|
--- |
|
language: |
|
- en |
|
license: apache-2.0 |
|
library_name: transformers |
|
tags: |
|
- mergekit |
|
- merge |
|
base_model: |
|
- arcee-ai/Virtuoso-Small |
|
- CultriX/SeQwence-14B-EvolMerge |
|
- CultriX/Qwen2.5-14B-Wernicke |
|
- sthenno-com/miscii-14b-1028 |
|
- underwoods/medius-erebus-magnum-14b |
|
- sometimesanotion/lamarck-14b-prose-model_stock |
|
- sometimesanotion/lamarck-14b-reason-model_stock |
|
metrics: |
|
- accuracy |
|
pipeline_tag: text-generation |
|
model-index: |
|
- name: Lamarck-14B-v0.3 |
|
results: |
|
- task: |
|
type: text-generation |
|
name: Text Generation |
|
dataset: |
|
name: IFEval (0-Shot) |
|
type: HuggingFaceH4/ifeval |
|
args: |
|
num_few_shot: 0 |
|
metrics: |
|
- type: inst_level_strict_acc and prompt_level_strict_acc |
|
value: 50.32 |
|
name: strict accuracy |
|
source: |
|
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=sometimesanotion/Lamarck-14B-v0.3 |
|
name: Open LLM Leaderboard |
|
- task: |
|
type: text-generation |
|
name: Text Generation |
|
dataset: |
|
name: BBH (3-Shot) |
|
type: BBH |
|
args: |
|
num_few_shot: 3 |
|
metrics: |
|
- type: acc_norm |
|
value: 51.27 |
|
name: normalized accuracy |
|
source: |
|
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=sometimesanotion/Lamarck-14B-v0.3 |
|
name: Open LLM Leaderboard |
|
- task: |
|
type: text-generation |
|
name: Text Generation |
|
dataset: |
|
name: MATH Lvl 5 (4-Shot) |
|
type: hendrycks/competition_math |
|
args: |
|
num_few_shot: 4 |
|
metrics: |
|
- type: exact_match |
|
value: 32.4 |
|
name: exact match |
|
source: |
|
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=sometimesanotion/Lamarck-14B-v0.3 |
|
name: Open LLM Leaderboard |
|
- task: |
|
type: text-generation |
|
name: Text Generation |
|
dataset: |
|
name: GPQA (0-shot) |
|
type: Idavidrein/gpqa |
|
args: |
|
num_few_shot: 0 |
|
metrics: |
|
- type: acc_norm |
|
value: 18.46 |
|
name: acc_norm |
|
source: |
|
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=sometimesanotion/Lamarck-14B-v0.3 |
|
name: Open LLM Leaderboard |
|
- task: |
|
type: text-generation |
|
name: Text Generation |
|
dataset: |
|
name: MuSR (0-shot) |
|
type: TAUR-Lab/MuSR |
|
args: |
|
num_few_shot: 0 |
|
metrics: |
|
- type: acc_norm |
|
value: 18.0 |
|
name: acc_norm |
|
source: |
|
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=sometimesanotion/Lamarck-14B-v0.3 |
|
name: Open LLM Leaderboard |
|
- task: |
|
type: text-generation |
|
name: Text Generation |
|
dataset: |
|
name: MMLU-PRO (5-shot) |
|
type: TIGER-Lab/MMLU-Pro |
|
config: main |
|
split: test |
|
args: |
|
num_few_shot: 5 |
|
metrics: |
|
- type: acc |
|
value: 49.01 |
|
name: accuracy |
|
source: |
|
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=sometimesanotion/Lamarck-14B-v0.3 |
|
name: Open LLM Leaderboard |
|
--- |
|
 |
|
--- |
|
|
|
# merge |
|
|
|
Lamarck-14B is a carefully designed merge which emphasizes [arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small) in early and finishing layers, and midway features strong influence on reasoning and prose from [CultriX/SeQwence-14B-EvolMerge](http://huggingface.co/CultriX/SeQwence-14B-EvolMerge) especially, but a number of other models as well through its model_stock. |
|
|
|
Version 0.3 is the product of a carefully planned and tested sequence of templated merges, produced by a toolchain which wraps around Arcee's mergekit. |
|
|
|
For GGUFs, [mradermacher/Lamarck-14B-v0.3-i1-GGUF](https://huggingface.co/mradermacher/Lamarck-14B-v0.3-i1-GGUF) has you covered. Thank you @mradermacher! |
|
|
|
**The merge strategy of Lamarck 0.3 can be summarized as:** |
|
|
|
- Two model_stocks commence specialized branches for reasoning and prose quality. |
|
- For refinement on both model_stocks, DELLA merges re-emphasize selected ancestors. |
|
- For smooth instruction following, a SLERP merges Virtuoso with a DELLA merge of the two branches, where reason vs. prose quality are balanced. |
|
- For finalization and normalization, a TIES merge. |
|
|
|
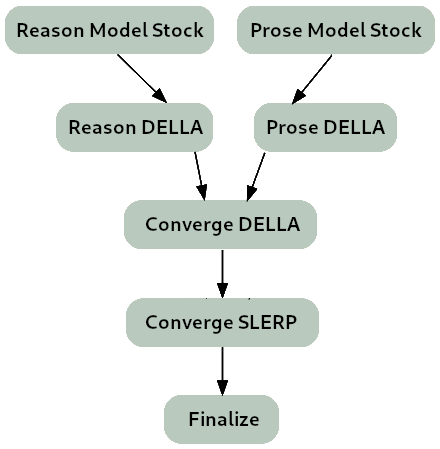 |
|
|
|
