
url
stringlengths 66
66
| text
stringlengths 141
41.9k
| num_labels
sequencelengths 1
8
| arr_labels
sequencelengths 82
82
| labels
sequencelengths 1
8
|
|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/34715 |
TITLE
The error caused by the missing espeak library
COMMENTS
3
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
**System Info**
- `transformers` version: 4.46.2
- Platform: Linux-5.4.0-198-generic-x86_64-with-glibc2.35
- Python version: 3.11.9
- Huggingface_hub version: 0.26.2
- Safetensors version: 0.4.5
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: Tesla V100-SXM2-16GB
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. **Docker Image**: Use the Docker image `pytorch/pytorch:2.4.0-cuda12.4-cudnn9-devel`.
2. **Install Requirements**:
```
transformers
other necessary packages
```
3. **Run the First Test Code**:
```python
from transformers.models.auto.tokenization_auto import AutoTokenizer as A
b = A.from_pretrained("facebook/wav2vec2-xlsr-53-espeak-cv-ft", cache_dir=None, force_download=True, local_files_only=False, revision='main')
print("b", b)
# b False
```
4. **After Analysis**, run the following test code:
```python
from transformers.models.wav2vec2_phoneme.tokenization_wav2vec2_phoneme import (
Wav2Vec2PhonemeCTCTokenizer,
)
kwargs = {
"cache_dir": None,
"force_download": True,
"local_files_only": False,
"revision": "main",
"_from_auto": True,
"_commit_hash": None,
}
A = Wav2Vec2PhonemeCTCTokenizer("facebook/wav2vec2-xlsr-53-espeak-cv-ft", **kwargs)
```
### Expected behavior
In step 3, the Tokenizer was not loaded correctly.
Step 4 throws the following error:
```
Traceback (most recent call last):
File "/workspace/test.py", line 14, in <module>
A = Wav2Vec2PhonemeCTCTokenizer(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py", line 136, in __init__
self.init_backend(self.phonemizer_lang)
File "/opt/conda/lib/python3.11/site-packages/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py", line 185, in init_backend
self.backend = BACKENDS[self.phonemizer_backend](phonemizer_lang, language_switch="remove-flags")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/site-packages/phonemizer/backend/espeak/espeak.py", line 45, in __init__
super().__init__(
File "/opt/conda/lib/python3.11/site-packages/phonemizer/backend/espeak/base.py", line 39, in __init__
super().__init__(
File "/opt/conda/lib/python3.11/site-packages/phonemizer/backend/base.py", line 77, in __init__
raise RuntimeError( # pragma: nocover
RuntimeError: espeak not installed on your system
``` | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/33665 |
TITLE
[Tests] Diverse Whisper fixes
COMMENTS
12
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
There's a lot of pending failing tests with Whisper. This PR addresses some issues:
1. #31683 and #31770 mentioned a out-of-range word level timestamps. This happens because `decoder_inputs_ids` were once `forced_input_ids`. This had an impact on the `beam_indices`.
`beam_indices` has a length of `decoder_input_ids + potentially_generated_ids` but doesn't take into account `decoder_input_ids` when keeping track of the indices. In other words `beam_indices[0]` is really the beam indice of the first generated token, instead of `decoder_input_ids[0]`.
2. The Flash-Attention 2 attention mask was causing an issue
3. The remaining work is done on the modeling tests. Note that some of these tests were failing because of straightforward reasons - e.g the output was a dict - and are actually still failing, but their reasons for failing are not straightforward anymore. Debugging will be easier though.
**Note:** With #33450 and this, we're down from 29 failing tests to 17
| [
73
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"run-slow"
] |
https://api.github.com/repos/huggingface/transformers/issues/34622 |
TITLE
Question on OWLv2 Model Input Size Flexibility in Hugging Face
COMMENTS
3
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
I noticed that in Google Research's OWLv2 implementation, the model can accept images of varying sizes, as it allows the input image size to be adjusted. Does Hugging Face’s version of OWLv2 support this same flexibility in input image sizes? | [
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/34583 |
TITLE
Add support for Apple's Depth-Pro
COMMENTS
86
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 3
rocket: 0
eyes: 0
BODY
# What does this PR do?
Fixes #34020
This PR adds Apple's Depth Pro model to Hugging Face Transformers. Depth Pro is a foundation model for zero-shot metric monocular depth estimation. It leverages a multi-scale vision transformer optimized for dense predictions. It downsamples an image at several scales. At each scale, it is split into patches, which are processed by a ViT-based (Dinov2) patch encoder, with weights shared across scales. Patches are merged into feature maps, upsampled, and fused via a DPT decoder.
Relevant Links
- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
- Authors: [Aleksei Bochkovskii](https://arxiv.org/search/cs?searchtype=author&query=Bochkovskii,+A), [Amaël Delaunoy](https://arxiv.org/search/cs?searchtype=author&query=Delaunoy,+A), and others
- Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
- Models Weights: [apple/DepthPro](https://huggingface.co/apple/DepthPro)
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#create-a-pull-request),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@amyeroberts, @qubvel
| [
77,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0
] | [
"New model",
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/35349 |
TITLE
A warning message showing that `MultiScaleDeformableAttention.so` is not found in `/root/.cache/torch_extensions` if `ninja` is installed with `transformers`
COMMENTS
12
REACTIONS
+1: 1
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
* `transformers`: `4.47.1`
* `torch`: `2.5.1`
* `timm`: `1.0.12`
* `ninja`: `1.11.1.3`
* `python`: `3.10.14`
* `pip`: `23.0.1`
* CUDA runtime installed by `torch`: `nvidia-cuda-runtime-cu12==12.4.127`
* OS (in container): Debian GNU/Linux 12 (bookworm)
* OS (native device): Windows 11 Enterprise 23H2 (`10.0.22631 Build 22631`)
* Docker version: `27.3.1, build ce12230`
* NVIDIA Driver: `565.57.02`
### Who can help?
I am asking help for [`DeformableDetrModel`](https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/deformable_detr#transformers.DeformableDetrModel)
vision models: @amyeroberts, @qubvel
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. Start a new docker container by
```sh
docker run --gpus all -it --rm --shm-size=1g python:3.10-slim bash
```
2. Install dependencies
```sh
pip install transformers[torch] requests pillow timm
```
3. Run the following script (copied from [the document](https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/deformable_detr#transformers.DeformableDetrModel.forward.example)), it works fine and does not show any message.
```python
from transformers import AutoImageProcessor, DeformableDetrModel
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
model = DeformableDetrModel.from_pretrained("SenseTime/deformable-detr")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
list(last_hidden_states.shape)
```
4. Install ninja:
```sh
pip install ninja
```
5. Run [the same script](https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/deformable_detr#transformers.DeformableDetrModel.forward.example) again, this time, the following warning messages will show
```text
!! WARNING !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Your compiler (c++) is not compatible with the compiler Pytorch was
built with for this platform, which is g++ on linux. Please
use g++ to to compile your extension. Alternatively, you may
compile PyTorch from source using c++, and then you can also use
c++ to compile your extension.
See https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md for help
with compiling PyTorch from source.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! WARNING !!
warnings.warn(WRONG_COMPILER_WARNING.format(
Could not load the custom kernel for multi-scale deformable attention: CUDA_HOME environment variable is not set. Please set it to your CUDA install root.
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
Could not load the custom kernel for multi-scale deformable attention: /root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/MultiScaleDeformableAttention.so: cannot open shared object file: No such file or directory
```
Certainly, `/root/.cache/torch_extensions/py310_cu124/MultiScaleDeformableAttention/` is empty.
The issue happens only when both `ninja` and `transformers` are installed. I believe that the following issue may be related to this issue:
https://app.semanticdiff.com/gh/huggingface/transformers/pull/32834/overview
### Expected behavior
It seems that ninja will let `DeformableDetrModel` throw unexpected error messages (despite that the script still works). That's may be because I am using a container without any compiler or CUDA preinstalled (the CUDA run time is installed by `pip`).
I think there should be a check that automatically turn of the `ninja` related functionalities even if `ninja` is installed by `pip`, as long as the requirements like compiler version, CUDA path, or something, are not fulfilled.
| [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34699 |
TITLE
TypeError: Accelerator.__init__() got an unexpected keyword argument 'dispatch_batches'
COMMENTS
8
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
transformers: 4.39.3
python: 3.10.12
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
An error may occur at line 580 of [run_ner.py](https://github.com/huggingface/transformers/blob/v4.39.3/examples/pytorch/token-classification/run_ner.py)
```python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
```
### Expected behavior
```
Traceback (most recent call last):
File "/usr/src/app/llm_model_test/ner_train/run_ner.py", line 666, in <module>
main()
File "/usr/src/app/llm_model_test/ner_train/run_ner.py", line 580, in main
trainer = Trainer(
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 373, in __init__
self.create_accelerator_and_postprocess()
File "/usr/local/lib/python3.10/dist-packages/transformers/trainer.py", line 4252, in create_accelerator_and_postprocess
self.accelerator = Accelerator(
TypeError: Accelerator.__init__() got an unexpected keyword argument 'dispatch_batches'
```
Please Help Me... | [
27,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"dependencies",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/35979 |
TITLE
Fix custom kernel for DeformableDetr, RT-Detr, GroundingDINO, OmDet-Turbo in Pytorch 2.6.0
COMMENTS
6
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
Updates
- tesnor.type().is_cuda() -> tesnor.is_cuda();
- tensor.data<...> -> tensor.data_ptr<...>
The following message appears in logs:
```
Tensor.type() is deprecated. Instead use Tensor.options(), which in many cases (e.g. in a constructor)
is a drop-in replacement. If you were using data from type(), that is now available from Tensor
itself, so instead of tensor.type().scalar_type(), use tensor.scalar_type() instead and instead of
tensor.type().backend() use tensor.device().
```
Fixes #35976
Might be relevant:
- https://github.com/pytorch/pytorch/issues/28472
- https://discuss.pytorch.org/t/kernel-launch-deprecated-packed-accessor-arguments-and-tensor-type-alternative/138875
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#create-a-pull-request),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker
- vision models: @amyeroberts, @qubvel
- speech models: @ylacombe, @eustlb
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @zucchini-nlp (visual-language models) or @gante (all others)
- pipelines: @Rocketknight1
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerzr and @SunMarc
- chat templates: @Rocketknight1
Integrations:
- deepspeed: HF Trainer/Accelerate: @muellerzr
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc @MekkCyber
Documentation: @stevhliu
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
| [
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/36023 |
TITLE
CEP_AI
COMMENTS
0
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Model description
CEP of Subject Ai
### Open source status
- [ ] The model implementation is available
- [ ] The model weights are available
### Provide useful links for the implementation
_No response_ | [
77
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0
] | [
"New model"
] |
https://api.github.com/repos/huggingface/transformers/issues/35767 |
TITLE
Issue: Error with _eos_token_tensor when using Generator with GenerationMixin
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
e-readability-summarization/src/inference$ python run_2.py
Traceback (most recent call last):
File "/home/surenoobster/Documents/project/src/inference/run_2.py", line 87, in <module>
output = generator.generate(
^^^^^^^^^^^^^^^^^^^
File "/home/surenoobster/anaconda3/lib/python3.12/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/surenoobster/Documents/project/src/inference/generation_2.py", line 572, in generate
stopping_criteria = self.model._get_stopping_criteria(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/surenoobster/anaconda3/lib/python3.12/site-packages/transformers/generation/utils.py", line 1126, in _get_stopping_criteria
if generation_config._eos_token_tensor is not None:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'GenerationConfig' object has no attribute '_eos_token_tensor'
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I'm not able to get it , getting problem with device
### Expected behavior
The Generator should initialize the required token tensors correctly to ensure compatibility with GenerationMixin and avoid errors. | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/36037 |
TITLE
Fix qwen2-vl generate calls with synced_gpus
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
When using `synced_gpus`, after one peer finishes generating, the cache position in the generation process continues to increase. This leads to the input IDs going out of bounds, resulting in errors. The issue specifically occurs in the following line of code:
[modeling_qwen2_vl.py#L1739](https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen2_vl/modeling_qwen2_vl.py#L1739).
The root cause seems to be the difference in the implementation of the `prepare_inputs_for_generation` function compared to the default implementation found here:
[utils.py#L388](https://github.com/huggingface/transformers/blob/main/src/transformers/generation/utils.py#L388).
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Happened when running this code
https://github.com/Deep-Agent/R1-V/blob/main/src/open-r1-multimodal/src/open_r1/trainer/grpo_trainer.py#L372
### Expected behavior
Keep consistent with the default implementation | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34024 |
TITLE
HF Trainer do not support Pytorch FSDP with FP8; ValueError: You must pass a model and an optimizer together to `accelerate.prepare()` when using TransformerEngine.
COMMENTS
0
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info

acc_cfg.yml:
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
enable_cpu_affinity: false
fsdp_config:
fsdp_activation_checkpointing: true
fsdp_auto_wrap_policy: NO_WRAP
fsdp_backward_prefetch: NO_PREFETCH
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: true
fsdp_offload_params: true
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: true
machine_rank: 0
main_process_ip: 0.0.0.0
main_process_port: 0
main_training_function: main
mixed_precision: fp8
fp8_config:
amax_compute_algorithm: max
amax_history_length: 1024
backend: TE
fp8_format: HYBRID
interval: 1
margin: 0
override_linear_precision: false
use_autocast_during_eval: true
num_machines: 3
num_processes: 24
rdzv_backend: etcd-v2
same_network: false
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
* accelerate launch --config_file acc_cfg.yml train.py $TRAINING_ARGS
* the train.py is any training script that train using transformers.Trainer
* $TRAINING_ARGS are the TrainingArguments plus some path to data
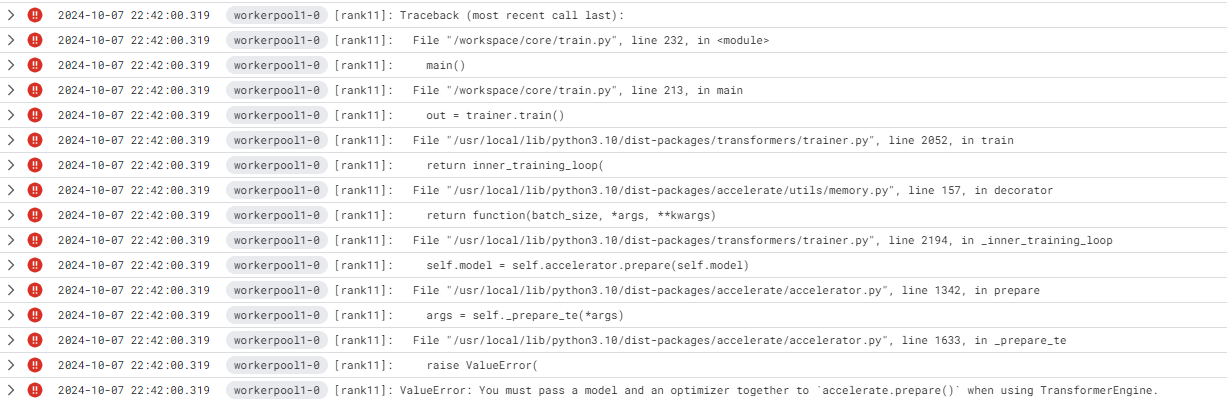
### Expected behavior
Train Paligemma model with FSDP and FP8. | [
66,
64,
17,
80
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0
] | [
"trainer",
"bug",
"PyTorch FSDP",
"Accelerate"
] |
https://api.github.com/repos/huggingface/transformers/issues/35507 |
TITLE
Memory Access out of bounds in mra/cuda_kernel.cu::index_max_cuda_kernel()
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
* OS: Linux ubuntu 22.04 LTS
* Device: A100-80GB
* docker: nvidia/pytorch:24.04-py3
* transformers: latest, 4.47.0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
## Reproduction
1. pip install the latest transformers
2. prepare the UT test enviroments by `pip install -e .[testing]`
3. `pytest tests/models/mra/test_modeling_mra.py`
## Analysis
There might be some memory access out-of-bound behaviours in CUDA kernel `index_max_cuda_kernel()`
https://github.com/huggingface/transformers/blob/main/src/transformers/kernels/mra/cuda_kernel.cu#L6C1-L58C2
Note that `max_buffer` in this kernel is `extern __shared__ float` type, which means `max_buffer` would be stored in shared memory.
