
metadata
library_name: custom
tags:
- robotics
- diffusion
- mixture-of-experts
- multi-modal
license: mit
datasets:
- CALVIN
languages:
- en
pipeline_tag: robotics
MoDE (Mixture of Denoising Experts) Diffusion Policy
Model Description
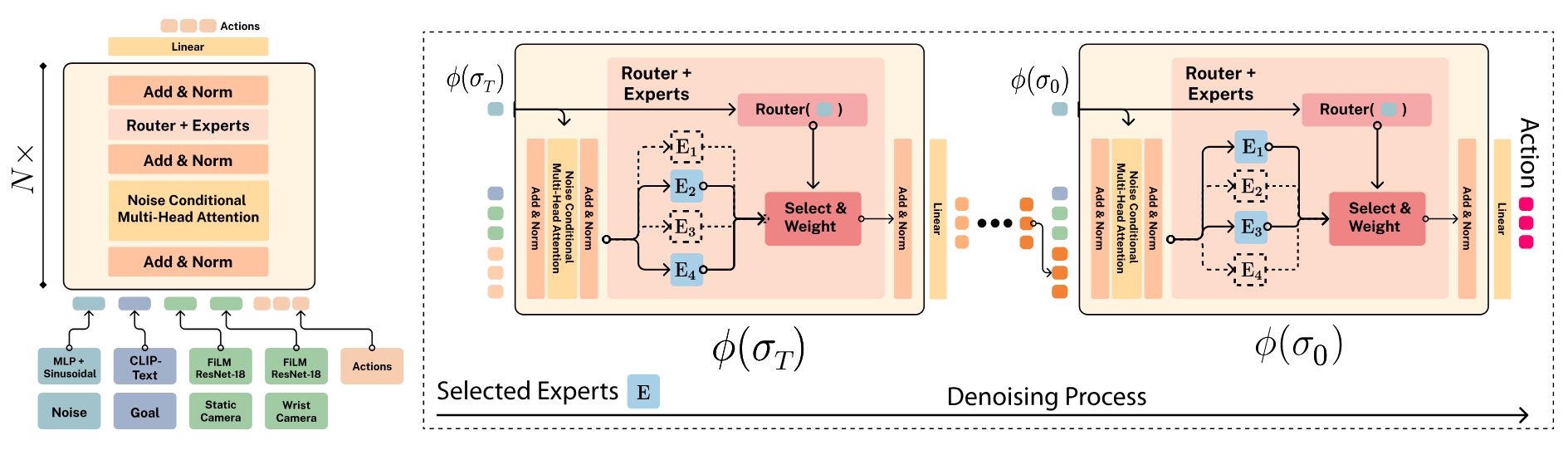
This model implements a Mixture of Diffusion Experts architecture for robotic manipulation, combining transformer-based backbone with noise-only expert routing. For faster inference, we can precache the chosen expert for each timestep to reduce computation time.
The model has been pretrained on a subset of OXE for 300k steps and finetuned for downstream tasks on the CALVIN/LIBERO dataset.
Model Details
Architecture
- Base Architecture: MoDE with custom Mixture of Experts Transformer
- Vision Encoder: ResNet-50 with FiLM conditioning finetuned from ImageNet
- EMA: Enabled
- Action Window Size: 10
- Sampling Steps: 5 (optimal for performance)
- Sampler Type: DDIM
Input/Output Specifications
Inputs
- RGB Static Camera:
(B, T, 3, H, W)tensor - RGB Gripper Camera:
(B, T, 3, H, W)tensor - Language Instructions: Text strings
Outputs
- Action Space:
(B, T, 7)tensor representing delta EEF actions
Usage
Check out our full model implementation on Github MoDE_Diffusion_Policy and follow the instructions in the readme to test the model on one of the environments.
obs = {
"rgb_obs": {
"rgb_static": static_image,
"rgb_gripper": gripper_image
}
}
goal = {"lang_text": "pick up the blue cube"}
action = model.step(obs, goal)
Training Details
Configuration
- Optimizer: AdamW
- Learning Rate: 0.0001
- Weight Decay: 0.05
Citation
If you found the code usefull, please cite our work:
@misc{reuss2024efficient,
title={Efficient Diffusion Transformer Policies with Mixture of Expert Denoisers for Multitask Learning},
author={Moritz Reuss and Jyothish Pari and Pulkit Agrawal and Rudolf Lioutikov},
year={2024},
eprint={2412.12953},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
License
This model is released under the MIT license.