|
--- |
|
license: apache-2.0 |
|
annotations_creators: |
|
- machine-generated |
|
language_creators: |
|
- found |
|
task_categories: |
|
- sentence-similarity |
|
language: |
|
- ro |
|
multilinguality: |
|
- monolingual |
|
tags: |
|
- sentence similarity |
|
- paraphrase |
|
- romanian |
|
- nlp |
|
task_ids: |
|
- text-scoring |
|
- semantic-similarity-scoring |
|
- semantic-similarity-classification |
|
pretty_name: Romanian Bible Paraphrase Corpus |
|
size_categories: |
|
- 100K<n<1M |
|
dataset_info: |
|
features: |
|
- name: text1 |
|
dtype: string |
|
- name: text2 |
|
dtype: string |
|
- name: score |
|
dtype: int8 |
|
--- |
|
|
|
# Dataset Card for "Romanian Bible Paraphrase Corpus" |
|
|
|
## Table of Contents |
|
- [Dataset Description](#dataset-description) |
|
- [Dataset Summary](#dataset-summary) |
|
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards) |
|
- [Languages](#languages) |
|
- [Dataset Structure](#dataset-structure) |
|
- [Data Instances](#data-instances) |
|
- [Data Fields](#data-fields) |
|
- [Data Splits](#data-splits) |
|
- [Dataset Creation](#dataset-creation) |
|
- [Curation Rationale](#curation-rationale) |
|
- [Source Data](#source-data) |
|
- [Annotations](#annotations) |
|
- [Personal and Sensitive Information](#personal-and-sensitive-information) |
|
- [Considerations for Using the Data](#considerations-for-using-the-data) |
|
- [Social Impact of Dataset](#social-impact-of-dataset) |
|
- [Discussion of Biases](#discussion-of-biases) |
|
- [Other Known Limitations](#other-known-limitations) |
|
- [Additional Information](#additional-information) |
|
- [Dataset Curators](#dataset-curators) |
|
- [Licensing Information](#licensing-information) |
|
- [Citation Information](#citation-information) |
|
- [Contributions](#contributions) |
|
|
|
## Dataset Description |
|
<!-- |
|
- **Paper:** Fake News Opensources |
|
--> |
|
- **Homepage:** [https://github.com/AndyTheFactory/ro-paraphrase-bible](https://github.com/AndyTheFactory/ro-paraphrase-bible) |
|
- **Repository:** [https://github.com/AndyTheFactory/ro-paraphrase-bible](https://github.com/AndyTheFactory/ro-paraphrase-bible) |
|
- **Point of Contact:** [Andrei Paraschiv](https://github.com/AndyTheFactory) |
|
- |
|
### Dataset Summary |
|
|
|
A paraphprase corpus created from 10 different Romanian language Bible versions. Since the Bible has all paragraphs uniquely numbered an alignment between two |
|
versions is straighforward. |
|
We compiled a complete combination of paragraph pairs from the following Bible versions: |
|
|
|
- Română Noul Testament Interconfesional 2009 |
|
- Biblia în versuri 2014 |
|
- Biblia Traducerea Fidela 2015 |
|
- Biblia în Versiune Actualizată 2018 |
|
- Ediția Dumitru Cornilescu revizuită 2022 |
|
- Noua Traducere Românească |
|
- Noul Testament SBR 2023 |
|
- Versiunea Biblia Romano-Catolică 2020 |
|
