
YuLan-Mini
Collection
A highly capable 2.4B lightweight LLM using only 1T pre-training data with all details.
•
5 items
•
Updated
•
14

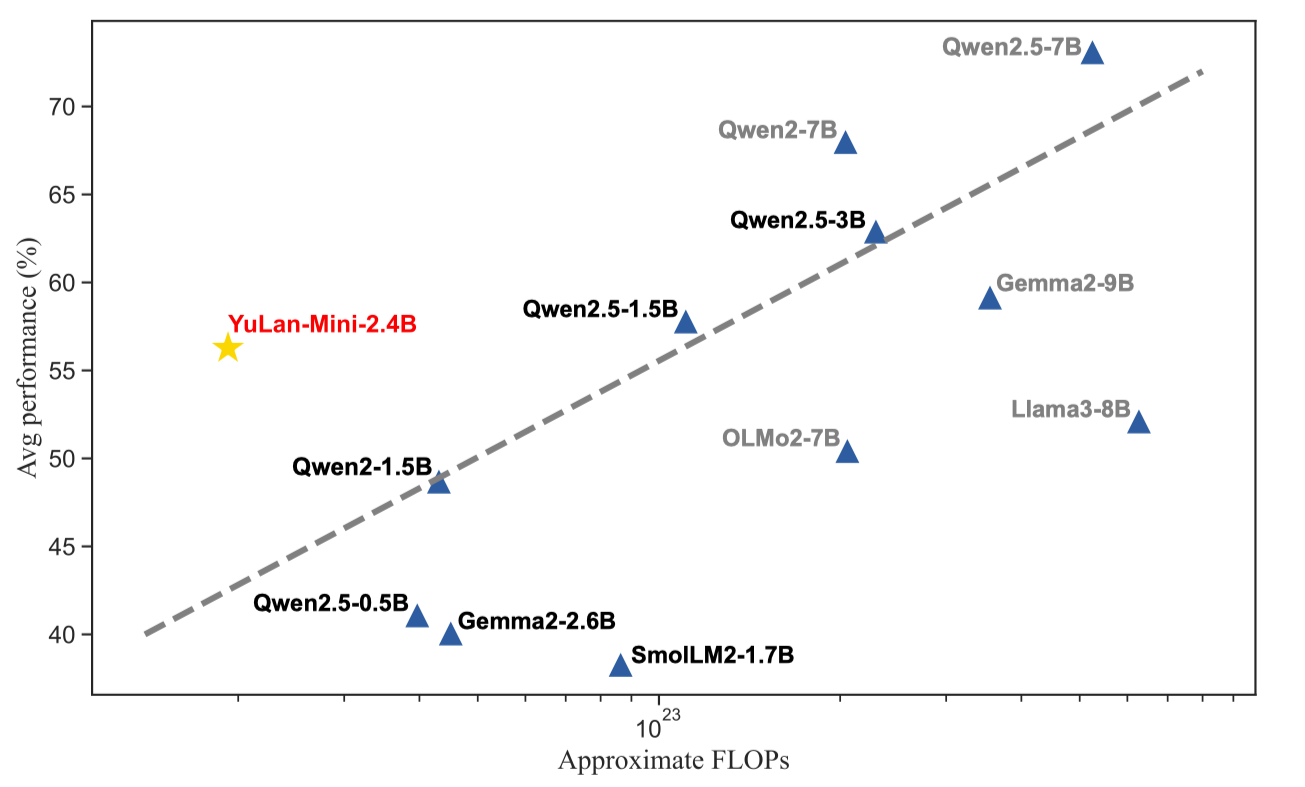
YuLan-Mini is a lightweight language model with 2.4 billion parameters. It achieves performance comparable to industry-leading models trained on significantly more data, despite being pre-trained on only 1.08T tokens. The model excels particularly in the domains of mathematics and code. To facilitate reproducibility, we will open-source the relevant pre-training resources.
| Model | Context Length | SFT | DPO | 🤗 Hugging Face | ModelScope | Wise Model |
|---|---|---|---|---|---|---|
| YuLan-Mini | 28K | ❎ | ❎ | Base |
Base |
Base |
| YuLan-Mini-Instruct | 28K | ✅ | ✅ | Instruct |
Our pre-training methodology improves training efficiency through three key innovations:
| Models | Model Size | # Train Tokens | Context Length | MATH 500 | GSM 8K | Human Eval | MBPP | RACE Middle | RACE High | RULER |
|---|---|---|---|---|---|---|---|---|---|---|
| MiniCPM | 2.6B | 1.06T | 4K | 15.00 | 53.83 | 50.00* | 47.31 | 56.61 | 44.27 | N/A |
| Qwen-2 | 1.5B | 7T | 128K | 22.60 | 46.90* | 34.80* | 46.90* | 55.77 | 43.69 | 60.16 |
| Qwen2.5 | 0.5B | 18T | 128K | 23.60 | 41.60* | 30.50* | 39.30* | 52.36 | 40.31 | 49.23 |
| Qwen2.5 | 1.5B | 18T | 128K | 45.40 | 68.50* | 37.20* | 60.20* | 58.77 | 44.33 | 68.26 |
| Gemma2 | 2.6B | 2T | 8K | 18.30* | 30.30* | 19.50* | 42.10* | - | - | N/A |
| StableLM2 | 1.7B | 2T | 4K | - | 20.62 | 8.50* | 17.50 | 56.33 | 45.06 | N/A |
| SmolLM2 | 1.7B | 11T | 8K | 11.80 | - | 23.35 | 45.00 | 55.77 | 43.06 | N/A |
| Llama3.2 | 3.2B | 9T | 128K | 7.40 | - | 29.30 | 49.70 | 55.29 | 43.34 | 77.06 |
| YuLan-Mini | 2.4B | 1.04T | 4K | 32.60 | 66.65 | 61.60 | 66.70 | 55.71 | 43.58 | N/A |
| YuLan-Mini | 2.4B | 1.08T | 28K | 37.80 | 68.46 | 64.00 | 65.90 | 57.18 | 44.57 | 51.48 |
| Models | LAMBADA | MMLU | CMMLU | CEval | HellaSwag | WinoGrande | StoryCloze | ARC-e | ARC-c |
|---|---|---|---|---|---|---|---|---|---|
| MiniCPM-2.6B | 61.91 | 53.37 | 48.97 | 48.24 | 67.92 | 65.74 | 78.51 | 55.51 | 43.86 |
| Qwen2-1.5B | 64.68 | 55.90 | 70.76 | 71.94 | 66.11 | 66.14 | 77.60 | 62.21 | 42.92 |
| Qwen2.5-0.5B | 52.00 | 47.50 | 52.17 | 54.27 | 50.54 | 55.88 | 71.67 | 56.10 | 39.51 |
| Qwen2.5-1.5B | 62.12 | 60.71 | 67.82 | 69.05 | 67.18 | 64.48 | 76.80 | 71.51 | 53.41 |
| Gemma2-2.6B | - | 52.20* | - | 28.00* | 74.60* | 71.50* | - | - | 55.70* |
| StableLM2-1.7B | 66.15 | 40.37 | 29.29 | 26.99 | 69.79 | 64.64 | 78.56 | 54.00 | 40.78 |
| SmolLM2-1.7B | 67.42 | 51.91 | 33.46 | 35.10 | 72.96 | 67.40 | 79.32 | 44.82 | 35.49 |
| Llama3.2-3B | 69.08 | 63.40 | 44.44 | 44.49 | 75.62 | 67.48 | 76.80 | 70.12 | 48.81 |
| YuLan-Mini | 64.72 | 51.79 | 48.35 | 51.47 | 68.65 | 67.09 | 76.37 | 69.87 | 50.51 |
| YuLan-Mini | 65.67 | 49.10 | 45.45 | 48.23 | 67.22 | 67.24 | 75.89 | 67.47 | 49.32 |
To enhance research transparency and reproducibility, we are open-sourcing relevant pre-training resources:
The pre-training and evaluation code will be released in a future update.
| Stage | Curriculum Phase | 4K Context | 28K Context | Optimizer | Inference Architecture | LAMBADA Acc |
GSM8K Acc |
HumanEval pass@1 |
|---|---|---|---|---|---|---|---|---|
| Stable | 5 | YuLan-Mini-Phase5 | yulanmini |
53.85 | 3.41 | 12.26 | ||
| Stable | 10 | YuLan-Mini-Phase10 | yulanmini |
55.00 | 9.57 | 15.95 | ||
| Stable | 15 | YuLan-Mini-Phase15 | yulanmini |
55.81 | 13.81 | 16.99 | ||
| Stable | 20 | YuLan-Mini-Phase20 | ✅ | yulanmini |
55.81 | 21.39 | 20.79 | |
| Stable | 25 (1T tokens) | YuLan-Mini-Before-Annealing | ✅ | yulanmini |
55.67 | 29.94 | 34.06 | |
| Annealing | 26 | YuLan-Mini-4K | llama* |
64.72 | 66.65 | 61.60 | ||
| Annealing | 27 | YuLan-Mini | llama* |
65.67 | 68.46 | 64.00 |
*: For easier inference and deployment, we merged the re-parameterized added parameters and scaling factors into the final released models (YuLan-Mini and YuLan-Mini-Intermediate-4K), enabling it to run on the Llama architecture. However, these parameters are still retained in the intermediate checkpoints from the training process.

