
metadata
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
widget:
- text: <s0><s1> webpage about Star Wars
output:
url: star wars.jpeg
- text: <s0><s1> webpage about the movie Mean Girls
output:
url: image_1.png
- text: <s0><s1> webpage about Taylor Swift
output:
url: taylor swift.jpeg
- text: <s0><s1> webpage about Ramen
output:
url: ramen.jpeg
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a webpage in the style of <s0><s1>
license: openrail++
SDXL LoRA DreamBooth - LinoyTsaban/web_y2k

- Prompt
- <s0><s1> webpage about Star Wars

- Prompt
- <s0><s1> webpage about the movie Mean Girls
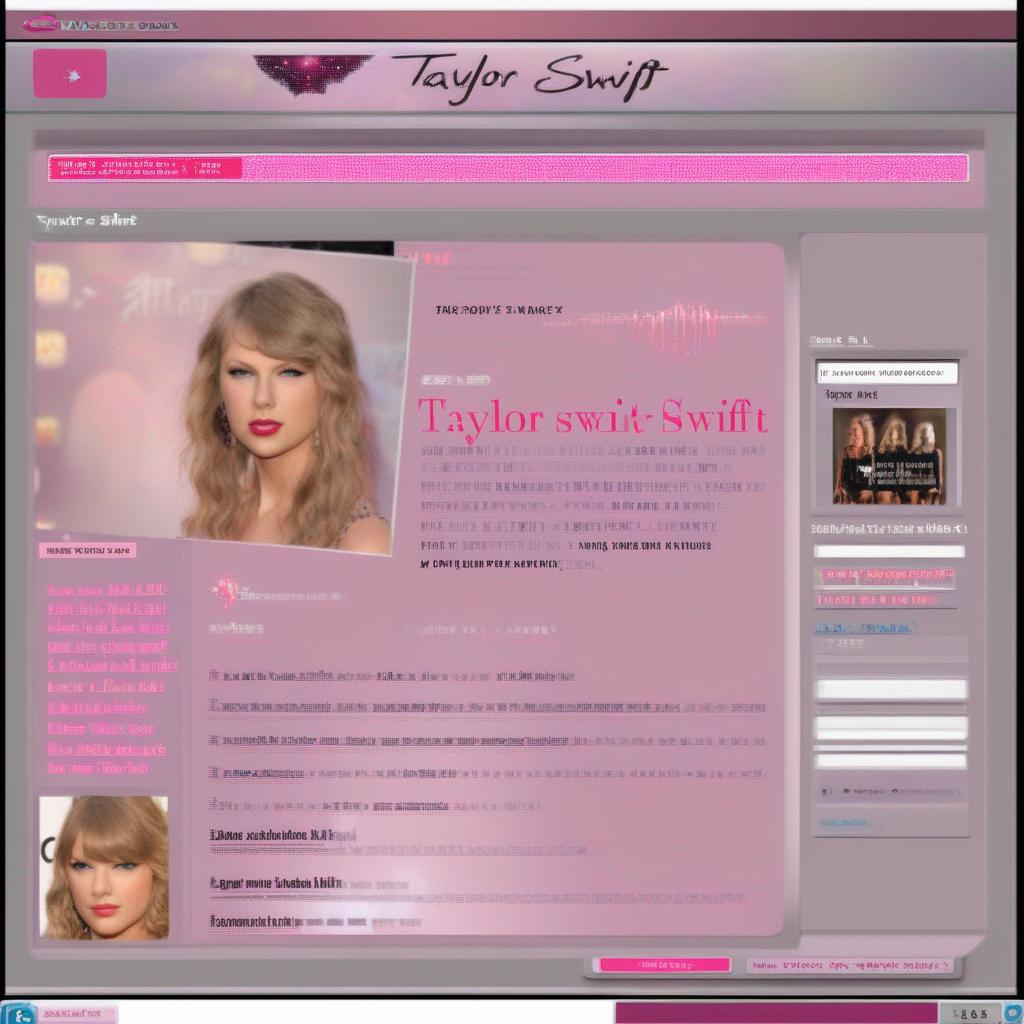
- Prompt
- <s0><s1> webpage about Taylor Swift

- Prompt
- <s0><s1> webpage about Ramen
Model description
These are LinoyTsaban/web_y2k LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
Trigger words
To trigger image generation of trained concept(or concepts) replace each concept identifier in you prompt with the new inserted tokens:
to trigger concept TOK → use <s0><s1> in your prompt
Use it with the 🧨 diffusers library
from diffusers import AutoPipelineForText2Image
import torch
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('LinoyTsaban/web_y2k', weight_name='pytorch_lora_weights.safetensors')
embedding_path = hf_hub_download(repo_id='LinoyTsaban/web_y2k', filename="embeddings.safetensors", repo_type="model")
state_dict = load_file(embedding_path)
pipeline.load_textual_inversion(state_dict["clip_l"], token=["<s0>", "<s1>"], text_encoder=pipe.text_encoder, tokenizer=pipe.tokenizer)
pipeline.load_textual_inversion(state_dict["clip_g"], token=["<s0>", "<s1>"], text_encoder=pipe.text_encoder_2, tokenizer=pipe.tokenizer_2)
image = pipeline('<s0><s1> webpage about the movie Mean Girls').images[0]
For more details, including weighting, merging and fusing LoRAs, check the documentation on loading LoRAs in diffusers
Download model
Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- Download the LoRA *.safetensors here. Rename it and place it on your Lora folder.
- Download the text embeddings *.safetensors here. Rename it and place it on it on your embeddings folder.
All Files & versions.
Details
The weights were trained using 🧨 diffusers Advanced Dreambooth Training Script.
LoRA for the text encoder was enabled. False.
Pivotal tuning was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.