According to https://github.com/huggingface/transformers/blob/main/src/transformers/kernels/mra/cuda_launch.cu#L24-L35, CUDA would launch this kernel with
* gird size: `batch_size`
* block size: 256
* shared memory size: `A_num_block * 32 * sizeof(float)`
In case that `A_num_block` < 4, the for statement below might accidentally locate the memory out of `A_num_block * 32`, since num_thread here is 256, and threadIdx.x is [0, 255].
```
for (int idx_start = 0; idx_start < 32 * num_block; idx_start = idx_start + num_thread) {
```
Therefore, when threadblocks of threads try to access `max_buffer`, it would be wiser and more careful to always add `if` statements before to avoid memory access out of bounds.
So We suggest to add `if` statements in two places:

### Expected behavior
UT tests should all pass! | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/36057 |
TITLE
past_key_values type support bug
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
In many `XXXXForCausalLM` Class, the past_key_values signature of the forward function is: `past_key_values: Optional[Union[Cache, List[torch.FloatTensor]]] = None,` but the corresponding past_key_values signature of the forward function of the `XXXXModel` Class is: `past_key_values: Optional[Cache] = None,` and the function implementation does not support the `List` type. `past_key_values` will causes an error when calling `self.model` use List type `past_key_values`.
Like `LlamaForCausalLM` and `Qwen2ForCausalLM` | [
74
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0
] | [
"Documentation"
] |
https://api.github.com/repos/huggingface/transformers/issues/36142 |
TITLE
Bump cryptography from 43.0.1 to 44.0.1 in /examples/research_projects/decision_transformer
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
Bumps [cryptography](https://github.com/pyca/cryptography) from 43.0.1 to 44.0.1.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/pyca/cryptography/blob/main/CHANGELOG.rst">cryptography's changelog</a>.</em></p>
<blockquote>
<p>44.0.1 - 2025-02-11</p>
<pre><code>
* Updated Windows, macOS, and Linux wheels to be compiled with OpenSSL 3.4.1.
* We now build ``armv7l`` ``manylinux`` wheels and publish them to PyPI.
* We now build ``manylinux_2_34`` wheels and publish them to PyPI.
<p>.. _v44-0-0:</p>
<p>44.0.0 - 2024-11-27
</code></pre></p>
<ul>
<li><strong>BACKWARDS INCOMPATIBLE:</strong> Dropped support for LibreSSL < 3.9.</li>
<li>Deprecated Python 3.7 support. Python 3.7 is no longer supported by the
Python core team. Support for Python 3.7 will be removed in a future
<code>cryptography</code> release.</li>
<li>Updated Windows, macOS, and Linux wheels to be compiled with OpenSSL 3.4.0.</li>
<li>macOS wheels are now built against the macOS 10.13 SDK. Users on older
versions of macOS should upgrade, or they will need to build
<code>cryptography</code> themselves.</li>
<li>Enforce the :rfc:<code>5280</code> requirement that extended key usage extensions must
not be empty.</li>
<li>Added support for timestamp extraction to the
:class:<code>~cryptography.fernet.MultiFernet</code> class.</li>
<li>Relax the Authority Key Identifier requirements on root CA certificates
during X.509 verification to allow fields permitted by :rfc:<code>5280</code> but
forbidden by the CA/Browser BRs.</li>
<li>Added support for :class:<code>~cryptography.hazmat.primitives.kdf.argon2.Argon2id</code>
when using OpenSSL 3.2.0+.</li>
<li>Added support for the :class:<code>~cryptography.x509.Admissions</code> certificate extension.</li>
<li>Added basic support for PKCS7 decryption (including S/MIME 3.2) via
:func:<code>~cryptography.hazmat.primitives.serialization.pkcs7.pkcs7_decrypt_der</code>,
:func:<code>~cryptography.hazmat.primitives.serialization.pkcs7.pkcs7_decrypt_pem</code>, and
:func:<code>~cryptography.hazmat.primitives.serialization.pkcs7.pkcs7_decrypt_smime</code>.</li>
</ul>
<p>.. _v43-0-3:</p>
<p>43.0.3 - 2024-10-18</p>
<pre><code>
* Fixed release metadata for ``cryptography-vectors``
<p>.. _v43-0-2:</p>
<p>43.0.2 - 2024-10-18
</code></pre></p>
<ul>
<li>Fixed compilation when using LibreSSL 4.0.0.</li>
</ul>
<p>.. _v43-0-1:</p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/pyca/cryptography/commit/adaaaed77db676bbaa9d171175db81dce056e2a7"><code>adaaaed</code></a> Bump for 44.0.1 release (<a href="https://redirect.github.com/pyca/cryptography/issues/12441">#12441</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/ccc61dabe38b86956bf218565cd4e82b918345a1"><code>ccc61da</code></a> [backport] test and build on armv7l (<a href="https://redirect.github.com/pyca/cryptography/issues/12420">#12420</a>) (<a href="https://redirect.github.com/pyca/cryptography/issues/12431">#12431</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/f299a48153650f2dd87716343f2daa7cd39a1f59"><code>f299a48</code></a> remove deprecated call (<a href="https://redirect.github.com/pyca/cryptography/issues/12052">#12052</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/439eb0594a9ffb7c9adedb2490998d83914d141e"><code>439eb05</code></a> Bump version for 44.0.0 (<a href="https://redirect.github.com/pyca/cryptography/issues/12051">#12051</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/2c5ad4d8dcec1b8f833198bc2f3b4634c4fd9d78"><code>2c5ad4d</code></a> chore(deps): bump maturin from 1.7.4 to 1.7.5 in /.github/requirements (<a href="https://redirect.github.com/pyca/cryptography/issues/12050">#12050</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/d23968adddd79aa8508d7c1f985da09383b3808f"><code>d23968a</code></a> chore(deps): bump libc from 0.2.165 to 0.2.166 (<a href="https://redirect.github.com/pyca/cryptography/issues/12049">#12049</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/133c0e02edf2f172318eb27d8f50525ed64c9ec3"><code>133c0e0</code></a> Bump x509-limbo and/or wycheproof in CI (<a href="https://redirect.github.com/pyca/cryptography/issues/12047">#12047</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/f2259d7aa0d134c839ebe298baa8b63de9ead804"><code>f2259d7</code></a> Bump BoringSSL and/or OpenSSL in CI (<a href="https://redirect.github.com/pyca/cryptography/issues/12046">#12046</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/e201c870b89fd2606d67230a97e50c3badb07907"><code>e201c87</code></a> fixed metadata in changelog (<a href="https://redirect.github.com/pyca/cryptography/issues/12044">#12044</a>)</li>
<li><a href="https://github.com/pyca/cryptography/commit/c6104cc3669585941dc1d2b9c6507621c53d242f"><code>c6104cc</code></a> Prohibit Python 3.9.0, 3.9.1 -- they have a bug that causes errors (<a href="https://redirect.github.com/pyca/cryptography/issues/12045">#12045</a>)</li>
<li>Additional commits viewable in <a href="https://github.com/pyca/cryptography/compare/43.0.1...44.0.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/huggingface/transformers/network/alerts).
</details> | [
27,
60
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"dependencies",
"python"
] |
https://api.github.com/repos/huggingface/transformers/issues/34727 |
TITLE
[Idefics3] processing_idefics3 - IndexError: list index out of range for multiple image input
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.46.2
- Platform: Linux-5.4.0-1134-aws-x86_64-with-glibc2.31
- Python version: 3.10.2
- Huggingface_hub version: 0.26.2
- Safetensors version: 0.4.5
- Accelerate version: 1.1.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1+cu124 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: No
- Using GPU in script?: Yes
- GPU type: Tesla T4
### Who can help?
@amyeroberts , @quvb
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Code to reproduce:
from PIL import Image
img1=Image.open('Image1.JPG')
img2=Image.open('Image2.JPG')
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[img1,img2], return_tensors="pt")
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=512)
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[4], line 6
3 img2=Image.open('Image2.JPG')
5 prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
----> 6 inputs = processor(text=[prompt,prompt], images=[img1,img2], return_tensors="pt")
7 inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
9 # Generate
File ~/envs/default/lib/python3.10/site-packages/transformers/models/idefics3/processing_idefics3.py:302, in Idefics3Processor.__call__(self, images, text, audio, videos, image_seq_len, **kwargs)
300 sample = split_sample[0]
301 for i, image_prompt_string in enumerate(image_prompt_strings):
--> 302 sample += image_prompt_string + split_sample[i + 1]
303 prompt_strings.append(sample)
305 text_inputs = self.tokenizer(text=prompt_strings, **output_kwargs["text_kwargs"])
IndexError: list index out of range
### Expected behavior
I would expect Model to take 2 images in the input and provide generation using these 2 images as context. | [
64,
62,
12
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug",
"Vision",
"Multimodal"
] |
https://api.github.com/repos/huggingface/transformers/issues/34176 |
TITLE
[Bug] transformers `TPU` support broken on `v4.45.0`
COMMENTS
23
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 1
BODY
### System Info
transformers: v4.45.0 and up (any of v4.45.0 / v4.45.1 / v4.45.2)
accelerate: v1.0.1 (same result on v0.34.2)
### Who can help?
trainer experts: @muellerzr @SunMarc
accelerate expert: @muellerzr
text models expert: @ArthurZucker
Thank you guys!
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Minimal working code is [Here](https://gist.github.com/steveepreston/acd125a08214c631ba8389eb61a13798). Code follows [GoogleCloudPlatform example](https://github.com/GoogleCloudPlatform/vertex-ai-samples/blob/main/notebooks/official/training/tpuv5e_llama2_pytorch_finetuning_and_serving.ipynb)
on TPU VM, train done like a charm on transformers from v4.43.1 to v4.44.2, but when upgrading to any of v4.45.0 / v4.45.1 / v4.45.2 it throws this Error: `RuntimeError: There are currently no available devices found, must be one of 'XPU', 'CUDA', or 'NPU'.`
**Error Traceback:**
General traceback is: callling `SFTTrainer()` > `self.accelerator = Accelerator(**args)` (transformers/trainer.py)
<details>
<summary>Click here to Show Full Error Traceback</summary>
```python
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[48], line 4
1 from trl import SFTTrainer
2 from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
----> 4 trainer = SFTTrainer(
5 model=base_model,
6 train_dataset=data,
7 args=TrainingArguments(
8 per_device_train_batch_size=BATCH_SIZE, # This is actually the global batch size for SPMD.
9 num_train_epochs=1,
10 max_steps=-1,
11 output_dir="/output_dir",
12 optim="adafactor",
13 logging_steps=1,
14 dataloader_drop_last = True, # Required for SPMD.
15 fsdp="full_shard",
16 fsdp_config=fsdp_config,
17 ),
18 peft_config=lora_config,
19 dataset_text_field="quote",
20 max_seq_length=max_seq_length,
21 packing=True,
22 )
File /usr/local/lib/python3.10/site-packages/huggingface_hub/utils/_deprecation.py:101, in _deprecate_arguments.<locals>._inner_deprecate_positional_args.<locals>.inner_f(*args, **kwargs)
99 message += "\n\n" + custom_message
100 warnings.warn(message, FutureWarning)
--> 101 return f(*args, **kwargs)
File /usr/local/lib/python3.10/site-packages/trl/trainer/sft_trainer.py:401, in SFTTrainer.__init__(self, model, args, data_collator, train_dataset, eval_dataset, tokenizer, model_init, compute_metrics, callbacks, optimizers, preprocess_logits_for_metrics, peft_config, dataset_text_field, packing, formatting_func, max_seq_length, infinite, num_of_sequences, chars_per_token, dataset_num_proc, dataset_batch_size, neftune_noise_alpha, model_init_kwargs, dataset_kwargs, eval_packing)
395 if tokenizer.padding_side is not None and tokenizer.padding_side != "right":
396 warnings.warn(
397 "You passed a tokenizer with `padding_side` not equal to `right` to the SFTTrainer. This might lead to some unexpected behaviour due to "
398 "overflow issues when training a model in half-precision. You might consider adding `tokenizer.padding_side = 'right'` to your code."
399 )
--> 401 super().__init__(
402 model=model,
403 args=args,
404 data_collator=data_collator,
405 train_dataset=train_dataset,
406 eval_dataset=eval_dataset,
407 tokenizer=tokenizer,
408 model_init=model_init,
409 compute_metrics=compute_metrics,
410 callbacks=callbacks,
411 optimizers=optimizers,
412 preprocess_logits_for_metrics=preprocess_logits_for_metrics,
413 )
415 # Add tags for models that have been loaded with the correct transformers version
416 if hasattr(self.model, "add_model_tags"):
File /usr/local/lib/python3.10/site-packages/transformers/trainer.py:411, in Trainer.__init__(self, model, args, data_collator, train_dataset, eval_dataset, tokenizer, model_init, compute_metrics, callbacks, optimizers, preprocess_logits_for_metrics)
408 self.deepspeed = None
409 self.is_in_train = False
--> 411 self.create_accelerator_and_postprocess()
413 # memory metrics - must set up as early as possible
414 self._memory_tracker = TrainerMemoryTracker(self.args.skip_memory_metrics)
File /usr/local/lib/python3.10/site-packages/transformers/trainer.py:4858, in Trainer.create_accelerator_and_postprocess(self)
4855 args.update(accelerator_config)
4857 # create accelerator object
-> 4858 self.accelerator = Accelerator(**args)
4859 # some Trainer classes need to use `gather` instead of `gather_for_metrics`, thus we store a flag
4860 self.gather_function = self.accelerator.gather_for_metrics
File /usr/local/lib/python3.10/site-packages/accelerate/accelerator.py:349, in Accelerator.__init__(self, device_placement, split_batches, mixed_precision, gradient_accumulation_steps, cpu, dataloader_config, deepspeed_plugin, fsdp_plugin, megatron_lm_plugin, rng_types, log_with, project_dir, project_config, gradient_accumulation_plugin, step_scheduler_with_optimizer, kwargs_handlers, dynamo_backend, deepspeed_plugins)
345 raise ValueError(f"FSDP requires PyTorch >= {FSDP_PYTORCH_VERSION}")
347 if fsdp_plugin is None: # init from env variables
348 fsdp_plugin = (
--> 349 FullyShardedDataParallelPlugin() if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true" else None
350 )
351 else:
352 if not isinstance(fsdp_plugin, FullyShardedDataParallelPlugin):
File <string>:21, in __init__(self, sharding_strategy, backward_prefetch, mixed_precision_policy, auto_wrap_policy, cpu_offload, ignored_modules, state_dict_type, state_dict_config, optim_state_dict_config, limit_all_gathers, use_orig_params, param_init_fn, sync_module_states, forward_prefetch, activation_checkpointing, cpu_ram_efficient_loading, transformer_cls_names_to_wrap, min_num_params)
File /usr/local/lib/python3.10/site-packages/accelerate/utils/dataclasses.py:1684, in FullyShardedDataParallelPlugin.__post_init__(self)
1682 device = torch.xpu.current_device()
1683 else:
-> 1684 raise RuntimeError(
1685 "There are currently no available devices found, must be one of 'XPU', 'CUDA', or 'NPU'."
