
Original model card
Buy me a coffee if you like this project ;)

Description
GGML Format model files for This project.
inference
import ctransformers
from ctransformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(output_dir, ggml_file,
gpu_layers=32, model_type="llama")
manual_input: str = "Tell me about your last dream, please."
llm(manual_input,
max_new_tokens=256,
temperature=0.9,
top_p= 0.7)
Original model card
Medical LLaMA-13B Model
基于LLaMA-13B的中英医疗问答模型
shibing624/ziya-llama-13b-medical-merged evaluate test data:
The overall performance of model on QA test:
| input_text | predict |
|---|---|
| 一岁宝宝发烧能吃啥药? | 孩子的身体是很脆弱的,如果不注意保护好自己就会出现各种疾病。有些家长在看到孩子生病后都非常着急,想要立刻给他们用药治疗,但其实并没有那么简单,因为每个人对于药物的敏感度和耐受性都是不同的,所以我们需要根据具体情况来选择合适的方法进行治疗才可以达到最佳效果。1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少,但也存在过量使用引起胃肠道损伤甚至消化道溃疡出血的风险;2、还有部分小儿退热药中含有扑尔敏等抗组胺药,它们本身属于处方药,应该严格按照医嘱服用,切勿擅自加减剂量或者延长用药时间;3、此外,某些小儿退热药中含有维生素C及葡萄糖酸钙等营养补充剂,只有当患儿伴随脱水症状(如口渴、尿色深)时才考虑添加,否则容易造成电解质紊乱。 |
在中文开放测试集中的表现优异,继承了两方面的优势:1)微调训练的底座是Ziya-LLaMA-13B模型,是较强的中英文底座模型,2)微调使用的是高质量240万条中英文医疗指令数据集,和多种通用指令数据集,微调后的模型在医疗行业答复能力达到领先水平,在通用问题上的答复能力不弱于LLaMA-13B。
Training details
training args:
{"per_device_train_batch_size": 8, "per_device_eval_batch_size": 8, "per_gpu_train_batch_size": null, "per_gpu_eval_batch_size": null, "gradient_accumulation_steps": 1, "eval_accumulation_steps": null, "eval_delay": 0, "learning_rate": 2e-05, "weight_decay": 0.0, "adam_beta1": 0.9, "adam_beta2": 0.999, "adam_epsilon": 