
Typhoon T | Typhoon R
Collection
Our Typhoon reasoning research model series
•
2 items
•
Updated
Typhoon2-DeepSeek-R1-70B: Thai reasoning large language model. (research preview)
Typhoon2-DeepSeek-R1-70B is a Thai 🇹🇭 reasoning large language model with 70 billion parameters, and it is based on DeepSeek R1 70B Distill and Typhoon2 70B Instruct + SFT merged.
For more details, please see our blog. Demo on opentyphoon.ai.
The paper is coming soon.
*To acknowledge Meta's effort in creating the foundation model and to comply with the license, we explicitly include "llama-3.1" in the model name.
Reasoning Performance
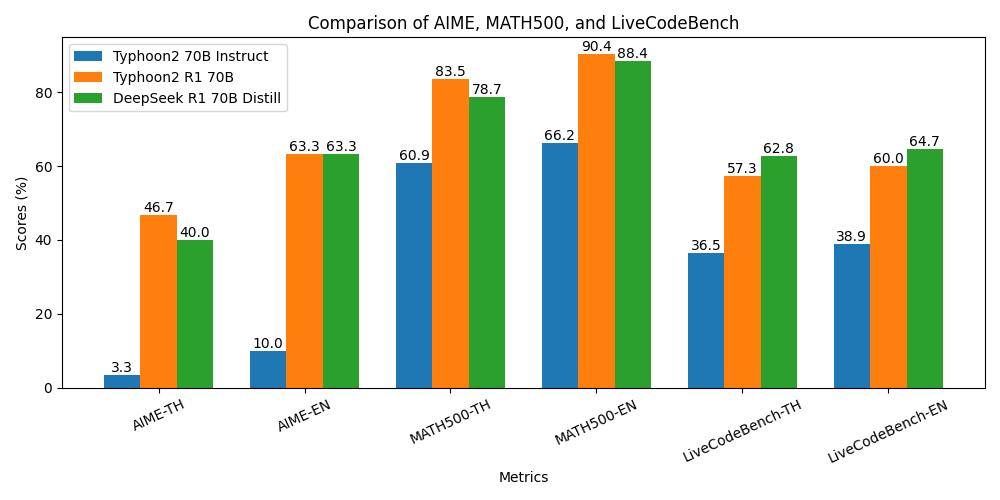
General Instruction-Following Performance
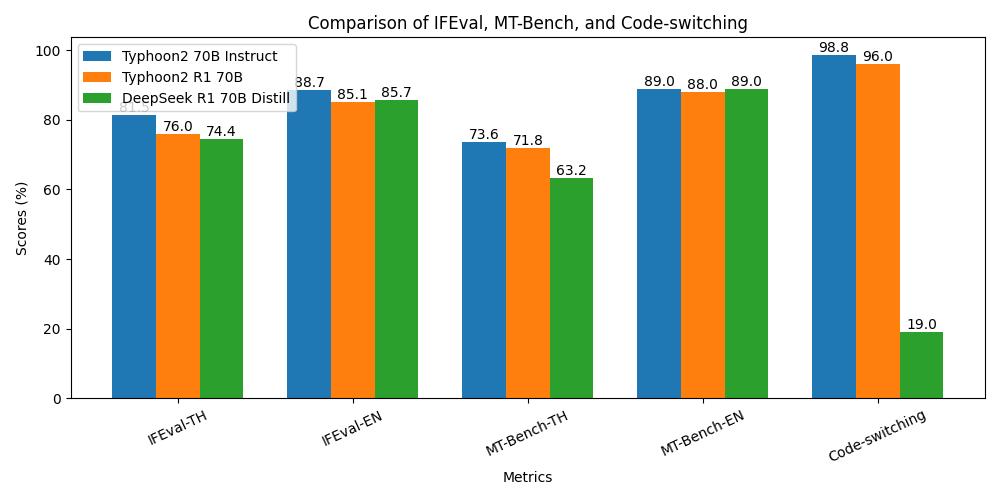
More controllable | less reasoning capability
You are a helpful assistant named Typhoon that always reasons before answering. First, provide reasoning in English, starting with "Alright!" and ending with the `</think>` token. Then, always respond to the user in the language they use or request. Avoid unnecessary affirmations or filler phrases such as "Alright", "Okay", etc., in the response.
More reasoning capability | less controllable
You are a helpful assistant named Typhoon that always reasons before answering. First, provide reasoning in English start with Alright!, then respond to the user in the language they use or request.
Highest reasoning capability | least controllable
# No system prompt
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/llama3.1-typhoon2-deepseek-r1-70b-preview"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": 'You are a helpful assistant named Typhoon that always reasons before answering. First, provide reasoning in English, starting with "Alright!" and ending with the `</think>` token. Then, always respond to the user in the language they use or request. Avoid unnecessary affirmations or filler phrases such as "Alright", "Okay", etc., in the response'},
{"role": "user", "content": "จำนวนเต็มบวกที่น้อยที่สุดที่เป็นผลคูณของ 30 ซึ่งสามารถเขียนได้ด้วยตัวเลข 0 และ 2 เท่านั้นคืออะไร"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.7,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
# if you want only response without thinking trace. try `tokenizer.decode(response, skip_special_tokens=True).split('</think>')[-1]` to get only response
print(tokenizer.decode(response, skip_special_tokens=True)) # <think> Okay, .... </think> ดังนั้น จำนวนเต็มบวกที่น้อยที่สุดที่เป็นผลคูณของ 30 และเขียนได้ด้วยตัวเลข 0 และ 2 เท่านั้นคือ 2220 boxed{2220}
pip install vllm
vllm serve scb10x/llama3.1-typhoon2-deepseek-r1-70b-preview --tensor-parallel-size 2 --gpu-memory-utilization 0.95 --max-model-len 16384 --enforce-eager
# using at least 2 80GB gpu eg A100, H100 for hosting 70b model
# to serving longer context (90k), 4 gpu is required (and you can omit --enforce-eager to improve throughput)
# see more information at https://docs.vllm.ai/
This model is using the DeepSeek R1 70B Distill chat template, not the Llama 3 template. Be careful.
{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|><think>\\n'}}{% endif %}
We don't recommend using tool use on this model.
This model is an reasoning instructional model. However, it’s still undergoing development. It incorporates some level of guardrails, but it still may produce answers that are inaccurate, biased, or otherwise objectionable in response to user prompts. We recommend that developers assess these risks in the context of their use case.
https://twitter.com/opentyphoon
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}