Spaces:
Running

title: Qwen Agent
emoji: 📈
colorFrom: yellow
colorTo: purple
sdk: docker
pinned: false
license: apache-2.0
app_port: 7860
中文 | English
![]()
Qwen-Agent是一个代码框架,用于发掘开源通义千问模型(Qwen)的工具使用、规划、记忆能力。 在Qwen-Agent的基础上,我们开发了一个名为BrowserQwen的Chrome浏览器扩展,它具有以下主要功能:
- 与Qwen讨论当前网页或PDF文档的内容。
- 在获得您的授权后,BrowserQwen会记录您浏览过的网页和PDF/Word/PPT材料,以帮助您快速了解多个页面的内容,总结您浏览过的内容,并自动化繁琐的文字工作。
- 集成各种插件,包括可用于数学问题求解、数据分析与可视化、处理文件等的代码解释器(Code Interpreter)。
用例演示
如果您更喜欢观看视频,而不是效果截图,可以参见视频演示。
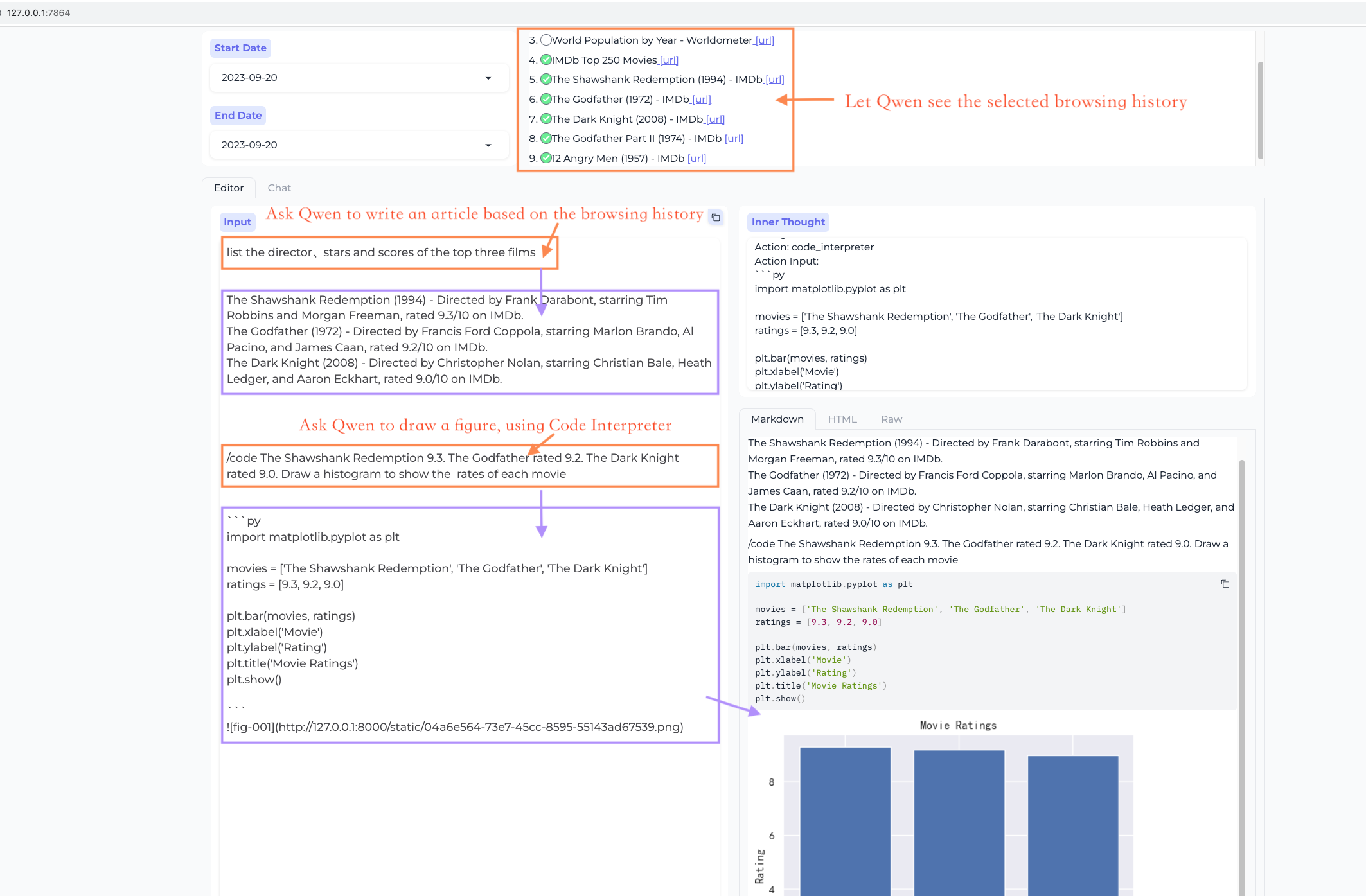
工作台 - 创作模式
根据浏览过的网页、PDFs素材进行长文创作

调用插件辅助富文本创作
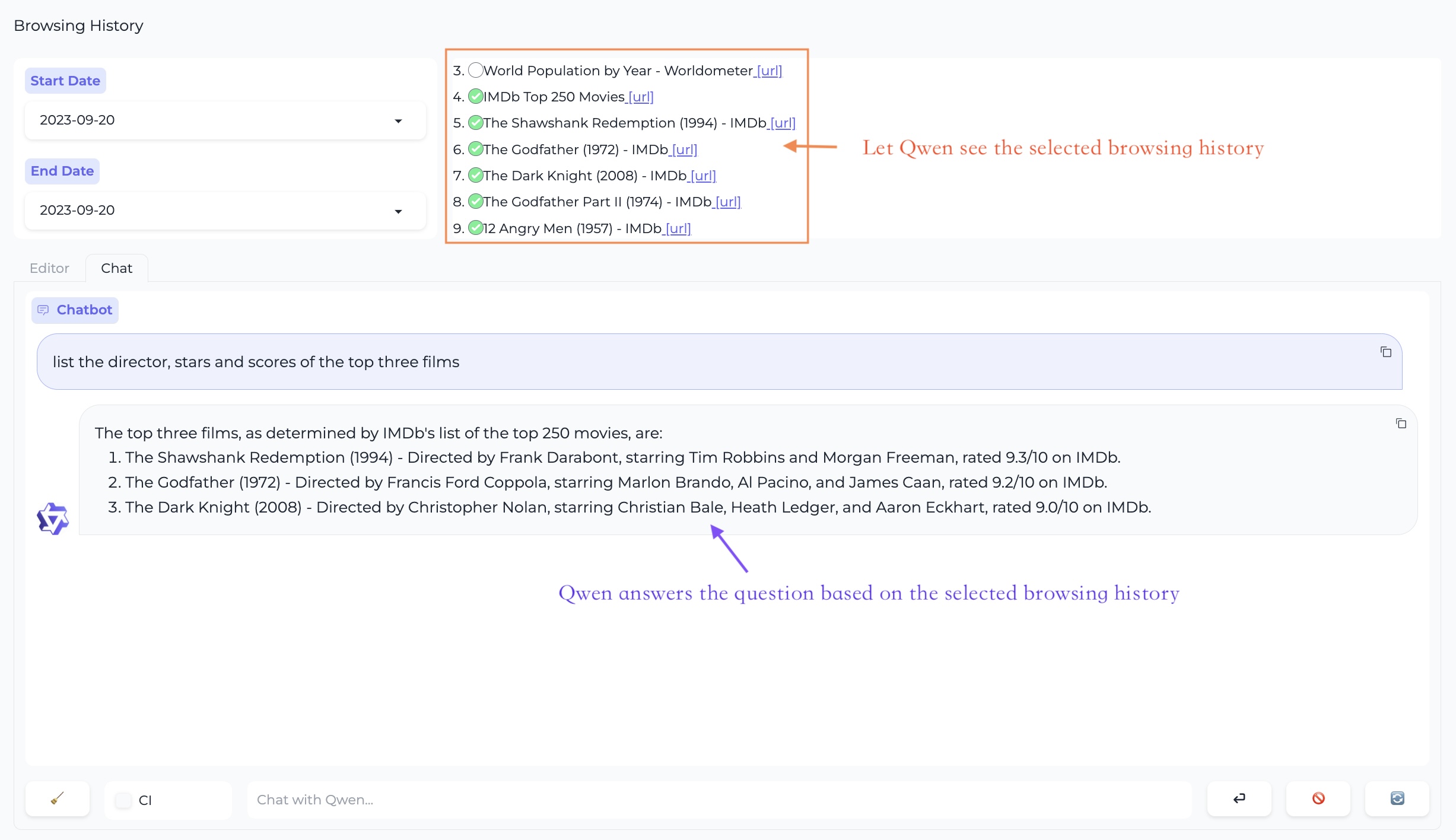
工作台 - 对话模式
多网页问答
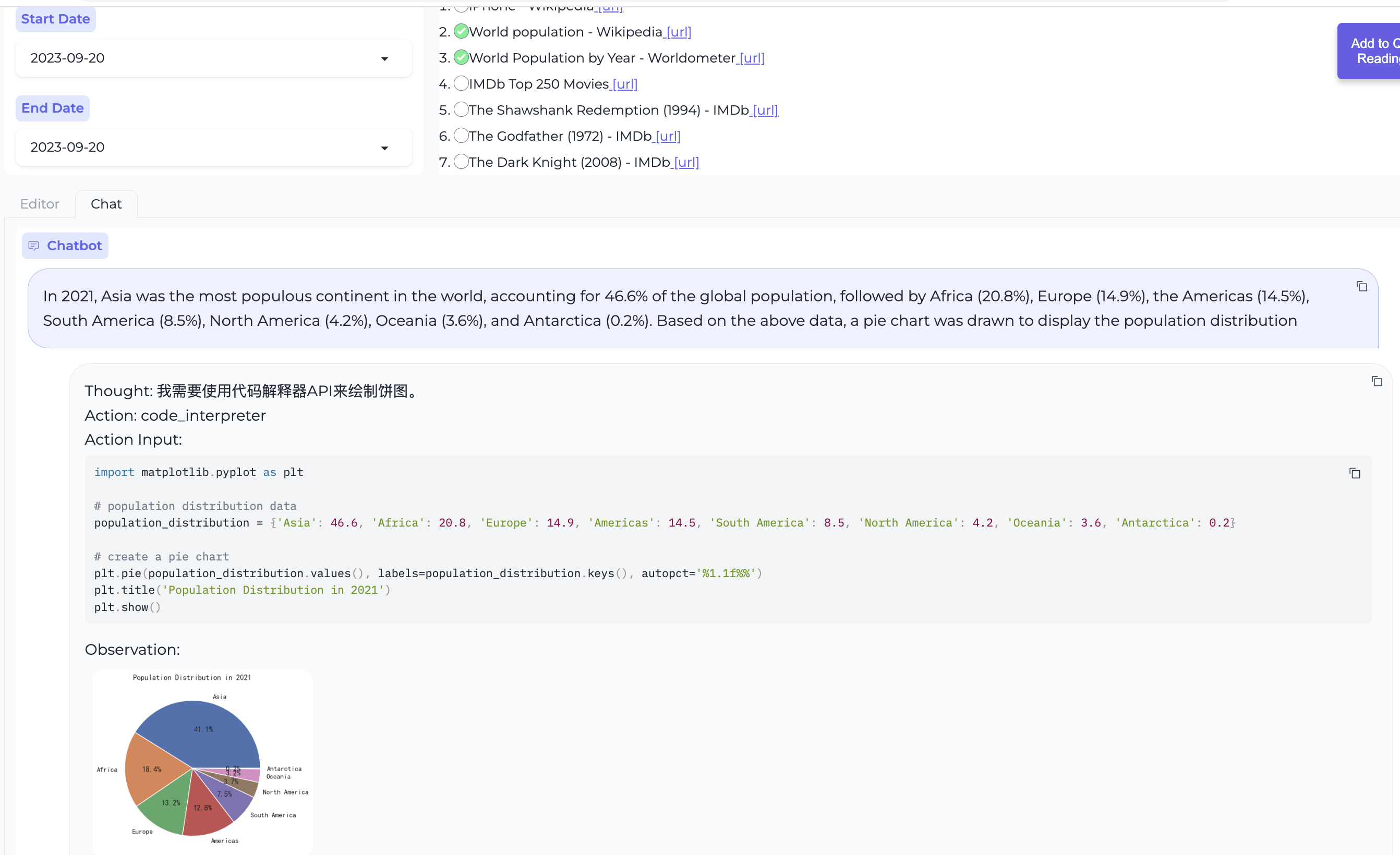
使用代码解释器绘制数据图表
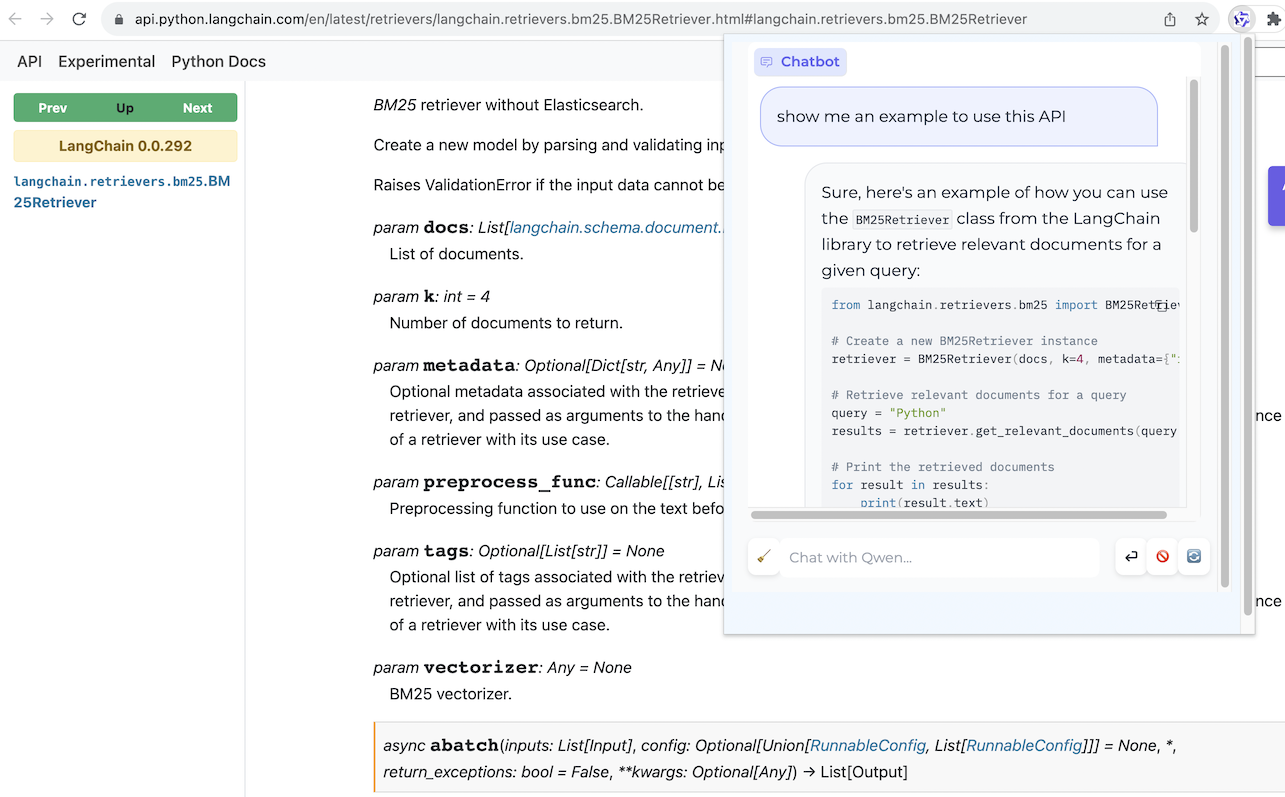
浏览器助手
网页问答
PDF文档问答
BrowserQwen 使用说明
