

Model Overview
A pre-trained model for volumetric (3D) Brats MRI 3D Latent Diffusion Generative Model.
This model is trained on BraTS 2016 and 2017 data from Medical Decathlon, using the Latent diffusion model [1].
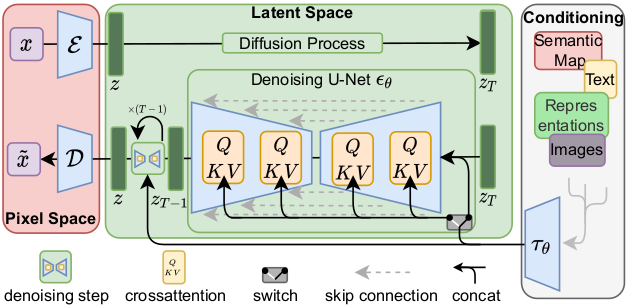
This model is a generator for creating images like the Flair MRIs based on BraTS 2016 and 2017 data. It was trained as a 3d latent diffusion model and accepts Gaussian random noise as inputs to produce an image output. The train_autoencoder.json file describes the training process of the variational autoencoder with GAN loss. The train_diffusion.json file describes the training process of the 3D latent diffusion model.
In this bundle, the autoencoder uses perceptual loss, which is based on ResNet50 with pre-trained weights (the network is frozen and will not be trained in the bundle). In default, the pretrained parameter is specified as False in train_autoencoder.json. To ensure correct training, changing the default settings is necessary. There are two ways to utilize pretrained weights:
- if set
pretrainedtoTrue, ImageNet pretrained weights from torchvision will be used. However, the weights are for non-commercial use only. - if set
pretrainedtoTrueand specifies theperceptual_loss_model_weights_pathparameter, users are able to load weights from a local path. This is the way this bundle used to train, and the pre-trained weights are from some internal data.
Please note that each user is responsible for checking the data source of the pre-trained models, the applicable licenses, and determining if suitable for the intended use.
Example synthetic image
An example result from inference is shown below:
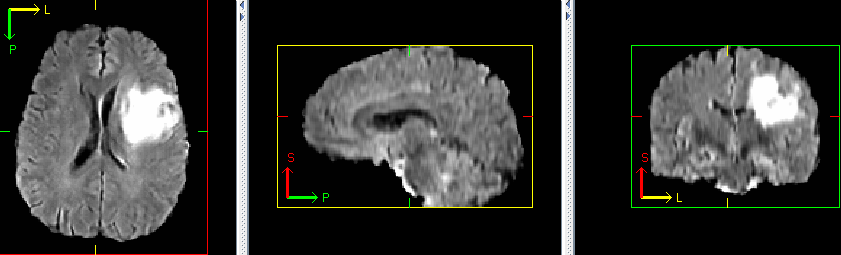
This is a demonstration network meant to just show the training process for this sort of network with MONAI. To achieve better performance, users need to use larger dataset like Brats 2021 and have GPU with memory larger than 32G to enable larger networks and attention layers.
MONAI Generative Model Dependencies
This bundle requires to install MONAI generative models.
Data
The training data is BraTS 2016 and 2017 from the Medical Segmentation Decathalon. Users can find more details on the dataset (Task01_BrainTumour) at http://medicaldecathlon.com/.
- Target: Image Generation
- Task: Synthesis
- Modality: MRI
- Size: 388 3D volumes (1 channel used)
Training Configuration
If you have a GPU with less than 32G of memory, you may need to decrease the batch size when training. To do so, modify the train_batch_size parameter in the configs/train_autoencoder.json and configs/train_diffusion.json configuration files.