1e-08, "max_grad_norm": 1.0, "num_train_epochs": 10.0, "max_steps": -1, "lr_scheduler_type": "linear", "warmup_ratio": 0.0, "warmup_steps": 50, "log_level": "passive", "log_level_replica": "warning", "log_on_each_node": true, "logging_dir": "outputs-ziya-llama-13b-sft-med-v2/logs", "logging_strategy": "steps", "logging_first_step": false, "logging_steps": 50, "logging_nan_inf_filter": true, "save_strategy": "steps", "save_steps": 50, "save_total_limit": 3, "save_safetensors": false, "save_on_each_node": false, "no_cuda": false, "use_mps_device": false, "seed": 42, "data_seed": null, "jit_mode_eval": false, "use_ipex": false, "bf16": false, "fp16": true, "fp16_opt_level": "O1", "half_precision_backend": "cuda_amp", "bf16_full_eval": false, "fp16_full_eval": false, "tf32": null, "local_rank": 0, "xpu_backend": null, "tpu_num_cores": null, "tpu_metrics_debug": false, "debug": [], "dataloader_drop_last": false, "eval_steps": 50, "dataloader_num_workers": 0, "past_index": -1, "run_name": "outputs-ziya-llama-13b-sft-med-v2", "disable_tqdm": false, "remove_unused_columns": false, "label_names": null, "load_best_model_at_end": true, "metric_for_best_model": "loss", "greater_is_better": false, "ignore_data_skip": false, "sharded_ddp": [], "fsdp": [], "fsdp_min_num_params": 0, "fsdp_config": { "fsdp_min_num_params": 0, "xla": false, "xla_fsdp_grad_ckpt": false }, "fsdp_transformer_layer_cls_to_wrap": null, "deepspeed": null, "label_smoothing_factor": 