
DNA 1.0
Collection
DNA 1.0 8B instruction-tuned language model
•
2 items
•
Updated
![]()
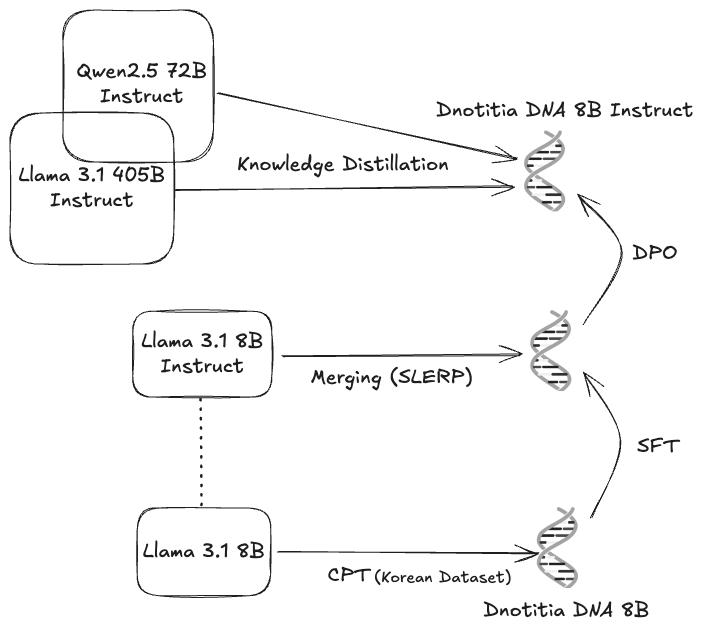
DNA 1.0 8B Instruct is a state-of-the-art (SOTA) bilingual language model based on Llama architecture, specifically optimized for Korean language understanding and generation, while also maintaining strong English capabilities. The model was developed through a sophisticated process involving model merging via spherical linear interpolation (SLERP) with Llama 3.1 8B Instruct, and underwent knowledge distillation (KD) using Llama 3.1 405B as the teacher model. It was extensively trained through continual pre-training (CPT) with a high-quality Korean dataset. The training pipeline was completed with supervised fine-tuning (SFT) and direct preference optimization (DPO) to align with human preferences and enhance instruction-following abilities.
DNA 1.0 8B Instruct was fine-tuned on approximately 10B tokens of carefully curated data and has undergone extensive instruction tuning to enhance its ability to follow complex instructions and engage in natural conversations.
NOTICE (Korean):
본 모델은 상업적 목적으로 활용하실 수 있습니다. 상업적 이용을 원하시는 경우, Contact us를 통해 문의해 주시기 바랍니다. 간단한 협의 절차를 거쳐 상업적 활용을 승인해 드리도록 하겠습니다.
Try DNA-powered Mnemos Assistant! Beta Open →
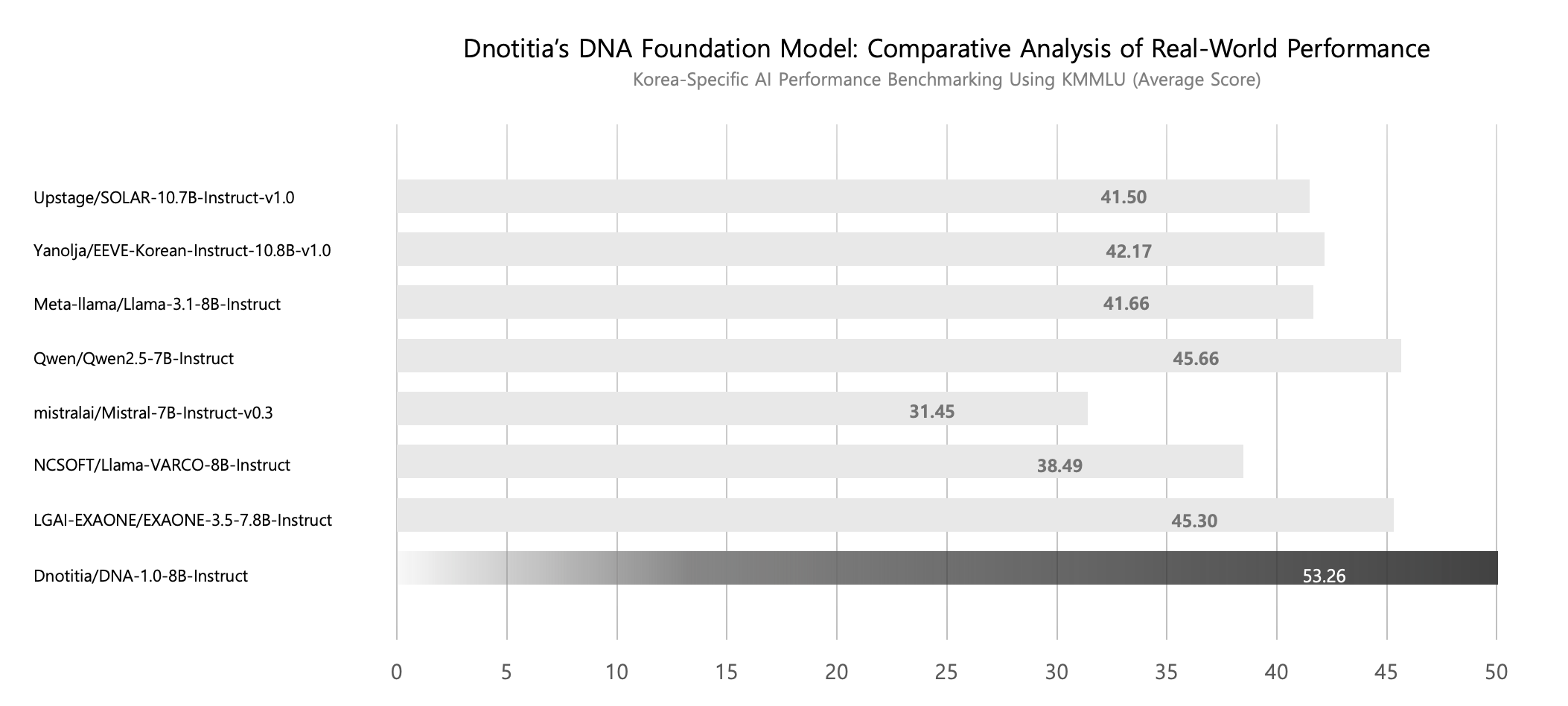
We evaluated DNA 1.0 8B Instruct against other prominent language models of similar size across various benchmarks, including Korean-specific tasks and general language understanding metrics. More details will be provided in the upcoming Technical Report.