Training Configuration of Autoencoder
The autoencoder was trained using the following configuration:
- GPU: at least 32GB GPU memory
- Actual Model Input: 112 x 128 x 80
- AMP: False
- Optimizer: Adam
- Learning Rate: 1e-5
- Loss: L1 loss, perceptual loss, KL divergence loss, adversarial loss, GAN BCE loss
Input
1 channel 3D MRI Flair patches
Output
- 1 channel 3D MRI reconstructed patches
- 8 channel mean of latent features
- 8 channel standard deviation of latent features
Training Configuration of Diffusion Model
The latent diffusion model was trained using the following configuration:
- GPU: at least 32GB GPU memory
- Actual Model Input: 36 x 44 x 28
- AMP: False
- Optimizer: Adam
- Learning Rate: 1e-5
- Loss: MSE loss
Training Input
- 8 channel noisy latent features
- a long int that indicates the time step
Training Output
8 channel predicted added noise
Inference Input
8 channel noise
Inference Output
8 channel denoised latent features
Memory Consumption Warning
If you face memory issues with data loading, you can lower the caching rate cache_rate in the configurations within range [0, 1] to minimize the System RAM requirements.
Performance
Training Loss
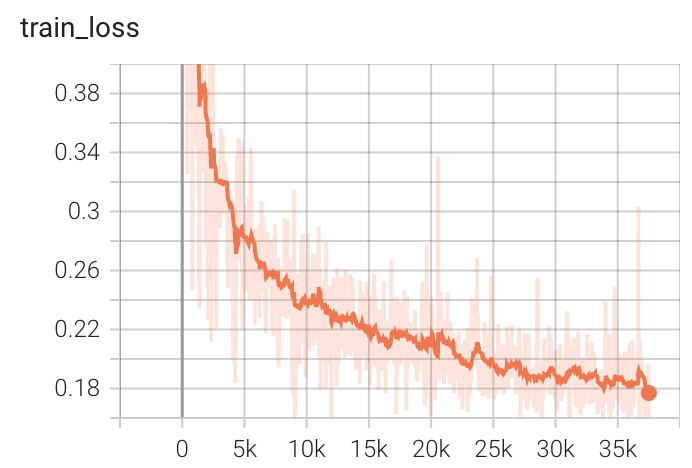
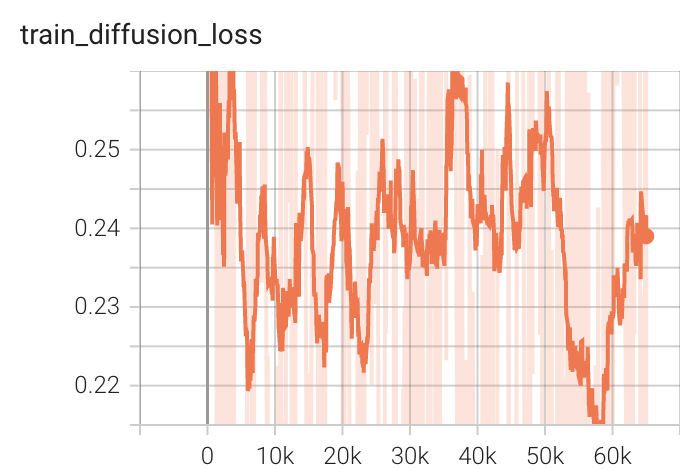
MONAI Bundle Commands
In addition to the Pythonic APIs, a few command line interfaces (CLI) are provided to interact with the bundle. The CLI supports flexible use cases, such as overriding configs at runtime and predefining arguments in a file.
For more details usage instructions, visit the MONAI Bundle Configuration Page.