0.0, "optim": "adamw_torch", "optim_args": null, "adafactor": false, "group_by_length": false, "length_column_name": "length", "report_to": [ "tensorboard" ], "ddp_find_unused_parameters": false, "ddp_bucket_cap_mb": null, "dataloader_pin_memory": true, "skip_memory_metrics": true, "use_legacy_prediction_loop": false, "push_to_hub": false, "resume_from_checkpoint": null, "hub_model_id": null, "hub_strategy": "every_save", "hub_token": "<hub_token>", "hub_private_repo": false, "gradient_checkpointing": false, "include_inputs_for_metrics": false, "fp16_backend": "auto", "push_to_hub_model_id": null, "push_to_hub_organization": null, "push_to_hub_token": "<push_to_hub_token>", "mp_parameters": "", "auto_find_batch_size": false, "full_determinism": false, "torchdynamo": null, "ray_scope": "last", "ddp_timeout": 1800, "torch_compile": false, "torch_compile_backend": null, "torch_compile_mode": null }
train loss:
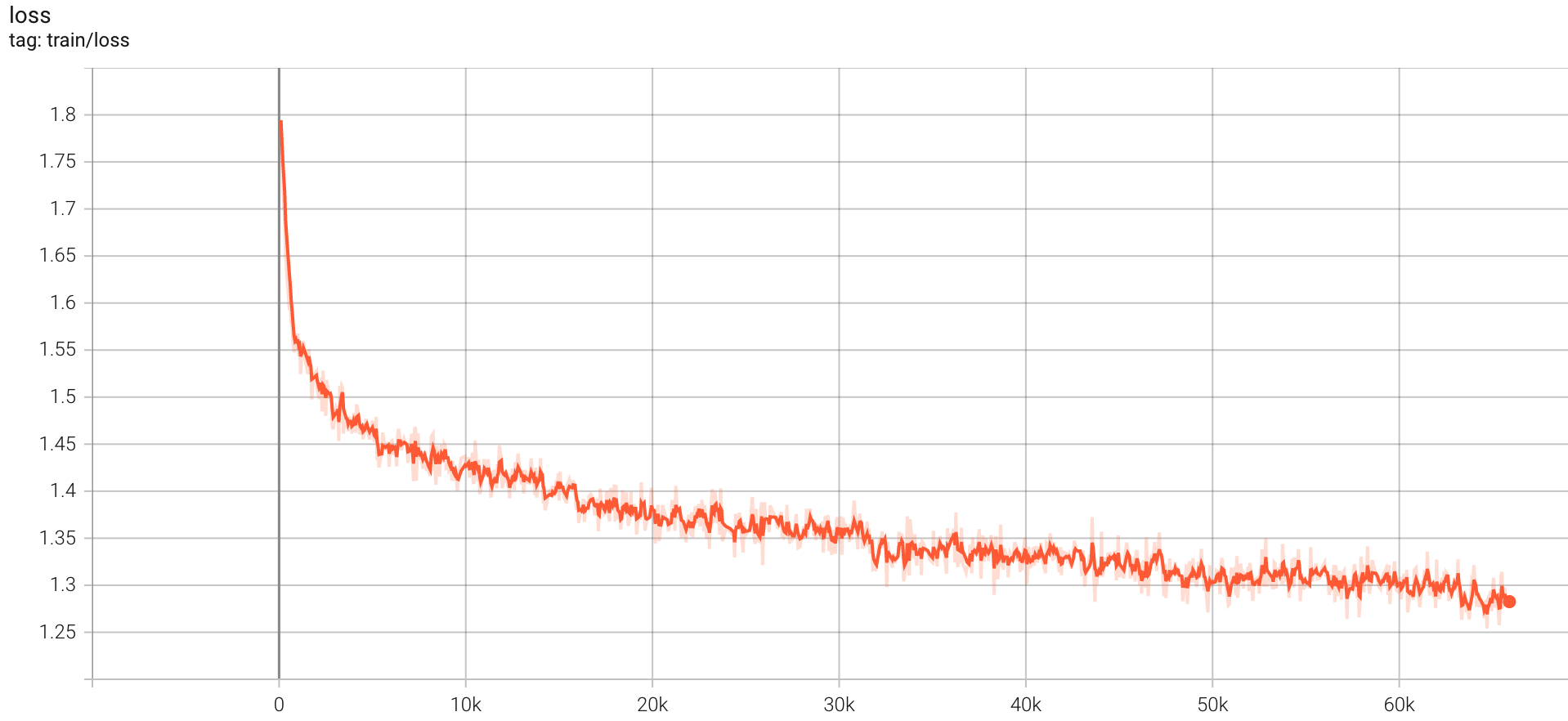
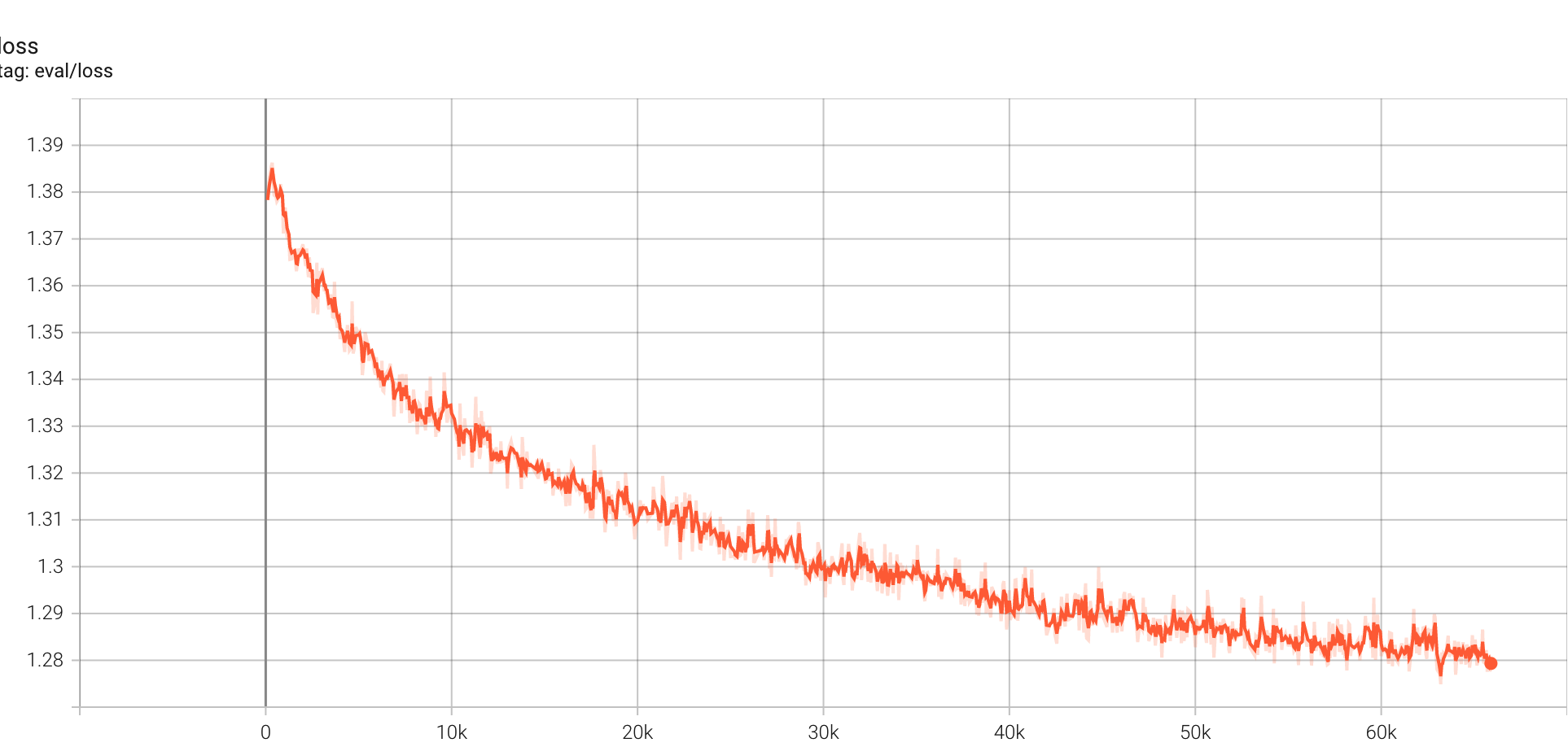
evaluate loss:
Usage
本项目开源在 github repo:
使用textgen库:textgen,可调用LLaMA模型:
Install package:
pip install -U textgen
from textgen import GptModel
def generate_prompt(instruction):
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:{instruction}\n\n### Response: """
model = GptModel("llama", "shibing624/ziya-llama-13b-medical-merged")
predict_sentence = generate_prompt("一岁宝宝发烧能吃啥药?")
r = model.predict([predict_sentence])
print(r) # ["1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少..."]
