
T5 base finetuned for Question Answering (QA) on SQUaD v1.1 Portuguese
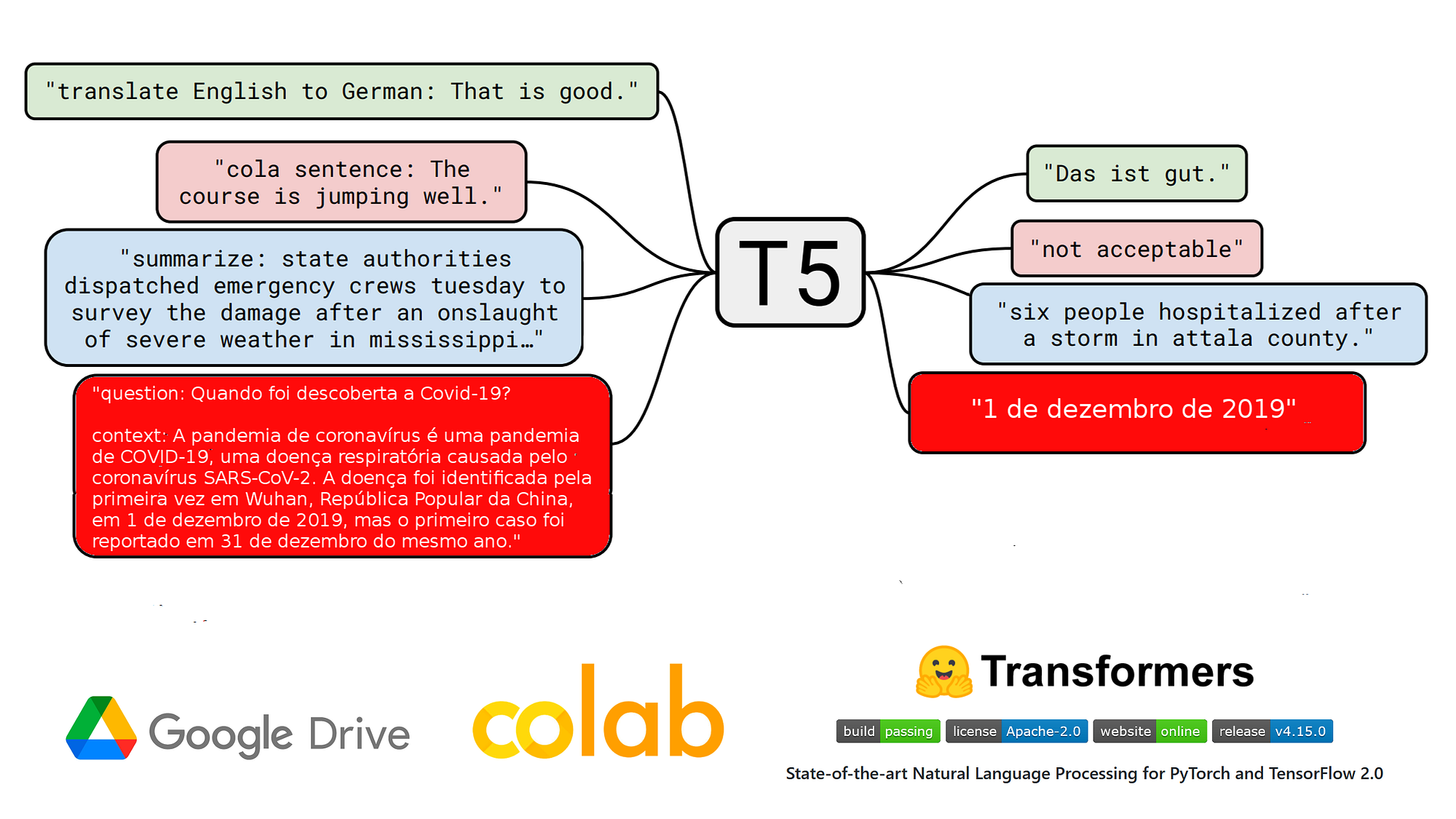
Introduction
t5-base-qa-squad-v1.1-portuguese is a QA model (Question Answering) in Portuguese that was finetuned on 27/01/2022 in Google Colab from the model unicamp-dl/ptt5-base-portuguese-vocab of Neuralmind on the dataset SQUAD v1.1 in portuguese from the Deep Learning Brasil group by using a Test2Text-Generation objective.