Execute Autoencoder Training
Execute Autoencoder Training on single GPU
python -m monai.bundle run --config_file configs/train_autoencoder.json
Please note that if the default dataset path is not modified with the actual path (it should be the path that contains Task01_BrainTumour) in the bundle config files, you can also override it by using --dataset_dir:
python -m monai.bundle run --config_file configs/train_autoencoder.json --dataset_dir <actual dataset path>
Override the train config to execute multi-GPU training for Autoencoder
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/multi_gpu_train_autoencoder.json']" --lr 8e-5
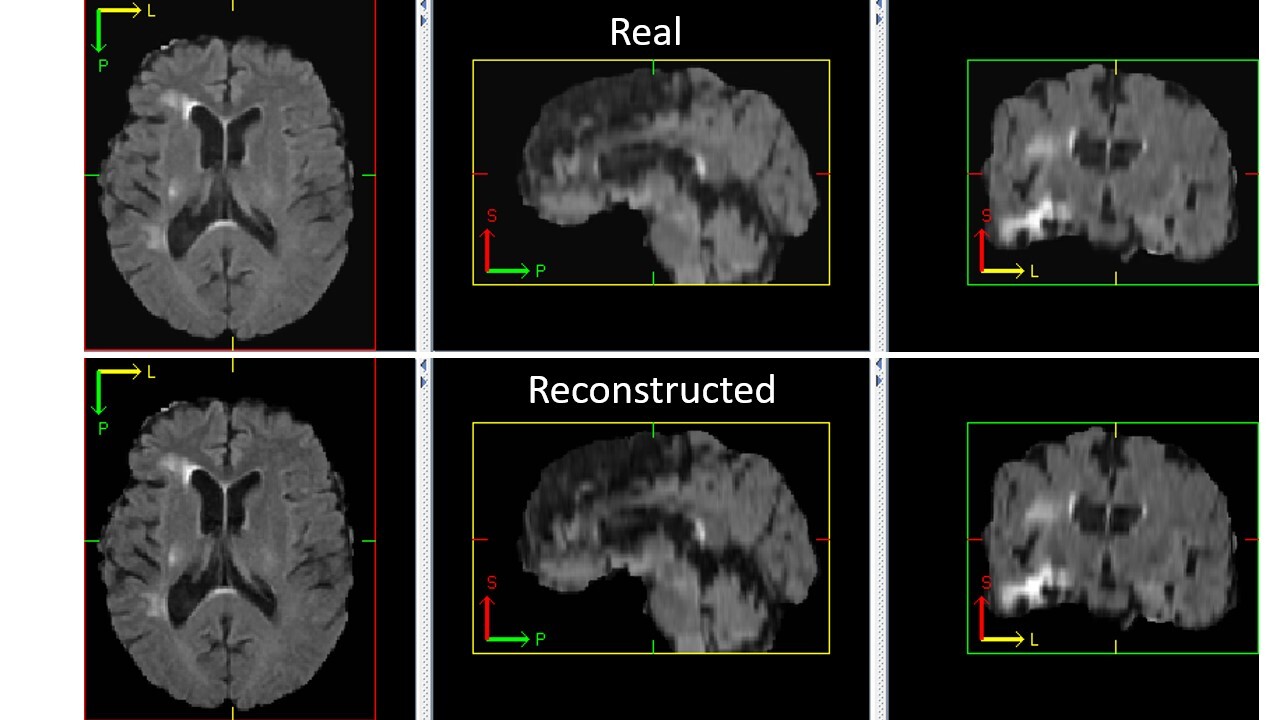
Check the Autoencoder Training result
The following code generates a reconstructed image from a random input image. We can visualize it to see if the autoencoder is trained correctly.
python -m monai.bundle run --config_file configs/inference_autoencoder.json
An example of reconstructed image from inference is shown below. If the autoencoder is trained correctly, the reconstructed image should look similar to original image.
Execute Latent Diffusion Training
Execute Latent Diffusion Model Training on single GPU
After training the autoencoder, run the following command to train the latent diffusion model. This command will print out the scale factor of the latent feature space. If your autoencoder is well trained, this value should be close to 1.0.
python -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json']"
Override the train config to execute multi-GPU training for Latent Diffusion Model
To train with multiple GPUs, use the following command, which requires scaling up the learning rate according to the number of GPUs.
torchrun --standalone --nnodes=1 --nproc_per_node=8 -m monai.bundle run --config_file "['configs/train_autoencoder.json','configs/train_diffusion.json','configs/multi_gpu_train_autoencoder.json','configs/multi_gpu_train_diffusion.json']" --lr 8e-5
Execute inference
The following code generates a synthetic image from a random sampled noise.
python -m monai.bundle run --config_file configs/inference.json
Export checkpoint to TorchScript file
The Autoencoder can be exported into a TorchScript file.
python -m monai.bundle ckpt_export autoencoder_def --filepath models/model_autoencoder.ts --ckpt_file models/model_autoencoder.pt --meta_file configs/metadata.json --config_file configs/inference.json
References
[1] Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
License
Copyright (c) MONAI Consortium
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.