支持环境:MacOS,Linux,Windows。
第一步 - 部署模型服务
如果您正在使用阿里云提供的DashScope服务来访问Qwen系列模型,可以跳过这一步,直接到第二步。
但如果您不想使用DashScope,而是希望自己部署一个模型服务。那么可以参考Qwen项目,部署一个兼容OpenAI API的模型服务:
# 安装依赖
git clone git@github.com:QwenLM/Qwen.git
cd Qwen
pip install -r requirements.txt
pip install fastapi uvicorn "openai<1.0.0" "pydantic>=2.3.0" sse_starlette
# 启动模型服务,通过 -c 参数指定模型版本
# - 指定 --server-name 0.0.0.0 将允许其他机器访问您的模型服务
# - 指定 --server-name 127.0.0.1 则只允许部署模型的机器自身访问该模型服务
python openai_api.py --server-name 0.0.0.0 --server-port 7905 -c Qwen/Qwen-14B-Chat
目前,我们支持指定-c参数以加载 Qwen 的 Hugging Face主页 上的模型,比如Qwen/Qwen-1_8B-Chat、Qwen/Qwen-7B-Chat、Qwen/Qwen-14B-Chat、Qwen/Qwen-72B-Chat,以及它们的Int4和Int8版本。
第二步 - 部署本地数据库服务
在这一步,您需要在您的本地机器上(即您可以打开Chrome浏览器的那台机器),部署维护个人浏览历史、对话历史的数据库服务。
首次启动数据库服务前,请记得安装相关的依赖:
# 安装依赖
git clone https://github.com/QwenLM/Qwen-Agent.git
cd Qwen-Agent
pip install -r requirements.txt
如果跳过了第一步、因为您打算使用DashScope提供的模型服务的话,请执行以下命令启动数据库服务:
# 启动数据库服务,通过 --llm 参数指定您希望通过DashScope使用的具体模型
# 参数 --llm 可以是如下之一,按资源消耗从小到大排序:
# - qwen-7b-chat (与开源的Qwen-7B-Chat相同模型)
# - qwen-14b-chat (与开源的Qwen-14B-Chat相同模型)
# - qwen-turbo
# - qwen-plus
# 您需要将YOUR_DASHSCOPE_API_KEY替换为您的真实API-KEY。
export DASHSCOPE_API_KEY=YOUR_DASHSCOPE_API_KEY
python run_server.py --model_server dashscope --llm qwen-7b-chat --workstation_port 7864
如果您没有在使用DashScope、而是参考第一步部署了自己的模型服务的话,请执行以下命令:
# 启动数据库服务,通过 --model_server 参数指定您在 Step 1 里部署好的模型服务
# - 若 Step 1 的机器 IP 为 123.45.67.89,则可指定 --model_server http://123.45.67.89:7905/v1
# - 若 Step 1 和 Step 2 是同一台机器,则可指定 --model_server http://127.0.0.1:7905/v1
python run_server.py --model_server http://{MODEL_SERVER_IP}:7905/v1 --workstation_port 7864
现在您可以访问 http://127.0.0.1:7864/ 来使用工作台(Workstation)的创作模式(Editor模式)和对话模式(Chat模式)了。
关于工作台的使用技巧,请参见工作台页面的文字说明、或观看视频演示。
Step 3. 安装浏览器助手
安装BrowserQwen的Chrome插件(又称Chrome扩展程序):
- 打开Chrome浏览器,在浏览器的地址栏中输入
chrome://extensions/并按下回车键; - 确保右上角的
开发者模式处于打开状态,之后点击加载已解压的扩展程序上传本项目下的browser_qwen目录并启用; - 单击谷歌浏览器右上角
扩展程序图标,将BrowserQwen固定在工具栏。
注意,安装Chrome插件后,需要刷新页面,插件才能生效。
当您想让Qwen阅读当前网页的内容时:
- 请先点击屏幕上的
Add to Qwen's Reading List按钮,以授权Qwen在后台分析本页面。 - 再单击浏览器右上角扩展程序栏的Qwen图标,便可以和Qwen交流当前页面的内容了。
视频演示
可查看以下几个演示视频,了解BrowserQwen的基本操作:
评测基准
我们也开源了一个评测基准,用于评估一个模型写Python代码并使用Code Interpreter进行数学解题、数据分析、及其他通用任务时的表现。评测基准见 benchmark 目录,当前的评测结果如下:
| In-house Code Interpreter Benchmark (Version 20231206) | ||||
|---|---|---|---|---|
| Model | 代码执行结果正确性 (%) | 生成代码的可执行率 (%) | ||
| Math↑ | Visualization-Hard↑ | Visualization-Easy↑ | General↑ | |
| GPT-4 | 82.8 | 66.7 | 60.8 | 82.8 |
| GPT-3.5 | 47.3 | 33.3 | 55.7 | 74.1 |
| LLaMA2-13B-Chat | 8.3 | 1.2 | 15.2 | 48.3 |
| CodeLLaMA-13B-Instruct | 28.2 | 15.5 | 21.5 | 74.1 |
| InternLM-20B-Chat | 34.6 | 10.7 | 24.1 | 65.5 |
| ChatGLM3-6B | 54.2 | 4.8 | 15.2 | 62.1 |
| Qwen-1.8B-Chat | 25.6 | 21.4 | 22.8 | 65.5 |
| Qwen-7B-Chat | 41.9 | 23.8 | 38.0 | 67.2 |
| Qwen-14B-Chat | 58.4 | 31.0 | 45.6 | 65.5 |
| Qwen-72B-Chat | 72.7 | 41.7 | 43.0 | 82.8 |
免责声明
本项目并非正式产品,而是一个概念验证项目,用于演示Qwen系列模型的能力。
重要提示:代码解释器未进行沙盒隔离,会在部署环境中执行代码。请避免向Qwen发出危险指令,切勿将该代码解释器直接用于生产目的。