Data cleaning and synthesis pipeline:

The synthetic data we are using is released in YuLan-Mini-Datasets
Below is a simple example for inference using Huggingface:
Huggingface Inference Example
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("yulan-team/YuLan-Mini")
model = AutoModelForCausalLM.from_pretrained("yulan-team/YuLan-Mini", torch_dtype=torch.bfloat16)
# Input text
input_text = "Renmin University of China is"
inputs = tokenizer(input_text, return_tensors="pt")
# Completion
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
vLLM Serve Example
vllm serve yulan-team/YuLan-Mini --dtype bfloat16
SGLang Serve Example
python -m sglang.launch_server --model-path yulan-team/YuLan-Mini --port 30000 --host 0.0.0.0
YuLan-Mini is developed and maintained by AI Box, Renmin University of China.
If you find YuLan-Mini helpful for your research or development, please cite our technical report:
@misc{hu2024yulanmini,
title={YuLan-Mini: An Open Data-efficient Language Model},
author={Yiwen Hu and Huatong Song and Jia Deng and Jiapeng Wang and Jie Chen and Kun Zhou and Yutao Zhu and Jinhao Jiang and Zican Dong and Wayne Xin Zhao and Ji-Rong Wen},
year={2024},
eprint={2412.17743},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.17743},
}