The first two layers come entirely from Virtuoso. The choice to leave these layers untouched comes from [arxiv.org/abs/2307.03172](https://arxiv.org/abs/2307.03172) which identifies early attention glitches as a chief cause of hallucinations. Layers 3-8 feature a SLERP gradient into introducing the DELLA merge tree in which the reason branch is emphasized, the prose branch only given a small ranking. |
|
|
|
### Thanks go to: |
|
|
|
- @arcee-ai's team for the ever-capable mergekit, and the exceptional Virtuoso Small model. |
|
- @CultriX for the helpful examples of memory-efficient sliced merges and evolutionary merging. Their contribution of tinyevals on version 0.1 of Lamarck did much to validate the hypotheses of the DELLA->SLERP gradient process used here. |
|
- The authors behind the capable models that appear in the model_stock. |
|
### Models Merged |
|
|
|
**Top influences:** These ancestors are base models and present in the model_stocks, but are heavily re-emphasized in the DELLA and SLERP merges. |
|
|
|
- **[arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small)** - A brand new model from Arcee, refined from the notable cross-architecture Llama-to-Qwen distillation [arcee-ai/SuperNova-Medius](https://huggingface.co/arcee-ai/SuperNova-Medius). The first two layers are nearly exclusively from Virtuoso. It has proven to be a well-rounded performer, and contributes a noticeable boost to the model's prose quality. |
|
|
|
- **[CultriX/SeQwence-14B-EvolMerge](http://huggingface.co/CultriX/SeQwence-14B-EvolMerge)** - A top contender on reasoning benchmarks. |
|
|
|
**Reason:** While Virtuoso is the strongest influence the starting ending layers, the reasoning mo |
|
|
|
- **[CultriX/Qwen2.5-14B-Wernicke](http://huggingface.co/CultriX/Qwen2.5-14B-Wernicke)** - A top performer for Arc and GPQA, Wernicke is re-emphasized in small but highly-ranked portions of the model. |
|
|
|
- **[VAGOsolutions/SauerkrautLM-v2-14b-DPO](https://huggingface.co/VAGOsolutions/SauerkrautLM-v2-14b-DPO)** - This model's influence is understated, but aids BBH and coding capability. |
|
|
|
**Prose:** While the prose module is gently applied, its impact is noticeable on Lamarck 0.3's prose quality, and a DELLA merge re-emphasizes the contributions of two models particularly: |
|
|
|
- **[sthenno-com/miscii-14b-1028](https://huggingface.co/sthenno-com/miscii-14b-1028)** |
|
|
|
- **[underwoods/medius-erebus-magnum-14b](https://huggingface.co/underwoods/medius-erebus-magnum-14b)** |
|
|
|
**Model stock:** Two model_stock merges, specialized for specific aspects of performance, are used to mildly influence a large range of the model. |
|
|
|
- **[sometimesanotion/lamarck-14b-reason-model_stock](https://huggingface.co/sometimesanotion/lamarck-14b-reason-model_stock)** |
|
|
|
- **[sometimesanotion/lamarck-14b-prose-model_stock](https://huggingface.co/sometimesanotion/lamarck-14b-prose-model_stock)** - This brings in a little influence from [EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2](https://huggingface.co/EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2), [oxyapi/oxy-1-small](https://huggingface.co/oxyapi/oxy-1-small), and [allura-org/TQ2.5-14B-Sugarquill-v1](https://huggingface.co/allura-org/TQ2.5-14B-Sugarquill-v1). |
|
|
|
**Note on abliteration:** This author believes that adjacent services and not language models themselves are where guardrails are best placed. Effort to de-censor Lamarck will resume after the model has been further studied. |
|
|
|
### Configuration |
|
|
|
The following YAML configuration was used to produce this model: |
|
|
|
```yaml |
|
name: lamarck-14b-reason-della # This contributes the knowledge and reasoning pool, later to be merged |
|
merge_method: della # with the dominant instruction-following model |
|
base_model: arcee-ai/Virtuoso-Small |
|
tokenizer_source: arcee-ai/Virtuoso-Small |
|
parameters: |
|
int8_mask: false |
|
normalize: true |
|
rescale: false |
|
density: 0.30 |
|
weight: 0.50 |
|
epsilon: 0.08 |
|
lambda: 1.00 |
|
models: |
|
- model: CultriX/SeQwence-14B-EvolMerge |
|
parameters: |
|