1686 )
1687 # Create a function that will be used to initialize the parameters of the model
1688 # when using `sync_module_states`
1689 self.param_init_fn = lambda x: x.to_empty(device=device, recurse=False)
RuntimeError: There are currently no available devices found, must be one of 'XPU', 'CUDA', or 'NPU'.
```
</details>
**My observation and guess**
I tested multiple times, and can confirm that this error is Directly Caused by only changing version of `transformers`. Therefore `accelerate` version was fixed during all runs, my guess is something changed on `v4.45.0` (maybe on `trainer.py`) that affects `args` in the `self.accelerator = Accelerator(**args)`, so that error will raised by `accelerate` .
### Expected behavior
my guess: `args` corrected and `self.accelerator = Accelerator(**args)` called correctly. so `accelerate` can work on `TPU`. | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34162 |
TITLE
requests.exceptions.ReadTimeout on already cached/downloaded model using SentenceTransformers
COMMENTS
5
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
transformers version: 44.2
python version: 3.11.6
system OS: Linux
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
When HuggingFace servers are down or you have no internet connection, try to initialize an already downloaded/cached model. I was using SentenceTransformers (running SentenceTransformer(model_name_or_path=model_id, device=my_device), but the problem comes from the transformers library, so I'm not sure which library should make the changes.
### Expected behavior
The model loads properly without requiring any connection to the hub. | [
67,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Usage",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/33998 |
TITLE
Is the BOS token id of 128000 **hardcoded** into the llama 3.2 tokenizer?
COMMENTS
13
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.45.1
- Platform: Linux-5.15.154+-x86_64-with-glibc2.31
- Python version: 3.10.13
- Huggingface_hub version: 0.23.2
- Safetensors version: 0.4.3
- Accelerate version: 0.30.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.1.2+cpu (False)
- Tensorflow version (GPU?): 2.15.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.8.4 (cpu)
- Jax version: 0.4.28
- JaxLib version: 0.4.28
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@ArthurZucker @itazap
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I trained the llama 3.2 tokenizer using an Amharic language corpus and a vocab size of `28k`, but when I use it to tokenize text, the first token id is still `128000` when it should have been the new tokenizer's **BOS token id** of `0`.
And here's a tokenization of an example text. As can be seen, the first token id is `128000` when it should have been `0`.
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("rasyosef/llama-3.2-amharic-tokenizer-28k")
text = "ሁሉም ነገር"
inputs = tokenizer(text, return_tensors="pt")
print(inputs["input_ids"])
```
Output:
```
tensor([[128000, 1704, 802]])
```
### Expected behavior
The first token id of the tokenized text should be the new tokenizer's **BOS token id** of `0` instead of the original llama 3.2 tokenizer's BOS token id of `128000`. The vocab size is `28000` and the number `128000` should not appear anywhere in the `input_ids` list.
This is causing index out of range errors when indexing the embedding matrix of a newly initialized model. | [
47,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Core: Tokenization",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/36168 |
TITLE
Bump transformers from 4.38.0 to 4.48.0 in /examples/research_projects/adversarial
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
Bumps [transformers](https://github.com/huggingface/transformers) from 4.38.0 to 4.48.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/huggingface/transformers/releases">transformers's releases</a>.</em></p>
<blockquote>
<h2>v4.48.0: ModernBERT, Aria, TimmWrapper, ColPali, Falcon3, Bamba, VitPose, DinoV2 w/ Registers, Emu3, Cohere v2, TextNet, DiffLlama, PixtralLarge, Moonshine</h2>
<h2>New models</h2>
<h3>ModernBERT</h3>
<p>The ModernBert model was proposed in <a href="https://arxiv.org/abs/2412.13663">Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference</a> by Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Galalgher, Raja Bisas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Grifin Adams, Jeremy Howard and Iacopo Poli.</p>
<p>It is a refresh of the traditional encoder architecture, as used in previous models such as <a href="https://huggingface.co/docs/transformers/en/model_doc/bert">BERT</a> and <a href="https://huggingface.co/docs/transformers/en/model_doc/roberta">RoBERTa</a>.</p>
<p>It builds on BERT and implements many modern architectural improvements which have been developed since its original release, such as:</p>
<ul>
<li><a href="https://huggingface.co/blog/designing-positional-encoding">Rotary Positional Embeddings</a> to support sequences of up to 8192 tokens.</li>
<li><a href="https://arxiv.org/abs/2208.08124">Unpadding</a> to ensure no compute is wasted on padding tokens, speeding up processing time for batches with mixed-length sequences.</li>
<li><a href="https://arxiv.org/abs/2002.05202">GeGLU</a> Replacing the original MLP layers with GeGLU layers, shown to improve performance.</li>
<li><a href="https://arxiv.org/abs/2004.05150v2">Alternating Attention</a> where most attention layers employ a sliding window of 128 tokens, with Global Attention only used every 3 layers.</li>
<li><a href="https://github.com/Dao-AILab/flash-attention">Flash Attention</a> to speed up processing.</li>
<li>A model designed following recent <a href="https://arxiv.org/abs/2401.14489">The Case for Co-Designing Model Architectures with Hardware</a>, ensuring maximum efficiency across inference GPUs.</li>
<li>Modern training data scales (2 trillion tokens) and mixtures (including code ande math data)</li>
</ul>
<p><img src="https://github.com/user-attachments/assets/4256c0b1-9b40-4d71-ac42-fc94827d5e9d" alt="image" /></p>
<ul>
<li>Add ModernBERT to Transformers by <a href="https://github.com/warner-benjamin"><code>@warner-benjamin</code></a> in <a href="https://redirect.github.com/huggingface/transformers/issues/35158">#35158</a></li>
</ul>
<h3>Aria</h3>
<p>The Aria model was proposed in <a href="https://huggingface.co/papers/2410.05993">Aria: An Open Multimodal Native Mixture-of-Experts Model</a> by Li et al. from the Rhymes.AI team.</p>
<p>Aria is an open multimodal-native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. It has a Mixture-of-Experts architecture, with respectively 3.9B and 3.5B activated parameters per visual token and text token.</p>
<ul>
<li>Add Aria by <a href="https://github.com/aymeric-roucher"><code>@aymeric-roucher</code></a> in <a href="https://redirect.github.com/huggingface/transformers/issues/34157">#34157</a>
<img src="https://github.com/user-attachments/assets/ef41fcc9-2c5f-4a75-ab1a-438f73d3d7e2" alt="image" /></li>
</ul>
<h3>TimmWrapper</h3>
<p>We add a <code>TimmWrapper</code> set of classes such that timm models can be loaded in as transformer models into the library.</p>
<p>Here's a general usage example:</p>
<pre lang="py"><code>import torch
from urllib.request import urlopen
from PIL import Image
from transformers import AutoConfig, AutoModelForImageClassification, AutoImageProcessor
<p>checkpoint = "timm/resnet50.a1_in1k"
img = Image.open(urlopen(
'<a href="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png">https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png</a>'
))</p>
<p>image_processor = AutoImageProcessor.from_pretrained(checkpoint)
</tr></table>
</code></pre></p>
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/commit/6bc0fbcfa7acb6ac4937e7456a76c2f7975fefec"><code>6bc0fbc</code></a> [WIP] Emu3: add model (<a href="https://redirect.github.com/huggingface/transformers/issues/33770">#33770</a>)</li>
<li><a href="https://github.com/huggingface/transformers/commit/59e28c30fa3a91213f569bccef73f082afa8c656"><code>59e28c3</code></a> Fix flex_attention in training mode (<a href="https://redirect.github.com/huggingface/transformers/issues/35605">#35605</a>)</li>
<li><a href="https://github.com/huggingface/transformers/commit/7cf6230e25078742b21907ae49d1542747606457"><code>7cf6230</code></a> push a fix for now</li>
<li><a href="https://github.com/huggingface/transformers/commit/d6f446ffa79811d35484d445bc5c7932e8a536d6"><code>d6f446f</code></a> when filtering we can't use the convert script as we removed them</li>
<li><a href="https://github.com/huggingface/transformers/commit/8ce1e9578af6151e4192d59c345e2ad86ee789d4"><code>8ce1e95</code></a> [test-all]</li>
<li><a href="https://github.com/huggingface/transformers/commit/af2d7caff393cf8881396b73d92d0595b6a3b2ae"><code>af2d7ca</code></a> Add Moonshine (<a href="https://redirect.github.com/huggingface/transformers/issues/34784">#34784</a>)</li>
<li><a href="https://github.com/huggingface/transformers/commit/42b8e7916b6b6dff5cb77252286db1aa07b7b41e"><code>42b8e79</code></a> ModernBert: reuse GemmaRotaryEmbedding via modular + Integration tests (<a href="https://redirect.github.com/huggingface/transformers/issues/35459">#35459</a>)</li>
<li><a href="https://github.com/huggingface/transformers/commit/e39c9f7a78fa2960a7045e8fc5a2d96b5d7eebf1"><code>e39c9f7</code></a> v4.48-release</li>
<li><a href="https://github.com/huggingface/transformers/commit/8de7b1ba8d126a6fc9f9bcc3173a71b46f0c3601"><code>8de7b1b</code></a> Add flex_attn to diffllama (<a href="https://redirect.github.com/huggingface/transformers/issues/35601">#35601</a>)</li>
<li><a href="https://github.com/huggingface/transformers/commit/1e3ddcb2d0380d0d909a44edc217dff68956ec5e"><code>1e3ddcb</code></a> ModernBERT bug fixes (<a href="https://redirect.github.com/huggingface/transformers/issues/35404">#35404</a>)</li>
<li>Additional commits viewable in <a href="https://github.com/huggingface/transformers/compare/v4.38.0...v4.48.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/huggingface/transformers/network/alerts).
</details> | [
27,
60
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"dependencies",
"python"
] |
https://api.github.com/repos/huggingface/transformers/issues/34446 |
TITLE
Beit image classification have different results compared from versions prior to 4.43.0
COMMENTS
10
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.43.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.10.9
- Huggingface_hub version: 0.26.1
- Safetensors version: 0.4.5
- Accelerate version: 0.23.0
- Accelerate config: not found
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: No
- Using GPU in script?: Yes
- GPU type: NVIDIA GeForce RTX 3060 Ti
### Who can help?
@amyeroberts
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Given the following image:

Running the following pipeline for versions prior to `4.43.0` (4.42.4)
```py
from PIL import Image
from transformers import pipeline
import transformers
pipeline_aesthetic = pipeline(
"image-classification", "cafeai/cafe_aesthetic", device=0
)
with Image.open("F:\\Downloads\\Tower.jpg") as img:
predictions = pipeline_aesthetic(img, top_k=2)
predict_keyed = {}
for p in predictions:
# print(type(p))
if not isinstance(p, dict):
raise Exception("Prediction value is missing?")
predict_keyed[p["label"]] = p["score"]
print(predict_keyed,transformers.__version__)
```
For 4.42.4, it returns:
```
{'aesthetic': 0.651885986328125, 'not_aesthetic': 0.3481140434741974} 4.42.4
```
For 4.43.0:
```
{'aesthetic': 0.43069663643836975, 'not_aesthetic': 0.2877475321292877} 4.43.0
```
### Expected behavior
Expected results from 4.42.4 instead of 4.43.0.
### Addn Notes.
I narrowed it down to this commit being the cause: https://github.com/huggingface/transformers/blob/06fd7972acbc6a5e9cd75b4d482583c060ac2ed0/src/transformers/models/beit/modeling_beit.py but unsure where exactly it is changed. | [
64,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug",
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/35664 |
TITLE
RLE of SAM can't handle masks with no change
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.49.0.dev0
- Platform: Windows-10-10.0.26100-SP0
- Python version: 3.11.11
- Huggingface_hub version: 0.27.1
- Safetensors version: 0.5.2
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I'm fine-tuning the SamModel and using the fine-tuned model in a mask-generation pipeline afterward.
After some time in the training, I suddenly get the following error when using the fine-tuned model in the pipeline:
```
Traceback (most recent call last):
File "***.py", line 17, in <module>
outputs = generator(image)
^^^^^^^^^^^^^^^^
File "transformers\pipelines\mask_generation.py", line 166, in __call__
return super().__call__(image, *args, num_workers=num_workers, batch_size=batch_size, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "transformers\pipelines\base.py", line 1354, in __call__
return next(
^^^^^
File "transformers\pipelines\pt_utils.py", line 124, in __next__
item = next(self.iterator)
^^^^^^^^^^^^^^^^^^^
File "transformers\pipelines\pt_utils.py", line 269, in __next__
processed = self.infer(next(self.iterator), **self.params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "transformers\pipelines\base.py", line 1269, in forward
model_outputs = self._forward(model_inputs, **forward_params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "transformers\pipelines\mask_generation.py", line 237, in _forward
masks, iou_scores, boxes = self.image_processor.filter_masks(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "transformers\models\sam\image_processing_sam.py", line 847, in filter_masks
return self._filter_masks_pt(
^^^^^^^^^^^^^^^^^^^^^^
File "transformers\models\sam\image_processing_sam.py", line 945, in _filter_masks_pt
masks = _mask_to_rle_pytorch(masks)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "transformers\models\sam\image_processing_sam.py", line 1386, in _mask_to_rle_pytorch
counts += [cur_idxs[0].item()] + btw_idxs.tolist() + [height * width - cur_idxs[-1]]
~~~~~~~~^^^
IndexError: index 0 is out of bounds for dimension 0 with size 0
```
Note: this error doesn't occur on every image, but just on some.