- Biblia sau Sfânta Scriptură cu Trimiteri 1924, Dumitru Cornilescu |
|
- Traducere Literală Cornilescu 1931 |
|
|
|
In order to provide a similarity score between two paragraphs, we use FuzzyWuzzy library to compute the partial_token_sort_ratio (PTSoR) |
|
between the lemmatized versions of the two texts. The final similarity score between matching paragraphs was computed as follows: |
|
|
|
> score = 50 + ptsor // 2 |
|
|
|
where ptsor = partial_token_sort_ratio(lemmatize(text1), lemmatize(text2)) |
|
|
|
|
|
We also provide a set of non-matching texts, generated from a random pairing of paragraphs. |
|
The score for the non-matching paragraphs was computed using this formula: |
|
|
|
> score = int(ptsor / 2 +10) |
|
|
|
The final dataset contains 904,815 similar records and 218,977 non matching records, totaling 1,123,927 |
|
|
|
### Languages |
|
|
|
Romanian |
|
|
|
## Dataset Structure |
|
|
|
|
|
### Data Instances |
|
|
|
|
|
An example record looks as follows. |
|
|
|
``` |
|
{ |
|
'text1': 'Poporul a început să strige: „Este glasul lui Dumnezeu, nu al unui om!”', |
|
'text2': 'Norodul a strigat: „Glas de Dumnezeu, nu de om!”', |
|
'score': 82 |
|
} |
|
``` |
|
|
|
### Data Fields |
|
|
|
- `text1`, `text2`: compared Paragraphs |
|
- `score`: 0 - 100 matching score (integer) - records with score > 50 are matches |
|
|
|
### Data Statistics |
|
**Score Distribution**: |
|
|
|
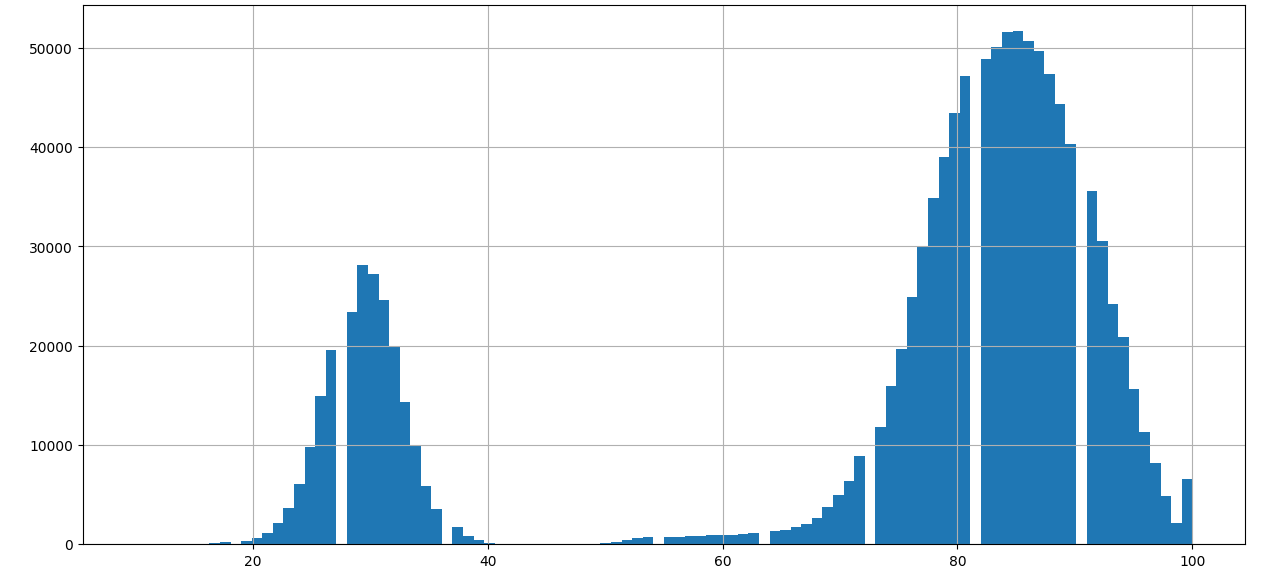 |
|
|
|
|
|
|
|
Statistics for matching record scores: |
|
``` |
|
count 904950.000000 |
|
mean 83.998228 |
|
std 7.083741 |
|
min 50.000000 |
|
25% 80.000000 |
|
50% 84.000000 |
|
75% 89.000000 |
|
max 100.000000 |
|
|
|
``` |
|
|
|
Statistics for non-matching record scores: |
|
|
|
``` |
|
count 218977.000000 |
|
mean 29.400873 |
|
std 3.339921 |
|
min 10.000000 |
|
25% 27.000000 |
|
50% 29.000000 |
|
75% 32.000000 |
|
max 40.000000 |
|
``` |
|
|
|
## Dataset Creation |
|
|
|
|
|
### Curation Rationale |
|
|
|
### Source Data |
|
|
|
Romanian Language Bible translations |
|
|
|
|
|
#### Initial Data Collection and Normalization |
|
|
|
|
|
|
|
#### Who are the source language producers? |
|
|
|
|
|
### Annotations |
|
|
|
|
|
#### Annotation process |
|
|
|
|
|
#### Who are the annotators? |
|
|
|
|
|
### Personal and Sensitive Information |
|
|
|
|
|
## Considerations for Using the Data |
|
|
|
|
|
### Social Impact of Dataset |
|
|
|
|
|
### Discussion of Biases |
|
|
|
|
|
### Other Known Limitations |
|
|
|
The dataset is biased towards some archaic language. Additionally, it involves religious figures and phrase constructions that are rarly used in the common language. |
|
|
|
## Additional Information |
|
|
|
|
|
### Dataset Curators |
|
|
|
|
|
### Licensing Information |
|
|
|
This data is available and distributed under Apache-2.0 license |
|
|
|
### Citation Information |
|
|
|
``` |
|
tbd |
|
``` |
|
|
|
|
|
### Contributions |