| Language | Benchmark | dnotitia/Llama-DNA-1.0-8B-Instruct | LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct | LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct | yanolja/EEVE-Korean-Instruct-10.8B-v1.0 | Qwen/Qwen2.5-7B-Instruct | meta-llama/Llama-3.1-8B-Instruct | mistralai/Mistral-7B-Instruct-v0.3 | NCSOFT/Llama-VARCO-8B-Instruct | upstage/SOLAR-10.7B-Instruct-v1.0 |
|---|---|---|---|---|---|---|---|---|---|---|
| Korean | KMMLU | 53.26 (1st) | 45.30 | 45.28 | 42.17 | 45.66 | 41.66 | 31.45 | 38.49 | 41.50 |
| KMMLU-hard | 29.46 (1st) | 23.17 | 20.78 | 19.25 | 24.78 | 20.49 | 17.86 | 19.83 | 20.61 | |
| KoBEST | 83.40 (1st) | 79.05 | 80.13 | 81.67 | 78.51 | 67.56 | 63.77 | 72.99 | 73.26 | |
| Belebele | 57.99 (1st) | 40.97 | 45.11 | 49.40 | 54.85 | 54.70 | 40.31 | 53.17 | 48.68 | |
| CSATQA | 43.32 (2nd) | 40.11 | 34.76 | 39.57 | 45.45 | 36.90 | 27.27 | 32.62 | 34.22 | |
| English | MMLU | 66.64 (3rd) | 65.27 | 64.32 | 63.63 | 74.26 | 68.26 | 62.04 | 63.25 | 65.30 |
| MMLU-Pro | 43.05 (1st) | 40.73 | 38.90 | 32.79 | 42.5 | 40.92 | 33.49 | 37.11 | 30.25 | |
| GSM8K | 80.52 (1st) | 65.96 | 80.06 | 56.18 | 75.74 | 75.82 | 49.66 | 64.14 | 69.22 |
Evaluation Protocol
For easy reproduction of our evaluation results, we list the evaluation tools and settings used below:
| Evaluation setting | Metric | Evaluation tool | |
|---|---|---|---|
| KMMLU | 5-shot | macro_avg / exact_match | lm-eval-harness |
| KMMLU Hard | 5-shot | macro_avg / exact_match | lm-eval-harness |
| KoBEST | 5-shot | macro_avg / f1 | lm-eval-harness |
| Belebele | 0-shot | acc | lm-eval-harness |
| CSATQA | 0-shot | acc_norm | lm-eval-harness |
| MMLU | 5-shot | macro_avg / acc | lm-eval-harness |
| MMLU Pro | 5-shot | macro_avg / exact_match | lm-eval-harness |
| GSM8K | 5-shot | acc, exact_match & strict_extract | lm-eval-harness |
This model requires transformers >= 4.43.0.
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained('dnotitia/Llama-DNA-1.0-8B-Instruct')
model = AutoModelForCausalLM.from_pretrained('dnotitia/Llama-DNA-1.0-8B-Instruct', device_map='auto')
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
conversation = [
{"role": "system", "content": "You are a helpful assistant, Dnotitia DNA."},
{"role": "user", "content": "너의 이름은?"},
]
inputs = tokenizer.apply_chat_template(conversation,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt").to(model.device)
_ = model.generate(**inputs, streamer=streamer)
While DNA 1.0 8B Instruct demonstrates strong performance, users should be aware of the following limitations:
This model is released under CC BY-NC 4.0 license. For commercial usage inquiries, please Contact us.
KMMLU scores comparison chart:
DNA 1.0 8B Instruct model architecture 1:

If you use or discuss this model in your academic research, please cite the project to help spread awareness:
@article{dnotitiadna2024,
title = {Dnotitia DNA 1.0 8B Instruct},
author = {Jungyup Lee, Jemin Kim, Sang Park, Seungjae Lee},
year = {2024},
url = {https://huggingface.co/dnotitia/DNA-1.0-8B-Instruct},
version = {1.0},
}