
A newer version of the Gradio SDK is available:
5.16.1
metadata
title: 'GCViT: Global Context Vision Transformer'
colorFrom: indigo
sdk: gradio
sdk_version: 3.0.15
emoji: 🚀
pinned: false
license: apache-2.0
app_file: app.py
GCViT: Global Context Vision Transformer
![]()
![]()
![]()

Tensorflow 2.0 Implementation of GCViT
This library implements GCViT using Tensorflow 2.0 specifically in tf.keras.Model manner to get PyTorch flavor.
Update
- 15 Jan 2023 :
GCViTLargemodel added with ckpt. - 3 Sept 2022 : Annotated kaggle-notebook based on this project won Kaggle ML Research Spotlight: August 2022.
- 19 Aug 2022 : This project got acknowledged by Official repo here
Model
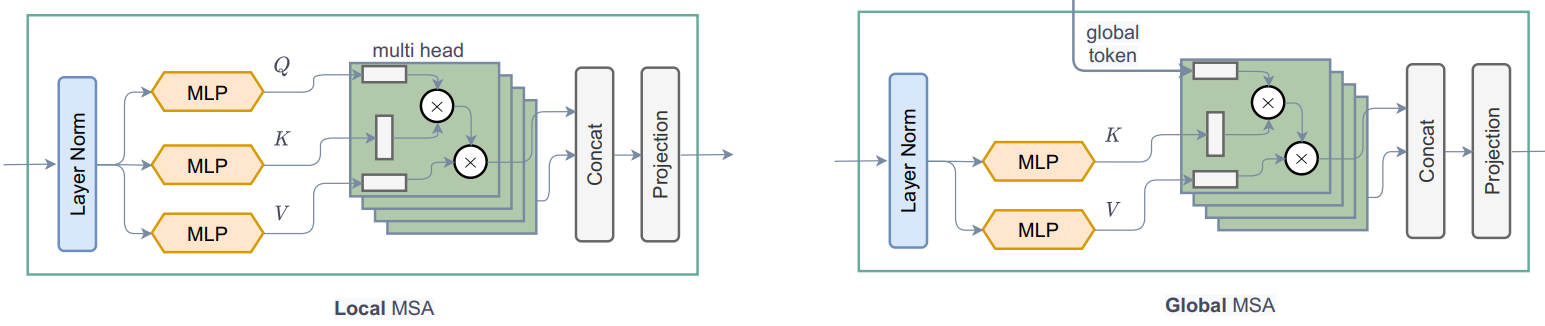
- Architecture:

