
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
base_model:
- arcee-ai/Virtuoso-Small
- CultriX/SeQwence-14B-EvolMerge
- CultriX/Qwen2.5-14B-Wernicke
- sometimesanotion/lamarck-14b-prose-model_stock
- sometimesanotion/lamarck-14b-if-model_stock
- sometimesanotion/lamarck-14b-reason-model_stock
language:
- en

Overview:
Lamarck-14B version 0.3 is the product of a custom toolchain built around multi-stage templated merges, with an end-to-end strategy for giving each ancestor model priority where it's most effective. It is strongly based on arcee-ai/Virtuoso-Small as a diffuse influence for prose and reasoning. Arcee's pioneering use of distillation and innovative merge techniques create a diverse knowledge pool for its models.
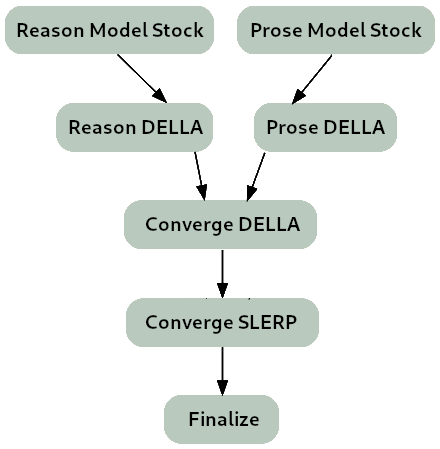
** The merge strategy of Lamarck 0.3 can be summarized as:**
- Two model_stocks used to begin specialized branches for reasoning and prose quality.
- For refinement on Virtuoso as a base model, DELLA and SLERP include the model_stocks while re-emphasizing selected ancestors.
- For integration, a SLERP merge of Virtuoso with the converged branches.
- For finalization, a TIES merge.
While most censorship is unwelcome in Lamarck, and the author believes that adjacent services and not language models themselves are where guardrails are best placed, no effort has been made to de-censor this release of Lamarck. That is reserved for future merges and fine-tuning.
Thanks go to:
- @arcee-ai's team for the bounties of mergekit and the exceptional Virtuoso Small model
- @CultriX for the helpful examples of memory-efficient sliced merges and evolutionary merging. Their contribution of tinyevals on version 0.1 of Lamarck did much to validate the hypotheses of the process used here.
Ancestor Models:
Top influences: These ancestors are base models and present in the model_stocks, but are heavily re-emphasized in the DELLA and SLERP merges.
arcee-ai/Virtuoso-Small - A brand new model from Arcee, refined from the notable cross-architecture Llama-to-Qwen distillation arcee-ai/SuperNova-Medius. The first two layers are nearly exclusively from Virtuoso. It has proven to be a well-rounded performer, and contributes a noticeable boost to the model's prose quality.
CultriX/SeQwence-14B-EvolMerge - A well-rounded model, with interesting gains for instruction following while remaining strong for reasoning.
CultriX/Qwen2.5-14B-Wernicke - A top performer for Arc and GPQA, Wernicke is re-emphasized in small but highly-ranked portions of the model.
Merge YAML:
name: lamarck-14b-reason-della # This contributes the knowledge and reasoning pool, later to be merged
merge_method: della # with the dominant instruction-following model
base_model: arcee-ai/Virtuoso-Small
tokenizer_source: arcee-ai/Virtuoso-Small
parameters:
int8_mask: false
normalize: true
rescale: false
density: 0.30
weight: 0.50
epsilon: 0.08
lambda: 1.00
models:
- model: CultriX/SeQwence-14B-EvolMerge
parameters:
density: 0.70
weight: 0.90
- model: sometimesanotion/lamarck-14b-reason-model_stock
parameters:
density: 0.90
weight: 0.60
- model: CultriX/Qwen2.5-14B-Wernicke
parameters:
density: 0.20
weight: 0.30
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-prose-della # This contributes the prose, later to be merged
merge_method: della # with the dominant instruction-following model
base_model: arcee-ai/Virtuoso-Small
tokenizer_source: arcee-ai/Virtuoso-Small
parameters:
int8_mask: false
normalize: true
rescale: false
density: 0.30
weight: 0.50
epsilon: 0.08
lambda: 0.95
models:
- model: sthenno-com/miscii-14b-1028
parameters:
density: 0.40
weight: 0.90
- model: sometimesanotion/lamarck-14b-prose-model_stock
parameters:
density: 0.60
weight: 0.70
- model: underwoods/medius-erebus-magnum-14b
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-converge-della # This is the strongest control point to quickly
merge_method: della # re-balance reasoning vs. prose
base_model: arcee-ai/Virtuoso-Small
tokenizer_source: arcee-ai/Virtuoso-Small
parameters:
int8_mask: false
normalize: true
rescale: false
density: 0.30
weight: 0.50
epsilon: 0.08
lambda: 1.00
models:
- model: sometimesanotion/lamarck-14b-reason-della
parameters:
density: 0.80
weight: 1.00
- model: arcee-ai/Virtuoso-Small
parameters:
density: 0.40
weight: 0.50
- model: sometimesanotion/lamarck-14b-prose-della
parameters:
density: 0.10
weight: 0.40
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-converge # Virtuoso has good capabilities all-around; it is 100% of the first
merge_method: slerp # two layers, and blends into the reasoning+prose convergance
base_model: arcee-ai/Virtuoso-Small # for some interesting boosts
tokenizer_source: base
parameters:
t: [ 0.00, 0.60, 0.80, 0.80, 0.80, 0.70, 0.40 ]
slices:
- sources:
- layer_range: [ 0, 2 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 0, 2 ]
model: merges/lamarck-14b-converge-della
t: [ 0.00, 0.00 ]
- sources:
- layer_range: [ 2, 8 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 2, 8 ]
model: merges/lamarck-14b-converge-della
t: [ 0.00, 0.60 ]
- sources:
- layer_range: [ 8, 16 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 8, 16 ]
model: merges/lamarck-14b-converge-della
t: [ 0.60, 0.70 ]
- sources:
- layer_range: [ 16, 24 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 16, 24 ]
model: merges/lamarck-14b-converge-della
t: [ 0.70, 0.70 ]
- sources:
- layer_range: [ 24, 32 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 24, 32 ]
model: merges/lamarck-14b-converge-della
t: [ 0.70, 0.70 ]
- sources:
- layer_range: [ 32, 40 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 32, 40 ]
model: merges/lamarck-14b-converge-della
t: [ 0.70, 0.60 ]
- sources:
- layer_range: [ 40, 48 ]
model: arcee-ai/Virtuoso-Small
- layer_range: [ 40, 48 ]
model: merges/lamarck-14b-converge-della
t: [ 0.60, 0.40 ]
dtype: bfloat16
out_dtype: bfloat16
---
name: lamarck-14b-finalize
merge_method: ties
base_model: Qwen/Qwen2.5-14B
tokenizer_source: Qwen/Qwen2.5-14B-Instruct
parameters:
int8_mask: false
normalize: true
rescale: false
density: 1.00
weight: 1.00
models:
- model: merges/lamarck-14b-converge
dtype: bfloat16
out_dtype: bfloat16
---