To minimize compilation costs, we recommend keeping tensor shapes static whenever possible. Hugging Face library’s shapes are already static for the most part with input tokens being padded appropriately, so throughout training the cache should be consistently hit. This can be checked using the debugging tools that PyTorch / XLA provides. In the example below, you can see that compilation only happened 5 times (`CompileTime`) whereas execution happened during each of 1220 steps (`ExecuteTime`):
```python
>>> import torch_xla.debug.metrics as met
>>> print(met.metrics_report())
Metric: CompileTime
TotalSamples: 5
Accumulator: 28s920ms153.731us
ValueRate: 092ms152.037us / second
Rate: 0.0165028 / second
Percentiles: 1%=428ms053.505us; 5%=428ms053.505us; 10%=428ms053.505us; 20%=03s640ms888.060us; 50%=03s650ms126.150us; 80%=11s110ms545.595us; 90%=11s110ms545.595us; 95%=11s110ms545.595us; 99%=11s110ms545.595us
Metric: DeviceLockWait
TotalSamples: 1281
Accumulator: 38s195ms476.007us
ValueRate: 151ms051.277us / second
Rate: 4.54374 / second
Percentiles: 1%=002.895us; 5%=002.989us; 10%=003.094us; 20%=003.243us; 50%=003.654us; 80%=038ms978.659us; 90%=192ms495.718us; 95%=208ms893.403us; 99%=221ms394.520us
Metric: ExecuteTime
TotalSamples: 1220
Accumulator: 04m22s555ms668.071us
ValueRate: 923ms872.877us / second
Rate: 4.33049 / second
Percentiles: 1%=045ms041.018us; 5%=213ms379.757us; 10%=215ms434.912us; 20%=217ms036.764us; 50%=219ms206.894us; 80%=222ms335.146us; 90%=227ms592.924us; 95%=231ms814.500us; 99%=239ms691.472us
Counter: CachedCompile
Value: 1215
Counter: CreateCompileHandles
Value: 5
...
```
### Train Your Transformer on Cloud TPUs
To configure your VM and Cloud TPUs, please follow [“Set up a Compute Engine instance”](https://cloud.google.com/tpu/docs/tutorials/transformer-pytorch#set_up_a_instance) and [“Launch a Cloud TPU resource”](https://cloud.google.com/tpu/docs/tutorials/transformer-pytorch#launch-tpu) (pytorch-1.7 version as of writing) sections. Once you have your VM and Cloud TPU created, using them is as simple as SSHing to your GCE VM and running the following commands to get `bert-large-uncased` training kicked off (batch size is for v3-8 device, may OOM on v2-8):
```bash
conda activate torch-xla-1.7
export TPU_IP_ADDRESS="ENTER_YOUR_TPU_IP_ADDRESS" # ex. 10.0.0.2
export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470"
git clone -b v4.2.2 https://github.com/huggingface/transformers.git
cd transformers && pip install .
pip install datasets==1.2.1
python examples/xla_spawn.py \
--num_cores 8 \
examples/language-modeling/run_mlm.py \
--dataset_name wikitext \
--dataset_config_name wikitext-103-raw-v1 \
--max_seq_length 512 \
--pad_to_max_length \
--logging_dir ./tensorboard-metrics \
--cache_dir ./cache_dir \
--do_train \
--do_eval \
--overwrite_output_dir \
--output_dir language-modeling \
--overwrite_cache \
--tpu_metrics_debug \
--model_name_or_path bert-large-uncased \
--num_train_epochs 3 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--save_steps 500000
```
The above should complete training in roughly less than 200 minutes with an eval perplexity of ~3.25.
## Performance Benchmarking
The following table shows the performance of training bert-large-uncased on a v3-8 Cloud TPU system (containing 4 TPU v3 chips) running PyTorch / XLA. The dataset used for all benchmarking measurements is the [WikiText103](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/) dataset, and we use the [run_mlm.py](https://github.com/huggingface/transformers/blob/v4.2.2/examples/language-modeling/run_mlm.py) script provided in Hugging Face examples. To ensure that the workloads are not host-CPU-bound, we use the n1-standard-96 CPU configuration for these tests, but you may be able to use smaller configurations as well without impacting performance.
| Name | Dataset | Hardware | Global Batch Size | Precision | Training Time (mins) |
|--------------------|-------------|---------------------------|-------------------|-----------|----------------------|
| bert-large-uncased | WikiText103 | 4 TPUv3 chips (i.e. v3-8) | 64 | FP32 | 178.4 |
| bert-large-uncased | WikiText103 | 4 TPUv3 chips (i.e. v3-8) | 128 | BF16 | 106.4 |
## Get Started with PyTorch / XLA on TPUs
See the [“Running on TPUs”](https://github.com/huggingface/transformers/tree/master/examples#running-on-tpus) section under the Hugging Face examples to get started. For a more detailed description of our APIs, check out our [API_GUIDE](https://github.com/pytorch/xla/blob/master/API_GUIDE.md), and for performance best practices, take a look at our [TROUBLESHOOTING](https://github.com/pytorch/xla/blob/master/TROUBLESHOOTING.md) guide. For generic PyTorch / XLA examples, run the following [Colab Notebooks](https://github.com/pytorch/xla/tree/master/contrib/colab) we offer with free Cloud TPU access. To run directly on GCP, please see our tutorials labeled “PyTorch” on our [documentation site](https://cloud.google.com/tpu/docs/tutorials).
Have any other questions or issues? Please open an issue or question at https://github.com/huggingface/transformers/issues or directly at https://github.com/pytorch/xla/issues.
| huggingface/blog/blob/main/pytorch-xla.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generate the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, in this directory:
```bash
make install
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look like before committing for instance). You don't have to commit the built documentation.
---
## Preview the documentation
Once you have setup the `doc-builder` and additional packages, you can preview the documentation by typing the
following command:
```bash
make preview
```
The documentation is available at http://localhost:3000/.
## Build the documentation
To build the documentation, launch:
```bash
BUILD_DIR=/tmp/doc-datasets-server/ make build
```
You can adapt the `BUILD_DIR` environment variable to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
---
**NOTE**
It's not possible to see locally how the final documentation will look like for now. Once you have opened a PR, you
will see a bot add a comment to a link where the documentation with your changes lives.
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md or .mdx).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/datasets-server/blob/main/docs/source/_toctree.yml) file.
## Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
| huggingface/datasets-server/blob/main/docs/README.md |
Check dataset validity
Before you download a dataset from the Hub, it is helpful to know if a specific dataset you're interested in is available. Datasets Server provides the `/is-valid` endpoint to check if a specific dataset works without any errors.
The API endpoint will return an error for datasets that cannot be loaded with the [🤗 Datasets](https://github.com/huggingface/datasets) library, for example, because the data hasn't been uploaded or the format is not supported.
<Tip warning={true}>
The largest datasets are partially supported by Datasets Server. If they are{" "}
<a href="https://huggingface.co/docs/datasets/stream">streamable</a>, Datasets
Server can extract the first 100 rows without downloading the whole dataset.
This is especially useful for previewing large datasets where downloading the
whole dataset may take hours! See the <code>preview</code> field in the
response of <code>/is-valid</code> to check if a dataset is partially
supported.
</Tip>
This guide shows you how to check dataset validity programmatically, but free to try it out with [Postman](https://www.postman.com/huggingface/workspace/hugging-face-apis/request/23242779-17b761d0-b2b8-4638-a4f7-73be9049c324), [RapidAPI](https://rapidapi.com/hugging-face-hugging-face-default/api/hugging-face-datasets-api), or [ReDoc](https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json#operation/isValidDataset).
## Check if a dataset is valid
`/is-valid` checks whether a specific dataset loads without any error. This endpoint's query parameter requires you to specify the name of the dataset:
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The response looks like this if a dataset is valid:
```json
{
"viewer": true,
"preview": true
}
```
If only the first rows of a dataset are available, then the response looks like:
```json
{
"viewer": false,
"preview": true
}
```
Finally, if the dataset is not valid at all, then the response is:
```json
{
"viewer": false,
"preview": false
}
```
Some cases where a dataset is not valid are:
- the dataset viewer is disabled
- the dataset is gated but the access is not granted: no token is passed or the passed token is not authorized
- the dataset is private
- the dataset contains no data or the data format is not supported
<Tip>
Remember if a dataset is <a href="./quick_start#gated-datasets">gated</a>,
you'll need to provide your user token to submit a successful query!
</Tip>
| huggingface/datasets-server/blob/main/docs/source/valid.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Text-to-image
[[open-in-colab]]
When you think of diffusion models, text-to-image is usually one of the first things that come to mind. Text-to-image generates an image from a text description (for example, "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k") which is also known as a *prompt*.
From a very high level, a diffusion model takes a prompt and some random initial noise, and iteratively removes the noise to construct an image. The *denoising* process is guided by the prompt, and once the denoising process ends after a predetermined number of time steps, the image representation is decoded into an image.
<Tip>
Read the [How does Stable Diffusion work?](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work) blog post to learn more about how a latent diffusion model works.
</Tip>
You can generate images from a prompt in 🤗 Diffusers in two steps:
1. Load a checkpoint into the [`AutoPipelineForText2Image`] class, which automatically detects the appropriate pipeline class to use based on the checkpoint:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
```
2. Pass a prompt to the pipeline to generate an image:
```py
image = pipeline(
"stained glass of darth vader, backlight, centered composition, masterpiece, photorealistic, 8k"
).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-vader.png"/>
</div>
## Popular models
The most common text-to-image models are [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5), [Stable Diffusion XL (SDXL)](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and [Kandinsky 2.2](https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder). There are also ControlNet models or adapters that can be used with text-to-image models for more direct control in generating images. The results from each model are slightly different because of their architecture and training process, but no matter which model you choose, their usage is more or less the same. Let's use the same prompt for each model and compare their results.
### Stable Diffusion v1.5
[Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) is a latent diffusion model initialized from [Stable Diffusion v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4), and finetuned for 595K steps on 512x512 images from the LAION-Aesthetics V2 dataset. You can use this model like:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", generator=generator).images[0]
image
```
### Stable Diffusion XL
SDXL is a much larger version of the previous Stable Diffusion models, and involves a two-stage model process that adds even more details to an image. It also includes some additional *micro-conditionings* to generate high-quality images centered subjects. Take a look at the more comprehensive [SDXL](sdxl) guide to learn more about how to use it. In general, you can use SDXL like:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", generator=generator).images[0]
image
```
### Kandinsky 2.2
The Kandinsky model is a bit different from the Stable Diffusion models because it also uses an image prior model to create embeddings that are used to better align text and images in the diffusion model.
The easiest way to use Kandinsky 2.2 is:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", generator=generator).images[0]
image
```
### ControlNet
ControlNet models are auxiliary models or adapters that are finetuned on top of text-to-image models, such as [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5). Using ControlNet models in combination with text-to-image models offers diverse options for more explicit control over how to generate an image. With ControlNet, you add an additional conditioning input image to the model. For example, if you provide an image of a human pose (usually represented as multiple keypoints that are connected into a skeleton) as a conditioning input, the model generates an image that follows the pose of the image. Check out the more in-depth [ControlNet](controlnet) guide to learn more about other conditioning inputs and how to use them.
In this example, let's condition the ControlNet with a human pose estimation image. Load the ControlNet model pretrained on human pose estimations:
```py
from diffusers import ControlNetModel, AutoPipelineForText2Image
from diffusers.utils import load_image
import torch
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/control_v11p_sd15_openpose", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
pose_image = load_image("https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/control.png")
```
Pass the `controlnet` to the [`AutoPipelineForText2Image`], and provide the prompt and pose estimation image:
```py
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, variant="fp16"
).to("cuda")
generator = torch.Generator("cuda").manual_seed(31)
image = pipeline("Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", image=pose_image, generator=generator).images[0]
image
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-1.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion v1.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion XL</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-2.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Kandinsky 2.2</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-3.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">ControlNet (pose conditioning)</figcaption>
</div>
</div>
## Configure pipeline parameters
There are a number of parameters that can be configured in the pipeline that affect how an image is generated. You can change the image's output size, specify a negative prompt to improve image quality, and more. This section dives deeper into how to use these parameters.
### Height and width
The `height` and `width` parameters control the height and width (in pixels) of the generated image. By default, the Stable Diffusion v1.5 model outputs 512x512 images, but you can change this to any size that is a multiple of 8. For example, to create a rectangular image:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", height=768, width=512
).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-hw.png"/>
</div>
<Tip warning={true}>
Other models may have different default image sizes depending on the image sizes in the training dataset. For example, SDXL's default image size is 1024x1024 and using lower `height` and `width` values may result in lower quality images. Make sure you check the model's API reference first!
</Tip>
### Guidance scale
The `guidance_scale` parameter affects how much the prompt influences image generation. A lower value gives the model "creativity" to generate images that are more loosely related to the prompt. Higher `guidance_scale` values push the model to follow the prompt more closely, and if this value is too high, you may observe some artifacts in the generated image.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", guidance_scale=3.5
).images[0]
image
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-guidance-scale-2.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 2.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-guidance-scale-7.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 7.5</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-guidance-scale-10.5.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guidance_scale = 10.5</figcaption>
</div>
</div>
### Negative prompt
Just like how a prompt guides generation, a *negative prompt* steers the model away from things you don't want the model to generate. This is commonly used to improve overall image quality by removing poor or bad image features such as "low resolution" or "bad details". You can also use a negative prompt to remove or modify the content and style of an image.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
image = pipeline(
prompt="Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
negative_prompt="ugly, deformed, disfigured, poor details, bad anatomy",
).images[0]
image
```
<div class="flex flex-row gap-4">
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-neg-prompt-1.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">negative_prompt = "ugly, deformed, disfigured, poor details, bad anatomy"</figcaption>
</div>
<div class="flex-1">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/text2img-neg-prompt-2.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">negative_prompt = "astronaut"</figcaption>
</div>
</div>
### Generator
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html#generator) object enables reproducibility in a pipeline by setting a manual seed. You can use a `Generator` to generate batches of images and iteratively improve on an image generated from a seed as detailed in the [Improve image quality with deterministic generation](reusing_seeds) guide.
You can set a seed and `Generator` as shown below. Creating an image with a `Generator` should return the same result each time instead of randomly generating a new image.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
generator = torch.Generator(device="cuda").manual_seed(30)
image = pipeline(
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
generator=generator,
).images[0]
image
```
## Control image generation
There are several ways to exert more control over how an image is generated outside of configuring a pipeline's parameters, such as prompt weighting and ControlNet models.
### Prompt weighting
Prompt weighting is a technique for increasing or decreasing the importance of concepts in a prompt to emphasize or minimize certain features in an image. We recommend using the [Compel](https://github.com/damian0815/compel) library to help you generate the weighted prompt embeddings.
<Tip>
Learn how to create the prompt embeddings in the [Prompt weighting](weighted_prompts) guide. This example focuses on how to use the prompt embeddings in the pipeline.
</Tip>
Once you've created the embeddings, you can pass them to the `prompt_embeds` (and `negative_prompt_embeds` if you're using a negative prompt) parameter in the pipeline.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
).to("cuda")
image = pipeline(
prompt_embeds=prompt_embeds, # generated from Compel
negative_prompt_embeds=negative_prompt_embeds, # generated from Compel
).images[0]
```
### ControlNet
As you saw in the [ControlNet](#controlnet) section, these models offer a more flexible and accurate way to generate images by incorporating an additional conditioning image input. Each ControlNet model is pretrained on a particular type of conditioning image to generate new images that resemble it. For example, if you take a ControlNet model pretrained on depth maps, you can give the model a depth map as a conditioning input and it'll generate an image that preserves the spatial information in it. This is quicker and easier than specifying the depth information in a prompt. You can even combine multiple conditioning inputs with a [MultiControlNet](controlnet#multicontrolnet)!
There are many types of conditioning inputs you can use, and 🤗 Diffusers supports ControlNet for Stable Diffusion and SDXL models. Take a look at the more comprehensive [ControlNet](controlnet) guide to learn how you can use these models.
## Optimize
Diffusion models are large, and the iterative nature of denoising an image is computationally expensive and intensive. But this doesn't mean you need access to powerful - or even many - GPUs to use them. There are many optimization techniques for running diffusion models on consumer and free-tier resources. For example, you can load model weights in half-precision to save GPU memory and increase speed or offload the entire model to the GPU to save even more memory.
PyTorch 2.0 also supports a more memory-efficient attention mechanism called [*scaled dot product attention*](../optimization/torch2.0#scaled-dot-product-attention) that is automatically enabled if you're using PyTorch 2.0. You can combine this with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) to speed your code up even more:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16").to("cuda")
pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead", fullgraph=True)
```
For more tips on how to optimize your code to save memory and speed up inference, read the [Memory and speed](../optimization/fp16) and [Torch 2.0](../optimization/torch2.0) guides.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/conditional_image_generation.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Generating the documentation
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
you can install them with the following command, at the root of the code repository:
```bash
pip install -e ".[docs]"
```
Then you need to install our special tool that builds the documentation:
```bash
pip install git+https://github.com/huggingface/doc-builder
```
---
**NOTE**
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
check how they look like before committing for instance). You don't have to commit the built documentation.
---
## Building the documentation
Once you have setup the `doc-builder` and additional packages, you can generate the documentation by typing th
following command:
```bash
doc-builder build simulate docs/source/ --build_dir ~/tmp/test-build
```
You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
Markdown editor.
---
**NOTE**
It's not possible to see locally how the final documentation will look like for now. Once you have opened a PR, you
will see a bot add a comment to a link where the documentation with your changes lives.
---
## Adding a new element to the navigation bar
Accepted files are Markdown (.md or .mdx).
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/master/docs/source/_toctree.yml) file.
## Renaming section headers and moving sections
It helps to keep the old links working when renaming section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums and Social media and it'd be make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
Therefore we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
```
Sections that were moved:
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
```
and of course if you moved it to another file, then:
```
Sections that were moved:
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
```
Use the relative style to link to the new file so that the versioned docs continue to work.
For an example of a rich moved sections set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/master/docs/source/main_classes/trainer.mdx).
## Writing Documentation - Specification
The `huggingface/transformers` documentation follows the
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
although we can write them directly in Markdown.
### Adding a new tutorial
Adding a new tutorial or section is done in two steps:
- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
- Link that file in `./source/_toctree.yml` on the correct toc-tree.
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
depending on the intended targets (beginners, more advanced users or researchers) it should go in section two, three or
four.
### Adding a new model
When adding a new model:
- Create a file `xxx.mdx` or under `./source/model_doc` (don't hesitate to copy an existing file as template).
- Link that file in `./source/_toctree.yml`.
- Write a short overview of the model:
- Overview with paper & authors
- Paper abstract
- Tips and tricks and how to use it best
- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
The order is generally:
- Configuration,
- Tokenizer
- PyTorch base model
- PyTorch head models
- TensorFlow base model
- TensorFlow head models
- Flax base model
- Flax head models
These classes should be added using our Markdown syntax. Usually as follows:
```
## XXXConfig
[[autodoc]] XXXConfig
```
This will include every public method of the configuration that is documented. If for some reason you wish for a method
not to be displayed in the documentation, you can do so by specifying which methods should be in the docs:
```
## XXXTokenizer
[[autodoc]] XXXTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
```
If you just want to add a method that is not documented (for instance magic method like `__call__` are not documented
byt default) you can put the list of methods to add in a list that contains `all`:
```
## XXXTokenizer
[[autodoc]] XXXTokenizer
- all
- __call__
```
### Writing source documentation
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
and objects like True, None or any strings should usually be put in `code`.
When mentioning a class, function or method, it is recommended to use our syntax for internal links so that our tool
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
function to be in the main package.
If you want to create a link to some internal class or function, you need to
provide its path. For instance: \[\`file_utils.ModelOutput\`\]. This will be converted into a link with
`file_utils.ModelOutput` in the description. To get rid of the path and only keep the name of the object you are
linking to in the description, add a ~: \[\`~file_utils.ModelOutput\`\] will generate a link with `ModelOutput` in the description.
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
#### Defining arguments in a method
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon and its
description:
```
Args:
n_layers (`int`): The number of layers of the model.
```
If the description is too long to fit in one line, another indentation is necessary before writing the description
after th argument.
Here's an example showcasing everything so far:
```
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
[`~PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
```
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
following signature:
```
def my_function(x: str = None, a: float = 1):
```
then its documentation should look like this:
```
Args:
x (`str`, *optional*):
This argument controls ...
a (`float`, *optional*, defaults to 1):
This argument is used to ...
```
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
however write as many lines as you want in the indented description (see the example above with `input_ids`).
#### Writing a multi-line code block
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
````
```
# first line of code
# second line
# etc
```
````
We follow the [doctest](https://docs.python.org/3/library/doctest.html) syntax for the examples to automatically test
the results stay consistent with the library.
#### Writing a return block
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
building the return.
Here's an example for a single value return:
```
Returns:
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
```
Here's an example for tuple return, comprising several objects:
```
Returns:
`tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
- **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
```
#### Adding an image
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## Styling the docstring
We have an automatic script running with the `make style` comment that will make sure that:
- the docstrings fully take advantage of the line width
- all code examples are formatted using black, like the code of the Transformers library
This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
recommended to commit your changes before running `make style`, so you can revert the changes done by that script
easily. | huggingface/simulate/blob/main/docs/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Normalized Configurations
Model configuration classes in 🤗 Transformers are not standardized. Although Transformers implements an `attribute_map` attribute that mitigates the issue to some extent, it does not make it easy to reason on common configuration attributes in the code.
[`~optimum.utils.normalized_config.NormalizedConfig`] classes try to fix that by allowing access to the configuration
attribute they wrap in a standardized way.
## Base class
<Tip>
While it is possible to create `NormalizedConfig` subclasses for common use-cases, it is also possible to overwrite
the `original attribute name -> normalized attribute name` mapping directly using the
[`~optimum.utils.normalized_config.NormalizedConfig.with_args`] class method.
</Tip>
[[autodoc]] optimum.utils.normalized_config.NormalizedConfig
## Existing normalized configurations
[[autodoc]] optimum.utils.normalized_config.NormalizedTextConfig
[[autodoc]] optimum.utils.normalized_config.NormalizedSeq2SeqConfig
[[autodoc]] optimum.utils.normalized_config.NormalizedVisionConfig
[[autodoc]] optimum.utils.normalized_config.NormalizedTextAndVisionConfig
| huggingface/optimum/blob/main/docs/source/utils/normalized_config.mdx |
Use with Spark
This document is a quick introduction to using 🤗 Datasets with Spark, with a particular focus on how to load a Spark DataFrame into a [`Dataset`] object.
From there, you have fast access to any element and you can use it as a data loader to train models.
## Load from Spark
A [`Dataset`] object is a wrapper of an Arrow table, which allows fast reads from arrays in the dataset to PyTorch, TensorFlow and JAX tensors.
The Arrow table is memory mapped from disk, which can load datasets bigger than your available RAM.
You can get a [`Dataset`] from a Spark DataFrame using [`Dataset.from_spark`]:
```py
>>> from datasets import Dataset
>>> df = spark.createDataFrame(
... data=[[1, "Elia"], [2, "Teo"], [3, "Fang"]],
... columns=["id", "name"],
... )
>>> ds = Dataset.from_spark(df)
```
The Spark workers write the dataset on disk in a cache directory as Arrow files, and the [`Dataset`] is loaded from there.
Alternatively, you can skip materialization by using [`IterableDataset.from_spark`], which returns an [`IterableDataset`]:
```py
>>> from datasets import IterableDataset
>>> df = spark.createDataFrame(
... data=[[1, "Elia"], [2, "Teo"], [3, "Fang"]],
... columns=["id", "name"],
... )
>>> ds = IterableDataset.from_spark(df)
>>> print(next(iter(ds)))
{"id": 1, "name": "Elia"}
```
### Caching
When using [`Dataset.from_spark`], the resulting [`Dataset`] is cached; if you call [`Dataset.from_spark`] multiple
times on the same DataFrame it won't re-run the Spark job that writes the dataset as Arrow files on disk.
You can set the cache location by passing `cache_dir=` to [`Dataset.from_spark`].
Make sure to use a disk that is available to both your workers and your current machine (the driver).
<Tip warning={true}>
In a different session, a Spark DataFrame doesn't have the same [semantic hash](https://spark.apache.org/docs/3.2.0/api/python/reference/api/pyspark.sql.DataFrame.semanticHash.html), and it will rerun a Spark job and store it in a new cache.
</Tip>
### Feature types
If your dataset is made of images, audio data or N-dimensional arrays, you can specify the `features=` argument in
[`Dataset.from_spark`] (or [`IterableDataset.from_spark`]):
```py
>>> from datasets import Dataset, Features, Image, Value
>>> data = [(0, open("image.png", "rb").read())]
>>> df = spark.createDataFrame(data, "idx: int, image: binary")
>>> # Also works if you have arrays
>>> # data = [(0, np.zeros(shape=(32, 32, 3), dtype=np.int32).tolist())]
>>> # df = spark.createDataFrame(data, "idx: int, image: array<array<array<int>>>")
>>> features = Features({"idx": Value("int64"), "image": Image()})
>>> dataset = Dataset.from_spark(df, features=features)
>>> dataset[0]
{'idx': 0, 'image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32>}
```
You can check the [`Features`] documentation to know about all the feature types available.
| huggingface/datasets/blob/main/docs/source/use_with_spark.mdx |
Decoder models[[decoder-models]]
<CourseFloatingBanner
chapter={1}
classNames="absolute z-10 right-0 top-0"
/>
<Youtube id="d_ixlCubqQw" />
Decoder models use only the decoder of a Transformer model. At each stage, for a given word the attention layers can only access the words positioned before it in the sentence. These models are often called *auto-regressive models*.
The pretraining of decoder models usually revolves around predicting the next word in the sentence.
These models are best suited for tasks involving text generation.
Representatives of this family of models include:
- [CTRL](https://huggingface.co/transformers/model_doc/ctrl.html)
- [GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)
- [GPT-2](https://huggingface.co/transformers/model_doc/gpt2.html)
- [Transformer XL](https://huggingface.co/transformers/model_doc/transfo-xl.html)
| huggingface/course/blob/main/chapters/en/chapter1/6.mdx |
!--Copyright 2021 NVIDIA Corporation and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MegatronGPT2
## Overview
The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular, it
contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
## Usage tips
We have provided pretrained [GPT2-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_lm_345m) checkpoints
for use to evaluate or finetuning downstream tasks.
To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
Alternatively, you can directly download the checkpoints using:
```bash
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O
megatron_gpt2_345m_v0_0.zip
```
Once you have obtained the checkpoint from NVIDIA GPU Cloud (NGC), you have to convert it to a format that will easily
be loaded by Hugging Face Transformers GPT2 implementation.
The following command allows you to do the conversion. We assume that the folder `models/megatron_gpt2` contains
`megatron_gpt2_345m_v0_0.zip` and that the command is run from that folder:
```bash
python3 $PATH_TO_TRANSFORMERS/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py megatron_gpt2_345m_v0_0.zip
```
<Tip>
MegatronGPT2 architecture is the same as OpenAI GPT-2 . Refer to [GPT-2 documentation](gpt2) for information on
configuration classes and their parameters.
</Tip> | huggingface/transformers/blob/main/docs/source/en/model_doc/megatron_gpt2.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Diffusion 2
Stable Diffusion 2 is a text-to-image _latent diffusion_ model built upon the work of the original [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release), and it was led by Robin Rombach and Katherine Crowson from [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
*The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases. The text-to-image models in this release can generate images with default resolutions of both 512x512 pixels and 768x768 pixels.
These models are trained on an aesthetic subset of the [LAION-5B dataset](https://laion.ai/blog/laion-5b/) created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using [LAION’s NSFW filter](https://openreview.net/forum?id=M3Y74vmsMcY).*
For more details about how Stable Diffusion 2 works and how it differs from the original Stable Diffusion, please refer to the official [announcement post](https://stability.ai/blog/stable-diffusion-v2-release).
The architecture of Stable Diffusion 2 is more or less identical to the original [Stable Diffusion model](./text2img) so check out it's API documentation for how to use Stable Diffusion 2. We recommend using the [`DPMSolverMultistepScheduler`] as it gives a reasonable speed/quality trade-off and can be run with as little as 20 steps.