density: 0.70 |
|
weight: 0.90 |
|
- model: sometimesanotion/lamarck-14b-reason-model_stock |
|
parameters: |
|
density: 0.90 |
|
weight: 0.60 |
|
- model: CultriX/Qwen2.5-14B-Wernicke |
|
parameters: |
|
density: 0.20 |
|
weight: 0.30 |
|
dtype: bfloat16 |
|
out_dtype: bfloat16 |
|
--- |
|
name: lamarck-14b-prose-della # This contributes the prose, later to be merged |
|
merge_method: della # with the dominant instruction-following model |
|
base_model: arcee-ai/Virtuoso-Small |
|
tokenizer_source: arcee-ai/Virtuoso-Small |
|
parameters: |
|
int8_mask: false |
|
normalize: true |
|
rescale: false |
|
density: 0.30 |
|
weight: 0.50 |
|
epsilon: 0.08 |
|
lambda: 0.95 |
|
models: |
|
- model: sthenno-com/miscii-14b-1028 |
|
parameters: |
|
density: 0.40 |
|
weight: 0.90 |
|
- model: sometimesanotion/lamarck-14b-prose-model_stock |
|
parameters: |
|
density: 0.60 |
|
weight: 0.70 |
|
- model: underwoods/medius-erebus-magnum-14b |
|
dtype: bfloat16 |
|
out_dtype: bfloat16 |
|
--- |
|
name: lamarck-14b-converge-della # This is the strongest control point to quickly |
|
merge_method: della # re-balance reasoning vs. prose |
|
base_model: arcee-ai/Virtuoso-Small |
|
tokenizer_source: arcee-ai/Virtuoso-Small |
|
parameters: |
|
int8_mask: false |
|
normalize: true |
|
rescale: false |
|
density: 0.30 |
|
weight: 0.50 |
|
epsilon: 0.08 |
|
lambda: 1.00 |
|
models: |
|
- model: sometimesanotion/lamarck-14b-reason-della |
|
parameters: |
|
density: 0.80 |
|
weight: 1.00 |
|
- model: arcee-ai/Virtuoso-Small |
|
parameters: |
|
density: 0.40 |
|
weight: 0.50 |
|
- model: sometimesanotion/lamarck-14b-prose-della |
|
parameters: |
|
density: 0.10 |
|
weight: 0.40 |
|
dtype: bfloat16 |
|
out_dtype: bfloat16 |
|
--- |
|
name: lamarck-14b-converge # Virtuoso has good capabilities all-around; it is 100% of the first |
|
merge_method: slerp # two layers, and blends into the reasoning+prose convergance |
|
base_model: arcee-ai/Virtuoso-Small # for some interesting boosts |
|
tokenizer_source: base |
|
parameters: |
|
t: [ 0.00, 0.60, 0.80, 0.80, 0.80, 0.70, 0.40 ] |
|
slices: |
|
- sources: |
|
- layer_range: [ 0, 2 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 0, 2 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.00, 0.00 ] |
|
- sources: |
|
- layer_range: [ 2, 8 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 2, 8 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.00, 0.60 ] |
|
- sources: |
|
- layer_range: [ 8, 16 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 8, 16 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.60, 0.70 ] |
|
- sources: |
|
- layer_range: [ 16, 24 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 16, 24 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.70, 0.70 ] |
|
- sources: |
|
- layer_range: [ 24, 32 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 24, 32 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.70, 0.70 ] |
|
- sources: |
|
- layer_range: [ 32, 40 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 32, 40 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.70, 0.60 ] |
|
- sources: |
|
- layer_range: [ 40, 48 ] |
|
model: arcee-ai/Virtuoso-Small |
|
- layer_range: [ 40, 48 ] |
|
model: merges/lamarck-14b-converge-della |
|
t: [ 0.60, 0.40 ] |
|
dtype: bfloat16 |
|
out_dtype: bfloat16 |
|
--- |
|
name: lamarck-14b-finalize |
|
merge_method: ties |
|
base_model: Qwen/Qwen2.5-14B |
|
tokenizer_source: Qwen/Qwen2.5-14B-Instruct |
|
parameters: |
|
int8_mask: false |
|
normalize: true |
|
rescale: false |
|
density: 1.00 |
|
weight: 1.00 |
|
models: |
|
- model: merges/lamarck-14b-converge |
|
dtype: bfloat16 |
|
out_dtype: bfloat16 |
|
--- |
|
|
|
``` |
|
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) |
|
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_sometimesanotion__Lamarck-14B-v0.3) |
|
|
|
| Metric |Value| |
|
|-------------------|----:| |
|
|Avg. |36.58| |
|
|IFEval (0-Shot) |50.32| |
|
|BBH (3-Shot) |51.27| |
|
|MATH Lvl 5 (4-Shot)|32.40| |
|
|GPQA (0-shot) |18.46| |
|
|MuSR (0-shot) |18.00| |
|
|MMLU-PRO (5-shot) |49.01| |
|
|
|
|

