
metadata
license: apache-2.0
pipeline_tag: image-to-3d
[ECCV 2024] VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
VFusion3D is a large, feed-forward 3D generative model trained with a small amount of 3D data and a large volume of synthetic multi-view data. It is the first work exploring scalable 3D generative/reconstruction models as a step towards a 3D foundation.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Junlin Han, Filippos Kokkinos, Philip Torr
GenAI, Meta and TVG, University of Oxford
European Conference on Computer Vision (ECCV), 2024
News
- [25.07.2024] Release weights and inference code for VFusion3D.
Quick Start
Getting started with VFusion3D is super easy! 🤗 Here’s how you can use the model with Hugging Face:
Load model directly
from transformers import AutoModel
model = AutoModel.from_pretrained("jadechoghari/vfusion3d", trust_remote_code=True)
Check out our demo app to see VFusion3D in action! 🤗
Results and Comparisons
3D Generation Results


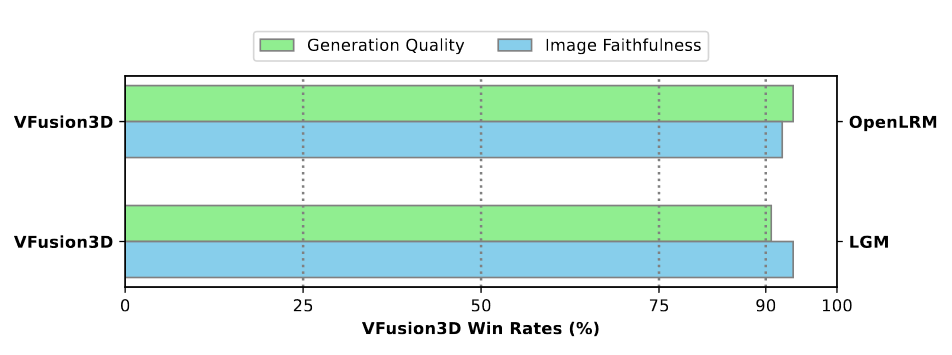
User Study Results
Acknowledgement
- This inference code of VFusion3D heavily borrows from OpenLRM.
Citation
If you find this work useful, please cite us:
@article{han2024vfusion3d,
title={VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models},
author={Junlin Han and Filippos Kokkinos and Philip Torr},
journal={European Conference on Computer Vision (ECCV)},
year={2024}
}
License
- The majority of VFusion3D is licensed under CC-BY-NC, however portions of the project are available under separate license terms: OpenLRM as a whole is licensed under the Apache License, Version 2.0, while certain components are covered by NVIDIA's proprietary license.
- The model weights of VFusion3D is also licensed under CC-BY-NC.