
LongLLaMA: Focused Transformer Training for Context Scaling
TLDR
This repository contains the research preview of LongLLaMA, a large language model capable of handling long contexts of 256k tokens or even more.
LongLLaMA-Code is built upon the foundation of Code Llama.
LongLLaMA-Code has improved reasoning capabilities compared to CodeLlama, in particular we improve GSM8K math reasoning from 13% to 17.4% after just continued pre-training, no in-distribution fine-tuning.
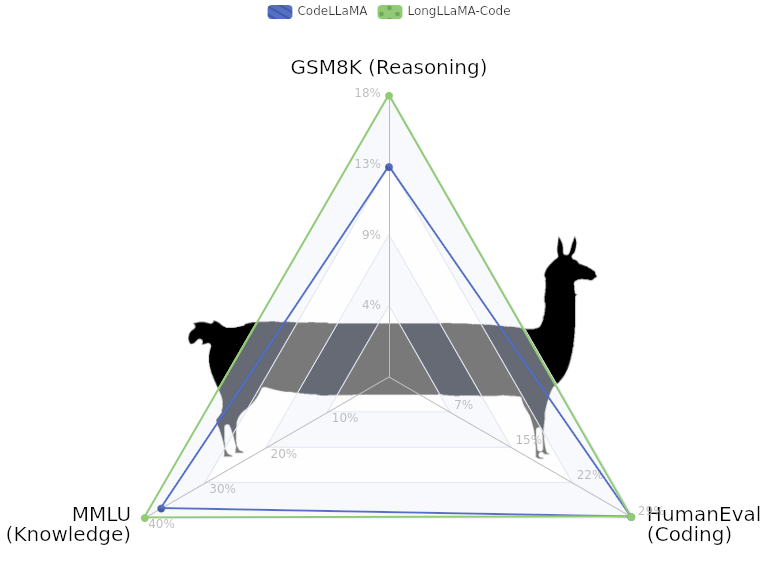
Overview
Base models
Focused Transformer: Contrastive Training for Context Scaling (FoT) presents a simple method for endowing language models with the ability to handle context consisting possibly of millions of tokens while training on significantly shorter input. FoT permits a subset of attention layers to access a memory cache of (key, value) pairs to extend the context length. The distinctive aspect of FoT is its training procedure, drawing from contrastive learning. Specifically, we deliberately expose the memory attention layers to both relevant and irrelevant keys (like negative samples from unrelated documents). This strategy incentivizes the model to differentiate keys connected with semantically diverse values, thereby enhancing their structure. This, in turn, makes it possible to extrapolate the effective context length much beyond what is seen in training.
LongLLaMA is an OpenLLaMA model finetuned with the FoT method,
with three layers used for context extension. Crucially, LongLLaMA is able to extrapolate much beyond the context length seen in training: 8k. E.g., in the passkey retrieval task, it can handle inputs of length 256k.
LongLLaMA-Code is a Code Llama model finetuned with the FoT method.
Model card
| LongLLaMA-3B | LongLLaMA-3Bv1.1 | LongLLaMA Code-7B | |
|---|---|---|---|
| Source model | OpenLLaMA-3B | OpenLLaMA-3Bv2 | CodeLLaMA-7b-hf |
| Source model tokens | 1T | 1 T | 2T + 0.5 T |
| Fine-tuning context | 8K | 32K | 32K |
| Fine-tuning tokens | 10B | 5B | 35B |
| Memory layers | 6, 12, 18 | 6, 12, 18 | 8, 16, 24 |
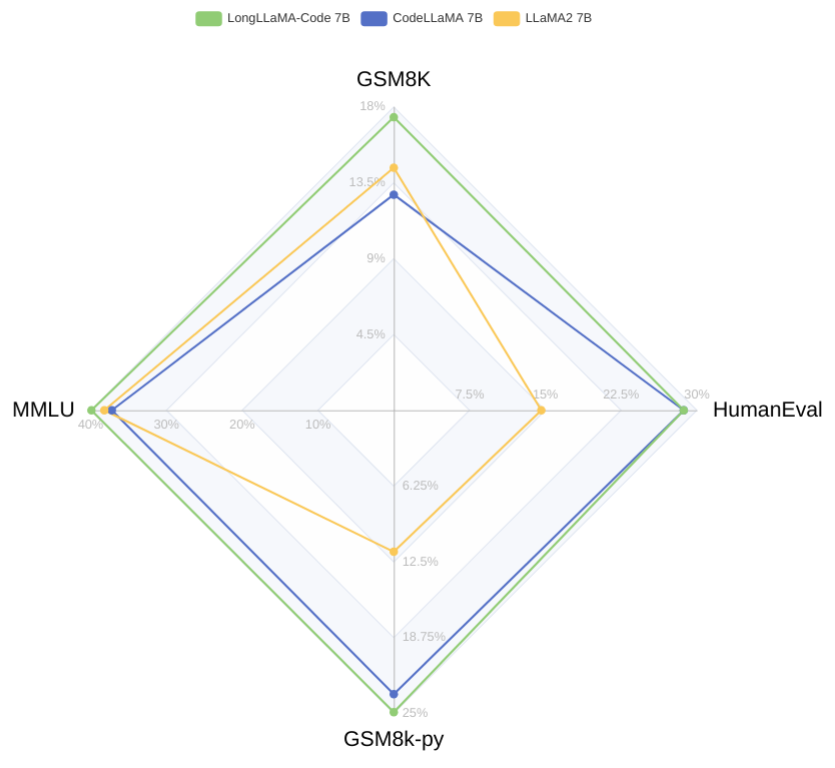
Results
Usage
See also:
Requirements
pip install --upgrade pip
pip install git+https://github.com/huggingface/transformers.git@main sentencepiece accelerate
Loading model
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("syzymon/long_llama_code_7b")
model = AutoModelForCausalLM.from_pretrained("syzymon/long_llama_code_7b",
torch_dtype=torch.float32,
trust_remote_code=True)
Input handling and generation
LongLLaMA uses the Hugging Face interface, the long input given to the model will be split into context windows and loaded into the memory cache.