Stable Diffusion 2 is available for tasks like text-to-image, inpainting, super-resolution, and depth-to-image:
| Task | Repository |
|-------------------------|---------------------------------------------------------------------------------------------------------------|
| text-to-image (512x512) | [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) |
| text-to-image (768x768) | [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) |
| inpainting | [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) |
| super-resolution | [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) |
| depth-to-image | [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) |
Here are some examples for how to use Stable Diffusion 2 for each task:
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## Text-to-image
```py
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
import torch
repo_id = "stabilityai/stable-diffusion-2-base"
pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "High quality photo of an astronaut riding a horse in space"
image = pipe(prompt, num_inference_steps=25).images[0]
image
```
## Inpainting
```py
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import load_image, make_image_grid
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url).resize((512, 512))
mask_image = load_image(mask_url).resize((512, 512))
repo_id = "stabilityai/stable-diffusion-2-inpainting"
pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image, num_inference_steps=25).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```
## Super-resolution
```py
from diffusers import StableDiffusionUpscalePipeline
from diffusers.utils import load_image, make_image_grid
import torch
# load model and scheduler
model_id = "stabilityai/stable-diffusion-x4-upscaler"
pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")
# let's download an image
url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
low_res_img = load_image(url)
low_res_img = low_res_img.resize((128, 128))
prompt = "a white cat"
upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
make_image_grid([low_res_img.resize((512, 512)), upscaled_image.resize((512, 512))], rows=1, cols=2)
```
## Depth-to-image
```py
import torch
from diffusers import StableDiffusionDepth2ImgPipeline
from diffusers.utils import load_image, make_image_grid
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
).to("cuda")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
init_image = load_image(url)
prompt = "two tigers"
negative_prompt = "bad, deformed, ugly, bad anotomy"
image = pipe(prompt=prompt, image=init_image, negative_prompt=negative_prompt, strength=0.7).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/stable_diffusion_2.md |
n this video, we'll study the encoder architecture. An example of a popular encoder-only architecture is BERT, which is the most popular model of its kind. Let's first start by understanding how it works. We'll use a small example, using three words. We use these as inputs, and pass them through the encoder. We retrieve a numerical representation of each word. Here, for example, the encoder converts the three words “Welcome to NYC” in these three sequences of numbers. The encoder outputs exactly one sequence of numbers per input word. This numerical representation can also be called a "Feature vector", or "Feature tensor".
Let's dive in this representation. It contains one vector per word that was passed through the encoder. Each of these vector is a numerical representation of the word in question. The dimension of that vector is defined by the architecture of the model, for the base BERT model, it is 768. These representations contain the value of a word; but contextualized. For example, the vector attributed to the word "to", isn't the representation of only the "to" word. It also takes into account the words around it, which we call the “context”.As in, it looks to the left context, the word on the left of the one we're studying (here the word "Welcome") and the context on the right (here the word "NYC") and outputs a value for the word, within its context. It is therefore a contextualized value. One could say that the vector of 768 values holds the "meaning" of that word in the text. How it does this is thanks to the self-attention mechanism. The self-attention mechanism relates to different positions (or different words) in a single sequence, in order to compute a representation of that sequence. As we've seen before, this means that the resulting representation of a word has been affected by other words in the sequence. We won't dive into the specifics here, but we'll offer some further readings if you want to get a better understanding at what happens under the hood. So when should one use an encoder? Encoders can be used as standalone models in a wide variety of tasks. For example BERT, arguably the most famous transformer model, is a standalone encoder model and at the time of release, beat the state of the art in many sequence classification tasks, question answering tasks, and masked language modeling, to only cite a few. The idea is that encoders are very powerful at extracting vectors that carry meaningful information about a sequence. This vector can then be handled down the road by additional layers of neurons to make sense of them. Let's take a look at some examples where encoders really shine. First of all, Masked Language Modeling, or MLM. It's the task of predicting a hidden word in a sequence of words. Here, for example, we have hidden the word between "My" and "is". This is one of the objectives with which BERT was trained: it was trained to predict hidden words in a sequence. Encoders shine in this scenario in particular, as bidirectional information is crucial here. If we didn't have the words on the right (is, Sylvain, and the dot), then there is very little chance that BERT would have been able to identify "name" as the correct word. The encoder needs to have a good understanding of the sequence in order to predict a masked word, as even if the text is grammatically correct, It does not necessarily make sense in the context of the sequence. As mentioned earlier, encoders are good at doing sequence classification. Sentiment analysis is an example of a sequence classification task. The model's aim is to identify the sentiment of a sequence – it can range from giving a sequence a rating from one to five stars if doing review analysis, to giving a positive or negative rating to a sequence, which is what is shown here. For example here, given the two sequences, we use the model to compute a prediction and to classify the sequences among these two classes: positive and negative. While the two sequences are very similar, containing the same words, the meaning is different – and the encoder model is able to grasp that difference. | huggingface/course/blob/main/subtitles/en/raw/chapter1/05_encoders.md |
Summarization (Seq2Seq model) training examples
The following example showcases how to finetune a sequence-to-sequence model for summarization
using the JAX/Flax backend.
JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
Models written in JAX/Flax are **immutable** and updated in a purely functional
way which enables simple and efficient model parallelism.
`run_summarization_flax.py` is a lightweight example of how to download and preprocess a dataset from the 🤗 Datasets library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files and you also will find examples of these below.
### Train the model
Next we can run the example script to train the model:
```bash
python run_summarization_flax.py \
--output_dir ./bart-base-xsum \
--model_name_or_path facebook/bart-base \
--tokenizer_name facebook/bart-base \
--dataset_name="xsum" \
--do_train --do_eval --do_predict --predict_with_generate \
--num_train_epochs 6 \
--learning_rate 5e-5 --warmup_steps 0 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--overwrite_output_dir \
--max_source_length 512 --max_target_length 64 \
--push_to_hub
```
This should finish in 37min, with validation loss and ROUGE2 score of 1.7785 and 17.01 respectively after 6 epochs. training statistics can be accessed on [tfhub.de](https://tensorboard.dev/experiment/OcPfOIgXRMSJqYB4RdK2tA/#scalars).
> Note that here we used default `generate` arguments, using arguments specific for `xsum` dataset should give better ROUGE scores.
| huggingface/transformers/blob/main/examples/flax/summarization/README.md |
Gradio Demo: live_with_vars
```
!pip install -q gradio
```
```
import gradio as gr
demo = gr.Interface(
lambda x, y: (x + y if y is not None else x, x + y if y is not None else x),
["textbox", "state"],
["textbox", "state"], live=True)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/live_with_vars/run.ipynb |
FrameworkSwitchCourse {fw} />
# Translation[[translation]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={7}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter7/section4_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter7/section4_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={7}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter7/section4_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter7/section4_tf.ipynb"},
]} />
{/if}
Let's now dive into translation. This is another [sequence-to-sequence task](/course/chapter1/7), which means it's a problem that can be formulated as going from one sequence to another. In that sense the problem is pretty close to [summarization](/course/chapter7/6), and you could adapt what we will see here to other sequence-to-sequence problems such as:
- **Style transfer**: Creating a model that *translates* texts written in a certain style to another (e.g., formal to casual or Shakespearean English to modern English)
- **Generative question answering**: Creating a model that generates answers to questions, given a context
<Youtube id="1JvfrvZgi6c"/>
If you have a big enough corpus of texts in two (or more) languages, you can train a new translation model from scratch like we will in the section on [causal language modeling](/course/chapter7/6). It will be faster, however, to fine-tune an existing translation model, be it a multilingual one like mT5 or mBART that you want to fine-tune to a specific language pair, or even a model specialized for translation from one language to another that you want to fine-tune to your specific corpus.
In this section, we will fine-tune a Marian model pretrained to translate from English to French (since a lot of Hugging Face employees speak both those languages) on the [KDE4 dataset](https://huggingface.co/datasets/kde4), which is a dataset of localized files for the [KDE apps](https://apps.kde.org/). The model we will use has been pretrained on a large corpus of French and English texts taken from the [Opus dataset](https://opus.nlpl.eu/), which actually contains the KDE4 dataset. But even if the pretrained model we use has seen that data during its pretraining, we will see that we can get a better version of it after fine-tuning.
Once we're finished, we will have a model able to make predictions like this one:
<iframe src="https://course-demos-marian-finetuned-kde4-en-to-fr.hf.space" frameBorder="0" height="350" title="Gradio app" class="block dark:hidden container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
<a class="flex justify-center" href="/huggingface-course/marian-finetuned-kde4-en-to-fr">
<img class="block dark:hidden lg:w-3/5" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/modeleval-marian-finetuned-kde4-en-to-fr.png" alt="One-hot encoded labels for question answering."/>
<img class="hidden dark:block lg:w-3/5" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/modeleval-marian-finetuned-kde4-en-to-fr-dark.png" alt="One-hot encoded labels for question answering."/>
</a>
As in the previous sections, you can find the actual model that we'll train and upload to the Hub using the code below and double-check its predictions [here](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
## Preparing the data[[preparing-the-data]]
To fine-tune or train a translation model from scratch, we will need a dataset suitable for the task. As mentioned previously, we'll use the [KDE4 dataset](https://huggingface.co/datasets/kde4) in this section, but you can adapt the code to use your own data quite easily, as long as you have pairs of sentences in the two languages you want to translate from and into. Refer back to [Chapter 5](/course/chapter5) if you need a reminder of how to load your custom data in a `Dataset`.
### The KDE4 dataset[[the-kde4-dataset]]
As usual, we download our dataset using the `load_dataset()` function:
```py
from datasets import load_dataset
raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
```
If you want to work with a different pair of languages, you can specify them by their codes. A total of 92 languages are available for this dataset; you can see them all by expanding the language tags on its [dataset card](https://huggingface.co/datasets/kde4).
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/language_tags.png" alt="Language available for the KDE4 dataset." width="100%">
Let's have a look at the dataset:
```py
raw_datasets
```
```python out
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 210173
})
})
```
We have 210,173 pairs of sentences, but in one single split, so we will need to create our own validation set. As we saw in [Chapter 5](/course/chapter5), a `Dataset` has a `train_test_split()` method that can help us. We'll provide a seed for reproducibility:
```py
split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
split_datasets
```
```python out
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 189155
})
test: Dataset({
features: ['id', 'translation'],
num_rows: 21018
})
})
```
We can rename the `"test"` key to `"validation"` like this:
```py
split_datasets["validation"] = split_datasets.pop("test")
```
Now let's take a look at one element of the dataset:
```py
split_datasets["train"][1]["translation"]
```
```python out
{'en': 'Default to expanded threads',
'fr': 'Par défaut, développer les fils de discussion'}
```
We get a dictionary with two sentences in the pair of languages we requested. One particularity of this dataset full of technical computer science terms is that they are all fully translated in French. However, French engineers leave most computer science-specific words in English when they talk. Here, for instance, the word "threads" might well appear in a French sentence, especially in a technical conversation; but in this dataset it has been translated into the more correct "fils de discussion." The pretrained model we use, which has been pretrained on a larger corpus of French and English sentences, takes the easier option of leaving the word as is:
```py
from transformers import pipeline
model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
translator = pipeline("translation", model=model_checkpoint)
translator("Default to expanded threads")
```
```python out
[{'translation_text': 'Par défaut pour les threads élargis'}]
```
Another example of this behavior can be seen with the word "plugin," which isn't officially a French word but which most native speakers will understand and not bother to translate.
In the KDE4 dataset this word has been translated in French into the more official "module d'extension":
```py
split_datasets["train"][172]["translation"]
```
```python out
{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
```
Our pretrained model, however, sticks with the compact and familiar English word:
```py
translator(
"Unable to import %1 using the OFX importer plugin. This file is not the correct format."
)
```
```python out
[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
```
It will be interesting to see if our fine-tuned model picks up on those particularities of the dataset (spoiler alert: it will).
<Youtube id="0Oxphw4Q9fo"/>
<Tip>
✏️ **Your turn!** Another English word that is often used in French is "email." Find the first sample in the training dataset that uses this word. How is it translated? How does the pretrained model translate the same English sentence?
</Tip>
### Processing the data[[processing-the-data]]
<Youtube id="XAR8jnZZuUs"/>
You should know the drill by now: the texts all need to be converted into sets of token IDs so the model can make sense of them. For this task, we'll need to tokenize both the inputs and the targets. Our first task is to create our `tokenizer` object. As noted earlier, we'll be using a Marian English to French pretrained model. If you are trying this code with another pair of languages, make sure to adapt the model checkpoint. The [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) organization provides more than a thousand models in multiple languages.
```python
from transformers import AutoTokenizer
model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
```
You can also replace the `model_checkpoint` with any other model you prefer from the [Hub](https://huggingface.co/models), or a local folder where you've saved a pretrained model and a tokenizer.
<Tip>
💡 If you are using a multilingual tokenizer such as mBART, mBART-50, or M2M100, you will need to set the language codes of your inputs and targets in the tokenizer by setting `tokenizer.src_lang` and `tokenizer.tgt_lang` to the right values.
</Tip>
The preparation of our data is pretty straightforward. There's just one thing to remember; you need to ensure that the tokenizer processes the targets in the output language (here, French). You can do this by passing the targets to the `text_targets` argument of the tokenizer's `__call__` method.
To see how this works, let's process one sample of each language in the training set:
```python
en_sentence = split_datasets["train"][1]["translation"]["en"]
fr_sentence = split_datasets["train"][1]["translation"]["fr"]
inputs = tokenizer(en_sentence, text_target=fr_sentence)
inputs
```
```python out
{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
```
As we can see, the output contains the input IDs associated with the English sentence, while the IDs associated with the French one are stored in the `labels` field. If you forget to indicate that you are tokenizing labels, they will be tokenized by the input tokenizer, which in the case of a Marian model is not going to go well at all:
```python
wrong_targets = tokenizer(fr_sentence)
print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
```
```python out
['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '</s>']
['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '</s>']
```
As we can see, using the English tokenizer to preprocess a French sentence results in a lot more tokens, since the tokenizer doesn't know any French words (except those that also appear in the English language, like "discussion").
Since `inputs` is a dictionary with our usual keys (input IDs, attention mask, etc.), the last step is to define the preprocessing function we will apply on the datasets:
```python
max_length = 128
def preprocess_function(examples):
inputs = [ex["en"] for ex in examples["translation"]]
targets = [ex["fr"] for ex in examples["translation"]]
model_inputs = tokenizer(
inputs, text_target=targets, max_length=max_length, truncation=True
)
return model_inputs
```
Note that we set the same maximum length for our inputs and outputs. Since the texts we're dealing with seem pretty short, we use 128.
<Tip>
💡 If you are using a T5 model (more specifically, one of the `t5-xxx` checkpoints), the model will expect the text inputs to have a prefix indicating the task at hand, such as `translate: English to French:`.
</Tip>
<Tip warning={true}>
⚠️ We don't pay attention to the attention mask of the targets, as the model won't expect it. Instead, the labels corresponding to a padding token should be set to `-100` so they are ignored in the loss computation. This will be done by our data collator later on since we are applying dynamic padding, but if you use padding here, you should adapt the preprocessing function to set all labels that correspond to the padding token to `-100`.
</Tip>
We can now apply that preprocessing in one go on all the splits of our dataset:
```py
tokenized_datasets = split_datasets.map(
preprocess_function,
batched=True,
remove_columns=split_datasets["train"].column_names,
)
```
Now that the data has been preprocessed, we are ready to fine-tune our pretrained model!
{#if fw === 'pt'}
## Fine-tuning the model with the `Trainer` API[[fine-tuning-the-model-with-the-trainer-api]]
The actual code using the `Trainer` will be the same as before, with just one little change: we use a [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) here, which is a subclass of `Trainer` that will allow us to properly deal with the evaluation, using the `generate()` method to predict outputs from the inputs. We'll dive into that in more detail when we talk about the metric computation.
First things first, we need an actual model to fine-tune. We'll use the usual `AutoModel` API:
```py
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
```
{:else}
## Fine-tuning the model with Keras[[fine-tuning-the-model-with-keras]]
First things first, we need an actual model to fine-tune. We'll use the usual `AutoModel` API:
```py
from transformers import TFAutoModelForSeq2SeqLM
model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
```
<Tip warning={false}>
💡 The `Helsinki-NLP/opus-mt-en-fr` checkpoint only has PyTorch weights, so
you'll get an error if you try to load the model without using the
`from_pt=True` argument in the `from_pretrained()` method. When you specify
`from_pt=True`, the library will automatically download and convert the
PyTorch weights for you. As you can see, it is very simple to switch between
frameworks in 🤗 Transformers!
</Tip>
{/if}
Note that this time we are using a model that was trained on a translation task and can actually be used already, so there is no warning about missing weights or newly initialized ones.
### Data collation[[data-collation]]
We'll need a data collator to deal with the padding for dynamic batching. We can't just use a `DataCollatorWithPadding` like in [Chapter 3](/course/chapter3) in this case, because that only pads the inputs (input IDs, attention mask, and token type IDs). Our labels should also be padded to the maximum length encountered in the labels. And, as mentioned previously, the padding value used to pad the labels should be `-100` and not the padding token of the tokenizer, to make sure those padded values are ignored in the loss computation.
This is all done by a [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq). Like the `DataCollatorWithPadding`, it takes the `tokenizer` used to preprocess the inputs, but it also takes the `model`. This is because this data collator will also be responsible for preparing the decoder input IDs, which are shifted versions of the labels with a special token at the beginning. Since this shift is done slightly differently for different architectures, the `DataCollatorForSeq2Seq` needs to know the `model` object:
{#if fw === 'pt'}
```py
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
```
{:else}
```py
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
```
{/if}
To test this on a few samples, we just call it on a list of examples from our tokenized training set:
```py
batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
batch.keys()
```
```python out
dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
```
We can check our labels have been padded to the maximum length of the batch, using `-100`:
```py
batch["labels"]
```
```python out
tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
-100, -100, -100, -100, -100, -100],
[ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
550, 7032, 5821, 7907, 12649, 0]])
```
And we can also have a look at the decoder input IDs, to see that they are shifted versions of the labels:
```py
batch["decoder_input_ids"]
```
```python out
tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
59513, 59513, 59513, 59513, 59513, 59513],
[59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
817, 550, 7032, 5821, 7907, 12649]])
```
Here are the labels for the first and second elements in our dataset:
```py
for i in range(1, 3):
print(tokenized_datasets["train"][i]["labels"])
```
```python out
[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
```
{#if fw === 'pt'}
We will pass this `data_collator` along to the `Seq2SeqTrainer`. Next, let's have a look at the metric.
{:else}
We can now use this `data_collator` to convert each of our datasets to a `tf.data.Dataset`, ready for training:
```python
tf_train_dataset = model.prepare_tf_dataset(
tokenized_datasets["train"],
collate_fn=data_collator,
shuffle=True,
batch_size=32,
)
tf_eval_dataset = model.prepare_tf_dataset(
tokenized_datasets["validation"],
collate_fn=data_collator,
shuffle=False,
batch_size=16,
)
```
{/if}
### Metrics[[metrics]]
<Youtube id="M05L1DhFqcw"/>
{#if fw === 'pt'}
The feature that `Seq2SeqTrainer` adds to its superclass `Trainer` is the ability to use the `generate()` method during evaluation or prediction. During training, the model will use the `decoder_input_ids` with an attention mask ensuring it does not use the tokens after the token it's trying to predict, to speed up training. During inference we won't be able to use those since we won't have labels, so it's a good idea to evaluate our model with the same setup.
As we saw in [Chapter 1](/course/chapter1/6), the decoder performs inference by predicting tokens one by one -- something that's implemented behind the scenes in 🤗 Transformers by the `generate()` method. The `Seq2SeqTrainer` will let us use that method for evaluation if we set `predict_with_generate=True`.
{/if}
The traditional metric used for translation is the [BLEU score](https://en.wikipedia.org/wiki/BLEU), introduced in [a 2002 article](https://aclanthology.org/P02-1040.pdf) by Kishore Papineni et al. The BLEU score evaluates how close the translations are to their labels. It does not measure the intelligibility or grammatical correctness of the model's generated outputs, but uses statistical rules to ensure that all the words in the generated outputs also appear in the targets. In addition, there are rules that penalize repetitions of the same words if they are not also repeated in the targets (to avoid the model outputting sentences like `"the the the the the"`) and output sentences that are shorter than those in the targets (to avoid the model outputting sentences like `"the"`).
One weakness with BLEU is that it expects the text to already be tokenized, which makes it difficult to compare scores between models that use different tokenizers. So instead, the most commonly used metric for benchmarking translation models today is [SacreBLEU](https://github.com/mjpost/sacrebleu), which addresses this weakness (and others) by standardizing the tokenization step. To use this metric, we first need to install the SacreBLEU library:
```py
!pip install sacrebleu
```
We can then load it via `evaluate.load()` like we did in [Chapter 3](/course/chapter3):
```py
import evaluate
metric = evaluate.load("sacrebleu")
```
This metric will take texts as inputs and targets. It is designed to accept several acceptable targets, as there are often multiple acceptable translations of the same sentence -- the dataset we're using only provides one, but it's not uncommon in NLP to find datasets that give several sentences as labels. So, the predictions should be a list of sentences, but the references should be a list of lists of sentences.
Let's try an example:
```py
predictions = [
"This plugin lets you translate web pages between several languages automatically."
]
references = [
[
"This plugin allows you to automatically translate web pages between several languages."
]
]
metric.compute(predictions=predictions, references=references)
```
```python out
{'score': 46.750469682990165,
'counts': [11, 6, 4, 3],
'totals': [12, 11, 10, 9],
'precisions': [91.67, 54.54, 40.0, 33.33],
'bp': 0.9200444146293233,
'sys_len': 12,
'ref_len': 13}
```
This gets a BLEU score of 46.75, which is rather good -- for reference, the original Transformer model in the ["Attention Is All You Need" paper](https://arxiv.org/pdf/1706.03762.pdf) achieved a BLEU score of 41.8 on a similar translation task between English and French! (For more information about the individual metrics, like `counts` and `bp`, see the [SacreBLEU repository](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74).) On the other hand, if we try with the two bad types of predictions (lots of repetitions or too short) that often come out of translation models, we will get rather bad BLEU scores:
```py
predictions = ["This This This This"]
references = [
[
"This plugin allows you to automatically translate web pages between several languages."
]
]
metric.compute(predictions=predictions, references=references)
```
```python out
{'score': 1.683602693167689,
'counts': [1, 0, 0, 0],
'totals': [4, 3, 2, 1],
'precisions': [25.0, 16.67, 12.5, 12.5],
'bp': 0.10539922456186433,
'sys_len': 4,
'ref_len': 13}
```
```py
predictions = ["This plugin"]
references = [
[
"This plugin allows you to automatically translate web pages between several languages."
]
]
metric.compute(predictions=predictions, references=references)
```
```python out
{'score': 0.0,
'counts': [2, 1, 0, 0],
'totals': [2, 1, 0, 0],
'precisions': [100.0, 100.0, 0.0, 0.0],
'bp': 0.004086771438464067,
'sys_len': 2,
'ref_len': 13}
```
The score can go from 0 to 100, and higher is better.
{#if fw === 'tf'}
To get from the model outputs to texts the metric can use, we will use the `tokenizer.batch_decode()` method. We just have to clean up all the `-100`s in the labels; the tokenizer will automatically do the same for the padding token. Let's define a function that takes our model and a dataset and computes metrics on it. We're also going to use a trick that dramatically increases performance - compiling our generation code with [XLA](https://www.tensorflow.org/xla), TensorFlow's accelerated linear algebra compiler. XLA applies various optimizations to the model's computation graph, and results in significant improvements to speed and memory usage. As described in the Hugging Face [blog](https://huggingface.co/blog/tf-xla-generate), XLA works best when our input shapes don't vary too much. To handle this, we'll pad our inputs to multiples of 128, and make a new dataset with the padding collator, and then we'll apply the `@tf.function(jit_compile=True)` decorator to our generation function, which marks the whole function for compilation with XLA.
```py
import numpy as np
import tensorflow as tf
from tqdm import tqdm
generation_data_collator = DataCollatorForSeq2Seq(
tokenizer, model=model, return_tensors="tf", pad_to_multiple_of=128
)
tf_generate_dataset = model.prepare_tf_dataset(
tokenized_datasets["validation"],
collate_fn=generation_data_collator,
shuffle=False,
batch_size=8,
)
@tf.function(jit_compile=True)
def generate_with_xla(batch):
return model.generate(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
max_new_tokens=128,
)
def compute_metrics():
all_preds = []
all_labels = []
for batch, labels in tqdm(tf_generate_dataset):
predictions = generate_with_xla(batch)
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = labels.numpy()
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
all_preds.extend(decoded_preds)
all_labels.extend(decoded_labels)
result = metric.compute(predictions=all_preds, references=all_labels)
return {"bleu": result["score"]}
```
{:else}
To get from the model outputs to texts the metric can use, we will use the `tokenizer.batch_decode()` method. We just have to clean up all the `-100`s in the labels (the tokenizer will automatically do the same for the padding token):
```py
import numpy as np
def compute_metrics(eval_preds):
preds, labels = eval_preds
# In case the model returns more than the prediction logits
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100s in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
return {"bleu": result["score"]}
```
{/if}
Now that this is done, we are ready to fine-tune our model!
### Fine-tuning the model[[fine-tuning-the-model]]
The first step is to log in to Hugging Face, so you're able to upload your results to the Model Hub. There's a convenience function to help you with this in a notebook:
```python
from huggingface_hub import notebook_login
notebook_login()
```
This will display a widget where you can enter your Hugging Face login credentials.
If you aren't working in a notebook, just type the following line in your terminal:
```bash
huggingface-cli login
```
{#if fw === 'tf'}
Before we start, let's see what kind of results we get from our model without any training:
```py
print(compute_metrics())
```
```
{'bleu': 33.26983701454733}
```
Once this is done, we can prepare everything we need to compile and train our model. Note the use of `tf.keras.mixed_precision.set_global_policy("mixed_float16")` -- this will tell Keras to train using float16, which can give a significant speedup on GPUs that support it (Nvidia 20xx/V100 or newer).
```python
from transformers import create_optimizer
from transformers.keras_callbacks import PushToHubCallback
import tensorflow as tf
# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
num_epochs = 3
num_train_steps = len(tf_train_dataset) * num_epochs
optimizer, schedule = create_optimizer(
init_lr=5e-5,
num_warmup_steps=0,
num_train_steps=num_train_steps,
weight_decay_rate=0.01,
)
model.compile(optimizer=optimizer)
# Train in mixed-precision float16
tf.keras.mixed_precision.set_global_policy("mixed_float16")
```
Next, we define a `PushToHubCallback` to upload our model to the Hub during training, as we saw in [section 2]((/course/chapter7/2)), and then we simply fit the model with that callback:
```python
from transformers.keras_callbacks import PushToHubCallback
callback = PushToHubCallback(
output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
)
model.fit(
tf_train_dataset,
validation_data=tf_eval_dataset,
callbacks=[callback],
epochs=num_epochs,
)
```
Note that you can specify the name of the repository you want to push to with the `hub_model_id` argument (in particular, you will have to use this argument to push to an organization). For instance, when we pushed the model to the [`huggingface-course` organization](https://huggingface.co/huggingface-course), we added `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` to `Seq2SeqTrainingArguments`. By default, the repository used will be in your namespace and named after the output directory you set, so here it will be `"sgugger/marian-finetuned-kde4-en-to-fr"` (which is the model we linked to at the beginning of this section).
<Tip>
💡 If the output directory you are using already exists, it needs to be a local clone of the repository you want to push to. If it isn't, you'll get an error when calling `model.fit()` and will need to set a new name.
</Tip>
Finally, let's see what our metrics look like now that training has finished:
```py
print(compute_metrics())
```
```
{'bleu': 57.334066271545865}
```
At this stage, you can use the inference widget on the Model Hub to test your model and share it with your friends. You have successfully fine-tuned a model on a translation task -- congratulations!
{:else}
Once this is done, we can define our `Seq2SeqTrainingArguments`. Like for the `Trainer`, we use a subclass of `TrainingArguments` that contains a few more fields:
```python
from transformers import Seq2SeqTrainingArguments
args = Seq2SeqTrainingArguments(
f"marian-finetuned-kde4-en-to-fr",
evaluation_strategy="no",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=3,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
```
Apart from the usual hyperparameters (like learning rate, number of epochs, batch size, and some weight decay), here are a few changes compared to what we saw in the previous sections:
- We don't set any regular evaluation, as evaluation takes a while; we will just evaluate our model once before training and after.
- We set `fp16=True`, which speeds up training on modern GPUs.
- We set `predict_with_generate=True`, as discussed above.
- We use `push_to_hub=True` to upload the model to the Hub at the end of each epoch.
Note that you can specify the full name of the repository you want to push to with the `hub_model_id` argument (in particular, you will have to use this argument to push to an organization). For instance, when we pushed the model to the [`huggingface-course` organization](https://huggingface.co/huggingface-course), we added `hub_model_id="huggingface-course/marian-finetuned-kde4-en-to-fr"` to `Seq2SeqTrainingArguments`. By default, the repository used will be in your namespace and named after the output directory you set, so in our case it will be `"sgugger/marian-finetuned-kde4-en-to-fr"` (which is the model we linked to at the beginning of this section).
<Tip>
💡 If the output directory you are using already exists, it needs to be a local clone of the repository you want to push to. If it isn't, you'll get an error when defining your `Seq2SeqTrainer` and will need to set a new name.
