
Welcome to Qwen2-72B-Instruct-math model, which is used for solving Math Problem.
Welcome to LLM Math Solver
LLM Math Solver: using LLM to solve MATH problems.
本项目已经在Github上开源,网址为:https://github.com/percent4/llm_math_solver ,更多内容可参考文档:https://percent4.github.io/llm_math_solver/ 。
评估结果
不同模型经过微调的数学能力测评表如下:
| 基座模型 | GSM8K | MATH | 样本数 |
|---|---|---|---|
| QWen1.5-32B | 79.68% | 43.58% | 2402 |
| Yi-1.5-34B | 83.47% | 52.76% | 3480 |
| Yi-1.5-34B-Chat | 85.67% | 57.22% | 3479 |
| QWen-2-72B-Instruct | 93.03% | 68.54% | 3469 |
| QWen-2-72B-Instruct | 93.56% | 69.66% | 4799 |
其它模型:
| 模型 | GSM8K | MATH |
|---|---|---|
| GPT-4o-0513 | 95.8% | 76.6% |
| Claude-3.5-Sonnet | 96.4% | 71.1% |
| GEMINI-1.5-PRO(May 2024) | / | 67.7% |
| DeepSeek-Coder-V2-Instruct(236B) | 94.9% | 75.7% |
使用方法
- 使用vLLM部署
命令如下:
CUDA_VISIBLE_DEVICES=0,1 python -m vllm.entrypoints.openai.api_server --model /workspace/models/Qwen2-72B-Instruct-math --served-model-name Qwen2-72B-Instruct-math --gpu-memory-utilization 0.95 --max-model-len 8192 --dtype auto --api-key token-abc123 --tensor-parallel-size 2
将--model参数后面的模型路径替换成你本地路径,或者直接使用项目名称。
也可以使用LLaMA-Factory框架提供的api部署命令提供模型推理服务。
注意:需使用两张80G显存的A100才能部署。
- 使用Python调用
注意:该模型解数学题的系统人设(System Prompt)为:你是一个数学解题大师,请解决下面的数学题,给出思考过程,必要时需要给出解题过程中的Python代码。正确答案的数值用\boxed{}包围起来,最终的答案以因此开头,不要讲多余的废话。
# -*- coding: utf-8 -*-
# @file: infer.py
import os
import re
import subprocess
from openai import OpenAI
from random import choices
os.environ["OPENAI_BASE_URL"] = "http://localhost:8000/v1"
os.environ["OPENAI_API_KEY"] = "token-abc123"
client = OpenAI()
execution_desc = ["运行以上代码,输出会是: ",
"现在将上面的代码复制到Python环境中运行,运行结果为:",
"执行上述Python代码,运行结果将是:",
"上面的Python代码执行结果为:",
"运行上述代码,我们可以得到题目要求的答案。输出结果将是:"]
query = "一列火车经过南京长江大桥,大桥长6700米,这列火车长140米,火车每分钟行400米,这列火车通过长江大桥需要多少分钟?"
messages = [{"role": "system","content": "你是一个数学解题大师,请解决下面的数学题,给出思考过程,必要时需要给出解题过程中的Python代码。正确答案的数值用\\boxed{}包围起来,最终的答案以因此开头,不要讲多余的废话。"}]
messages.append({"role": "user", "content": f"题目:{query}"})
result = client.chat.completions.create(messages=messages,
model="Qwen2-72B-Instruct-math",
temperature=0.2,
stream=True)
reply_message = ""
for chunk in result:
if hasattr(chunk, "choices") and chunk.choices[0].delta.content:
reply_message += chunk.choices[0].delta.content
# find python code and execute the code
if '```python' in reply_message and '\n```' in reply_message:
messages.append({"role": "assistant", "content": '```'.join(reply_message.split('```')[:-1]) + '```'})
python_code_string = re.findall(r'```python\n(.*?)\n```', reply_message, re.S)[0]
python_file_path = 'temp.py'
with open(python_file_path, 'w') as f:
f.write(python_code_string)
python_code_run = subprocess.run(['python3', python_file_path], stdout=subprocess.PIPE, timeout=10)
if python_code_run.returncode:
raise RuntimeError("生成的Python代码无法运行!")
python_code_execution = python_code_run.stdout.decode('utf-8')
os.remove(python_file_path)
code_reply_str = choices(execution_desc, k=1)[0]
code_reply = f"\n{code_reply_str}```{python_code_execution.strip()}```\n"
reply_message += code_reply
messages.append({"role": "user", "content": code_reply})
result = client.chat.completions.create(messages=messages,
model="Qwen2-72B-Instruct-math",
temperature=0.2,
stream=True)
final_reply = ""
for chunk in result:
if hasattr(chunk, "choices") and chunk.choices[0].delta.content:
reply_message += chunk.choices[0].delta.content
final_reply += chunk.choices[0].delta.content
print(reply_message.replace('```python', '\n```python'))
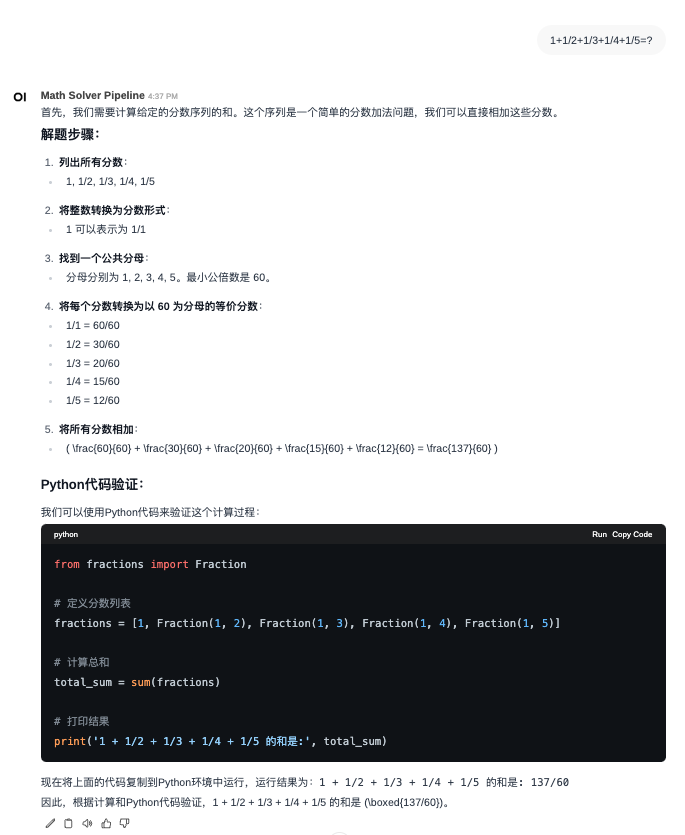
- 或者 使用Open WebUI中的Pipelines,提供推理页面
具体使用方法见参考文献中的 4. Open WebUI的Pipelines学习之使用大模型解数学题 。






参考文献
关于该模型使用的训练数据、训练方法和相关文章,可以参考Github上项目: llm_math_solver.
文章如下:
- Downloads last month
- 15
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.