Usage (HuggingFace Transformers)
Without textgen, you can use the model like this:
First, you pass your input through the transformer model, then you get the generated sentence.
Install package:
pip install transformers
import sys
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("shibing624/ziya-llama-13b-medical-merged", device_map='auto')
tokenizer = LlamaTokenizer.from_pretrained("shibing624/ziya-llama-13b-medical-merged")
device = "cuda" if torch.cuda.is_available() else "cpu"
def generate_prompt(instruction):
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:{instruction}\n\n### Response: """
sents = ['一岁宝宝发烧能吃啥药', "who are you?"]
for s in sents:
q = generate_prompt(s)
inputs = tokenizer(q, return_tensors="pt")
inputs = inputs.to(device=device)
generate_ids = ref_model.generate(
**inputs,
max_new_tokens=120,
do_sample=True,
top_p=0.85,
temperature=1.0,
repetition_penalty=1.0,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.batch_decode(generate_ids, skip_special_tokens=True)[0]
print(output)
print()
output:
一岁宝宝发烧能吃啥药
孩子的身体是很脆弱的,如果不注意保护好自己就会出现各种疾病。有些家长在看到孩子生病后都非常着急,想要立刻给他们用药治疗,但其实并没有那么简单,因为每个人对于药物的敏感度和耐受性都是不同的,所以我们需要根据具体情况来选择合适的方法进行治疗才可以达到最佳效果。1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少,但也存在过量使用引起胃肠道损伤甚至消化道溃疡出血的风险;2、还有部分小儿退热药中含有扑尔敏等抗组胺药,它们本身属于处方药,应该严格按照医嘱服用,切勿擅自加减剂量或者延长用药时间;3、此外,某些小儿退热药中含有维生素C及葡萄糖酸钙等营养补充剂,只有当患儿伴随脱水症状(如口渴、尿色深)时才考虑添加,否则容易造成电解质紊乱。
模型文件组成:
ziya-llama-13b-medical-merged
|-- added_tokens.json
|-- config.json
|-- generation_config.json
|-- pytorch_model-00001-of-00003.bin
|-- pytorch_model-00002-of-00003.bin
|-- pytorch_model-00003-of-00003.bin
|-- pytorch_model.bin.index.json
|-- README.md
|-- special_tokens_map.json
|-- tokenizer_config.json
`-- tokenizer.model
Inference Examples
| Human | Assitant |
|---|---|