</Tip>
Finally, we just pass everything to the `Seq2SeqTrainer`:
```python
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
```
Before training, we'll first look at the score our model gets, to double-check that we're not making things worse with our fine-tuning. This command will take a bit of time, so you can grab a coffee while it executes:
```python
trainer.evaluate(max_length=max_length)
```
```python out
{'eval_loss': 1.6964408159255981,
'eval_bleu': 39.26865061007616,
'eval_runtime': 965.8884,
'eval_samples_per_second': 21.76,
'eval_steps_per_second': 0.341}
```
A BLEU score of 39 is not too bad, which reflects the fact that our model is already good at translating English sentences to French ones.
Next is the training, which will also take a bit of time:
```python
trainer.train()
```
Note that while the training happens, each time the model is saved (here, every epoch) it is uploaded to the Hub in the background. This way, you will be able to to resume your training on another machine if necessary.
Once training is done, we evaluate our model again -- hopefully we will see some amelioration in the BLEU score!
```py
trainer.evaluate(max_length=max_length)
```
```python out
{'eval_loss': 0.8558505773544312,
'eval_bleu': 52.94161337775576,
'eval_runtime': 714.2576,
'eval_samples_per_second': 29.426,
'eval_steps_per_second': 0.461,
'epoch': 3.0}
```
That's a nearly 14-point improvement, which is great.
Finally, we use the `push_to_hub()` method to make sure we upload the latest version of the model. The `Trainer` also drafts a model card with all the evaluation results and uploads it. This model card contains metadata that helps the Model Hub pick the widget for the inference demo. Usually, there is no need to say anything as it can infer the right widget from the model class, but in this case, the same model class can be used for all kinds of sequence-to-sequence problems, so we specify it's a translation model:
```py
trainer.push_to_hub(tags="translation", commit_message="Training complete")
```
This command returns the URL of the commit it just did, if you want to inspect it:
```python out
'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
```
At this stage, you can use the inference widget on the Model Hub to test your model and share it with your friends. You have successfully fine-tuned a model on a translation task -- congratulations!
If you want to dive a bit more deeply into the training loop, we will now show you how to do the same thing using 🤗 Accelerate.
{/if}
{#if fw === 'pt'}
## A custom training loop[[a-custom-training-loop]]
Let's now take a look at the full training loop, so you can easily customize the parts you need. It will look a lot like what we did in [section 2](/course/chapter7/2) and [Chapter 3](/course/chapter3/4).
### Preparing everything for training[[preparing-everything-for-training]]
You've seen all of this a few times now, so we'll go through the code quite quickly. First we'll build the `DataLoader`s from our datasets, after setting the datasets to the `"torch"` format so we get PyTorch tensors:
```py
from torch.utils.data import DataLoader
tokenized_datasets.set_format("torch")
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)
```
Next we reinstantiate our model, to make sure we're not continuing the fine-tuning from before but starting from the pretrained model again:
```py
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
```
Then we will need an optimizer:
```py
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
```
Once we have all those objects, we can send them to the `accelerator.prepare()` method. Remember that if you want to train on TPUs in a Colab notebook, you will need to move all of this code into a training function, and that shouldn't execute any cell that instantiates an `Accelerator`.
```py
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
```
Now that we have sent our `train_dataloader` to `accelerator.prepare()`, we can use its length to compute the number of training steps. Remember we should always do this after preparing the dataloader, as that method will change the length of the `DataLoader`. We use a classic linear schedule from the learning rate to 0:
```py
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
```
Lastly, to push our model to the Hub, we will need to create a `Repository` object in a working folder. First log in to the Hugging Face Hub, if you're not logged in already. We'll determine the repository name from the model ID we want to give our model (feel free to replace the `repo_name` with your own choice; it just needs to contain your username, which is what the function `get_full_repo_name()` does):
```py
from huggingface_hub import Repository, get_full_repo_name
model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
```
```python out
'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
```
Then we can clone that repository in a local folder. If it already exists, this local folder should be a clone of the repository we are working with:
```py
output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
We can now upload anything we save in `output_dir` by calling the `repo.push_to_hub()` method. This will help us upload the intermediate models at the end of each epoch.
### Training loop[[training-loop]]
We are now ready to write the full training loop. To simplify its evaluation part, we define this `postprocess()` function that takes predictions and labels and converts them to the lists of strings our `metric` object will expect:
```py
def postprocess(predictions, labels):
predictions = predictions.cpu().numpy()
labels = labels.cpu().numpy()
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
return decoded_preds, decoded_labels
```
The training loop looks a lot like the ones in [section 2](/course/chapter7/2) and [Chapter 3](/course/chapter3), with a few differences in the evaluation part -- so let's focus on that!
The first thing to note is that we use the `generate()` method to compute predictions, but this is a method on our base model, not the wrapped model 🤗 Accelerate created in the `prepare()` method. That's why we unwrap the model first, then call this method.
The second thing is that, like with [token classification](/course/chapter7/2), two processes may have padded the inputs and labels to different shapes, so we use `accelerator.pad_across_processes()` to make the predictions and labels the same shape before calling the `gather()` method. If we don't do this, the evaluation will either error out or hang forever.
```py
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in tqdm(eval_dataloader):
with torch.no_grad():
generated_tokens = accelerator.unwrap_model(model).generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
max_length=128,
)
labels = batch["labels"]
# Necessary to pad predictions and labels for being gathered
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(generated_tokens)
labels_gathered = accelerator.gather(labels)
decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=decoded_preds, references=decoded_labels)
results = metric.compute()
print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)
```
```python out
epoch 0, BLEU score: 53.47
epoch 1, BLEU score: 54.24
epoch 2, BLEU score: 54.44
```
Once this is done, you should have a model that has results pretty similar to the one trained with the `Seq2SeqTrainer`. You can check the one we trained using this code at [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate). And if you want to test out any tweaks to the training loop, you can directly implement them by editing the code shown above!
{/if}
## Using the fine-tuned model[[using-the-fine-tuned-model]]
We've already shown you how you can use the model we fine-tuned on the Model Hub with the inference widget. To use it locally in a `pipeline`, we just have to specify the proper model identifier:
```py
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
translator = pipeline("translation", model=model_checkpoint)
translator("Default to expanded threads")
```
```python out
[{'translation_text': 'Par défaut, développer les fils de discussion'}]
```
As expected, our pretrained model adapted its knowledge to the corpus we fine-tuned it on, and instead of leaving the English word "threads" alone, it now translates it to the French official version. It's the same for "plugin":
```py
translator(
"Unable to import %1 using the OFX importer plugin. This file is not the correct format."
)
```
```python out
[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
```
Another great example of domain adaptation!
<Tip>
✏️ **Your turn!** What does the model return on the sample with the word "email" you identified earlier?
</Tip>
| huggingface/course/blob/main/chapters/en/chapter7/4.mdx |
# Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Training with Intel Extension for PyTorch
Intel Extension for PyTorch provides the optimizations for faster training and inference on CPUs. You can leverage the training example "textual_inversion.py". Follow the [instructions](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) to get the model and [dataset](https://huggingface.co/sd-concepts-library/dicoo2) before running the script.
The example supports both single node and multi-node distributed training:
### Single node training
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATA_DIR="path-to-dir-containing-dicoo-images"
python textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--seed=7 \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--max_train_steps=3000 \
--learning_rate=2.5e-03 --scale_lr \
--output_dir="textual_inversion_dicoo"
```
Note: Bfloat16 is available on Intel Xeon Scalable Processors Cooper Lake or Sapphire Rapids. You may not get performance speedup without Bfloat16 support.
### Multi-node distributed training
Before running the scripts, make sure to install the library's training dependencies successfully:
```bash
python -m pip install oneccl_bind_pt==1.13 -f https://developer.intel.com/ipex-whl-stable-cpu
```
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATA_DIR="path-to-dir-containing-dicoo-images"
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
python -m intel_extension_for_pytorch.cpu.launch --distributed \
--hostfile hostfile --nnodes 2 --nproc_per_node 2 textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--seed=7 \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--max_train_steps=750 \
--learning_rate=2.5e-03 --scale_lr \
--output_dir="textual_inversion_dicoo"
```
The above is a simple distributed training usage on 2 nodes with 2 processes on each node. Add the right hostname or ip address in the "hostfile" and make sure these 2 nodes are reachable from each other. For more details, please refer to the [user guide](https://github.com/intel/torch-ccl).
### Reference
We publish a [Medium blog](https://medium.com/intel-analytics-software/personalized-stable-diffusion-with-few-shot-fine-tuning-on-a-single-cpu-f01a3316b13) on how to create your own Stable Diffusion model on CPUs using textual inversion. Try it out now, if you have interests.
| huggingface/diffusers/blob/main/examples/research_projects/intel_opts/textual_inversion/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification
The script [`run_ner.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/quantization/token-classification/run_ner.py)
allows us to apply different quantization approaches (such as dynamic and static quantization) as well as graph
optimizations using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for token classification tasks.
The following example applies post-training dynamic quantization on a DistilBERT fine-tuned on the CoNLL-2003 task
```bash
python run_ner.py \
--model_name_or_path elastic/distilbert-base-uncased-finetuned-conll03-english \
--dataset_name conll2003 \
--quantization_approach dynamic \
--do_eval \
--output_dir /tmp/quantized_distilbert_conll2003
```
In order to apply dynamic or static quantization, `quantization_approach` must be set to respectively `dynamic` or `static`.
| huggingface/optimum/blob/main/examples/onnxruntime/quantization/token-classification/README.md |
Introduction[[introduction]]
<CourseFloatingBanner
chapter={6}
classNames="absolute z-10 right-0 top-0"
/>
In [Chapter 3](/course/chapter3), we looked at how to fine-tune a model on a given task. When we do that, we use the same tokenizer that the model was pretrained with -- but what do we do when we want to train a model from scratch? In these cases, using a tokenizer that was pretrained on a corpus from another domain or language is typically suboptimal. For example, a tokenizer that's trained on an English corpus will perform poorly on a corpus of Japanese texts because the use of spaces and punctuation is very different in the two languages.
In this chapter, you will learn how to train a brand new tokenizer on a corpus of texts, so it can then be used to pretrain a language model. This will all be done with the help of the [🤗 Tokenizers](https://github.com/huggingface/tokenizers) library, which provides the "fast" tokenizers in the [🤗 Transformers](https://github.com/huggingface/transformers) library. We'll take a close look at the features that this library provides, and explore how the fast tokenizers differ from the "slow" versions.
Topics we will cover include:
* How to train a new tokenizer similar to the one used by a given checkpoint on a new corpus of texts
* The special features of fast tokenizers
* The differences between the three main subword tokenization algorithms used in NLP today
* How to build a tokenizer from scratch with the 🤗 Tokenizers library and train it on some data
The techniques introduced in this chapter will prepare you for the section in [Chapter 7](/course/chapter7/6) where we look at creating a language model for Python source code. Let's start by looking at what it means to "train" a tokenizer in the first place. | huggingface/course/blob/main/chapters/en/chapter6/1.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPTSAN-japanese
## Overview
The GPTSAN-japanese model was released in the repository by Toshiyuki Sakamoto (tanreinama).
GPTSAN is a Japanese language model using Switch Transformer. It has the same structure as the model introduced as Prefix LM
in the T5 paper, and support both Text Generation and Masked Language Modeling tasks. These basic tasks similarly can
fine-tune for translation or summarization.
### Usage example
The `generate()` method can be used to generate text using GPTSAN-Japanese model.
```python
>>> from transformers import AutoModel, AutoTokenizer
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
>>> model = AutoModel.from_pretrained("Tanrei/GPTSAN-japanese").cuda()
>>> x_tok = tokenizer("は、", prefix_text="織田信長", return_tensors="pt")
>>> torch.manual_seed(0)
>>> gen_tok = model.generate(x_tok.input_ids.cuda(), token_type_ids=x_tok.token_type_ids.cuda(), max_new_tokens=20)
>>> tokenizer.decode(gen_tok[0])
'織田信長は、2004年に『戦国BASARA』のために、豊臣秀吉'
```
## GPTSAN Features
GPTSAN has some unique features. It has a model structure of Prefix-LM. It works as a shifted Masked Language Model for Prefix Input tokens. Un-prefixed inputs behave like normal generative models.
The Spout vector is a GPTSAN specific input. Spout is pre-trained with random inputs, but you can specify a class of text or an arbitrary vector during fine-tuning. This allows you to indicate the tendency of the generated text.
GPTSAN has a sparse Feed Forward based on Switch-Transformer. You can also add other layers and train them partially. See the original GPTSAN repository for details.
### Prefix-LM Model
GPTSAN has the structure of the model named Prefix-LM in the `T5` paper. (The original GPTSAN repository calls it `hybrid`)
In GPTSAN, the `Prefix` part of Prefix-LM, that is, the input position that can be referenced by both tokens, can be specified with any length.
Arbitrary lengths can also be specified differently for each batch.
This length applies to the text entered in `prefix_text` for the tokenizer.
The tokenizer returns the mask of the `Prefix` part of Prefix-LM as `token_type_ids`.
The model treats the part where `token_type_ids` is 1 as a `Prefix` part, that is, the input can refer to both tokens before and after.
## Usage tips
Specifying the Prefix part is done with a mask passed to self-attention.
When token_type_ids=None or all zero, it is equivalent to regular causal mask
for example:
>>> x_token = tokenizer("アイウエ")
input_ids: | SOT | SEG | ア | イ | ウ | エ |
token_type_ids: | 1 | 0 | 0 | 0 | 0 | 0 |
prefix_lm_mask:
SOT | 1 0 0 0 0 0 |
SEG | 1 1 0 0 0 0 |
ア | 1 1 1 0 0 0 |
イ | 1 1 1 1 0 0 |
ウ | 1 1 1 1 1 0 |
エ | 1 1 1 1 1 1 |
>>> x_token = tokenizer("", prefix_text="アイウエ")
input_ids: | SOT | ア | イ | ウ | エ | SEG |
token_type_ids: | 1 | 1 | 1 | 1 | 1 | 0 |
prefix_lm_mask:
SOT | 1 1 1 1 1 0 |
ア | 1 1 1 1 1 0 |
イ | 1 1 1 1 1 0 |
ウ | 1 1 1 1 1 0 |
エ | 1 1 1 1 1 0 |
SEG | 1 1 1 1 1 1 |
>>> x_token = tokenizer("ウエ", prefix_text="アイ")
input_ids: | SOT | ア | イ | SEG | ウ | エ |
token_type_ids: | 1 | 1 | 1 | 0 | 0 | 0 |
prefix_lm_mask:
SOT | 1 1 1 0 0 0 |
ア | 1 1 1 0 0 0 |
イ | 1 1 1 0 0 0 |
SEG | 1 1 1 1 0 0 |
ウ | 1 1 1 1 1 0 |
エ | 1 1 1 1 1 1 |
### Spout Vector
A Spout Vector is a special vector for controlling text generation.
This vector is treated as the first embedding in self-attention to bring extraneous attention to the generated tokens.
In the pre-trained model published from `Tanrei/GPTSAN-japanese`, the Spout Vector is a 128-dimensional vector that passes through 8 fully connected layers in the model and is projected into the space acting as external attention.
The Spout Vector projected by the fully connected layer is split to be passed to all self-attentions.
## GPTSanJapaneseConfig
[[autodoc]] GPTSanJapaneseConfig
## GPTSanJapaneseTokenizer
[[autodoc]] GPTSanJapaneseTokenizer
## GPTSanJapaneseModel
[[autodoc]] GPTSanJapaneseModel
## GPTSanJapaneseForConditionalGeneration
[[autodoc]] GPTSanJapaneseForConditionalGeneration
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/gptsan-japanese.md |
Introduction[[introduction]]
<CourseFloatingBanner
chapter={5}
classNames="absolute z-10 right-0 top-0"
/>
In [Chapter 3](/course/chapter3) you got your first taste of the 🤗 Datasets library and saw that there were three main steps when it came to fine-tuning a model:
1. Load a dataset from the Hugging Face Hub.
2. Preprocess the data with `Dataset.map()`.
3. Load and compute metrics.
But this is just scratching the surface of what 🤗 Datasets can do! In this chapter, we will take a deep dive into the library. Along the way, we'll find answers to the following questions:
* What do you do when your dataset is not on the Hub?
* How can you slice and dice a dataset? (And what if you _really_ need to use Pandas?)
* What do you do when your dataset is huge and will melt your laptop's RAM?
* What the heck are "memory mapping" and Apache Arrow?
* How can you create your own dataset and push it to the Hub?
The techniques you learn here will prepare you for the advanced tokenization and fine-tuning tasks in [Chapter 6](/course/chapter6) and [Chapter 7](/course/chapter7) -- so grab a coffee and let's get started! | huggingface/course/blob/main/chapters/en/chapter5/1.mdx |
Webhook guide: Setup an automatic metadata quality review for models and datasets
<Tip>
Webhooks are now publicly available!
</Tip>
This guide will walk you through creating a system that reacts to changes to a user's or organization's models or datasets on the Hub and creates a 'metadata review' for the changed repository.
## What are we building and why?
Before we dive into the technical details involved in this particular workflow, we'll quickly outline what we're creating and why.
[Model cards](https://huggingface.co/docs/hub/model-cards) and [dataset cards](https://huggingface.co/docs/hub/datasets-cards) are essential tools for documenting machine learning models and datasets. The Hugging Face Hub uses a `README.md` file containing a [YAML](https://en.wikipedia.org/wiki/YAML) header block to generate model and dataset cards. This `YAML` section defines metadata relating to the model or dataset. For example:
```yaml
---
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
---
```
This metadata contains essential information about your model or dataset for potential users. The license, for example, defines the terms under which a model or dataset can be used. Hub users can also use the fields defined in the `YAML` metadata as filters for identifying models or datasets that fit specific criteria.
Since the metadata defined in this block is essential for potential users of our models and datasets, it is important that we complete this section. In a team or organization setting, users pushing models and datasets to the Hub may have differing familiarity with the importance of this YAML metadata block. While someone in a team could take on the responsibility of reviewing this metadata, there may instead be some automation we can do to help us with this problem. The result will be a metadata review report automatically posted or updated when a repository on the Hub changes. For our metadata quality, this system works similarly to [CI/CD](https://en.wikipedia.org/wiki/CI/CD).
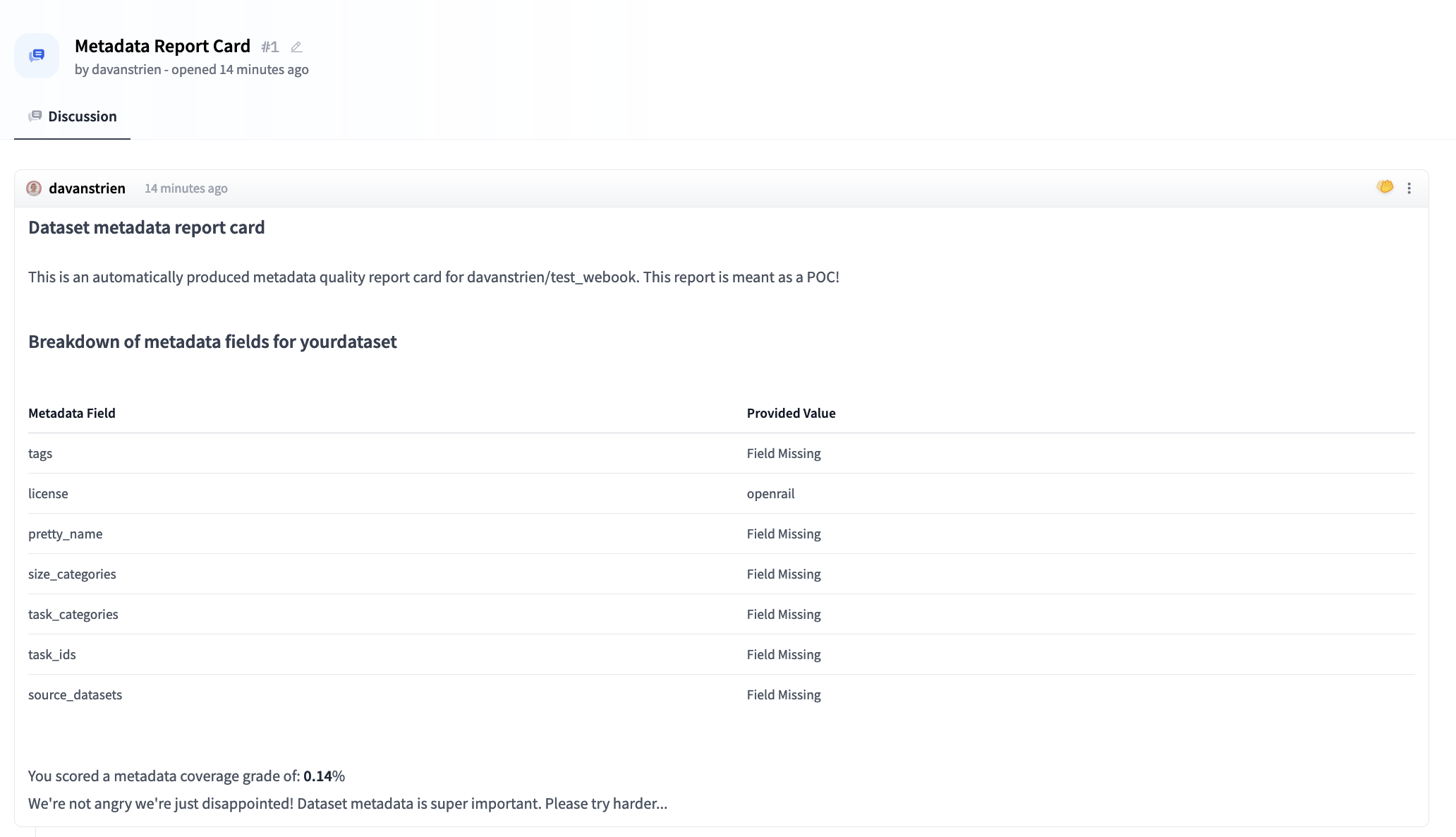
You can also find an example review [here](https://huggingface.co/datasets/davanstrien/test_webhook/discussions/1#63d932fe19aa7b8ed2718b3f).
## Using the Hub Client Library to create a model review card
The `huggingface_hub` is a Python library that allows you to interact with the Hub. We can use this library to [download model and dataset cards](https://huggingface.co/docs/huggingface_hub/how-to-model-cards) from the Hub using the `DatasetCard.load` or `ModelCard.load` methods. In particular, we'll use these methods to load a Python dictionary, which contains the metadata defined in the `YAML` of our model or dataset card. We'll create a small Python function to wrap these methods and do some exception handling.
```python
from huggingface_hub import DatasetCard, ModelCard
from huggingface_hub.utils import EntryNotFoundError
def load_repo_card_metadata(repo_type, repo_name):
if repo_type == "dataset":
try:
return DatasetCard.load(repo_name).data.to_dict()
except EntryNotFoundError:
return {}
if repo_type == "model":
try:
return ModelCard.load(repo_name).data.to_dict()
except EntryNotFoundError:
return {}
```
This function will return a Python dictionary containing the metadata associated with the repository (or an empty dictionary if there is no metadata).
```python
{'license': 'afl-3.0'}
```
## Creating our metadata review report
Once we have a Python dictionary containing the metadata associated with a repository, we'll create a 'report card' for our metadata review. In this particular instance, we'll review our metadata by defining some metadata fields for which we want values. For example, we may want to ensure that the `license` field has always been completed. To rate our metadata, we'll count which metadata fields are present out of our desired fields and return a percentage score based on the coverage of the required metadata fields we want to see values.
Since we have a Python dictionary containing our metadata, we can loop through this dictionary to check if our desired keys are there. If a desired metadata field (a key in our dictionary) is missing, we'll assign the value as `None`.
```python
def create_metadata_key_dict(card_data, repo_type: str):
shared_keys = ["tags", "license"]
if repo_type == "model":
model_keys = ["library_name", "datasets", "metrics", "co2", "pipeline_tag"]
shared_keys.extend(model_keys)
keys = shared_keys
return {key: card_data.get(key) for key in keys}
if repo_type == "dataset":
# [...]
```
This function will return a dictionary containing keys representing the metadata fields we require for our model or dataset. The dictionary values will either include the metadata entered for that field or `None` if that metadata field is missing in the `YAML`.
```python
{'tags': None,
'license': 'afl-3.0',
'library_name': None,
'datasets': None,
'metrics': None,
'co2': None,
'pipeline_tag': None}
```
Once we have this dictionary, we can create our metadata report. In the interest of brevity, we won't include the complete code here, but the Hugging Face Spaces [repository](https://huggingface.co/spaces/librarian-bot/webhook_metadata_reviewer/blob/main/main.py) for this Webhook contains the full code.
We create one function which creates a markdown table that produces a prettier version of the data we have in our metadata coverage dictionary.
```python
def create_metadata_breakdown_table(desired_metadata_dictionary):
# [...]
return tabulate(
table_data, tablefmt="github", headers=("Metadata Field", "Provided Value")
)
```
We also have a Python function that generates a score (representing the percentage of the desired metadata fields present)
```python
def calculate_grade(desired_metadata_dictionary):
# [...]
return round(score, 2)
```
and a Python function that creates a markdown report for our metadata review. This report contains both the score and metadata table, along with some explanation of what the report contains.
```python
def create_markdown_report(
desired_metadata_dictionary, repo_name, repo_type, score, update: bool = False
):
# [...]
return report
```
## How to post the review automatically?
We now have a markdown formatted metadata review report. We'll use the `huggingface_hub` library to post this review. We define a function that takes back the Webhook data received from the Hub, parses the data, and creates the metadata report. Depending on whether a report has previously been created, the function creates a new report or posts a new issue to an existing metadata review thread.
```python
def create_or_update_report(data):
if parsed_post := parse_webhook_post(data):
repo_type, repo_name = parsed_post
else:
return Response("Unable to parse webhook data", status_code=400)
# [...]
return True
```
<Tip>
`:=` is the Python Syntax for an assignment expression operator added to the Python language in version 3.8 (colloquially known as the walrus operator). People have mixed opinions on this syntax, and it doesn't change how Python evaluates the code if you don't use this. You can read more about this operator in this [Real Python article](https://realpython.com/python-walrus-operator/).
</Tip>
## Creating a Webhook to respond to changes on the Hub
We've now got the core functionality for creating a metadata review report for a model or dataset. The next step is to use Webhooks to respond to changes automatically.
## Create a Webhook in your user profile
First, create your Webhook by going to https://huggingface.co/settings/webhooks.
- Input a few target repositories that your Webhook will listen to (you will likely want to limit this to your own repositories or the repositories of the organization you belong to).
- Input a secret to make your Webhook more secure (if you don't know what to choose for this, you may want to use a [password generator](https://1password.com/password-generator/) to generate a sufficiently long random string for your secret).
- We can pass a dummy URL for the `Webhook URL` parameter for now.
Your Webhook will look like this:
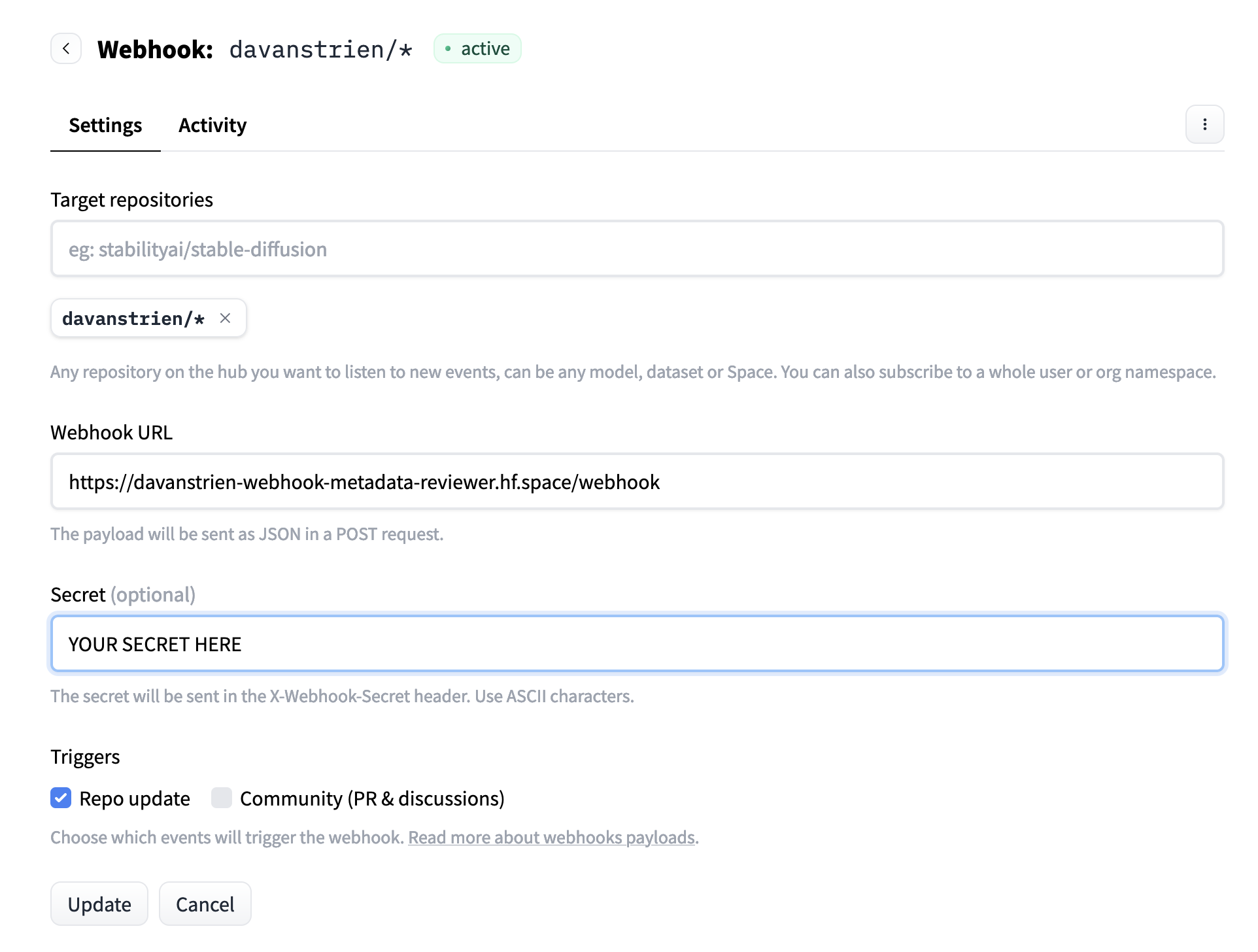
## Create a new Bot user profile
This guide creates a separate user account that will post the metadata reviews.
