
Eurus Models
Collection
Fixed versions of the 'Eurus' models to use 16k context + other fixes.
•
2 items
•
Updated
This is a fixed version of Eurus-70b-sft made by copying the json files from the (base) CodeLlama-70b-hf model and adding in the Mistral chat template, eg:
<s>[INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
This version has the same context length (16k) and RoPE base frequency (1000000) as CodeLlama-70b:
> ./perplexity -m eurus:70b-nca-fixed-q8_0.gguf -f wiki.test.raw -c 4096
Final estimate: PPL = 5.4451 +/- 0.03053
> ./perplexity -m eurus:70b-nca-fixed-q8_0.gguf -f wiki.test.raw -c 16384
Final estimate: PPL = 5.2458 +/- 0.02892
I have also tested it with multi-turn conversations for 10k+ context and it has remained perfectly coherent.
It even looks to be fine for use with a context length of 32k:
> ./perplexity -m eurus:70b-nca-fixed-q8_0.gguf -f wiki.test.raw -c 32768
Final estimate: PPL = 5.0394 +/- 0.02719
Also see: Eurus-70b-nca-fixed
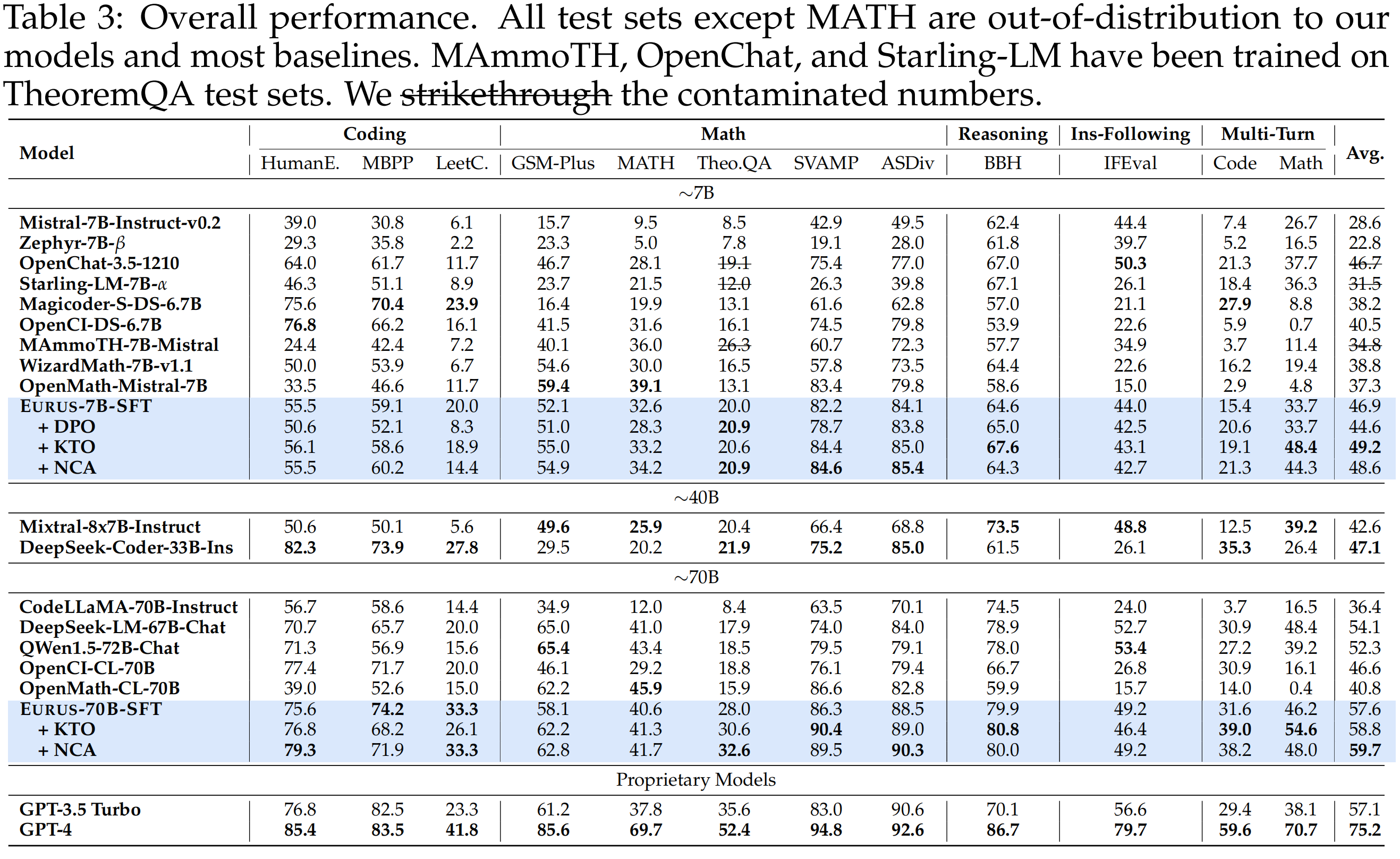
Eurus-70B-SFT is fine-tuned from CodeLLaMA-70B on all correct actions in UltraInteract, mixing a small proportion of UltraChat, ShareGPT, and OpenOrca examples.
It achieves better performance than other open-source models of similar sizes and even outperforms specialized models in corresponding domains in many cases.
We apply tailored prompts for coding and math, consistent with UltraInteract data formats:
Coding
[INST] Write Python code to solve the task:
{Instruction} [/INST]
Math-CoT
[INST] Solve the following math problem step-by-step.
Simplify your answer as much as possible. Present your final answer as \\boxed{Your Answer}.
{Instruction} [/INST]
Math-PoT
[INST] Tool available:
[1] Python interpreter
When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment.
Solve the following math problem step-by-step.
Simplify your answer as much as possible.
{Instruction} [/INST]
@misc{yuan2024advancing,
title={Advancing LLM Reasoning Generalists with Preference Trees},
author={Lifan Yuan and Ganqu Cui and Hanbin Wang and Ning Ding and Xingyao Wang and Jia Deng and Boji Shan and Huimin Chen and Ruobing Xie and Yankai Lin and Zhenghao Liu and Bowen Zhou and Hao Peng and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2404.02078},
archivePrefix={arXiv},
primaryClass={cs.AI}
}