Code used to produce error:
```
image = Image.open("PATH_TO_MY_IMAGE")
model = SamModel.from_pretrained("PATH_TO_MY_CHECKPOINT")
processor = SamImageProcessor.from_pretrained("facebook/sam-vit-huge")
generator = pipeline(
"mask-generation",
model=model,
device="cpu",
points_per_batch=64,
image_processor=processor
) # MaskGenerationPipeline
outputs = generator(image)
```
### Expected behavior
No error should be thrown and the RLE should be computed correctly. | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/36068 |
TITLE
cannot import name 'is_timm_config_dict' from 'transformers.utils.generic'
COMMENTS
16
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
Transformers version 4.48.2
platform kaggle L4*4 or P40
timm version 1.0.12 or1.0.14 or None
Python version 3.10.12 (main, Nov 6 2024, 20:22:13) [GCC 11.4.0]
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from vllm.platforms import current_platform
then get
```
ImportError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/transformers/utils/import_utils.py in _get_module(self, module_name)
1792 missing_backends = self._object_missing_backend[name]
-> 1793
1794 class Placeholder(metaclass=DummyObject):
/usr/lib/python3.10/importlib/__init__.py in import_module(name, package)
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
127
/usr/lib/python3.10/importlib/_bootstrap.py in _gcd_import(name, package, level)
/usr/lib/python3.10/importlib/_bootstrap.py in _find_and_load(name, import_)
/usr/lib/python3.10/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
/usr/lib/python3.10/importlib/_bootstrap.py in _load_unlocked(spec)
/usr/lib/python3.10/importlib/_bootstrap_external.py in exec_module(self, module)
/usr/lib/python3.10/importlib/_bootstrap.py in _call_with_frames_removed(f, *args, **kwds)
/usr/local/lib/python3.10/dist-packages/transformers/configuration_utils.py in <module>
42 )
---> 43 from .utils.generic import is_timm_config_dict
44
ImportError: cannot import name 'is_timm_config_dict' from 'transformers.utils.generic' (/usr/local/lib/python3.10/dist-packages/transformers/utils/generic.py)
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
<ipython-input-13-46a92ab71489> in <cell line: 1>()
----> 1 from vllm.platforms import current_platform
2 device_name = current_platform.get_device_name().lower()
3 print(device_name)
/usr/local/lib/python3.10/dist-packages/vllm/__init__.py in <module>
4 import torch
5
----> 6 from vllm.engine.arg_utils import AsyncEngineArgs, EngineArgs
7 from vllm.engine.async_llm_engine import AsyncLLMEngine
8 from vllm.engine.llm_engine import LLMEngine
/usr/local/lib/python3.10/dist-packages/vllm/engine/arg_utils.py in <module>
9
10 import vllm.envs as envs
---> 11 from vllm.config import (CacheConfig, CompilationConfig, ConfigFormat,
12 DecodingConfig, DeviceConfig, HfOverrides,
13 KVTransferConfig, LoadConfig, LoadFormat, LoRAConfig,
/usr/local/lib/python3.10/dist-packages/vllm/config.py in <module>
15 import torch
16 from pydantic import BaseModel, Field, PrivateAttr
---> 17 from transformers import PretrainedConfig
18
19 import vllm.envs as envs
/usr/lib/python3.10/importlib/_bootstrap.py in _handle_fromlist(module, fromlist, import_, recursive)
/usr/local/lib/python3.10/dist-packages/transformers/utils/import_utils.py in __getattr__(self, name)
1779 def __dir__(self):
1780 result = super().__dir__()
-> 1781 # The elements of self.__all__ that are submodules may or may not be in the dir already, depending on whether
1782 # they have been accessed or not. So we only add the elements of self.__all__ that are not already in the dir.
1783 for attr in self.__all__:
/usr/local/lib/python3.10/dist-packages/transformers/utils/import_utils.py in _get_module(self, module_name)
1793
1794 class Placeholder(metaclass=DummyObject):
-> 1795 _backends = missing_backends
1796
1797 def __init__(self, *args, **kwargs):
RuntimeError: Failed to import transformers.configuration_utils because of the following error (look up to see its traceback):
cannot import name 'is_timm_config_dict' from 'transformers.utils.generic' (/usr/local/lib/python3.10/dist-packages/transformers/utils/generic.py)
```
### Expected behavior
No error
@zucchini-nlp | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34690 |
TITLE
Changes required to `save_model` for certain models (e.g., Phi 3.5 Vision)
COMMENTS
4
REACTIONS
+1: 1
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Feature request
This request proposes one of three changes (see **Motivation** for background, and **Your contribution** more thoughts on possible solutions) in order to allow saving of a certain class of models, including but not limited to Phi 3.5 Vision.
1. Accept a `state_dict` argument in the `Trainer` class's `save_model()` method (https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L3719-L3768). This `state_dict` parameter should then be passed down to the call to the private `_save()` method (https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L3842), which _does_ accept a `state_dict` argument.
2. Rather than`state_dict` as an argument to `save_model()`, determine the appropriate heuristic such that we can successfully save Phi 3.5 Vision and other architecturally similar models.
3. Some change to the way `transformers` handles shared tensors...?
### Motivation
I encountered an issue while trying to fine-tune Phi 3.5 Vision using the `Trainer` class from `transformers`. In particular, when trying to call `save()` or `save_pretrained()`, transformers throws the following error:
```
RuntimeError: The weights trying to be saved contained shared tensors [{'model.vision_embed_tokens.wte.weight',
'model.embed_tokens.weight'}] that are mismatching the transformers base configuration.
Try saving using `safe_serialization=False` or remove this tensor sharing.
```
Below are two minimal reproducible examples:
_Example #1_
```
from transformers import AutoModelForCausalLM
model_id = "microsoft/Phi-3.5-vision-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="cuda", trust_remote_code=True, torch_dtype="auto"
)
model.save_pretrained("out")
```
_Example #2_
```
from transformers import (
Trainer,
TrainingArguments,
)
training_args = TrainingArguments(
save_only_model=True,
output_dir='./out/',
save_strategy='no',
)
trainer = Trainer(
model=model,
args=training_args
)
trainer.save_model()
```
It looks like others have also encountered this issue. See the list of reference issues below in "Issues".
A contributor to the Phi 3 Vision cookbook suggested the following solution, stating "You need to remove the wte weight. It's okay because when the model is loaded from the checkpoint, it will automatically copy the weight from the embedding weight."
```
state_dict = model.state_dict()
state_dict = {k:v for k, v in state_dict.items() if "wte" not in k}
model.save_pretrained(args.save_model_path, state_dict=state_dict, safe_serialization=True)
processor.save_pretrained(args.save_model_path)
```
This does indeed seem to work. However, it doesn't exactly fit into a use case that relies on the `Trainer` abstraction. The call to the `Trainer` class's `save_model()` method doesn't accommodate a state_dict argument (see https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L3719-L3768).
**Issues**
1. https://github.com/kazuar/Phi3-Vision-ft/issues/2
2. https://discuss.huggingface.co/t/runtimeerror-when-saving-phi-3-5-vision-due-to-shared-tensors/116457
4. https://github.com/huggingface/transformers/issues/32354
5. https://discuss.huggingface.co/t/using-trainer-to-save-a-bartforsequenceclassification-model/81606
### Your contribution
I'd be glad to submit a PR, but I think some discussion is needed from the appropriate `transformers` stakeholders.
It's not clear to me whether the most appropriate change here is to modify the function signature.
Alternatively, maybe there's a heuristic by which we could determine whether the architecture is such that one needs to save everything but the `wte` weights. I don't know the answer to that off-hand. It may require a deep dive from Phi 3/3.5 Vision SMEs.
Or more broadly, perhaps there's some change to the way `transformers` handles shared tensors in the base configuration that would be most appropriate. | [
66,
76,
4
] | [
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"trainer",
"Feature request",
"Safetensors"
] |
https://api.github.com/repos/huggingface/transformers/issues/33409 |
TITLE
Can’t train Mamba2 with FP16 (Mamba(/2)ForCausalLM)
COMMENTS
3
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
transformers.version=4.44.2
### Reproduction
1. Run script:
```
config = AutoConfig.from_pretrained('state-spaces/mamba-130m')
model = MambaForCausalLM(config)
model.to(device)
training_args = TrainingArguments(
output_dir=args.output_dir,
logging_dir='./logs',
gradient_accumulation_steps=1,
save_steps=50000,
max_steps=1000000,
eval_strategy="steps",
eval_steps=50000,
logging_strategy="epoch",
logging_steps=2000,
learning_rate=1e-4,
fp16=True,
dataloader_num_workers=4,
per_device_train_batch_size=512,
per_device_eval_batch_size=512,
lr_scheduler_type="constant_with_warmup",
weight_decay=0.1,
warmup_steps=2000,
)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_eval
)
trainer.train()
```
### Expected behavior
```
File "/users/PAS2581/kanaka/research/GrokkedTransformersarewang2024/trying_different_archs/mamba/main.py", line 575, in <module>
main()
File "/users/PAS2581/kanaka/research/GrokkedTransformersarewang2024/trying_different_archs/mamba/main.py", line 545, in main
trainer.train()
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 1938, in train
return inner_training_loop(
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 2356, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, grad_norm, model, trial, epoch, ignore_keys_for_eval)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 2804, in _maybe_log_save_evaluate
metrics = self._evaluate(trial, ignore_keys_for_eval)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 2761, in _evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 3666, in evaluate
output = eval_loop(
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 3857, in evaluation_loop
losses, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 4075, in prediction_step
loss, outputs = self.compute_loss(model, inputs, return_outputs=True)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/trainer.py", line 3363, in compute_loss
outputs = model(**inputs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/accelerate/utils/operations.py", line 819, in forward
return model_forward(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/accelerate/utils/operations.py", line 807, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 43, in decorate_autocast
return func(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/models/mamba/modeling_mamba.py", line 738, in forward
mamba_outputs = self.backbone(
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/models/mamba/modeling_mamba.py", line 610, in forward
hidden_states = mixer_block(hidden_states, cache_params=cache_params, cache_position=cache_position)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/models/mamba/modeling_mamba.py", line 354, in forward
hidden_states = self.mixer(hidden_states, cache_params=cache_params, cache_position=cache_position)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/models/mamba/modeling_mamba.py", line 310, in forward
return self.cuda_kernels_forward(hidden_states, cache_params, cache_position)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/models/mamba/modeling_mamba.py", line 178, in cuda_kernels_forward
cache_params.update_conv_state(self.layer_idx, conv_states, cache_position)
File "/users/PAS2581/kanaka/miniconda3/envs/grokk/lib/python3.10/site-packages/transformers/cache_utils.py", line 1644, in update_conv_state
conv_state[:, :, cache_position] = new_conv_state.to(conv_state.device)
RuntimeError: Index put requires the source and destination dtypes match, got Float for the destination and Half for the source.
``` | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/33536 |
TITLE
Documentation for HuBERT is Incomplete
COMMENTS
7
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.44.2
- Platform: Linux-4.18.0-477.27.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.11.9
- Huggingface_hub version: 0.23.4
- Safetensors version: 0.4.3
- Accelerate version: 0.32.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.2.1+cu121 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: Tesla V100-SXM2-32GB
### Who can help?
@ylacombe @muellerzr
There are two issues.
- One is with the missing information in the documentation regarding the parameters of the HuBERT model. The `init` function of `HubertConfig` has `pad_token_id=0, bos_token_id=1, eos_token_id=2` but the information about it missing from the docstring.
- This is concerning because if someone is following the ASR tutorial by Von Platen (https://huggingface.co/blog/fine-tune-wav2vec2-english), the token ids for padding, bos, and eos would not correspond to 0, 1, and 2, respectively.
- The other issue is a result of the mismatch between the padding token ids. In `HF trainer`, when the `compute_metric` is called during evaluation, it bundles the whole dataset together by padding `pred_ids` by a value of 0 to the length of the longest sample in the dataset. However, during the decoding, if the `token_id` doesn't correspond to 0, the decoding would carry one extra letter at the end of the transcription, which would correspond to the token with id 0, thereby generating an incorrect transcription and hence an incorrect CER/WER.
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This issue could be replicated by following Von Platen's tutorial on finetuning `wav2vec 2.0` but instead of `wav2vec 2.0`, use `hubert-base`. Please let me know if you require any further information.
### Expected behavior
There should be a clear mention about the default values of the special `token_ids`, in particular the `pad_token` and the potential issues downstream with any other value. And if the behaviour of `compute_metric` is not actually intended, taking an arbitrary value of `pad_token_id` could be considered to make the code token_id invariant. | [
74,
64,
43
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0
] | [
"Documentation",
"bug",
"Audio"
] |
https://api.github.com/repos/huggingface/transformers/issues/35559 |
TITLE
iframe
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
Test
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
<iframe
src="https://hkchengrex-mmaudio.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
### Expected behavior
Hello, what is the reason for the issue of the application not functioning in an iframe for some of the spaces? For example:
<iframe
src="https://hkchengrex-mmaudio.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
When we use this in a webpage, the application does not work. Is there a solution to run it inside the iframe? Since I can't use Web components because the Gradio library is not available in my region. Is there a way to run that application using an iframe? | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/35700 |
TITLE
Uniformize OwlViT and Owlv2 processors
COMMENTS
9
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
Adds uniformized processors following https://github.com/huggingface/transformers/issues/31911 for OwlViT and Owlv2.
Split from this PR #32841
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker
- vision models: @amyeroberts, @qubvel
- speech models: @ylacombe, @eustlb
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @zucchini-nlp (visual-language models) or @gante (all others)
- pipelines: @Rocketknight1
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerzr and @SunMarc
- chat templates: @Rocketknight1
Integrations:
- deepspeed: HF Trainer/Accelerate: @muellerzr
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc @MekkCyber
Documentation: @stevhliu
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
| [
73
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"run-slow"
] |
https://api.github.com/repos/huggingface/transformers/issues/36150 |
TITLE
SDPA `is_causal=False` has no effect due to `LlamaModel._prepare_4d_causal_attention_mask_with_cache_position`
COMMENTS
3
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 3
BODY
### System Info
- `transformers` version: 4.48.3
- Platform: Linux-5.15.0-130-generic-x86_64-with-glibc2.35
- Python version: 3.9.21
- Huggingface_hub version: 0.28.1
- Safetensors version: 0.5.2
- Accelerate version: 1.3.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.6.0+cu124 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA H100 80GB HBM3
### Who can help?
@ArthurZucker @Cyrilvallez
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Observe `is_causal=False` has no effect when using `attn_implementation="sdpa"` with an `attention_mask` with at least one `False` element:
```python
import torch
import transformers
device = torch.device("cuda:0")
input_ids = torch.tensor(
[
[
128000, 128006, 9125, 128007, 271, 34, 7747, 553, 279,
2768, 1495, 439, 1694, 5552, 311, 5557, 11, 17452,
11, 10034, 11, 477, 11759, 13, 128009, 128006, 882,
128007, 271, 791, 502, 77355, 3280, 690, 10536, 1022,
449, 264, 72097, 2489, 1990, 35812, 323, 64921, 13,
128009, 128006, 78191, 128007, 271, 42079, 128009, 128004, 128004,
128004, 128004
]
],
device=device,
)
attention_mask = torch.tensor(
[
[
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, True, False, False, False, False
]
],
device=device,
)
with device:
model = transformers.AutoModelForCausalLM.from_pretrained(
"/models/meta-llama/Llama-3.2-1B-Instruct", # https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct
attn_implementation="sdpa",
torch_dtype=torch.bfloat16,
)
causal_logits = model(input_ids, attention_mask=attention_mask, is_causal=True).logits
noncausal_logits = model(input_ids, attention_mask=attention_mask, is_causal=False).logits
torch.testing.assert_close(causal_logits, noncausal_logits) # shouldn't be true, otherwise what is_causal controlling?
