
Vicuna 13b Weights vicuna-weights
Converted model from https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
Install
pip3 install fschat
Inference with Command Line Interface
(Experimental Feature: You can specify --style rich to enable rich text output and better text streaming quality for some non-ASCII content. This may not work properly on certain terminals.)

When use huggingface, the </path/to/vicuna/weights> is "jinxuewen/vicuna-13b"
Single GPU
The command below requires around 28GB of GPU memory for Vicuna-13B and 14GB of GPU memory for Vicuna-7B. See the "No Enough Memory" section below if you do not have enough memory.
python3 -m fastchat.serve.cli --model-path /path/to/vicuna/weights
Multiple GPUs
You can use model parallelism to aggregate GPU memory from multiple GPUs on the same machine.
python3 -m fastchat.serve.cli --model-path /path/to/vicuna/weights --num-gpus 2
CPU Only
This runs on the CPU only and does not require GPU. It requires around 60GB of CPU memory for Vicuna-13B and around 30GB of CPU memory for Vicuna-7B.
python3 -m fastchat.serve.cli --model-path /path/to/vicuna/weights --device cpu
Metal Backend (Mac Computers with Apple Silicon or AMD GPUs)
Use --device mps to enable GPU acceleration on Mac computers (requires torch >= 2.0).
Use --load-8bit to turn on 8-bit compression.
python3 -m fastchat.serve.cli --model-path /path/to/vicuna/weights --device mps --load-8bit
Vicuna-7B can run on a 32GB M1 Macbook with 1 - 2 words / second.
No Enough Memory or Other Platforms
If you do not have enough memory, you can enable 8-bit compression by adding --load-8bit to commands above.
This can reduce memory usage by around half with slightly degraded model quality.
It is compatible with the CPU, GPU, and Metal backend.
Vicuna-13B with 8-bit compression can run on a single NVIDIA 3090/4080/V100(16GB) GPU.
python3 -m fastchat.serve.cli --model-path /path/to/vicuna/weights --load-8bit
Besides, we are actively exploring more methods to make the model easier to run on more platforms. Contributions and pull requests are welcome.
Serving with Web GUI
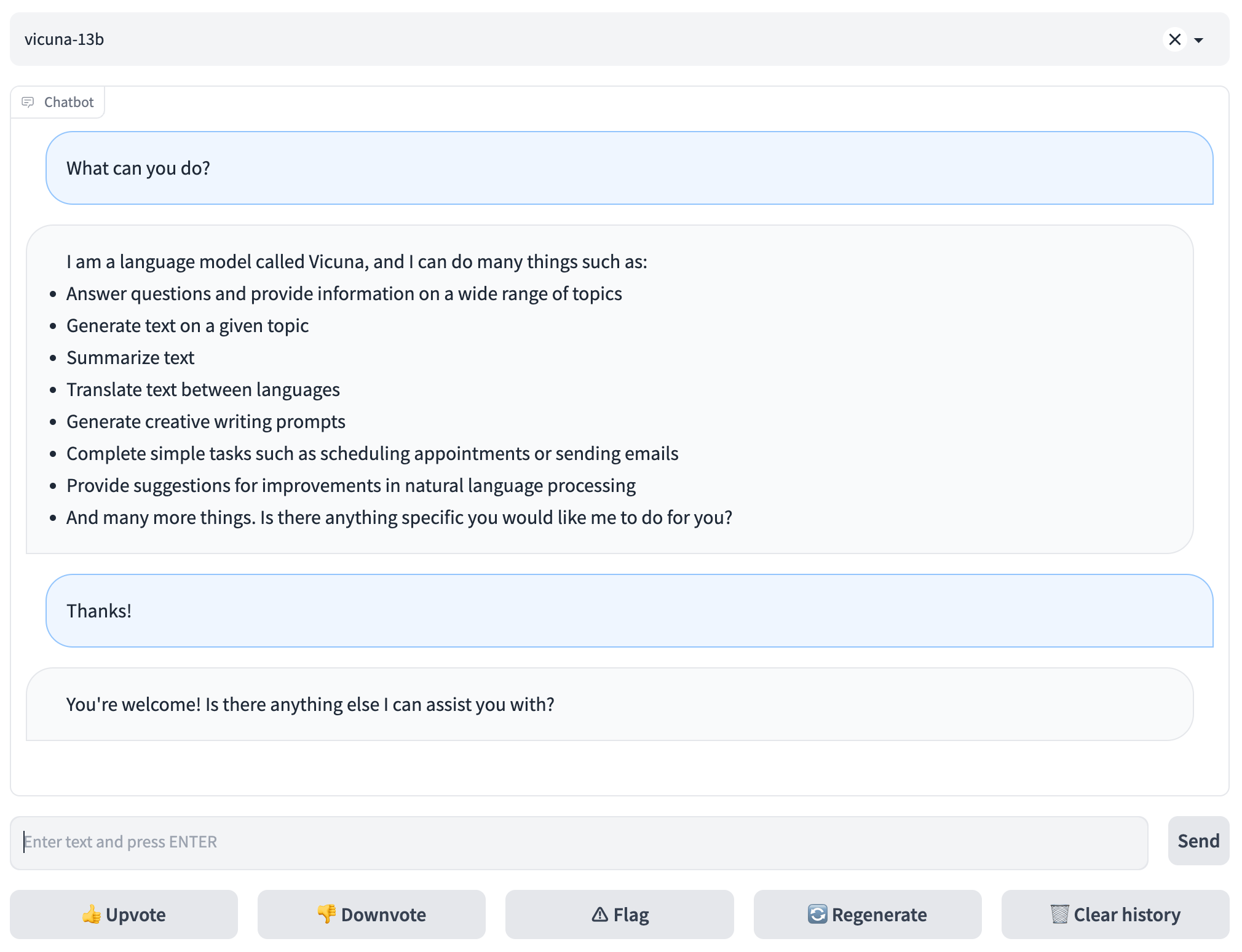
To serve using the web UI, you need three main components: web servers that interface with users, model workers that host one or more models, and a controller to coordinate the webserver and model workers. Here are the commands to follow in your terminal:
Launch the controller
python3 -m fastchat.serve.controller
This controller manages the distributed workers.
Launch the model worker
python3 -m fastchat.serve.model_worker --model-path /path/to/vicuna/weights
Wait until the process finishes loading the model and you see "Uvicorn running on ...". You can launch multiple model workers to serve multiple models concurrently. The model worker will connect to the controller automatically.
To ensure that your model worker is connected to your controller properly, send a test message using the following command:
python3 -m fastchat.serve.test_message --model-name vicuna-13b
Launch the Gradio web server
python3 -m fastchat.serve.gradio_web_server
This is the user interface that users will interact with.
By following these steps, you will be able to serve your models using the web UI. You can open your browser and chat with a model now.
API
Huggingface Generation APIs
See fastchat/serve/huggingface_api.py
OpenAI-compatible RESTful APIs & SDK
(Experimental. We will keep improving the API and SDK.)
Chat Completion
Reference: https://platform.openai.com/docs/api-reference/chat/create
Some features/compatibilities to be implemented:
- streaming
- support of some parameters like
top_p,presence_penalty - proper error handling (e.g. model not found)
- the return value in the client SDK could be used like a dict
RESTful API Server
First, launch the controller
python3 -m fastchat.serve.controller
Then, launch the model worker(s)
python3 -m fastchat.serve.model_worker --model-name 'vicuna-7b-v1.1' --model-path /path/to/vicuna/weights
Finally, launch the RESTful API server
export FASTCHAT_CONTROLLER_URL=http://localhost:21001
python3 -m fastchat.serve.api --host localhost --port 8000
Test the API server
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "vicuna-7b-v1.1",
"messages": [{"role": "user", "content": "Hello!"}]
}'
Client SDK
Assuming environment variable FASTCHAT_BASEURL is set to the API server URL (e.g., http://localhost:8000), you can use the following code to send a request to the API server:
import os
from fastchat import client
client.set_baseurl(os.getenv("FASTCHAT_BASEURL"))
completion = client.ChatCompletion.create(
model="vicuna-7b-v1.1",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
- Downloads last month
- 32