| 小孩发烧怎么办 | 宝宝的抵抗力是比较差的,所以很容易就会出现感冒或者其他疾病。如果宝宝在平时没有注意保暖,那么也可能导致身体受凉而引起了感冒等症状,这样不仅对于健康造成影响,还可能让宝宝出现高热的情况。因此当家长们发现自己的宝宝出现了高热的问题之后一定要及早进行治疗和护理才好。 1、首先我们应该给宝宝服用退烧药物来帮助降温,但是千万不要盲目使用退烧药物,否则只会加重宝宝的病情,最好带着宝宝到医院去检查清楚具体原因之后再针对性地采取措施处理。 2、另外大人们也需要做好预防工作,尤其是天气变化的时候更应该多关心下宝宝的身体状态,避免宝宝受寒受凉从而诱发各种疾病,同时也要尽量减少宝宝接触细菌病毒的机会,增强宝宝的免疫力。 3、除了上面两点之外,大人们还可以通过按摩推拿穴位的方式来缓解宝宝的病痛,促进血液循环,提升新陈代谢速度,达到快速消炎止疼的效果 |
| 一岁宝宝发烧能吃啥药? | 孩子的身体是很脆弱的,如果不注意保护好自己就会出现各种疾病。有些家长在看到孩子生病后都非常着急,想要立刻给他们用药治疗,但其实并没有那么简单,因为每个人对于药物的敏感度和耐受性都是不同的,所以我们需要根据具体情况来选择合适的方法进行治疗才可以达到最佳效果。1、首先大多数小儿退热药中含有解热镇痛成分阿司匹林或布洛芬等,这类药品虽然副作用较少,但也存在过量使用引起胃肠道损伤甚至消化道溃疡出血的风险;2、还有部分小儿退热药中含有扑尔敏等抗组胺药,它们本身属于处方药,应该严格按照医嘱服用,切勿擅自加减剂量或者延长用药时间;3、此外,某些小儿退热药中含有维生素C及葡萄糖酸钙等营养补充剂,只有当患儿伴随脱水症状(如口渴、尿色深)时才考虑添加,否则容易造成电解质紊乱。 |
| 肛门病变可能是什么疾病的症状 | 痔疮、直肠息肉等。 |
| 医生,您好白带增多泛黄怎么回事? | 你这种情况考虑可能会是阴道炎症引起的建议平时留意卫生清洁,勤换洗衣物内裤,必要时去正规公立医院妇科复诊做分泌物常规等相关检查明确病因后对症治疗,不同原因所致的疾病在临床表现上也存在差异性,如果患者出现了类似于的症状应当及早到专业、权威的医院进行详细的检验和救治 |
| 药流后有巧克力白带是没流干净吗 | 在日常生活中,我们要或多或少了解一些常见疾病的相关知识,不仅能起到增加知识水平的作用,更能让自己更好地预防此类疾病的产生。很多女性都会出现月经紊乱、腹痛等症状,这时候就需要考虑妇科炎症可能,比如说宫颈糜烂和盆腔积液。那么下面小编来给大家介绍一种情况:药物流产后白带呈巧克力色怎么回事?1、首先,对于药物流产之后发现阴道分泌物异常,应该及时去医院做检查确诊具体原因,然后再根据结果进行治疗调理。2、其次,由于每个人身体素质以及患病程度存在差别,所以采取的措施也不尽相同,但无论选择哪种方式处理,都必须严格按照规定剂量服用,并且注意观察副作用反映情况,若出现明显不适感觉,则应立即停止使用。3、最后,建议你保持外阴清洁卫生,勤换内裤,避免吃辛辣刺激食品,而且还要禁忌房事,否则容易引起交叉感染影响恢复健康。 |
| 维胺酯维E乳膏能治理什么疾病 | 皮肤淀粉样变性;脂溢性角化症 |
| 痤疮是什么原因导致的? | 痤疮,又称青春痘、粉刺。它主要发生在面部和胸背部位,表现为黑头粉刺、白头粉刺、丘疹、脓疱、结节等多种形式。其中以黑头粉刺最常见,约占全身皮肤病患者的70%左右。那么,痤疮是什么原因引起的呢?下面就给大家介绍一些相关内容。1、雄性激素分泌过旺:男女都会长痘痘,但是女孩子比较喜欢用化妆品来掩盖脸上的问题,而且很多人不知道这样做反而加重了自己的毛囊炎症状,所以说平时应该少使用含有雌激素类的产品。2、饮食习惯差:经常吃辛辣油腻的东西或者甜食也可能造成体内毒素堆积,从而诱发痤疮。3、压力太大:如果你总是处于紧张焦虑的情绪之中,同时还没有及时调整好心态,那么很容易出现内分泌失调的情况,进而影响到肌肤健康。4、睡眠质量差:熬夜对我们的身体伤害非常严重,尤其是对于年轻人群更甚,他们需要保证充足的睡眠才行,否则很容易让肌肤变得暗沉无光泽。 |
| 脸上长青春痘怎么办,能吃啥药,需要注意啥 | 你好,根据您的描述考虑是痤疮。建议外用维胺酯乳膏或者阿达帕林凝胶进行治疗看看,平时禁忌辛辣和刺激性食物,如海鲜、狗肉、羊肉等“发”动品,以及葱蒜韭姜等刺激性调料。多喝水,少吃油腻高热量食物。 |