```
Observe that mocking `LlamaModel._prepare_4d_causal_attention_mask_with_cache_position` with an implementation that just replicates the `attention_mask` also has no effect when using `is_causal=True`:
```python
from unittest import mock
def _prepare_4d_causal_attention_mask_with_cache_position(
attention_mask: torch.Tensor,
sequence_length: int,
target_length: int,
dtype: torch.dtype,
device: torch.device,
cache_position: torch.Tensor,
batch_size: int,
**kwargs,
):
min_dtype = torch.tensor(torch.finfo(dtype).min, dtype=dtype, device=attention_mask.device)
return ~attention_mask.view(batch_size, 1, 1, sequence_length).expand(batch_size, 1, sequence_length, sequence_length) * min_dtype
with mock.patch.object(model.model, "_prepare_4d_causal_attention_mask_with_cache_position", _prepare_4d_causal_attention_mask_with_cache_position):
sdpa_causal_logits = model(input_ids, attention_mask=attention_mask, is_causal=True).logits
hf_causal_logits = model(input_ids, attention_mask=attention_mask, is_causal=True).logits
torch.testing.assert_close(sdpa_causal_logits, hf_causal_logits) # shouldn't be true, otherwise what is _prepare_4d_causal_attention_mask_with_cache_position doing?
```
### Expected behavior
1. At the very least, `LlamaModel. _prepare_4d_causal_attention_mask_with_cache_position` should respect `is_causal=False`. Right now, it always returns a causal mask when using sdpa with sequence_length > 1 and an attention_mask with at least one False element.
2. It is not really clear to me why we aren't purely relying on SDPA's own `is_causal` parameter. My 2nd example demonstrates that the current implementation of `LlamaModel. _prepare_4d_causal_attention_mask_with_cache_position` definitely isn't always necessary... so when is it necessary? Or what parts are necessary? Looking at the equivalent implementation that PyTorch describes for [`scaled_dot_product_attention`](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html), it seems like we are replicating a bit of their handling of `attn_mask`. Also notably there are 4 separate CUDA allocations happening in the current implementation (`torch.full`, `torch.triu`, `torch.arange`, `Tensor.clone`) compared to my proposed 1. | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/35245 |
TITLE
Add Dinov2 with registers
COMMENTS
6
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
This PR is a continuance of #32905 by @NielsRogge.
When running pytest there were two errors:
ERROR examples/research_projects/codeparrot/scripts/tests/test_deduplicate.py
ERROR templates/adding_a_missing_tokenization_test/cookiecutter-template-{{cookiecutter.modelname}}/test_tokenization_{{cookiecutter.lowercase_modelname}}.py
I am not sure what the problem for these are. Any guidance would be appreciated.
**Relevant Reviewers**
@ArthurZucker | [
77,
62,
73
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
1,
0,
0,
0,
0
] | [
"New model",
"Vision",
"run-slow"
] |
https://api.github.com/repos/huggingface/transformers/issues/35022 |
TITLE
Only Fine-tune the embeddings of the added special tokens
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Feature request
Hi, I added some new special tokens to the LLMs (specifically I'm using Qwen2-VL) and then I only want to fine-tune the embedding layers of these added tokens while keeping all other parameters (and the embedding layers for other tokens) frozen. I wonder if there is a built-in way to do so instead of fine-tuning the whole embedding matrix?
### Motivation
If we want to maximumly retain the original capabilities of the model while adding new tokens for certain scenarios, this might be needed, especially when we don't have much data and do not want to alter the pretrained weights.
Another question: if we have a considerable amount of data, is it recommended to fine-tune the whole embedding matrix or only the embeddings for the added tokens?
### Your contribution
If it's a reasonable feature and not implemented yet, I'm happy to submit a PR. | [
76
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"Feature request"
] |
https://api.github.com/repos/huggingface/transformers/issues/35205 |
TITLE
run_mlm_flax on tpu v5-pods
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
Latest update of both transformers and jax
### Who can help?
@ArthurZucker I am trying to use the `run_mlm_flax.py` to train a Roberta model on a v5-256 pod. However, while a single v3-8 is capable of running with `per_device_batch_size=128`, the v5-256 are only able to run with` per_device_batch_size=2`. Any ideas?
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Using default code.
### Expected behavior
I would expect a v5-256 to run a lot faster here. | [
55,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Flax",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/33827 |
TITLE
bug in the token healing
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.45.1
- Platform: Windows-11-10.0.22631-SP0
- Python version: 3.12.5
- Huggingface_hub version: 0.24.6
- Safetensors version: 0.4.4
- Accelerate version: 0.34.2
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.0+cu124 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: no
- Using GPU in script?: yes
- GPU type: NVIDIA GeForce GTX 1660 Ti
### Who can help?
@ArthurZucker @gante
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am using the below script to generate outputs. I am using a custom trained GPT2 model.
```python
inputs = self.tokenizer(input, padding=True, return_tensors="pt").to(self.dev)
generated_ids = self.model.generate(
**inputs,
**get_variable_dictionary(args),
pad_token_id=self.tokenizer.eos_token_id,
renormalize_logits=True,
token_healing=True,
tokenizer=self.tokenizer,
)
```
Below code block is filling the **GenerationConfig** parameters:
```python
**get_variable_dictionary(args)
```
The script is run without issues when ```token_healing``` is disabled. When ```token_healing``` is enabled, this error is occured:
```bash
!!! Exception during processing !!! 'ExtensionsTrie' object has no attribute 'values'
Traceback (most recent call last):
File "D:\sd\ComfyUI\execution.py", line 323, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\sd\ComfyUI\execution.py", line 198, in get_output_data
return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\sd\ComfyUI\custom_nodes\prompt-generator-comfyui\generator\generate.py", line 102, in generate_multiple_texts
generated_ids = self.model.generate(
^^^^^^^^^^^^^^^^^^^^
File "D:\sd\ComfyUI\venv\Lib\site-packages\torch\utils\_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\sd\ComfyUI\venv\Lib\site-packages\transformers\generation\utils.py", line 1882, in generate
input_ids = self.heal_tokens(input_ids, tokenizer)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\sd\ComfyUI\venv\Lib\site-packages\transformers\generation\utils.py", line 2295, in heal_tokens
seq_bias = {(alt_tok,): 10.0 for alt_tok in vocab_trie.values(prefix=tail_tok)}
^^^^^^^^^^^^^^^^^
AttributeError: 'ExtensionsTrie' object has no attribute 'values'
```
I did some changes to the code in [src/transformers/generation/utils.py](https://github.com/huggingface/transformers/blob/main/src/transformers/generation/utils.py#L2295) file at line 2295 and it is working after the below updates:
```python
seq_bias = {(tokenizer.convert_tokens_to_ids(alt_tok),): 10.0 for alt_tok in vocab_trie.extensions(prefix=tail_tok)}
```
As I understand from the exceptions; ```sequence_bias``` need the keys to be integer tuple values, but the older version is given the string tuple as the key. And **ExtensionsTrie** doesn't have values function but have extensions function.
I can't be sure if the error is a general one because I saw that there are already tests for ```token_healing``` and it passed those tests.
### Expected behavior
When using ```token_healing``` variable, the program has to be not terminated with error. | [
64,
18
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug",
"Generation"
] |
https://api.github.com/repos/huggingface/transformers/issues/34613 |
TITLE
redirect logging output to `stdout` instead of `stderr`
COMMENTS
3
REACTIONS
+1: 2
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Feature request
Redirect logging output to `stdout` instead of `stderr`. Specifically, add argument `stream=sys.stdout` at: https://github.com/huggingface/transformers/blob/893ad04fad145904ccb71e4e858e4134c32226b6/src/transformers/utils/logging.py#L88.
### Motivation
It is a common practice to redirect logging output to `stdout` in deep learning frameworks.
For example: Detectron2: https://github.com/facebookresearch/detectron2/blob/8d85329aed8506ea3672e3e208971345973ea761/detectron2/utils/logger.py#L84
fairseq: https://github.com/facebookresearch/fairseq/blob/ecbf110e1eb43861214b05fa001eff584954f65a/fairseq_cli/train.py#L22
Deepspeed: https://github.com/microsoft/DeepSpeed/blob/2b41d6212c160a3645691b77b210ba7dd957c23f/deepspeed/utils/logging.py#L69.
Here is my analysis. Traditionally, `stdout` is used for output of the program and `stderr` is used for warning/debugging. That's why the default stream of `logging` is `stderr`. However, the output of deep learning frameworks consists of losses, eval results and checkpoints. It's a common practice to use `logger.info()` to display this information. Therefore, it would be more appropriate to redirect these outputs to `stdout` since they are part of the program's normal output.
### Your contribution
I can submit a PR if this request is confirmed. | [
76
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"Feature request"
] |
https://api.github.com/repos/huggingface/transformers/issues/35276 |
TITLE
inconsistent generation
COMMENTS
3
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.45.2
- Python version: 3.8.18
- Huggingface_hub version: 0.26.3
- Safetensors version: 0.4.1
- Accelerate version: 0.32.1
- PyTorch version (GPU?): 2.1.0+cu121 (True)
- GPU type: NVIDIA A10
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
I used the same input, but changed the code logic slightly, resulting in different results
here is the context of code(mainly load model)
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, DynamicCache
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_path = "meta-llama/Meta-Llama-3-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path, attn_implementation="flash_attention_2", device_map=device).eval()
tokenizer = AutoTokenizer.from_pretrained(model_path)
encoded_input = tokenizer("what is your name", return_tensors='pt').to(device)
window_size = 1
front_input = {key: value[:, :-window_size] for key, value in encoded_input.items()}
rear_input = {key: value[:, -window_size:] for key, value in encoded_input.items()}
```
and here is the first generation code
```
past_key_values = DynamicCache()
generation = model.generate(**encoded_input, past_key_values=past_key_values, max_new_tokens=32, do_sample=False)
generation = tokenizer.batch_decode(generation)[0]
print(generation)
```
the generation is as below:
```
what is your name?" and "what is your occupation?" are not necessary. The form is designed to be as simple and easy to fill out as possible, while still gathering the
```
and the seconde generation code is:
```
past_key_values = DynamicCache()
with torch.no_grad():
_ = model(**front_input, past_key_values=past_key_values, use_cache=True)
generation = model.generate(**encoded_input, past_key_values=past_key_values, max_new_tokens=32, do_sample=False)
generation = tokenizer.batch_decode(generation)[0]
```
the generation is as below:
```
what is your name?" and "what is your occupation?" are not necessary. The form is designed to be as simple and easy to fill out as possible, so that you can
```
### Expected behavior
well, it's weird, I think these two generation process is the same since I do not use sampling, but why the results are different. Is there anything wrong with my operation? | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34059 |
TITLE
data load speed is quite slow when dataloader_num_workers=0
COMMENTS
5
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.45.2
- Platform: Linux-6.9.10-amd64-x86_64-with-glibc2.39
- Python version: 3.11.9
- Huggingface_hub version: 0.24.5
- Safetensors version: 0.4.4
- Accelerate version: 1.0.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: DEEPSPEED
- mixed_precision: bf16
- use_cpu: False
- debug: False
- num_processes: 8
- machine_rank: 0
- num_machines: 1
- rdzv_backend: static
- same_network: True
- main_training_function: main
- enable_cpu_affinity: False
- deepspeed_config: {'gradient_accumulation_steps': 1, 'offload_optimizer_device': 'none', 'offload_param_device': 'none', 'zero3_init_flag': False, 'zero3_save_16bit_model': False, 'zero_stage': 3}
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
- PyTorch version (GPU?): 2.4.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA RTX A6000
### Who can help?
@muellerzr @SunMarc
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
My dataset:
```
import torch
import os
import json
from utils.video import read_frames_decord
from torchvision.transforms import Compose, Resize, CenterCrop, RandomResizedCrop, RandomHorizontalFlip, ToTensor, Normalize
from PIL import Image
class DatasetForOfflineDistill(torch.utils.data.Dataset):
def __init__(
self,
anno_path: str | os.PathLike,
data_root: str | os.PathLike,
feat_path: str | os.PathLike,
tokenizer: torch.nn.Module | None = None,
tokenize: bool = False,
num_frames: int = 8,
test: bool = False
):
with open(anno_path) as f:
self.anno = json.load(f)
self.data_root = data_root
# keys of each item: idx, text_embeds, video_embeds
self.feat = torch.load(feat_path, weights_only=True)
self.num_frames = num_frames
self.transforms = self.build_transforms(test)
self.tokenizer = tokenizer
self.tokenize = tokenize
def build_transforms(self, test: bool):
image_mean = [
0.48145466,
0.4578275,
0.40821073
]
image_std = [
0.26862954,
0.26130258,
0.27577711
]
size = 224
normalize = (
Normalize(mean=image_mean, std=image_std)
)
train_transforms = Compose(
[
RandomResizedCrop(size),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)
val_transforms = Compose(
[
Resize(size),
CenterCrop(size),
ToTensor(),
normalize,
]
)
if test:
return val_transforms
return train_transforms
def __len__(self):
return len(self.anno)
def __getitem__(self, idx):
rank = int(os.environ.get("LOCAL_RANK") or 0)
# HERE IS THE DEBUG MESSAGE
now = datetime.now()
dt_string = now.strftime("%d/%m/%Y %H:%M:%S")
print(f'[{dt_string}] Rank {rank} is loading', idx)
item = self.feat[idx]
anno_idx = item['idx']
# [teacher_dim] -> [1, teacher_dim]
text_embeds = item['text_embeds']
video_embeds = item['video_embeds']
caption = self.anno[anno_idx]['caption']
if self.tokenizer is not None and self.tokenize:
tokenized_caption = self.tokenizer(caption)
caption = {
'input_ids': tokenized_caption['input_ids'],
'attention_mask': tokenized_caption['attention_mask'],
}
video_path = os.path.join(self.data_root, self.anno[anno_idx]['video'])
video = read_frames_decord(video_path, num_frames=self.num_frames).numpy()
frames = [self.transforms(Image.fromarray(frame)) for frame in video]
frames = torch.stack(frames)
return {
'caption': caption,
'video': frames,
'text_embeds': text_embeds,
'video_embeds': video_embeds
}
```
Part of my training script:
```
train_data = DatasetForOfflineDistill(
anno_path=data_config['anno_path'],
data_root=data_config['data_root'],
feat_path=data_config['feat_paths'][teacher_type],
tokenize=False,
num_frames=num_frames,
)
def custom_collate_fn(batch):
# batch is a list of dicts
collated_batch = {}
for key in batch[0].keys():
collated_batch[key] = [b[key] for b in batch]
# collated_batch['video'] is a list of [num_frames, 3, 224, 224]
# collated_batch['caption'] is a list of strings
tokenized_caption = model.student_caller.tokenizer(collated_batch['caption'], padding=True, return_tensors="pt")
collated_batch['input_ids'] = tokenized_caption['input_ids']
collated_batch['attention_mask'] = tokenized_caption['attention_mask']
collated_batch['pixel_values'] = torch.stack(collated_batch['video'])
collated_batch['video_embeds'] = torch.stack(collated_batch['video_embeds'])
collated_batch['text_embeds'] = torch.stack(collated_batch['text_embeds'])
return collated_batch
trainer = Trainer(
model=model,
train_dataset=train_data,
args=transformers.TrainingArguments(
per_device_train_batch_size=micro_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
warmup_ratio=warmup_ratio,
num_train_epochs=num_epochs,
learning_rate=learning_rate,
fp16=True if not bf16 else False,
bf16=bf16,
logging_steps=logging_steps,
save_strategy="steps",
eval_steps=None,
save_steps=save_steps,
output_dir=output_dir,
save_total_limit=1,
load_best_model_at_end=False,
ddp_find_unused_parameters=False if ddp else None,
run_name=run_name,
report_to=None,
deepspeed=deepspeed,
gradient_checkpointing=grad_checkpoint,
remove_unused_columns=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
# dataloader_prefetch_factor=10,
# dataloader_persistent_workers=True,
),
data_collator=custom_collate_fn,
)
```
The model is a simple CLIPModel.