<Tip>
When creating a bot that will interact with other users on the Hub, we ask that you clearly label the account as a "Bot" (see profile screenshot).
</Tip>
## Create a Webhook listener
We now need some way of listening to Webhook events. There are many possible tools you can use to listen to Webhook events. Many existing services, such as [Zapier](https://zapier.com/) and [IFTTT](https://ifttt.com), can use Webhooks to trigger actions (for example, they could post a tweet every time a model is updated). In this case, we'll implement our Webhook listener using [FastAPI](https://fastapi.tiangolo.com/).
[FastAPI](https://fastapi.tiangolo.com/) is a Python web framework. We'll use FastAPI to create a Webhook listener. In particular, we need to implement a route that accepts `POST` requests on `/webhook`. For authentication, we'll compare the `X-Webhook-Secret` header with a `WEBHOOK_SECRET` secret that can be passed to our [Docker container at runtime](./spaces-sdks-docker#runtime).
```python
from fastapi import FastAPI, Request, Response
import os
KEY = os.environ.get("WEBHOOK_SECRET")
app = FastAPI()
@app.post("/webhook")
async def webhook(request: Request):
if request.method == "POST":
if request.headers.get("X-Webhook-Secret") != KEY:
return Response("Invalid secret", status_code=401)
data = await request.json()
result = create_or_update_report(data)
return "Webhook received!" if result else result
```
The above function will receive Webhook events and creates or updates the metadata review report for the changed repository.
## Use Spaces to deploy our Webhook app
Our [main.py](https://huggingface.co/spaces/librarian-bot/webhook_metadata_reviewer/blob/main/main.py) file contains all the code we need for our Webhook app. To deploy it, we'll use a [Space](./spaces-overview).
For our Space, we'll use Docker to run our app. The [Dockerfile](https://huggingface.co/spaces/librarian-bot/webhook_metadata_reviewer/blob/main/Dockerfile) copies our app file, installs the required dependencies, and runs the application. To populate the `KEY` variable, we'll also set a `WEBHOOK_SECRET` secret for our Space with the secret we generated earlier. You can read more about Docker Spaces [here](./spaces-sdks-docker).
Finally, we need to update the URL in our Webhook settings to the URL of our Space. We can get our Space’s “direct URL” from the contextual menu. Click on “Embed this Space” and copy the “Direct URL”.
Once we have this URL, we can pass this to the `Webhook URL` parameter in our Webhook settings. Our bot should now start posting reviews when monitored repositories change!
## Conclusion and next steps
We now have an automatic metadata review bot! Here are some ideas for how you could build on this guide:
- The metadata review done by our bot was relatively crude; you could add more complex rules for reviewing metadata.
- You could use the full `README.md` file for doing the review.
- You may want to define 'rules' which are particularly important for your organization and use a webhook to check these are followed.
If you build a metadata quality app using Webhooks, please tag me @davanstrien; I would love to know about it!
| huggingface/hub-docs/blob/main/docs/hub/webhooks-guide-metadata-review.md |
🟧 Label Studio on Spaces
[Label Studio](https://labelstud.io) is an [open-source data labeling
platform](https://github.com/heartexlabs/label-studio) for labeling,
annotating, and exploring many different data types. Additionally, Label Studio
includes a powerful [machine learning
interface](https://labelstud.io/guide/ml.html) that can be used for new model
training, active learning, supervised learning, and many other training
techniques.
This guide will teach you how to deploy Label Studio for data
labeling and annotation within the Hugging Face Hub. You can use the default
configuration of Label Studio as a self-contained application hosted completely
on the Hub using Docker for demonstration and evaluation purposes, or you can
attach your own database and cloud storage to host a fully-featured
production-ready application hosted on Spaces.
## ⚡️ Deploy Label Studio on Spaces
You can deploy Label Studio on Spaces with just a few clicks:
<a href="https://huggingface.co/new-space?template=LabelStudio/LabelStudio">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg" />
</a>
Spaces requires you to define:
* An **Owner**: either your personal account or an organization you're a
part of.
* A **Space name**: the name of the Space within the account
you're creating the Space.
* The **Visibility**: _private_ if you want the
Space to be visible only to you or your organization, or _public_ if you want
it to be visible to other users or applications using the Label Studio API
(suggested).
## 🚀 Using the Default Configuration
By default, Label Studio is installed in Spaces with a configuration that uses
local storage for the application database to store configuration, account
credentials, and project information. Labeling tasks and data items are also held
in local storage.
<Tip warning={true}>
Storage in Hugging Face Spaces is ephemeral, and the data you store in the default
configuration can be lost in a reboot or reset of the Space. Because of this,
we strongly encourage you to use the default configuration only for testing and
demonstration purposes.
</Tip>
After launching Label Studio, you will be presented with the standard login
screen. You can start by creating a new account using your email address and
logging in with your new credentials. Periodically after logging in, Label
Studio will warn you that the storage is ephemeral and data could be
lost if your Space is restarted. You will also be preset with a prompt from
Heidi, the helpful Label Studio mascot, to create a new project to start
labeling your data. To get started, check out the Label Studio ["Zero to One"
tutorial](https://labelstud.io/blog/introduction-to-label-studio-in-hugging-face-spaces/)
with a guide on how to build an annotation interface for sentiment analysis.
## 🛠️ Configuring a Production-Ready Instance of Label Studio
To make your Space production-ready, you will need to make three configuration
changes:
* Disable the unrestricted creation of new accounts.
* Enable persistence by attaching an external database.
* Attach cloud storage for labeling tasks.
### Disable Unrestricted Creation of New Accounts
The default configuration on Label Studio allows for the unrestricted creation
of new accounts for anyone who has the URL for your application. You can
[restrict signups](https://labelstud.io/guide/signup.html#Restrict-signup-for-local-deployments)
by adding the following configuration secrets to your Space **Settings**.
* `LABEL_STUDIO_DISABLE_SIGNUP_WITHOUT_LINK`: Setting this value to `true` will
disable unrestricted account creation.
* `LABEL_STUDIO_USERNAME`: This is the username of the account that you will
use as the first user in your Label Studio Space. It should be a valid email
address.
* `LABEL_STUDIO_PASSWORD`: The password that will be associated with the first
user account.
Restart the Space to apply these settings. The ability to create new accounts
from the login screen will be disabled. To create new accounts, you will need
to invite new users in the `Organization` settings in the Label Studio
application.
### Enable Configuration Persistence
By default, this Space stores all project configuration and data annotations in
local storage with SQLite. If the Space is reset, all configuration and
annotation data in the Space will be lost. You can enable configuration
persistence by [connecting an external Postgres database to your
space](https://labelstud.io/guide/storedata.html#PostgreSQL-database),
guaranteeing that all project and annotation settings are preserved.
Set the following secret variables to match your own hosted instance of
Postgres. We strongly recommend setting these as secrets to prevent leaking
information about your database service to the public in your spaces
definition.
* `DJANGO_DB`: Set this to `default`.
* `POSTGRE_NAME`: Set this to the name of the Postgres database.
* `POSTGRE_USER`: Set this to the Postgres username.
* `POSTGRE_PASSWORD`: Set this to the password for your Postgres user.
* `POSTGRE_HOST`: Set this to the host that your Postgres database is running
on.
* `POSTGRE_PORT`: Set this to the port that your Pogtgres database is running
on.
* `STORAGE_PERSISTENCE`: Set this to `1` to remove the warning about ephemeral
storage.
Restart the Space to apply these settings. Information about users, projects,
and annotations will be stored in the database, and will be reloaded by Label
Studio if the space is restarted or reset.
### Enable Cloud Storage
By default, the only data storage enabled for this Space is local. In the case
of a Space reset, all data will be lost. To enable permanent storage, you must
enable a [cloud storage connector](https://labelstud.io/guide/storage.html).
Choose the appropriate cloud connector and configure the secrets for it.
#### Amazon S3
* `STORAGE_TYPE`: Set this to `s3`.
* `STORAGE_AWS_ACCESS_KEY_ID`: `<YOUR_ACCESS_KEY_ID>`
* `STORAGE_AWS_SECRET_ACCESS_KEY`: `<YOUR_SECRET_ACCESS_KEY>`
* `STORAGE_AWS_BUCKET_NAME`: `<YOUR_BUCKET_NAME>`
* `STORAGE_AWS_REGION_NAME`: `<YOUR_BUCKET_REGION>`
* `STORAGE_AWS_FOLDER`: Set this to an empty string.
#### Google Cloud Storage
* `STORAGE_TYPE`: Set this to `gcs`.
* `STORAGE_GCS_BUCKET_NAME`: `<YOUR_BUCKET_NAME>`
* `STORAGE_GCS_PROJECT_ID`: `<YOUR_PROJECT_ID>`
* `STORAGE_GCS_FOLDER`: Set this to an empty string.
* `GOOGLE_APPLICATION_CREDENTIALS`: Set this to `/opt/heartex/secrets/key.json`.
#### Azure Blob Storage
* `STORAGE_TYPE`: Set this to `azure`.
* `STORAGE_AZURE_ACCOUNT_NAME`: `<YOUR_STORAGE_ACCOUNT>`
* `STORAGE_AZURE_ACCOUNT_KEY`: `<YOUR_STORAGE_KEY>`
* `STORAGE_AZURE_CONTAINER_NAME`: `<YOUR_CONTAINER_NAME>`
* `STORAGE_AZURE_FOLDER`: Set this to an empty string.
## 🤗 Next Steps, Feedback, and Support
To get started with Label Studio, check out the Label Studio ["Zero to One"
tutorial](https://labelstud.io/blog/introduction-to-label-studio-in-hugging-face-spaces/),
which walks you through an example sentiment analysis annotation project. You
can find a full set of resources about Label Studio and the Label Studio
community on at the [Label Studio Home Page](https://labelstud.io). This
includes [full documentation](https://labelstud.io/guide/), an [interactive
playground](https://labelstud.io/playground/) for trying out different
annotation interfaces, and links to join the [Label Studio Slack
Community](https://slack.labelstudio.heartex.com/?source=spaces).
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-label-studio.md |
p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/datasets-logo-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/datasets-logo-light.svg">
<img alt="Hugging Face Datasets Library" src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/datasets-logo-light.svg" width="352" height="59" style="max-width: 100%;">
</picture>
<br/>
<br/>
</p>
<p align="center">
<a href="https://github.com/huggingface/datasets/actions/workflows/ci.yml?query=branch%3Amain">
<img alt="Build" src="https://github.com/huggingface/datasets/actions/workflows/ci.yml/badge.svg?branch=main">
</a>
<a href="https://github.com/huggingface/datasets/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue">
</a>
<a href="https://huggingface.co/docs/datasets/index.html">
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/datasets/index.html.svg?down_color=red&down_message=offline&up_message=online">
</a>
<a href="https://github.com/huggingface/datasets/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/datasets.svg">
</a>
<a href="https://huggingface.co/datasets/">
<img alt="Number of datasets" src="https://img.shields.io/endpoint?url=https://huggingface.co/api/shields/datasets&color=brightgreen">
</a>
<a href="CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.0-4baaaa.svg">
</a>
<a href="https://zenodo.org/badge/latestdoi/250213286"><img src="https://zenodo.org/badge/250213286.svg" alt="DOI"></a>
</p>
🤗 Datasets is a lightweight library providing **two** main features:
- **one-line dataloaders for many public datasets**: one-liners to download and pre-process any of the  major public datasets (image datasets, audio datasets, text datasets in 467 languages and dialects, etc.) provided on the [HuggingFace Datasets Hub](https://huggingface.co/datasets). With a simple command like `squad_dataset = load_dataset("squad")`, get any of these datasets ready to use in a dataloader for training/evaluating a ML model (Numpy/Pandas/PyTorch/TensorFlow/JAX),
- **efficient data pre-processing**: simple, fast and reproducible data pre-processing for the public datasets as well as your own local datasets in CSV, JSON, text, PNG, JPEG, WAV, MP3, Parquet, etc. With simple commands like `processed_dataset = dataset.map(process_example)`, efficiently prepare the dataset for inspection and ML model evaluation and training.
[🎓 **Documentation**](https://huggingface.co/docs/datasets/) [🔎 **Find a dataset in the Hub**](https://huggingface.co/datasets) [🌟 **Share a dataset on the Hub**](https://huggingface.co/docs/datasets/share)
<h3 align="center">
<a href="https://hf.co/course"><img src="https://raw.githubusercontent.com/huggingface/datasets/main/docs/source/imgs/course_banner.png"></a>
</h3>
🤗 Datasets is designed to let the community easily add and share new datasets.
🤗 Datasets has many additional interesting features:
- Thrive on large datasets: 🤗 Datasets naturally frees the user from RAM memory limitation, all datasets are memory-mapped using an efficient zero-serialization cost backend (Apache Arrow).
- Smart caching: never wait for your data to process several times.
- Lightweight and fast with a transparent and pythonic API (multi-processing/caching/memory-mapping).
- Built-in interoperability with NumPy, pandas, PyTorch, TensorFlow 2 and JAX.
- Native support for audio and image data.
- Enable streaming mode to save disk space and start iterating over the dataset immediately.
🤗 Datasets originated from a fork of the awesome [TensorFlow Datasets](https://github.com/tensorflow/datasets) and the HuggingFace team want to deeply thank the TensorFlow Datasets team for building this amazing library. More details on the differences between 🤗 Datasets and `tfds` can be found in the section [Main differences between 🤗 Datasets and `tfds`](#main-differences-between--datasets-and-tfds).
# Installation
## With pip
🤗 Datasets can be installed from PyPi and has to be installed in a virtual environment (venv or conda for instance)
```bash
pip install datasets
```
## With conda
🤗 Datasets can be installed using conda as follows:
```bash
conda install -c huggingface -c conda-forge datasets
```
Follow the installation pages of TensorFlow and PyTorch to see how to install them with conda.
For more details on installation, check the installation page in the documentation: https://huggingface.co/docs/datasets/installation
## Installation to use with PyTorch/TensorFlow/pandas
If you plan to use 🤗 Datasets with PyTorch (1.0+), TensorFlow (2.2+) or pandas, you should also install PyTorch, TensorFlow or pandas.
For more details on using the library with NumPy, pandas, PyTorch or TensorFlow, check the quick start page in the documentation: https://huggingface.co/docs/datasets/quickstart
# Usage
🤗 Datasets is made to be very simple to use - the API is centered around a single function, `datasets.load_dataset(dataset_name, **kwargs)`, that instantiates a dataset.
This library can be used for text/image/audio/etc. datasets. Here is an example to load a text dataset:
Here is a quick example:
```python
from datasets import load_dataset
# Print all the available datasets
from huggingface_hub import list_datasets
print([dataset.id for dataset in list_datasets()])
# Load a dataset and print the first example in the training set
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
# Process the dataset - add a column with the length of the context texts
dataset_with_length = squad_dataset.map(lambda x: {"length": len(x["context"])})
# Process the dataset - tokenize the context texts (using a tokenizer from the 🤗 Transformers library)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
tokenized_dataset = squad_dataset.map(lambda x: tokenizer(x['context']), batched=True)
```
If your dataset is bigger than your disk or if you don't want to wait to download the data, you can use streaming:
```python
# If you want to use the dataset immediately and efficiently stream the data as you iterate over the dataset
image_dataset = load_dataset('cifar100', streaming=True)
for example in image_dataset["train"]:
break
```
For more details on using the library, check the quick start page in the documentation: https://huggingface.co/docs/datasets/quickstart and the specific pages on:
- Loading a dataset: https://huggingface.co/docs/datasets/loading
- What's in a Dataset: https://huggingface.co/docs/datasets/access
- Processing data with 🤗 Datasets: https://huggingface.co/docs/datasets/process
- Processing audio data: https://huggingface.co/docs/datasets/audio_process
- Processing image data: https://huggingface.co/docs/datasets/image_process
- Processing text data: https://huggingface.co/docs/datasets/nlp_process
- Streaming a dataset: https://huggingface.co/docs/datasets/stream
- Writing your own dataset loading script: https://huggingface.co/docs/datasets/dataset_script
- etc.
# Add a new dataset to the Hub
We have a very detailed step-by-step guide to add a new dataset to the  datasets already provided on the [HuggingFace Datasets Hub](https://huggingface.co/datasets).
You can find:
- [how to upload a dataset to the Hub using your web browser or Python](https://huggingface.co/docs/datasets/upload_dataset) and also
- [how to upload it using Git](https://huggingface.co/docs/datasets/share).
# Main differences between 🤗 Datasets and `tfds`
If you are familiar with the great TensorFlow Datasets, here are the main differences between 🤗 Datasets and `tfds`:
- the scripts in 🤗 Datasets are not provided within the library but are queried, downloaded/cached and dynamically loaded upon request
- the backend serialization of 🤗 Datasets is based on [Apache Arrow](https://arrow.apache.org/) instead of TF Records and leverage python dataclasses for info and features with some diverging features (we mostly don't do encoding and store the raw data as much as possible in the backend serialization cache).
- the user-facing dataset object of 🤗 Datasets is not a `tf.data.Dataset` but a built-in framework-agnostic dataset class with methods inspired by what we like in `tf.data` (like a `map()` method). It basically wraps a memory-mapped Arrow table cache.
# Disclaimers
🤗 Datasets may run Python code defined by the dataset authors to parse certain data formats or structures. For security reasons, we ask users to:
- check the dataset scripts they're going to run beforehand and
- pin the `revision` of the repositories they use.
If you're a dataset owner and wish to update any part of it (description, citation, license, etc.), or do not want your dataset to be included in the Hugging Face Hub, please get in touch by opening a discussion or a pull request in the Community tab of the dataset page. Thanks for your contribution to the ML community!
## BibTeX
If you want to cite our 🤗 Datasets library, you can use our [paper](https://arxiv.org/abs/2109.02846):
```bibtex
@inproceedings{lhoest-etal-2021-datasets,
title = "Datasets: A Community Library for Natural Language Processing",
author = "Lhoest, Quentin and
Villanova del Moral, Albert and
Jernite, Yacine and
Thakur, Abhishek and
von Platen, Patrick and
Patil, Suraj and
Chaumond, Julien and
Drame, Mariama and
Plu, Julien and
Tunstall, Lewis and
Davison, Joe and
{\v{S}}a{\v{s}}ko, Mario and
Chhablani, Gunjan and
Malik, Bhavitvya and
Brandeis, Simon and
Le Scao, Teven and
Sanh, Victor and
Xu, Canwen and
Patry, Nicolas and
McMillan-Major, Angelina and
Schmid, Philipp and
Gugger, Sylvain and
Delangue, Cl{\'e}ment and
Matussi{\`e}re, Th{\'e}o and
Debut, Lysandre and
Bekman, Stas and
Cistac, Pierric and
Goehringer, Thibault and
Mustar, Victor and
Lagunas, Fran{\c{c}}ois and
Rush, Alexander and
Wolf, Thomas",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.21",
pages = "175--184",
abstract = "The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.",
eprint={2109.02846},
archivePrefix={arXiv},
primaryClass={cs.CL},
}
```
If you need to cite a specific version of our 🤗 Datasets library for reproducibility, you can use the corresponding version Zenodo DOI from this [list](https://zenodo.org/search?q=conceptrecid:%224817768%22&sort=-version&all_versions=True).
| huggingface/datasets/blob/main/README.md |
NASNet
**NASNet** is a type of convolutional neural network discovered through neural architecture search. The building blocks consist of normal and reduction cells.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('nasnetalarge', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `nasnetalarge`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('nasnetalarge', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{zoph2018learning,
title={Learning Transferable Architectures for Scalable Image Recognition},
author={Barret Zoph and Vijay Vasudevan and Jonathon Shlens and Quoc V. Le},
year={2018},
eprint={1707.07012},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: NASNet
Paper:
Title: Learning Transferable Architectures for Scalable Image Recognition
URL: https://paperswithcode.com/paper/learning-transferable-architectures-for
Models:
- Name: nasnetalarge
In Collection: NASNet
Metadata:
FLOPs: 30242402862
Parameters: 88750000
File Size: 356056626
Architecture:
- Average Pooling
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- ReLU
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 50x Tesla K40 GPUs
ID: nasnetalarge
Dropout: 0.5
Crop Pct: '0.911'
Momentum: 0.9
Image Size: '331'
Interpolation: bicubic
Label Smoothing: 0.1
RMSProp $\epsilon$: 1.0
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/nasnet.py#L562
Weights: http://data.lip6.fr/cadene/pretrainedmodels/nasnetalarge-a1897284.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.63%
Top 5 Accuracy: 96.05%
--> | huggingface/pytorch-image-models/blob/main/docs/models/nasnet.md |
--
title: Deploying TensorFlow Vision Models in Hugging Face with TF Serving
thumbnail: /blog/assets/90_tf_serving_vision/thumbnail.png
authors:
- user: sayakpaul
guest: true
---
# Deploying TensorFlow Vision Models in Hugging Face with TF Serving
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/111_tf_serving_vision.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In the past few months, the Hugging Face team and external contributors
added a variety of vision models in TensorFlow to Transformers. This
list is growing comprehensively and already includes state-of-the-art
pre-trained models like [Vision Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/vit),
[Masked Autoencoders](https://huggingface.co/docs/transformers/model_doc/vit_mae),
[RegNet](https://huggingface.co/docs/transformers/main/en/model_doc/regnet),
[ConvNeXt](https://huggingface.co/docs/transformers/model_doc/convnext),
and many others!
When it comes to deploying TensorFlow models, you have got a variety of
options. Depending on your use case, you may want to expose your model
as an endpoint or package it in an application itself. TensorFlow
provides tools that cater to each of these different scenarios.
In this post, you'll see how to deploy a Vision Transformer (ViT) model (for image classification)
locally using [TensorFlow Serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple)
(TF Serving). This will allow developers to expose the model either as a
REST or gRPC endpoint. Moreover, TF Serving supports many
deployment-specific features off-the-shelf such as model warmup,
server-side batching, etc.
To get the complete working code shown throughout this post, refer to
the Colab Notebook shown at the beginning.
# Saving the Model
All TensorFlow models in 🤗 Transformers have a method named
`save_pretrained()`. With it, you can serialize the model weights in
the h5 format as well as in the standalone [SavedModel format](https://www.tensorflow.org/guide/saved_model).
TF Serving needs a model to be present in the SavedModel format. So, let's first
load a Vision Transformer model and save it:
```py
from transformers import TFViTForImageClassification
temp_model_dir = "vit"
ckpt = "google/vit-base-patch16-224"
model = TFViTForImageClassification.from_pretrained(ckpt)
model.save_pretrained(temp_model_dir, saved_model=True)
```
By default, `save_pretrained()` will first create a version directory
inside the path we provide to it. So, the path ultimately becomes:
`{temp_model_dir}/saved_model/{version}`.
We can inspect the serving signature of the SavedModel like so:
```bash
saved_model_cli show --dir {temp_model_dir}/saved_model/1 --tag_set serve --signature_def serving_default
```
This should output:
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['pixel_values'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, -1, -1)
name: serving_default_pixel_values:0
The given SavedModel SignatureDef contains the following output(s):
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1000)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
```
As can be noticed the model accepts single 4-d inputs (namely
`pixel_values`) which has the following axes: `(batch_size,
num_channels, height, width)`. For this model, the acceptable height
and width are set to 224, and the number of channels is 3. You can verify
this by inspecting the config argument of the model (`model.config`).
The model yields a 1000-d vector of `logits`.
# Model Surgery
Usually, every ML model has certain preprocessing and postprocessing
steps. The ViT model is no exception to this. The major preprocessing
steps include:
- Scaling the image pixel values to [0, 1] range.
- Normalizing the scaled pixel values to [-1, 1].
- Resizing the image so that it has a spatial resolution of (224, 224).
You can confirm these by investigating the image processor associated
with the model:
```py
from transformers import AutoImageProcessor
processor = AutoImageProcessor.from_pretrained(ckpt)
print(processor)
```
This should print:
```bash
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
Since this is an image classification model pre-trained on the
[ImageNet-1k dataset](https://huggingface.co/datasets/imagenet-1k), the model
outputs need to be mapped to the ImageNet-1k classes as the
post-processing step.
To reduce the developers' cognitive load and training-serving skew,
it's often a good idea to ship a model that has most of the
preprocessing and postprocessing steps in built. Therefore, you should
serialize the model as a SavedModel such that the above-mentioned
processing ops get embedded into its computation graph.
## Preprocessing
For preprocessing, image normalization is one of the most essential
components:
```py
def normalize_img(
img, mean=processor.image_mean, std=processor.image_std
):
# Scale to the value range of [0, 1] first and then normalize.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
```
You also need to resize the image and transpose it so that it has leading
channel dimensions since following the standard format of 🤗
Transformers. The below code snippet shows all the preprocessing steps:
```py
CONCRETE_INPUT = "pixel_values" # Which is what we investigated via the SavedModel CLI.
SIZE = processor.size["height"]
def normalize_img(
img, mean=processor.image_mean, std=processor.image_std
):
# Scale to the value range of [0, 1] first and then normalize.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
def preprocess(string_input):
decoded_input = tf.io.decode_base64(string_input)
decoded = tf.io.decode_jpeg(decoded_input, channels=3)
resized = tf.image.resize(decoded, size=(SIZE, SIZE))
normalized = normalize_img(resized)
normalized = tf.transpose(
normalized, (2, 0, 1)
) # Since HF models are channel-first.
return normalized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(string_input):
decoded_images = tf.map_fn(
preprocess, string_input, dtype=tf.float32, back_prop=False
)
return {CONCRETE_INPUT: decoded_images}
```
**Note on making the model accept string inputs**:
When dealing with images via REST or gRPC requests the size of the
request payload can easily spiral up depending on the resolution of the
images being passed. This is why it is a good practice to compress them
reliably and then prepare the request payload.
## Postprocessing and Model Export
You're now equipped with the preprocessing operations that you can inject
into the model's existing computation graph. In this section, you'll also
inject the post-processing operations into the graph and export the
model!
```py
def model_exporter(model: tf.keras.Model):
m_call = tf.function(model.call).get_concrete_function(
tf.TensorSpec(
shape=[None, 3, SIZE, SIZE], dtype=tf.float32, name=CONCRETE_INPUT
)
)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(string_input):
labels = tf.constant(list(model.config.id2label.values()), dtype=tf.string)
images = preprocess_fn(string_input)
predictions = m_call(**images)
indices = tf.argmax(predictions.logits, axis=1)
pred_source = tf.gather(params=labels, indices=indices)
probs = tf.nn.softmax(predictions.logits, axis=1)
pred_confidence = tf.reduce_max(probs, axis=1)
return {"label": pred_source, "confidence": pred_confidence}
return serving_fn
```
You can first derive the [concrete function](https://www.tensorflow.org/guide/function)
from the model's forward pass method (`call()`) so the model is nicely compiled
into a graph. After that, you can apply the following steps in order:
1. Pass the inputs through the preprocessing operations.
2. Pass the preprocessing inputs through the derived concrete function.
3. Post-process the outputs and return them in a nicely formatted
dictionary.
Now it's time to export the model!
```py
MODEL_DIR = tempfile.gettempdir()
VERSION = 1
tf.saved_model.save(
model,
os.path.join(MODEL_DIR, str(VERSION)),
signatures={"serving_default": model_exporter(model)},
)
os.environ["MODEL_DIR"] = MODEL_DIR
```
After exporting, let's inspect the model signatures again:
```bash
saved_model_cli show --dir {MODEL_DIR}/1 --tag_set serve --signature_def serving_default
```
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
You can notice that the model's signature has now changed. Specifically,
the input type is now a string and the model returns two things: a
confidence score and the string label.