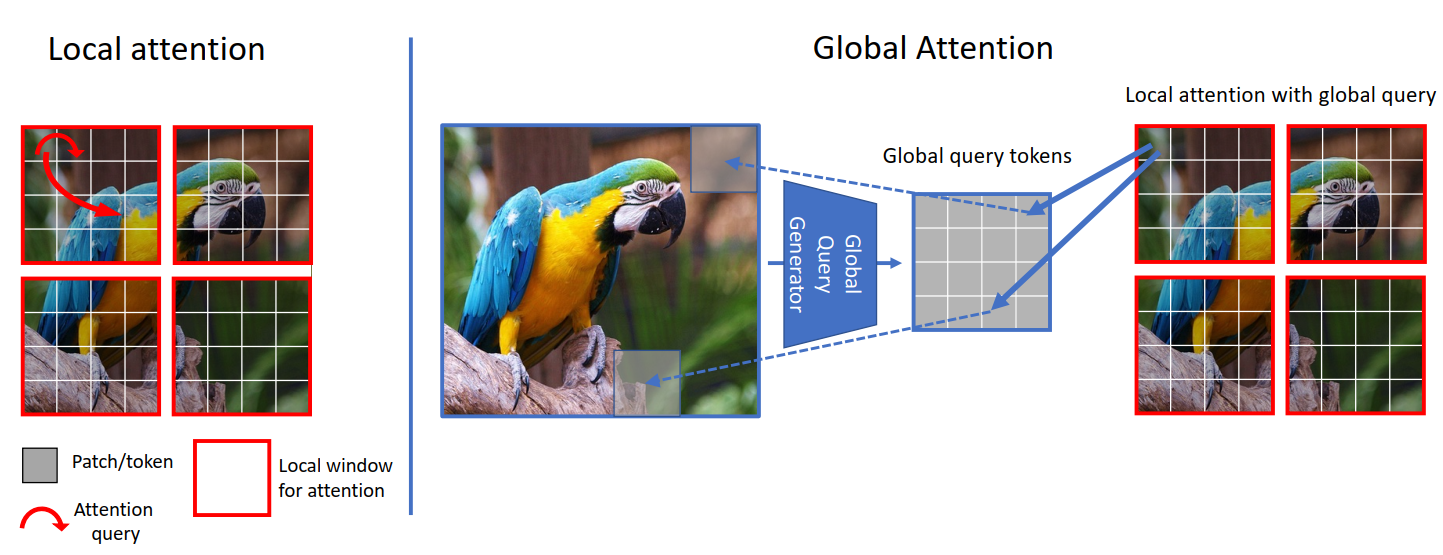
- Local Vs Global Attention:
Result
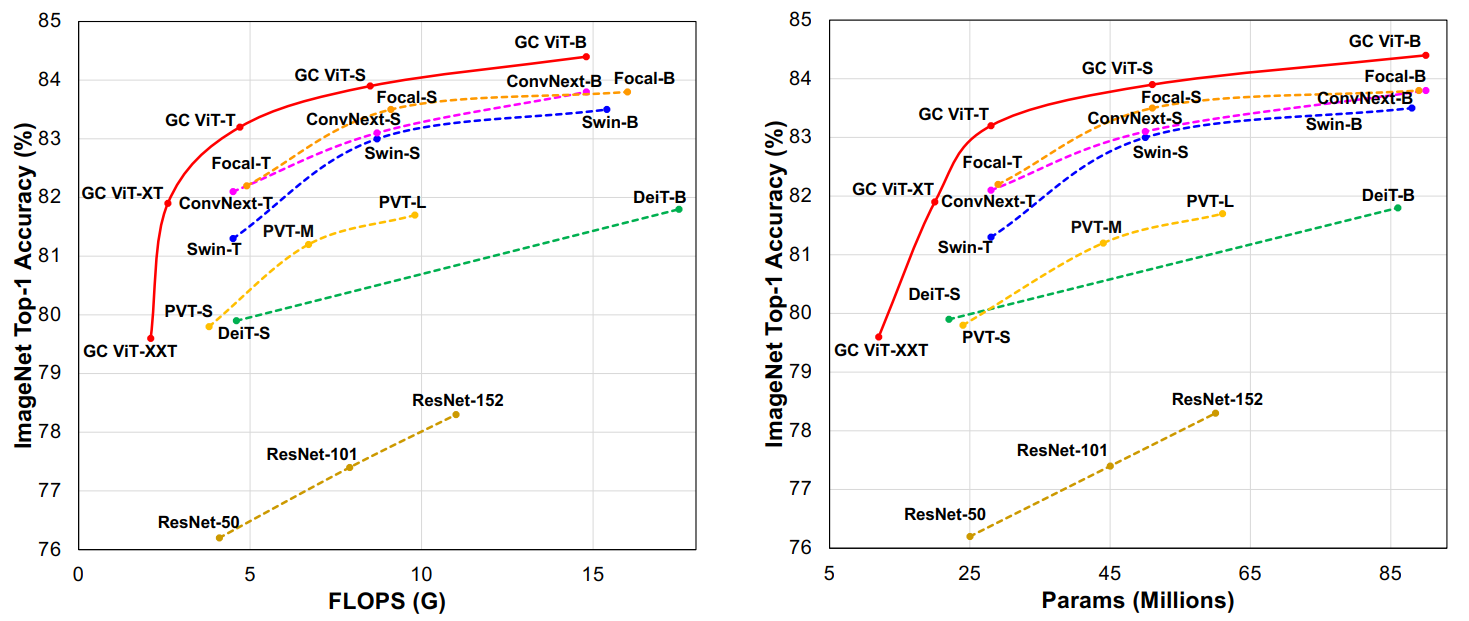
Official codebase had some issue which has been fixed recently (12 August 2022). Here's the result of ported weights on ImageNetV2-Test data,
| Model | Acc@1 | Acc@5 | #Params |
|---|---|---|---|
| GCViT-XXTiny | 0.663 | 0.873 | 12M |
| GCViT-XTiny | 0.685 | 0.885 | 20M |
| GCViT-Tiny | 0.708 | 0.899 | 28M |
| GCViT-Small | 0.720 | 0.901 | 51M |
| GCViT-Base | 0.731 | 0.907 | 90M |
| GCViT-Large | 0.734 | 0.913 | 202M |
Installation
pip install -U gcvit
# or
# pip install -U git+https://github.com/awsaf49/gcvit-tf
Usage
Load model using following codes,
from gcvit import GCViTTiny
model = GCViTTiny(pretrain=True)
Simple code to check model's prediction,
from skimage.data import chelsea
img = tf.keras.applications.imagenet_utils.preprocess_input(chelsea(), mode='torch') # Chelsea the cat
img = tf.image.resize(img, (224, 224))[None,] # resize & create batch
pred = model(img).numpy()
print(tf.keras.applications.imagenet_utils.decode_predictions(pred)[0])
Prediction:
[('n02124075', 'Egyptian_cat', 0.9194835),
('n02123045', 'tabby', 0.009686623),
('n02123159', 'tiger_cat', 0.0061576385),
('n02127052', 'lynx', 0.0011503297),
('n02883205', 'bow_tie', 0.00042479983)]
For feature extraction:
model = GCViTTiny(pretrain=True) # when pretrain=True, num_classes must be 1000
model.reset_classifier(num_classes=0, head_act=None)
feature = model(img)
print(feature.shape)
Feature:
(None, 512)
For feature map:
model = GCViTTiny(pretrain=True) # when pretrain=True, num_classes must be 1000
feature = model.forward_features(img)
print(feature.shape)
Feature map:
(None, 7, 7, 512)
Live-Demo
- For live demo on Image Classification & Grad-CAM, with ImageNet weights, click
powered by 🤗 Space and Gradio. here's an example,

Example
For working training example checkout these notebooks on Google Colab ![]() & Kaggle .
& Kaggle .
Here is grad-cam result after training on Flower Classification Dataset,

To Do
- Segmentation Pipeline
- New updated weights have been added.
- Working training example in Colab & Kaggle.
- GradCAM showcase.
- Gradio Demo.
- Build model with
tf.keras.Model. - Port weights from official repo.
- Support for
TPU.
Acknowledgement
- GCVit (Official)
- Swin-Transformer-TF
- tfgcvit
- keras_cv_attention_models
Citation
@article{hatamizadeh2022global,
title={Global Context Vision Transformers},
author={Hatamizadeh, Ali and Yin, Hongxu and Kautz, Jan and Molchanov, Pavlo},
journal={arXiv preprint arXiv:2206.09959},
year={2022}
}