Due to the small size of T5 base and finetuning dataset, the model overfitted before to reach the end of training. Here are the overall final metrics on the validation dataset:
- f1: 79.3
- exact_match: 67.3983
Check our other QA models in Portuguese finetuned on SQUAD v1.1:
Blog post
NLP nas empresas | Como eu treinei um modelo T5 em português na tarefa QA no Google Colab (27/01/2022)
Widget & App
You can test this model into the widget of this page.
Use as well the QA App | T5 base pt that allows using the model T5 base finetuned on the QA task with the SQuAD v1.1 pt dataset.
Using the model for inference in production
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# model & tokenizer
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# parameters
max_target_length=32
num_beams=1
early_stopping=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs["input_ids"],
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping
)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
print('true answer |', label)
print('pred |', pred)
You can use pipeline, too. However, it seems to have an issue regarding to the max_length of the input sequence.
!pip install transformers
import transformers
from transformers import pipeline
# model
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
# parameters
max_target_length=32
num_beams=1
early_stopping=True
clean_up_tokenization_spaces=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
text2text = pipeline(
"text2text-generation",
model=model_name,
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping,
clean_up_tokenization_spaces=clean_up_tokenization_spaces
)
pred = text2text(input_text)
print('true answer |', label)
print('pred |', pred)
Training procedure
Notebook
The notebook of finetuning (HuggingFace_Notebook_t5-base-portuguese-vocab_question_answering_QA_squad_v11_pt.ipynb) is in github.
Hyperparameters
# do training and evaluation
do_train = True
do_eval= True
# batch
batch_size = 4
gradient_accumulation_steps = 3
per_device_train_batch_size = batch_size
per_device_eval_batch_size = per_device_train_batch_size*16
# LR, wd, epochs
learning_rate = 1e-4
weight_decay = 0.01
num_train_epochs = 10
fp16 = True
# logs
logging_strategy = "steps"
logging_first_step = True
logging_steps = 3000 # if logging_strategy = "steps"
eval_steps = logging_steps
# checkpoints
evaluation_strategy = logging_strategy
save_strategy = logging_strategy
save_steps = logging_steps
save_total_limit = 3
# best model
load_best_model_at_end = True
metric_for_best_model = "f1" #"loss"
if metric_for_best_model == "loss":
greater_is_better = False
else:
greater_is_better = True
# evaluation
num_beams = 1
Training results
Num examples = 87510
Num Epochs = 10
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 12
Gradient Accumulation steps = 3
Total optimization steps = 72920
Step Training Loss Exact Match F1
3000 0.776100 61.807001 75.114517
6000 0.545900 65.260170 77.468930
9000 0.460500 66.556291 78.491938
12000 0.393400 66.821192 78.745397
15000 0.379800 66.603595 78.815515
18000 0.298100 67.578051 79.287899
21000 0.303100 66.991485 78.979669
24000 0.251600 67.275307 78.929923
27000 0.237500 66.972564 79.333612
30000 0.220500 66.915799 79.236574
33000 0.182600 67.029328 78.964212
36000 0.190600 66.982025 79.086125
- Downloads last month
- 146
Datasets used to train pierreguillou/t5-base-qa-squad-v1.1-portuguese
Space using pierreguillou/t5-base-qa-squad-v1.1-portuguese 1
Evaluation results
- f1 on squadself-reported79.300
- exact-match on squadself-reported67.398