Provided you've already installed TF Serving (covered in the Colab
Notebook), you're now ready to deploy this model!
# Deployment with TensorFlow Serving
It just takes a single command to do this:
```bash
nohup tensorflow_model_server \
--rest_api_port=8501 \
--model_name=vit \
--model_base_path=$MODEL_DIR >server.log 2>&1
```
From the above command, the important parameters are:
- `rest_api_port` denotes the port number that TF Serving will use
deploying the REST endpoint of your model. By default, TF Serving
uses the 8500 port for the gRPC endpoint.
- `model_name` specifies the model name (can be anything) that will
used for calling the APIs.
- `model_base_path` denotes the base model path that TF Serving will
use to load the latest version of the model.
(The complete list of supported parameters is
[here](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/model_servers/main.cc).)
And voila! Within minutes, you should be up and running with a deployed
model having two endpoints - REST and gRPC.
# Querying the REST Endpoint
Recall that you exported the model such that it accepts string inputs
encoded with the [base64 format](https://en.wikipedia.org/wiki/Base64). So, to craft the
request payload you can do something like this:
```py
# Get image of a cute cat.
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
# Read the image from disk as raw bytes and then encode it.
bytes_inputs = tf.io.read_file(image_path)
b64str = base64.urlsafe_b64encode(bytes_inputs.numpy()).decode("utf-8")
# Create the request payload.
data = json.dumps({"signature_name": "serving_default", "instances": [b64str]})
```
TF Serving's request payload format specification for the REST endpoint
is available [here](https://www.tensorflow.org/tfx/serving/api_rest#request_format_2).
Within the `instances` you can pass multiple encoded images. This kind
of endpoints are meant to be consumed for online prediction scenarios.
For inputs having more than a single data point, you would to want to
[enable batching](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/batching/README.md)
to get performance optimization benefits.
Now you can call the API:
```py
headers = {"content-type": "application/json"}
json_response = requests.post(
"http://localhost:8501/v1/models/vit:predict", data=data, headers=headers
)
print(json.loads(json_response.text))
# {'predictions': [{'label': 'Egyptian cat', 'confidence': 0.896659195}]}
```
The REST API is -
`http://localhost:8501/v1/models/vit:predict` following the specification from
[here](https://www.tensorflow.org/tfx/serving/api_rest#predict_api). By default,
this always picks up the latest version of the model. But if you wanted a
specific version you can do: `http://localhost:8501/v1/models/vit/versions/1:predict`.
# Querying the gRPC Endpoint
While REST is quite popular in the API world, many applications often
benefit from gRPC. [This post](https://blog.dreamfactory.com/grpc-vs-rest-how-does-grpc-compare-with-traditional-rest-apis/)
does a good job comparing the two ways of deployment. gRPC is usually
preferred for low-latency, highly scalable, and distributed systems.
There are a couple of steps are. First, you need to open a communication
channel:
```py
import grpc
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
```
Then, create the request payload:
```py
request = predict_pb2.PredictRequest()
request.model_spec.name = "vit"
request.model_spec.signature_name = "serving_default"
request.inputs[serving_input].CopyFrom(tf.make_tensor_proto([b64str]))
```
You can determine the `serving_input` key programmatically like so:
```py
loaded = tf.saved_model.load(f"{MODEL_DIR}/{VERSION}")
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input:", serving_input)
# Serving function input: string_input
```
Now, you can get some predictions:
```py
grpc_predictions = stub.Predict(request, 10.0) # 10 secs timeout
print(grpc_predictions)
```
```bash
outputs {
key: "confidence"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
}
float_val: 0.8966591954231262
}
}
outputs {
key: "label"
value {
dtype: DT_STRING
tensor_shape {
dim {
size: 1
}
}
string_val: "Egyptian cat"
}
}
model_spec {
name: "resnet"
version {
value: 1
}
signature_name: "serving_default"
}
```
You can also fetch the key-values of our interest from the above results like so:
```py
grpc_predictions.outputs["label"].string_val, grpc_predictions.outputs[
"confidence"
].float_val
# ([b'Egyptian cat'], [0.8966591954231262])
```
# Wrapping Up
In this post, we learned how to deploy a TensorFlow vision model from
Transformers with TF Serving. While local deployments are great for
weekend projects, we would want to be able to scale these deployments to
serve many users. In the next series of posts, you'll see how to scale up
these deployments with Kubernetes and Vertex AI.
# Additional References
- [gRPC](https://grpc.io/)
- [Practical Machine Learning for Computer Vision](https://www.oreilly.com/library/view/practical-machine-learning/9781098102357/)
- [Faster TensorFlow models in Hugging Face Transformers](https://huggingface.co/blog/tf-serving)
| huggingface/blog/blob/main/tf-serving-vision.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Train a diffusion model
Unconditional image generation is a popular application of diffusion models that generates images that look like those in the dataset used for training. Typically, the best results are obtained from finetuning a pretrained model on a specific dataset. You can find many of these checkpoints on the [Hub](https://huggingface.co/search/full-text?q=unconditional-image-generation&type=model), but if you can't find one you like, you can always train your own!
This tutorial will teach you how to train a [`UNet2DModel`] from scratch on a subset of the [Smithsonian Butterflies](https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset) dataset to generate your own 🦋 butterflies 🦋.
<Tip>
💡 This training tutorial is based on the [Training with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) notebook. For additional details and context about diffusion models like how they work, check out the notebook!
</Tip>
Before you begin, make sure you have 🤗 Datasets installed to load and preprocess image datasets, and 🤗 Accelerate, to simplify training on any number of GPUs. The following command will also install [TensorBoard](https://www.tensorflow.org/tensorboard) to visualize training metrics (you can also use [Weights & Biases](https://docs.wandb.ai/) to track your training).
```py
# uncomment to install the necessary libraries in Colab
#!pip install diffusers[training]
```
We encourage you to share your model with the community, and in order to do that, you'll need to login to your Hugging Face account (create one [here](https://hf.co/join) if you don't already have one!). You can login from a notebook and enter your token when prompted. Make sure your token has the write role.
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
Or login in from the terminal:
```bash
huggingface-cli login
```
Since the model checkpoints are quite large, install [Git-LFS](https://git-lfs.com/) to version these large files:
```bash
!sudo apt -qq install git-lfs
!git config --global credential.helper store
```
## Training configuration
For convenience, create a `TrainingConfig` class containing the training hyperparameters (feel free to adjust them):
```py
>>> from dataclasses import dataclass
>>> @dataclass
... class TrainingConfig:
... image_size = 128 # the generated image resolution
... train_batch_size = 16
... eval_batch_size = 16 # how many images to sample during evaluation
... num_epochs = 50
... gradient_accumulation_steps = 1
... learning_rate = 1e-4
... lr_warmup_steps = 500
... save_image_epochs = 10
... save_model_epochs = 30
... mixed_precision = "fp16" # `no` for float32, `fp16` for automatic mixed precision
... output_dir = "ddpm-butterflies-128" # the model name locally and on the HF Hub
... push_to_hub = True # whether to upload the saved model to the HF Hub
... hub_model_id = "<your-username>/<my-awesome-model>" # the name of the repository to create on the HF Hub
... hub_private_repo = False
... overwrite_output_dir = True # overwrite the old model when re-running the notebook
... seed = 0
>>> config = TrainingConfig()
```
## Load the dataset
You can easily load the [Smithsonian Butterflies](https://huggingface.co/datasets/huggan/smithsonian_butterflies_subset) dataset with the 🤗 Datasets library:
```py
>>> from datasets import load_dataset
>>> config.dataset_name = "huggan/smithsonian_butterflies_subset"
>>> dataset = load_dataset(config.dataset_name, split="train")
```
<Tip>
💡 You can find additional datasets from the [HugGan Community Event](https://huggingface.co/huggan) or you can use your own dataset by creating a local [`ImageFolder`](https://huggingface.co/docs/datasets/image_dataset#imagefolder). Set `config.dataset_name` to the repository id of the dataset if it is from the HugGan Community Event, or `imagefolder` if you're using your own images.
</Tip>
🤗 Datasets uses the [`~datasets.Image`] feature to automatically decode the image data and load it as a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html) which we can visualize:
```py
>>> import matplotlib.pyplot as plt
>>> fig, axs = plt.subplots(1, 4, figsize=(16, 4))
>>> for i, image in enumerate(dataset[:4]["image"]):
... axs[i].imshow(image)
... axs[i].set_axis_off()
>>> fig.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/butterflies_ds.png"/>
</div>
The images are all different sizes though, so you'll need to preprocess them first:
* `Resize` changes the image size to the one defined in `config.image_size`.
* `RandomHorizontalFlip` augments the dataset by randomly mirroring the images.
* `Normalize` is important to rescale the pixel values into a [-1, 1] range, which is what the model expects.
```py
>>> from torchvision import transforms
>>> preprocess = transforms.Compose(
... [
... transforms.Resize((config.image_size, config.image_size)),
... transforms.RandomHorizontalFlip(),
... transforms.ToTensor(),
... transforms.Normalize([0.5], [0.5]),
... ]
... )
```
Use 🤗 Datasets' [`~datasets.Dataset.set_transform`] method to apply the `preprocess` function on the fly during training:
```py
>>> def transform(examples):
... images = [preprocess(image.convert("RGB")) for image in examples["image"]]
... return {"images": images}
>>> dataset.set_transform(transform)
```
Feel free to visualize the images again to confirm that they've been resized. Now you're ready to wrap the dataset in a [DataLoader](https://pytorch.org/docs/stable/data#torch.utils.data.DataLoader) for training!
```py
>>> import torch
>>> train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=config.train_batch_size, shuffle=True)
```
## Create a UNet2DModel
Pretrained models in 🧨 Diffusers are easily created from their model class with the parameters you want. For example, to create a [`UNet2DModel`]:
```py
>>> from diffusers import UNet2DModel
>>> model = UNet2DModel(
... sample_size=config.image_size, # the target image resolution
... in_channels=3, # the number of input channels, 3 for RGB images
... out_channels=3, # the number of output channels
... layers_per_block=2, # how many ResNet layers to use per UNet block
... block_out_channels=(128, 128, 256, 256, 512, 512), # the number of output channels for each UNet block
... down_block_types=(
... "DownBlock2D", # a regular ResNet downsampling block
... "DownBlock2D",
... "DownBlock2D",
... "DownBlock2D",
... "AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
... "DownBlock2D",
... ),
... up_block_types=(
... "UpBlock2D", # a regular ResNet upsampling block
... "AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
... "UpBlock2D",
... "UpBlock2D",
... "UpBlock2D",
... "UpBlock2D",
... ),
... )
```
It is often a good idea to quickly check the sample image shape matches the model output shape:
```py
>>> sample_image = dataset[0]["images"].unsqueeze(0)
>>> print("Input shape:", sample_image.shape)
Input shape: torch.Size([1, 3, 128, 128])
>>> print("Output shape:", model(sample_image, timestep=0).sample.shape)
Output shape: torch.Size([1, 3, 128, 128])
```
Great! Next, you'll need a scheduler to add some noise to the image.
## Create a scheduler
The scheduler behaves differently depending on whether you're using the model for training or inference. During inference, the scheduler generates image from the noise. During training, the scheduler takes a model output - or a sample - from a specific point in the diffusion process and applies noise to the image according to a *noise schedule* and an *update rule*.
Let's take a look at the [`DDPMScheduler`] and use the `add_noise` method to add some random noise to the `sample_image` from before:
```py
>>> import torch
>>> from PIL import Image
>>> from diffusers import DDPMScheduler
>>> noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
>>> noise = torch.randn(sample_image.shape)
>>> timesteps = torch.LongTensor([50])
>>> noisy_image = noise_scheduler.add_noise(sample_image, noise, timesteps)
>>> Image.fromarray(((noisy_image.permute(0, 2, 3, 1) + 1.0) * 127.5).type(torch.uint8).numpy()[0])
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/noisy_butterfly.png"/>
</div>
The training objective of the model is to predict the noise added to the image. The loss at this step can be calculated by:
```py
>>> import torch.nn.functional as F
>>> noise_pred = model(noisy_image, timesteps).sample
>>> loss = F.mse_loss(noise_pred, noise)
```
## Train the model
By now, you have most of the pieces to start training the model and all that's left is putting everything together.
First, you'll need an optimizer and a learning rate scheduler:
```py
>>> from diffusers.optimization import get_cosine_schedule_with_warmup
>>> optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate)
>>> lr_scheduler = get_cosine_schedule_with_warmup(
... optimizer=optimizer,
... num_warmup_steps=config.lr_warmup_steps,
... num_training_steps=(len(train_dataloader) * config.num_epochs),
... )
```
Then, you'll need a way to evaluate the model. For evaluation, you can use the [`DDPMPipeline`] to generate a batch of sample images and save it as a grid:
```py
>>> from diffusers import DDPMPipeline
>>> from diffusers.utils import make_image_grid
>>> import os
>>> def evaluate(config, epoch, pipeline):
... # Sample some images from random noise (this is the backward diffusion process).
... # The default pipeline output type is `List[PIL.Image]`
... images = pipeline(
... batch_size=config.eval_batch_size,
... generator=torch.manual_seed(config.seed),
... ).images
... # Make a grid out of the images
... image_grid = make_image_grid(images, rows=4, cols=4)
... # Save the images
... test_dir = os.path.join(config.output_dir, "samples")
... os.makedirs(test_dir, exist_ok=True)
... image_grid.save(f"{test_dir}/{epoch:04d}.png")
```
Now you can wrap all these components together in a training loop with 🤗 Accelerate for easy TensorBoard logging, gradient accumulation, and mixed precision training. To upload the model to the Hub, write a function to get your repository name and information and then push it to the Hub.
<Tip>
💡 The training loop below may look intimidating and long, but it'll be worth it later when you launch your training in just one line of code! If you can't wait and want to start generating images, feel free to copy and run the code below. You can always come back and examine the training loop more closely later, like when you're waiting for your model to finish training. 🤗
</Tip>
```py
>>> from accelerate import Accelerator
>>> from huggingface_hub import create_repo, upload_folder
>>> from tqdm.auto import tqdm
>>> from pathlib import Path
>>> import os
>>> def train_loop(config, model, noise_scheduler, optimizer, train_dataloader, lr_scheduler):
... # Initialize accelerator and tensorboard logging
... accelerator = Accelerator(
... mixed_precision=config.mixed_precision,
... gradient_accumulation_steps=config.gradient_accumulation_steps,
... log_with="tensorboard",
... project_dir=os.path.join(config.output_dir, "logs"),
... )
... if accelerator.is_main_process:
... if config.output_dir is not None:
... os.makedirs(config.output_dir, exist_ok=True)
... if config.push_to_hub:
... repo_id = create_repo(
... repo_id=config.hub_model_id or Path(config.output_dir).name, exist_ok=True
... ).repo_id
... accelerator.init_trackers("train_example")
... # Prepare everything
... # There is no specific order to remember, you just need to unpack the
... # objects in the same order you gave them to the prepare method.
... model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
... model, optimizer, train_dataloader, lr_scheduler
... )
... global_step = 0
... # Now you train the model
... for epoch in range(config.num_epochs):
... progress_bar = tqdm(total=len(train_dataloader), disable=not accelerator.is_local_main_process)
... progress_bar.set_description(f"Epoch {epoch}")
... for step, batch in enumerate(train_dataloader):
... clean_images = batch["images"]
... # Sample noise to add to the images
... noise = torch.randn(clean_images.shape, device=clean_images.device)
... bs = clean_images.shape[0]
... # Sample a random timestep for each image
... timesteps = torch.randint(
... 0, noise_scheduler.config.num_train_timesteps, (bs,), device=clean_images.device,
... dtype=torch.int64
... )
... # Add noise to the clean images according to the noise magnitude at each timestep
... # (this is the forward diffusion process)
... noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
... with accelerator.accumulate(model):
... # Predict the noise residual
... noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
... loss = F.mse_loss(noise_pred, noise)
... accelerator.backward(loss)
... accelerator.clip_grad_norm_(model.parameters(), 1.0)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
... logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
... progress_bar.set_postfix(**logs)
... accelerator.log(logs, step=global_step)
... global_step += 1
... # After each epoch you optionally sample some demo images with evaluate() and save the model
... if accelerator.is_main_process:
... pipeline = DDPMPipeline(unet=accelerator.unwrap_model(model), scheduler=noise_scheduler)
... if (epoch + 1) % config.save_image_epochs == 0 or epoch == config.num_epochs - 1:
... evaluate(config, epoch, pipeline)
... if (epoch + 1) % config.save_model_epochs == 0 or epoch == config.num_epochs - 1:
... if config.push_to_hub:
... upload_folder(
... repo_id=repo_id,
... folder_path=config.output_dir,
... commit_message=f"Epoch {epoch}",
... ignore_patterns=["step_*", "epoch_*"],
... )
... else:
... pipeline.save_pretrained(config.output_dir)
```
Phew, that was quite a bit of code! But you're finally ready to launch the training with 🤗 Accelerate's [`~accelerate.notebook_launcher`] function. Pass the function the training loop, all the training arguments, and the number of processes (you can change this value to the number of GPUs available to you) to use for training:
```py
>>> from accelerate import notebook_launcher
>>> args = (config, model, noise_scheduler, optimizer, train_dataloader, lr_scheduler)
>>> notebook_launcher(train_loop, args, num_processes=1)
```
Once training is complete, take a look at the final 🦋 images 🦋 generated by your diffusion model!
```py
>>> import glob
>>> sample_images = sorted(glob.glob(f"{config.output_dir}/samples/*.png"))
>>> Image.open(sample_images[-1])
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/butterflies_final.png"/>
</div>
## Next steps
Unconditional image generation is one example of a task that can be trained. You can explore other tasks and training techniques by visiting the [🧨 Diffusers Training Examples](../training/overview) page. Here are some examples of what you can learn:
* [Textual Inversion](../training/text_inversion), an algorithm that teaches a model a specific visual concept and integrates it into the generated image.
* [DreamBooth](../training/dreambooth), a technique for generating personalized images of a subject given several input images of the subject.
* [Guide](../training/text2image) to finetuning a Stable Diffusion model on your own dataset.
* [Guide](../training/lora) to using LoRA, a memory-efficient technique for finetuning really large models faster.
| huggingface/diffusers/blob/main/docs/source/en/tutorials/basic_training.md |
FrameworkSwitchCourse {fw} />
# Question answering[[question-answering]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={7}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter7/section7_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter7/section7_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={7}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter7/section7_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter7/section7_tf.ipynb"},
]} />
{/if}
Time to look at question answering! This task comes in many flavors, but the one we'll focus on in this section is called *extractive* question answering. This involves posing questions about a document and identifying the answers as _spans of text_ in the document itself.
<Youtube id="ajPx5LwJD-I"/>
We will fine-tune a BERT model on the [SQuAD dataset](https://rajpurkar.github.io/SQuAD-explorer/), which consists of questions posed by crowdworkers on a set of Wikipedia articles. This will give us a model able to compute predictions like this one:
<iframe src="https://course-demos-bert-finetuned-squad.hf.space" frameBorder="0" height="450" title="Gradio app" class="block dark:hidden container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
This is actually showcasing the model that was trained and uploaded to the Hub using the code shown in this section. You can find it and double-check the predictions [here](https://huggingface.co/huggingface-course/bert-finetuned-squad?context=%F0%9F%A4%97+Transformers+is+backed+by+the+three+most+popular+deep+learning+libraries+%E2%80%94+Jax%2C+PyTorch+and+TensorFlow+%E2%80%94+with+a+seamless+integration+between+them.+It%27s+straightforward+to+train+your+models+with+one+before+loading+them+for+inference+with+the+other.&question=Which+deep+learning+libraries+back+%F0%9F%A4%97+Transformers%3F).
<Tip>
💡 Encoder-only models like BERT tend to be great at extracting answers to factoid questions like "Who invented the Transformer architecture?" but fare poorly when given open-ended questions like "Why is the sky blue?" In these more challenging cases, encoder-decoder models like T5 and BART are typically used to synthesize the information in a way that's quite similar to [text summarization](/course/chapter7/5). If you're interested in this type of *generative* question answering, we recommend checking out our [demo](https://yjernite.github.io/lfqa.html) based on the [ELI5 dataset](https://huggingface.co/datasets/eli5).
</Tip>
## Preparing the data[[preparing-the-data]]
The dataset that is used the most as an academic benchmark for extractive question answering is [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/), so that's the one we'll use here. There is also a harder [SQuAD v2](https://huggingface.co/datasets/squad_v2) benchmark, which includes questions that don't have an answer. As long as your own dataset contains a column for contexts, a column for questions, and a column for answers, you should be able to adapt the steps below.
### The SQuAD dataset[[the-squad-dataset]]
As usual, we can download and cache the dataset in just one step thanks to `load_dataset()`:
```py
from datasets import load_dataset
raw_datasets = load_dataset("squad")
```
We can then have a look at this object to learn more about the SQuAD dataset:
```py
raw_datasets
```
```python out
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 87599
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})
})
```
It looks like we have everything we need with the `context`, `question`, and `answers` fields, so let's print those for the first element of our training set:
```py
print("Context: ", raw_datasets["train"][0]["context"])
print("Question: ", raw_datasets["train"][0]["question"])
print("Answer: ", raw_datasets["train"][0]["answers"])
```
```python out
Context: 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.'
Question: 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?'
Answer: {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}
```
The `context` and `question` fields are very straightforward to use. The `answers` field is a bit trickier as it comports a dictionary with two fields that are both lists. This is the format that will be expected by the `squad` metric during evaluation; if you are using your own data, you don't necessarily need to worry about putting the answers in the same format. The `text` field is rather obvious, and the `answer_start` field contains the starting character index of each answer in the context.
During training, there is only one possible answer. We can double-check this by using the `Dataset.filter()` method:
```py
raw_datasets["train"].filter(lambda x: len(x["answers"]["text"]) != 1)
```
```python out
Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 0
})
```
For evaluation, however, there are several possible answers for each sample, which may be the same or different:
```py
print(raw_datasets["validation"][0]["answers"])
print(raw_datasets["validation"][2]["answers"])
```
```python out
{'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}
{'text': ['Santa Clara, California', "Levi's Stadium", "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California."], 'answer_start': [403, 355, 355]}
```
We won't dive into the evaluation script as it will all be wrapped up by a 🤗 Datasets metric for us, but the short version is that some of the questions have several possible answers, and this script will compare a predicted answer to all the acceptable answers and take the best score. If we take a look at the sample at index 2, for instance:
```py
print(raw_datasets["validation"][2]["context"])
print(raw_datasets["validation"][2]["question"])
```
```python out
'Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi\'s Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.'
'Where did Super Bowl 50 take place?'
```
we can see that the answer can indeed be one of the three possibilities we saw before.
### Processing the training data[[processing-the-training-data]]
<Youtube id="qgaM0weJHpA"/>
Let's start with preprocessing the training data. The hard part will be to generate labels for the question's answer, which will be the start and end positions of the tokens corresponding to the answer inside the context.
But let's not get ahead of ourselves. First, we need to convert the text in the input into IDs the model can make sense of, using a tokenizer:
```py
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
As mentioned previously, we'll be fine-tuning a BERT model, but you can use any other model type as long as it has a fast tokenizer implemented. You can see all the architectures that come with a fast version in [this big table](https://huggingface.co/transformers/#supported-frameworks), and to check that the `tokenizer` object you're using is indeed backed by 🤗 Tokenizers you can look at its `is_fast` attribute:
```py
tokenizer.is_fast
```
```python out
True
```
We can pass to our tokenizer the question and the context together, and it will properly insert the special tokens to form a sentence like this:
```
[CLS] question [SEP] context [SEP]
```
Let's double-check:
```py
context = raw_datasets["train"][0]["context"]
question = raw_datasets["train"][0]["question"]
inputs = tokenizer(question, context)
tokenizer.decode(inputs["input_ids"])
```
```python out
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, '
'the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin '
'Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms '
'upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred '
'Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a '
'replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette '
'Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues '
'and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
```
The labels will then be the index of the tokens starting and ending the answer, and the model will be tasked to predicted one start and end logit per token in the input, with the theoretical labels being as follow:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/qa_labels.svg" alt="One-hot encoded labels for question answering."/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter7/qa_labels-dark.svg" alt="One-hot encoded labels for question answering."/>
</div>
In this case the context is not too long, but some of the examples in the dataset have very long contexts that will exceed the maximum length we set (which is 384 in this case). As we saw in [Chapter 6](/course/chapter6/4) when we explored the internals of the `question-answering` pipeline, we will deal with long contexts by creating several training features from one sample of our dataset, with a sliding window between them.
To see how this works using the current example, we can limit the length to 100 and use a sliding window of 50 tokens. As a reminder, we use:
- `max_length` to set the maximum length (here 100)
- `truncation="only_second"` to truncate the context (which is in the second position) when the question with its context is too long
- `stride` to set the number of overlapping tokens between two successive chunks (here 50)
- `return_overflowing_tokens=True` to let the tokenizer know we want the overflowing tokens
```py
inputs = tokenizer(
question,
context,
max_length=100,
truncation="only_second",
stride=50,
return_overflowing_tokens=True,
)
for ids in inputs["input_ids"]:
print(tokenizer.decode(ids))
```
```python out
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basi [SEP]'
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin [SEP]'
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 [SEP]'
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP]. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
```
As we can see, our example has been in split into four inputs, each of them containing the question and some part of the context. Note that the answer to the question ("Bernadette Soubirous") only appears in the third and last inputs, so by dealing with long contexts in this way we will create some training examples where the answer is not included in the context. For those examples, the labels will be `start_position = end_position = 0` (so we predict the `[CLS]` token). We will also set those labels in the unfortunate case where the answer has been truncated so that we only have the start (or end) of it. For the examples where the answer is fully in the context, the labels will be the index of the token where the answer starts and the index of the token where the answer ends.
The dataset provides us with the start character of the answer in the context, and by adding the length of the answer, we can find the end character in the context. To map those to token indices, we will need to use the offset mappings we studied in [Chapter 6](/course/chapter6/4). We can have our tokenizer return these by passing along `return_offsets_mapping=True`:
```py
inputs = tokenizer(
question,
context,
max_length=100,
truncation="only_second",
stride=50,
return_overflowing_tokens=True,
return_offsets_mapping=True,
)
inputs.keys()
```
```python out
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping'])
```
As we can see, we get back the usual input IDs, token type IDs, and attention mask, as well as the offset mapping we required and an extra key, `overflow_to_sample_mapping`. The corresponding value will be of use to us when we tokenize several texts at the same time (which we should do to benefit from the fact that our tokenizer is backed by Rust). Since one sample can give several features, it maps each feature to the example it originated from. Because here we only tokenized one example, we get a list of `0`s:
```py
inputs["overflow_to_sample_mapping"]
```
```python out
[0, 0, 0, 0]
```
But if we tokenize more examples, this will become more useful:
```py
inputs = tokenizer(
raw_datasets["train"][2:6]["question"],
raw_datasets["train"][2:6]["context"],
max_length=100,
truncation="only_second",
stride=50,
return_overflowing_tokens=True,
return_offsets_mapping=True,
)
print(f"The 4 examples gave {len(inputs['input_ids'])} features.")
print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.")
```
```python out
'The 4 examples gave 19 features.'
'Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].'
```
As we can see, the first three examples (at indices 2, 3, and 4 in the training set) each gave four features and the last example (at index 5 in the training set) gave 7 features.
This information will be useful to map each feature we get to its corresponding label. As mentioned earlier, those labels are:
- `(0, 0)` if the answer is not in the corresponding span of the context
- `(start_position, end_position)` if the answer is in the corresponding span of the context, with `start_position` being the index of the token (in the input IDs) at the start of the answer and `end_position` being the index of the token (in the input IDs) where the answer ends
To determine which of these is the case and, if relevant, the positions of the tokens, we first find the indices that start and end the context in the input IDs. We could use the token type IDs to do this, but since those do not necessarily exist for all models (DistilBERT does not require them, for instance), we'll instead use the `sequence_ids()` method of the `BatchEncoding` our tokenizer returns.