| 由于输精管堵塞会不会导致男性不育?,医生您好,我同事这几天不开心,我问她怎么了,她说她老公输精管堵塞,所以一直没孩子,不是不想要,请问输精管堵塞会不会导致男性不育? | 你好!根据你的叙述及症状推测:如果有输精管阻塞或者狭窄等情况都可能会引来无法排出来精液而影响怀上。建议到正规专业的快孕医院实施进行咨询和治疗为宜。对于输精管患者来说,及时救治是可以减低病发,如果不及时救治会影响到受孕情况。因此患者要及时药物救治,并且日常生活中要多看重自身护理 |
| 心肌梗塞能治疗吗? | 心脏病是一种危害性极大的疾病,我们要对它有足够多的了解。在生活中很多人都会患上这个疾病,而且还不知道怎么去预防和护理,所以就导致自己的身体越来越差,那么下面小编给你介绍几点关于心脏病的常识吧!1、冠状动脉粥样硬化性心脏病:又称为冠心病或缺血型心脏病(IHD),是世界各地最重要的死亡原因之一。2、风湿热:主要侵犯心脏瓣膜,可引起二尖瓣狭窄及其他类型的心脏瓣膜病变;3、先天性心脏病:包括房间隔缺损、室间隔缺损等;4、高脂蛋白血症:由于胆固醇与低密度脂蛋白升高,使得动脉壁增厚,管腔缩小,易形成斑块并脱落造成急性栓塞;5、肥胖:过量摄入食物,特别是含糖饮料,加速脂肪堆积,促进动脉粥样硬化发展;6、吸烟:尼古丁刺激交感神经兴奋,使外周阻力增强,收缩压升高,舒张期减短,从而降低左右心室射血分数,诱发心律失常;7、酗酒:长期嗜酒者,肝功受到影响,代谢紊乱,容易出现脂质代谢异常。 |
| 怎么让自己精力充沛,列5点建议 | 1、保证睡眠质量:每天晚上7-8小时的高质量睡眠是提升身体和大脑活跃度最有效的方法。2、合理饮食:均衡营养摄入对于维持人体正常运转至关重要,多吃蔬菜水果,少油腻辛辣刺激性食物。3、适当锻炼:坚持一定强度的锻炼可以促进血液循环,增加肌肉耐力,改善心肺功能等。4、学习新知识:不断接触新事物,开拓视野,思考问题,都会使得我们更具创造力与灵感。5、放松心情:通过冥想或者瑜伽来缓解压力,也可以听音乐或看电影来调节情绪。 |
| 写个春天的诗 | 春风吹拂,花儿绽放。 阳光明媚,鸟语鸣叫。 树木抽芽,草地变绿。 万物复苏,生机勃发。 |
| 南极洲为啥没有北极熊? | 南极是世界上最大的冰盖,覆盖着98%以上的地球表面积。它位于南纬60度至74度之间,环绕在海洋中心周围。由于其独特的气候条件和生态系统,南极被称为“真正的荒野”。南极洲拥有丰富多样的动植物资源,但这里并不存在北极熊。 那么,为什么南极洲没有北极熊呢?首先,我们需要了解一下两者栖息地的差异。北极熊主要分布在北半球寒冷的高纬度地区,如加拿大、格陵兰岛等地。而南极洲则处于南半球,属于温带或寒带气候类型。虽然南极洲也有很低的平均气温(-25℃左右),但与北极相比还是太热了。因此,即使北极熊能够适应更严酷的气候条件,它们也无法在南极找到合适的栖息地。另外,南极洲缺乏陆地哺乳动物食物来源,包括鱼类、鲸鱼和企鹅等。尽管南极洲的水域中也有各种鱼类,但数量远少于北极圈内。同时,南极洲的土著居民——企鹅群体繁殖季节期间会消耗掉大部分可用的食物资源,导致当地的鱼类数量减少甚至枯竭。 |
训练数据集
- 50万条中文ChatGPT指令Belle数据集:BelleGroup/train_0.5M_CN
- 100万条中文ChatGPT指令Belle数据集:BelleGroup/train_1M_CN
- 5万条英文ChatGPT指令Alpaca数据集:50k English Stanford Alpaca dataset
- 2万条中文ChatGPT指令Alpaca数据集:shibing624/alpaca-zh
- 69万条中文指令Guanaco数据集(Belle50万条+Guanaco19万条):Chinese-Vicuna/guanaco_belle_merge_v1.0
- 240万条中文医疗数据集(包括预训练数据和指令微调数据集):shibing624/medical
如果需要训练ChatGLM/LLAMA/BLOOM模型,请参考https://github.com/shibing624/textgen
Citation
@software{textgen,
author = {Ming Xu},
title = {textgen: Implementation of language model finetune},
year = {2023},
url = {https://github.com/shibing624/textgen},
}
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.