prompt = "My name is Julien and I like to"
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
outputs = model(input_ids=input_ids)
During the model call, one can provide the parameter last_context_length which specifies the number of tokens left in the last context window. Tuning this parameter can improve generation as the first layers do not have access to memory. See details in How LongLLaMA handles long inputs.
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=1024,
num_beams=1,
last_context_length=3072,
do_sample=True,
temperature=1.0,
)
print(tokenizer.decode(generation_output[0]))
Additional configuration
LongLLaMA has several other parameters:
mem_layersspecifies layers endowed with memory (should be either an empty list or a list of all memory layers specified in the description of the checkpoint).mem_dtypeallows changing the type of memory cachemem_attention_groupingcan trade off speed for reduced memory usage. When equal to(4, 2048), the memory layers will process at most $4*2048$ queries at once ($4$ heads and $2048$ queries for each head).
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
tokenizer = LlamaTokenizer.from_pretrained("syzymon/long_llama_code_7b")
model = AutoModelForCausalLM.from_pretrained(
"syzymon/long_llama_code_7b", torch_dtype=torch.float32,
mem_layers=[],
mem_dtype='bfloat16',
trust_remote_code=True,
mem_attention_grouping=(4, 2048),
)
Drop-in use with LLaMA code
LongLLaMA checkpoints can also be used as a drop-in replacement for LLaMA checkpoints in Hugging Face implementation of LLaMA, but in this case, they will be limited to the original context length.
from transformers import LlamaTokenizer, LlamaForCausalLM
import torch
tokenizer = LlamaTokenizer.from_pretrained("syzymon/long_llama_code_7b")
model = LlamaForCausalLM.from_pretrained("syzymon/long_llama_code_7b", torch_dtype=torch.float32)
How LongLLaMA handles long inputs
Inputs over $ctx=2048$ ($ctx=4096$ for LongLLaMA Code) tokens are automatically split into windows $w_1, \ldots, w_m$. The first $m-2$ windows contain $ctx$ tokens each, $w_{m-1}$ has no more than $2048$ tokens, and $w_m$ contains the number of tokens specified by last_context_length. The model processes the windows one by one extending the memory cache after each. If use_cache is True, then the last window will not be loaded to the memory cache but to the local (generation) cache.
The memory cache stores $(key, value)$ pairs for each head of the specified memory layers mem_layers. In addition to this, it stores attention masks.
If use_cache=True (which is the case in generation), LongLLaMA will use two caches: the memory cache for the specified layers and the local (generation) cache for all layers. When the local cache exceeds $2048$ elements, its content is moved to the memory cache for the memory layers.
For simplicity, context extension is realized with a memory cache and full attention in this repo. Replacing this simple mechanism with a KNN search over an external database is possible with systems like Faiss. This potentially would enable further context length scaling. We leave this as a future work.
Authors
Citation
To cite this work please use
@misc{tworkowski2023focused,
title={Focused Transformer: Contrastive Training for Context Scaling},
author={Szymon Tworkowski and Konrad Staniszewski and Mikołaj Pacek and Yuhuai Wu and Henryk Michalewski and Piotr Miłoś},
year={2023},
eprint={2307.03170},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
License
For the LongLLaMA Code see codellama/CodeLlama-7b-hf license.
Some of the examples use external code (see headers of files for copyright notices and licenses).
Acknowledgments
Special thanks to Keiran Paster for providing immensely valuable suggestions about the pre-training data.
We gratefully acknowledge the TPU Research Cloud program, which was instrumental to our research by providing significant computational resources. We are also grateful to Xinyang Geng and Hao Liu for releasing OpenLLaMA checkpoints and the EasyLM library.
We would like to thank Xiaosong,He for suggestions on how to improve the explanations of cross-batch code.
- Downloads last month
- 31
Datasets used to train syzymon/long_llama_code_7b
Evaluation results
- pass@1 on HumanEvalself-reported0.286
- pass@1 on GSM8K-Pythonself-reported0.249
- pass@1 on GSM8Kself-reported0.174
- accuracy on MMLUself-reported0.399