Once we have those token indices, we look at the corresponding offsets, which are tuples of two integers representing the span of characters inside the original context. We can thus detect if the chunk of the context in this feature starts after the answer or ends before the answer begins (in which case the label is `(0, 0)`). If that's not the case, we loop to find the first and last token of the answer:
```py
answers = raw_datasets["train"][2:6]["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(inputs["offset_mapping"]):
sample_idx = inputs["overflow_to_sample_mapping"][i]
answer = answers[sample_idx]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label is (0, 0)
if offset[context_start][0] > start_char or offset[context_end][1] < end_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
start_positions, end_positions
```
```python out
([83, 51, 19, 0, 0, 64, 27, 0, 34, 0, 0, 0, 67, 34, 0, 0, 0, 0, 0],
[85, 53, 21, 0, 0, 70, 33, 0, 40, 0, 0, 0, 68, 35, 0, 0, 0, 0, 0])
```
Let's take a look at a few results to verify that our approach is correct. For the first feature we find `(83, 85)` as labels, so let's compare the theoretical answer with the decoded span of tokens from 83 to 85 (inclusive):
```py
idx = 0
sample_idx = inputs["overflow_to_sample_mapping"][idx]
answer = answers[sample_idx]["text"][0]
start = start_positions[idx]
end = end_positions[idx]
labeled_answer = tokenizer.decode(inputs["input_ids"][idx][start : end + 1])
print(f"Theoretical answer: {answer}, labels give: {labeled_answer}")
```
```python out
'Theoretical answer: the Main Building, labels give: the Main Building'
```
So that's a match! Now let's check index 4, where we set the labels to `(0, 0)`, which means the answer is not in the context chunk of that feature:
```py
idx = 4
sample_idx = inputs["overflow_to_sample_mapping"][idx]
answer = answers[sample_idx]["text"][0]
decoded_example = tokenizer.decode(inputs["input_ids"][idx])
print(f"Theoretical answer: {answer}, decoded example: {decoded_example}")
```
```python out
'Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]'
```
Indeed, we don't see the answer inside the context.
<Tip>
✏️ **Your turn!** When using the XLNet architecture, padding is applied on the left and the question and context are switched. Adapt all the code we just saw to the XLNet architecture (and add `padding=True`). Be aware that the `[CLS]` token may not be at the 0 position with padding applied.
</Tip>
Now that we have seen step by step how to preprocess our training data, we can group it in a function we will apply on the whole training dataset. We'll pad every feature to the maximum length we set, as most of the contexts will be long (and the corresponding samples will be split into several features), so there is no real benefit to applying dynamic padding here:
```py
max_length = 384
stride = 128
def preprocess_training_examples(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=max_length,
truncation="only_second",
stride=stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
sample_map = inputs.pop("overflow_to_sample_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
sample_idx = sample_map[i]
answer = answers[sample_idx]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label is (0, 0)
if offset[context_start][0] > start_char or offset[context_end][1] < end_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
```
Note that we defined two constants to determine the maximum length used as well as the length of the sliding window, and that we added a tiny bit of cleanup before tokenizing: some of the questions in the SQuAD dataset have extra spaces at the beginning and the end that don't add anything (and take up space when being tokenized if you use a model like RoBERTa), so we removed those extra spaces.
To apply this function to the whole training set, we use the `Dataset.map()` method with the `batched=True` flag. It's necessary here as we are changing the length of the dataset (since one example can give several training features):
```py
train_dataset = raw_datasets["train"].map(
preprocess_training_examples,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)
len(raw_datasets["train"]), len(train_dataset)
```
```python out
(87599, 88729)
```
As we can see, the preprocessing added roughly 1,000 features. Our training set is now ready to be used -- let's dig into the preprocessing of the validation set!
### Processing the validation data[[processing-the-validation-data]]
Preprocessing the validation data will be slightly easier as we don't need to generate labels (unless we want to compute a validation loss, but that number won't really help us understand how good the model is). The real joy will be to interpret the predictions of the model into spans of the original context. For this, we will just need to store both the offset mappings and some way to match each created feature to the original example it comes from. Since there is an ID column in the original dataset, we'll use that ID.
The only thing we'll add here is a tiny bit of cleanup of the offset mappings. They will contain offsets for the question and the context, but once we're in the post-processing stage we won't have any way to know which part of the input IDs corresponded to the context and which part was the question (the `sequence_ids()` method we used is available for the output of the tokenizer only). So, we'll set the offsets corresponding to the question to `None`:
```py
def preprocess_validation_examples(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=max_length,
truncation="only_second",
stride=stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_map = inputs.pop("overflow_to_sample_mapping")
example_ids = []
for i in range(len(inputs["input_ids"])):
sample_idx = sample_map[i]
example_ids.append(examples["id"][sample_idx])
sequence_ids = inputs.sequence_ids(i)
offset = inputs["offset_mapping"][i]
inputs["offset_mapping"][i] = [
o if sequence_ids[k] == 1 else None for k, o in enumerate(offset)
]
inputs["example_id"] = example_ids
return inputs
```
We can apply this function on the whole validation dataset like before:
```py
validation_dataset = raw_datasets["validation"].map(
preprocess_validation_examples,
batched=True,
remove_columns=raw_datasets["validation"].column_names,
)
len(raw_datasets["validation"]), len(validation_dataset)
```
```python out
(10570, 10822)
```
In this case we've only added a couple of hundred samples, so it appears the contexts in the validation dataset are a bit shorter.
Now that we have preprocessed all the data, we can get to the training.
{#if fw === 'pt'}
## Fine-tuning the model with the `Trainer` API[[fine-tuning-the-model-with-the-trainer-api]]
The training code for this example will look a lot like the code in the previous sections -- the hardest thing will be to write the `compute_metrics()` function. Since we padded all the samples to the maximum length we set, there is no data collator to define, so this metric computation is really the only thing we have to worry about. The difficult part will be to post-process the model predictions into spans of text in the original examples; once we have done that, the metric from the 🤗 Datasets library will do most of the work for us.
{:else}
## Fine-tuning the model with Keras[[fine-tuning-the-model-with-keras]]
The training code for this example will look a lot like the code in the previous sections, but computing the metrics will be uniquely challenging. Since we padded all the samples to the maximum length we set, there is no data collator to define, so this metric computation is really the only thing we have to worry about. The hard part will be to post-process the model predictions into spans of text in the original examples; once we have done that, the metric from the 🤗 Datasets library will do most of the work for us.
{/if}
### Post-processing[[post-processing]]
{#if fw === 'pt'}
<Youtube id="BNy08iIWVJM"/>
{:else}
<Youtube id="VN67ZpN33Ss"/>
{/if}
The model will output logits for the start and end positions of the answer in the input IDs, as we saw during our exploration of the [`question-answering` pipeline](/course/chapter6/3b). The post-processing step will be similar to what we did there, so here's a quick reminder of the actions we took:
- We masked the start and end logits corresponding to tokens outside of the context.
- We then converted the start and end logits into probabilities using a softmax.
- We attributed a score to each `(start_token, end_token)` pair by taking the product of the corresponding two probabilities.
- We looked for the pair with the maximum score that yielded a valid answer (e.g., a `start_token` lower than `end_token`).
Here we will change this process slightly because we don't need to compute actual scores (just the predicted answer). This means we can skip the softmax step. To go faster, we also won't score all the possible `(start_token, end_token)` pairs, but only the ones corresponding to the highest `n_best` logits (with `n_best=20`). Since we will skip the softmax, those scores will be logit scores, and will be obtained by taking the sum of the start and end logits (instead of the product, because of the rule \\(\log(ab) = \log(a) + \log(b)\\)).
To demonstrate all of this, we will need some kind of predictions. Since we have not trained our model yet, we are going to use the default model for the QA pipeline to generate some predictions on a small part of the validation set. We can use the same processing function as before; because it relies on the global constant `tokenizer`, we just have to change that object to the tokenizer of the model we want to use temporarily:
```python
small_eval_set = raw_datasets["validation"].select(range(100))
trained_checkpoint = "distilbert-base-cased-distilled-squad"
tokenizer = AutoTokenizer.from_pretrained(trained_checkpoint)
eval_set = small_eval_set.map(
preprocess_validation_examples,
batched=True,
remove_columns=raw_datasets["validation"].column_names,
)
```
Now that the preprocessing is done, we change the tokenizer back to the one we originally picked:
```python
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
```
We then remove the columns of our `eval_set` that are not expected by the model, build a batch with all of that small validation set, and pass it through the model. If a GPU is available, we use it to go faster:
{#if fw === 'pt'}
```python
import torch
from transformers import AutoModelForQuestionAnswering
eval_set_for_model = eval_set.remove_columns(["example_id", "offset_mapping"])
eval_set_for_model.set_format("torch")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
batch = {k: eval_set_for_model[k].to(device) for k in eval_set_for_model.column_names}
trained_model = AutoModelForQuestionAnswering.from_pretrained(trained_checkpoint).to(
device
)
with torch.no_grad():
outputs = trained_model(**batch)
```
Since the `Trainer` will give us predictions as NumPy arrays, we grab the start and end logits and convert them to that format:
```python
start_logits = outputs.start_logits.cpu().numpy()
end_logits = outputs.end_logits.cpu().numpy()
```
{:else}
```python
import tensorflow as tf
from transformers import TFAutoModelForQuestionAnswering
eval_set_for_model = eval_set.remove_columns(["example_id", "offset_mapping"])
eval_set_for_model.set_format("numpy")
batch = {k: eval_set_for_model[k] for k in eval_set_for_model.column_names}
trained_model = TFAutoModelForQuestionAnswering.from_pretrained(trained_checkpoint)
outputs = trained_model(**batch)
```
For ease of experimentation, let's convert these outputs to NumPy arrays:
```python
start_logits = outputs.start_logits.numpy()
end_logits = outputs.end_logits.numpy()
```
{/if}
Now, we need to find the predicted answer for each example in our `small_eval_set`. One example may have been split into several features in `eval_set`, so the first step is to map each example in `small_eval_set` to the corresponding features in `eval_set`:
```python
import collections
example_to_features = collections.defaultdict(list)
for idx, feature in enumerate(eval_set):
example_to_features[feature["example_id"]].append(idx)
```
With this in hand, we can really get to work by looping through all the examples and, for each example, through all the associated features. As we said before, we'll look at the logit scores for the `n_best` start logits and end logits, excluding positions that give:
- An answer that wouldn't be inside the context
- An answer with negative length
- An answer that is too long (we limit the possibilities at `max_answer_length=30`)
Once we have all the scored possible answers for one example, we just pick the one with the best logit score:
```python
import numpy as np
n_best = 20
max_answer_length = 30
predicted_answers = []
for example in small_eval_set:
example_id = example["id"]
context = example["context"]
answers = []
for feature_index in example_to_features[example_id]:
start_logit = start_logits[feature_index]
end_logit = end_logits[feature_index]
offsets = eval_set["offset_mapping"][feature_index]
start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist()
end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Skip answers that are not fully in the context
if offsets[start_index] is None or offsets[end_index] is None:
continue
# Skip answers with a length that is either < 0 or > max_answer_length.
if (
end_index < start_index
or end_index - start_index + 1 > max_answer_length
):
continue
answers.append(
{
"text": context[offsets[start_index][0] : offsets[end_index][1]],
"logit_score": start_logit[start_index] + end_logit[end_index],
}
)
best_answer = max(answers, key=lambda x: x["logit_score"])
predicted_answers.append({"id": example_id, "prediction_text": best_answer["text"]})
```
The final format of the predicted answers is the one that will be expected by the metric we will use. As usual, we can load it with the help of the 🤗 Evaluate library:
```python
import evaluate
metric = evaluate.load("squad")
```
This metric expects the predicted answers in the format we saw above (a list of dictionaries with one key for the ID of the example and one key for the predicted text) and the theoretical answers in the format below (a list of dictionaries with one key for the ID of the example and one key for the possible answers):
```python
theoretical_answers = [
{"id": ex["id"], "answers": ex["answers"]} for ex in small_eval_set
]
```
We can now check that we get sensible results by looking at the first element of both lists:
```python
print(predicted_answers[0])
print(theoretical_answers[0])
```
```python out
{'id': '56be4db0acb8001400a502ec', 'prediction_text': 'Denver Broncos'}
{'id': '56be4db0acb8001400a502ec', 'answers': {'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}}
```
Not too bad! Now let's have a look at the score the metric gives us:
```python
metric.compute(predictions=predicted_answers, references=theoretical_answers)
```
```python out
{'exact_match': 83.0, 'f1': 88.25}
```
Again, that's rather good considering that according to [its paper](https://arxiv.org/abs/1910.01108v2) DistilBERT fine-tuned on SQuAD obtains 79.1 and 86.9 for those scores on the whole dataset.
{#if fw === 'pt'}
Now let's put everything we just did in a `compute_metrics()` function that we will use in the `Trainer`. Normally, that `compute_metrics()` function only receives a tuple `eval_preds` with logits and labels. Here we will need a bit more, as we have to look in the dataset of features for the offset and in the dataset of examples for the original contexts, so we won't be able to use this function to get regular evaluation results during training. We will only use it at the end of training to check the results.
The `compute_metrics()` function groups the same steps as before; we just add a small check in case we don't come up with any valid answers (in which case we predict an empty string).
{:else}
Now let's put everything we just did in a `compute_metrics()` function that we will use after training our model. We will need to pass a bit more than just the output logits, as we have to look in the dataset of features for the offset and in the dataset of examples for the original contexts:
{/if}
```python
from tqdm.auto import tqdm
def compute_metrics(start_logits, end_logits, features, examples):
example_to_features = collections.defaultdict(list)
for idx, feature in enumerate(features):
example_to_features[feature["example_id"]].append(idx)
predicted_answers = []
for example in tqdm(examples):
example_id = example["id"]
context = example["context"]
answers = []
# Loop through all features associated with that example
for feature_index in example_to_features[example_id]:
start_logit = start_logits[feature_index]
end_logit = end_logits[feature_index]
offsets = features[feature_index]["offset_mapping"]
start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist()
end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Skip answers that are not fully in the context
if offsets[start_index] is None or offsets[end_index] is None:
continue
# Skip answers with a length that is either < 0 or > max_answer_length
if (
end_index < start_index
or end_index - start_index + 1 > max_answer_length
):
continue
answer = {
"text": context[offsets[start_index][0] : offsets[end_index][1]],
"logit_score": start_logit[start_index] + end_logit[end_index],
}
answers.append(answer)
# Select the answer with the best score
if len(answers) > 0:
best_answer = max(answers, key=lambda x: x["logit_score"])
predicted_answers.append(
{"id": example_id, "prediction_text": best_answer["text"]}
)
else:
predicted_answers.append({"id": example_id, "prediction_text": ""})
theoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples]
return metric.compute(predictions=predicted_answers, references=theoretical_answers)
```
We can check it works on our predictions:
```python
compute_metrics(start_logits, end_logits, eval_set, small_eval_set)
```
```python out
{'exact_match': 83.0, 'f1': 88.25}
```
Looking good! Now let's use this to fine-tune our model.
### Fine-tuning the model[[fine-tuning-the-model]]
{#if fw === 'pt'}
We are now ready to train our model. Let's create it first, using the `AutoModelForQuestionAnswering` class like before:
```python
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
```
{:else}
We are now ready to train our model. Let's create it first, using the `TFAutoModelForQuestionAnswering` class like before:
```python
model = TFAutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
```
{/if}
As usual, we get a warning that some weights are not used (the ones from the pretraining head) and some others are initialized randomly (the ones for the question answering head). You should be used to this by now, but that means this model is not ready to be used just yet and needs fine-tuning -- good thing we're about to do that!
To be able to push our model to the Hub, we'll need to log in to Hugging Face. If you're running this code in a notebook, you can do so with the following utility function, which displays a widget where you can enter your login credentials:
```python
from huggingface_hub import notebook_login
notebook_login()
```
If you aren't working in a notebook, just type the following line in your terminal:
```bash
huggingface-cli login
```
{#if fw === 'pt'}
Once this is done, we can define our `TrainingArguments`. As we said when we defined our function to compute the metric, we won't be able to have a regular evaluation loop because of the signature of the `compute_metrics()` function. We could write our own subclass of `Trainer` to do this (an approach you can find in the [question answering example script](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/trainer_qa.py)), but that's a bit too long for this section. Instead, we will only evaluate the model at the end of training here and show you how to do a regular evaluation in "A custom training loop" below.
This is really where the `Trainer` API shows its limits and the 🤗 Accelerate library shines: customizing the class to a specific use case can be painful, but tweaking a fully exposed training loop is easy.
Let's take a look at our `TrainingArguments`:
```python
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-squad",
evaluation_strategy="no",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
fp16=True,
push_to_hub=True,
)
```
We've seen most of these before: we set some hyperparameters (like the learning rate, the number of epochs we train for, and some weight decay) and indicate that we want to save the model at the end of every epoch, skip evaluation, and upload our results to the Model Hub. We also enable mixed-precision training with `fp16=True`, as it can speed up the training nicely on a recent GPU.
{:else}
Now that's done, we can create our TF Datasets. We can use the simple default data collator this time:
```python
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
```
And now we create the datasets as usual.
```python
tf_train_dataset = model.prepare_tf_dataset(
train_dataset,
collate_fn=data_collator,
shuffle=True,
batch_size=16,
)
tf_eval_dataset = model.prepare_tf_dataset(
validation_dataset,
collate_fn=data_collator,
shuffle=False,
batch_size=16,
)
```
Next, we set up our training hyperparameters and compile our model:
```python
from transformers import create_optimizer
from transformers.keras_callbacks import PushToHubCallback
import tensorflow as tf
# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
num_train_epochs = 3
num_train_steps = len(tf_train_dataset) * num_train_epochs
optimizer, schedule = create_optimizer(
init_lr=2e-5,
num_warmup_steps=0,
num_train_steps=num_train_steps,
weight_decay_rate=0.01,
)
model.compile(optimizer=optimizer)
# Train in mixed-precision float16
tf.keras.mixed_precision.set_global_policy("mixed_float16")
```
Finally, we're ready to train with `model.fit()`. We use a `PushToHubCallback` to upload the model to the Hub after each epoch.
{/if}
By default, the repository used will be in your namespace and named after the output directory you set, so in our case it will be in `"sgugger/bert-finetuned-squad"`. We can override this by passing a `hub_model_id`; for instance, to push the model to the `huggingface_course` organization we used `hub_model_id="huggingface_course/bert-finetuned-squad"` (which is the model we linked to at the beginning of this section).
{#if fw === 'pt'}
<Tip>
💡 If the output directory you are using exists, it needs to be a local clone of the repository you want to push to (so set a new name if you get an error when defining your `Trainer`).
</Tip>
Finally, we just pass everything to the `Trainer` class and launch the training:
```python
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=validation_dataset,
tokenizer=tokenizer,
)
trainer.train()
```
{:else}
```python
from transformers.keras_callbacks import PushToHubCallback
callback = PushToHubCallback(output_dir="bert-finetuned-squad", tokenizer=tokenizer)
# We're going to do validation afterwards, so no validation mid-training
model.fit(tf_train_dataset, callbacks=[callback], epochs=num_train_epochs)
```
{/if}
Note that while the training happens, each time the model is saved (here, every epoch) it is uploaded to the Hub in the background. This way, you will be able to to resume your training on another machine if necessary. The whole training takes a while (a little over an hour on a Titan RTX), so you can grab a coffee or reread some of the parts of the course that you've found more challenging while it proceeds. Also note that as soon as the first epoch is finished, you will see some weights uploaded to the Hub and you can start playing with your model on its page.
{#if fw === 'pt'}
Once the training is complete, we can finally evaluate our model (and pray we didn't spend all that compute time on nothing). The `predict()` method of the `Trainer` will return a tuple where the first elements will be the predictions of the model (here a pair with the start and end logits). We send this to our `compute_metrics()` function:
```python
predictions, _, _ = trainer.predict(validation_dataset)
start_logits, end_logits = predictions
compute_metrics(start_logits, end_logits, validation_dataset, raw_datasets["validation"])
```
{:else}
Once the training is complete, we can finally evaluate our model (and pray we didn't spend all that compute time on nothing). The `predict()` method of our `model` will take care of getting predictions, and since we did all the hard work of defining a `compute_metrics()` function earlier, we can get our results in a single line:
```python
predictions = model.predict(tf_eval_dataset)
compute_metrics(
predictions["start_logits"],
predictions["end_logits"],
validation_dataset,
raw_datasets["validation"],
)
```
{/if}
```python out
{'exact_match': 81.18259224219489, 'f1': 88.67381321905516}
```
Great! As a comparison, the baseline scores reported in the BERT article for this model are 80.8 and 88.5, so we're right where we should be.
{#if fw === 'pt'}
Finally, we use the `push_to_hub()` method to make sure we upload the latest version of the model:
```py
trainer.push_to_hub(commit_message="Training complete")
```
This returns the URL of the commit it just did, if you want to inspect it:
```python out
'https://huggingface.co/sgugger/bert-finetuned-squad/commit/9dcee1fbc25946a6ed4bb32efb1bd71d5fa90b68'
```
The `Trainer` also drafts a model card with all the evaluation results and uploads it.
{/if}
At this stage, you can use the inference widget on the Model Hub to test the model and share it with your friends, family, and favorite pets. You have successfully fine-tuned a model on a question answering task -- congratulations!
<Tip>
✏️ **Your turn!** Try another model architecture to see if it performs better on this task!
</Tip>
{#if fw === 'pt'}
If you want to dive a bit more deeply into the training loop, we will now show you how to do the same thing using 🤗 Accelerate.
## A custom training loop[[a-custom-training-loop]]
Let's now have a look at the full training loop, so you can easily customize the parts you need. It will look a lot like the training loop in [Chapter 3](/course/chapter3/4), with the exception of the evaluation loop. We will be able to evaluate the model regularly since we're not constrained by the `Trainer` class anymore.
### Preparing everything for training[[preparing-everything-for-training]]
First we need to build the `DataLoader`s from our datasets. We set the format of those datasets to `"torch"`, and remove the columns in the validation set that are not used by the model. Then, we can use the `default_data_collator` provided by Transformers as a `collate_fn` and shuffle the training set, but not the validation set:
```py
from torch.utils.data import DataLoader
from transformers import default_data_collator
train_dataset.set_format("torch")
validation_set = validation_dataset.remove_columns(["example_id", "offset_mapping"])
validation_set.set_format("torch")
train_dataloader = DataLoader(
train_dataset,
shuffle=True,
collate_fn=default_data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
validation_set, collate_fn=default_data_collator, batch_size=8
)
```
Next we reinstantiate our model, to make sure we're not continuing the fine-tuning from before but starting from the BERT pretrained model again:
```py
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
```
Then we will need an optimizer. As usual we use the classic `AdamW`, which is like Adam, but with a fix in the way weight decay is applied:
```py
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)
```
Once we have all those objects, we can send them to the `accelerator.prepare()` method. Remember that if you want to train on TPUs in a Colab notebook, you will need to move all of this code into a training function, and that shouldn't execute any cell that instantiates an `Accelerator`. We can force mixed-precision training by passing `fp16=True` to the `Accelerator` (or, if you are executing the code as a script, just make sure to fill in the 🤗 Accelerate `config` appropriately).
```py
from accelerate import Accelerator
accelerator = Accelerator(fp16=True)
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
```
As you should know from the previous sections, we can only use the `train_dataloader` length to compute the number of training steps after it has gone through the `accelerator.prepare()` method. We use the same linear schedule as in the previous sections:
```py
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
```
To push our model to the Hub, we will need to create a `Repository` object in a working folder. First log in to the Hugging Face Hub, if you're not logged in already. We'll determine the repository name from the model ID we want to give our model (feel free to replace the `repo_name` with your own choice; it just needs to contain your username, which is what the function `get_full_repo_name()` does):
```py
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-squad-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name
```
```python out
'sgugger/bert-finetuned-squad-accelerate'
```
Then we can clone that repository in a local folder. If it already exists, this local folder should be a clone of the repository we are working with:
```py
output_dir = "bert-finetuned-squad-accelerate"
repo = Repository(output_dir, clone_from=repo_name)
```
We can now upload anything we save in `output_dir` by calling the `repo.push_to_hub()` method. This will help us upload the intermediate models at the end of each epoch.
## Training loop[[training-loop]]
We are now ready to write the full training loop. After defining a progress bar to follow how training goes, the loop has three parts:
- The training in itself, which is the classic iteration over the `train_dataloader`, forward pass through the model, then backward pass and optimizer step.
- The evaluation, in which we gather all the values for `start_logits` and `end_logits` before converting them to NumPy arrays. Once the evaluation loop is finished, we concatenate all the results. Note that we need to truncate because the `Accelerator` may have added a few samples at the end to ensure we have the same number of examples in each process.
- Saving and uploading, where we first save the model and the tokenizer, then call `repo.push_to_hub()`. As we did before, we use the argument `blocking=False` to tell the 🤗 Hub library to push in an asynchronous process. This way, training continues normally and this (long) instruction is executed in the background.
Here's the complete code for the training loop:
```py
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for step, batch in enumerate(train_dataloader):
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
start_logits = []
end_logits = []
accelerator.print("Evaluation!")
for batch in tqdm(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
start_logits.append(accelerator.gather(outputs.start_logits).cpu().numpy())
end_logits.append(accelerator.gather(outputs.end_logits).cpu().numpy())
start_logits = np.concatenate(start_logits)
end_logits = np.concatenate(end_logits)
start_logits = start_logits[: len(validation_dataset)]
end_logits = end_logits[: len(validation_dataset)]
metrics = compute_metrics(
start_logits, end_logits, validation_dataset, raw_datasets["validation"]
)
print(f"epoch {epoch}:", metrics)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)
```
In case this is the first time you're seeing a model saved with 🤗 Accelerate, let's take a moment to inspect the three lines of code that go with it:
```py
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
```
The first line is self-explanatory: it tells all the processes to wait until everyone is at that stage before continuing. This is to make sure we have the same model in every process before saving. Then we grab the `unwrapped_model`, which is the base model we defined. The `accelerator.prepare()` method changes the model to work in distributed training, so it won't have the `save_pretrained()` method anymore; the `accelerator.unwrap_model()` method undoes that step. Lastly, we call `save_pretrained()` but tell that method to use `accelerator.save()` instead of `torch.save()`.
Once this is done, you should have a model that produces results pretty similar to the one trained with the `Trainer`. You can check the model we trained using this code at [*huggingface-course/bert-finetuned-squad-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-squad-accelerate). And if you want to test out any tweaks to the training loop, you can directly implement them by editing the code shown above!
{/if}
## Using the fine-tuned model[[using-the-fine-tuned-model]]
We've already shown you how you can use the model we fine-tuned on the Model Hub with the inference widget. To use it locally in a `pipeline`, you just have to specify the model identifier:
```py
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-squad"
question_answerer = pipeline("question-answering", model=model_checkpoint)
context = """
🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integration
between them. It's straightforward to train your models with one before loading them for inference with the other.
"""
question = "Which deep learning libraries back 🤗 Transformers?"
question_answerer(question=question, context=context)
```
```python out
{'score': 0.9979003071784973,
'start': 78,
'end': 105,
'answer': 'Jax, PyTorch and TensorFlow'}
```
Great! Our model is working as well as the default one for this pipeline!
| huggingface/course/blob/main/chapters/en/chapter7/7.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MarkupLM
## Overview
The MarkupLM model was proposed in [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document
Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. MarkupLM is BERT, but
applied to HTML pages instead of raw text documents. The model incorporates additional embedding layers to improve
performance, similar to [LayoutLM](layoutlm).
The model can be used for tasks like question answering on web pages or information extraction from web pages. It obtains
state-of-the-art results on 2 important benchmarks:
- [WebSRC](https://x-lance.github.io/WebSRC/), a dataset for Web-Based Structural Reading Comprehension (a bit like SQuAD but for web pages)
- [SWDE](https://www.researchgate.net/publication/221299838_From_one_tree_to_a_forest_a_unified_solution_for_structured_web_data_extraction), a dataset
for information extraction from web pages (basically named-entity recogntion on web pages)
The abstract from the paper is the following:
*Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document
Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a
large number of digital documents where the layout information is not fixed and needs to be interactively and
dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this
paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as
HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the
pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding
tasks. The pre-trained model and code will be publicly available.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
## Usage tips
- In addition to `input_ids`, [`~MarkupLMModel.forward`] expects 2 additional inputs, namely `xpath_tags_seq` and `xpath_subs_seq`.
These are the XPATH tags and subscripts respectively for each token in the input sequence.
- One can use [`MarkupLMProcessor`] to prepare all data for the model. Refer to the [usage guide](#usage-markuplmprocessor) for more info.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/markuplm_architecture.jpg"
alt="drawing" width="600"/>
<small> MarkupLM architecture. Taken from the <a href="https://arxiv.org/abs/2110.08518">original paper.</a> </small>
## Usage: MarkupLMProcessor
The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
([`MarkupLMFeatureExtractor`]) and a tokenizer ([`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]). The feature extractor is
used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
token-level inputs of the model (`input_ids` etc.). Note that you can still use the feature extractor and tokenizer separately,
if you only want to handle one of the two tasks.
```python
from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
feature_extractor = MarkupLMFeatureExtractor()
tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
processor = MarkupLMProcessor(feature_extractor, tokenizer)
```
In short, one can provide HTML strings (and possibly additional data) to [`MarkupLMProcessor`],
and it will create the inputs expected by the model. Internally, the processor first uses
[`MarkupLMFeatureExtractor`] to get a list of nodes and corresponding xpaths. The nodes and
xpaths are then provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which converts them
to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_subs_seq`, `xpath_tags_seq`.
Optionally, one can provide node labels to the processor, which are turned into token-level `labels`.
[`MarkupLMFeatureExtractor`] uses [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/), a Python library for
pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of
choice, and provide the nodes and xpaths yourself to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`].