If dataloader_num_workers=0 and dataloader_pin_memory=True, the load of cpu is around 1000 but the print speed of the debug message(see my code above) is about 1-2/sec. See the image below.
<img width="1010" alt="image" src="https://github.com/user-attachments/assets/6d433ae4-4620-4c2a-a0e7-e852e8e14883">
<img width="1979" alt="image" src="https://github.com/user-attachments/assets/08f68dad-0a6b-4363-a51f-e5d62a965fae">
If dataloader_num_workers=4, dataloader_pin_memory=True, dataloader_prefetch_factor=2 and dataloader_persistent_workers=True, the load of cpu is around 100 and the print speed of the debug message(see my code above) is above 20/sec.
<img width="1033" alt="image" src="https://github.com/user-attachments/assets/109540b0-d874-49a5-baa2-450eee5e5609">
<img width="1969" alt="image" src="https://github.com/user-attachments/assets/aa431e28-6237-40b7-9445-d9620bff8e27">
### Expected behavior
1. The speed should be the same whatever the setting. (at least dataloader_num_workers=0 is slower than dataloader_num_workers=4)
2. The dataloader should prefetch data to avoid gpu waiting. | [
66,
64,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"trainer",
"bug",
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/34033 |
TITLE
IDEFICS can't use inputs_embeds in generate function
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.45.2
- Platform: Linux-5.4.0-148-generic-x86_64-with-glibc2.31
- Python version: 3.10.13
- Huggingface_hub version: 0.23.3
- Safetensors version: 0.4.2
- Accelerate version: 0.27.2
- Accelerate config: not found
- PyTorch version (GPU?): 2.2.1+cu121 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: parallel
- Using GPU in script?: yes
- GPU type: NVIDIA RTX A6000
when I use inputs_embeds instead of input_ids, the idefics model's generate function return a error:
"""
You passed `inputs_embeds` to `.generate()`, but the model class IdeficsForVisionText2Text doesn't have its forwarding implemented. See the GPT2 implementation for an example ([Generate: decoder-only models can generate with `inputs_embeds` by gante · Pull Request #21405 · hug](https://github.com/huggingface/transformers/pull/21405)), and feel free to open a PR with it!
"""
However, In IdeficsForVisionText2Text's defintation, I find the forward already have the inputs_embeds enabled. The following function is defined at line 1541 of the code:
```python
class IdeficsForVisionText2Text(IdeficsPreTrainedModel):
_keys_to_ignore_on_load_missing = [r"lm_head.weight"]
_tied_weights_keys = ["model.embed_tokens.weight", "lm_head.weight"]
def __init__(self, config, vision_model=None):
super().__init__(config)
self.model = IdeficsModel(config)
self.lm_head = IdeficsDecoupledLinear(
in_features=config.hidden_size,
out_features=config.vocab_size,
out_additional_features=config.additional_vocab_size,
bias=False,
partially_freeze=config.freeze_lm_head,
)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.model.embed_tokens
def set_input_embeddings(self, value):
self.model.embed_tokens = value
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
def set_decoder(self, decoder):
self.model = decoder
def get_decoder(self):
return self.model
def tie_weights(self):
"""
Overwrite `transformers.modeling_utils.PreTrainedModel.tie_weights` to handle the case of
IdeficsDecoupledLinear and IdeficsDecoupledEmbedding.
"""
output_embeddings = self.get_output_embeddings()
input_embeddings = self.get_input_embeddings()
if getattr(self.config, "tie_word_embeddings", True):
output_embeddings.weight = input_embeddings.weight
if input_embeddings.num_additional_embeddings > 0:
assert output_embeddings.out_additional_features == input_embeddings.num_additional_embeddings
output_embeddings.additional_fc.weight = input_embeddings.additional_embedding.weight
if hasattr(output_embeddings, "out_features") and hasattr(input_embeddings, "num_embeddings"):
output_embeddings.out_features = input_embeddings.num_embeddings
if hasattr(output_embeddings, "out_additional_features") and hasattr(
input_embeddings, "num_additional_embeddings"
):
output_embeddings.out_additional_features = input_embeddings.num_additional_embeddings
@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=IdeficsCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
image_encoder_embeddings: Optional[torch.FloatTensor] = None,
perceiver_embeddings: Optional[torch.FloatTensor] = None,
image_attention_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
interpolate_pos_encoding: Optional[bool] = False,
return_dict: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
) -> Union[Tuple, IdeficsCausalLMOutputWithPast]:
```
So why can't this code just use generate to generate it, I'd be very grateful if solve this problem 🙏
### Who can help?
@zucchini-nlp @patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda:1" if torch.cuda.is_available() else "cpu"
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"In this picture from Asterix and Obelix, we can see"
],
]
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics-9b")
# --batched mode
inputs = processor(prompts, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
inputs_embeds = interface.model.model.embed_tokens(inputs["input_ids"])
inputs["input_ids"] = None
generated_ids = interface.generate(inputs_embeds = inputs_embeds, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
```
### Expected behavior
It shouldn't crash | [
64,
62,
18
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug",
"Vision",
"Generation"
] |
https://api.github.com/repos/huggingface/transformers/issues/33342 |
TITLE
Add "EAT: Self-Supervised Pre-Training with Efficient Audio Transformer"
COMMENTS
0
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Model description
The original authors of the model write:
> EAT is an audio self-supervised learning model with high effectiveness and efficiency during self-supervised pre-training. You can find details in the paper [EAT: Self-Supervised Pre-Training with Efficient Audio Transformer](https://arxiv.org/abs/2401.03497).
A self-supervised learning model can benefit the community greatly, since it requires no labelled data, and can be trained on any dataset. Especially since, the strength of this approach is that it can be applied to variable-length audio. With enough resources (for example, compute, and, data), it could have a similar reach as BERT.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
- GitHub Repo: https://github.com/cwx-worst-one/EAT
- Links for model checkpoints:
- [EAT-base_epoch30](https://drive.google.com/file/d/19hfzLgHCkyqTOYmHt8dqVa9nm-weBq4f/view?usp=sharing) (pre-training)
- [EAT-base_epoch30](https://drive.google.com/file/d/1aCYiQmoZv_Gh1FxnR-CCWpNAp6DIJzn6/view?usp=sharing) (fine-tuning on AS-2M)
- [EAT-large_epoch20](https://drive.google.com/file/d/1PEgriRvHsqrtLzlA478VemX7Q0ZGl889/view?usp=sharing) (pre-training)
- [EAT-large_epoch20](https://drive.google.com/file/d/1b_f_nQAdjM1B6u72OFUtFiUu-4yM2shd/view?usp=sharing) (fine-tuning on AS-2M)
- Paper: https://www.ijcai.org/proceedings/2024/421 | [
77,
76
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
1,
0,
0,
0,
0
] | [
"New model",
"Feature request"
] |
https://api.github.com/repos/huggingface/transformers/issues/33661 |
TITLE
Undefined variable in: scripts/check_tokenizers.py
COMMENTS
9
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
Python 3.12.4
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
`if check_diff(spm_ids[first : first + i], tok_ids[first : first + j], sp, tok) and check_details(
line,
spm_ids[first + i : last],
tok_ids[first + j : last],
slow,
fast,`
### Expected behavior
Undefined Variables: sp and tok are not defined anywhere within the check_details function or its enclosing scopes. This will result in a NameError when the code attempts to execute this line. | [
47,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Core: Tokenization",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34600 |
TITLE
AssertionError for Pytorch PiPPy example
COMMENTS
3
REACTIONS
+1: 1
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
```
(zt) root@autodl-container-7071118252-7032359d:~/test/PiPPy/examples/llama# transformers-cli env
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.44.0
- Platform: Linux-5.4.0-126-generic-x86_64-with-glibc2.35
- Python version: 3.10.0
- Huggingface_hub version: 0.26.2
- Safetensors version: 0.4.5
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1+cu124 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA GeForce RTX 3090
```
### Who can help?
pipelines: @Rocketknight1
Big Model Inference: @SunMarc
Hi! I am MD students who interested in pipeline parallelism in LLM inference. I have successfully run a[ llama2 example](https://github.com/pytorch/PiPPy/blob/main/examples/llama/pippy_llama.py) in [PiPPy repo](https://github.com/pytorch/PiPPy). So I want to further modify this code to support Llama3 series models/, especially for **Llama-3.2-3B**. But when I run this code just simple modfy the path of model and tokenizer. But It turned out bug:
```
(zt) root@autodl-container-7071118252-7032359d:~/test/PiPPy/examples/llama# torchrun --nproc-per-node 2 pippy_llama.py
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.09s/it]
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 3072)
(layers): ModuleList(
(0-27): 28 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=3072, bias=False)
(k_proj): Linear(in_features=3072, out_features=1024, bias=False)
(v_proj): Linear(in_features=3072, out_features=1024, bias=False)
(o_proj): Linear(in_features=3072, out_features=3072, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=3072, out_features=8192, bias=False)
(up_proj): Linear(in_features=3072, out_features=8192, bias=False)
(down_proj): Linear(in_features=8192, out_features=3072, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((3072,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((3072,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((3072,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=3072, out_features=128256, bias=False)
)
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.15s/it]
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 3072)
(layers): ModuleList(
(0-27): 28 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=3072, bias=False)
(k_proj): Linear(in_features=3072, out_features=1024, bias=False)
(v_proj): Linear(in_features=3072, out_features=1024, bias=False)
(o_proj): Linear(in_features=3072, out_features=3072, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=3072, out_features=8192, bias=False)
(up_proj): Linear(in_features=3072, out_features=8192, bias=False)
(down_proj): Linear(in_features=8192, out_features=3072, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((3072,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((3072,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((3072,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=3072, out_features=128256, bias=False)
)
layers_per_rank = 14
layers_per_rank = 14
[rank0]: Traceback (most recent call last):
[rank0]: File "/root/test/PiPPy/examples/llama/pippy_llama.py", line 36, in <module>
[rank0]: pipe = pipeline(llama, mb_args=(mb_inputs["input_ids"],))
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_IR.py", line 1238, in pipeline
[rank0]: return Pipe.from_tracing(
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_IR.py", line 1051, in from_tracing
[rank0]: pipe = Pipe._from_traced(
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_IR.py", line 750, in _from_traced
[rank0]: new_submod = _outline_submodules(submodule.graph)
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_unflatten.py", line 24, in _outline_submodules
[rank0]: ).run_outer()
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1014, in run_outer
[rank0]: self.run_from(node_idx)
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1094, in run_from
[rank0]: ).run_from(node_idx)
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1094, in run_from
[rank0]: ).run_from(node_idx)
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1043, in run_from
[rank0]: self.finalize_outputs()
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 993, in finalize_outputs
[rank0]: _verify_graph_equivalence(self.cached_graph_module, self.module)
[rank0]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 655, in _verify_graph_equivalence
[rank0]: assert graph_dump(x.graph) == graph_dump(y.graph)
[rank0]: AssertionError
[rank0]:[W1104 21:21:40.765172753 ProcessGroupNCCL.cpp:1250] Warning: WARNING: process group has NOT been destroyed before we destruct ProcessGroupNCCL. On normal program exit, the application should call destroy_process_group to ensure that any pending NCCL operations have finished in this process. In rare cases this process can exit before this point and block the progress of another member of the process group. This constraint has always been present, but this warning has only been added since PyTorch 2.4 (function operator())
[rank1]: Traceback (most recent call last):
[rank1]: File "/root/test/PiPPy/examples/llama/pippy_llama.py", line 36, in <module>
[rank1]: pipe = pipeline(llama, mb_args=(mb_inputs["input_ids"],))
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_IR.py", line 1238, in pipeline
[rank1]: return Pipe.from_tracing(
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_IR.py", line 1051, in from_tracing
[rank1]: pipe = Pipe._from_traced(
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_IR.py", line 750, in _from_traced
[rank1]: new_submod = _outline_submodules(submodule.graph)
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/pipelining/_unflatten.py", line 24, in _outline_submodules
[rank1]: ).run_outer()
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1014, in run_outer
[rank1]: self.run_from(node_idx)
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1094, in run_from
[rank1]: ).run_from(node_idx)
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1094, in run_from
[rank1]: ).run_from(node_idx)
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 1043, in run_from
[rank1]: self.finalize_outputs()
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 993, in finalize_outputs
[rank1]: _verify_graph_equivalence(self.cached_graph_module, self.module)
[rank1]: File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/export/unflatten.py", line 655, in _verify_graph_equivalence
[rank1]: assert graph_dump(x.graph) == graph_dump(y.graph)
[rank1]: AssertionError
W1104 21:21:41.688867 2513 site-packages/torch/distributed/elastic/multiprocessing/api.py:897] Sending process 2540 closing signal SIGTERM
E1104 21:21:42.054025 2513 site-packages/torch/distributed/elastic/multiprocessing/api.py:869] failed (exitcode: 1) local_rank: 0 (pid: 2539) of binary: /root/miniconda3/envs/zt/bin/python
Traceback (most recent call last):
File "/root/miniconda3/envs/zt/bin/torchrun", line 8, in <module>
sys.exit(main())
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 355, in wrapper
return f(*args, **kwargs)
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/run.py", line 919, in main
run(args)
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/run.py", line 910, in run
elastic_launch(
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 138, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 269, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
pippy_llama.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2024-11-04_21:21:41
host : autodl-container-7071118252-7032359d
rank : 0 (local_rank: 0)
exitcode : 1 (pid: 2539)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
```
That's a same problem when I run this example for Llama2 model, but I fix it by degrading the version of transformers to **4.36.2**. But when I use this solution for Llama3, it seems that the dependency isn't support the newest Llama model.