In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
**Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True**
This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
```python
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>Here is my website.</p>
... </body>
... </html>"""
>>> # note that you can also add provide all tokenizer parameters here such as padding, truncation
>>> encoding = processor(html_string, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
**Use case 2: web page classification (training, inference) + token classification (inference), parse_html=False**
In case one already has obtained all nodes and xpaths, one doesn't need the feature extractor. In that case, one should
provide the nodes and corresponding xpaths themselves to the processor, and make sure to set `parse_html` to `False`.
```python
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
**Use case 3: token classification (training), parse_html=False**
For token classification tasks (such as [SWDE](https://paperswithcode.com/dataset/swde)), one can also provide the
corresponding node labels in order to train a model. The processor will then convert these into token-level `labels`.
By default, it will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
initialize the tokenizer with `only_label_first_subword` set to `False`.
```python
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> node_labels = [1, 2, 2, 1]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq', 'labels'])
```
**Use case 4: web page question answering (inference), parse_html=True**
For question answering tasks on web pages, you can provide a question to the processor. By default, the
processor will use the feature extractor to get all nodes and xpaths, and create [CLS] question tokens [SEP] word tokens [SEP].
```python
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>My name is Niels.</p>
... </body>
... </html>"""
>>> question = "What's his name?"
>>> encoding = processor(html_string, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
**Use case 5: web page question answering (inference), parse_html=False**
For question answering tasks (such as WebSRC), you can provide a question to the processor. If you have extracted
all nodes and xpaths yourself, you can provide them directly to the processor. Make sure to set `parse_html` to `False`.
```python
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> question = "What's his name?"
>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
```
## Resources
- [Demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
## MarkupLMConfig
[[autodoc]] MarkupLMConfig
- all
## MarkupLMFeatureExtractor
[[autodoc]] MarkupLMFeatureExtractor
- __call__
## MarkupLMTokenizer
[[autodoc]] MarkupLMTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## MarkupLMTokenizerFast
[[autodoc]] MarkupLMTokenizerFast
- all
## MarkupLMProcessor
[[autodoc]] MarkupLMProcessor
- __call__
## MarkupLMModel
[[autodoc]] MarkupLMModel
- forward
## MarkupLMForSequenceClassification
[[autodoc]] MarkupLMForSequenceClassification
- forward
## MarkupLMForTokenClassification
[[autodoc]] MarkupLMForTokenClassification
- forward
## MarkupLMForQuestionAnswering
[[autodoc]] MarkupLMForQuestionAnswering
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/markuplm.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoBERTa-PreLayerNorm
## Overview
The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
It is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
The abstract from the paper is the following:
*fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs.*
This model was contributed by [andreasmaden](https://huggingface.co/andreasmadsen).
The original code can be found [here](https://github.com/princeton-nlp/DinkyTrain).
## Usage tips
- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## RobertaPreLayerNormConfig
[[autodoc]] RobertaPreLayerNormConfig
<frameworkcontent>
<pt>
## RobertaPreLayerNormModel
[[autodoc]] RobertaPreLayerNormModel
- forward
## RobertaPreLayerNormForCausalLM
[[autodoc]] RobertaPreLayerNormForCausalLM
- forward
## RobertaPreLayerNormForMaskedLM
[[autodoc]] RobertaPreLayerNormForMaskedLM
- forward
## RobertaPreLayerNormForSequenceClassification
[[autodoc]] RobertaPreLayerNormForSequenceClassification
- forward
## RobertaPreLayerNormForMultipleChoice
[[autodoc]] RobertaPreLayerNormForMultipleChoice
- forward
## RobertaPreLayerNormForTokenClassification
[[autodoc]] RobertaPreLayerNormForTokenClassification
- forward
## RobertaPreLayerNormForQuestionAnswering
[[autodoc]] RobertaPreLayerNormForQuestionAnswering
- forward
</pt>
<tf>
## TFRobertaPreLayerNormModel
[[autodoc]] TFRobertaPreLayerNormModel
- call
## TFRobertaPreLayerNormForCausalLM
[[autodoc]] TFRobertaPreLayerNormForCausalLM
- call
## TFRobertaPreLayerNormForMaskedLM
[[autodoc]] TFRobertaPreLayerNormForMaskedLM
- call
## TFRobertaPreLayerNormForSequenceClassification
[[autodoc]] TFRobertaPreLayerNormForSequenceClassification
- call
## TFRobertaPreLayerNormForMultipleChoice
[[autodoc]] TFRobertaPreLayerNormForMultipleChoice
- call
## TFRobertaPreLayerNormForTokenClassification
[[autodoc]] TFRobertaPreLayerNormForTokenClassification
- call
## TFRobertaPreLayerNormForQuestionAnswering
[[autodoc]] TFRobertaPreLayerNormForQuestionAnswering
- call
</tf>
<jax>
## FlaxRobertaPreLayerNormModel
[[autodoc]] FlaxRobertaPreLayerNormModel
- __call__
## FlaxRobertaPreLayerNormForCausalLM
[[autodoc]] FlaxRobertaPreLayerNormForCausalLM
- __call__
## FlaxRobertaPreLayerNormForMaskedLM
[[autodoc]] FlaxRobertaPreLayerNormForMaskedLM
- __call__
## FlaxRobertaPreLayerNormForSequenceClassification
[[autodoc]] FlaxRobertaPreLayerNormForSequenceClassification
- __call__
## FlaxRobertaPreLayerNormForMultipleChoice
[[autodoc]] FlaxRobertaPreLayerNormForMultipleChoice
- __call__
## FlaxRobertaPreLayerNormForTokenClassification
[[autodoc]] FlaxRobertaPreLayerNormForTokenClassification
- __call__
## FlaxRobertaPreLayerNormForQuestionAnswering
[[autodoc]] FlaxRobertaPreLayerNormForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/roberta-prelayernorm.md |
ow to write a good issue on GitHub? GitHub is the main place for the Hugging Face open source libraries, and should always go there to report a bug or ask for a new feature. For more general questions or to debug your own code, use the forums (see the video linked below). It's very important to write good issues as it will help the bug you uncovered be fixed in no time. For this video, we have created a version of Transformers with a bug. You can install it by executing this command in a notebook (remove the exclamation mark to execute it in a terminal). In this version, the following example fails. The error is rather cryptic and does not seem to come from anything in our code, so it seems we have a bug to report! The first thing to do in this case is to try to find the smallest amount of code possible that reproduces the bug. In our case, inspecting the traceback, we see the failure happens inside the pipeline function when it calls AutoTokenizer.from_pretrained. Using the debugger, we find the values passed to that method and can thus create a small sample of code that hopefully generates the same error. It's very important to go though this step as you may realize the error was on your side and not a bug in the library, but it also will make it easier for the maintainers to fix your problem. Here we can play around a bit more with this code and notice the error happens for different checkpoints and not just this one, and that it disappears when we use use_fast=False inside our tokenizer call. The important part is to have something that does not depend on any external files or data. Try to replace your data by fake values if you can't share it. With all of this done, we are ready to start writing our issue. Click on the button next to Bug Report and you will discover there is a template to fill. It will only take you a couple of minutes. The first thing is to properly name your issue. Don't pick a title that is too vague! Then you have to fill your environment information. There is a command provided by the Transformers library to do this. Just execute it in your notebook or in a terminal, and copy paste the results. There are two last questions to fill manually (to which the answers are no and no in our case). Next, we need to determine who to tag. There is a full list of usernames. Since our issue has to do with tokenizers, we pick the maintainer associated with them. There is no point tagging more than 3 people, they will redirect you to the right person if you made a mistake. Next, we have to give the information necessary to reproduce the bug. We paste our sample, and put it between two lines with three backticks so it's formatted properly. We also paste the full traceback, still between two lines of three backticks. Lastly, we can add any additional information about what we tried to debug the issue at hand. With all of this, you should expect an answer to your issue pretty fast, and hopefully, a quick fix! Note that all the advise in this video applies for almost every open-source project. | huggingface/course/blob/main/subtitles/en/raw/chapter8/05_issues.md |
The Hugging Face Hub[[the-hugging-face-hub]]
<CourseFloatingBanner
chapter={4}
classNames="absolute z-10 right-0 top-0"
/>
The [Hugging Face Hub](https://huggingface.co/) –- our main website –- is a central platform that enables anyone to discover, use, and contribute new state-of-the-art models and datasets. It hosts a wide variety of models, with more than 10,000 publicly available. We'll focus on the models in this chapter, and take a look at the datasets in Chapter 5.
The models in the Hub are not limited to 🤗 Transformers or even NLP. There are models from [Flair](https://github.com/flairNLP/flair) and [AllenNLP](https://github.com/allenai/allennlp) for NLP, [Asteroid](https://github.com/asteroid-team/asteroid) and [pyannote](https://github.com/pyannote/pyannote-audio) for speech, and [timm](https://github.com/rwightman/pytorch-image-models) for vision, to name a few.
Each of these models is hosted as a Git repository, which allows versioning and reproducibility. Sharing a model on the Hub means opening it up to the community and making it accessible to anyone looking to easily use it, in turn eliminating their need to train a model on their own and simplifying sharing and usage.
Additionally, sharing a model on the Hub automatically deploys a hosted Inference API for that model. Anyone in the community is free to test it out directly on the model's page, with custom inputs and appropriate widgets.
The best part is that sharing and using any public model on the Hub is completely free! [Paid plans](https://huggingface.co/pricing) also exist if you wish to share models privately.
The video below shows how to navigate the Hub.
<Youtube id="XvSGPZFEjDY"/>
Having a huggingface.co account is required to follow along this part, as we'll be creating and managing repositories on the Hugging Face Hub: [create an account](https://huggingface.co/join) | huggingface/course/blob/main/chapters/en/chapter4/1.mdx |
反应式界面 (Reactive Interfaces)
本指南介绍了如何使 Gradio 界面自动刷新或连续流式传输数据。
## 实时界面 (Live Interfaces)
您可以通过在界面中设置 `live=True` 来使界面自动刷新。现在,只要用户输入发生变化,界面就会重新计算。
$code_calculator_live
$demo_calculator_live
注意,因为界面在更改时会自动重新提交,所以没有提交按钮。
## 流式组件 (Streaming Components)
某些组件具有“流式”模式,比如麦克风模式下的 `Audio` 组件或网络摄像头模式下的 `Image` 组件。流式传输意味着数据会持续发送到后端,并且 `Interface` 函数会持续重新运行。
当在 `gr.Interface(live=True)` 中同时使用 `gr.Audio(sources=['microphone'])` 和 `gr.Audio(sources=['microphone'], streaming=True)` 时,两者的区别在于第一个 `Component` 会在用户停止录制时自动提交数据并运行 `Interface` 函数,而第二个 `Component` 会在录制过程中持续发送数据并运行 `Interface` 函数。
以下是从网络摄像头实时流式传输图像的示例代码。
$code_stream_frames
| gradio-app/gradio/blob/main/guides/cn/02_building-interfaces/02_reactive-interfaces.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Phi
## Overview
The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
### Summary
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size.
They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer
based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
to “think step by step” or perform some rudimentary in-context learning.
With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
The abstract from the Phi-1 paper is the following:
*We introduce phi-1, a new large language model for code, with significantly smaller size than
competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on
8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically
generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains
pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent
properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding
exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as
phi-1 that still achieves 45% on HumanEval.*
The abstract from the Phi-1.5 paper is the following:
*We continue the investigation into the power of smaller Transformer-based language models as
initiated by TinyStories – a 10 million parameter model that can produce coherent English – and
the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close
to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to
generate “textbook quality” data as a way to enhance the learning process compared to traditional
web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common
sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5,
with performance on natural language tasks comparable to models 5x larger, and surpassing most
non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic
coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such
as the ability to “think step by step” or perform some rudimentary in-context learning– and bad,
including hallucinations and the potential for toxic and biased generations –encouragingly though, we
are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to
promote further research on these urgent topics.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code for Phi-1 and Phi-1.5 can be found [here](https://huggingface.co/microsoft/phi-1/blob/main/modeling_mixformer_sequential.py) and [here](https://huggingface.co/microsoft/phi-1_5/blob/main/modeling_mixformer_sequential.py) respectively.
## Usage tips
- This model is quite similar to `Llama` with the main difference in [`PhiDecoderLayer`], where they used [`PhiAttention`] and [`PhiMLP`] layers in parallel configuration.
- The tokenizer used for this model is identical to the [`CodeGenTokenizer`].
### Example :
```python
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
## Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `susnato/phi-1_dev` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/phi_1_speedup_plot.jpg">
</div>
## PhiConfig
[[autodoc]] PhiConfig
<frameworkcontent>
<pt>
## PhiModel
[[autodoc]] PhiModel
- forward
## PhiForCausalLM
[[autodoc]] PhiForCausalLM
- forward
- generate
## PhiForSequenceClassification
[[autodoc]] PhiForSequenceClassification
- forward
## PhiForTokenClassification
[[autodoc]] PhiForTokenClassification
- forward
</pt>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/phi.md |
Gradio Demo: gpt2_xl
```
!pip install -q gradio
```
```
import gradio as gr
title = "gpt2-xl"
examples = [
["The tower is 324 metres (1,063 ft) tall,"],
["The Moon's orbit around Earth has"],
["The smooth Borealis basin in the Northern Hemisphere covers 40%"],
]
demo = gr.load(
"huggingface/gpt2-xl",
inputs=gr.Textbox(lines=5, max_lines=6, label="Input Text"),
title=title,
examples=examples,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/gpt2_xl/run.ipynb |
--
title: "Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU"
thumbnail: assets/133_trl_peft/thumbnail.png
authors:
- user: edbeeching
- user: ybelkada
- user: lvwerra
- user: smangrul
- user: lewtun
- user: kashif
---
# Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
We are excited to officially release the integration of `trl` with `peft` to make Large Language Model (LLM) fine-tuning with Reinforcement Learning more accessible to anyone! In this post, we explain why this is a competitive alternative to existing fine-tuning approaches.
Note `peft` is a general tool that can be applied to many ML use-cases but it’s particularly interesting for RLHF as this method is especially memory-hungry!
If you want to directly deep dive into the code, check out the example scripts directly on the [documentation page of TRL](https://huggingface.co/docs/trl/main/en/sentiment_tuning_peft).
## Introduction
### LLMs & RLHF
LLMs combined with RLHF (Reinforcement Learning with Human Feedback) seems to be the next go-to approach for building very powerful AI systems such as ChatGPT.
Training a language model with RLHF typically involves the following three steps:
1- Fine-tune a pretrained LLM on a specific domain or corpus of instructions and human demonstrations
2- Collect a human annotated dataset and train a reward model
3- Further fine-tune the LLM from step 1 with the reward model and this dataset using RL (e.g. PPO)
|  |
|:--:|
| <b>Overview of ChatGPT's training protocol, from the data collection to the RL part. Source: <a href="https://openai.com/blog/chatgpt" rel="noopener" target="_blank" >OpenAI's ChatGPT blogpost</a> </b>|
The choice of the base LLM is quite crucial here. At this time of writing, the “best” open-source LLM that can be used “out-of-the-box” for many tasks are instruction finetuned LLMs. Notable models being: [BLOOMZ](https://huggingface.co/bigscience/bloomz), [Flan-T5](https://huggingface.co/google/flan-t5-xxl), [Flan-UL2](https://huggingface.co/google/flan-ul2), and [OPT-IML](https://huggingface.co/facebook/opt-iml-max-30b). The downside of these models is their size. To get a decent model, you need at least to play with 10B+ scale models which would require up to 40GB GPU memory in full precision, just to fit the model on a single GPU device without doing any training at all!
### What is TRL?
The `trl` library aims at making the RL step much easier and more flexible so that anyone can fine-tune their LM using RL on their custom dataset and training setup. Among many other applications, you can use this algorithm to fine-tune a model to generate [positive movie reviews](https://huggingface.co/docs/trl/sentiment_tuning), do [controlled generation](https://github.com/lvwerra/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment-control.ipynb) or [make the model less toxic](https://huggingface.co/docs/trl/detoxifying_a_lm).
Using `trl` you can run one of the most popular Deep RL algorithms, [PPO](https://huggingface.co/deep-rl-course/unit8/introduction?fw=pt), in a distributed manner or on a single device! We leverage `accelerate` from the Hugging Face ecosystem to make this possible, so that any user can scale up the experiments up to an interesting scale.
Fine-tuning a language model with RL follows roughly the protocol detailed below. This requires having 2 copies of the original model; to avoid the active model deviating too much from its original behavior / distribution you need to compute the logits of the reference model at each optimization step. This adds a hard constraint on the optimization process as you need always at least two copies of the model per GPU device. If the model grows in size, it becomes more and more tricky to fit the setup on a single GPU.
|  |
|:--:|
| <b>Overview of the PPO training setup in TRL.</b>|
In `trl` you can also use shared layers between reference and active models to avoid entire copies. A concrete example of this feature is showcased in the detoxification example.
### Training at scale
Training at scale can be challenging. The first challenge is fitting the model and its optimizer states on the available GPU devices. The amount of GPU memory a single parameter takes depends on its “precision” (or more specifically `dtype`). The most common `dtype` being `float32` (32-bit), `float16`, and `bfloat16` (16-bit). More recently “exotic” precisions are supported out-of-the-box for training and inference (with certain conditions and constraints) such as `int8` (8-bit). In a nutshell, to load a model on a GPU device each billion parameters costs 4GB in float32 precision, 2GB in float16, and 1GB in int8. If you would like to learn more about this topic, have a look at this blogpost which dives deeper: [https://huggingface.co/blog/hf-bitsandbytes-integration](https://huggingface.co/blog/hf-bitsandbytes-integration).
If you use an AdamW optimizer each parameter needs 8 bytes (e.g. if your model has 1B parameters, the full AdamW optimizer of the model would require 8GB GPU memory - [source](https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one)).
Many techniques have been adopted to tackle these challenges at scale. The most familiar paradigms are Pipeline Parallelism, Tensor Parallelism, and Data Parallelism.
| 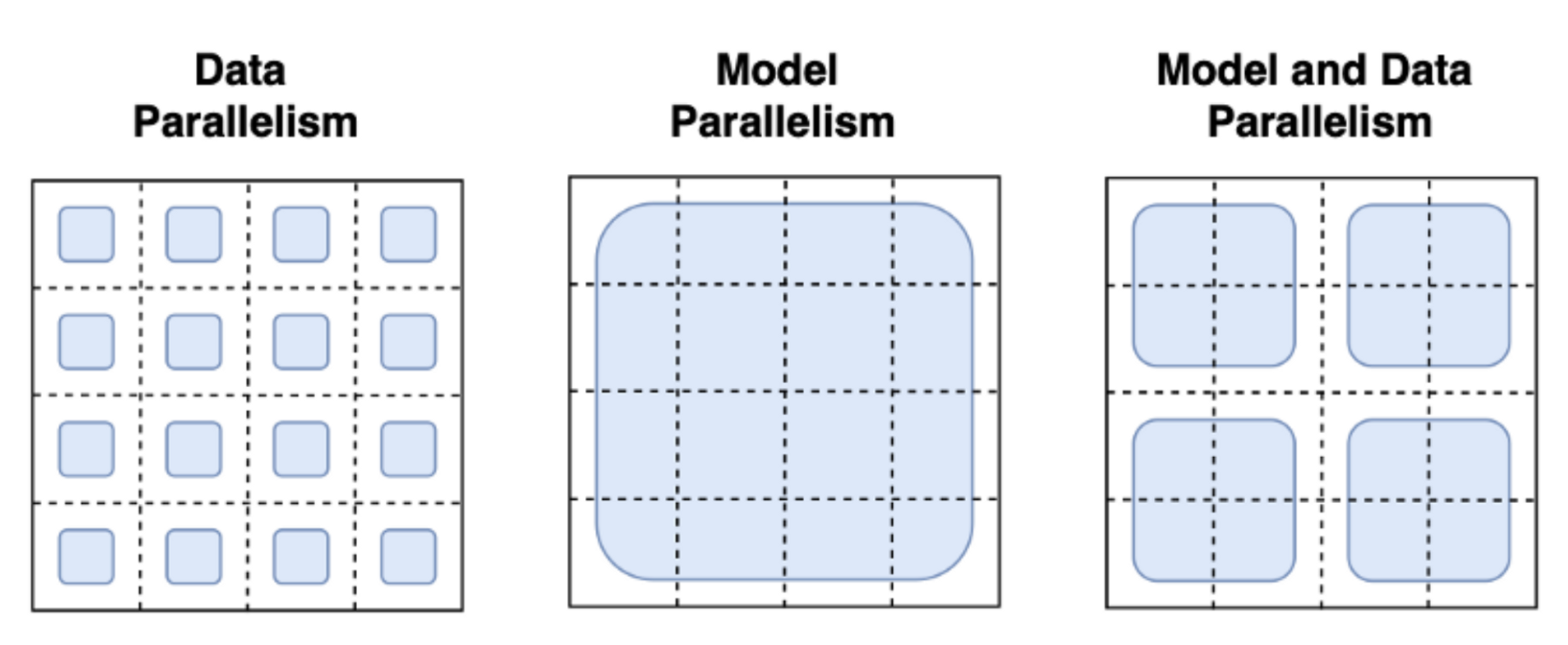 |
|:--:|
| <b>Image Credits to <a href="https://towardsdatascience.com/distributed-parallel-training-data-parallelism-and-model-parallelism-ec2d234e3214" rel="noopener" target="_blank" >this blogpost</a> </b>|
With data parallelism the same model is hosted in parallel on several machines and each instance is fed a different data batch. This is the most straight forward parallelism strategy essentially replicating the single-GPU case and is already supported by `trl`. With Pipeline and Tensor Parallelism the model itself is distributed across machines: in Pipeline Parallelism the model is split layer-wise, whereas Tensor Parallelism splits tensor operations across GPUs (e.g. matrix multiplications). With these Model Parallelism strategies, you need to shard the model weights across many devices which requires you to define a communication protocol of the activations and gradients across processes. This is not trivial to implement and might need the adoption of some frameworks such as [`Megatron-DeepSpeed`](https://github.com/microsoft/Megatron-DeepSpeed) or [`Nemo`](https://github.com/NVIDIA/NeMo). It is also important to highlight other tools that are essential for scaling LLM training such as Adaptive activation checkpointing and fused kernels. Further reading about parallelism paradigms can be found [here](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism).
Therefore, we asked ourselves the following question: how far can we go with just data parallelism? Can we use existing tools to fit super-large training processes (including active model, reference model and optimizer states) in a single device? The answer appears to be yes. The main ingredients are: adapters and 8bit matrix multiplication! Let us cover these topics in the following sections:
### 8-bit matrix multiplication
Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper LLM.int8() and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8.
| 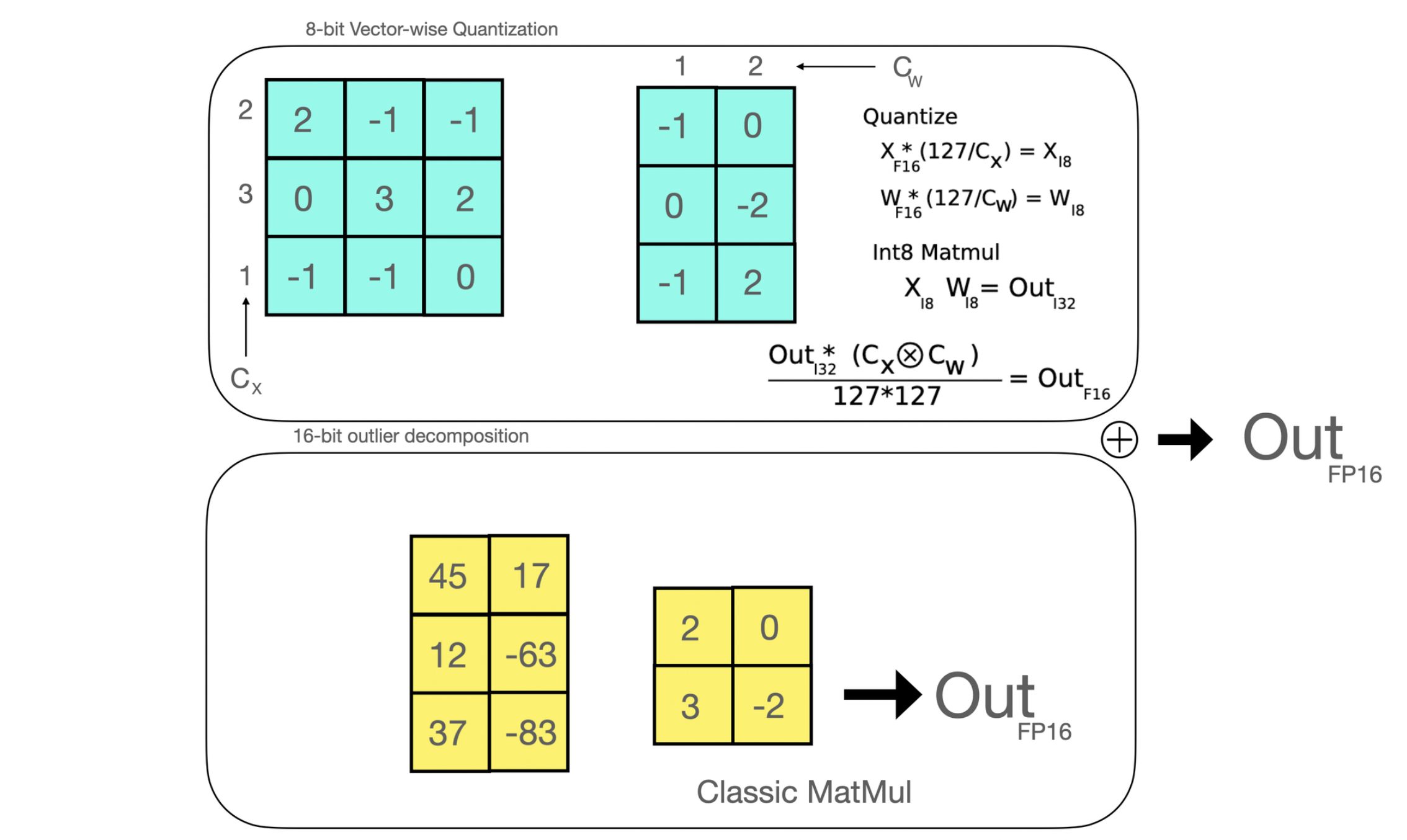 |
|:--:|
| <b>Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper [LLM.int8()](https://arxiv.org/abs/2208.07339) and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8. </b>|
In a nutshell, you can reduce the size of a full-precision model by 4 (thus, by 2 for half-precision models) if you use 8-bit matrix multiplication.
### Low rank adaptation and PEFT
In 2021, a paper called LoRA: Low-Rank Adaption of Large Language Models demonstrated that fine tuning of large language models can be performed by freezing the pretrained weights and creating low rank versions of the query and value layers attention matrices. These low rank matrices have far fewer parameters than the original model, enabling fine-tuning with far less GPU memory. The authors demonstrate that fine-tuning of low-rank adapters achieved comparable results to fine-tuning the full pretrained model.
|  |
|:--:|
| <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>|
This technique allows the fine tuning of LLMs using a fraction of the memory requirements. There are, however, some downsides. The forward and backward pass is approximately twice as slow, due to the additional matrix multiplications in the adapter layers.
### What is PEFT?
[Parameter-Efficient Fine-Tuning (PEFT)](https://github.com/huggingface/peft), is a Hugging Face library, created to support the creation and fine tuning of adapter layers on LLMs.`peft` is seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
The library supports many state of the art models and has an extensive set of examples, including:
- Causal language modeling
- Conditional generation
- Image classification
- 8-bit int8 training
- Low Rank adaption of Dreambooth models
- Semantic segmentation
- Sequence classification
- Token classification
The library is still under extensive and active development, with many upcoming features to be announced in the coming months.
## Fine-tuning 20B parameter models with Low Rank Adapters
Now that the prerequisites are out of the way, let us go through the entire pipeline step by step, and explain with figures how you can fine-tune a 20B parameter LLM with RL using the tools mentioned above on a single 24GB GPU!