```
zt) root@autodl-container-7071118252-7032359d:~/test/PiPPy/examples/llama# torchrun --nproc-per-node 2 pippy_llama.py
Traceback (most recent call last):
File "/root/test/PiPPy/examples/llama/pippy_llama.py", line 8, in <module>
llama = AutoModelForCausalLM.from_pretrained(
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 526, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/transformers/models/auto/configuration_auto.py", line 1124, in from_pretrained
return config_class.from_dict(config_dict, **unused_kwargs)
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/transformers/configuration_utils.py", line 764, in from_dict
config = cls(**config_dict)
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/transformers/models/llama/configuration_llama.py", line 160, in __init__
self._rope_scaling_validation()
File "/root/miniconda3/envs/zt/lib/python3.10/site-packages/transformers/models/llama/configuration_llama.py", line 180, in _rope_scaling_validation
raise ValueError(
ValueError: `rope_scaling` must be a dictionary with with two fields, `type` and `factor`, got {'factor': 32.0, 'high_freq_factor': 4.0, 'low_freq_factor': 1.0, 'original_max_position_embeddings': 8192, 'rope_type': 'llama3'}
```
So how can I fix it, I am not good at fixing this bug. :(
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1、git the repo and install the related dependency
```
git cllone https://github.com/pytorch/PiPPy.git
pip install -r requirements.txt
```
2、go the llama directoty and run` pippy_llama.py`
`torchrun --nproc-per-node 2 pippy_llama.py`
**Here is the code I modify**
```ruby
# $ torchrun --nproc-per-node 4 pippy_llama.py
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.distributed.pipelining import SplitPoint, pipeline, ScheduleGPipe
# Grab the model
llama = AutoModelForCausalLM.from_pretrained(
"/root/autodl-tmp/model/Llama-3.2-3B", local_files_only= True
)
print(llama)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/model/Llama-3.2-3B", local_files_only= True)
tokenizer.pad_token = tokenizer.eos_token
mb_prompts = (
"How do you", "I like to",
) # microbatch size = 2
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
device = torch.device(f"cuda:{rank % torch.cuda.device_count()}")
torch.distributed.init_process_group(rank=rank, world_size=world_size)
llama.to(device).eval()
# Cut model by equal number of layers per rank
layers_per_rank = llama.config.num_hidden_layers // world_size
print(f"layers_per_rank = {layers_per_rank}")
split_spec = {
f"model.layers.{i * layers_per_rank}": SplitPoint.BEGINNING
for i in range(1, world_size)
}
# Create a pipeline representation from the model
mb_inputs = tokenizer(mb_prompts, return_tensors="pt", padding=True).to(device)
pipe = pipeline(llama, mb_args=(mb_inputs["input_ids"],))
# Create pipeline stage for each rank
stage = pipe.build_stage(rank, device=device)
# Run time inputs
full_batch_prompts = (
"How do you", "I like to", "Can I help", "You need to",
"The weather is", "I found a", "What is your", "You are so",
) # full batch size = 8
inputs = tokenizer(full_batch_prompts, return_tensors="pt", padding=True).to(device)
# Attach to a schedule
# number of microbatches = 8 // 2 = 4
num_mbs = 4
schedule = ScheduleGPipe(stage, num_mbs)
# Run
if rank == 0:
args = inputs["input_ids"]
else:
args = None
output = schedule.step(args)
# Decode
if output is not None:
next_token_logits = output[0][:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1)
print(tokenizer.batch_decode(next_token))
```
### Expected behavior
just the output for one decoding iteration of LLM
```
Outputs:
['make', 'think', 'you', 'be', 'getting', 'great', 'favorite', 'right']
``` | [
16,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Pipeline Parallel",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/33518 |
TITLE
HQQ
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.44.2
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.10.11
- Huggingface_hub version: 0.24.7
- Safetensors version: 0.4.5
- Accelerate version: 0.34.2
- Accelerate config: not found
- PyTorch version (GPU?): 2.6.0.dev20240915+cu121 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA GeForce MX330
And:
python.exe -m pip install --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu124
python.exe -m pip install --upgrade transformers
python.exe -m pip install --upgrade git+https://github.com/mobiusml/hqq.git
python.exe -m pip install --upgrade huggingface_hub
### Who can help?
@SunMarc
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
# from https://huggingface.co/docs/transformers/v4.44.2/quantization/hqq
```
from transformers import AutoModelForCausalLM, AutoTokenizer, HqqConfig
# Method 1: all linear layers will use the same quantization config
quant_config = HqqConfig(nbits=8, group_size=64, quant_zero=False, quant_scale=False, axis=0) #axis=0 is used by default
model = transformers.AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quant_config
)
```
Error:
Traceback (most recent call last):
File "C:\Users\Admin\Desktop\hqq\hqq2.py", line 4, in <module>
quant_config = HqqConfig(nbits=8, group_size=64, quant_zero=False, quant_scale=False, axis=0) #axis=0 is used by default
File "C:\Users\Admin\Desktop\hqq\venv\lib\site-packages\transformers\utils\quantization_config.py", line 228, in __init__
from hqq.core.quantize import BaseQuantizeConfig as HQQBaseQuantizeConfig
File "C:\Users\Admin\Desktop\hqq\hqq.py", line 3, in <module>
from hqq.models.hf.base import AutoHQQHFModel
ModuleNotFoundError: No module named 'hqq.models'; 'hqq' is not a package
### Expected behavior
Quantized model. | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/35402 |
TITLE
AttributeError: 'SegformerFeatureExtractor' object has no attribute 'reduce_labels' still has no clear guide around
COMMENTS
4
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
Python 3.11.10, transformers 4.47.0
### Who can help?
@stevhliu
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Trying to train by using
`from transformers import AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")`
as feature extractor and keep getting `AttributeError: 'SegformerFeatureExtractor' object has no attribute 'reduce_labels' still has no clear guide around`
found [this](https://github.com/huggingface/transformers/issues/25801) that said to repair the docs but I still haven't found the solution to do it by reading links and docs surrounding the links. Is it still a feature or should I move to other feature extractor?
### Expected behavior
``AttributeError: 'SegformerFeatureExtractor' object has no attribute 'reduce_labels' ` solution should be
`feature_extractor = AutoFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512", do_reduce_labels=True)
`
according to the [link](https://github.com/huggingface/transformers/issues/25801), but the problem persists.
Edit2:
Complete error message since by the time I wrote this I already try running it again for another chance. Here's the complete error code
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[158], line 1
----> 1 trainer.train()
2 trainer.push_to_hub()
File c:\Users\Lenovo\miniconda3\envs\pretrain-huggingface\Lib\site-packages\transformers\trainer.py:2155, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
2152 try:
2153 # Disable progress bars when uploading models during checkpoints to avoid polluting stdout
2154 hf_hub_utils.disable_progress_bars()
-> 2155 return inner_training_loop(
2156 args=args,
2157 resume_from_checkpoint=resume_from_checkpoint,
2158 trial=trial,
2159 ignore_keys_for_eval=ignore_keys_for_eval,
2160 )
2161 finally:
2162 hf_hub_utils.enable_progress_bars()
File c:\Users\Lenovo\miniconda3\envs\pretrain-huggingface\Lib\site-packages\transformers\trainer.py:2589, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
2587 self.state.epoch = epoch + (step + 1 + steps_skipped) / steps_in_epoch
2588 self.control = self.callback_handler.on_step_end(args, self.state, self.control)
-> 2589 self._maybe_log_save_evaluate(
2590 tr_loss, grad_norm, model, trial, epoch, ignore_keys_for_eval, start_time
2591 )
2592 else:
2593 self.control = self.callback_handler.on_substep_end(args, self.state, self.control)
File c:\Users\Lenovo\miniconda3\envs\pretrain-huggingface\Lib\site-packages\transformers\trainer.py:3047, in Trainer._maybe_log_save_evaluate(self, tr_loss, grad_norm, model, trial, epoch, ignore_keys_for_eval, start_time)
3045 metrics = None
3046 if self.control.should_evaluate:
-> 3047 metrics = self._evaluate(trial, ignore_keys_for_eval)
3048 is_new_best_metric = self._determine_best_metric(metrics=metrics, trial=trial)
3050 if self.args.save_strategy == SaveStrategy.BEST:
File c:\Users\Lenovo\miniconda3\envs\pretrain-huggingface\Lib\site-packages\transformers\trainer.py:3001, in Trainer._evaluate(self, trial, ignore_keys_for_eval, skip_scheduler)
3000 def _evaluate(self, trial, ignore_keys_for_eval, skip_scheduler=False):
-> 3001 metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
3002 self._report_to_hp_search(trial, self.state.global_step, metrics)
3004 # Run delayed LR scheduler now that metrics are populated
File c:\Users\Lenovo\miniconda3\envs\pretrain-huggingface\Lib\site-packages\transformers\trainer.py:4051, in Trainer.evaluate(self, eval_dataset, ignore_keys, metric_key_prefix)
4048 start_time = time.time()
4050 eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
-> 4051 output = eval_loop(
4052 eval_dataloader,
4053 description="Evaluation",
4054 # No point gathering the predictions if there are no metrics, otherwise we defer to
4055 # self.args.prediction_loss_only
4056 prediction_loss_only=True if self.compute_metrics is None else None,
4057 ignore_keys=ignore_keys,
4058 metric_key_prefix=metric_key_prefix,
4059 )
4061 total_batch_size = self.args.eval_batch_size * self.args.world_size
4062 if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
File c:\Users\Lenovo\miniconda3\envs\pretrain-huggingface\Lib\site-packages\transformers\trainer.py:4340, in Trainer.evaluation_loop(self, dataloader, description, prediction_loss_only, ignore_keys, metric_key_prefix)
4338 eval_set_kwargs["losses"] = all_losses if "loss" in args.include_for_metrics else None
4339 eval_set_kwargs["inputs"] = all_inputs if "inputs" in args.include_for_metrics else None
-> 4340 metrics = self.compute_metrics(
4341 EvalPrediction(predictions=all_preds, label_ids=all_labels, **eval_set_kwargs)
4342 )
4343 elif metrics is None:
4344 metrics = {}
Cell In[156], line 27, in compute_metrics(eval_pred)
19 pred_labels = logits_tensor.detach().cpu().numpy()
20 # currently using _compute instead of compute
21 # see this issue for more info: https://github.com/huggingface/evaluate/pull/328#issuecomment-1286866576
22 metrics = metric._compute(
23 predictions=pred_labels,
24 references=labels,
25 num_labels=num_labels,
26 ignore_index=0,
---> 27 reduce_labels=feature_extractor.reduce_labels,
28 )
30 # add per category metrics as individual key-value pairs
31 per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
AttributeError: 'SegformerFeatureExtractor' object has no attribute 'reduce_labels'
``` | [
64,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug",
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/33429 |
TITLE
`Zero-shot object detection` documentation sentence rephrase
COMMENTS
0
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
In [Zero-shot object detection](https://huggingface.co/docs/transformers/tasks/zero_shot_object_detection) documentation, there is an incomplete sentence:
```
...object classification and localization heads. associate images and their corresponding textual descriptions...
```
The sentence beginning with "associate images" needs to be rephrased to improve clarity and complete the thought. | [
74
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0
] | [
"Documentation"
] |
https://api.github.com/repos/huggingface/transformers/issues/33415 |
TITLE
Cannot batch them ({'num_frames', 'input_features', 'is_last'} != {'input_features', 'is_last'})
COMMENTS
11
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
I have the same problem.
when i use pipe to inference with batch_size=1, everything is ok. However the error occur when infer with batch_size>1.
transformers: 4.44.0
torch: 2.1.2
model: whisper-large-v3-zh-punct
autio_data: wav data
```python
import time
from transformers import pipeline, WhisperForConditionalGeneration, AutoModelForSpeechSeq2Seq, AutoProcessor
import os
import torch
DATA_DIR = r'C:\Users\chenjq2\Desktop\wav格式录音'
# DATA_DIR = r'./test_data'
LANGUAGE = 'zh'
TASK = 'transcribe'
files = os.listdir(DATA_DIR)
paths = []
for name in files:
paths.append(os.path.join(DATA_DIR, name))
MODEL_ID = r"C:\Users\chenjq2\Desktop\tmp\models--BELLE-2--Belle-whisper-large-v3-zh-punct\snapshots\f81f1ac2f123f118094a7baa69e532eab375600e"
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model = AutoModelForSpeechSeq2Seq.from_pretrained(
MODEL_ID, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(MODEL_ID, language=LANGUAGE, task=TASK)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
t1 = time.time()
print(pipe(paths, batch_size=4))
print(f'time cost:{time.time()-t1}')
```
error msg:
```
E:\program\anaconda3\envs\nlp\lib\site-packages\torch\_utils.py:831: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Traceback (most recent call last):
File "E:\program\anaconda3\envs\nlp\lib\site-packages\torch\utils\data\dataloader.py", line 630, in __next__
data = self._next_data()
File "E:\program\anaconda3\envs\nlp\lib\site-packages\torch\utils\data\dataloader.py", line 674, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "E:\program\anaconda3\envs\nlp\lib\site-packages\torch\utils\data\_utils\fetch.py", line 42, in fetch
return self.collate_fn(data)
File "E:\program\anaconda3\envs\nlp\lib\site-packages\transformers\pipelines\base.py", line 175, in inner
raise ValueError(
ValueError: The elements of the batch contain different keys. Cannot batch them ({'num_frames', 'input_features', 'is_last'} != {'input_features', 'is_last'})
```
The differnece is due to this:
It will have an additional field num_frames if the code runs to block 2, but not if it runs to block 1.
XXX\transformers\pipelines\automatic_speech_recognition.py
Could anyone tell me how to solve it?
_Originally posted by @minmie in https://github.com/huggingface/transformers/issues/33404#issuecomment-2342510083_
| [
51,
43
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Core: Pipeline",
"Audio"
] |
https://api.github.com/repos/huggingface/transformers/issues/34809 |
TITLE
Flex attention + refactor
COMMENTS
7
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 4
eyes: 0
BODY
Opening this to add support for all models following #34282
Lets bring support for flex attention to more models! 🤗
- [x] Gemma2
It would be great to add the support for more architectures such as
- [ ] Qwen2
- [ ] Llama
- [ ] Gemma
- [ ] QwenVl
- [ ] Mistral
- [ ] Clip
... and many more
For anyone who wants to contribute just open a PR and link it to this issue, and ping me for a review!! 🤗 | [
50,
76,
0
] | [
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"PyTorch",
"Feature request",
"Good Difficult Issue"
] |
https://api.github.com/repos/huggingface/transformers/issues/35976 |
TITLE
Deformable DETR custom kernel fails to compile with PyTorch 2.6
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
Hello,
I understand this might be expected given the recent release of PyTorch 2.6, but wanted to bring it to your attention for tracking purposes.