### Step 1: Load your active model in 8-bit precision
| 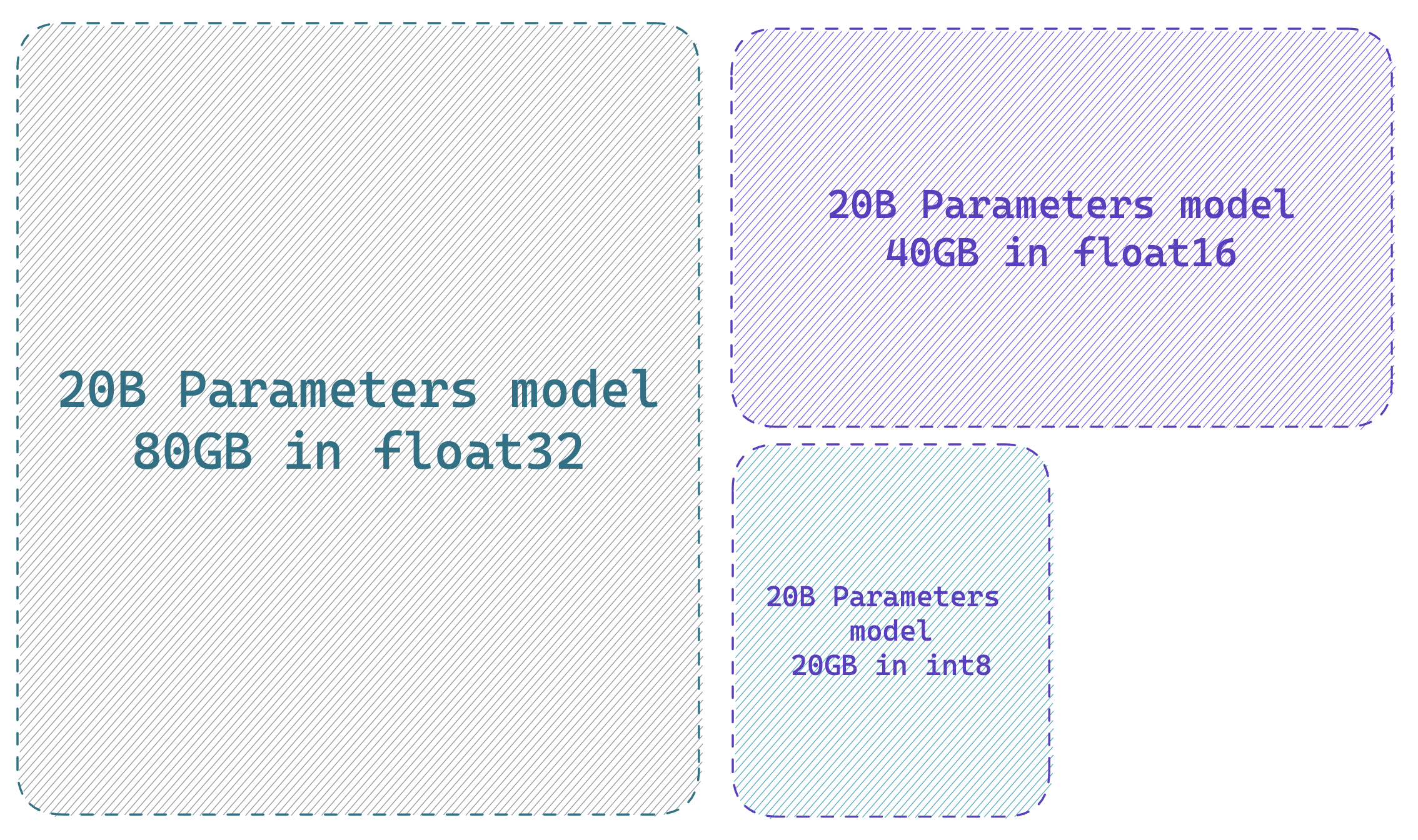 |
|:--:|
| <b> Loading a model in 8-bit precision can save up to 4x memory compared to full precision model</b>|
A “free-lunch” memory reduction of a LLM using `transformers` is to load your model in 8-bit precision using the method described in LLM.int8. This can be performed by simply adding the flag `load_in_8bit=True` when calling the `from_pretrained` method (you can read more about that [here](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)).
As stated in the previous section, a “hack” to compute the amount of GPU memory you should need to load your model is to think in terms of “billions of parameters”. As one byte needs 8 bits, you need 4GB per billion parameters for a full-precision model (32bit = 4bytes), 2GB per billion parameters for a half-precision model, and 1GB per billion parameters for an int8 model.
So in the first place, let’s just load the active model in 8-bit. Let’s see what we need to do for the second step!
### Step 2: Add extra trainable adapters using `peft`
| 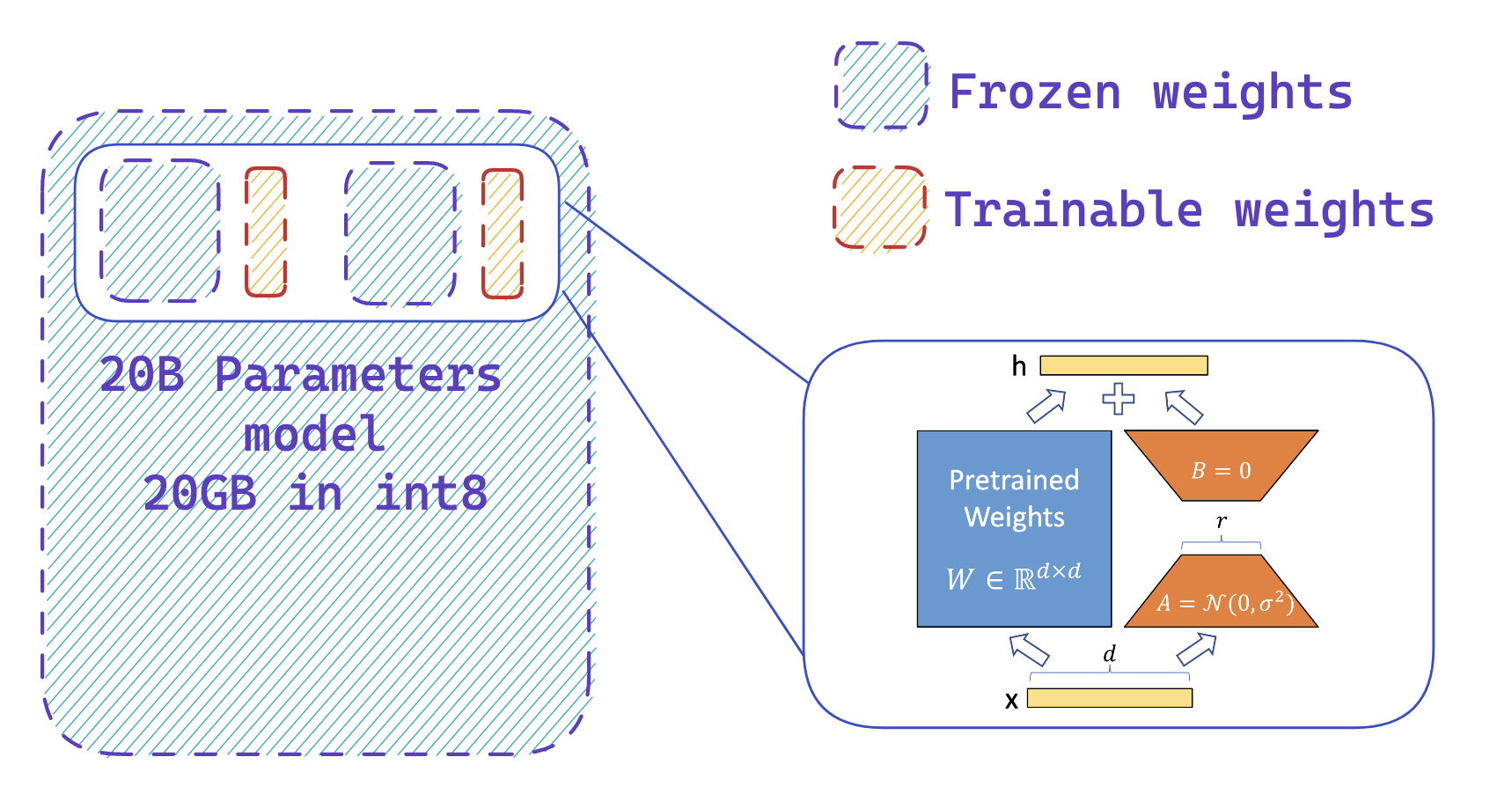 |
|:--:|
| <b> You easily add adapters on a frozen 8-bit model thus reducing the memory requirements of the optimizer states, by training a small fraction of parameters</b>|
The second step is to load adapters inside the model and make these adapters trainable. This enables a drastic reduction of the number of trainable weights that are needed for the active model. This step leverages `peft` library and can be performed with a few lines of code. Note that once the adapters are trained, you can easily push them to the Hub to use them later.
### Step 3: Use the same model to get the reference and active logits
| 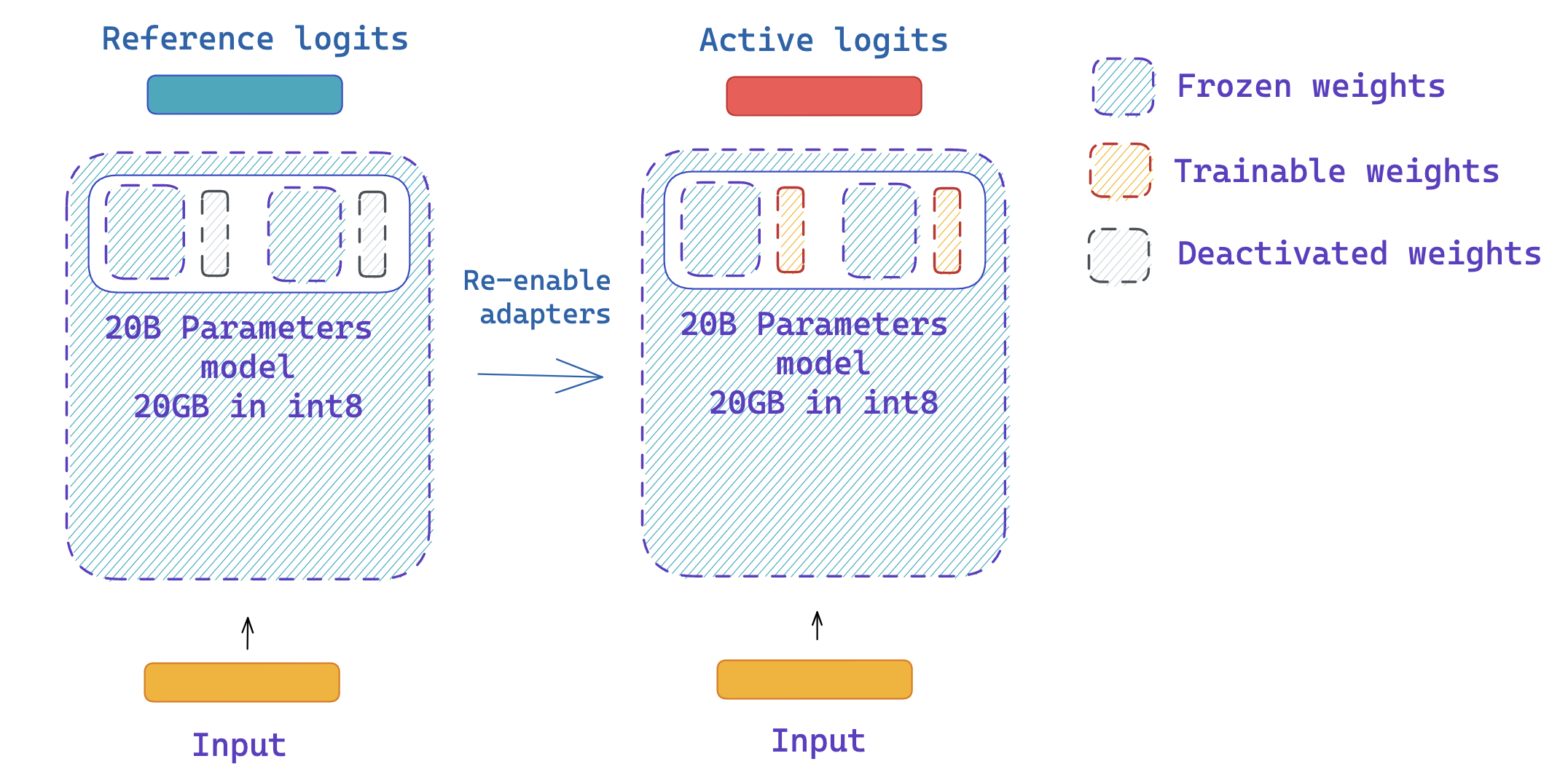 |
|:--:|
| <b> You can easily disable and enable adapters using the `peft` API.</b>|
Since adapters can be deactivated, we can use the same model to get the reference and active logits for PPO, without having to create two copies of the same model! This leverages a feature in `peft` library, which is the `disable_adapters` context manager.
### Overview of the training scripts:
We will now describe how we trained a 20B parameter [gpt-neox model](https://huggingface.co/EleutherAI/gpt-neox-20b) using `transformers`, `peft` and `trl`. The end goal of this example was to fine-tune a LLM to generate positive movie reviews in a memory constrained settting. Similar steps could be applied for other tasks, such as dialogue models.
Overall there were three key steps and training scripts:
1. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/clm_finetune_peft_imdb.py)** - Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset.
2. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py)** - Merging of the adapter layers into the base model’s weights and storing these on the hub.
3. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py)** - Sentiment fine-tuning of a Low Rank Adapter to create positive reviews.
We tested these steps on a 24GB NVIDIA 4090 GPU. While it is possible to perform the entire training run on a 24 GB GPU, the full training runs were untaken on a single A100 on the 🤗 reseach cluster.
The first step in the training process was fine-tuning on the pretrained model. Typically this would require several high-end 80GB A100 GPUs, so we chose to train a low rank adapter. We treated this as a Causal Language modeling setting and trained for one epoch of examples from the [imdb](https://huggingface.co/datasets/imdb) dataset, which features movie reviews and labels indicating whether they are of positive or negative sentiment.
|  |
|:--:|
| <b> Training loss during one epoch of training of a gpt-neox-20b model for one epoch on the imdb dataset</b>|
In order to take the adapted model and perform further finetuning with RL, we first needed to combine the adapted weights, this was achieved by loading the pretrained model and adapter in 16-bit floating point and summary with weight matrices (with the appropriate scaling applied).
Finally, we could then fine-tune another low-rank adapter, on top of the frozen imdb-finetuned model. We use an [imdb sentiment classifier](https://huggingface.co/lvwerra/distilbert-imdb) to provide the rewards for the RL algorithm.
|  |
|:--:|
| <b> Mean of rewards when RL fine-tuning of a peft adapted 20B parameter model to generate positive movie reviews.</b>|
The full Weights and Biases report is available for this experiment [here](https://wandb.ai/edbeeching/trl/runs/l8e7uwm6?workspace=user-edbeeching), if you want to check out more plots and text generations.
## Conclusion
We have implemented a new functionality in `trl` that allows users to fine-tune large language models using RLHF at a reasonable cost by leveraging the `peft` and `bitsandbytes` libraries. We demonstrated that fine-tuning `gpt-neo-x` (40GB in `bfloat16`!) on a 24GB consumer GPU is possible, and we expect that this integration will be widely used by the community to fine-tune larger models utilizing RLHF and share great artifacts.
We have identified some interesting directions for the next steps to push the limits of this integration
- *How this will scale in the multi-GPU setting?* We’ll mainly explore how this integration will scale with respect to the number of GPUs, whether it is possible to apply Data Parallelism out-of-the-box or if it’ll require some new feature adoption on any of the involved libraries.
- *What tools can we leverage to increase training speed?* We have observed that the main downside of this integration is the overall training speed. In the future we would be keen to explore the possible directions to make the training much faster.
## References
- parallelism paradigms: [https://huggingface.co/docs/transformers/v4.17.0/en/parallelism](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism)
- 8-bit integration in `transformers`: [https://huggingface.co/blog/hf-bitsandbytes-integration](https://huggingface.co/blog/hf-bitsandbytes-integration)
- LLM.int8 paper: [https://arxiv.org/abs/2208.07339](https://arxiv.org/abs/2208.07339)
- Gradient checkpoiting explained: [https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html)
| huggingface/blog/blob/main/trl-peft.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Text classification examples
This folder contains some scripts showing examples of *text classification* with the 🤗 Transformers library.
For straightforward use-cases you may be able to use these scripts without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
## run_text_classification.py
This script handles perhaps the single most common use-case for this entire library: Training an NLP classifier
on your own training data. This can be whatever you want - you could classify text as abusive/hateful or
allowable, or forum posts as spam or not-spam, or classify the genre of a headline as politics, sports or any
number of other categories. Any task that involves classifying natural language into two or more different categories
can work with this! You can even do regression, such as predicting the score on a 1-10 scale that a user gave,
given the text of their review.
The preferred input format is either a CSV or newline-delimited JSON file that contains a `sentence1` and
`label` field. If your task involves comparing two texts (for example, if your classifier
is deciding whether two sentences are paraphrases of each other, or were written by the same author) then you should also include a `sentence2` field in each example. If you do not have a `sentence1` field then the script will assume the non-label fields are the input text, which
may not always be what you want, especially if you have more than two fields!
Here is a snippet of a valid input JSON file, though note that your texts can be much longer than these, and are not constrained
(despite the field name) to being single grammatical sentences:
```
{"sentence1": "COVID-19 vaccine updates: How is the rollout proceeding?", "label": "news"}
{"sentence1": "Manchester United celebrates Europa League success", "label": "sports"}
```
### Usage notes
If your inputs are long (more than ~60-70 words), you may wish to increase the `--max_seq_length` argument
beyond the default value of 128. The maximum supported value for most models is 512 (about 200-300 words),
and some can handle even longer. This will come at a cost in runtime and memory use, however.
We assume that your labels represent *categories*, even if they are integers, since text classification
is a much more common task than text regression. If your labels are floats, however, the script will assume
you want to do regression. This is something you can edit yourself if your use-case requires it!
After training, the model will be saved to `--output_dir`. Once your model is trained, you can get predictions
by calling the script without a `--train_file` or `--validation_file`; simply pass it the output_dir containing
the trained model and a `--test_file` and it will write its predictions to a text file for you.
### Multi-GPU and TPU usage
By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most text classification datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
README, but for more information you can see the 'Input Datasets' section of
[this document](https://www.tensorflow.org/guide/tpu).
### Example command
```
python run_text_classification.py \
--model_name_or_path distilbert-base-cased \
--train_file training_data.json \
--validation_file validation_data.json \
--output_dir output/ \
--test_file data_to_predict.json
```
## run_glue.py
This script handles training on the GLUE dataset for various text classification and regression tasks. The GLUE datasets will be loaded automatically, so you only need to specify the task you want (with the `--task_name` argument). You can also supply your own files for prediction with the `--predict_file` argument, for example if you want to train a model on GLUE for e.g. paraphrase detection and then predict whether your own data contains paraphrases or not. Please ensure the names of your input fields match the names of the features in the relevant GLUE dataset - you can see a list of the column names in the `task_to_keys` dict in the `run_glue.py` file.
### Usage notes
The `--do_train`, `--do_eval` and `--do_predict` arguments control whether training, evaluations or predictions are performed. After training, the model will be saved to `--output_dir`. Once your model is trained, you can call the script without the `--do_train` or `--do_eval` arguments to quickly get predictions from your saved model.
### Multi-GPU and TPU usage
By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most text classification datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
README, but for more information you can see the 'Input Datasets' section of
[this document](https://www.tensorflow.org/guide/tpu).
### Example command
```
python run_glue.py \
--model_name_or_path distilbert-base-cased \
--task_name mnli \
--do_train \
--do_eval \
--do_predict \
--predict_file data_to_predict.json
```
| huggingface/transformers/blob/main/examples/tensorflow/text-classification/README.md |
The cache
The cache is one of the reasons why 🤗 Datasets is so efficient. It stores previously downloaded and processed datasets so when you need to use them again, they are reloaded directly from the cache. This avoids having to download a dataset all over again, or reapplying processing functions. Even after you close and start another Python session, 🤗 Datasets will reload your dataset directly from the cache!
## Fingerprint
How does the cache keeps track of what transforms are applied to a dataset? Well, 🤗 Datasets assigns a fingerprint to the cache file. A fingerprint keeps track of the current state of a dataset. The initial fingerprint is computed using a hash from the Arrow table, or a hash of the Arrow files if the dataset is on disk. Subsequent fingerprints are computed by combining the fingerprint of the previous state, and a hash of the latest transform applied.
<Tip>
Transforms are any of the processing methods from the [How-to Process](./process) guides such as [`Dataset.map`] or [`Dataset.shuffle`].
</Tip>
Here are what the actual fingerprints look like:
```py
>>> from datasets import Dataset
>>> dataset1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})
>>> print(dataset1._fingerprint, dataset2._fingerprint)
d19493523d95e2dc 5b86abacd4b42434
```
In order for a transform to be hashable, it needs to be picklable by [dill](https://dill.readthedocs.io/en/latest/) or [pickle](https://docs.python.org/3/library/pickle).
When you use a non-hashable transform, 🤗 Datasets uses a random fingerprint instead and raises a warning. The non-hashable transform is considered different from the previous transforms. As a result, 🤗 Datasets will recompute all the transforms. Make sure your transforms are serializable with pickle or dill to avoid this!
An example of when 🤗 Datasets recomputes everything is when caching is disabled. When this happens, the cache files are generated every time and they get written to a temporary directory. Once your Python session ends, the cache files in the temporary directory are deleted. A random hash is assigned to these cache files, instead of a fingerprint.
<Tip>
When caching is disabled, use [`Dataset.save_to_disk`] to save your transformed dataset or it will be deleted once the session ends.
</Tip>
## Hashing
The fingerprint of a dataset is updated by hashing the function passed to `map` as well as the `map` parameters (`batch_size`, `remove_columns`, etc.).
You can check the hash of any Python object using the [`fingerprint.Hasher`]:
```py
>>> from datasets.fingerprint import Hasher
>>> my_func = lambda example: {"length": len(example["text"])}
>>> print(Hasher.hash(my_func))
'3d35e2b3e94c81d6'
```
The hash is computed by dumping the object using a `dill` pickler and hashing the dumped bytes.
The pickler recursively dumps all the variables used in your function, so any change you do to an object that is used in your function, will cause the hash to change.
If one of your functions doesn't seem to have the same hash across sessions, it means at least one of its variables contains a Python object that is not deterministic.
When this happens, feel free to hash any object you find suspicious to try to find the object that caused the hash to change.
For example, if you use a list for which the order of its elements is not deterministic across sessions, then the hash won't be the same across sessions either.
| huggingface/datasets/blob/main/docs/source/about_cache.mdx |
Metric Card for chrF(++)
## Metric Description
ChrF and ChrF++ are two MT evaluation metrics that use the F-score statistic for character n-gram matches. ChrF++ additionally includes word n-grams, which correlate more strongly with direct assessment. We use the implementation that is already present in sacrebleu.
While this metric is included in sacreBLEU, the implementation here is slightly different from sacreBLEU in terms of the required input format. Here, the length of the references and hypotheses lists need to be the same, so you may need to transpose your references compared to sacrebleu's required input format. See https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534
See the [sacreBLEU README.md](https://github.com/mjpost/sacreBLEU#chrf--chrf) for more information.
## How to Use
At minimum, this metric requires a `list` of predictions and a `list` of `list`s of references:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction, references=reference)
>>> print(results)
{'score': 84.64214891738334, 'char_order': 6, 'word_order': 0, 'beta': 2}
```
### Inputs
- **`predictions`** (`list` of `str`): The predicted sentences.
- **`references`** (`list` of `list` of `str`): The references. There should be one reference sub-list for each prediction sentence.
- **`char_order`** (`int`): Character n-gram order. Defaults to `6`.
- **`word_order`** (`int`): Word n-gram order. If equals to 2, the metric is referred to as chrF++. Defaults to `0`.
- **`beta`** (`int`): Determine the importance of recall w.r.t precision. Defaults to `2`.
- **`lowercase`** (`bool`): If `True`, enables case-insensitivity. Defaults to `False`.
- **`whitespace`** (`bool`): If `True`, include whitespaces when extracting character n-grams. Defaults to `False`.
- **`eps_smoothing`** (`bool`): If `True`, applies epsilon smoothing similar to reference chrF++.py, NLTK, and Moses implementations. If `False`, takes into account effective match order similar to sacreBLEU < 2.0.0. Defaults to `False`.
### Output Values
The output is a dictionary containing the following fields:
- **`'score'`** (`float`): The chrF (chrF++) score.
- **`'char_order'`** (`int`): The character n-gram order.
- **`'word_order'`** (`int`): The word n-gram order. If equals to `2`, the metric is referred to as chrF++.
- **`'beta'`** (`int`): Determine the importance of recall w.r.t precision.
The output is formatted as below:
```python
{'score': 61.576379378113785, 'char_order': 6, 'word_order': 0, 'beta': 2}
```
The chrF(++) score can be any value between `0.0` and `100.0`, inclusive.
#### Values from Popular Papers
### Examples
A simple example of calculating chrF:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction, references=reference)
>>> print(results)
{'score': 84.64214891738334, 'char_order': 6, 'word_order': 0, 'beta': 2}
```
The same example, but with the argument `word_order=2`, to calculate chrF++ instead of chrF:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction,
... references=reference,
... word_order=2)
>>> print(results)
{'score': 82.87263732906315, 'char_order': 6, 'word_order': 2, 'beta': 2}
```
The same chrF++ example as above, but with `lowercase=True` to normalize all case:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction,
... references=reference,
... word_order=2,
... lowercase=True)
>>> print(results)
{'score': 92.12853119829202, 'char_order': 6, 'word_order': 2, 'beta': 2}
```
## Limitations and Bias
- According to [Popović 2017](https://www.statmt.org/wmt17/pdf/WMT70.pdf), chrF+ (where `word_order=1`) and chrF++ (where `word_order=2`) produce scores that correlate better with human judgements than chrF (where `word_order=0`) does.
## Citation
```bibtex
@inproceedings{popovic-2015-chrf,
title = "chr{F}: character n-gram {F}-score for automatic {MT} evaluation",
author = "Popovi{\'c}, Maja",
booktitle = "Proceedings of the Tenth Workshop on Statistical Machine Translation",
month = sep,
year = "2015",
address = "Lisbon, Portugal",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W15-3049",
doi = "10.18653/v1/W15-3049",
pages = "392--395",
}
@inproceedings{popovic-2017-chrf,
title = "chr{F}++: words helping character n-grams",
author = "Popovi{\'c}, Maja",
booktitle = "Proceedings of the Second Conference on Machine Translation",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W17-4770",
doi = "10.18653/v1/W17-4770",
pages = "612--618",
}
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
```
## Further References
- See the [sacreBLEU README.md](https://github.com/mjpost/sacreBLEU#chrf--chrf) for more information on this implementation. | huggingface/datasets/blob/main/metrics/chrf/README.md |
Gradio Demo: uploadbutton_component
```
!pip install -q gradio
```
```
import gradio as gr
def upload_file(files):
file_paths = [file.name for file in files]
return file_paths
with gr.Blocks() as demo:
file_output = gr.File()
upload_button = gr.UploadButton("Click to Upload an Image or Video File", file_types=["image", "video"], file_count="multiple")
upload_button.upload(upload_file, upload_button, file_output)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/uploadbutton_component/run.ipynb |
SelecSLS
**SelecSLS** uses novel selective long and short range skip connections to improve the information flow allowing for a drastically faster network without compromising accuracy.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('selecsls42b', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `selecsls42b`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('selecsls42b', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{Mehta_2020,
title={XNect},
volume={39},
ISSN={1557-7368},
url={http://dx.doi.org/10.1145/3386569.3392410},
DOI={10.1145/3386569.3392410},
number={4},
journal={ACM Transactions on Graphics},
publisher={Association for Computing Machinery (ACM)},
author={Mehta, Dushyant and Sotnychenko, Oleksandr and Mueller, Franziska and Xu, Weipeng and Elgharib, Mohamed and Fua, Pascal and Seidel, Hans-Peter and Rhodin, Helge and Pons-Moll, Gerard and Theobalt, Christian},
year={2020},
month={Jul}
}
```
<!--
Type: model-index
Collections:
- Name: SelecSLS
Paper:
Title: 'XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera'
URL: https://paperswithcode.com/paper/xnect-real-time-multi-person-3d-human-pose
Models:
- Name: selecsls42b
In Collection: SelecSLS
Metadata:
FLOPs: 3824022528
Parameters: 32460000
File Size: 129948954
Architecture:
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Global Average Pooling
- ReLU
- SelecSLS Block
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Random Erasing
Training Data:
- ImageNet
ID: selecsls42b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/selecsls.py#L335
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-selecsls/selecsls42b-8af30141.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.18%
Top 5 Accuracy: 93.39%
- Name: selecsls60
In Collection: SelecSLS
Metadata:
FLOPs: 4610472600
Parameters: 30670000
File Size: 122839714
Architecture:
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Global Average Pooling
- ReLU
- SelecSLS Block
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Random Erasing
Training Data:
- ImageNet
ID: selecsls60
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/selecsls.py#L342
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-selecsls/selecsls60-bbf87526.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.99%
Top 5 Accuracy: 93.83%
- Name: selecsls60b
In Collection: SelecSLS
Metadata:
FLOPs: 4657653144
Parameters: 32770000
File Size: 131252898
Architecture:
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Global Average Pooling
- ReLU
- SelecSLS Block
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Random Erasing
Training Data:
- ImageNet
ID: selecsls60b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/selecsls.py#L349
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-selecsls/selecsls60b-94e619b5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.41%
Top 5 Accuracy: 94.18%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/selecsls.mdx |