I'd like to report a compatibility issue between the Deformable DETR custom CUDA kernel and PyTorch 2.6.
The kernel fails to compile due to what appears to be API changes in PyTorch's type system.
I cut some of the error message out, but the gist of it is:
```
Could not load the custom kernel for multi-scale deformable attention: Error building extension 'MultiScaleDeformableAttention'...
.venv/lib/python3.11/site-packages/transformers/kernels/deformable_detr/cuda/ms_deform_attn_cuda.cu(69): error: no suitable conversion function from "const at::DeprecatedTypeProperties" to "c10::ScalarType" exists
; at::ScalarType _st = ::detail::scalar_type(the_type); ; switch (_st) { case at::ScalarType::Double: { do { if constexpr (!at::should_include_kernel_dtype( at_dispatch_name, at::ScalarType::Double)) { if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/hassonofer/Programming/transformers/.venv/lib/python3.11/site-packages/transformers/kernels/deformable_detr/cuda/ms_deform_attn_cuda.cu", static_cast<uint32_t>(69), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "dtype '", toString(at::ScalarType::Double), "' not selected for kernel tag ", at_dispatch_name))); }; } } while (0); using scalar_t [[maybe_unused]] = c10::impl::ScalarTypeToCPPTypeT<at::ScalarType::Double>; return
.venv/lib/python3.11/site-packages/transformers/kernels/deformable_detr/cuda/ms_deform_attn_cuda.cu(140): error: no suitable conversion function from "const at::DeprecatedTypeProperties" to "c10::ScalarType" exists
; at::ScalarType _st = ::detail::scalar_type(the_type); ; switch (_st) { case at::ScalarType::Double: { do { if constexpr (!at::should_include_kernel_dtype( at_dispatch_name, at::ScalarType::Double)) { if (!(false)) { ::c10::detail::torchCheckFail( __func__, "/home/hassonofer/Programming/transformers/.venv/lib/python3.11/site-packages/transformers/kernels/deformable_detr/cuda/ms_deform_attn_cuda.cu", static_cast<uint32_t>(140), (::c10::detail::torchCheckMsgImpl( "Expected " "false" " to be true, but got false. " "(Could this error message be improved? If so, " "please report an enhancement request to PyTorch.)", "dtype '", toString(at::ScalarType::Double), "' not selected for kernel tag ", at_dispatch_name))); }; } } while (0); using scalar_t [[maybe_unused]] = c10::impl::ScalarTypeToCPPTypeT<at::ScalarType::Double>; return
```
**Environment:**
- PyTorch 2.6
- CUDA 12.4
- Python 3.11
- transformers 4.48.1
Thank you for your time.
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. Set up a fresh environment with PyTorch 2.6:
pip3 install torch torchvision torchaudio
pip3 install timm transformers
2. Run the following minimal reproduction code:
```python
from transformers import DeformableDetrForObjectDetection
model = DeformableDetrForObjectDetection.from_pretrained("SenseTime/deformable-detr")
```
### Expected behavior
Clean compilation :) | [
64,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug",
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/34009 |
TITLE
Enabled Flash Attention for PaliGemma models
COMMENTS
9
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #33963
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#create-a-pull-request),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@qubvel
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker
- vision models: @amyeroberts, @qubvel
- speech models: @ylacombe, @eustlb
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @zucchini-nlp (visual-language models) or @gante (all others)
- pipelines: @Rocketknight1
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerzr and @SunMarc
- chat templates: @Rocketknight1
Integrations:
- deepspeed: HF Trainer/Accelerate: @muellerzr
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc
Documentation: @stevhliu
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
| [
68,
12,
73
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Flash Attention",
"Multimodal",
"run-slow"
] |
https://api.github.com/repos/huggingface/transformers/issues/33683 |
TITLE
AutoTokenizer for XGLM model not working properly
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 1
BODY
### System Info
- `transformers` version: 4.44.2
- Platform: Linux-6.1.85+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.24.7
- Safetensors version: 0.4.5
- Accelerate version: 0.34.2
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.1+cu121 (False)
- Tensorflow version (GPU?): 2.17.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.8.4 (cpu)
- Jax version: 0.4.26
- JaxLib version: 0.4.26
- Using distributed or parallel set-up in script?: no
### Who can help?
@ArthurZucker @itazap
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
from transformers import XGLMTokenizer, AutoTokenizer
xglm_tok = XGLMTokenizer.from_pretrained("facebook/xglm-2.9B")
auto_tok = AutoTokenizer.from_pretrained("facebook/xglm-2.9B")
print(xglm_tok.encode('a ')) # [2, 11]
print(auto_tok.encode('a ')) # [2, 11, 6]
```
### Expected behavior
both the tokenizer should output the same ids. | [
47,
35,
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Core: Tokenization",
"Fast Tokenizers",
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/34145 |
TITLE
Request more specific info from bug reporters when opening deepspeed issues
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Feature request
Hi!
I would like the bug reporters to be prompted (or have section to fill in the reports template) to provide `ds_report` info and `zero3` config when opening a bug report related to deepspeed integration (maybe it could be more general). Anything to make sure these bits of info are more likely to included upfront would make some of these issues much more actionable.
### Motivation
I've been looking at some deepspeed integration bugs lately (#28808,#29348,#31867), I noticed that often more deepspeed info has to be requested. I was wondering if some specific (and maybe **BOLDED**) guidelines about what info to provide would go a long way when opening bug reports. I think a reminder to include `zero configs` and `ds_report` might be helpful. I believe this is particularily a pitfall for stuff that is often parsed in (configs, etc).
Something like:
### Reproduction
Please provide a code sample that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
*If you are opening an issue related to one of the following please ensure the this info is included in your reproduction script:
Deepspeed - zero3 config, ds_report output,
Trainer - your trainer config file,
etc.*
@ArthurZucker @amyeroberts | [
76
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"Feature request"
] |
https://api.github.com/repos/huggingface/transformers/issues/36157 |
TITLE
Add functionality to save model when training unexpectedly terminates
COMMENTS
3
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Feature request
I'm thinking of implementing it like this:
```python
try:
trainer.train(resume_from_checkpoint=args.resume_from_checkpoint)
finally:
trainer._save_checkpoint(trainer.model, None)
```
I want to utilize the characteristics of 'finally' to ensure that the model is saved at least once at the end,
even if the training terminates unexpectedly.
### Motivation
Sometimes we need to terminate training unintentionally due to scheduling or various other issues.
If the model checkpoint hasn't been saved even after training has progressed to some extent,
all the training resources used until now are wasted.
### Your contribution
Therefore, I want to add functionality to save the model checkpoint unconditionally
even if the process is terminated by an error or kill signal unintentionally.
And I want to control this through train_args. | [
76
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"Feature request"
] |
https://api.github.com/repos/huggingface/transformers/issues/33917 |
TITLE
Fix Whisper shortform EOS
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
Since short and longform merging, Whisper removed EOS tokens when doing shortform transcription, which is something not happening in the original implementation. It fixes the `test_default_multilingual_transcription_short_form` and `test_generate_with_prompt_ids` tests
A side effect is that average logprob was miscomputed.
cc @eustlb
| [
73
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"run-slow"
] |
https://api.github.com/repos/huggingface/transformers/issues/34789 |
TITLE
Add `Tensor Parallel` support for ALL models
COMMENTS
6
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 4
eyes: 0
BODY
Just opening this to add support for all models following #34184
Lets bring support to all model! 🤗
- [x] Llama
It would be great to add the support for more architectures such as
- [ ] Qwen2
- [ ] QwenVl
- [ ] Mistral
- [ ] Llava
... and many more
For anyone who wants to contribute just open a PR and link it to this issue, and ping me for a review!! 🤗 | [
76,
81,
0
] | [
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
1
] | [
"Feature request",
"Tensor Parallel",
"Good Difficult Issue"
] |
https://api.github.com/repos/huggingface/transformers/issues/34977 |
TITLE
Deprecation Warning for `max_size` in `DetrImageProcessor.preprocess`
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.47.0.dev0
- Platform: Linux-5.15.0-126-generic-x86_64-with-glibc2.31
- Python version: 3.11.0
- Huggingface_hub version: 0.24.5
- Safetensors version: 0.4.4
- Accelerate version: 1.1.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.1.2+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA GeForce RTX 3090
### Who can help?
@amyeroberts, @qubvel
and I think @NielsRogge worked on it too ?
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import logging
import numpy as np
from transformers.models.detr.image_processing_detr import DetrImageProcessor
logging.basicConfig(level=logging.WARNING)
logger = logging.getLogger(__name__)
images = [np.ones((512, 512, 3))]
annotations = [{'image_id': [], 'annotations': []}]
size = {'max_height': 600, 'max_width': 600}
image_processor = DetrImageProcessor()
images = image_processor.preprocess(images, do_resize=True, do_rescale=False, size=size, annotations=annotations, format='coco_detection')
```
### Expected behavior
Hello!
I noticed that the `preprocess` method in the `DetrImageProcessor` class always passes `max_size` to the `resize` method,
https://github.com/huggingface/transformers/blob/4120cb257f03b834fb332e0b0ee6570245e85656/src/transformers/models/detr/image_processing_detr.py#L1445-L1447
and that triggers a deprecation warning in `resize` method,
```bash
The `max_size` parameter is deprecated and will be removed in v4.26. Please specify in `size['longest_edge'] instead`.
```
https://github.com/huggingface/transformers/blob/4120cb257f03b834fb332e0b0ee6570245e85656/src/transformers/models/detr/image_processing_detr.py#L992-L997
I propose removing the unused `max_size` argument from the preprocess method since it is always `None`,
https://github.com/huggingface/transformers/blob/4120cb257f03b834fb332e0b0ee6570245e85656/src/transformers/models/detr/image_processing_detr.py#L1340
Would it be okay if I work on this and submit a pull request? I can try to see if the problem also occurs in other models. | [
1,
62,
65
] | [
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"WIP",
"Vision",
"Processing"
] |
https://api.github.com/repos/huggingface/transformers/issues/35814 |
TITLE
[Feature Request] Support register customize quantization method out-of-tree
COMMENTS
2
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Feature request
Support register customize quantization method out-of-tree.
The usage would be as follows:
```python
from transformers.quantizers import HfQuantizer
from transformers.quantizers import regsiter_quantization_config, register_quantizer
from transformers.utils.quantization_config import QuantizationConfigMixin
@regsiter_quantization_config("custom")
class CustomFakeQuantizationConfig(QuantizationConfigMixin):
"""The custom fake quantization config."""
@register_quantizer("custom")
class CustomFakeQuantizer(HfQuantizer):
"""The custom fake quantizer."""
```
### Motivation
We would greatly appreciate it if HuggingFace could support registering custom quantization schemes externally. This would allow us to integrate the schemes of any LLM quantization tools and evaluate fake quantization models using the powerful combination of `lm_eval` + `huggingface`. Thank you for considering this!
Similar features have already been supported by vLLM, see:
- https://github.com/vllm-project/vllm/issues/11926
- https://github.com/vllm-project/vllm/pull/11969
### Your contribution
If this feature request is considered, I'd happily submit a PR to implement it. | [
76
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0
] | [
"Feature request"
] |
https://api.github.com/repos/huggingface/transformers/issues/35706 |
TITLE
autocast() got an unexpected keyword argument 'cache_enabled when use trainer.torch_jit_model_eval
COMMENTS
4
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.46.3
- Platform: Linux-4.18.0-147.el8_1.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.10
- Huggingface_hub version: 0.26.5
- Safetensors version: 0.4.5
- Accelerate version: 1.0.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA A100-SXM4-80GB
### Who can help?
@muellerzr
@SunMarc
### Information
- [x] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
When using the `torch_jit_model_eval()` method in trainer, it prompts
> "failed to use PyTorch jit mode due to: autocast() got an unexpected keyword argument 'cache_enabled'."
Looking at the details, it was found that the error was caused by the `self.accelerator.autocast(cache_enabled=False)` method. Its method definition is `def autocast(self, autocast_handler: AutocastKwargs = None)`, and there is no `cache_enabled` method.
Is this because the code here has not been updated, or because I ignored some settings?
Is there a solution now?
### Expected behavior
Work normally. | [
64
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"bug"
] |
https://api.github.com/repos/huggingface/transformers/issues/35105 |
TITLE
Fix signatures for processing kwargs
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
# What does this PR do?
as title | [
73
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"run-slow"
] |
https://api.github.com/repos/huggingface/transformers/issues/34272 |
TITLE
image_transforms preprocess quite slow when run large image with qwen2vl
COMMENTS
9
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### System Info
- `transformers` version: 4.45.2
- Platform: Linux-5.4.0-132-generic-x86_64-with-glibc2.31
- Python version: 3.12.7
- Huggingface_hub version: 0.25.1
- Safetensors version: 0.4.5
- Accelerate version: 1.0.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.4.0+cu121 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using distributed or parallel set-up in script?: <fill in>
- Using GPU in script?: <fill in>
- GPU type: NVIDIA GeForce RTX 3090
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
funcitons in image_transforms, `rescale`, `normalize` quite slow when preprocess large image.
https://github.com/huggingface/transformers/blob/main/src/transformers/image_transforms.py
here is benchmark

please refer to https://github.com/vllm-project/vllm/issues/9238
### Expected behavior
how to improve performance? | [
10,
64,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
] | [
"Performance",
"bug",
"Vision"
] |
https://api.github.com/repos/huggingface/transformers/issues/34474 |
TITLE
Useful Sensors Moonshine Transcription Model
COMMENTS
3
REACTIONS
+1: 1
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
### Model description
Model description can be found in the [Moonshine Whitepaper](https://github.com/usefulsensors/moonshine/blob/main/moonshine_paper.pdf).
I will be porting our [existing torch model](https://github.com/usefulsensors/moonshine/blob/b2a61fff243dd78ee2fa72dd1bceff8ccf656c4c/model.py) to Transformers.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
[Implementation](https://github.com/usefulsensors/moonshine) Special credit to @keveman for training and @evmaki for data collection and preprocessing.
[Model weights](https://huggingface.co/UsefulSensors/moonshine) | [
77
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0
] | [
"New model"
] |
https://api.github.com/repos/huggingface/transformers/issues/35744 |
TITLE
[Doc] Adding blog post to model doc for `TimmWrapper`
COMMENTS
1
REACTIONS
+1: 0
-1: 0
laugh: 0
hooray: 0
heart: 0
rocket: 0
eyes: 0
BODY
This PR adds the blog post link to the `TimmWrapper` documentation. | [
74,
62
] | [
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
1,
0,
0,
0,
0,
0,
0,
0
] | [
"Documentation",
"Vision"
] |
End of preview. Expand
in Dataset Viewer.
- Downloads last month
- 549